
Improving Deep Mutual Learning via Knowledge Distillation


Abstract
:1. Introduction
- Developing a new approach (FDDML and HDDML) that combines the two methods DML and KD into a formula to improve the performance of DML with adopting three losses by using variations of existing network architectures to improve the network performance;
- Exploring the effect of variations in the number of batch size on knowledge transfer from a teacher model has been trained with the original sample size in the TinyImageNet dataset to several untrained students with a downsampled size of 32 × 32;
- We show the effectiveness of our approach with Cinic-10 that two different batch size includes 64 and 128.
2. Materials and Methods
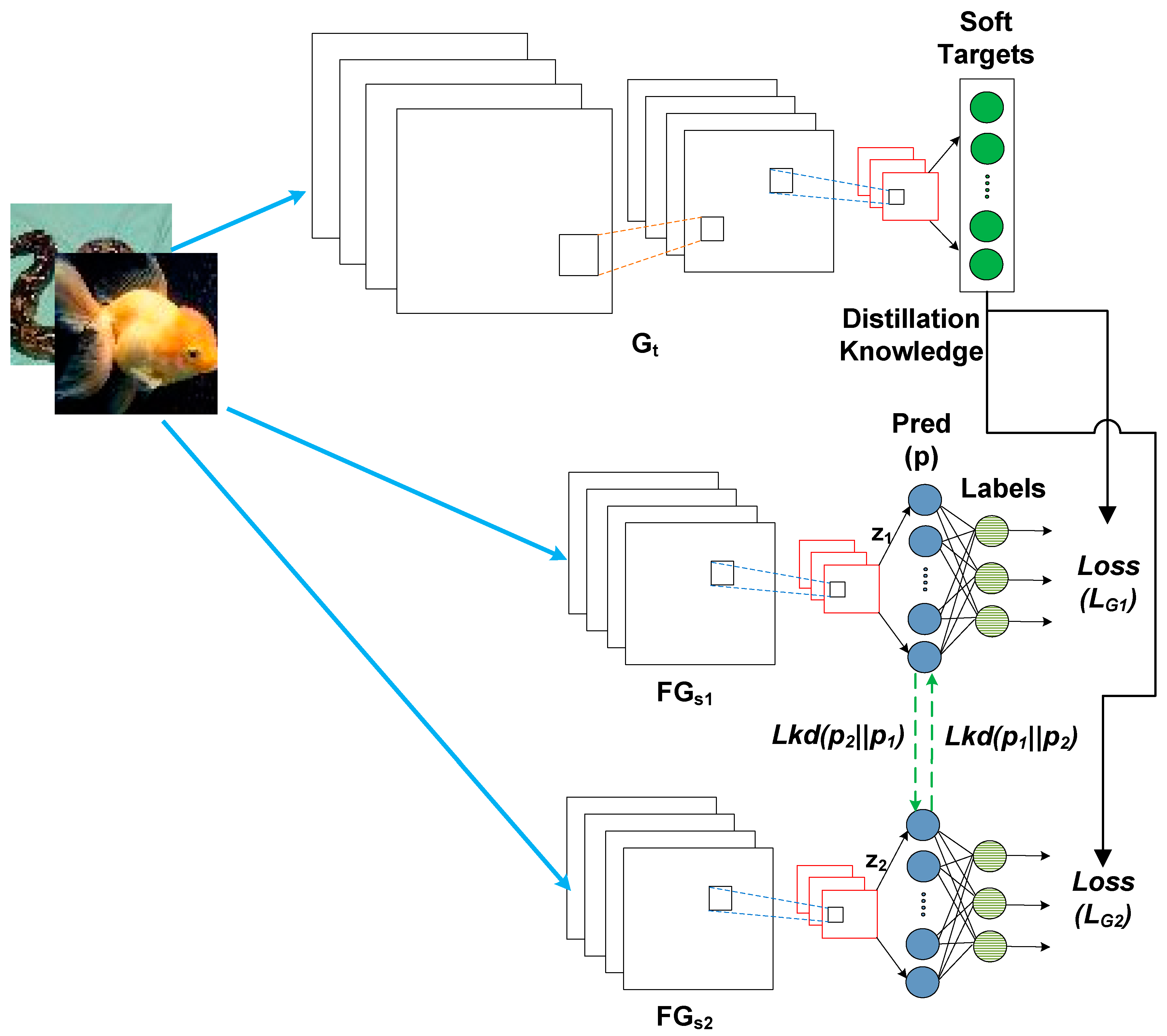
2.1. DML and KD
2.2. Full Deep Distillation Mutual Learning
2.3. Half Deep Distillation Mutual Learning
3. Results and Discussion
3.1. Dataset
3.2. Network Architectures
3.2.1. On CIFAR-100 Training and Testing
3.2.2. On TinyImageNet 64 × 64 Image Size Training and Testing
3.2.3. On TinyImageNet 32 × 32 DownsampledImage Size Training and Testing
3.2.4. On Cinic-10 32 × 32 image Size Training and Testing
3.3. Implementation Details
3.4. Experiment on CIFAR-100
3.5. Experiment on TinyImageNet
3.6. Experiment on Cinic-10
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- LeCun, Y.; Jackel, L.D.; Bottou, L.; Cortes, C.; Denker, J.S.; Drucker, H.; Guyon, I.; Muller, U.A.; Sackinger, E.; Simard, P.; et al. Learning algorithms for classification: A comparison on handwritten digit recognition. Neural Netw. Stat. Mech. Perspect. 1995, 261, 2. [Google Scholar]
- Wu, M.; Chen, L. Image recognition based on deep learning. In Proceedings of the 2015 Chinese Automation Congress (CAC), Wuhan, China, 27–29 November 2015; pp. 542–546. [Google Scholar]
- Kaur, P.; Harnal, S.; Tiwari, R.; Alharithi, F.S.; Almulihi, A.H.; Noya, I.D.; Goyal, N. A hybrid convolutional neural network model for diagnosis of COVID-19 using chest x-ray images. Int. J. Environ. Res. Public Health 2021, 18, 12191. [Google Scholar] [CrossRef] [PubMed]
- Lilhore, U.K.; Imoize, A.L.; Lee, C.C.; Simaiya, S.; Pani, S.K.; Goyal, N.; Kumar, A.; Li, C.T. Enhanced Convolutional Neural Network Model for Cassava Leaf Disease Identification and Classification. Mathematics 2022, 10, 580. [Google Scholar] [CrossRef]
- Singh, T.P.; Gupta, S.; Garg, M.; Gupta, D.; Alharbi, A.; Alyami, H.; Anand, D.; Ortega-Mansilla, A.; Goyal, N. Visualization of Customized Convolutional Neural Network for Natural Language Recognition. Sensors 2022, 22, 2881. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:150302531. [Google Scholar]
- Ba, L.J.; Caruana, R. Do deep nets really need to be deep? arXiv 2013, arXiv:13126184. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive representation distillation. arXiv 2019, arXiv:191010699. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:160507146. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 1365–1374. [Google Scholar]
- Peng, B.; Jin, X.; Liu, J.; Li, D.; Wu, Y.; Liu, Y.; Zhou, S.; Zhang, Z. Correlation congruence for knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5007–5016. [Google Scholar]
- Gao, Y.; Parcollet, T.; Lane, N.D. Distilling Knowledge from Ensembles of Acoustic Models for Joint CTC-Attention End-to-End Speech Recognition. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 138–145. [Google Scholar]
- Yao, A.; Sun, D. Knowledge transfer via dense cross-layer mutual-distillation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 294–311. [Google Scholar]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Zhao, H.; Yang, G.; Wang, D.; Lu, H. Deep mutual learning for visual object tracking. Pattern Recognit. 2021, 112, 107796. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:161203928. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Tech Report. 2009. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf (accessed on 23 July 2022).
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231N 2015, 7, 3. [Google Scholar]
- Darlow, L.N.; Crowley, E.J.; Antoniou, A.; Storkey, A.J. Cinic-10 is not imagenet or cifar-10. arXiv 2018, arXiv:181003505. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEEConference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June2009; pp. 248–255. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:14091556. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS Workshop 2017, Long Beach, CA, USA, 9 December 2017; Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 23 July 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref No. | Dataset Name | Number of Images Used | Method | GPU’s |
|---|---|---|---|---|
| [8] | MNIST, JFT, | 60,000, 100 million labeled images, | KD | No Information |
| [9] | TIMIT phoneme recognition, CIFAR-10 | 6300 sentences(5.4 h) 60 K images | Model Compression | Nvidia GTX 580 GPUs |
| [10] | CIFAR-100, ImageNet, STL-10, TinyImageNet | 60 K images, 1.2 million images from 1 K classes for training and 50 K for validation, Training set of 5 K labeled images from 10 classes and 100 K unlabeled images and a test set 8 K images, 120 K images | Contrastive Representation Distillation | Two Titan-V GPUs |
| [17] | CUB-200-2011, Cars 196 | 200 images, 196 images | Relational Knowledge distillation | |
| [14] | CIFAR-100, ImageNet | 60 K images, 1.2 million images from 1 K classes for training and 50 K for validation | Correlation Congruence for Knowledge Distillation | 16 TiTAN X |
| [13] | CINIC-10, CIFAR-10 | 270 K images, 60 K images | Similarity-Preserving Knowledge Distillation | No information |
| [16] | CIFAR-100, ImageNet | 60 K images, 1.2 million images from 1 K classes for training and 50 K for validation | Knowledge Transfer via Dense Cross-Layer Mutual-Distillation | GPUs |
| [11] | CIFAR-100, Market-1501 | 60 K images, 1501 images | DML | Single NVIDIA GeForce 1080 GPU |
| Ours | CIFAR-100, TinyImageNet, Cinic-10 | 60 K images, 120 K images 270 K images | FDDML HDDML | Single NVIDIA GeForce 1080 GPU |
| Network Architecture | ||||||||
|---|---|---|---|---|---|---|---|---|
| Teacher | Resnet32 | Resnet56 | Resnet110 | Resnet110 | WRN-40-2 | Resnet32x4 | WRN-40-2 | Resnet56 |
| Student 1 | Resnet20 | Resnet20 | Resnet56 | Resnet20 | MobileNetv2 | Resnet8x4 | WRN-16-2 | Resnet44 |
| Student 2 | Resnet20 | Resnet20 | Resnet56 | Resnet20 | MobileNetv2 | Resnet8x4 | WRN-16-2 | Resnet44 |
| Test Accuracy (%) | ||||||||
| Teacher | 70.12 | 72.04 | 73.79 | 73.79 | 75.3 | 76.95 | 75.3 | 72.04 |
| Student 1 | 69.05 | 69.05 | 72.04 | 69.05 | 64.55 | 71.14 | 73.15 | 71.54 |
| Student 2 | 69.05 | 69.05 | 72.04 | 69.05 | 64.55 | 71.14 | 73.15 | 71.54 |
| KD [8] | 70.5 | 70.33 | 74.41 | 70.88 | 68.51 | 75.24 | 74.76 | 73.87 |
| AT [19] | 69.42 | 70.91 | 74.54 | 69.95 | 59.27 | 72.46 | 73.02 | 71.46 |
| SP [13] | 70.16 | 69.71 | 73.83 | 69.65 | 64.82 | 73.12 | 73.74 | 73.54 |
| CC [14] | 68.78 | 68.45 | 71.89 | 69.06 | 65.91 | 72.4 | 72.97 | 72.06 |
| CRD [10] | 70.95 | 70.63 | 75.1 | 70.86 | 69.62 | 75.14 | 75.42 | 74.36 |
| CRD+KD [10] | 71.16 | 71 | 74.99 | 70.92 | 69.78 | 75.53 | 75.54 | 74.43 |
| DML: [22] | ||||||||
| Student 1 | 69.98 | 69.98 | 73.39 | 69.98 | 67.31 | 71.58 | 73.74 | 72.14 |
| Student 2 | 69.71 | 69.71 | 73.26 | 69.71 | 66.88 | 71.72 | 73.96 | 72.8 |
| FDDML: | ||||||||
| Student 1 | 70.6 | 70.9 | 75 | 71.04 | 70.63 | 75.27 | 75.21 | 74.31 |
| Student 2 | 71.17 | 71.16 | 74.9 | 70.85 | 69.88 | 74.99 | 75.75 | 74.49 |
| HDDML: | ||||||||
| Student 1 | 70.71 | 70.87 | 73.7 | 69.98 | 68.75 | 73.81 | 74.56 | 74.31 |
| Student 2 | 70.18 | 68.46 | 75.11 | 70.79 | 70.14 | 74.52 | 75.43 | 72.88 |
| Network Architecture | |||||||
|---|---|---|---|---|---|---|---|
| Teacher | WRN-40-2 | WRN-40-2 | WRN-40-2 | WRN-40-2 | Resnet110 | Resnet56 | Vgg13 |
| Student 1 | ShuffleV2 | WRN-28-2 | MobileNetv2 | Resnet32x4 | Resnet56 | Vgg8 | ShuffleV2 |
| Student 2 | Resnet32 | Resnet32 | Resnet32 | MobileNetv2 | WRN-16-2 | Resnet32 | MobileNetv2 |
| Test Accuracy (%) | |||||||
| Teacher | 75.3 | 75.3 | 75.3 | 75.3 | 73.79 | 72.04 | 74.94 |
| Student 1 | 71.88 | 73.89 | 64.55 | 71.14 | 72.04 | 69.83 | 71.88 |
| Student 2 | 70.12 | 70.12 | 70.12 | 64.55 | 73.15 | 70.12 | 64.55 |
| DML: [11] | |||||||
| Student 1 | 76.71 | 75.58 | 69.13 | 77.8 | 74.03 | 72.73 | 73.81 |
| Student 2 | 72.34 | 72.72 | 71.84 | 68.2 | 74.14 | 72.37 | 67.72 |
| FDDML: | |||||||
| Student 1 | 77.31 | 77.04 | 69.93 | 78.68 | 74.55 | 73.61 | 75.71 |
| Student 2 | 73.23 | 73.52 | 73 | 70.5 | 74.91 | 73.04 | 69.82 |
| HDDML: | |||||||
| Student 1 | 76.29 | 75.83 | 69.55 | 77.6 | 74.03 | 72.3 | 74.24 |
| Student 2 | 74.23 | 73.32 | 73.85 | 70 | 74.95 | 73.58 | 69.54 |
| Network Architecture | ||||||
|---|---|---|---|---|---|---|
| Teacher | Resnet50 | Resnet50 | Resnet50 | Vgg13 | Vgg16 | Vgg16 |
| Student 1 | Resnet34 | Resnet18 | Vgg16 | Vgg8 | Vgg13 | Vgg8 |
| Student 2 | Resnet34 | Resnet18 | Vgg16 | Vgg8 | Vgg13 | Vgg8 |
| Test Accuracy (%) | ||||||
| Teacher | 55.34 | 55.34 | 55.34 | 48.1 | 49.2 | 49.2 |
| Student 1 | 37.94 | 36.04 | 49.2 | 41.68 | 48.1 | 41.68 |
| Student 2 | 37.94 | 36.04 | 49.2 | 41.68 | 48.1 | 41.68 |
| KD [8] | 55.26 | 55.72 | 53.92 | 44.42 | 52.4 | 44.68 |
| AT [19] | 50.13 | 50.22 | 45.68 | 44.84 | 48.92 | 43.18 |
| SP [13] | 55.38 | 55.68 | 54.28 | 45.06 | 51.88 | 44.66 |
| CC [14] | 50.9 | 49.82 | 48.72 | 42.1 | 48.08 | 41.68 |
| CRD [10] | 57.48 | 55.92 | 55.82 | 45.12 | 51.1 | 45.38 |
| CRD+KD [10] | 57.14 | 56.94 | 55.74 | 46.08 | 51.98 | 46.88 |
| DML: [11] | ||||||
| Student 1 | 55.1 | 54.86 | 53.88 | 44.94 | 52.84 | 44.94 |
| Student 2 | 55.13 | 54.92 | 53.26 | 45.16 | 53.76 | 45.16 |
| FDDML: | ||||||
| Student 1 | 57.33 | 56.58 | 56.12 | 45.02 | 53.22 | 46.3 |
| Student 2 | 57.98 | 55.88 | 56.54 | 44.52 | 53.1 | 44.36 |
| HDDML: | ||||||
| Student 1 | 57.05 | 55.1 | 53,66 | 46.06 | 52.32 | 46.26 |
| Student 2 | 58.27 | 57.48 | 56.68 | 46.26 | 54.24 | 45.74 |
| Network Architecture | ||||||
|---|---|---|---|---|---|---|
| Teacher | WRN-40-2 | Resnet50 | Resnet34 | WRN-40-2 | Resnet50 | Resnet50 |
| Student 1 | Resnet34 | Resnet18 | Resnet18 | WRN-16-2 | Resnet34 | Resnet8x4 |
| Student 2 | Resnet34 | Resnet18 | Resnet18 | WRN-16-2 | Resnet34 | Resnet8x4 |
| Test Accuracy (%) | ||||||
| Teacher | 31.06 | 33.26 | 29.96 | 31.06 | 33.26 | 33.26 |
| Student 1 | 29.96 | 29.68 | 29.68 | 28.32 | 29.96 | 29.42 |
| Student 2 | 29.96 | 29.68 | 29.68 | 28.32 | 29.96 | 29.42 |
| DML: [11] | ||||||
| Student 1 | 30.92 | 32.06 | 32.06 | 28.8 | 30.92 | 30.12 |
| Student 2 | 32.86 | 30.94 | 30.94 | 29.22 | 32.86 | 29.46 |
| FDDML: | ||||||
| Student 1 | 33.56 | 33.77 | 32.44 | 29.54 | 33.18 | 30.06 |
| Student 2 | 32.62 | 33.66 | 31.94 | 30.06 | 32.76 | 29.9 |
| HDDML: | ||||||
| Student 1 | 32.3 | 31.52 | 31.78 | 30.8 | 31.52 | 29.7 |
| Student 2 | 33.02 | 33.5 | 32.64 | 29.54 | 32.68 | 31.18 |
| Temperature (T) | Network Architecture | KD | CRD | CRD+KD | FDDML | HDDML | Teacher | Student |
|---|---|---|---|---|---|---|---|---|
| Batch size 64 | ||||||||
| Resnet50 (T) | ||||||||
| 4 | WRN-16-2 (S) | 14.58 | 27.78 | 25.06 | 24.06 | 27.04 | ||
| WRN-16-2 (S) | 24.92 | 24.94 | ||||||
| Resnet50 (T) | 55.34 | 28.32 | ||||||
| 5 | WRN-16-2 (S) | 14.52 | 27.16 | 25.56 | 24.08 | 28.2 | ||
| WRN-16-2 (S) | 24.96 | 25.82 | ||||||
| Resnet50 (T) | ||||||||
| 6 | WRN-16-2 (S) | 15.22 | 27.74 | 25.52 | 25.34 | 28.12 | ||
| WRN-16-2 (S) | 24.84 | 26.62 | ||||||
| Batch size 128 | ||||||||
| Resnet50 (T) | ||||||||
| 4 | WRN-16-2 (S) | 14.18 | 26.92 | 25.52 | 23.6 | 23.22 | ||
| WRN-16-2 (S) | 24.28 | 23.94 | ||||||
| Resnet50 (T) | ||||||||
| 5 | WRN-16-2 (S) | 14.6 | 27.48 | 25.34 | 24.04 | 28.36 | 55.34 | 28.32 |
| WRN-16-2 (S) | 25.14 | 25.16 | ||||||
| Resnet50 (T) | ||||||||
| 6 | WRN-16-2 (S) | 14.56 | 26.32 | 24.42 | 23.22 | 26.76 | ||
| WRN-16-2 (S) | 24.62 | 25 | ||||||
| Batch size 180 | ||||||||
| Resnet50 (T) | ||||||||
| 4 | WRN-16-2 (S) | 13.82 | 27.2 | 24.52 | 22.58 | 26.46 | ||
| WRN-16-2 (S) | 24.04 | 24.16 | ||||||
| Resnet50 (T) | ||||||||
| 5 | WRN-16-2 (S) | 13.9 | 27.22 | 25.52 | 24.34 | 27.46 | 55.34 | 28.32 |
| WRN-16-2 (S) | 23.96 | 23.86 | ||||||
| Resnet50 (T) | ||||||||
| 6 | WRN-16-2 (S) | 13.78 | 26.08 | 24.68 | 23.94 | 27.48 | ||
| WRN-16-2 (S) | 24.58 | 25.62 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lukman, A.; Yang, C.-K. Improving Deep Mutual Learning via Knowledge Distillation. Appl. Sci. 2022, 12, 7916. https://doi.org/10.3390/app12157916
Lukman A, Yang C-K. Improving Deep Mutual Learning via Knowledge Distillation. Applied Sciences. 2022; 12(15):7916. https://doi.org/10.3390/app12157916
Chicago/Turabian StyleLukman, Achmad, and Chuan-Kai Yang. 2022. "Improving Deep Mutual Learning via Knowledge Distillation" Applied Sciences 12, no. 15: 7916. https://doi.org/10.3390/app12157916
APA StyleLukman, A., & Yang, C.-K. (2022). Improving Deep Mutual Learning via Knowledge Distillation. Applied Sciences, 12(15), 7916. https://doi.org/10.3390/app12157916