1. Introduction
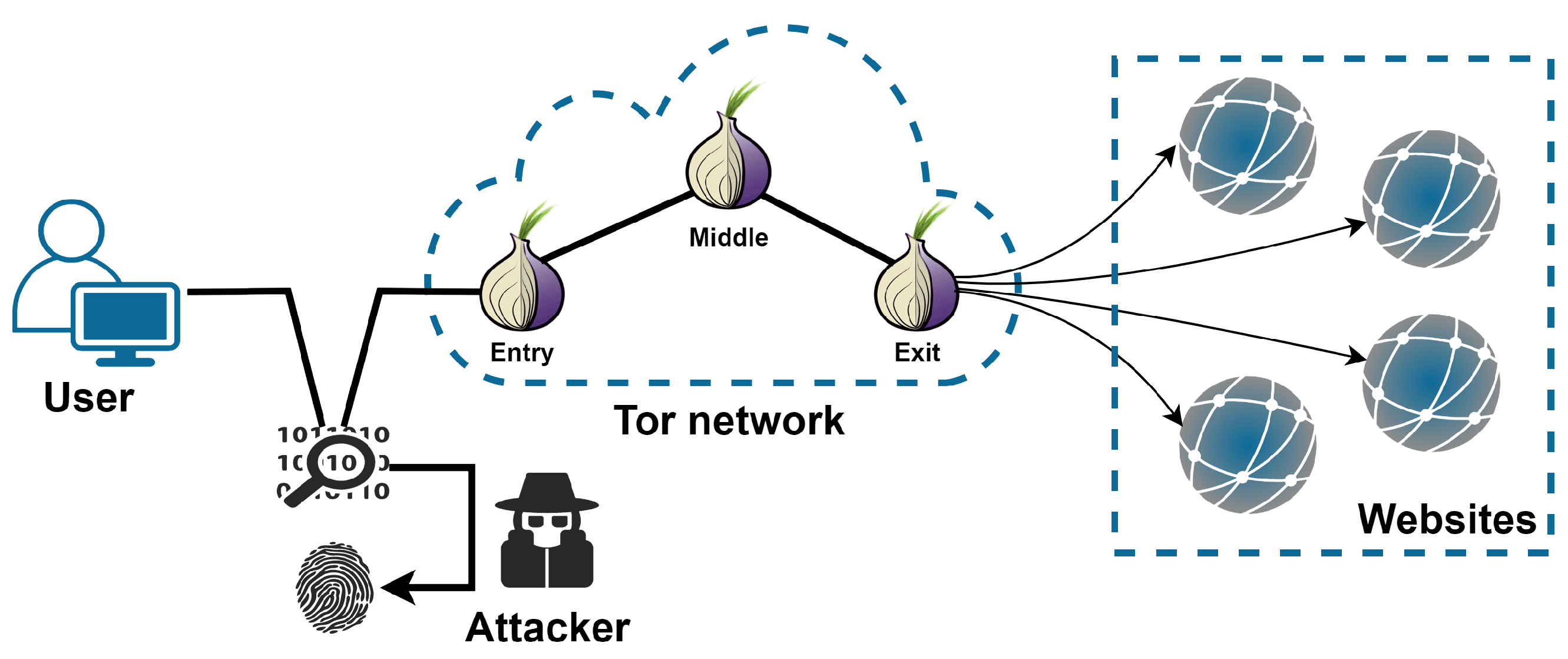
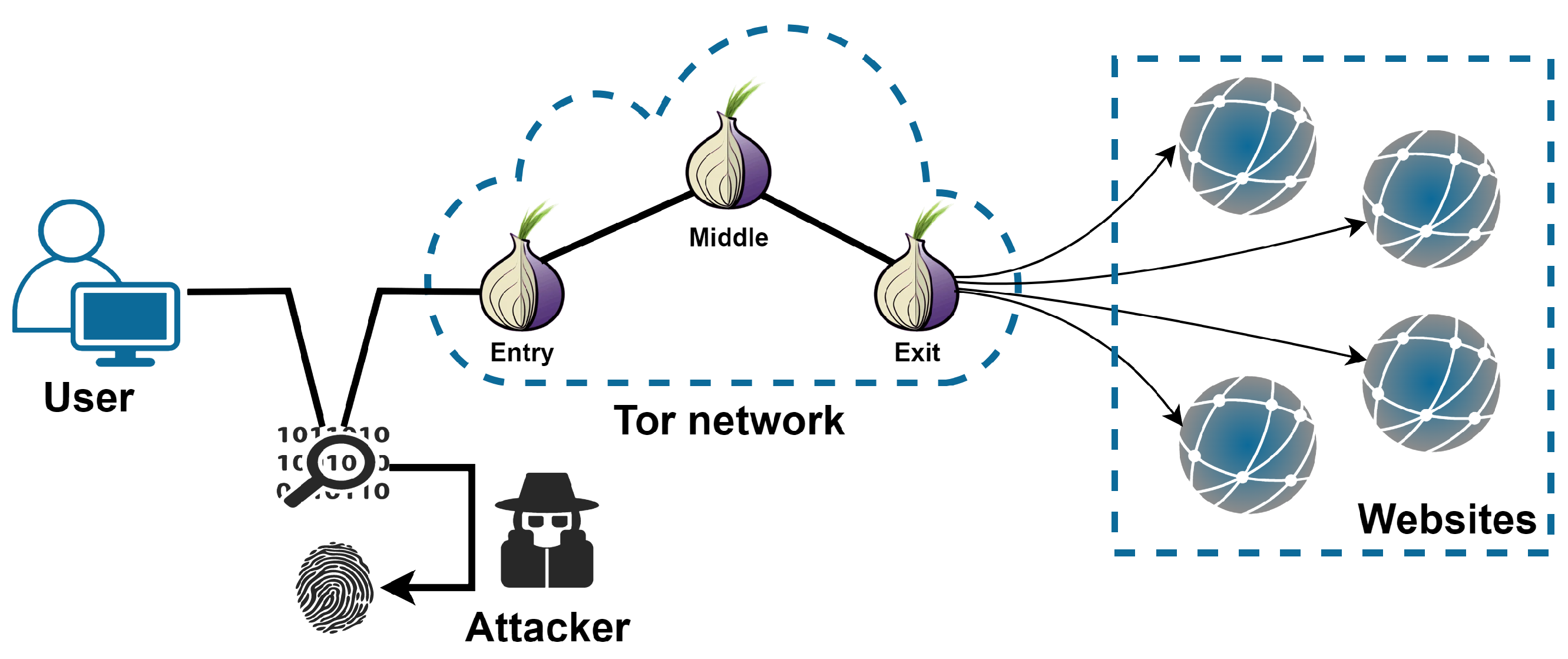
Tor has been proven better at protecting users’ privacy than other anonymous communication tools. It establishes a random multi-hop communication circuit through relays provided by global volunteers. The user’s browsing data is encrypted and contained in multiple layers in the process of transmitting, similar to an onion wrapped in layers. Random multi-hop communication circuits bring significant challenges to large-scale supervision. Onion encryption effectively prevents the attacker from analyzing the communication content to hide the user’s identity and location, as well as the target website visited by the user. Nevertheless, website fingerprinting (WF) attacks have proven that there are characteristics explicitly or implicitly hidden in traffic patterns. The attacker can de-anonymize the target website a user is browsing by well-trained classifiers.
Early on, some WF attacks were based on machine learning, such as SVM [
1,
2], k-NN [
3], and random forest [
4]. They used handcrafted features to describe the difference between the traffic trace of different websites and achieved more than 90% accuracy in the closed-world setting. Manually designed features have been criticized for being vulnerable to protocol changes [
5,
6,
7,
8], while deep learning can make up for this deficiency through automated feature engineering. Moreover, existing works show that features extracted by unsupervised DNNs are more effective [
9]. Deep-learning-based WF attacks, such as Var-CNN [
10], show great advantages with accuracy and a true positive rate of over 98% in both closed-world and open-world settings.
Although deep learning methods demonstrate promising results, they often require massive data in the training phase. It would be costly for the attacker to collect sufficient traffic instances for each website. Moreover, the content of a website may change irregularly all the time causing the data distribution shift. The adversary must collect training data frequently and retrain new models to catch up with the variation. It is an unaffordable expense, especially when running into a large set of monitored websites. As a result, the data hunger problem severely restricts the application of WF attacks. To tackle this problem, many studies [
11,
12,
13] were inspired by transfer learning, introducing pre-trained feature extractors in their attack process. The issue is that these attacks need a large amount of additional pre-training data. What is more, the effectiveness of the extractor will be lost when faced with target data with a different distribution than the pre-training data. Others [
14] have tried to use data augmentation methods borrowed from the computer vision field to offer extra training data. However, website traffic and pictures are of a completely different nature. For example, the mixup can perturb the color and shading of a picture without changing the semantics. The same perturbation does not work for traffic traces which only contain the direction and timestamps of cells.
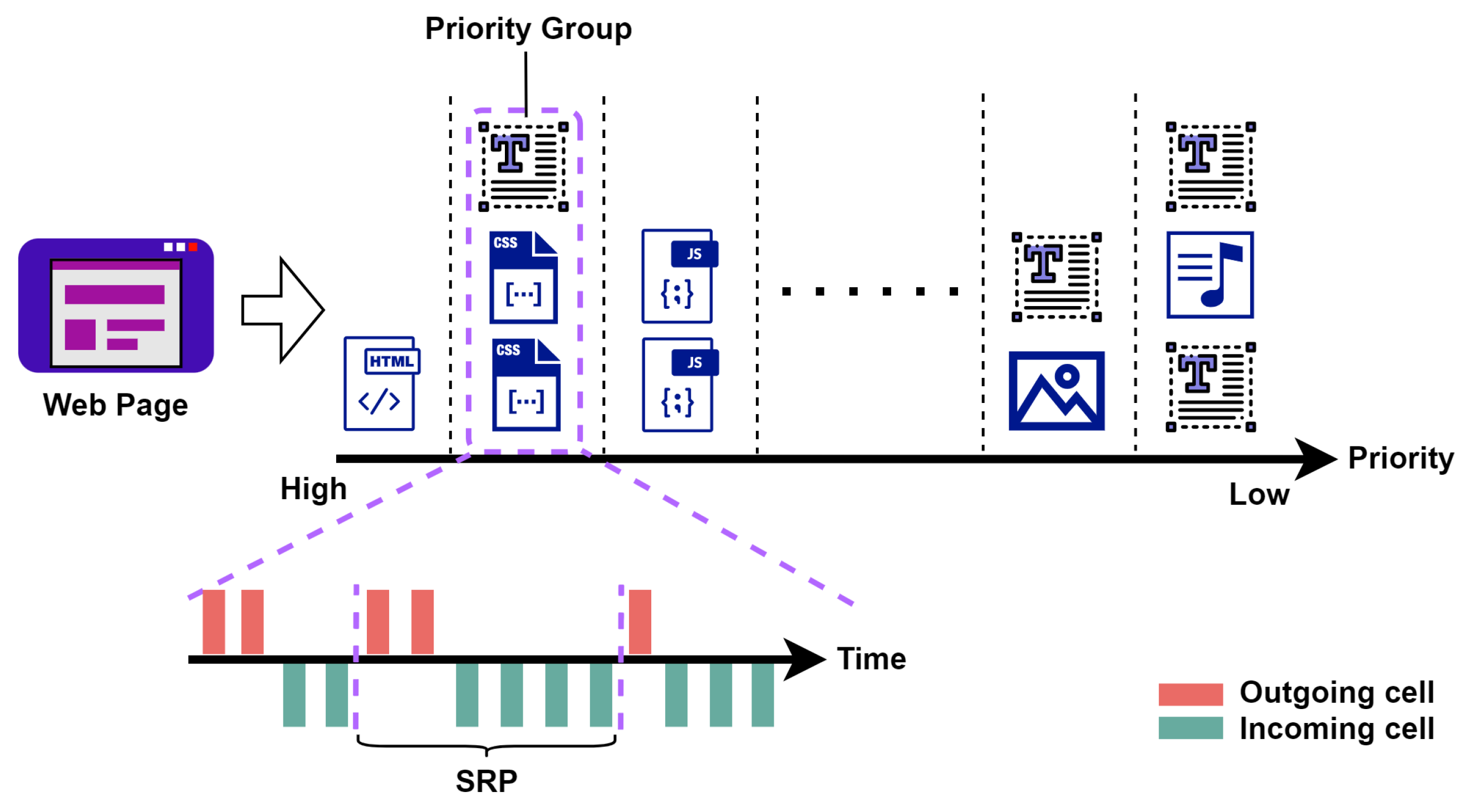
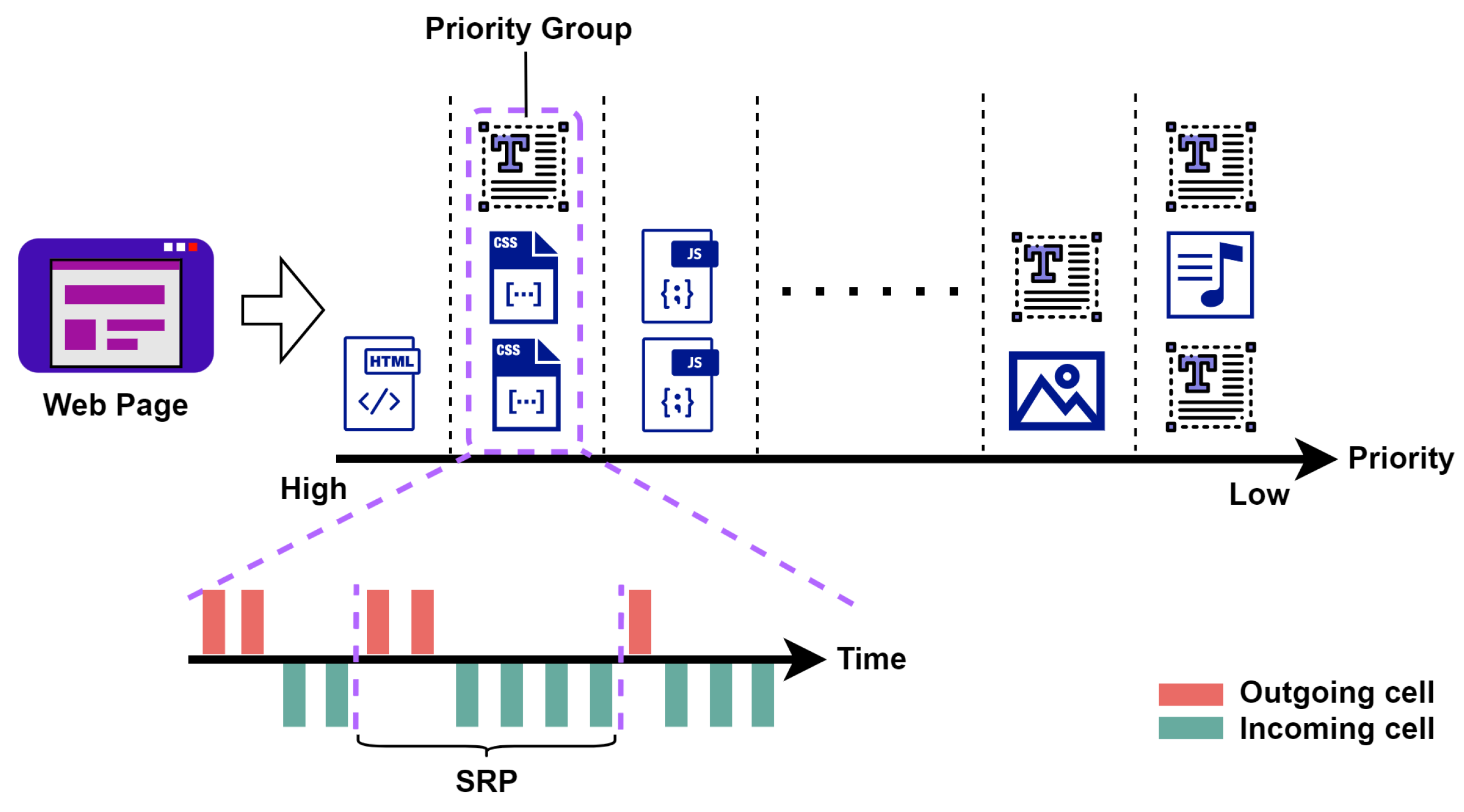
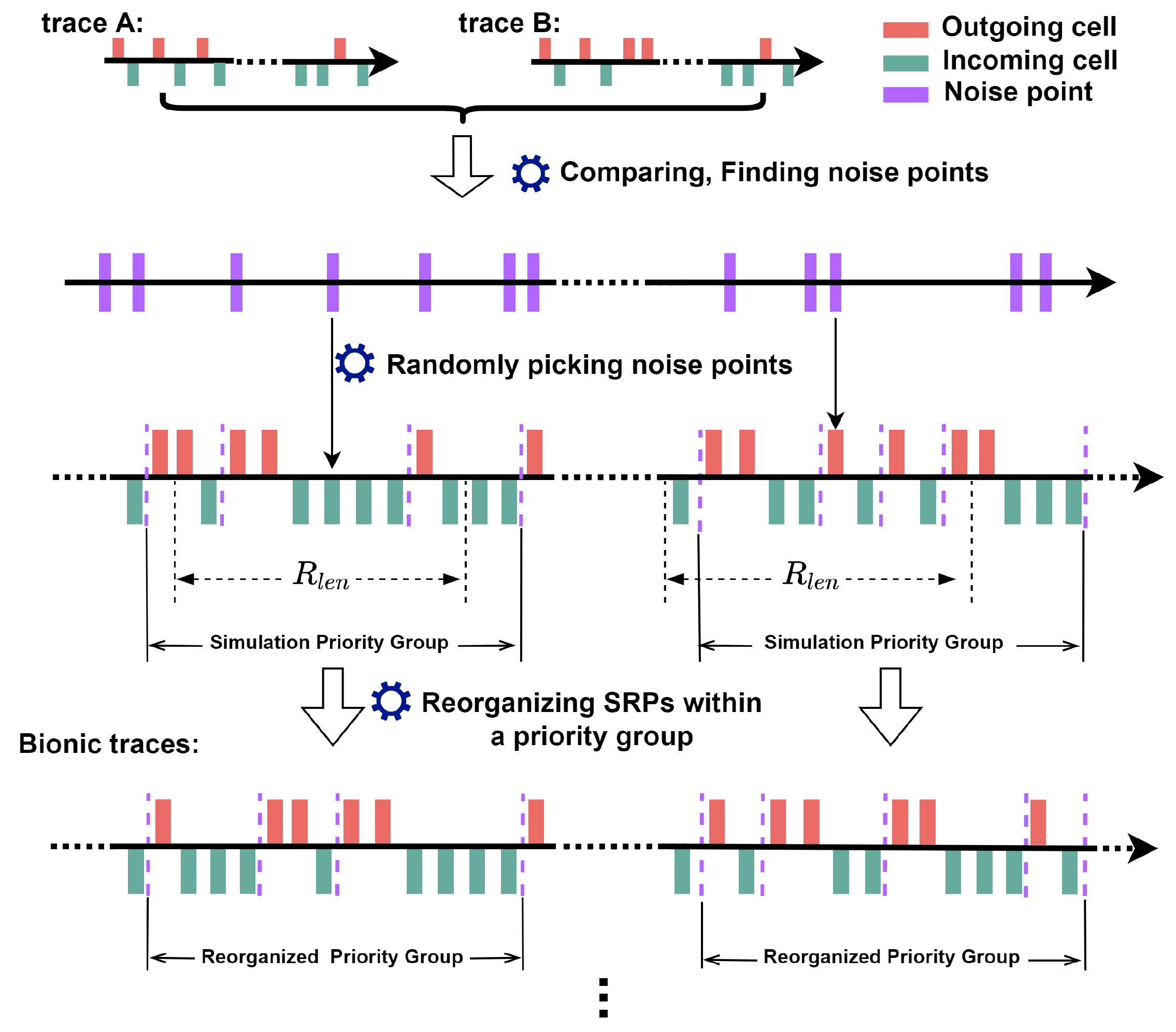
In this study, we reviewed the loading process of web pages and proposed the send-and-receive pair (SRP) as the basic unit to characterize website traffic. We observed that traffic traces could be bionic, quite different from entities with unique semantics and strict spatial structure, e.g., people’s faces. The bionic traces generated by our proposed method can be used as a supplementary training dataset of WF attacks and further enhance their capability.
The main contributions of this paper are listed as follows:
We proposed a new concept called send-and-receive pair (SRP), which provides a microscopic perspective for us to study website traffic.
We demonstrated that website traffic could be bionic by reorganizing SRPs generated by web page loading. Furthermore, we proposed a bionic trace generation method based on the browser working mechanism and network state fluctuation simulation.
We further investigate the concept drift problem of website traffic in closed-world and open-world scenarios. We reveal that bionic traces and SRP-based cumulative features can help mitigate the effects of concept drift.
Expensive experiments show that bionic traces we generated can significantly alleviate the data hunger problem of deep learning-based WF attacks. It can achieve a nontrivial increase in performance when incorporating the state-of-the-art deep learning model.
The remainder of this paper is organized as follows. We first describe the threat model of the WF section in
Section 2. In
Section 3, we give a review of related work. We introduce the proposed SRP and bionic trace generation method in detail in
Section 4.
Section 5 describes our performance metrics and analyzes experimental results. Finally, we discuss the limitation of this study and draw a conclusion in
Section 6.
3. Related Work
The history of WF attacks can be traced back to decades ago when Wagner et al. [
15], the pioneer of website fingerprint research, first studied the traffic encrypted by SSL. After that, reaserchers have studied the WF attack against different communication protocols and proxy tools [
16,
17,
18,
19,
20]. As WF attacks increasingly threaten user privacy, high expectations are placed on anonymous communication tools like Tor. Once the data leaves the user’s Tor client, it would be encrypted to hide the content and destination. This mechanism ensures that communication information is not leaked. As a contradictory pair, attack and defense have continuously been developed in confrontation.
Handcrafted features can represent traffic traces with meaningful statistics and traditional machine learning can work as classifiers to identify the monitored website. Some previous WF attacks focus on manually designing features through prior knowledge, e.g., brust [
1], the sequence of packets, size of packets, and inter-packet timings. Herrmann et al. [
21] first attempted to destroy Tor’s anonymity with the distribution of IP packet sizes but only achieved
accuracy. After that, the attack effect gradually improved [
1,
2,
3,
4] with the progress of machine learning. Hayes and Danezis [
4] proposed k-fingerprinting based on random decision forests, which can correctly determine one of 30 monitored hidden services a client is visiting with
TPR, an FPR as low as
. Moreover, their results show that simple features such as counting the number of packets in a sequence leak more information about a web page’s identity than complex features such as packet ordering or packet inter-arrival time features. Panchenko et al. [
22] extract cumulative behavioral representations of the page loading process along with other handcrafted features, e.g., packer ordering and burst behavior. Their CUMUL can attack with excellent computational efficiency, achieving
TPR in a sizeable open-world scenario. Nevertheless, attacks based on manually designed features have their performance limited by the quality of the feature set. For instance, simple WF defenses can easily perturb statistics between packets [
4].
Recently, deep-learning-based WF attacks have gradually become the mainstream. They can automate the process of feature engineering [
23,
24] and extract implicit features by designing networks with more complex structures. Oh et al. [
9] broadly study the applicability of deep learning to website fingerprinting. Their work proved that features extracted by unsupervised DNNs are more potent than the manual design features. Rimmer et al. [
5] systematically explored three deep learning algorithms applied to WF, including stacked denoising autoencoder (SDAE), convolutional neural network (CNN), and long short-term memory (LSTM). Their work shows that deep learning methods are more effective when provided with more training data. Later, Bhat et al. [
10] announced that Var-CNN was effective in a low data setting with 50 instances per class available.
Considering a more practical setting, websites on the Internet are far beyond an attacker’s monitoring capability, which means the attacker would not be able to have enough training instances for all monitored websites. Therefore, the WF attacks are closer to a few-shot problem in the real world. In this case, DF [
24] and Var-CNN both become weak in the few-shot setting, at the risk of overfitting the training data. Sirinam et al. [
11] decompose the attack model into two parts: a k-NN classifier and a triplet-network-based feature extractor. Their TF outperforms other attacks in the few-shot setting with more than 90% accuracy. However, WF attacks [
11,
12,
13] based on transfer learning are highly dependent on a large amount of pre-training data. Moreover, it is hard for these attacks to counteract the distribution changes of target data. As a typical data augmentation method, HDA [
14] shows that virtual instances can help with the data hunger problem. Since HDA is not designed for the characteristics of website traffic, its enhancement effect is limited.
Another unavoidable question is whether the WF attacks are time sensitive for the reason web pages are constantly changing irregularly [
25], namely the concept drift problem. A several minutes time gap would lead to the content of a news website to be update [
26]. With only a 10 days time gap, the accuracy of WF attacks dropped by approximately
. Rimmer et al. [
5] held that the classifier trained and evaluated at one moment in time might overlook the stable fingerprint and learn the temporary features instead. On the other hand, depending on the number of monitored websites an attacker aims to cover, the cost to catch up with the changes brought by time would be a significant burden. Guiding deep learning-based classifiers to learn deep abstract features will help combat concept drift in website fingerprinting.
5. Experiment
In this section, we design a series of experiments to prove that bionic traffic traces can be used to expand the training dataset as compensation for the data shortage of the WF problem. We simulate a tough, low data situation, where the attacker could only gather instances for each monitored website. Note that, for investigating the effectiveness of the proposed SRP-based cumulative feature, we report the results of the attack with or without using it (BionicT* represents the use of SRP-based cumulative feature while BionicT does not).
5.1. Dataset
We perform our experiment based on datasets used in the previous literature. These datasets are labeled as follows:
[
5]: This dataset is the largest WF dataset collected in 2017 with Tor browser 6.5, We use three subsets in our study:
- -
. The set consists of the top 100 Alexa websites, with 2500 instances each.
- -
. The set consists of the other 775 websites, with 2500 traffic traces each.
- -
. The set consists of the top 400,000 Alexa websites, with one instance each.
- -
. The set consists of the top 200 Alexa websites, with 500 traffic traces each. 100 instances of these 200 sites were gathered at each point in time over a two-month period: 3 days, 10 days, 28 days, 42 days, and 56 days after the end of the initial data collection.
[
3]: This dataset was collected by using Tor Browser 3.5.1 in 2013, which contains 100 monitored websites. Each website has 90 instances available.
[
24]. This dataset contains 95 monitored websites each with 1000 instances defended by WTF-PAD [
7].
5.2. Metric
In order to reasonably evaluate our work, we use different metrics for the closed-world and open-world settings separately. We first define
P as the total number of monitored traces. True positive (
) represents a monitored trace classified as its category. Wrong positive (
) indicates that it is classified as other monitored categories. Especially in the open-world scenario, a false negative (
) indicates that it is classified as the unmonitored category. If an unmonitored trace is considered a monitored category, it is a false positive (
). Therefore, we define accuracy for closed-world evaluation as:
The
-score used for open-world evaluation is defined as:
where:
We run each experiment 10 times and use the mean and standard deviation to report the performance. Moreover, we randomly sample instances for training and testing each time to ensure more reliable and representative results.
5.3. Hyperparameter Tuning
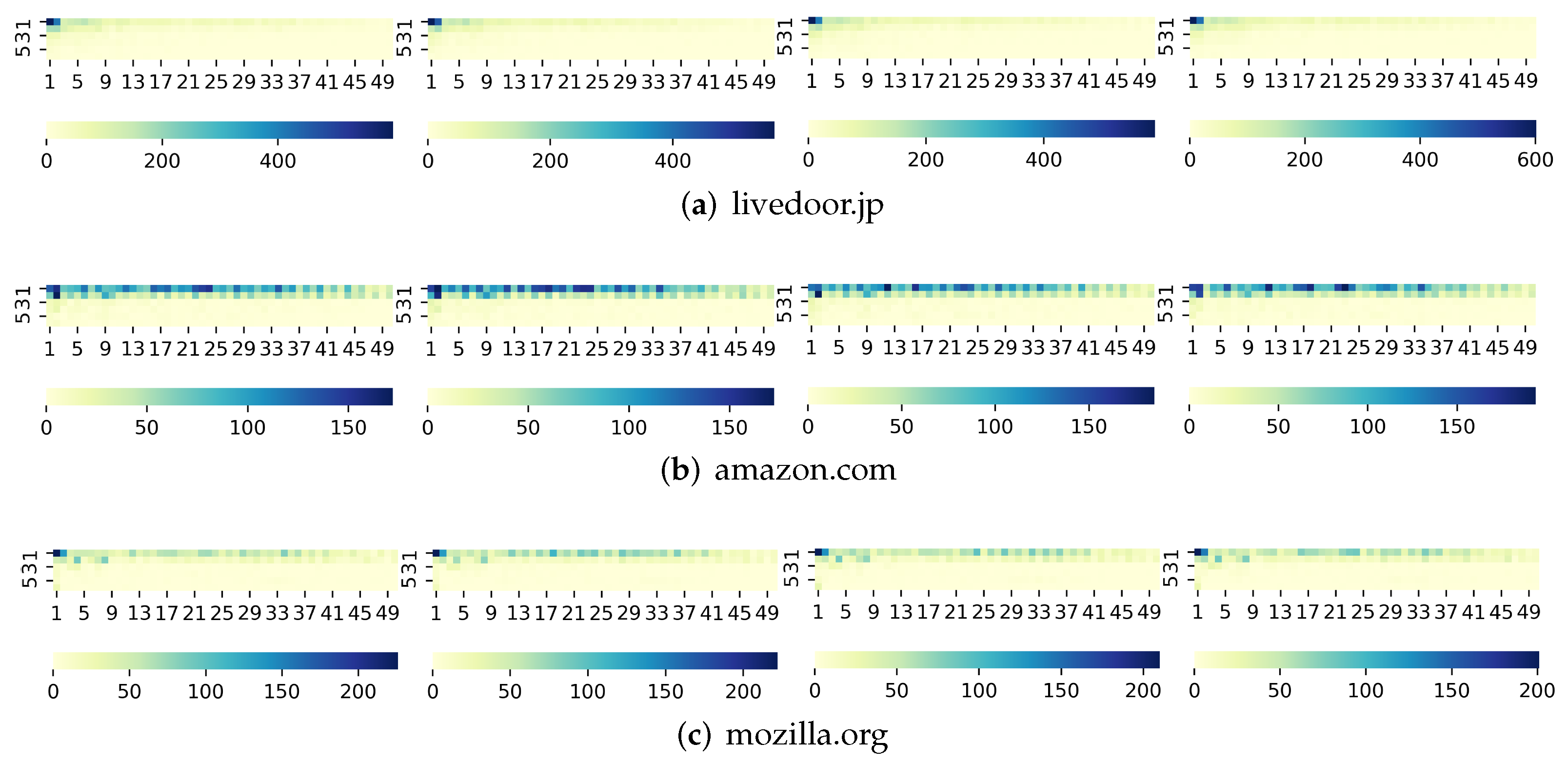
To develop the method of generating bionic traffic, we perform hyperparameter tuning for and , which have been used in Algorithm 2. The search space of ranges from 10% to 100%, with a step of 10%. The search space of is . We carried out the tuning process based on .
5.3.1. Experimental Setting
We use 100 random-sampled examples for each website from and divide them into three chunks with 20/10/70 examples, respectively. N training instances were collected from the first chunk to form the training datasets, and we generated 500 bionic traffic traces for each website based on the training dataset. Then, we join the bionic traces with original training samples to train the attack model. We train the model for 50 epochs and use the checkpoint to save the best performing one on the second chunk (validation dataset) and test on the third chunk (testing dataset). Note that, we apply these basic experimental settings for the rest of the experiments.
5.3.2. Results
Table 1 shows the effect of
to bionic traffic when
was fixed to 10, the accuracy peaks at
. It is reasonable since the traffic is disturbed for various reasons while shuffling the order of SRPs can only simulate the disturbance to the priority group. If this disturbance is applied to more noise points, it will destroy the basic traffic pattern. If it is applied to fewer noise points, the disturbance will be limited, and the influence of
will become greater. As shown in
Table 2,
is the most suitable value to help locate simulation priority group when
was fixed to
.
As the results, we use and to generate bionic traffic traces for the rest of the experiments.
5.4. Closed-World Evaluation
We investigate the effectiveness of the proposed bionic traffic generation method in the closed-world setting. The experiments are carried out based on datasets and , which have different data distributions.
5.4.1. Experimental Setting
We use 100 random-sampled examples for each website from and divide them into three chunks with 20/10/70 examples, respectively. Since only has 90 instances per website, the dataset could be split into three chunks with 20/10/60 instances each. N training instances were collected from the first chunk to form the n-shot training datasets. The second and third chunks serve as validation and testing datasets, respectively. We generated 1000 bionic traffic traces for each website.
5.4.2. Results
Table 3 shows the performance of WF attacks under
n-shot settings. Traditional WF attacks [
4,
22] based on manually designed features performed better than deep learning-based attacks DF [
29] and Var-CNN [
10], which severely reveal the data hunger problem. With data augmentation methods applied to traces, HDA [
14] can somewhat alleviate this problem. In contrast, our bionic traces show a significant advantage with 92.5% accuracy compared to 74.7% of HDA in the 10-shot setting. Moreover, our method performs better than TF [
11] in both 15/20-shot settings with more than 95% accuracy. Since TF uses the
[
5,
11] for pre-training, the data distribution shift occurs when testing on
. As shown in
Table 4, our advantage over TF expanded to the 10-shot setting in this case. Note that TF performs best in the five-shot setting because it learns extra knowledge from pre-training data. These two datasets were collected in different network environments with different browser versions, reflecting the feasibility and generality of the proposed SRP and bionic traces. By a fair comparison, the proposed SRP-based cumulative feature can enhance the performance of the attack further. The advantage is mainly shown when there are few origin samples, especially in the five-shot setting. This phenomenon can be reasonable since the manually designed features can help the model learn knowledge of traces lacking due to not having enough samples.
5.5. Open-World Evaluation
Next, we consider the more realistic open-world scenario to examine the practicality of the bionic trace generation method.
5.5.1. Experimental Setting
We include the unmonitored samples from with additional labels during the model training phase. We randomly pick 10,000 websites (each with one instance) from the dataset and split them into three disjoint chunks with 2000/1000/7000 instances, respectively. By doing this, we simulate the practical situation where the attack model must distinguish unmonitored websites that were never met in the training phase. To construct a balanced training dataset, we sample the same number of unmonitored samples from the first block as the monitored instances in the n-shot setting. We generate 1000 bionic traces for each monitored website.
5.5.2. Results
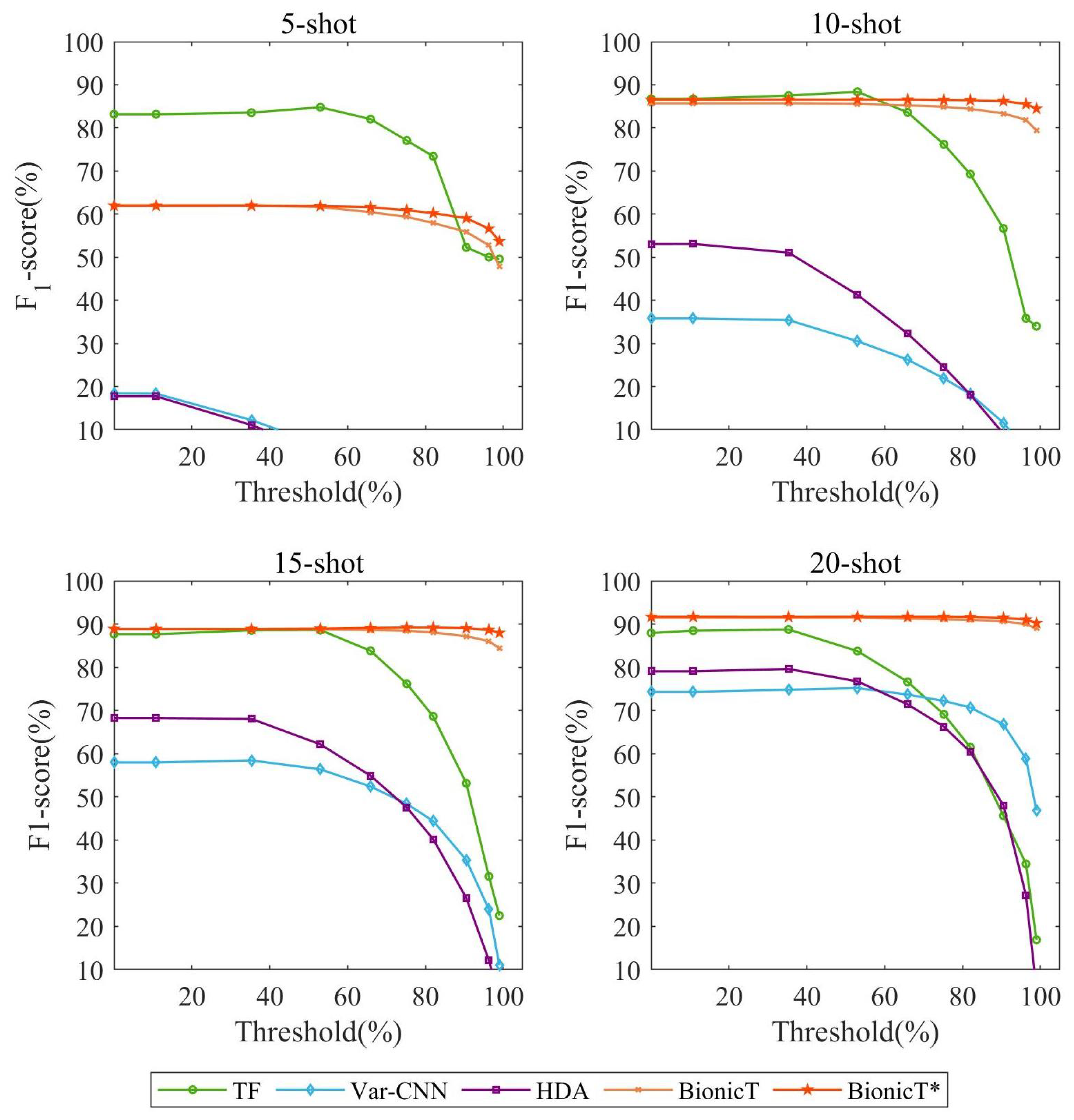
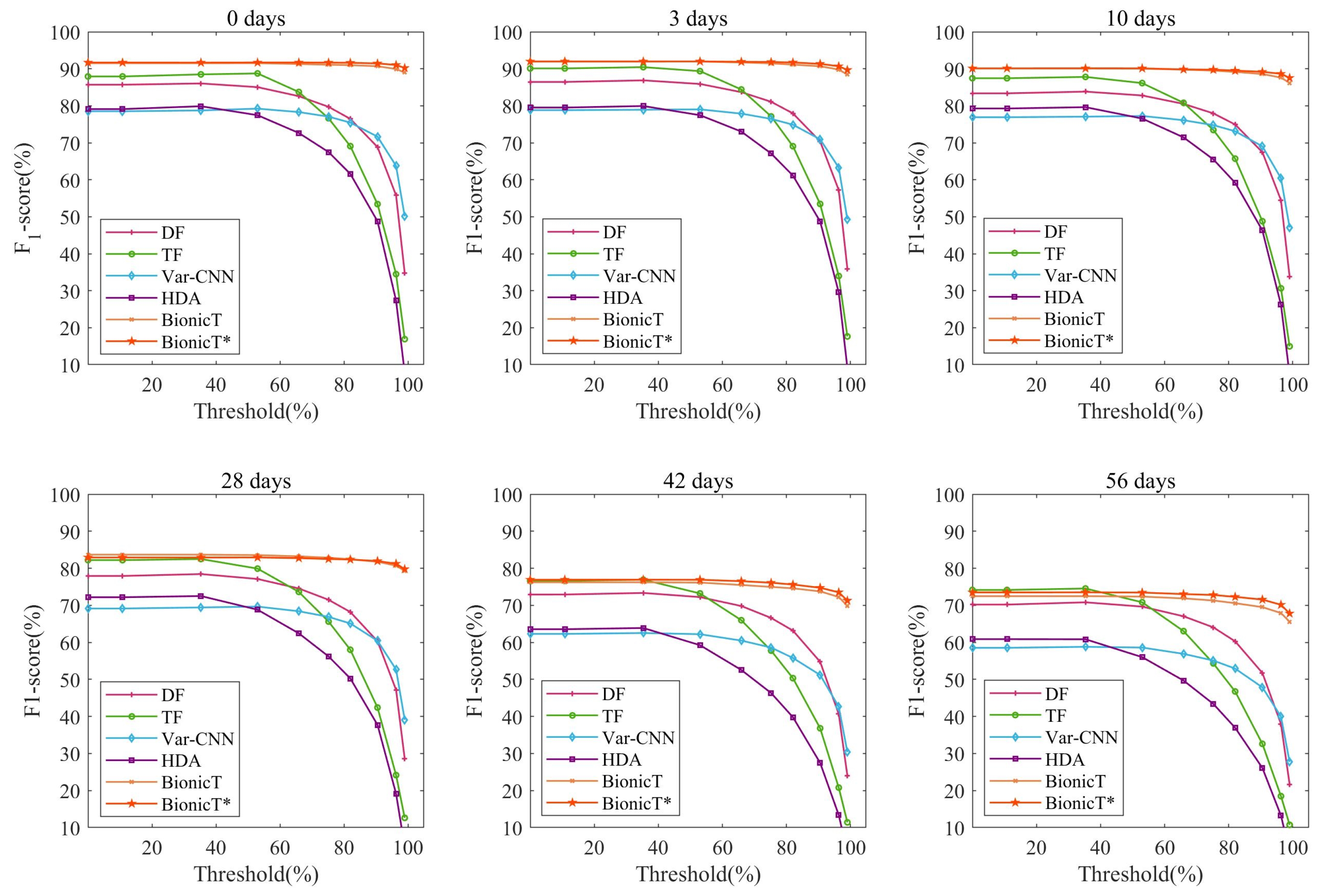
Figure 6 shows the results of WF attacks in the open-world scenario. Attackers may use high confidence thresholds to reduce false positives, resulting in higher precision but lower recall. It is also possible for the attacker to sacrifice precision to capture the user’s access to the monitored websites as much as possible. Therefore, we use the
-score to balance these two metrics. Like the closed-world results, our bionic traffic is more effective than HDA. It significantly improves the detection ability of the Var-CNN model. To a certain extent, our method is more practical than TF. For example, its performance is more stable as the threshold changes in the 10/15/20-shot settings. Moreover, the model trained with the SRP-based cumulative feature performs the best when the threshold grows. This phenomenon indicates that our bionic traces and the SRP-based cumulative feature give more detailed information about monitored websites. It can help the model better understand the distinction between different websites.
5.6. Evaluation on Concept Drift
In this section, we compare the performance of attacks in dealing with concept drift. We carried out experiments in both closed-world and open-world scenarios with 20 instances available for each monitored website. We mimic a scenario where the attacker only trains models on the initial dataset and tests on datasets collected after a period of time. We set the confidence threshold to to report the open-world scenario performance.
5.6.1. Experimental Setting
For the closed-world scenario, we use 100 random-sampled examples for each website from
and divide them into three chunks with 20/10/70 examples, respectively. We generated 1000 bionic traffic traces for each website base on the first chunk. We train the model by following the same way used in
Section 5.4. Then, we test the performance of attacks on each
subset.
For the open-world scenario, we introduce the unmonitored samples from
. We randomly pick 10,000 websites (each with one instance) from the dataset and split them into three disjoint chunks with 2000/1000/7000 instances, respectively. We organize the balance training dataset and train the model by following the same way used in
Section 5.5. We join the
subset with unmonitored samples from
to form the test dataset at every point in time.
5.6.2. Results
The closed-world results are shown in
Table 5, all attacks suffer the detrimental effect of concept drift. In a period of 56 days after training, the accuracy of DF dropped by nearly
, and the accuracy of Var-CNN dropped by nearly
. Our bionic trace can strongly weaken the influence of concept drift with the accuracy dropped by
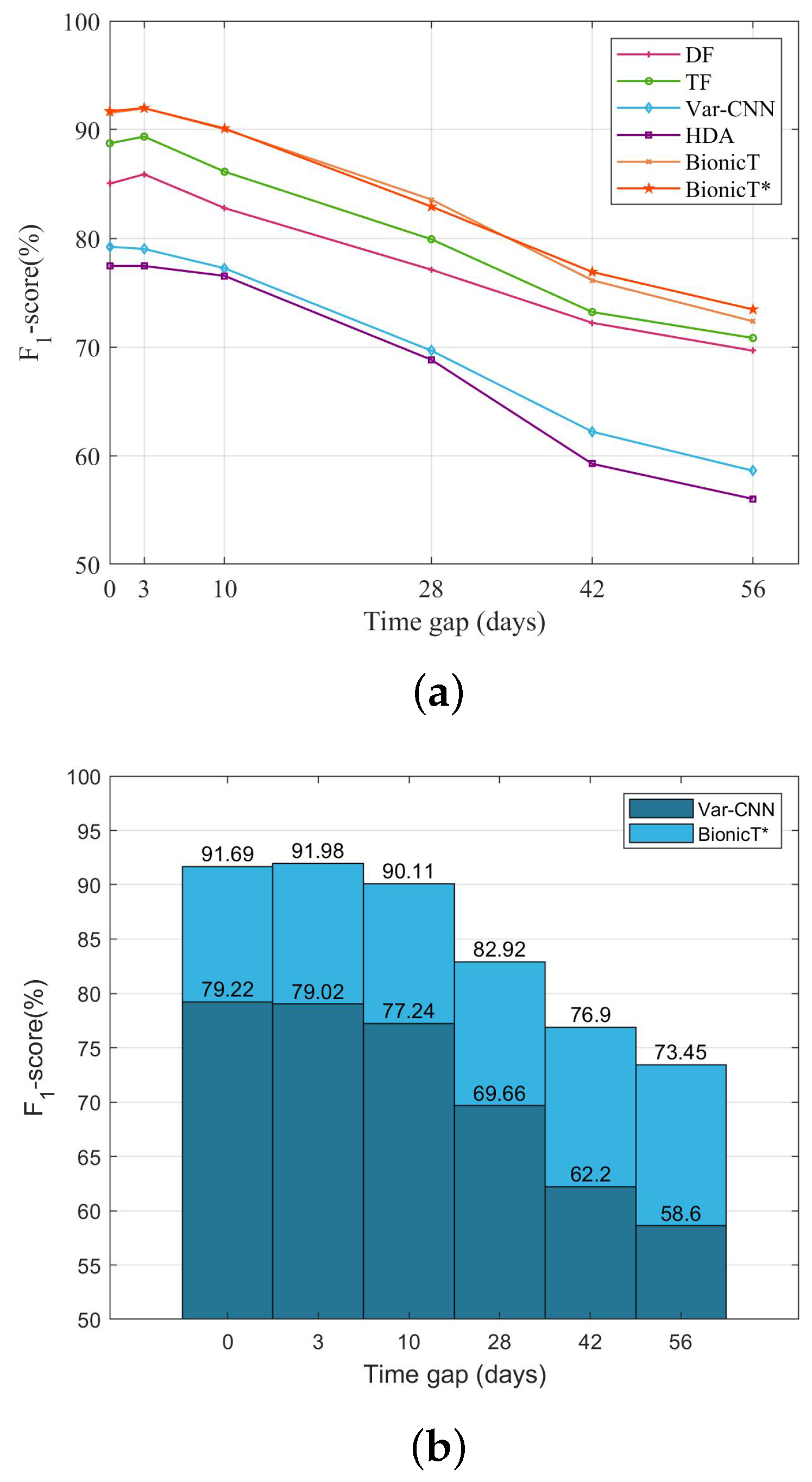
. At every point in time, our method shows an advantage over HDA. The performance of TF is impressive to stay at high accuracy. However, the attack that applies our bionic traces and the SRP-based cumulative feature performs the best.
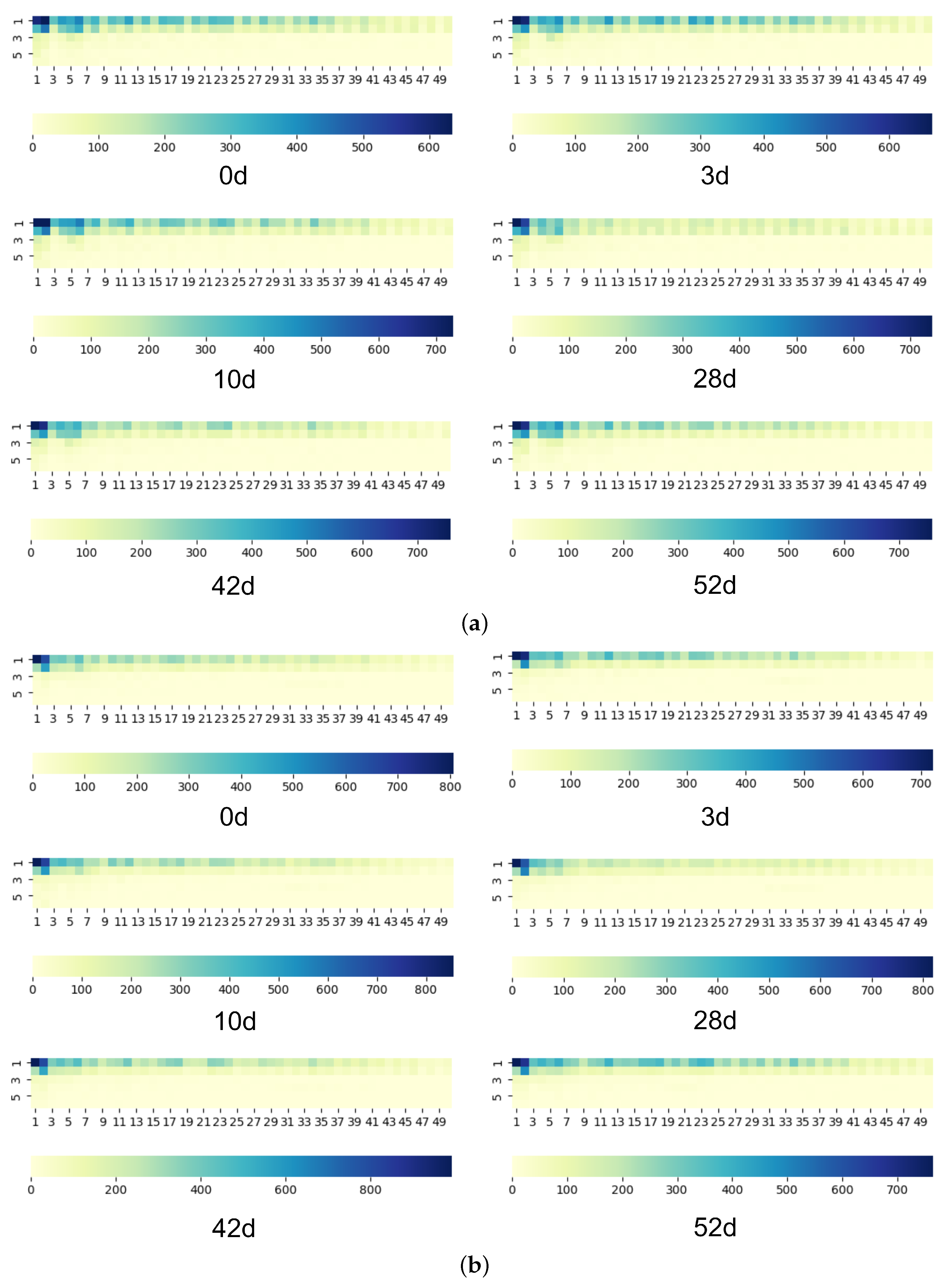
Figure 7 illustrates the performance of attacks in the open-world scenario. Our method leads the deep learning model to learn the deep abstract features of traffic traces, even though concept drift affects the data distribution of target datasets. Furthermore, as illustrated in
Figure 8a, the proposed SRP-based cumulative features show a greater advantage at a time gap of 56 days.
Figure 8b shows the enhancement of our method to the Var-CNN model. As the time gap grows, the enhancement of the
-score increases from 12% to 15%, which proves that our method can enhance the model’s ability to combat concept drift.
5.7. Closed-World Evaluation on the Defended Dataset
We further investigate whether bionic traces are effective for website traffic defended by WTF-PAD [
7], which is the main candidate to be deployed in Tor.
5.7.1. Experimental Setting
We randomly sample 100 instances for each website from the
. Then, we form the
n-shot training dataset by following the same procedure used in
Section 5.4. We generate 1000 bionic traces for each website.
5.7.2. Results
Table 6 shows the performance of WF attacks against WTF-PAD defense. The accuracy of all attacks significantly dropped to nearly 60% in the 20-shot setting. DF also behaves less than ideally even though it is announced to be effective against WTF-PAD. This observation suggests that the data hunger is more severe when WF defenses are applied. On the other hand, our bionic traces can help the Var-CNN model increase its capabilities to a certain extent. However, it is not as effective as it would be on undefended traces. The SRP-based cumulative feature even has a negative effect. It could be inferred that WTF-PAD sent dummy packets by both ends of the communication, which results in dummy SRP insertion and confusing traffic patterns. Therefore, we believe that the proposed bionic generation method needs to be tuned with some other tricks, e.g., insertion or deletion at SRP granularity.
6. Conclusions and Future Work
In this study, we investigated the composition mechanism of website fingerprinting from a microscopic level by proposing the concept of the send-and-receive pair (SRP). We demonstrated that SRP is statistically significant and can be used to describe website traffic trace. Based on this finding, we further proposed the bionic trace generation method. Expensive experiments show that bionic traces successfully simulated the website traffic and relieved the data hunger problem. The proposed SRP-based cumulative feature can help classify under the concept drift circumstances. Both closed-world and open-world results demonstrate that our method is competitive with TF while reducing the burden of data collection. The promising results verify that the concept of SRP is valuable.
We recognize some limitations in our study. For example, our bionic trace generation does not work well when WF defenses are applied. The bionic traces generation method we proposed is random to some extent, which may cause it useless for defended traffic. To tackle this problem, we need to focus on the property of each defense and specifically design our method. Therefore, more qualitative and quantitative studies are worthwhile to explore its potential further. Moreover, we believe that the intra-relationship between SRPs is an essential factor in composing fingerprints. We will continue researching in this direction by referring to the successful experience of learning the contextual connection of text in the natural language processing field.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}