Combining Keyframes and Image Classification for Violent Behavior Recognition


Abstract
:1. Introduction
2. Related Works
2.1. Datasets
2.2. Semantic Segmentation Algorithms
2.3. Keyframe Extraction Methods
2.4. Violence-Detection Models
3. Proposed Method
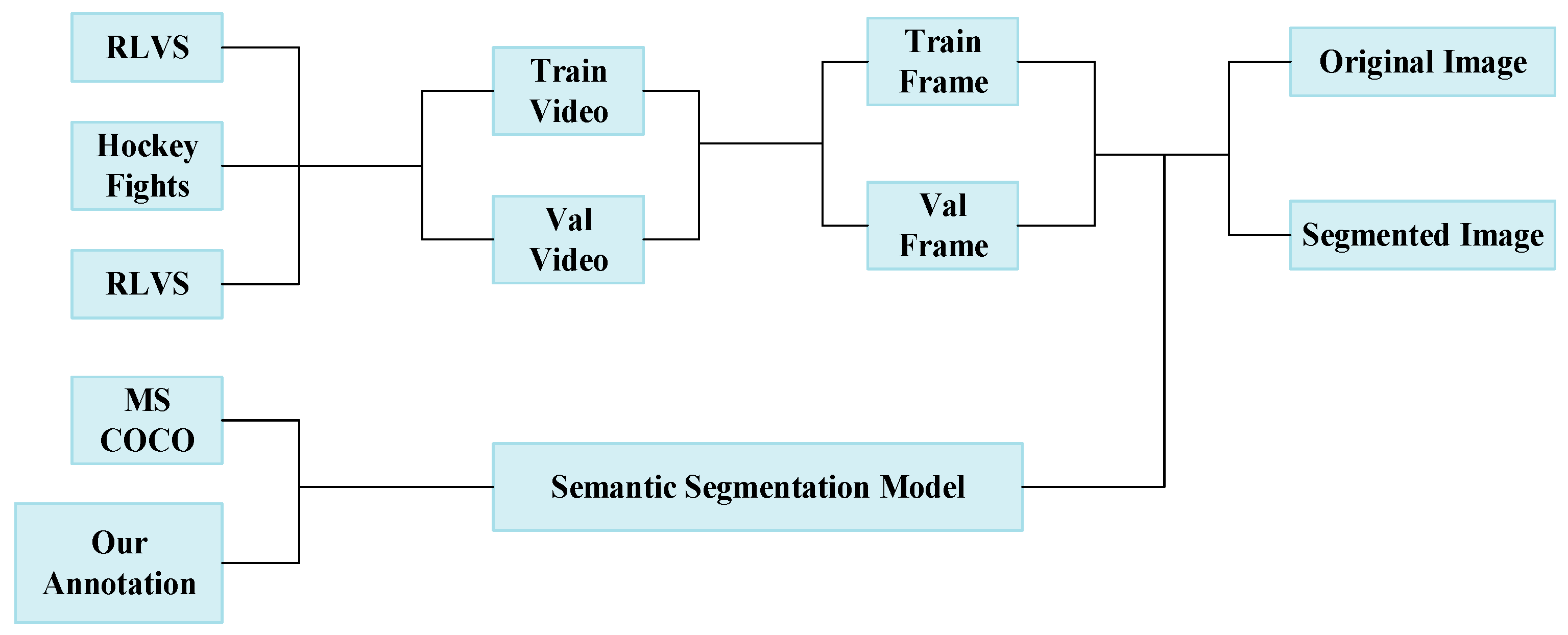
3.1. The Overall Framework
3.2. Dataset
3.3. Keyframe Extraction
3.4. Our Training Method
3.5. Judgment of Violence
4. Experiments
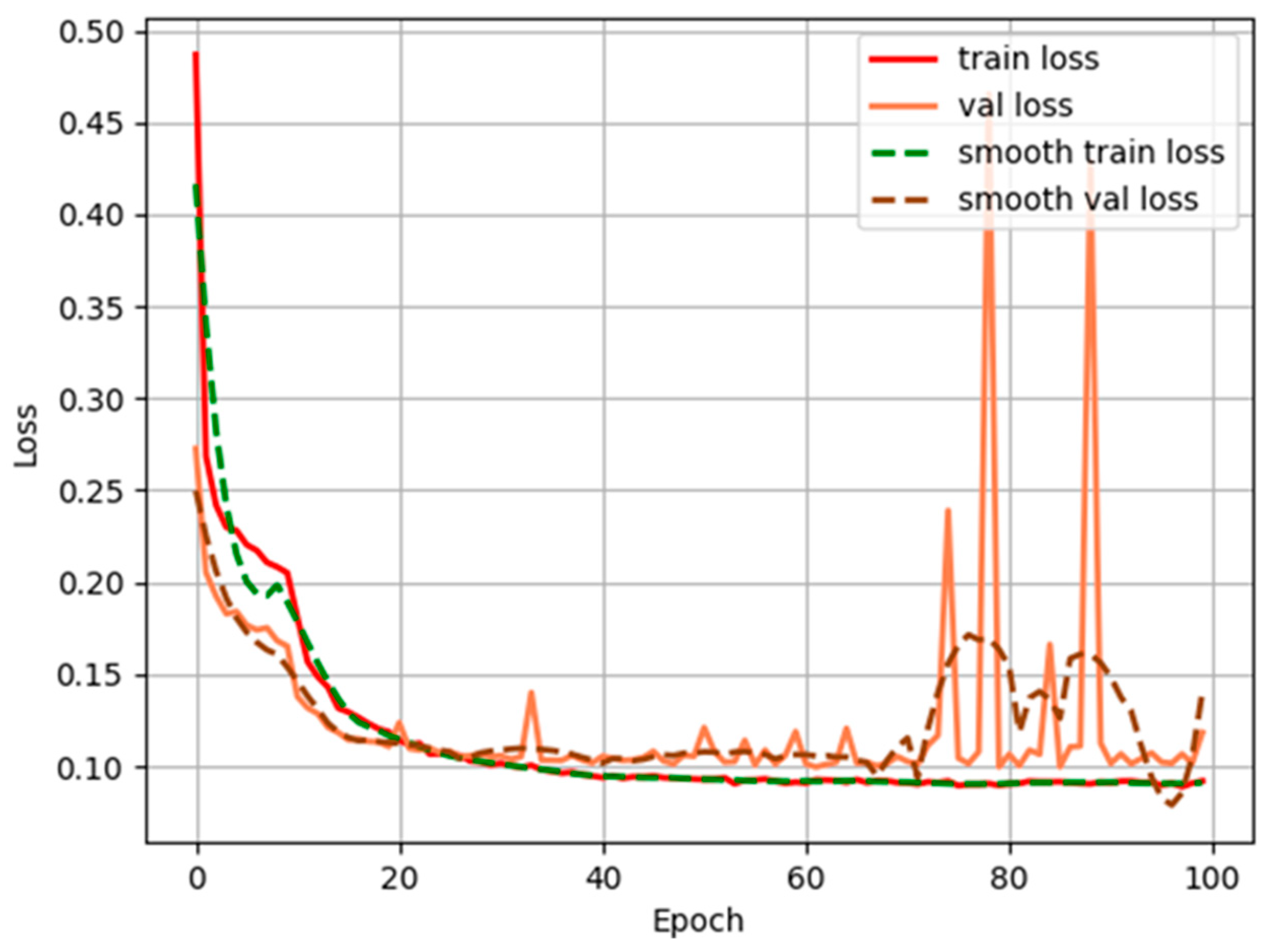
4.1. Deeplab-V3plus
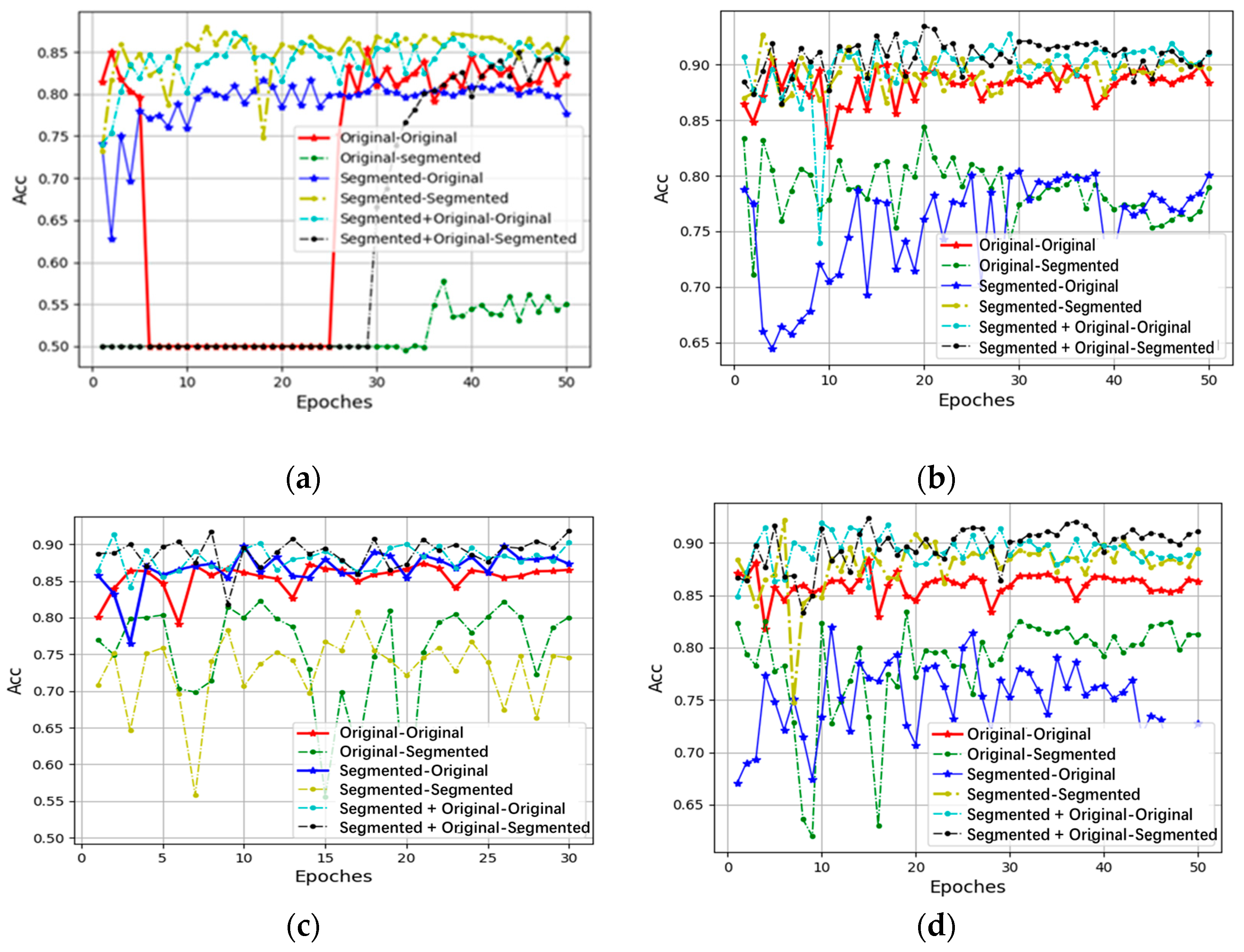
4.2. Facilitation of Model Learning by Segmented–Original Images
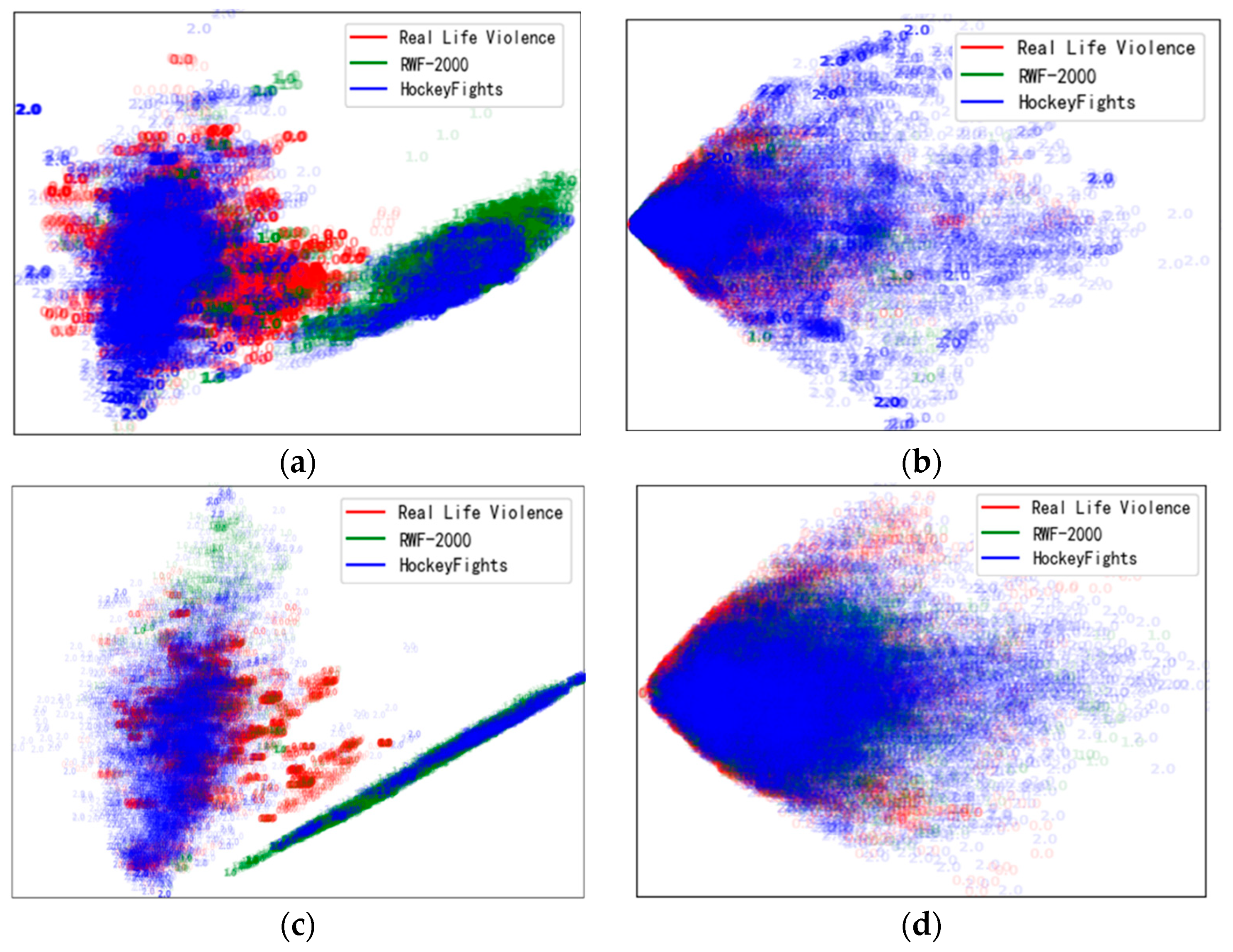
4.3. Keyframes
4.4. Our Violent-Behavior-Recognition System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Giannakopoulos, T.; Kosmopoulos, D.; Aristidou, A.; Theodoridis, S. Violence content classification using audio features. In Artificial Intelligence; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3955, pp. 502–507. [Google Scholar]
- Chen, L.-H.; Su, C.-W.; Hsu, H.-W. Violent scene detection in movies. Int. J. Pattern Recognit. Artif. Intell. 2011, 25, 1161–1172. [Google Scholar] [CrossRef]
- Sudhakaran, S.; Lanz, O. Learning to detect violent videos using convolutional long short-term memory. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Rendón-Segador, F.J.; Álvarez-García, J.A.; Enríquez, F.; Deniz, O. ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics 2021, 10, 1601. [Google Scholar] [CrossRef]
- Gkountakos, K.; Ioannidis, K.; Tsikrika, T.; Vrochidis, S.; Kompatsiaris, I. Crowd Violence Detection from Video Footage. In Proceedings of the 2021 International Conference on Content-Based Multimedia Indexing (CBMI), Lille, France, 28–30 June 2021.
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2014; pp. 568–576. [Google Scholar]
- Zhou, P.; Ding, Q.; Luo, H.; Hou, X. Violent interaction detection in video based on deep learning. J. Phys. Conf. Ser. 2017, 844, 012044. [Google Scholar] [CrossRef]
- Yasin, H.; Hussain, M.; Weber, A. Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network. Sensors 2020, 20, 2226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morais, R.; Le, V.; Tran, T.; Saha, B.; Mansour, M.; Venkatesh, S. Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cheng, Y.; Yang, Y.; Chen, H.B.; Wong, N.; Yu, H. S3-Net: A Fast and Lightweight Video Scene Understanding Network by Single-shot Segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Online, 5–9 January 2021; pp. 3328–3336. [Google Scholar]
- Zhang, J.; Yang, K.; Ma, C.; Reiß, S.; Peng, K.; Stiefelhagen, R. Bending reality: Distortion-Aware transformers for adapting to panoramic semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Deng, J.; Zhong, Z.; Huang, H.; Lan, Y.; Han, Y.; Zhang, Y. Lightweight semantic segmentation network for real-time weed mapping using unmanned aerial vehicles. Appl. Sci. 2020, 10, 7132. [Google Scholar] [CrossRef]
- Sadhu, S.; He, D.; Huang, C.-W.; Mallidi, S.H.; Wu, M.; Rastrow, A.; Stolcke, A.; Droppo, J.; Maas, R. wav2vec-c: A self-supervised model for speech representation learning. Proc. Interspeech 2021, 2021, 711–715. [Google Scholar]
- Serrano, I.; Deniz, O.; Espinosa-Aranda, J.L.; Bueno, G. Fight Recognition in Video Using Hough Forests and 2D Convolutional Neural Network. IEEE Trans. Image Process. 2018, 27, 4787–4797. [Google Scholar] [CrossRef] [PubMed]
- Soliman, M.M.; Kamal, M.H.; El-Massih, N.M.A.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Chongqing, China, 8–10 December 2019. [Google Scholar]
- Nievas, E.B.; Suarez, O.D.; Garc, G.B.; Sukthankar, G.B. Violence detection in video using computer vision techniques. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Seville, Spain, 29–31 August 2011. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An Open Large Scale Video Database for Violence Detection. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Perez, M.; Kot, A.C.; Rocha, A. Detection of Real-world Fights in Surveillance Videos. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Mark, E.; Luc Van, G.; Christopher, K.I.; Williams, J.W.; Andrew, Z. The pascal visual object classes (VOC) chal-lenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D. Microsoft coco: Common objects in context. In Proceedings of the European Conference On Computer Vision, Zürich, Switzerland, 6–12 September 2014. [Google Scholar]
- Miao, J.; Wei, Y.; Wu, Y.; Liang, C.; Li, G.; Yang, Y. VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004. [Google Scholar]
- Zivkovic, Z.; van der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Lin, S.; Ryabtsev, A.; Sengupta, S.; Curless, B.; Seitz, S.; Kemelmacher-Shlizerman, I. Real-Time High-Resolution Background Matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Sun, Z.; Jia, K.; Chen, H. Video Key Frame Extraction Based on Spatial-Temporal Color Distribution. In Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Haerbin, China, 15–17 August 2008. [Google Scholar]
- Hannane, R.; Elboushaki, A.; Afdel, K.; Naghabhushan, P.; Javed, M. An efficient method for video shot boundary detection and keyframe extraction using SIFT-point distribution histogram. Int. J. Multimedia Inf. Retr. 2016, 5, 89–104. [Google Scholar] [CrossRef]
- Guan, G.; Wang, Z.; Lu, S.; Deng, J.D.; Feng, D.D. Keypoint-Based Keyframe Selection. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 729–734. [Google Scholar] [CrossRef]
- Kar, A.; Rai, N.; Sikka, K.; Sharma, G. AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recogni-tion in Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial lstm networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Man, G.; Sun, X. Interested Keyframe Extraction of Commodity Video Based on Adaptive Clustering Annotation. Appl. Sci. 2022, 12, 1502. [Google Scholar] [CrossRef]
- Bellomo, N.; Burini, D.; Dosi, G.; Gibelli, L.; Knopoff, D.; Outada, N.; Terna, P.; Virgillito, M.E. What is life? A perspective of the mathematical kinetic theory of active particles. Math. Model. Methods Appl. Sci. 2021, 31, 1821–1866. [Google Scholar] [CrossRef]
- Song, W.; Zhang, D.; Zhao, X.; Yu, J.; Zheng, R.; Wang, A. A Novel Violent Video Detection Scheme Based on Modified 3D Convolutional Neural Networks. IEEE Access 2019, 7, 39172–39179. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis. Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | |
|---|---|
| backbone | xception |
| downsample | 16 or 8 |
| input_shape | 224 × 224 |
| Freeze_Epoch | 10 |
| Freeze_lr | 5.00 × 10−4 |
| UnFreeze_Epoch | 80 |
| Unfreeze_lr | 5.00 × 10−5 |
| No. | Training Dataset | Test Dataset |
|---|---|---|
| 1 | Original Image | Original Image |
| 2 | Original Image | Segmented Image |
| 3 | Segmented Image | Segmented Image |
| 4 | Segmented Image | Original Image |
| 5 | Segmented + Original Image | Original Image |
| 6 | Segmented + Original Image | Segmented Image |
| RLVS | Hockey Fights | |||
|---|---|---|---|---|
| Original Image | Segmented Image | Original Image | Segmented Image | |
| VGG19 | 85.70% | 70.79% | 97.62% | 90.38% |
| Ours (VGG19) | 88.34% | 89.34% | 97.03% | 96.52% |
| ResNet18 | 86.59% | 81.98% | 98.59% | 91.81% |
| Ours (ResNet18) | 91.39% | 91.78% | 98.27% | 96.35% |
| DesNet121 | 87.96% | 83.41% | 98.60% | 91.13% |
| Ours (DesNet121) | 93.01% | 92.34% | 98.40% | 97.58% |
| GoogLeNet | 90.49% | 84.42% | 98.48% | 91.23% |
| Ours (GoogLeNet) | 92.80% | 93.45% | 98.24% | 97.02% |
| # Define the reconstruction loss function def recon_loss(recon_x,x): loss = torch.sum((recon_seg—recon_unseg)**2).mean() return loss # Define segmented-original image pair hidden layer distance def Distance(laten_seg,laten_unseg): D = torch.sqrt((laten_seg—laten_unseg)**2).mean() Return D #model training for seg, unseg in emulate (trainloader): laten_seg = Encoder(seg) recon_seg = Decoder(laten_seg) #compute the segmented image reconstruction loss recon_loss_seg = recon_loss(seg, recon_seg) laten_unseg = Encoder(unseg) recon_unseg = Decoder(laten_unseg) #compute the original image reconstruction loss recon_loss_unseg = recon_loss(unseg, recon_unseg) #compute the distance of segmented-original image pair in the hidden layer Distance = Distance(laten_seg, laten_unseg) Loss = recon_loss_seg + recon_unseg_loss+ 0.001*Distance Loss.backward() optimizer() |
| Datasets | Average | Median | Var | Std | Min | Max |
|---|---|---|---|---|---|---|
| HockeyFights | 41.056 | 41 | 0.4528 | 0.6733 | 40 | 49 |
| RLVS | 143.69 | 132 | 84,490 | 290.74 | 29 | 11,272 |
| RWF-2000 | 150 | 150 | 0 | 0 | 150 | 150 |
| CCTV | 8797.55 | 1295 | 1,301,301,216.97 | 36,091.60 | 95 | 472,304 |
| Average | Violence | Nonviolence | |
|---|---|---|---|
| RLVS | 91.39% | 87.88% | 94.90% |
| Hockey Fights | 98.59% | 99.13% | 98.05% |
| Violent Flow | 92.06% | 87.12% | 98.73% |
| Threshold = 0.5 | Threshold = 0.7 | |||||
|---|---|---|---|---|---|---|
| A | V | N | A | V | N | |
| RLVS | 94.6% | 93.2% | 96.00% | 91.50% | 89.50% | 93.5% |
| Hockey | 98.5% | 98.0% | 99.0% | 97.5% | 96.0% | 99.0% |
| Violent Flow | 95.0% | 90.0% | 100% | 93.75% | 87.50% | 100% |
| RLVS | Hockey Fights | Violent Flow | ||
|---|---|---|---|---|
| Threshold = 0.5 | 5 | 94.6% | 98.50% | 95.0% |
| 10 | 96.75% | 97.5% | 95.0% | |
| 15 | 96.25% | 94.0% | 95.0% | |
| 20 | 96.0% | 92.0% | 95.0% | |
| Threshold = 0.7 | 5 | 91.50% | 91.5% | 91.5% |
| 10 | 93.0% | 98.0% | 93.5% | |
| 15 | 93.75% | 95.5% | 95.0% | |
| 20 | 92.5% | 91.5% | 93.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, Y.; Li, D.; Luo, Y. Combining Keyframes and Image Classification for Violent Behavior Recognition. Appl. Sci. 2022, 12, 8014. https://doi.org/10.3390/app12168014
Bi Y, Li D, Luo Y. Combining Keyframes and Image Classification for Violent Behavior Recognition. Applied Sciences. 2022; 12(16):8014. https://doi.org/10.3390/app12168014
Chicago/Turabian StyleBi, Yanqing, Dong Li, and Yu Luo. 2022. "Combining Keyframes and Image Classification for Violent Behavior Recognition" Applied Sciences 12, no. 16: 8014. https://doi.org/10.3390/app12168014
APA StyleBi, Y., Li, D., & Luo, Y. (2022). Combining Keyframes and Image Classification for Violent Behavior Recognition. Applied Sciences, 12(16), 8014. https://doi.org/10.3390/app12168014