
Detecting and Processing Anomalies in a Factory of the Future


 , ,
, ,
Abstract
:1. Introduction
- Presentation of new methods for detecting anomalies caused by malicious or accidental events for distributed systems in dynamic factory environments.
- Presentation of new approaches to mitigate such anomalies.
- Integration of the presented methods to develop a holistic anomaly handling approach to increase the resilience of the FoF.
2. Background and Related Work
2.1. Attack Vectors
2.2. Threat Actors
- Mass fraud and automated hacking: Use of automated tools (with as little human effort as possible) to monetize large-scale fraud.
- Providers of criminal infrastructures: These actors try to infect as many systems as possible in order to exploit them in a criminal infrastructure (e.g., botnets). They may also sell/rent the exploitation of this infrastructure to third parties.
- Skilled professionals: Expend significant effort to attack individual high-value targets. This type of attack may use specially designed malware with a significant effort, or the attacks are carried out across supply chain partners. High-value targets in an organization are also targeted by email and phone scams, using social engineering skills to extend the attack [20].
2.3. Anomaly Detection and Mitigation
3. Use-Case Introduction
4. Anomalies and Sources
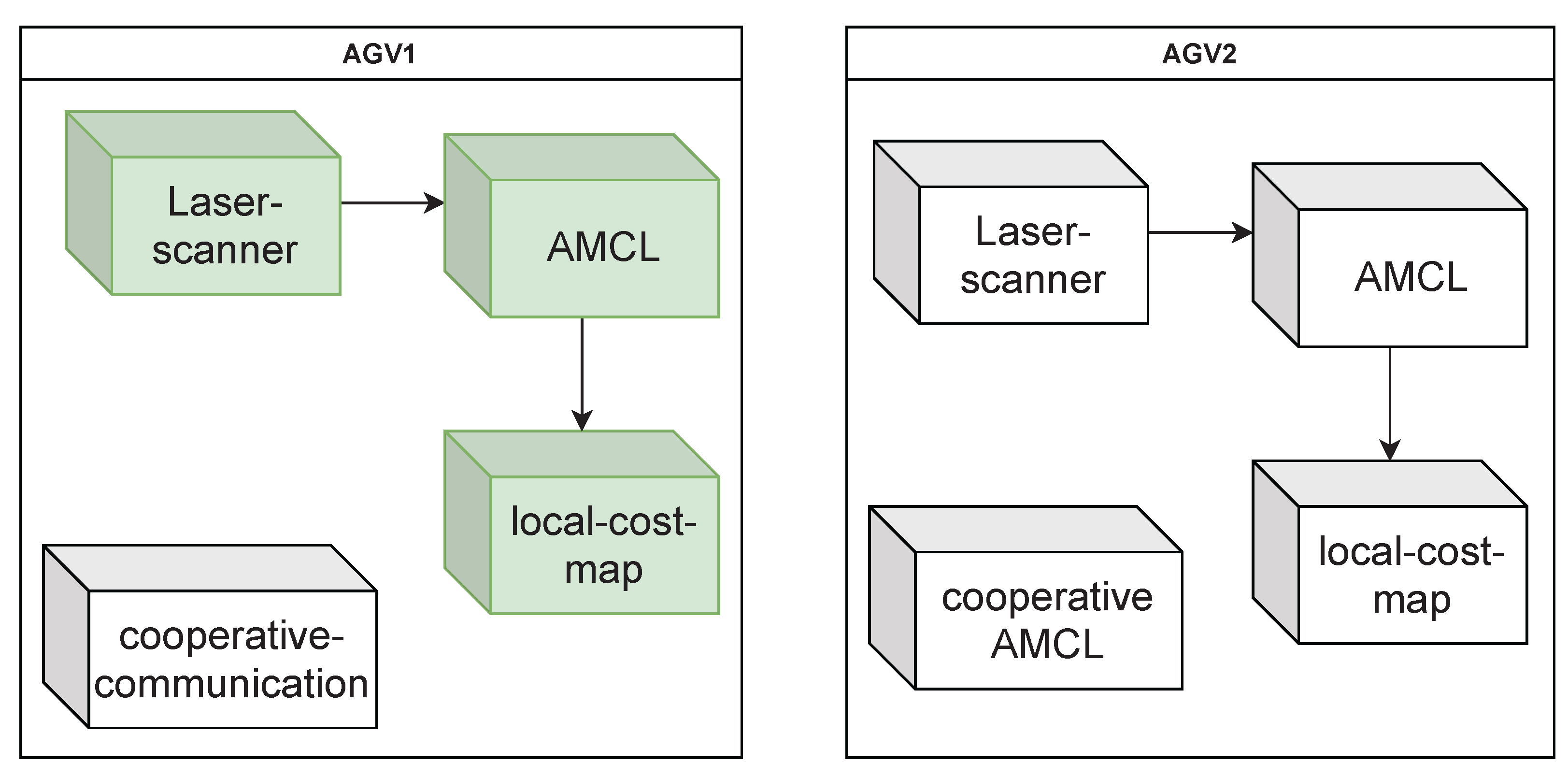
4.1. Unrecognized AGV Failure
4.2. AGV under Cyber-Attack
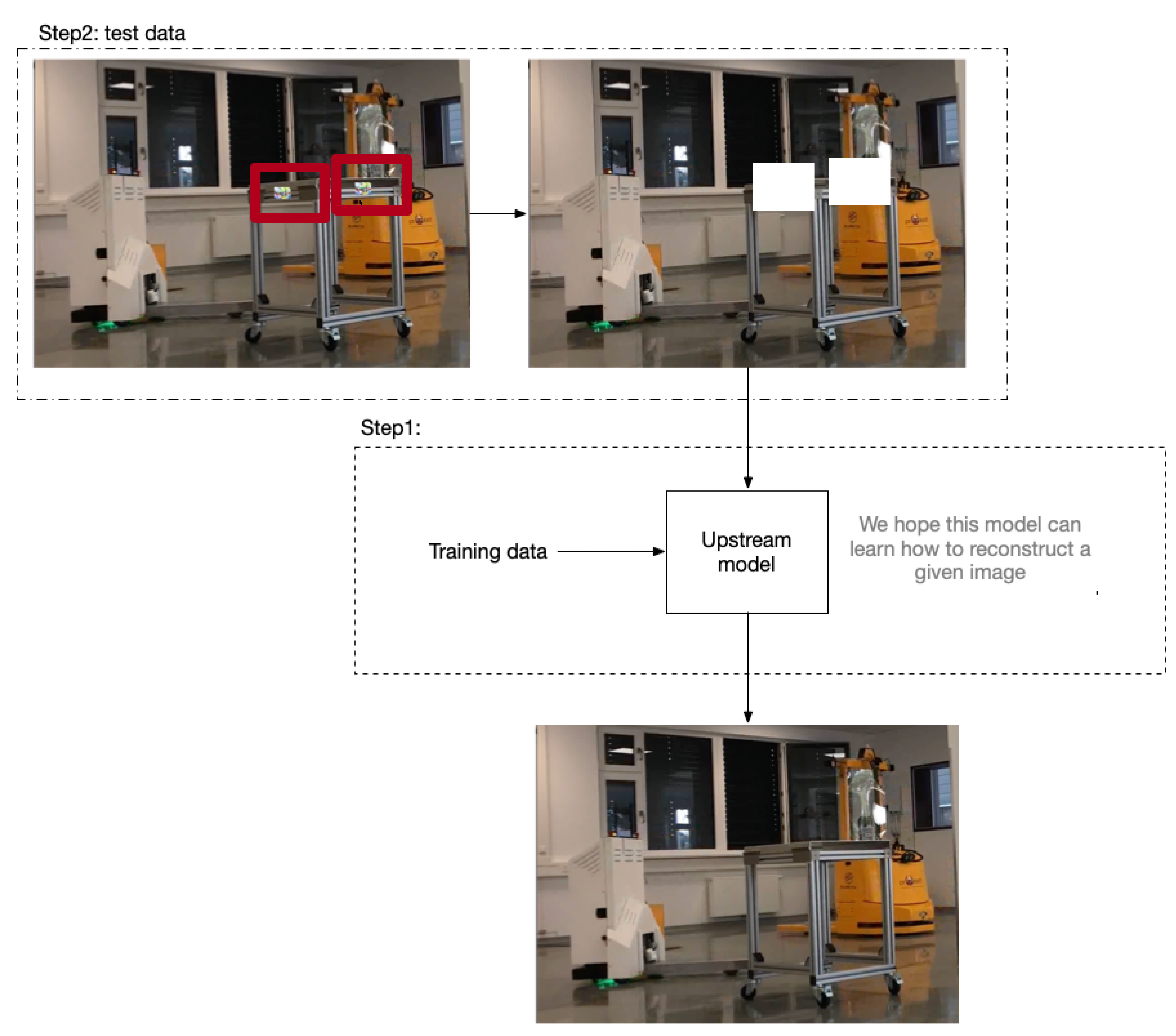
4.3. Adversarial Attack
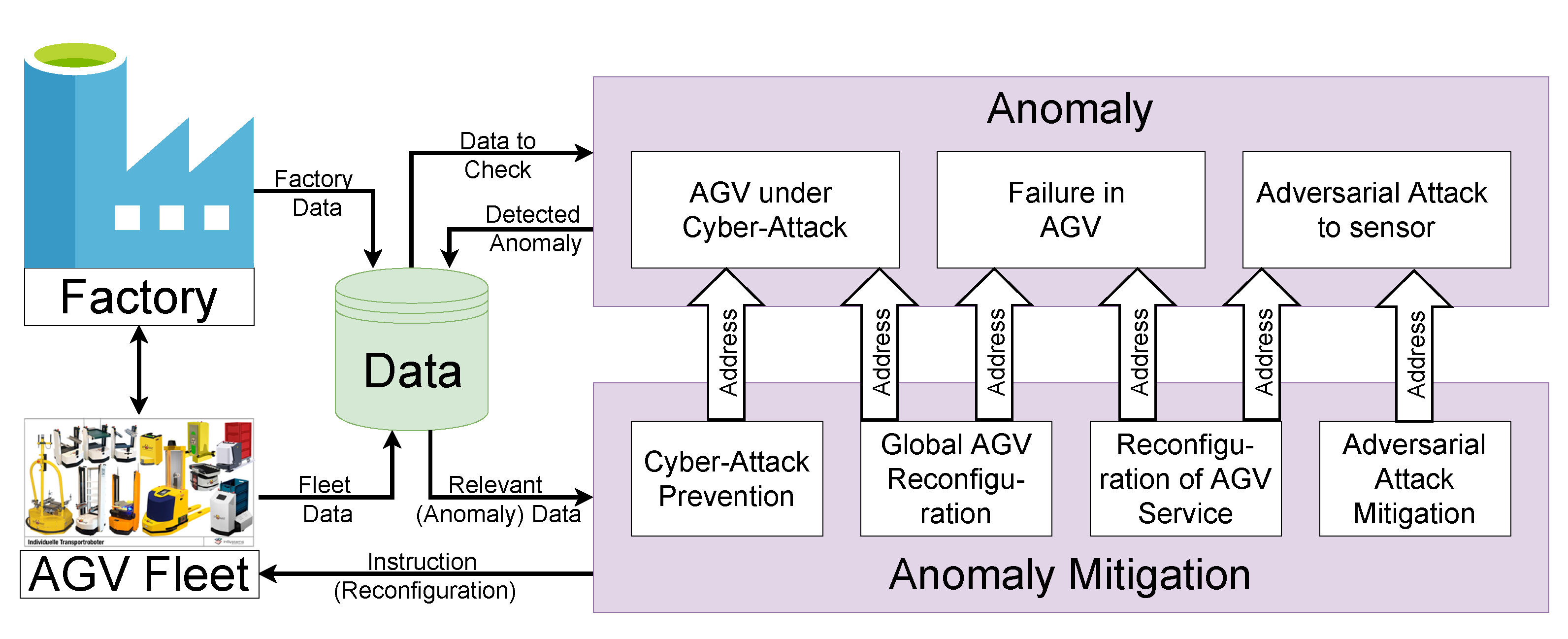
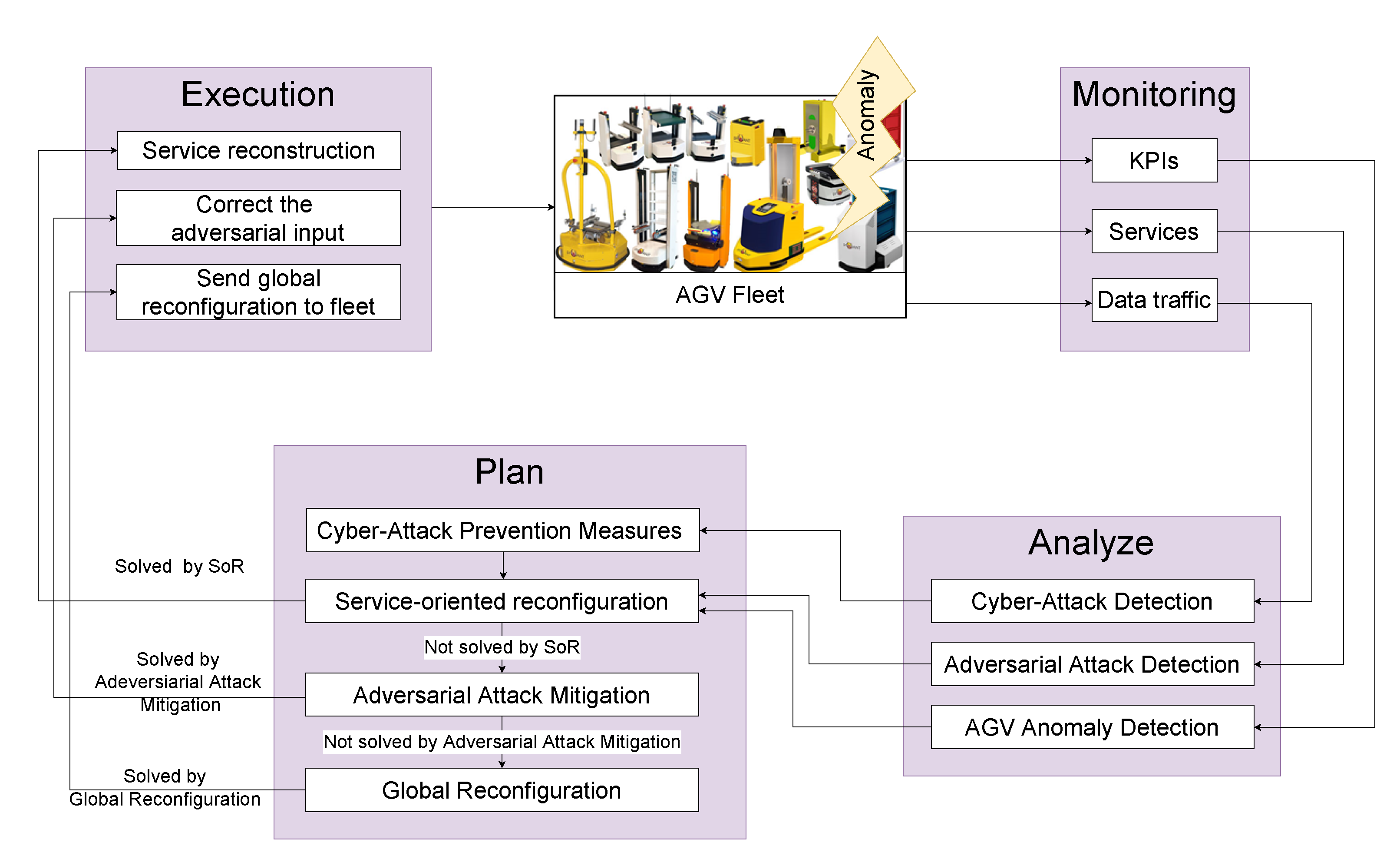
5. Methodology for Anomaly Detection and Mitigation
5.1. Anomaly Detection
5.1.1. Unrecognized Failure in AGV
Finalized Tasks per Hour
Driven Distances of Each AGV
Length of Local Queue of Each AGV
Battery Status
5.1.2. AGV under Cyber-Attack
5.1.3. Anomaly Information Exchange
5.2. Mitigation
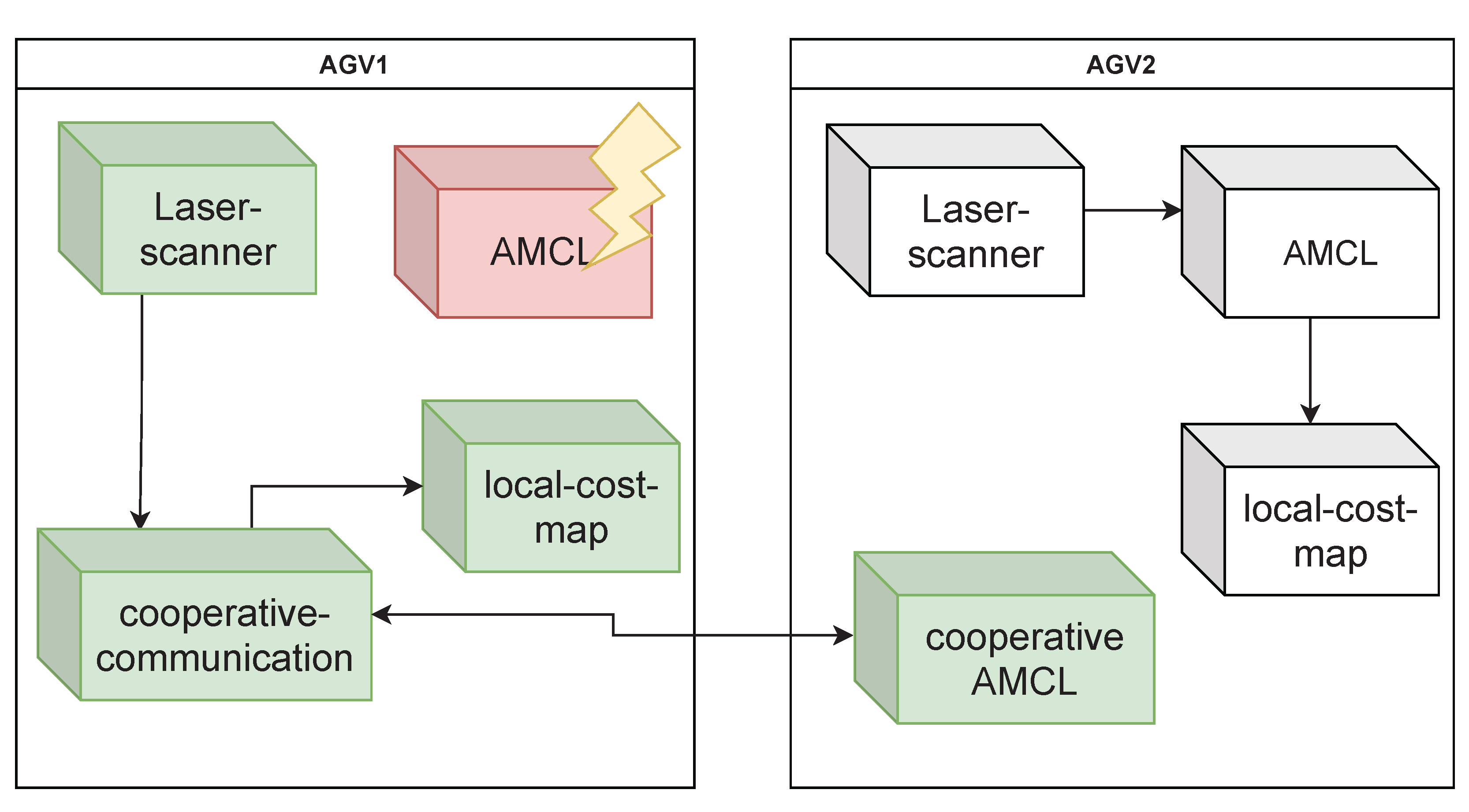
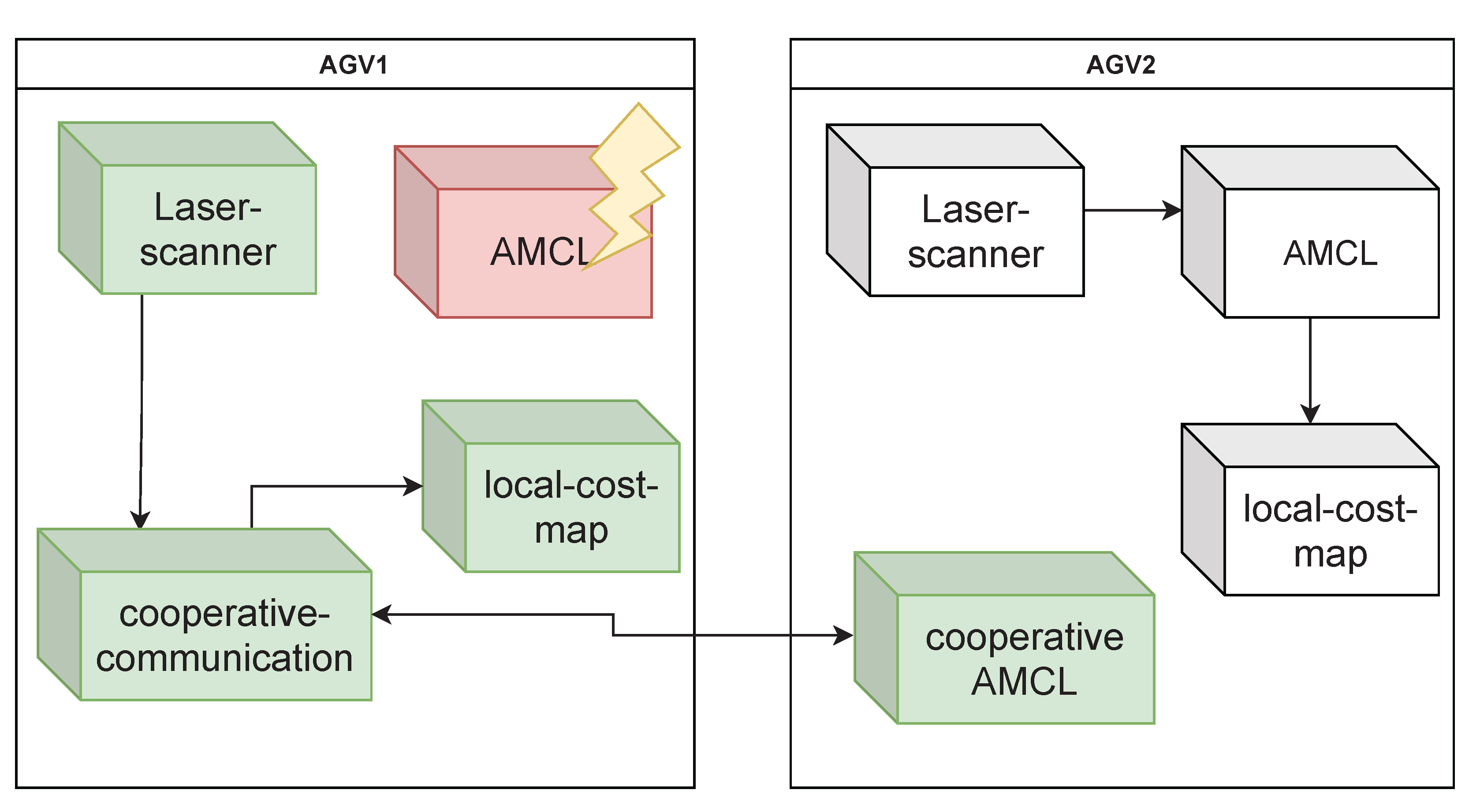
5.2.1. Reconfiguration of AGV Services
- Laser scanner running locally on AGV1,
- A cooperative communication-service that sends and receives all necessary messages,
- An AMCL-service provided by AGV2 and
- Local-cost map running on AGV1.
5.2.2. Global Reconfiguration
5.2.3. AGV under Cyber-Attack
5.2.4. Mitigation against Adversarial Attack
Ensemble Learning
Remove Adversarial Noise
6. Discussion
6.1. Integration of the Methods
6.2. Benefits, Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| AMCL | adaptive Monte Carlo landmark |
| AGV | Automated Guided Vehilce |
| CCaaS | Cybercrime-as-a-service |
| CSCA | Cyber Supply Chain Attacks |
| DDoS | Distributed-Denial-of-Service |
| FoF | Factory of the Future |
| IP | intellectual property |
| KPI | key performance indicator |
| MES | manufacturing execution system |
| MOOP | multi-objective optimization problem |
| MRTA | Multi Robot Task Assignment |
| OS | operating system |
| OT | operational technology |
| RaaS | Ransomware-as-a-Service |
| SoR | Service-Oriented Reconfiguration |
| TA | threat actor |
References
- Mohamed, M. Challenges and benefits of industry 4.0: An overview. Int. J. Supply Oper. Manag. 2018, 5, 256–265. [Google Scholar]
- Vaidya, S.; Ambad, P.; Bhosle, S. Industry 4.0–A Glimpse. Procedia Manuf. 2018, 20, 233–238. [Google Scholar] [CrossRef]
- Ahanger, T.A.; Aljumah, A. Internet of Things: A comprehensive study of security issues and defense mechanisms. IEEE Access 2018, 7, 11020–11028. [Google Scholar] [CrossRef]
- Sheffi, Y. Resilience: What it is and how to achieve it. Retrieved Oct. 2008, 1, 2013. [Google Scholar]
- Choi, S.; Youm, S.; Kang, Y.S. Development of scalable on-line anomaly detection system for autonomous and adaptive manufacturing processes. Appl. Sci. 2019, 9, 4502. [Google Scholar] [CrossRef]
- Wu, Y.; Dai, H.N.; Tang, H. Graph neural networks for anomaly detection in industrial internet of things. IEEE Internet Things J. 2021, 9, 9214–9231. [Google Scholar] [CrossRef]
- Quarta, D.; Pogliani, M.; Polino, M.; Maggi, F.; Zanchettin, A.M.; Zanero, S. An Experimental Security Analysis of an Industrial Robot Controller. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 268–286. [Google Scholar] [CrossRef]
- Gu, X.; Jin, X.; Ni, J.; Koren, Y. Manufacturing system design for resilience. Procedia Cirp 2015, 36, 135–140. [Google Scholar] [CrossRef]
- Kriaa, S.; Cambacedes, L.P.; Bouissou, M.; Halgand, Y. A survey of approaches combining safety and security for industrial control systems. Reliab. Eng. Syst. Saf. 2015, 139, 156–178. [Google Scholar] [CrossRef]
- Siepmann, D.; Graef, N. Industrie 4.0–Grundlagen und Gesamtzusammenhang. In Einführung und Umsetzung von Industrie 4.0; Roth, A., Ed.; Springer Gabler: Berlin, Germany, 2016; pp. 17–82. [Google Scholar] [CrossRef]
- Laufenburg, R. Cybercrime-as-a-Service. 2021. Available online: https://www.pcspezialist.de/blog/2021/09/15/cybercrime-as-a-service-caas/ (accessed on 19 May 2022).
- Panda Security. 73 Ransomware Statistics Vital for Security in 2022. 2022. Available online: https://www.pandasecurity.com/en/mediacenter/security/ransomware-statistics/ (accessed on 31 May 2022).
- SonicWall. 2022 SonicWall Cyber Threat Report. 2022. Available online: https://www.sonicwall.com/2022-cyber-threat-report/ (accessed on 28 July 2022).
- IBM Security. Cost of a Data Breach Report 2021. 2021. Available online: https://www.ibm.com/downloads/cas/OJDVQGRY (accessed on 28 July 2022).
- IBM Security. X-Force Threat Intelligence Index 2022. 2022. Available online: https://www.ibm.com/downloads/cas/ADLMYLAZ (accessed on 28 July 2022).
- Symantec. Internet Security Threat Report. 2019, Volume 24. Available online: https://docs.broadcom.com/doc/istr-24-2019-en (accessed on 28 July 2022).
- Kern, E.; Szanto, A. Cyber Supply Chain Attacks. Brandenburgisches Institut für Gesellschaft und Sicherheit. BIGS Policy Paper 10, forthcoming.
- Bryan, J. A Better Way to Manage Third-Party Risk. 2019. Available online: https://www.gartner.com/smarterwithgartner/a-better-way-to-manage-third-party-risk (accessed on 31 May 2022).
- Smith, Z.M.; Lostri, E.; Lewi, J.A. The Hidden Costs of Cybercrime. McAfee, 2020. Available online: https://www.mcafee.com/enterprise/en-us/assets/reports/rp-hidden-costs-of-cybercrime.pdf (accessed on 28 July 2022).
- Fortinet. Global Threat Landscape Report. A Semiannual Report by FortiGuard Labs. 1H 2021. 2021. Available online: https://www.fortinet.com/content/dam/fortinet/assets/threat-reports/report-threat-landscape-2021.pdf (accessed on 28 July 2022).
- FireEye Mandiant Services. M-Trends 2020 Special Report. 2020. Available online: hhttps://www.mandiant.com/sites/default/files/2021-09/mtrends-2020.pdf (accessed on 28 July 2022).
- Dunn, P. Deloitte and the Ethics of Corporate Espionage. In Proceedings of the International Association for Business and Society, Hong Kong SAR, China, 6–10 June 2018; Number 29. pp. 65–70. [Google Scholar] [CrossRef]
- Javers, E. Accountants and Spies: The Secret History of Deloitte’s Espionage Practice. 2016. Available online: https://www.cnbc.com/2016/12/19/accountants-and-spies-the-secret-history-of-deloittes-espionage-practice.html (accessed on 31 May 2022).
- Porter, M.E. Competitive Strategy: Techniques for Analyzing Industries and Competitors; University of Michigan Free Press: Ann Arbor, MI, USA, 1980. [Google Scholar]
- Davis, N.; Raina, G.; Jagannathan, K. A framework for end-to-end deep learning-based anomaly detection in transportation networks. Transp. Res. Interdiscip. Perspect. 2020, 5, 100112. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. CSUR 2009, 41, 1–58. [Google Scholar] [CrossRef]
- IndustryWeek in collaboration with Emerson How Manufacturers Can Achieve Top Quartile Performance. 2016. Available online: https://partners.wsj.com/emerson/unlocking-performance/how-manufacturers-can-achieve-top-quartile-performance/ (accessed on 19 July 2022).
- Kamat, P.; Sugandhi, R. Anomaly detection for predictive maintenance in industry 4.0-A survey. In E3S Web of Conferences; EDP Sciences: Les Ulis, France, 2020; Volume 170, p. 02007. [Google Scholar]
- Sharma, B.; Sharma, L.; Lal, C. Anomaly detection techniques using deep learning in IoT: A survey. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 146–149. [Google Scholar]
- Landauer, M.; Onder, S.; Skopik, F.; Wurzenberger, M. Deep Learning for Anomaly Detection in Log Data: A Survey. arXiv 2022, arXiv:2207.03820. [Google Scholar]
- Trauer, J.; Pfingstl, S.; Finsterer, M.; Zimmermann, M. Improving Production Efficiency with a Digital Twin Based on Anomaly Detection. Sustainability 2021, 13, 10155. [Google Scholar] [CrossRef]
- Bécue, A.; Maia, E.; Feeken, L.; Borchers, P.; Praça, I. A New Concept of Digital Twin Supporting Optimization and Resilience of Factories of the Future. Appl. Sci. 2020, 10, 4482. [Google Scholar] [CrossRef]
- Duman, T.B.; Bayram, B.; İnce, G. Acoustic Anomaly Detection Using Convolutional Autoencoders in Industrial Processes. In Proceedings of the 14th International Conference on Soft Computing Models in Industrial and Environmental Applications (SOCO 2019); Martínez Álvarez, F., Troncoso Lora, A., Sáez Muñoz, J.A., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 432–442. [Google Scholar]
- Münz, G.; Li, S.; Carle, G. Traffic Anomaly Detection Using K-Means Clustering. In GI/ITG Workshop MMBnet; University of Bamberg Press: Bamberg, Germany, 2007; Volume 7, p. 9. [Google Scholar]
- Hsieh, R.J.; Chou, J.; Ho, C.H. Unsupervised online anomaly detection on multivariate sensing time series data for smart manufacturing. In Proceedings of the 2019 IEEE 12th Conference on Service-Oriented Computing and Applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019; pp. 90–97. [Google Scholar]
- Windmann, S.; Maier, A.; Niggemann, O.; Frey, C.; Bernardi, A.; Gu, Y.; Pfrommer, H.; Steckel, T.; Krüger, M.; Kraus, R. Big data analysis of manufacturing processes. J. Phys. Conf. Ser. 2015, 659, 012055. [Google Scholar] [CrossRef]
- Stojanovic, L.; Dinic, M.; Stojanovic, N.; Stojadinovic, A. Big-data-driven anomaly detection in industry (4.0): An approach and a case study. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1647–1652. [Google Scholar]
- Zhang, C.; Wang, Z.; Ding, K.; Chan, F.T.; Ji, W. An energy-aware cyber physical system for energy Big data analysis and recessive production anomalies detection in discrete manufacturing workshops. Int. J. Prod. Res. 2020, 58, 7059–7077. [Google Scholar] [CrossRef]
- Hollerer, S.; Kastner, W.; Sauter, T. Towards a threat modeling approach addressing security and safety in OT environments. In Proceedings of the 2021 17th IEEE International Conference on Factory Communication Systems (WFCS), Linz, Austria, 9–11 June 2021; pp. 37–40. [Google Scholar]
- Novak, T.; Treytl, A.; Palensky, P. Common approach to functional safety and system security in building automation and control systems. In Proceedings of the 2007 IEEE Conference on Emerging Technologies and Factory Automation (EFTA 2007), Patras, Greece, 25–28 September 2007; pp. 1141–1148. [Google Scholar]
- Antón, S.D.; Schotten, H.D. Putting together the pieces: A concept for holistic industrial intrusion detection. In Proceedings of the ECCWS 2019 18th European Conference on Cyber Warfare and Security, Coimbra, Portugal, 4–5 July 2019; Academic Conferences and Publishing Limited: Reading, UK, 2019; p. 178. [Google Scholar]
- Bauer, D.; Böhm, M.; Bauernhansl, T.; Sauer, A. Increased resilience for manufacturing systems in supply networks through data-based turbulence mitigation. Prod. Eng. Res. Dev. 2021, 15, 385–395. [Google Scholar] [CrossRef]
- Hu, M.; Liao, Y.; Wang, W.; Li, G.; Cheng, B.; Chen, F. Decision Tree-Based Maneuver Prediction for Driver Rear-End Risk-Avoidance Behaviors in Cut-In Scenarios. J. Adv. Transp. 2017, 2017, 7170358. [Google Scholar] [CrossRef]
- Xia, W.; Goh, J.; Cortes, C.A.; Lu, Y.; Xu, X. Decentralized coordination of autonomous AGVs for flexible factory automation in the context of Industry 4.0. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 488–493. [Google Scholar]
- Herrero-Perez, D.; Matinez-Barbera, H. Decentralized coordination of autonomous agvs in flexible manufacturing systems. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3674–3679. [Google Scholar]
- Yao, F.; Keller, A.; Ahmad, M.; Ahmad, B.; Harrison, R.; Colombo, A.W. Optimizing the scheduling of autonomous guided vehicle in a manufacturing process. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 264–269. [Google Scholar]
- Salehie, M.; Tahvildari, L. Towards a Goal-Driven Approach to Action Selection in Self-Adaptive Software. Softw. Pract. Exp. 2012, 42, 211–233. [Google Scholar] [CrossRef]
- Rosa, L.; Rodrigues, L.; Lopes, A.; Hiltunen, M.; Schlichting, R. Self-Management of Adaptable Component-Based Applications. IEEE Trans. Softw. Eng. 2013, 39, 403–421. [Google Scholar] [CrossRef]
- Mauro, J.; Nieke, M.; Seidl, C.; Yu, I.C. Context Aware Reconfiguration in Software Product Lines. In Proceedings of the Tenth International Workshop on Variability Modelling of Software-Intensive Systems, VaMoS ’16, Salvador, Brazil, 27–29 January 2016; pp. 41–48. [Google Scholar] [CrossRef]
- Sinreich, D. An architectural blueprint for autonomic computing. In Technical Report; IBM: New York, NY, USA, 2006. [Google Scholar]
- Siefke, L.; Sommer, V.; Wudka, B.; Thomas, C. Robotic Systems of Systems Based on a Decentralized Service-Oriented Architecture. Robotics 2020, 9, 78. [Google Scholar] [CrossRef]
- Thomas, C.; Mirzaei, E.; Wudka, B.; Siefke, L.; Sommer, V. Service-Oriented Reconfiguration in Systems of Systems Assured by Dynamic Modular Safety Cases. In Communications in Computer and Information Science; Springer International Publishing: Basel, Switzerland, 2021; pp. 12–29. [Google Scholar] [CrossRef]
- Understanding and Mitigating Russian State-Sponsored Cyber Threats to U.S. Critical Infrastructure. 2022. Available online: https://www.cisa.gov/uscert/ncas/alerts/aa22-011a (accessed on 21 March 2022).
- Koutras, M.V.; Bersimis, S.; Maravelakis, P.E. Statistical Process Control using Shewhart Control Charts with Supplementary Runs Rules. Methodol. Comput. Appl. Probab. 2007, 9, 207–224. [Google Scholar] [CrossRef]
- Eschemann, P.; Borchers, P.; Lisiecki, D.; Krauskopf, J.E. Metric Based Dynamic Control Charts for Edge Anomaly Detection in Factory Logistics. In Proceedings of the 3nd International Joint Conference on Automation Science and Engineering (JCASE 2022), Chengdu, China, 14–16 October 2022; to appear. [Google Scholar]
- The Cyber Kill Chain. 2011. Available online: https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html (accessed on 21 March 2022).
- Korsah, G.A.; Stentz, A.; Dias, M.B. A comprehensive taxonomy for multi-robot task allocation. Int. J. Robot. Res. 2013, 32, 1495–1512. [Google Scholar] [CrossRef]
- Gerkey, B.P.; Matarić, M.J. A Formal Analysis and Taxonomy of Task Allocation in Multi-Robot Systems. Int. J. Robot. Res. 2004, 23, 939–954. [Google Scholar] [CrossRef]
- Borchers, P.; Lisiecki, D.; Eschemann, P.; Feeken, L.; Hajnorouzi, M.; Stierand, I. Comparison of Production Dynamics Prediction Methods to Increase Context Awareness for Industrial Transport Systems. In Proceedings of the European Simulation and Modelling Conference 2021, ESM 2021, Rome, Italy, 7–29 October 2021; pp. 49–55. [Google Scholar]
- Hwang, C.L.; Masud, A.S.M. Methods for Multiple Objective Decision Making. In Multiple Objective Decision Making—Methods and Applications: A State-of-the-Art Survey; Springer: Berlin/Heidelberg, Germany, 1979; pp. 21–283. [Google Scholar] [CrossRef]
- Li, R.; Tian, X.; Yu, L.; Kang, R. A systematic disturbance analysis method for resilience evaluation: A case study in material handling systems. Sustainability 2019, 11, 1447. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anomaly Source | ||||
|---|---|---|---|---|
| Defects | Process Changes | Cyber-Attack | ||
| Anomaly Indicator | Process indicator | No transport jobs from broken machine | High number of transport jobs from suddenly high active machine | Malicious or dangerous manipulated process data |
| Component indicator | Lower driven distance of AGV with broken self-localization module | Length of local queue of each robot longer than usual due to unexpected transport request peak | Deviation of AGV-internal software list | |
| Communication indicator | No messages received from AGV with broken WIFI module | High number of messages from MES received | Wrong agent (e.g., AGV) publishes transport job | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feeken, L.; Kern, E.; Szanto, A.; Winnicki, A.; Kao, C.-Y.; Wudka, B.; Glawe, M.; Mirzaei, E.; Borchers, P.; Burghardt, C. Detecting and Processing Anomalies in a Factory of the Future. Appl. Sci. 2022, 12, 8181. https://doi.org/10.3390/app12168181
Feeken L, Kern E, Szanto A, Winnicki A, Kao C-Y, Wudka B, Glawe M, Mirzaei E, Borchers P, Burghardt C. Detecting and Processing Anomalies in a Factory of the Future. Applied Sciences. 2022; 12(16):8181. https://doi.org/10.3390/app12168181
Chicago/Turabian StyleFeeken, Linda, Esther Kern, Alexander Szanto, Alexander Winnicki, Ching-Yu Kao, Björn Wudka, Matthias Glawe, Elham Mirzaei, Philipp Borchers, and Christian Burghardt. 2022. "Detecting and Processing Anomalies in a Factory of the Future" Applied Sciences 12, no. 16: 8181. https://doi.org/10.3390/app12168181
APA StyleFeeken, L., Kern, E., Szanto, A., Winnicki, A., Kao, C.-Y., Wudka, B., Glawe, M., Mirzaei, E., Borchers, P., & Burghardt, C. (2022). Detecting and Processing Anomalies in a Factory of the Future. Applied Sciences, 12(16), 8181. https://doi.org/10.3390/app12168181