
Accelerated Inference of Face Detection under Edge-Cloud Collaboration


Abstract
:1. Introduction
2. Related Work
2.1. Face Detection Models
2.2. Model Pruning
2.3. Model Partition
3. Proposed Method
3.1. Research Motivation
3.2. Weight Pruning
3.3. Deconvolution Pruning
3.4. Joint Optimization of Model Split Points and Bandwidth
| Algorithm 1 The partition algorithm |
Input: N: numbers of pre-partition points : numbers of layer before partition point : each layers output data size after partition point : relationship mapping table of different partition point B: current bandwidth : the target latency Output: Split point selection //Procedure
|
4. Evaluation
4.1. Experiment Setup
4.1.1. Environment
4.1.2. Dataset
4.1.3. Performance
4.2. Deconvolution Pruning Results
4.3. Acceleration Effect on the Server
4.4. Comparison of Different Input Resolutions
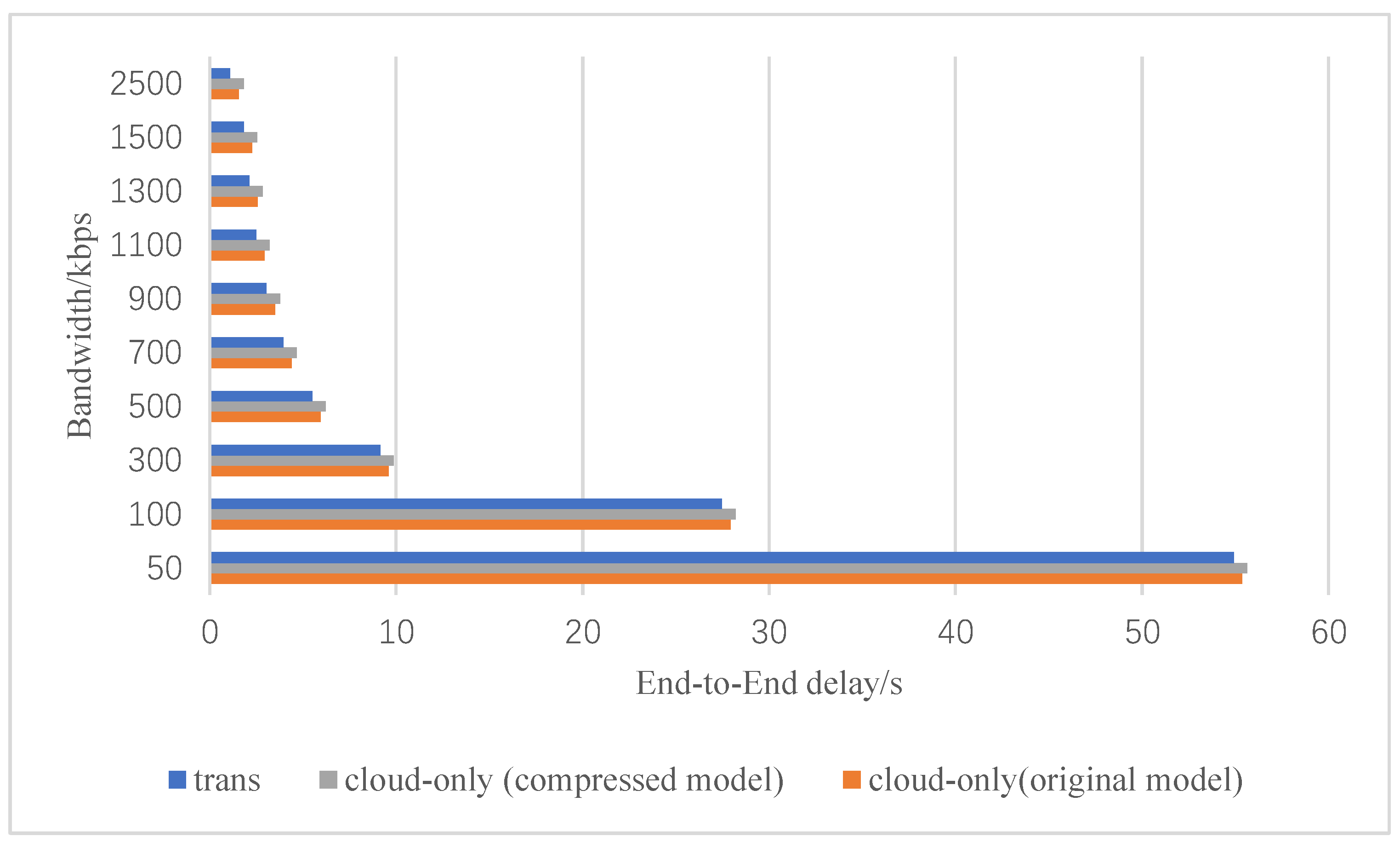
4.5. Co-Inference Acceleration Effect
5. Summary and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep neural network |
| CNN | Convolutional neural network |
| MAP | Mean average precision |
| TRT | Tensor RT |
References
- Xu, T.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar]
- Zhu, Y.; Cai, H.; Zhang, S.; Wang, C.; Xiong, Y. Tinaface: Strong but simple baseline for face detection. arXiv 2020, arXiv:2011.13183. [Google Scholar]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z.; Li, S.Z.; Zou, X. Selective refinement network for high performance face detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8231–8238. [Google Scholar]
- Deng, H.; Feng, Z.; Qian, G.; Lv, X.; Li, H.; Li, G. MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss. Appl. Sci. 2021, 11, 7310. [Google Scholar] [CrossRef]
- Gupta, K.D.; Ahsan, M.; Andrei, S.; Alam, K.M.R. A robust approach of facial orientation recognition from facial features. BRAIN Broad Res. Artif. Intell. Neurosci. 2017, 8, 5–12. [Google Scholar]
- Zhuang, L.; Li, J.; Shen, Z.; Gao, H.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.; Han, S. AMC: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- Ding, X.; Ding, G.; Guo, Y.; Han, J. Centripetal sgd for pruning very deep convolutional networks with complicated structure. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4943–4953. [Google Scholar]
- Lin, S.; Ji, R.; Yan, C.; Zhang, B.; Cao, L.; Ye, Q.; Huang, F.; Doermann, D. Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2790–2799. [Google Scholar]
- Song, H.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kang, Y.; Hauswald, J.; Cao, G.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative Intelligence between the Cloud and Mobile Edge. ACM Sigplan Not. 2017, 52, 615–629. [Google Scholar] [CrossRef] [Green Version]
- Paul, V.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar]
- Charles, B.S.; Wu, J.; Sun, J.; Mullin, M.D.; Rehg, J.M. On the design of cascades of boosted ensembles for face detection. Int. J. Comput. Vis. 2008, 77, 65–86. [Google Scholar]
- Pham, M.T.; Cham, T. Fast training and selection of haar features using statistics in boosting-based face detection. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–7. [Google Scholar]
- Liu, Y.; Tang, X.; Wu, X.; Han, J.; Liu, J.; Ding, E. Hambox: Delving into online high-quality anchors mining for detecting outer faces. arXiv 2019, arXiv:1912.09231. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual shot face detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5060–5069. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer vision(CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6569–6578. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. Faceboxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar]
- Veit, A.; Belongie, S. Convolutional networks with adaptive inference graphs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Zeng, L.; Li, E.; Zhou, Z.; Chen, X. Boomerang: On-demand cooperative deep neural network inference for edge intelligence on the industrial Internet of Things. IEEE Netw. 2019, 33, 96–103. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.S. Distributed deep neural networks over the cloud, the edge and end devices. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 328–339. [Google Scholar]
- Shao, J.; Zhang, H.; Mao, Y.; Zhang, J. Branchy-GNN: A device-edge co-inference framework for efficient point cloud processing. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8488–8492. [Google Scholar]
- Jiang, N.; Xiong, Z.; Tian, H.; Zhao, X.; Du, X.; Zhao, C.; Wang, J. PruneFaceDet: Pruning lightweight face detection network by sparsity training. Cogn. Comput. Syst. 2022. early view. [Google Scholar] [CrossRef]
- Zhao, X.; Liang, X.; Zhao, C.; Tang, M.; Wang, J. Real-time multi-scale face detector on embedded devices. Sensors 2019, 19, 2158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.; TPark, a.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Li, E.; Zhou, Z.; Chen, X. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy. In Proceedings of the 2018 Workshop on Mobile Edge Communications, Budapest, Hungary, 20 August 2018; pp. 31–36. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Vanholder, H. Efficient inference with tensorrt. GPU Technol. Conf. 2016, 1, 2. [Google Scholar]
- Boqueo, G.G.; Daya, L.I.O.; Eugenio, M.E.S.; Lumagas, A.G.; Guzman, F.E.D. Extensive assessment of various network interruption tools. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; pp. 463–467. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale-invariant face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Abdelatti, M.; Hendawi, A.; Sodhi, M. Optimizing a GPU-accelerated genetic algorithm for the vehicle routing problem. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Lille, France, 10–14 July 2021; pp. 117–118. [Google Scholar]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-millisecond neural face detection on mobile gpus. arXiv 2019, arXiv:1907.05047. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Cloud Server | NVIDIA JETSON NANO | PC |
|---|---|---|---|
| GPU | Two NVIDIA GeForce RTX 3090 | NVIDIA Maxwell w/128 | NVIDIA Geforce GTX 1060 |
| CPU | Intel(R) Xeon(R) silver 4210 CPU @ 2.20 GHz | quad-core ARM Cortex-A57 64-bit | Intel(R) Core (TM) i7-8750H CPU @ 2.20 GHz |
| Memory | 128 GB DDR4 | 4 GB LPDDR4 | 16 GB DDR4 |
| Pruning Strategy | Compression Ratio | AP_Easy | AP_Medium | AP_Hard | FLOPs/GMAC | Parameter/M |
|---|---|---|---|---|---|---|
| Backbone pruning | 1 | 83.635 | 79.481 | 79.481 | 40.15 | 15.815 |
| 0.80 | 83.682 | 79.995 | 56.332 | 56.332 | 11.341 | |
| 0.60 | 81.636 | 77.014 | 53.785 | 33.576 | 7.81 | |
| Deconvolution pruning | 1 | 83.635 | 79.481 | 54.748 | 40.15 | 15.815 |
| 0.80 | 83.709 | 80.031 | 56.518 | 26.96 | 10.145 | |
| 0.60 | 81.965 | 77.983 | 53.812 | 16.331 | 5.777 |
| Model | AP_Easy | AP_Medium | AP_Hard | FLOPs/GMAC | Parameter/M |
|---|---|---|---|---|---|
| PyramidBox | 92.6 | 92.0 | 86.2 | 236.58 | 57.18 |
| S3FD | 92.3 | 90.70 | 82.2 | 96.60 | 22.46 |
| SSH | 92.1 | 90.7 | 70.2 | 99.98 | 19.75 |
| Ours | 81.965 | 81.965 | 53.812 | 19.138 | 5.777 |
| Pruning Strategy | Compression Ratio | NO TRT Inference Delay | TRT Inference Delay | TRT Load Delay | Per Image Delay |
|---|---|---|---|---|---|
| Backbone pruning | 1 | 265.919 ms | 145.392 ms | 3287.6 ms | 2.496 ms |
| 0.80 | 251.741 ms | 140.882 ms | 3066.7 ms | 2.276 ms | |
| 0.60 | 242.892 ms | 135.738 ms | 2674.7 ms | 1.939 ms | |
| Deconvolution pruning | 1 | 265.919 ms | 145.392 ms | 3287.6 ms | 2.496 ms |
| 0.80 | 221.656 ms | 130.265 ms | 2817.5 ms | 1.955 ms | |
| 0.60 | 198.333 ms | 119.374 ms | 2563.9 ms | 1.451 ms |
| Pruning Strategy | Compression Ratio | 3 × 320 × 240 | 3 × 320 × 240 | 3 × 1280 × 720 |
|---|---|---|---|---|
| Backbone pruning | 1 | 1.514 ms | 2.657 ms | 4.728 ms |
| 0.80 | 1.252 ms | 2.387 ms | 4.417 ms | |
| 0.60 | 1.146 ms | 2.239 ms | 4.206 ms | |
| Deconvolution pruning | 1 | 1.514 ms | 2.657 ms | 4.728 ms |
| 0.80 | 1.071 ms | 2.279 ms | 3.810 ms | |
| 0.60 | 0.891 ms | 1.687 ms | 3.613 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Zhou, H.; Mo, J.; Zhen, C.; Ji, M. Accelerated Inference of Face Detection under Edge-Cloud Collaboration. Appl. Sci. 2022, 12, 8424. https://doi.org/10.3390/app12178424
Zhang W, Zhou H, Mo J, Zhen C, Ji M. Accelerated Inference of Face Detection under Edge-Cloud Collaboration. Applied Sciences. 2022; 12(17):8424. https://doi.org/10.3390/app12178424
Chicago/Turabian StyleZhang, Weiwei, Hongbo Zhou, Jian Mo, Chenghui Zhen, and Ming Ji. 2022. "Accelerated Inference of Face Detection under Edge-Cloud Collaboration" Applied Sciences 12, no. 17: 8424. https://doi.org/10.3390/app12178424