
GLFormer: Global and Local Context Aggregation Network for Temporal Action Detection

Abstract
:1. Introduction
- We design a tandem structure with window self-attention followed by a lightweight global attention module, which can not only establish long-range dependencies, but also effectively avoid the introduction of noise.
- We add a multi-scale local context branch parallel to the window self-attention, forming a dual-branch structure. This stems from our desire to simultaneously take into account local context, long-range dependencies, and global information, which can help adaptively capture temporal context for temporal action detection.
- We design a feature pyramid structure to be compatible with action instances of various durations. Moreover, our network enables end-to-end training and achieves state-of-the-art performance on two representative large-scale human activity datasets, namely THUMOS14 and ActivityNet 1.3.
2. Related Work
2.1. Action Recognition
2.2. Temporal Action Localization
2.3. Vision Transformer
3. Approach
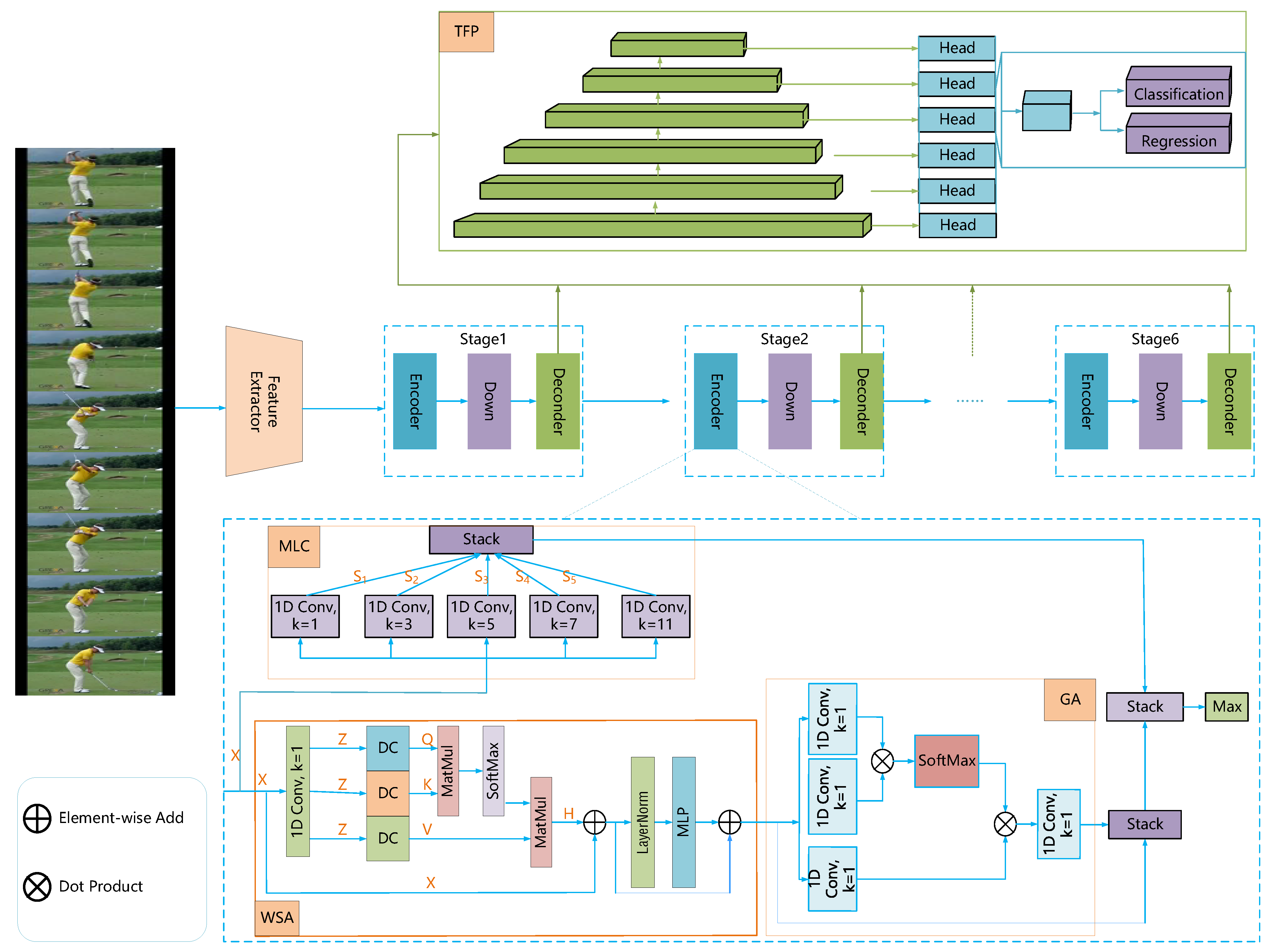
3.1. Overall Architecture
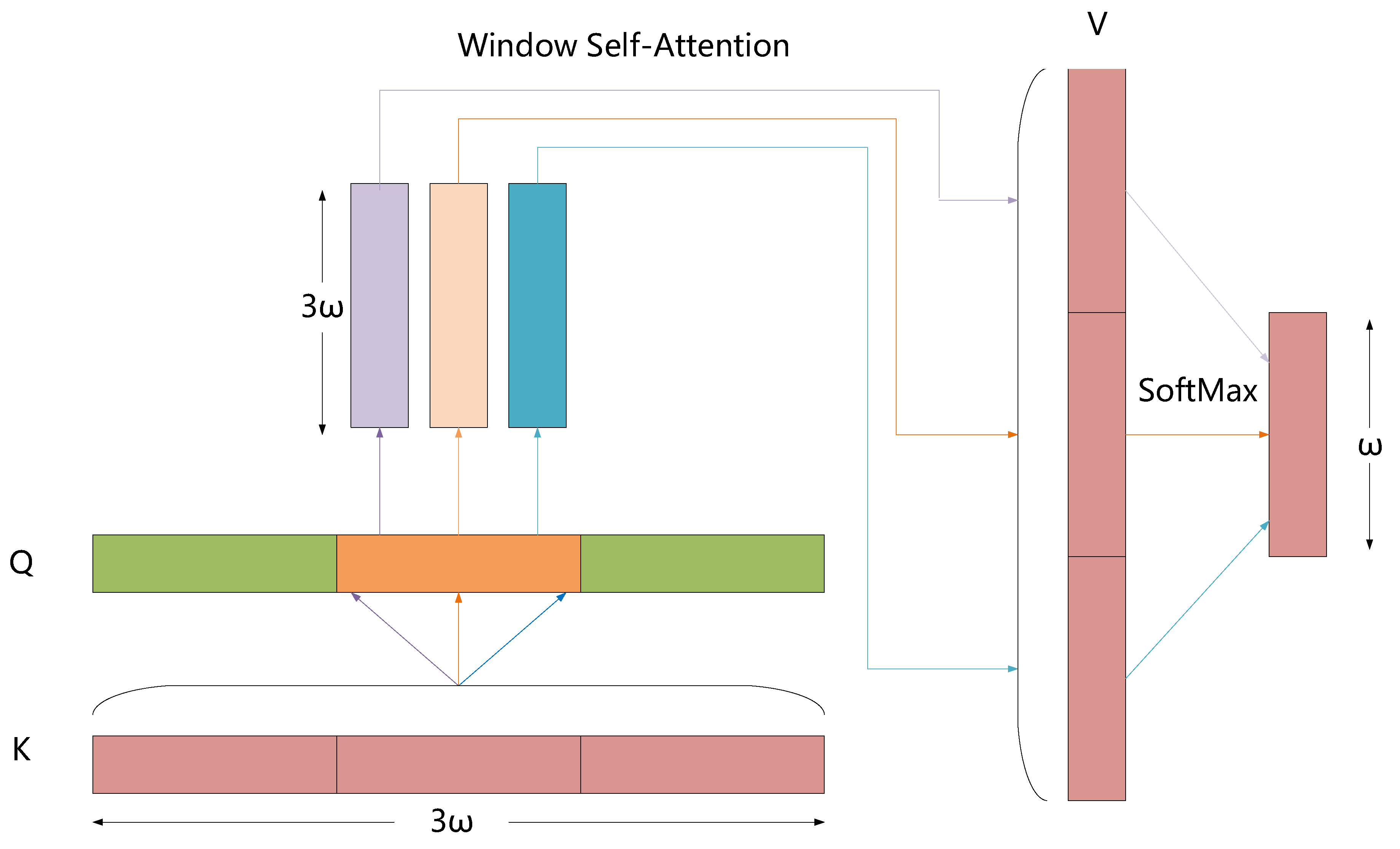
3.2. Window Self-Attention
3.3. Global Attention
3.4. Multi-Scale Local Convolution
3.5. Temporal Feature Pyramid
4. Training and Inference
4.1. Loss Function
4.2. Inference
5. Experiments
5.1. Datasets and Settings
5.2. Evaluation Metrics
5.3. Implementation Details
5.4. Comparison with State-of-the-Art Methods
6. Ablation Experiments
6.1. Effectiveness of WSA Module
6.2. Effectiveness of MLC Module
6.3. Effectiveness of GA Module
6.4. Module Complementarity
6.5. Temporal Feature Pyramid
6.6. Temporal Downsampling Module
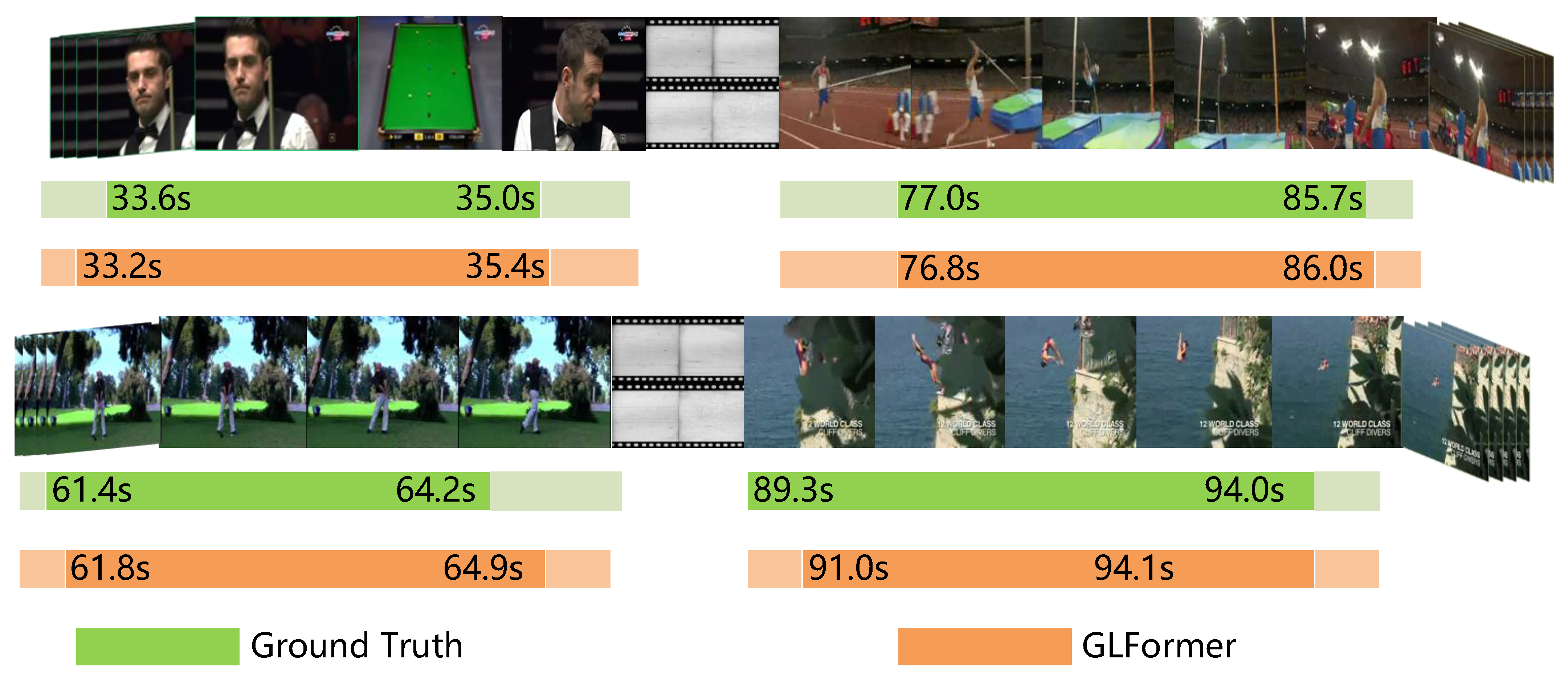
6.7. Visualization Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, R.; Tripathi, R.; Marchang, N.; Srivastava, G.; Gadekallu, T.R.; Xiong, N.N. A secured distributed detection system based on IPFS and blockchain for industrial image and video data security. J. Parallel Distrib. Comput. 2021, 152, 128–143. [Google Scholar] [CrossRef]
- Javed, A.R.; Jalil, Z.; Zehra, W.; Gadekallu, T.R.; Suh, D.Y.; Piran, M.J. A comprehensive survey on digital video forensics: Taxonomy, challenges, and future directions. Eng. Appl. Artif. Intell. 2021, 106, 104456. [Google Scholar] [CrossRef]
- Lin, T.; Zhao, X.; Shou, Z. Single shot temporal action detection. In Proceedings of the 25th ACM International Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 988–996. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5783–5792. [Google Scholar]
- Liu, Y.; Ma, L.; Zhang, Y.; Liu, W.; Chang, S.F. Multi-granularity generator for temporal action proposal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3604–3613. [Google Scholar]
- Yang, L.; Peng, H.; Zhang, D.; Fu, J.; Han, J. Revisiting anchor mechanisms for temporal action localization. IEEE Trans. Image Process. 2020, 29, 8535–8548. [Google Scholar] [CrossRef] [PubMed]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.F. Cdc: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5734–5743. [Google Scholar]
- Xiong, Y.; Zhao, Y.; Wang, L.; Lin, D.; Tang, X. A pursuit of temporal accuracy in general activity detection. arXiv 2017, arXiv:1703.02716. [Google Scholar]
- Yuan, Z.; Stroud, J.C.; Lu, T.; Deng, J. Temporal action localization by structured maximal sums. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3684–3692. [Google Scholar]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. Bsn: Boundary sensitive network for temporal action proposal generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3889–3898. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7094–7103. [Google Scholar]
- Su, H.; Gan, W.; Wu, W.; Qiao, Y.; Yan, J. Bsn++: Complementary boundary regressor with scale-balanced relation modeling for temporal action proposal generation. arXiv 2020, arXiv:2009.07641. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, X.; Wang, Q.; Hu, Y.; Tang, X.; Bai, S.; Bai, X. End-to-end temporal action detection with transformer. arXiv 2021, arXiv:2106.10271. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.; Tang, J.; Wang, L.; Wu, G. Relaxed transformer decoders for direct action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13526–13535. [Google Scholar]
- Zhang, C.; Wu, J.; Li, Y. ActionFormer: Localizing Moments of Actions with Transformers. arXiv 2022, arXiv:2202.07925. [Google Scholar]
- Idrees, H.; Zamir, A.R.; Jiang, Y.G.; Gorban, A.; Laptev, I.; Sukthankar, R.; Shah, M. The THUMOS challenge on action recognition for videos “in the wild”. Comput. Vis. Image Underst. 2017, 155, 1–23. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, B.; Wu, Z.; Yang, S.; Zhou, L.; Yan, S.; Wang, L.; Xiong, Y.; Lin, D.; Qiao, Y.; et al. Cuhk & ethz & siat submission to activitynet challenge 2017. arXiv 2017, arXiv:1710.08011. [Google Scholar]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1932–1939. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montréal, QC, Canada, 8 December 2014; pp. 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Nawhal, M.; Mori, G. Activity graph transformer for temporal action localization. arXiv 2021, arXiv:2101.08540. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the faster r-cnn architecture for temporal action localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1130–1139. [Google Scholar]
- Long, F.; Yao, T.; Qiu, Z.; Tian, X.; Luo, J.; Mei, T. Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 344–353. [Google Scholar]
- Liu, Q.; Wang, Z. Progressive boundary refinement network for temporal action detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11612–11619. [Google Scholar]
- Zhao, P.; Xie, L.; Ju, C.; Zhang, Y.; Wang, Y.; Tian, Q. Bottom-up temporal action localization with mutual regularization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 539–555. [Google Scholar]
- Lin, C.; Xu, C.; Luo, D.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Fu, Y. Learning salient boundary feature for anchor-free temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3320–3329. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T. On layer normalization in the transformer architecture. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 10524–10533. [Google Scholar]
- Zhang, P.; Dai, X.; Yang, J.; Xiao, B.; Yuan, L.; Zhang, L.; Gao, J. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2998–3008. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June-1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Alwassel, H.; Giancola, S.; Ghanem, B. Tsp: Temporally-sensitive pretraining of video encoders for localization tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3173–3183. [Google Scholar]
- Liu, X.; Hu, Y.; Bai, S.; Ding, F.; Bai, X.; Torr, P.H. Multi-shot temporal event localization: A benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12596–12606. [Google Scholar]
- Zhu, Z.; Tang, W.; Wang, L.; Zheng, N.; Hua, G. Enriching Local and Global Contexts for Temporal Action Localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13516–13525. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Xu, M.; Zhao, C.; Rojas, D.S.; Thabet, A.; Ghanem, B. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10156–10165. [Google Scholar]
- Bai, Y.; Wang, Y.; Tong, Y.; Yang, Y.; Liu, Q.; Liu, J. Boundary content graph neural network for temporal action proposal generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Sridhar, D.; Quader, N.; Muralidharan, S.; Li, Y.; Dai, P.; Lu, J. Class Semantics-based Attention for Action Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13739–13748. [Google Scholar]
- Li, Z.; Yao, L. Three Birds with One Stone: Multi-Task Temporal Action Detection via Recycling Temporal Annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4751–4760. [Google Scholar]
- Xia, K.; Wang, L.; Zhou, S.; Zheng, N.; Tang, W. Learning To Refactor Action and Co-Occurrence Features for Temporal Action Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 13884–13893. [Google Scholar]
- Yang, H.; Wu, W.; Wang, L.; Jin, S.; Xia, B.; Yao, H.; Huang, H. Temporal Action Proposal Generation with Background Constraint. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 3054–3062. [Google Scholar]
- Wang, Q.; Zhang, Y.; Zheng, Y.; Pan, P. RCL: Recurrent Continuous Localization for Temporal Action Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 13566–13575. [Google Scholar]
- Liu, X.; Bai, S.; Bai, X. An Empirical Study of End-to-End Temporal Action Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 20010–20019. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Characteristic | Ref. | Year | mAP@0.5 | Advantages | Limitations |
|---|---|---|---|---|---|
| Anchor-Based | RC3D [4] | ICCV-2017 | 28.9 | The method adopts the 3D fully convolutional network and proposalwise pooling to predict the class confidence and boundary offset for each pre-specified anchor. | These methods require pre-defined anchors, which are inflexible for action instances with varying durations. |
| TALNet [29] | CVPR-2018 | 42.8 | The method proposes dilated convolutions and a multi-tower network to align receptive fields. | ||
| GTAN [30] | CVPR-2019 | 38.8 | The method learns a set of Gaussian kernels to dynamically predict the duration of the candidate proposal. | ||
| PBRNet [31] | AAAI-2020 | 51.3 | The method uses three cascaded modules to refine the anchor boundary. | ||
| Bottom-up | BSN [10] | ECCV-2018 | 36.9 | The method predicts the probability of the start/end/action for each temporal location and then pairs the locations with higher scores to generate proposals. | These methods utilize the boundary probability to estimate the proposal quality, which are sensitive to noise and prone to local traps. |
| BMN [11] | ICCV-2019 | 38.8 | The method proposes an end-to-end framework to predict the candidate proposal and category scores simultaneously. | ||
| BUTAL [32] | ECCV-2020 | 45.4 | The method uses the potential relationship between boundary actionness and boundary probabilities to refine the start and end positions of action instances. | ||
| BSN++ [13] | AAAI-2021 | 41.3 | The method exploits proposal–proposal relation modeling and a novel boundary regressor to improve boundary precision. | ||
| Anchor-Free | MGG [5] | CVPR-2019 | 37.4 | The method combines two complementary generators with different granularities to generate proposals from fine (frame) and coarse (instance) perspectives, respectively. | These methods directly localize action instances without predefined anchors, thus lacking the guidance of prior knowledge, resulting in easily missed action instances. |
| A2Net [6] | TIP-20 | 45.5 | This method combines the anchor-free and anchor-based methods. | ||
| AFSD [33] | CVPR-2021 | 55.5 | The method uses contrastive learning and boundary pooling to refine candidate proposals’ boundary. | ||
| Actionr [18] | 2022 | 65.6 | This method introduces Transformer as the feature encoder. |
| Method | Year | Backbone | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg |
|---|---|---|---|---|---|---|---|---|
| SCNN [50] | CVPR16 | C3D | 36.3 | 28.7 | 19.0 | 10.3 | 5.3 | 19.9 |
| RC3D [2] | ICCV17 | C3D | 44.8 | 35.6 | 28.9 | - | - | - |
| SSAD [3] | ACM17 | TSN | 43.0 | 35.0 | 24.6 | - | - | - |
| TALNet [29] | CVPR18 | I3D | 53.2 | 48.5 | 42.8 | 33.8 | 20.8 | 39.8 |
| BSN [10] | ECCV18 | TSN | 53.5 | 45.0 | 36.9 | 28.4 | 20.0 | 36.8 |
| MGG [5] | CVPR19 | I3D | 53.9 | 46.8 | 37.4 | 29.5 | 21.3 | 37.8 |
| PGCN [12] | ICCV19 | I3D | 60.1 | 54.3 | 45.5 | 33.5 | 19.8 | 42.6 |
| BMN [11] | ICCV19 | TSN | 56.0 | 47.4 | 38.8 | 29.7 | 20.5 | 36.8 |
| A2Net [6] | TIP20 | I3D | 58.6 | 54.1 | 45.5 | 32.5 | 17.2 | 41.6 |
| GTAD [51] | CVPR20 | TSN | 54.5 | 47.6 | 40.2 | 30.8 | 23.4 | 39.3 |
| BCGNN [52] | ECCV20 | TSN | 57.1 | 49.1 | 40.4 | 31.2 | 23.1 | 40.2 |
| CSA [53] | ICCV21 | TSN | 64.4 | 58.0 | 49.2 | 38.2 | 27.8 | 47.5 |
| AFSD [33] | CVPR21 | I3D | 67.3 | 62.4 | 55.5 | 43.7 | 31.1 | 52.0 |
| ContextLoc [49] | ICCV21 | I3D | 68.3 | 63.8 | 54.3 | 41.8 | 26.2 | 50.9 |
| TBOS [54] | CVPR21 | C3D | 63.2 | 58.5 | 54.8 | 44.3 | 32.4 | 50.6 |
| RefactorNet [55] | CVPR2022 | I3D | 70.7 | 65.4 | 58.6 | 47.0 | 32.1 | 54.8 |
| ActionFormer [18] | 2022 | I3D | 75.5 | 72.5 | 65.6 | 56.6 | 42.7 | 62.6 |
| BCNet [56] | AAAI22 | I3D | 71.5 | 67.0 | 60.0 | 48.9 | 33.0 | 56.1 |
| RCL [57] | CVPR22 | TSN | 70.1 | 62.3 | 52.9 | 42.7 | 30.7 | 51.7 |
| AES [58] | CVPR22 | SF R50 | 69.4 | 64.3 | 56.0 | 46.4 | 34.9 | 54.2 |
| GLFormer(Ours) | I3D | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 |
| Method | Year | mAP@0.5 | mAP@0.75 | mAP@0.95 | mAP@avg |
|---|---|---|---|---|---|
| PGCN [12] | ICCV19 | 48.3 | 33.2 | 3.3 | 31.1 |
| BMN [11] | ICCV19 | 50.1 | 34.8 | 8.3 | 33.9 |
| PBRNet [31] | AAAI20 | 54.0 | 35.0 | 9.0 | 35.0 |
| GTAD [51] | CVPR20 | 50.4 | 34.6 | 9.0 | 34.1 |
| AFSD [33] | CVPR21 | 52.4 | 35.3 | 6.5 | 34.4 |
| ContextLoc [49] | ICCV21 | 56.0 | 35.2 | 3.6 | 34.2 |
| MUSES [48] | CVPR21 | 50.0 | 35.0 | 6.6 | 34.0 |
| ActionFormer [18] | 2022 | 53.5 | 36.2 | 8.2 | 35.6 |
| BCNet [56] | AAAI22 | 53.2 | 36.2 | 10.6 | 35.5 |
| RCL [57] | CVPR22 | 51.7 | 35.3 | 8.0 | 34.4 |
| AES [58] | CVPR22 | 50.1 | 35.8 | 10.5 | 35.1 |
| GLFormer(Ours) | 54.5 | 37.7 | 7.6 | 36.3 |
| Projection Method | Window Size | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg |
|---|---|---|---|---|---|---|---|
| Conv1D | 9 | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 |
| linear | 9 | 75.1 | 71.9 | 65.5 | 55.8 | 43.1 | 62.3 |
| Conv1D | 4 | 75.6 | 72.3 | 65.7 | 56.6 | 42.3 | 62.5 |
| Conv1D | 6 | 76.0 | 72.8 | 66.4 | 56.1 | 42.2 | 62.7 |
| Conv1D | 12 | 75.2 | 72.2 | 65.5 | 55.7 | 42.0 | 62.2 |
| Conv1D | 18 | 76.1 | 73.1 | 66.9 | 56.6 | 42.1 | 62.9 |
| Conv1D | full | 75.5 | 72.8 | 65.8 | 55.8 | 42.0 | 62.4 |
| Method | k = 1,3 | k = 5,7 | k = 9 | k = 11 | k = 13 | k = 15 | mAP@0.5 | mAP@avg |
|---|---|---|---|---|---|---|---|---|
| WSA + GA | 65.9 | 62.0 | ||||||
| WSA + GA + MLC | √ | 66.5 | 62.9 | |||||
| WSA + GA + MLC | √ | √ | 65.4 | 62.0 | ||||
| WSA + GA + MLC | √ | √ | √ | √ | 66.2 | 62.3 | ||
| WSA + GA + MLC | √ | √ | √ | 65.6 | 62.0 | |||
| WSA + GA + MLC | √ | √ | √ | 67.2 | 62.9 | |||
| WSA + GA + MLC | √ | √ | √ | 65.6 | 62.1 | |||
| WSA + GA + MLC | √ | √ | √ | 65.3 | 62.2 |
| Method | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg |
|---|---|---|---|---|---|---|
| WSA + MLC | 75.4 | 72.5 | 66.1 | 56.0 | 42.1 | 62.4 |
| WSA + MLC + GA | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 |
| WSA + MLC + 2GA | 75.3 | 72.1 | 66.0 | 56.2 | 43.0 | 62.5 |
| WSA + MLC + 3GA | 75.4 | 72.5 | 66.1 | 56.3 | 42.8 | 62.6 |
| Method | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg |
|---|---|---|---|---|---|---|
| WSA | 75.5 | 72.4 | 65.8 | 56.0 | 41.4 | 62.2 |
| WSA + GA | 75.4 | 72.0 | 65.9 | 55.3 | 41.1 | 62.3 |
| WSA + MLC | 75.4 | 72.5 | 66.1 | 56.0 | 42.1 | 62.4 |
| WSA + MLC + GA | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 |
| Levels | Channels | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| 4 | 1024 | 74.1 | 69.7 | 61.3 | 50.2 | 36.5 | 58.4 | 37.5 |
| 5 | 1024 | 74.2 | 71.2 | 63.9 | 53.8 | 38.8 | 60.4 | 38.3 |
| 6 | 1024 | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 | 38.8 |
| 7 | 1024 | 75.4 | 72.0 | 65.9 | 55.3 | 41.9 | 62.1 | 39.0 |
| 6 | 256 | 75.2 | 72.4 | 65.0 | 55.1 | 42.7 | 60.1 | 33.9 |
| 6 | 512 | 75.1 | 71.6 | 65.6 | 56.1 | 42.6 | 62.2 | 35.2 |
| 6 | 2048 | 75.7 | 72.4 | 66.0 | 56.1 | 42.5 | 62.5 | 50.2 |
| 6 | 4096 | 75.1 | 72.3 | 65.6 | 55.0 | 42.5 | 62.1 | 90.2 |
| Method | mAP@0.3 | mAP@0.4 | mAP@0.5 | mAP@0.6 | mAP@0.7 | mAP@avg |
|---|---|---|---|---|---|---|
| Max pooling | 75.7 | 72.3 | 66.3 | 57.3 | 43.1 | 62.9 |
| Avg pooling | 75.5 | 72.0 | 66.0 | 55.6 | 42.1 | 62.3 |
| stride = 2 | 75.9 | 72.6 | 67.2 | 57.2 | 41.8 | 62.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Zhong, Y.; Wang, L.; Dang, J. GLFormer: Global and Local Context Aggregation Network for Temporal Action Detection. Appl. Sci. 2022, 12, 8557. https://doi.org/10.3390/app12178557
He Y, Zhong Y, Wang L, Dang J. GLFormer: Global and Local Context Aggregation Network for Temporal Action Detection. Applied Sciences. 2022; 12(17):8557. https://doi.org/10.3390/app12178557
Chicago/Turabian StyleHe, Yilong, Yong Zhong, Lishun Wang, and Jiachen Dang. 2022. "GLFormer: Global and Local Context Aggregation Network for Temporal Action Detection" Applied Sciences 12, no. 17: 8557. https://doi.org/10.3390/app12178557
APA StyleHe, Y., Zhong, Y., Wang, L., & Dang, J. (2022). GLFormer: Global and Local Context Aggregation Network for Temporal Action Detection. Applied Sciences, 12(17), 8557. https://doi.org/10.3390/app12178557