1. Introduction
With the advent of big data, network information has been facing an increasing number of security threats. Although the rapid development of communication networks makes the information exchange and data transmission between users more convenient, it brings the risk of various attacks on users’ private data. It should be noted that once a network is malfunctioned by unknown attacks, malicious leakage and illegal use of important information can easily occur, resulting in enormous losses [
1]. Therefore, how to predict and deal with network attacks timely and effectively has always been a research hotspot in the network security field. In the view of network security, the concept of intrusion detection was first proposed by Anderson in 1980 [
2], and then many detection models represented by intrusion detection expert systems [
3] were developed. These models monitor the network operation status using certain software and hardware selected according to security policies and detect as many intrusions as possible to prevent damage to the network and data. Network intrusion detection, as a proactive security protection technology that aims to intercept and respond to intrusions before the network system is compromised, has received extensive attention worldwide. Traditional intrusion detection methods include misuse detection and anomaly detection. Misuse detection finds anomalous links in a network by establishing an intrusion rule base. Although this method has a high accuracy rate, it is often ineffective for new types of intrusions and old virus variant connections [
4]. Anomaly detection is used in network anomaly analysis by summarizing the characteristics of normal network connections, and this method has gained widespread attention because it has a good detection effect for new types of attacks [
5]. However, due to increasingly complex network environments, the defects of both misuse- and anomaly-based intrusion detection systems, such as high resource consumption, slow detection speed, and the need for manual intervention, have been increasingly prominent. It should be noted that when anomalous access or connection events are detected and handled, many severe consequences may have already occurred. Therefore, efficient and fast intrusion detection has been an extremely challenging task [
6].
Currently, many machine learning models, including discriminant analysis (DA) [
7], the
K-nearest neighbor (KNN) algorithm [
8], decision tree (DT) [
9], naive Bayes (NB) [
10], logistic regression (LR) [
11], and support vector machine (SVM) [
12], have been widely used in intrusion detection. First, historical access data are extracted from a database, where each historical access data sample contains certain information about accesses, such as access duration and usage of transmission control protocol (TCP) or user datagram protocol (UDP). Then, these data are labeled to mark normal and abnormal accesses, and finally, are used as training data for a machine learning algorithm. Training of supervised machine learning algorithms results in a classification model for intrusion detection and prediction of unknown accesses. Machine learning-based intrusion detection methods can have both advantages and disadvantages depending on a selected learner (classifier) [
13]. In general, complex classifiers require a relatively long time to train and are time-consuming, while simple learners, although efficient in processing, may be difficult to ensure effective detection for network attacks with a mixture of multiple features and complex and variable intrusion methods.
Some studies have aimed to improve detection performance by combining multiple learners, and intrusion detection methods based on ensemble learning have received extensive attention in recent years [
14]. Ensemble learning algorithms can improve the overall algorithm generalization capability by combining multiple base learners. Theoretically, intrusion detection based on ensemble learning is much better for the identification of unknown network attacks than intrusion detection methods based on a single learner. In ensemble learning, the early boosting algorithm was first used for practical applications by Schapire in 1993 [
15]. The early boosting algorithm combines multiple weak learners into one strong learner. Subsequently, Freund and Schapire proposed an improved boosting algorithm named the Adaboost (i.e., adaptive boosting) in 1995 [
16]. The Adaboost algorithm is efficient and has been widely used in practice. The bagging algorithm was first proposed by Breiman in 1996 [
17] to improve the accuracy and stability of the computing while avoiding overfitting by reducing the variance of results. However, both boosting and bagging algorithms are homologous assemble, namely, the base learners use models with the same structure. In multi-classification scenarios, due to the differences in design principles and actual performances of different models, using models with the same structure will inevitably result in different detection rates for different types of data. To solve the problem that a homogeneous ensemble cannot overcome the low detection rate for certain data types using the same structural model, the SE algorithm has been proposed as a heterogeneous ensemble algorithm to improve the detection rate of all data types comprehensively [
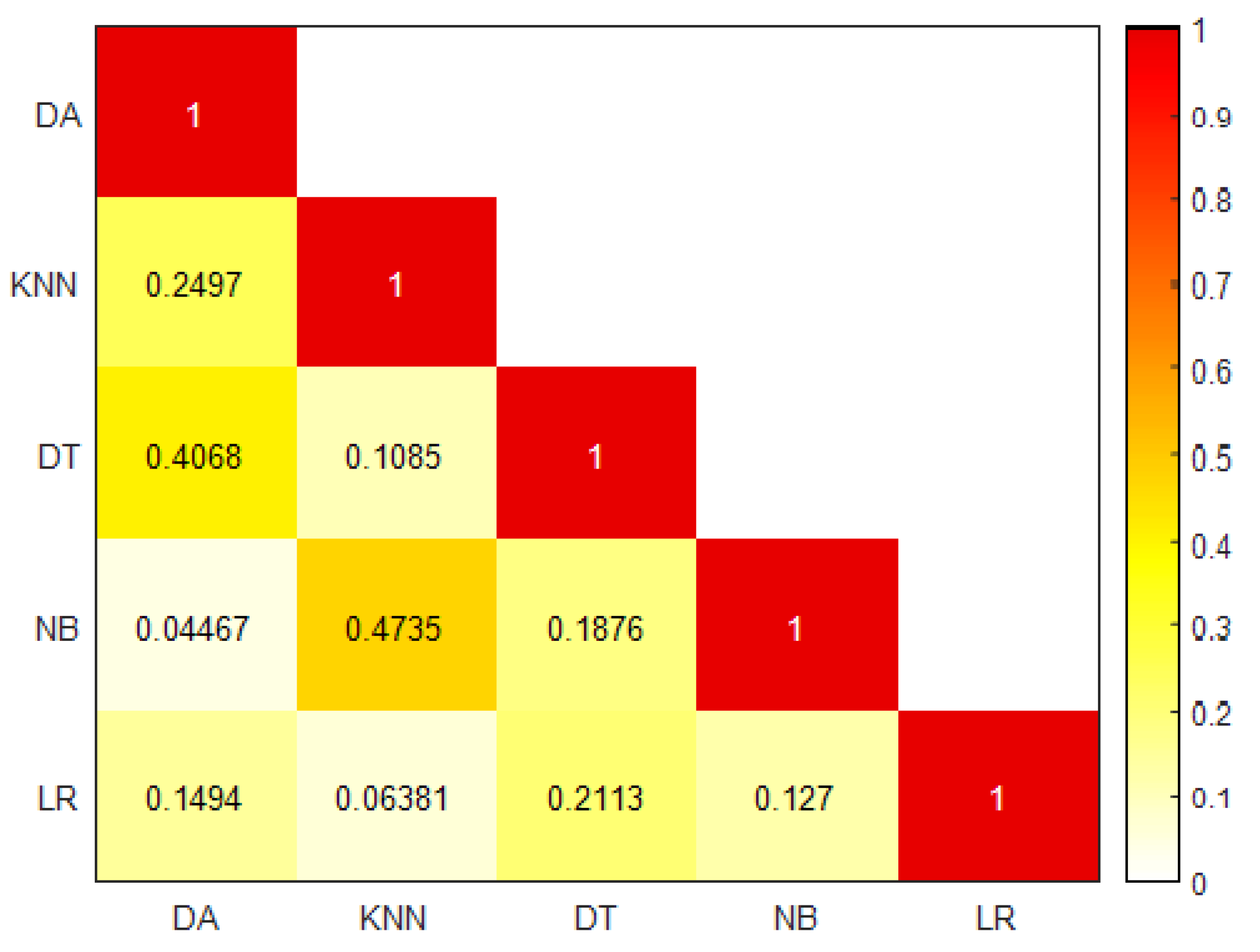
18]. The SE method tends to combine the advantages of different base classifiers through a certain strategy to improve classification efficiency.
The cyberspace data stream contains a large amount of temporal, spatial, load, and statistical data [
19], and it may also contain some incomplete or redundant information that may affect the data analysis process and results. Therefore, anomaly detection models based on full data features cannot capture anomalous information hidden in local data features. However, data analysis from different dimensions and perspectives can provide certain contributions and support to anomaly detection and analysis results. Commonly, the analysis implies a mutually supportive and complementary relationship between basic features of different dimensions [
20]. Nonetheless, anomalies are usually manifested in multiple basic feature data, so a comprehensive feature dataset is required. Feature fusion is based on effective feature extraction of the original data, and deep learning has been successfully applied to the field of feature extraction [
21]. Convolutional neural networks (CNNs) [
22,
23] denote deep learning-based models with a convolutional structure, which have been mainly used in the fields of computer vision and natural language processing. CNN-based methods for feature extraction generally use a single-scale single-type convolution kernel to extract target features, which may bring the problem of incomplete and inaccurate details of the extracted features [
24].
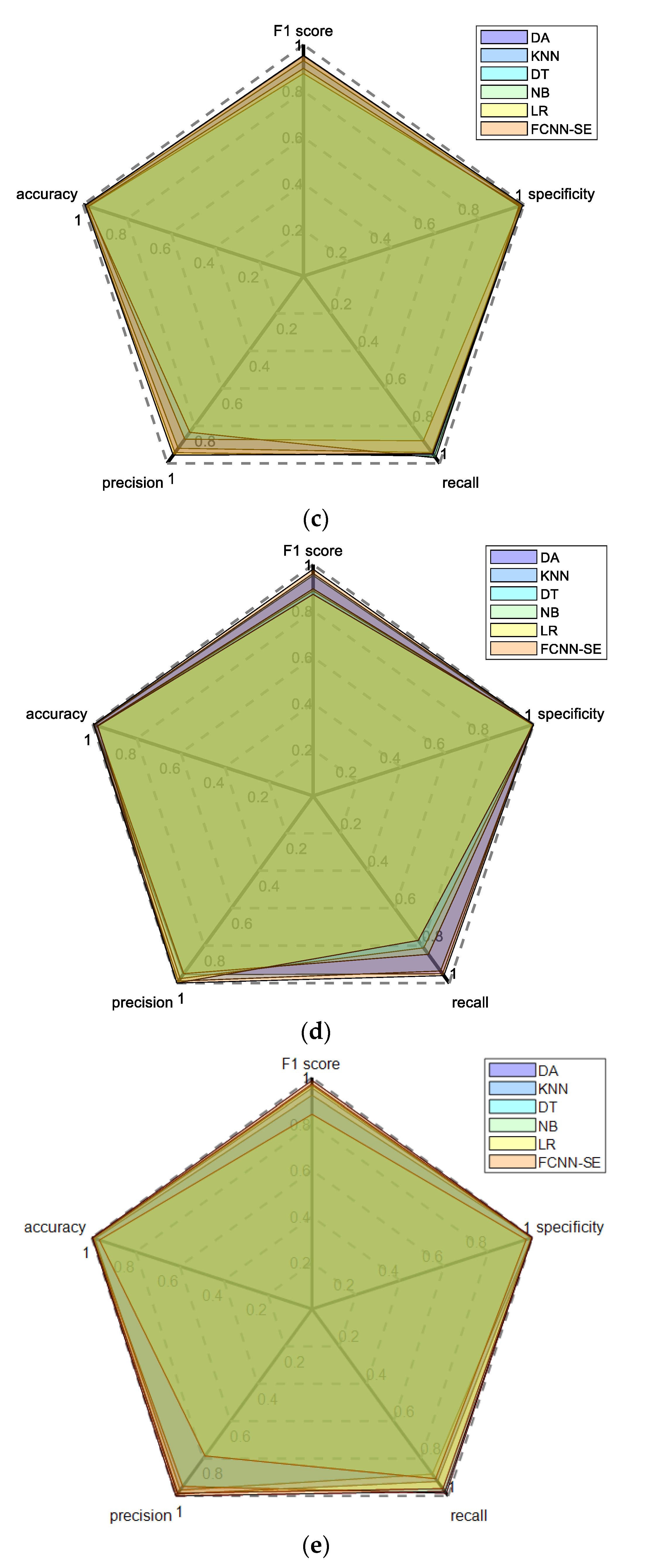
With the in-depth research on intrusion detection, an increasing number of models have been proposed to solve the intrusion detection problem; there are certain performance differences between these models. Currently, in the evaluation of the intrusion detection model performance, several evaluation metrics, including accuracy, precision, recall, specificity, and F1 score, have been mainly used to evaluate the model performance [
25,
26,
27]. However, the evaluation results may not be unique due to the inconsistency in evaluation metrics used in the comparative experiments. Additionally, a single-metric evaluation cannot fully reflect the comprehensive performance of a model. Commonly used comprehensive evaluation methods can be roughly classified into expert evaluation methods, economic analysis methods, operational research methods, mathematical and statistical methods, and radar chart methods. The radar chart methods denote common graphical methods for displaying multiple variables [
28], which can map a multi-dimensional space point to a two-dimensional space and can evaluate each evaluation object qualitatively. In addition, these methods can construct specific evaluation vector and function by extracting the feature vector of a radar plot and then use the evaluation function magnitude to realize a comprehensive evaluation of the selected evaluation object [
29]. The main advantages of these methods are that they are intuitive, visual, and easy to operate. They denote typical graphical evaluation methods with a wide range of engineering applications.
The specific contributions of this paper are as follows:
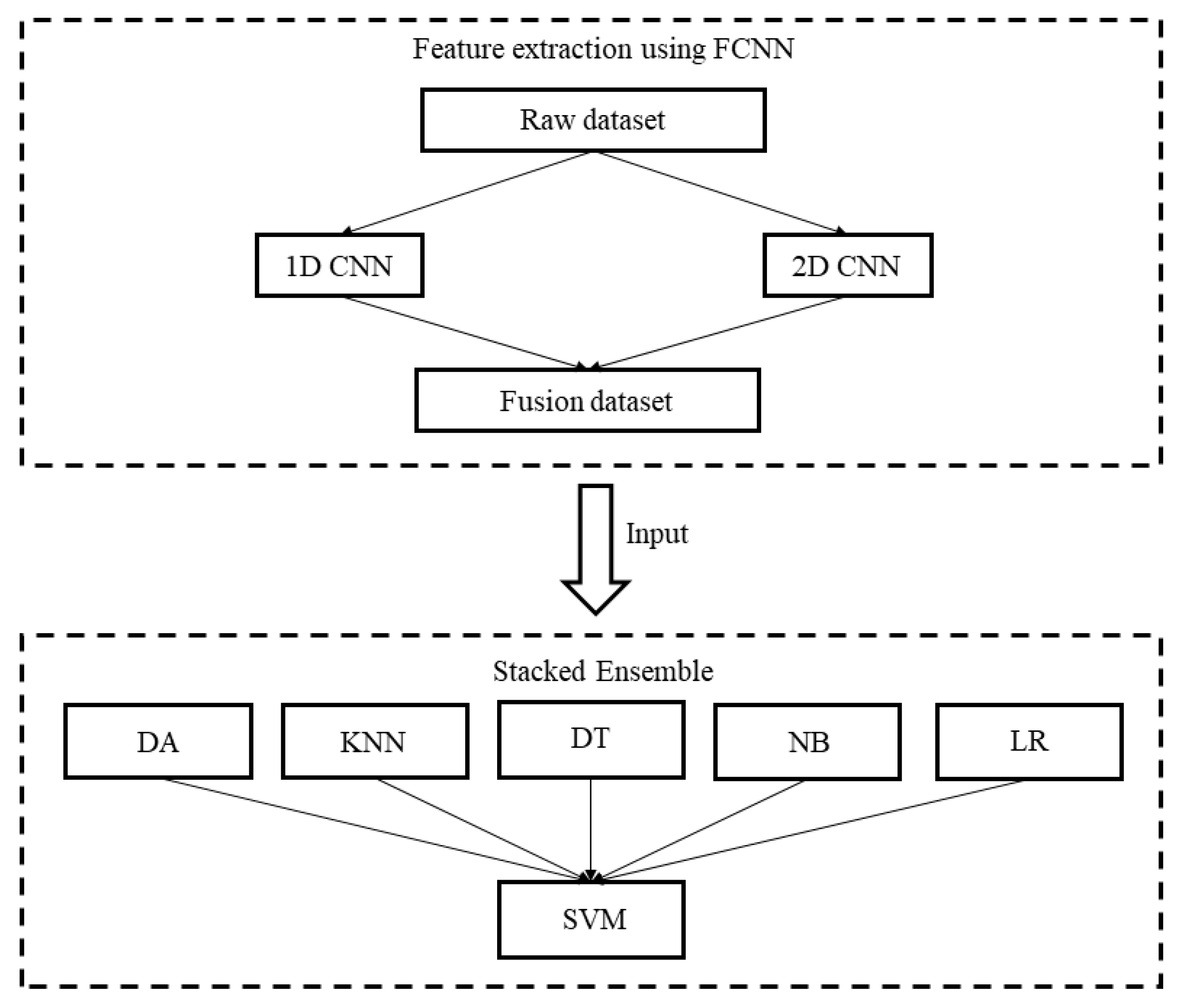
A feature extraction method, which uses the fusion CNN (FCNN) to fuse 1DCNN and 2DCNN, which is then used to extract features of the NSL-KDD dataset to generate a network traffic dataset, is proposed. The FCNN can ensure that low- and high-dimensional feature information is extracted simultaneously from the original dataset, and the generated feature set can characterize the specific attack mode comprehensively and in detail.
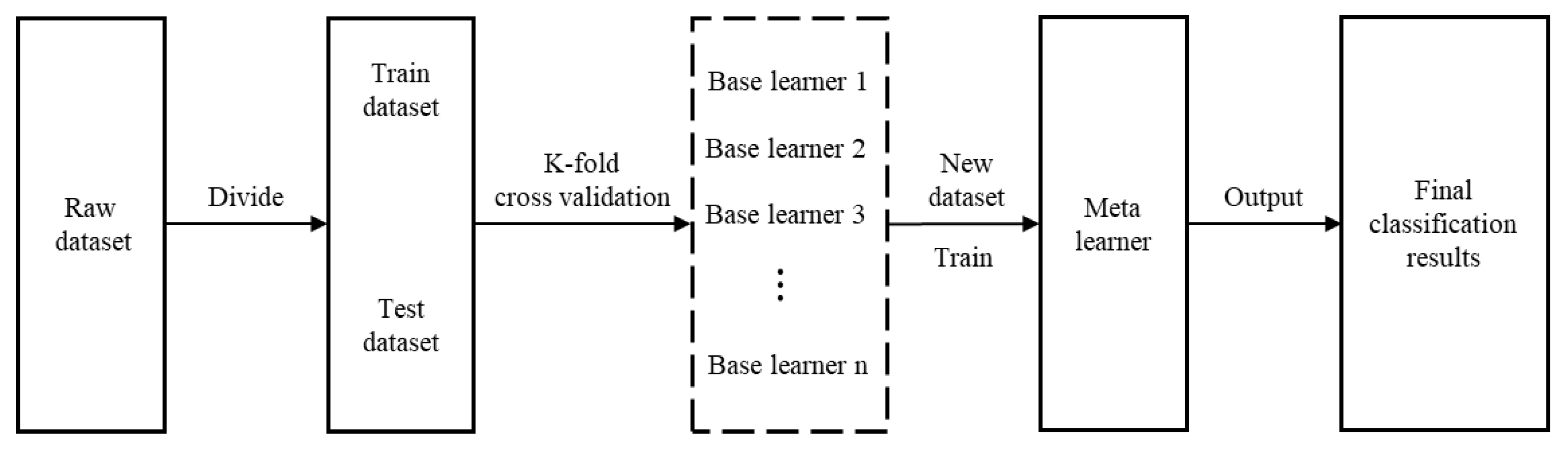
An innovative classification model based on the SE, with a heterogeneous learner as a base learner and an SVM as the meta-learner, is proposed for intrusion detection. Detailed simulation experiments and analyses are conducted to verify the proposed model;
A comprehensive performance evaluation index based on the radar chart method, which can achieve a comprehensive evaluation of comprehensive performance, is designed and used as an evaluation index of the intrusion detection model.
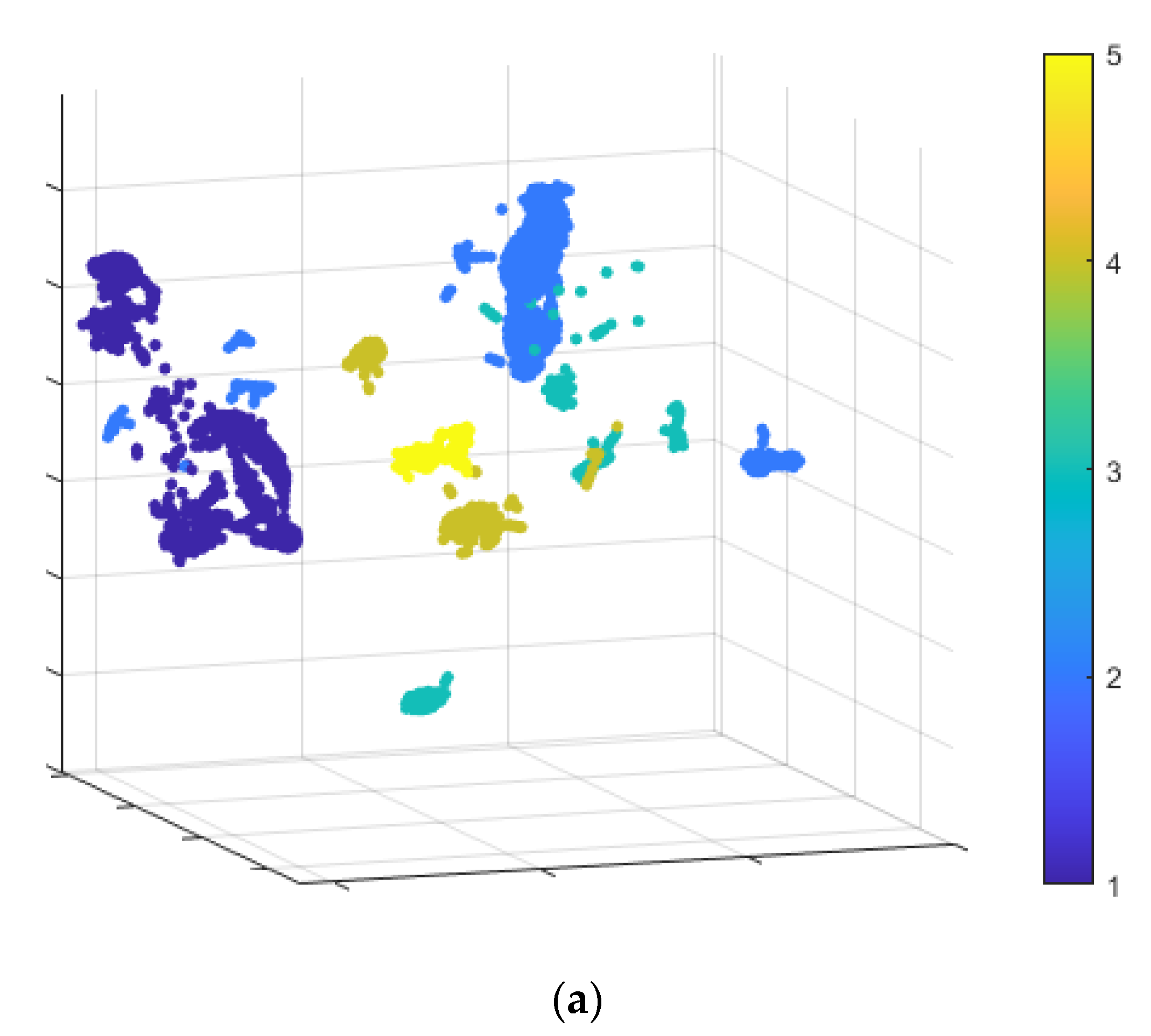
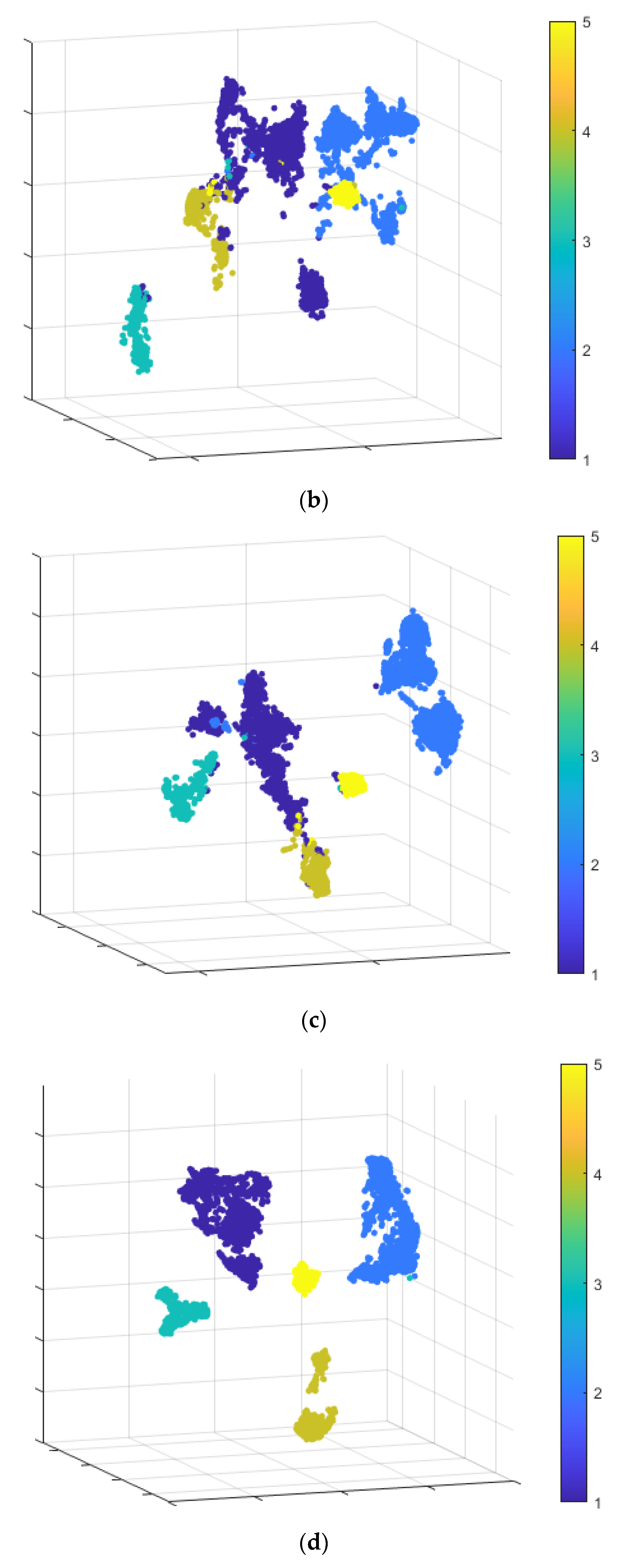
An ablation study, which illustrates the effect of feature extraction using CNNs of different dimensions on data distribution, is conducted.
The rest of this paper is structured as follows.
Section 2 discusses the related work.
Section 3 describes the proposed method.
Section 4 conducts simulation experiments and results analysis. Finally,
Section 5 presents the research conclusions.
2. Related Work
A well-performing intrusion detection model must be able to perform self-learning, self-adaptation, and eventually alarm various connection violations at high speed and low false alarm rate and missing rate. In recent years, network intrusion detection methods based on machine learning have received extensive attention due to their strong self-adaptability performance and high intelligence [
30]. Machine learning-based network intrusion detection aims to transform the network intrusion detection problem into the pattern recognition (classification) problem. Zheng et al. [
31] combined the DA with an extreme learning machine to classify dimensionality-reduced data using an extreme learning machine with a single hidden layer under the premise of reducing the feature size. They simplified the classification model structure and achieved an accuracy of 92.35% on the NSL-KDD dataset. Labiod et al. [
32] proposed an intrusion detection model, which combines fog computing combing variational autoencoders and multilayer perceptrons, to develop an efficient distributed lightweight intrusion detection system. This system adopts a two-layer fog architecture with anomaly detectors inside the fog nodes and attack recognition modules in the cloud and thus can accurately characterize the normal behavior inside the fog nodes and detect different types of attacks, such as DDoS attacks. Saba et al. [
33] reduced the information component of CNN by sharing parameters, equivariant representations, and sparse connections, as well as links between the layers, thus extending the scalability and reducing the training time. Yu et al. [
34] designed a multi-scale CNN model with multiple convolutional layers, where multi-scale convolutional layers and two convolutional layers were added and connected to the pooling layer through a multi-scale convolutional layer, and finally, to the softmax classifier through three fully connected layers. Although these approaches can provide the desired performance, it is difficult for an intrusion detection system composed of a single model to realize effective monitoring and processing, so the intrusion detection systems can scarcely meet the requirements of integrity and parallelism at the same time.
To address this problem, various ensemble learning-based models have been proposed to solve the intrusion detection problem. Wu et al. [
35] used the RVMs as base learners, determined voting weights for each RVM base learner dynamically, and obtained the final ensemble model classification results using the voting mechanism. This model has certain advantages in terms of the time cost and storage space. Mokbal et al. [
36] extracted an effective subset of features using an embedded feature selection method, which focuses on extracting features that can be computed rapidly and correctly using a relative importance approach. This method analytically selects the best features that can represent all attacks uniformly and comprehensively rather than selecting features for each attack separately. Finally, extreme gradient boosting was used to perform intrusion detection on the feature subset, which improved the detection accuracy. Alanazi et al. [
37] used four machine learning techniques, namely, the decision tree, extra tree, random forest, and XGBoost, to select the best features independently; features that obtained high scores were added to the best feature set, and then the best feature set’s features were classified by the ensemble classifier that combines multiple decision trees. This method can select the best unique features and eliminate unnecessary features, providing effective and efficient feature detection. The above-mentioned models can improve the overall detection accuracy by combining multiple homologous algorithms, but homologous model-based ensemble suffers from the problems of a model’s overfitting and insufficient generalization ability.
To improve the intrusion detection accuracy further while improving the classification performance, a large number of methods for feature selection and optimization have been proposed and verified on different datasets. Prasad et al. [
38] proposed a feature selection method based on multilevel correlation, which selects important features and reduces the training set size based on the multilevel correlation between the features; the verification results have indicated that this method can successfully improve detection capability. Patil et al. [
39] used feature selection methods, such as relevance-based feature subset selection, chi-square attribute evaluation, gain ratio attribute evaluation, and information gain attribute evaluation, to improve the data quality. The results have indicated that by adopting a feature selection strategy, considerable acceptable attack detection accuracy can be obtained at minimal system overhead. Quincozes et al. [
40] designed a feature extraction method named the GRASP-FS, which uses the F1 score as a fitness function for adapting the greedy random adaptive search process (GRASP) meta-heuristic. The experiments on the SWaT dataset showed that the GRASP-FS constructed a simplified subset of five features from 51 available features and used random trees as classifiers, achieving the F1 score and accuracy of 96.97% and a 99.65%, respectively.
All the above-mentioned feature extraction methods can reduce the feature space size of the original dataset and improve the detection performance of a classifier to a certain extent. However, high-dimensional feature information cannot be extracted from a dataset using feature extraction methods that only reduce the feature space size.
Recently, a large number of evaluation metrics based on statistical principles have been applied in the field of intrusion detection to evaluate the performances of intrusion detection systems. Prakash et al. [
41] used the DT, LR, KNN, SVM, and Bi-LSTM as base learners and adopted the voting mechanism for classification. The weights of all base learners were optimized using a hybrid approach of particle swarm optimization and a modified salps swarm algorithm. The proposed ensemble classifier achieved good performances in terms of accuracy rate, attack detection rate, and false alarm rate. Babu et al. [
42] proposed a bat-inspired optimization and correlation-based feature selection (BIOCFS) algorithm, which can estimate the correlation between identified features and select optimal subsets for the training and testing phases. In the BIOCFS algorithm, the base learner in the ensemble classifier uses the forest by penalizing attributes, random forest, and C4.5. The BIOCFS algorithm has an excellent performance in handling multiclassification and unbalanced datasets. On the NSL-KDD dataset, the BIOCFS algorithm can achieve a maximum classification accuracy, precision, F1 score, and attack detection ratio of 0.994, 0.993, 0.992, and 0.992, respectively, and the minimum false alarm rate of 0.008%. Niu et al. [
43] proposed a multi-granularity feature generation algorithm, which converts features into discrete features with different numbers of classes, where different numbers of classes indicate different granularities. On the KDD99 dataset, the multi-granularity feature generation algorithm can achieve the detection rates of 100%, 100%, and 99.43% for two-, five-, and multi-class tasks, respectively; on the NSL-KDD dataset, this algorithm can achieve the detection rates of 100%, 100%, and 90.84% for the two-, five-, and multi-class tasks, respectively. All aforementioned intrusion detection models can achieve excellent detection results, but their comprehensive performance cannot be fully evaluated using a single evaluation metric.
In this paper, an intrusion detection model (FCNN-SE) based on the FCNN and SE, which can effectively detect attacks in networks with a high traffic data rate, is proposed. The proposed model divides network data into two parts that are input to the FCNN at the same time; one part denotes one-dimensional data that are input directly into the FCNN, and the other part is the remaining data that are first converted into a two-dimensional matrix and then input into the FCNN. The feature information obtained from the two-dimensional CNN is fused in the aggregation layer to obtain a new dataset. The set of heterogeneous base learners is combined into an ensemble classifier SE, and the new dataset is input to SE for classification to ensure accurate detection of different attack types.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






