
Continual Learning for Table Detection in Document Images
 ,
,  ,
, 
Abstract
:1. Introduction
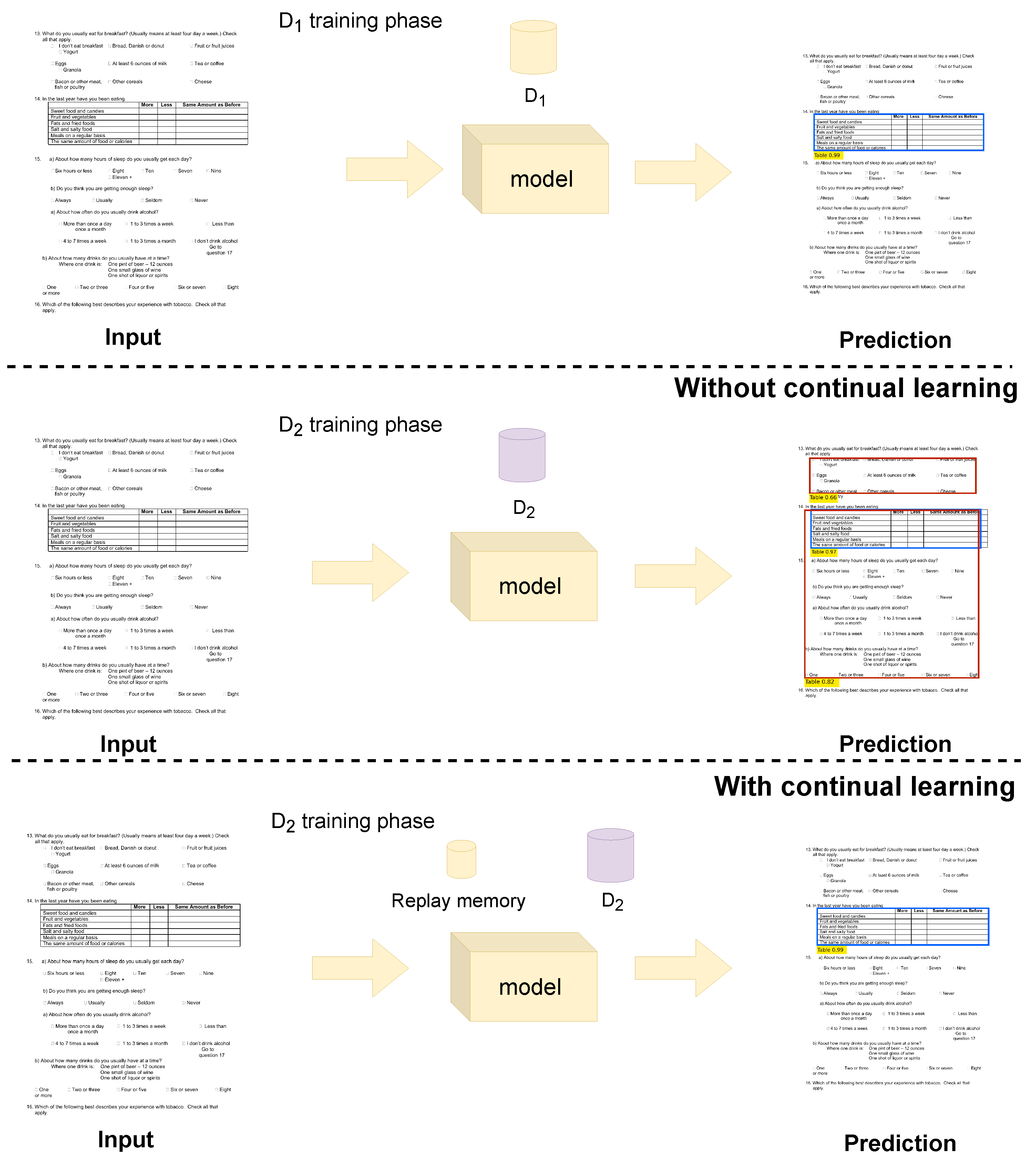
- To the best of our knowledge, this work is the first attempt to incorporate a continual learning-based method for table detection.
- Extensive experiments are conducted on considerably large datasets with more than 900 K images combined.
- The presented method is able to reduce the forgetting effect by a 15 percent margin.
2. Related Work
2.1. Rule-Based Table Detection
2.2. Table Detection with Deep Neural Networks
2.3. Applications of Continual Learning
3. Experimental Setup
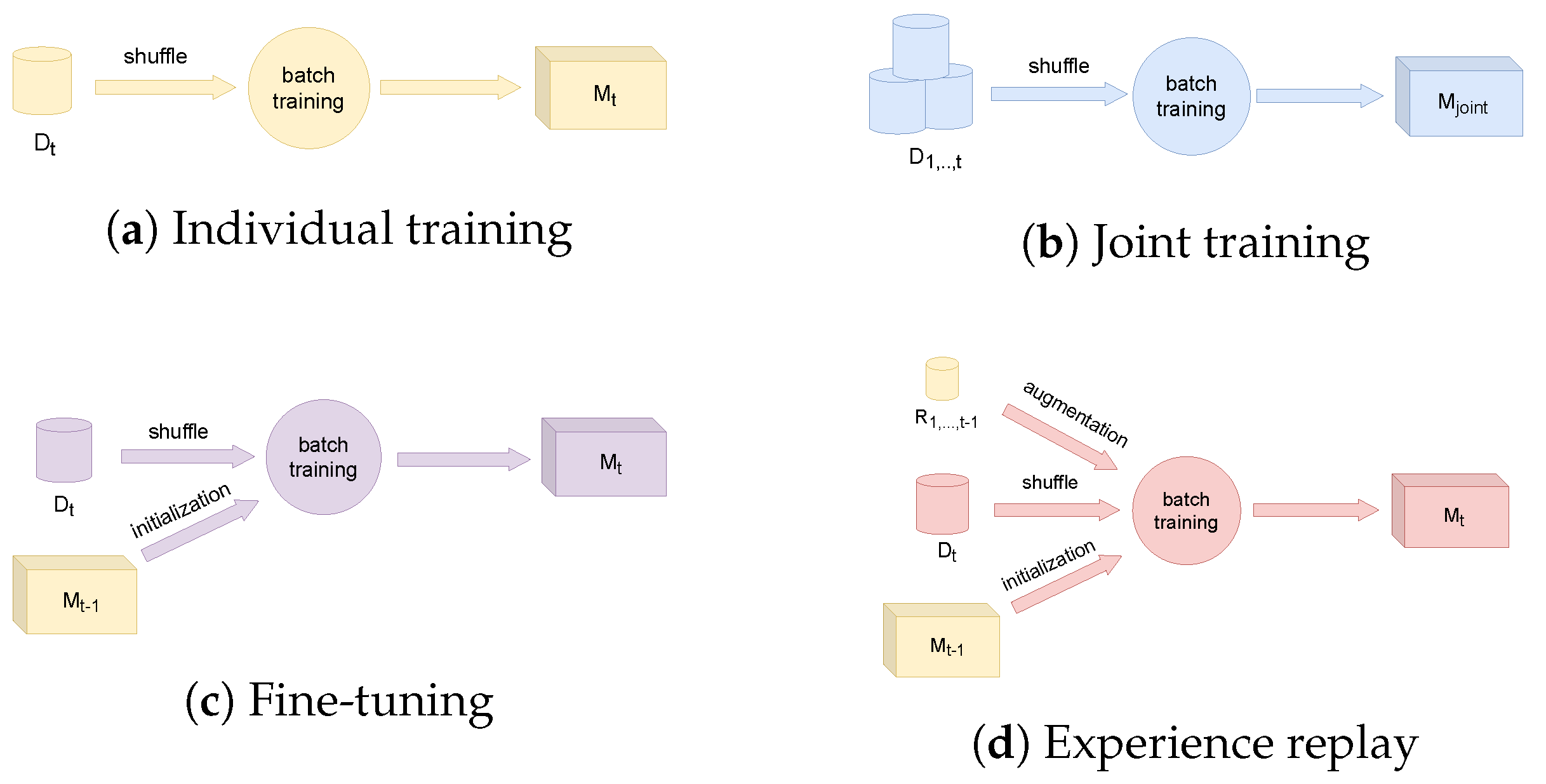
3.1. Independent Training
3.2. Joint Training
3.3. Fine-Tuning
3.4. Training with Experience Replay
| Algorithm 1: Batch training. |
| Require: Learning rate: Require: Initial weights from ImageNet inputs: dataset , batch size functionBatchTraining() for each iteration do ▹ sample a mini-batch from ▹ compute the gradient for the current batch, B ▹ update the current weights end for end function |
| Algorithm 2: Batch training with Experience replay. |
| Require: Formerly trained model Require: Learning rate: inputs: array of prior datasets , new dataset , batch size , and memory sample size functionBatchTrainingWithReplay() ▹ allocate samples from previous datasets for each iteration do ▹ sample a mini-batch from ▹ sample a mini-batch from the memory ▹ stack two minibatches and compute the gradient ▹ update the current weights end for end function |
3.5. Networks
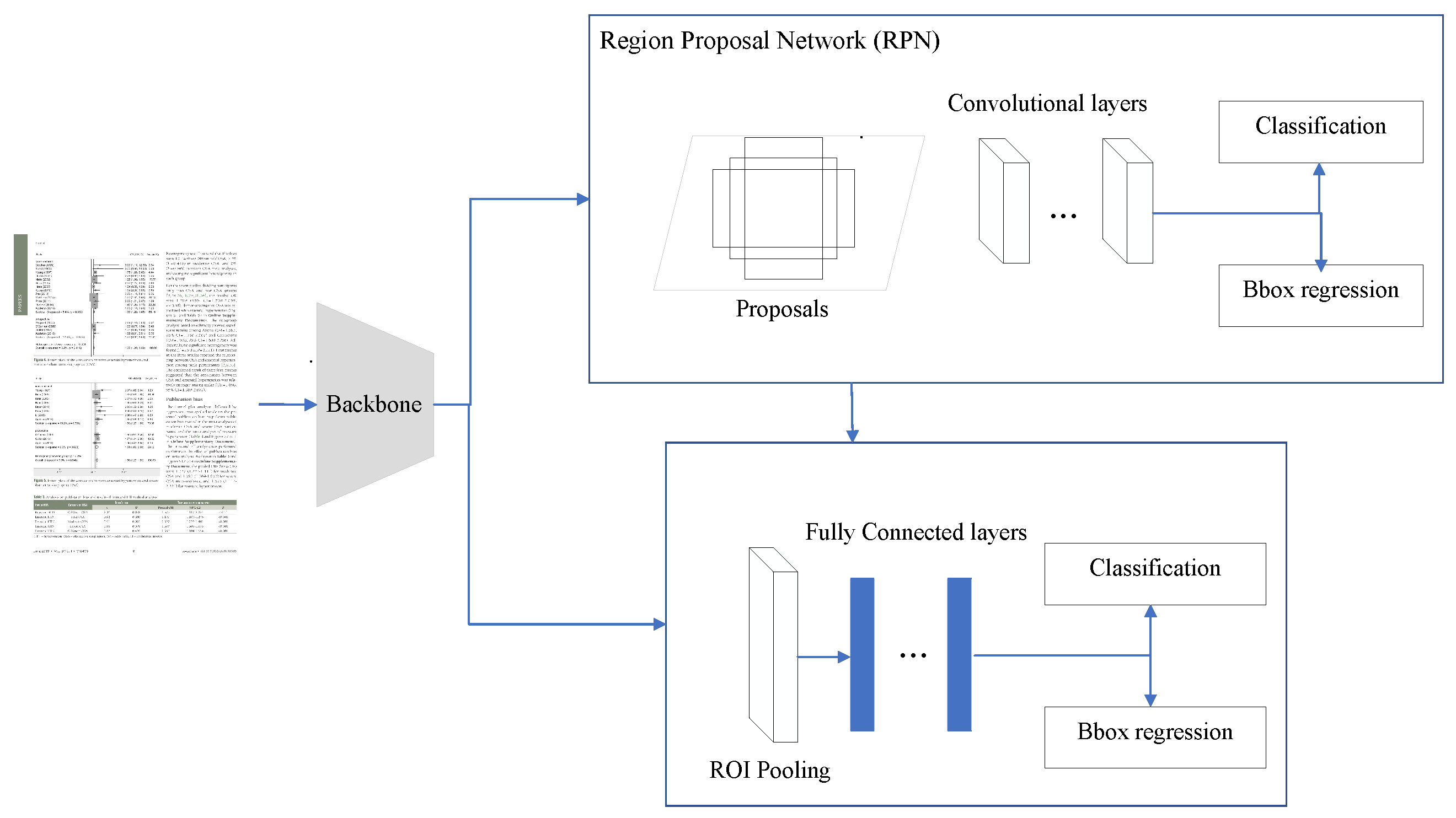
3.5.1. Faster R-CNN+ResNet
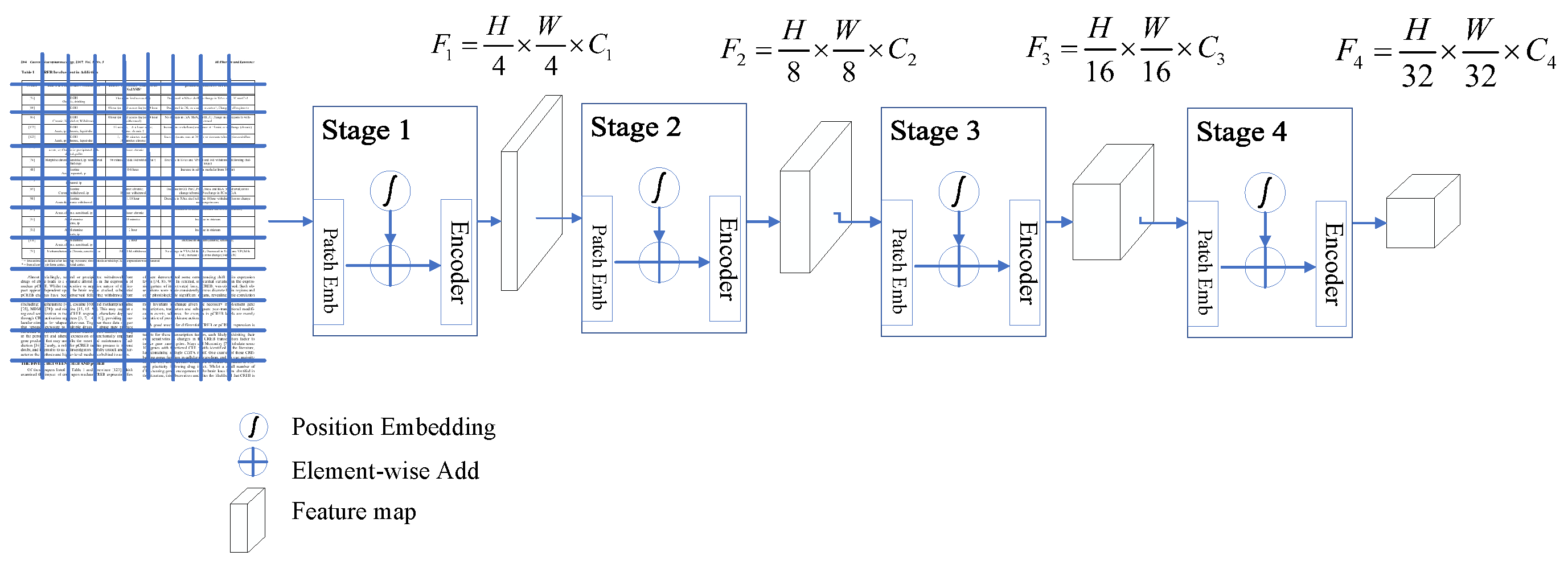
3.5.2. Sparse R-CNN+PVT
3.6. Implementation Details
3.7. Datasets
- TableBank [18]TableBank has been collected from the arXiv database [64], containing more than 417 K labeled document images. This dataset comes with two splits, Word and Latex. We combined both for training.
- PubLayNet [65]PubLayNet is another large-scale dataset that covers the task of layout analysis in documents. Contrary to manual labeling, this dataset has been collected by automatically annotating the document layout of PDF documents from the PubMed CentralTM database. PubLayNet comprises 360 K document samples containing text, title, list, figure, and table. All document samples from the PubLayNet dataset that contain tabular information were excluded for our experiments.
- PubTables-1M [66]This dataset is currently the largest and most complete dataset that addresses all three fundamental tasks of table analysis. For our experiments, we include the annotations of table detection from this dataset that consists of more than 500 K annotated document pages. Furthermore, we unify the annotations for various tabular boundaries in this dataset with a single class of tables to conduct joint training.
- FinTabNet [67]We employ FinTabNet to increase samples’ diversity. FinTabNet is derived from the PubTabNet [19] and contains complex tables from financial reports. This dataset comprises 70 K document samples with annotations of tabular boundaries and tabular structures.
4. Evaluations
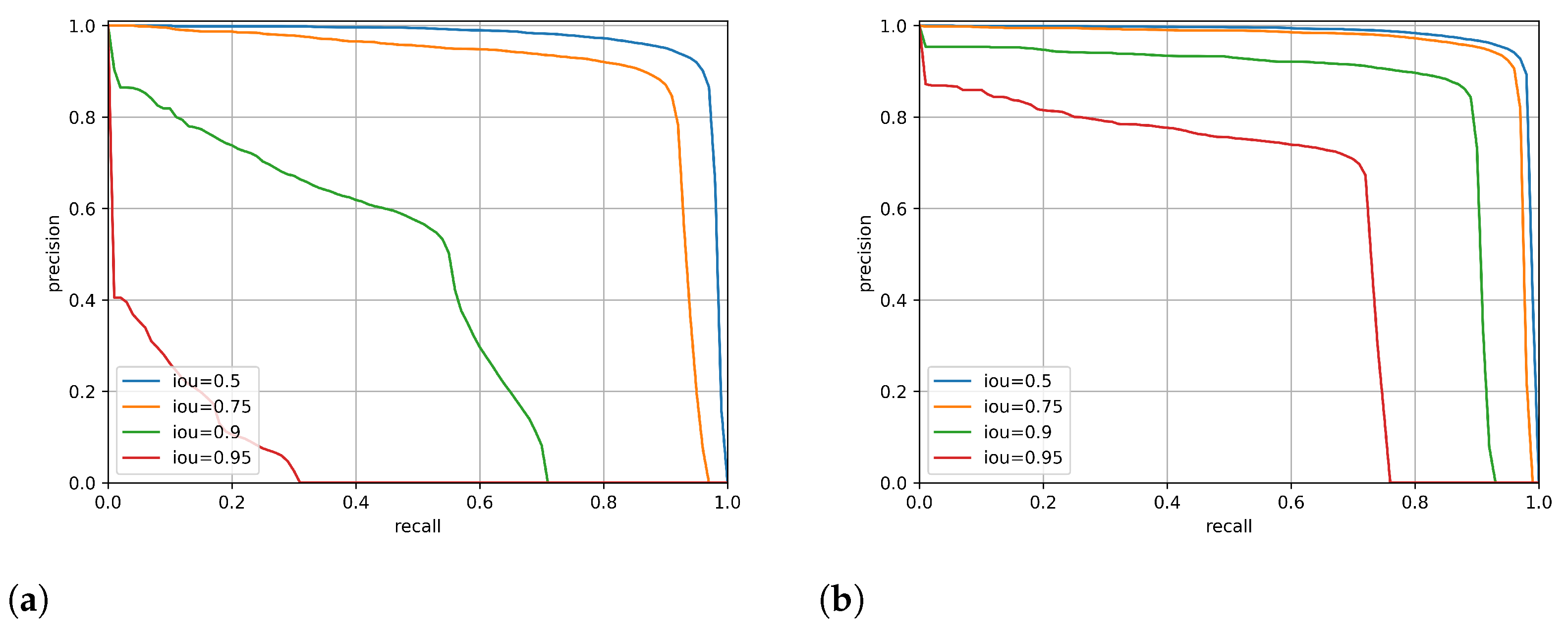
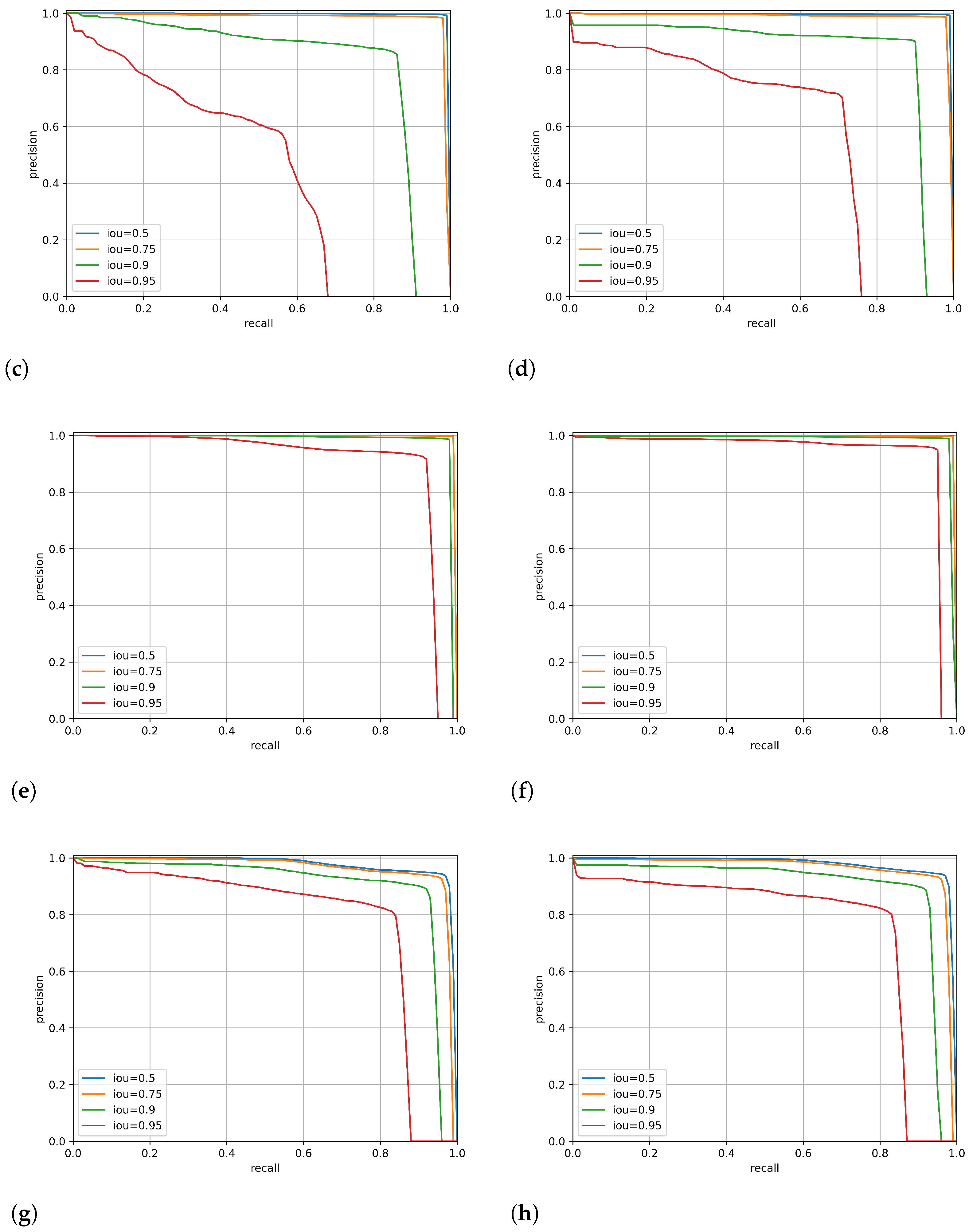
4.1. Evaluation Metrics
- PrecisionThe number of true positives divided by the total number of positive predictions is known as precision. This is a metric for determining the accuracy of a model. The precision is calculated through Equation (2):
- RecallTo indicate the rate of missed positive predictions, a metric named Recall (or Sensitivity) is commonly used. Recall could be obtained through dividing correct positive predictions (TP) by all positive predictions (TP + FP). Equation (3) shows the mathematical definition:
- Precision–Recall curveFor all possible thresholds, the precision–recall (PR) curve plots precision versus recall. A good object detector has a high recall rate as well as a high precision rate.
- Intersection Over Union (IOU)As written in Equation (4), the overlap of a predicted bounding box versus the correct one for an object is measured by the intersection over union of the two boxes:
- Mean Average Precision (mAP)The mean average precision (mAP) is a widely used parameter for evaluating object detection models. It is the area value under the precision–recall curve for each class, and the mAP is computed by averaging all average precision for all classes. Equation (5) formulates the metric:where is the average precision r.
4.2. Results
4.3. The Effect of Datasets Order
4.4. Comparison with State-of-the-Arts
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Z.; Jiang, M.; Guo, S.; Wang, Z.; Chao, F.; Tan, K.C. Improving Deep Learning Based Optical Character Recognition via Neural Architecture Search; IEEE Congress on Evolution Computation (CEC): Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Hashmi, K.A.; Ponnappa, R.B.; Bukhari, S.S.; Jenckel, M.; Dengel, A. Feedback Learning: Automating the Process of Correcting and Completing the Extracted Information. In Proceedings of the International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 5, pp. 116–121. [Google Scholar]
- van Strien, D.; Beelen, K.; Ardanuy, M.C.; Hosseini, K.; McGillivray, B.; Colavizza, G. Assessing the Impact of OCR Quality on Downstream NLP Tasks. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence, 1 ICAART, Valletta, Malta, 22–24 February 2020; pp. 484–496. [Google Scholar]
- Pyreddy, P.; Croft, W.B. Tintin: A system for retrieval in text tables. In Proceedings of the 2nd ACM International Conference on Digital Libraries, Philadelphia, PA, USA, 23–26 July 1997; pp. 193–200. [Google Scholar]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Cascade Network with Deformable Composite Backbone for Formula Detection in Scanned Document Images. Appl. Sci. 2021, 11, 7610. [Google Scholar] [CrossRef]
- Bhatt, J.; Hashmi, K.A.; Afzal, M.Z.; Stricker, D. A Survey of Graphical Page Object Detection with Deep Neural Networks. Appl. Sci. 2021, 11, 5344. [Google Scholar] [CrossRef]
- Zanibbi, R.; Blostein, D.; Cordy, J.R. A survey of table recognition. Doc. Anal. Recognit. 2004, 7, 1–16. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Liwicki, M.; Stricker, D.; Afzal, M.A.; Afzal, M.A.; Afzal, M.Z. Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks. IEEE Access 2021, 9, 87663–87685. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Gilani, A.; Qasim, S.R.; Malik, I.; Shafait, F. Table detection using deep learning. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 771–776. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Nazir, D.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. HybridTabNet: Towards better table detection in scanned document images. Appl. Sci. 2021, 11, 8396. [Google Scholar] [CrossRef]
- Prasad, D.; Gadpal, A.; Kapadni, K.; Visave, M.; Sultanpure, K. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 572–573. [Google Scholar]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. J. Imaging 2021, 7, 214. [Google Scholar] [CrossRef] [PubMed]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar] [CrossRef]
- Biesialska, M.; Biesialska, K.; Costa-jussà, M.R. Continual lifelong learning in natural language processing: A survey. arXiv 2020, arXiv:2012.09823. [Google Scholar]
- Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M.; Li, Z. Tablebank: Table benchmark for image-based table detection and recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1918–1925. [Google Scholar]
- Zhong, X.; ShafieiBavani, E.; Yepes, A.J. Image-based table recognition: Data, model, and evaluation. arXiv 2019, arXiv:1911.10683. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Itonori, K. Table structure recognition based on textblock arrangement and ruled line position. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Tsukuba City, Japan, 20–22 October 1993; pp. 765–768. [Google Scholar]
- Chandran, S.; Kasturi, R. Structural recognition of tabulated data. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Sukuba, Japan, 20–22 October 1993; pp. 516–519. [Google Scholar]
- Green, E.; Krishnamoorthy, M. Recognition of tables using table grammars. In Proceedings of the 4th Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 24–26 April 1995; pp. 261–278. [Google Scholar]
- Pivk, A.; Cimiano, P.; Sure, Y.; Gams, M.; Rajkovič, V.; Studer, R. Transforming arbitrary tables into logical form with TARTAR. Data Knowl. Eng. 2007, 3, 567–595. [Google Scholar] [CrossRef]
- e Silva, A.C.; Jorge, A.M.; Torgo, L. Design of an end-to-end method to extract information from tables. Int. J. Doc. Anal. Recognit. (IJDAR) 2006, 8, 144–171. [Google Scholar] [CrossRef]
- Khusro, S.; Latif, A.; Ullah, I. On methods and tools of table detection, extraction and annotation in PDF documents. J. Inf. Sci. 2015, 41, 41–57. [Google Scholar] [CrossRef]
- Coüasnon, B.; Lemaitre, A. Handbook of Document Image Processing and Recognition, Chapter Recognition of Tables and Forms; Doermann, D., Tombre, K., Eds.; Springer: London, UK, 2014; pp. 647–677. [Google Scholar]
- Embley, D.W.; Hurst, M.; Lopresti, D.; Nagy, G. Table-processing paradigms: A research survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2006, 8, 66–86. [Google Scholar] [CrossRef]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. Decnt: Deep deformable cnn for table detection. IEEE Access 2018, 6, 74151–74161. [Google Scholar] [CrossRef]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. Deepdesrt: Deep learning for detection and structure recognition of tables in document images. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1162–1167. [Google Scholar]
- Agarwal, M.; Mondal, A.; Jawahar, C. CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images. arXiv 2020, arXiv:2008.10831. [Google Scholar]
- Hashmi, K.A.; Stricker, D.; Liwicki, M.; Afzal, M.N.; Afzal, M.Z. Guided Table Structure Recognition through Anchor Optimization. arXiv 2021, arXiv:2104.10538. [Google Scholar] [CrossRef]
- Huang, Y.; Yan, Q.; Li, Y.; Chen, Y.; Wang, X.; Gao, L.; Tang, Z. A YOLO-based table detection method. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 813–818. [Google Scholar]
- Casado-García, Á.; Domínguez, C.; Heras, J.; Mata, E.; Pascual, V. The benefits of close-domain fine-tuning for table detection in document images. In International Workshop on Document Analysis Systems; Springer: Cham, Switzerland, 2020; pp. 199–215. [Google Scholar]
- Arif, S.; Shafait, F. Table detection in document images using foreground and background features. In Proceedings of the Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Sun, N.; Zhu, Y.; Hu, X. Faster R-CNN based table detection combining corner locating. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1314–1319. [Google Scholar]
- Qasim, S.R.; Mahmood, H.; Shafait, F. Rethinking table recognition using graph neural networks. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 142–147. [Google Scholar]
- Hao, L.; Gao, L.; Yi, X.; Tang, Z. A table detection method for pdf documents based on convolutional neural networks. In Proceedings of the 12th IAPR Workshop Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 287–292. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Saha, R.; Mondal, A.; Jawahar, C. Graphical object detection in document images. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 51–58. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Kavasidis, I.; Palazzo, S.; Spampinato, C.; Pino, C.; Giordano, D.; Giuffrida, D.; Messina, P. A saliency-based convolutional neural network for table and chart detection in digitized documents. arXiv 2018, arXiv:1804.06236. [Google Scholar]
- Paliwal, S.S.; Vishwanath, D.; Rahul, R.; Sharma, M.; Vig, L. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 128–133. [Google Scholar]
- Holeček, M.; Hoskovec, A.; Baudiš, P.; Klinger, P. Table understanding in structured documents. In Proceedings of the International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 5, pp. 158–164. [Google Scholar]
- Grossberg, S. How does a brain build a cognitive code? In Studies of Mind and Brain; Springer: Dordrecht, The Netherlands, 1982; pp. 1–52. [Google Scholar]
- Qu, H.; Rahmani, H.; Xu, L.; Williams, B.; Liu, J. Recent Advances of Continual Learning in Computer Vision: An Overview. arXiv 2021, arXiv:2109.11369. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Kuang, Z.; Chen, Y.; Xue, J.H.; Yang, W.; Zhang, W. Incdet: In defense of elastic weight consolidation for incremental object detection. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2306–2319. [Google Scholar] [CrossRef] [PubMed]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.025312. [Google Scholar]
- Zhang, J.; Zhang, J.; Ghosh, S.; Li, D.; Tasci, S.; Heck, L.; Zhang, H.; Kuo, C.C.J. Class-incremental learning via deep model consolidation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 13–19 June 2020; pp. 1131–1140. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental learning of object detectors without catastrophic forgetting. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3400–3409. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Araucano Park, Chile, 11–18 December 2015. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Acharya, M.; Hayes, T.L.; Kanan, C. Rodeo: Replay for online object detection. arXiv 2020, arXiv:2008.06439. [Google Scholar]
- Shieh, J.L.; Haq, M.A.; Karam, S.; Chondro, P.; Gao, D.Q.; Ruan, S.J. Continual learning strategy in one-stage object detection framework based on experience replay for autonomous driving vehicle. Sensors 2020, 20, 6777. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvtv2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 1–10. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition IEEE, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Michaelis, C.; Mitzkus, B.; Geirhos, R.; Rusak, E.; Bringmann, O.; Ecker, A.S.; Bethge, M.; Brendel, W. Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming. arXiv 2019, arXiv:1907.07484. [Google Scholar]
- arXiv.org e-Print Archive. Available online: https://arxiv.org/ (accessed on 30 March 2022).
- Zhong, X.; Tang, J.; Yepes, A.J. Publaynet: Largest dataset ever for document layout analysis. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1015–1022. [Google Scholar]
- Smock, B.; Pesala, R.; Abraham, R.; Redmond, W. PubTables-1M: Towards comprehensive table extraction from unstructured documents. arXiv 2021, arXiv:2110.00061. [Google Scholar]
- Zheng, X.; Burdick, D.; Popa, L.; Zhong, X.; Wang, N.X.R. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference. 11–17 October 2021; pp. 697–706. [Google Scholar]
- Huang, Y.; Zhang, Y.; Chen, J.; Wang, X.; Yang, D. Continual learning for text classification with information disentanglement based regularization. arXiv 2021, arXiv:2104.05489. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | TableBank | PubLayNet | PubTables-1M | FinTabNet | Joint |
|---|---|---|---|---|---|
| Train | 261 K | 86 K | 461 K | 48 K | 856 K |
| Test | 8 K | 4 K | 57 K | 6 K | 71 K |
| Experiment | Train-Set/Test-Set | Faster R-CNN+ResNet | Sparse R-CNN+PVT |
|---|---|---|---|
| IT | / | 95.7 | 96.2 |
| JT | / | 94.1 | 94.7 |
| FT | / | 74.2 | 76.4 |
| ER | / | 89.6(+15.4) | 90.7(+14.3) |
| IT | / | 97.6 | 97.4 |
| JT | / / | 97.4 | 97.5 |
| FT | / | 90.5 | 90.6 |
| ER | / | 93.7(+3.2) | 92.5(+1.9) |
| IT | / | 98.9 | 99 |
| JT | / | 98.4 | 98.7 |
| FT | / | 97.2 | 98 |
| ER | / | 97.4(+0.2) | 98.2(+0.2) |
| IT | / | 90 | 91.3 |
| JT | / | 88.4 | 92.7 |
| FT | / | 90 | 93.3 |
| ER | / | 90 | 93.1 |
| Experiment | Train-Set/Test-Set | Faster R-CNN+ResNet | Sparse R-CNN+PVT |
|---|---|---|---|
| FT | 96.1 | 97.4 | |
| ER | / | 97.7(+1.6) | 98.5(+1.1) |
| FT | / | 91.2 | 93.4 |
| ER | / | 94.2(+3) | 94.4(+1) |
| FT | / | 76.5 | 79.8 |
| ER | / | 87.9(+11.4) | 90.7(+10.9) |
| FT | / | 89.5 | 92.9 |
| ER | / | 89.1 | 93 |
| Method | TB[mAP] | PN[mAP] | PT[mAP] | FN[mAP] |
|---|---|---|---|---|
| CDeC-Net [31] | 96.5 | 97.8 | - | - |
| CasTabDetectoRS [14] | 95.3 | - | - | - |
| DETR [66] | - | - | 96.6 | - |
| Faster R-CNN+ResNet (ours) * | 89.6 | 93.7 | 97.4 | 90 |
| Sparse R-CNN+PVT (ours) * | 90.7 | 92.5 | 98.2 | 93.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minouei, M.; Hashmi, K.A.; Soheili, M.R.; Afzal, M.Z.; Stricker, D. Continual Learning for Table Detection in Document Images. Appl. Sci. 2022, 12, 8969. https://doi.org/10.3390/app12188969
Minouei M, Hashmi KA, Soheili MR, Afzal MZ, Stricker D. Continual Learning for Table Detection in Document Images. Applied Sciences. 2022; 12(18):8969. https://doi.org/10.3390/app12188969
Chicago/Turabian StyleMinouei, Mohammad, Khurram Azeem Hashmi, Mohammad Reza Soheili, Muhammad Zeshan Afzal, and Didier Stricker. 2022. "Continual Learning for Table Detection in Document Images" Applied Sciences 12, no. 18: 8969. https://doi.org/10.3390/app12188969