
Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques

 , ,
, ,
Abstract
:1. Introduction
- Automating the technique selection process to reduce human error;
- Building a robust decision-making model;
- Producing proper requirements and increasing the success ratio of IS projects.
2. Related Study
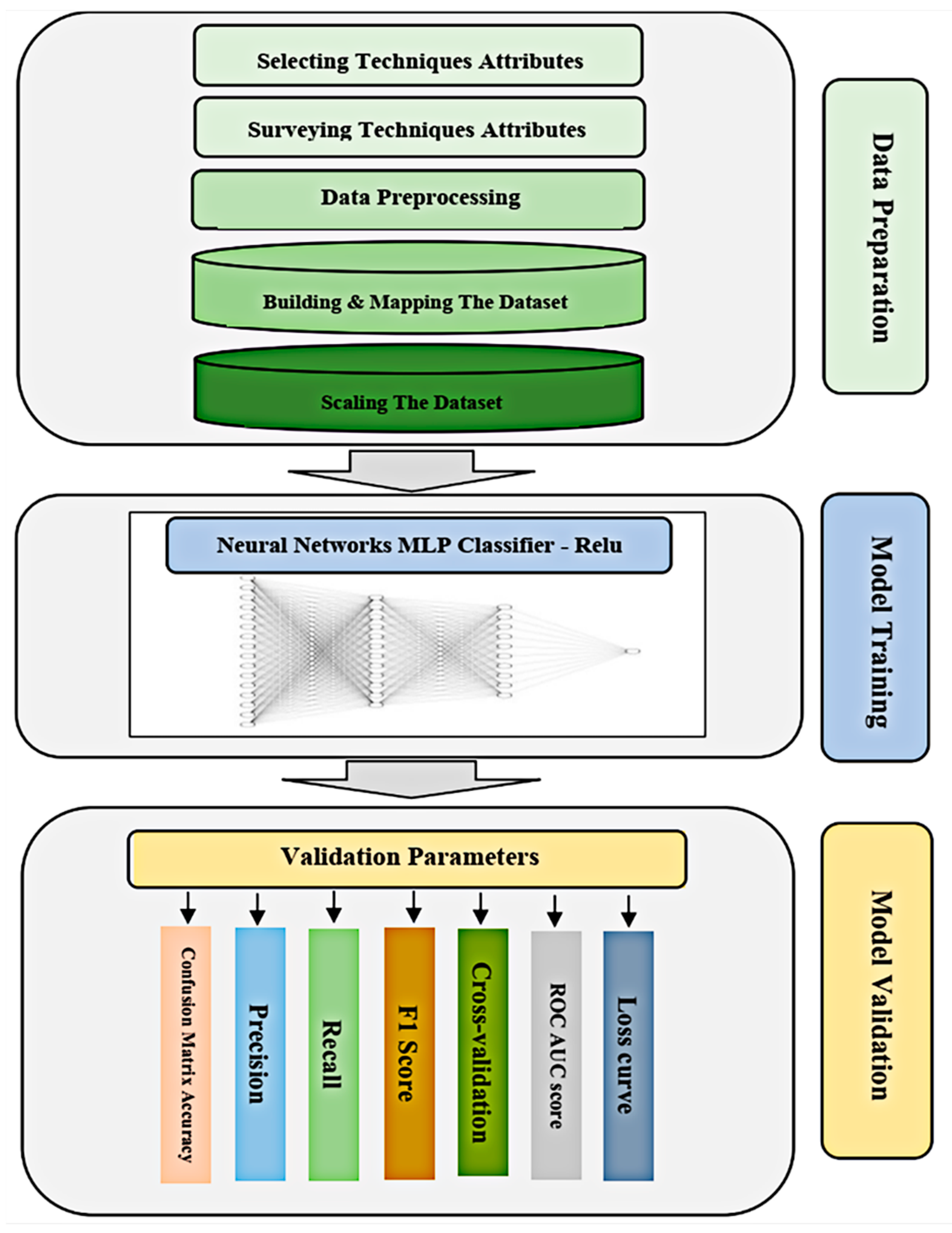
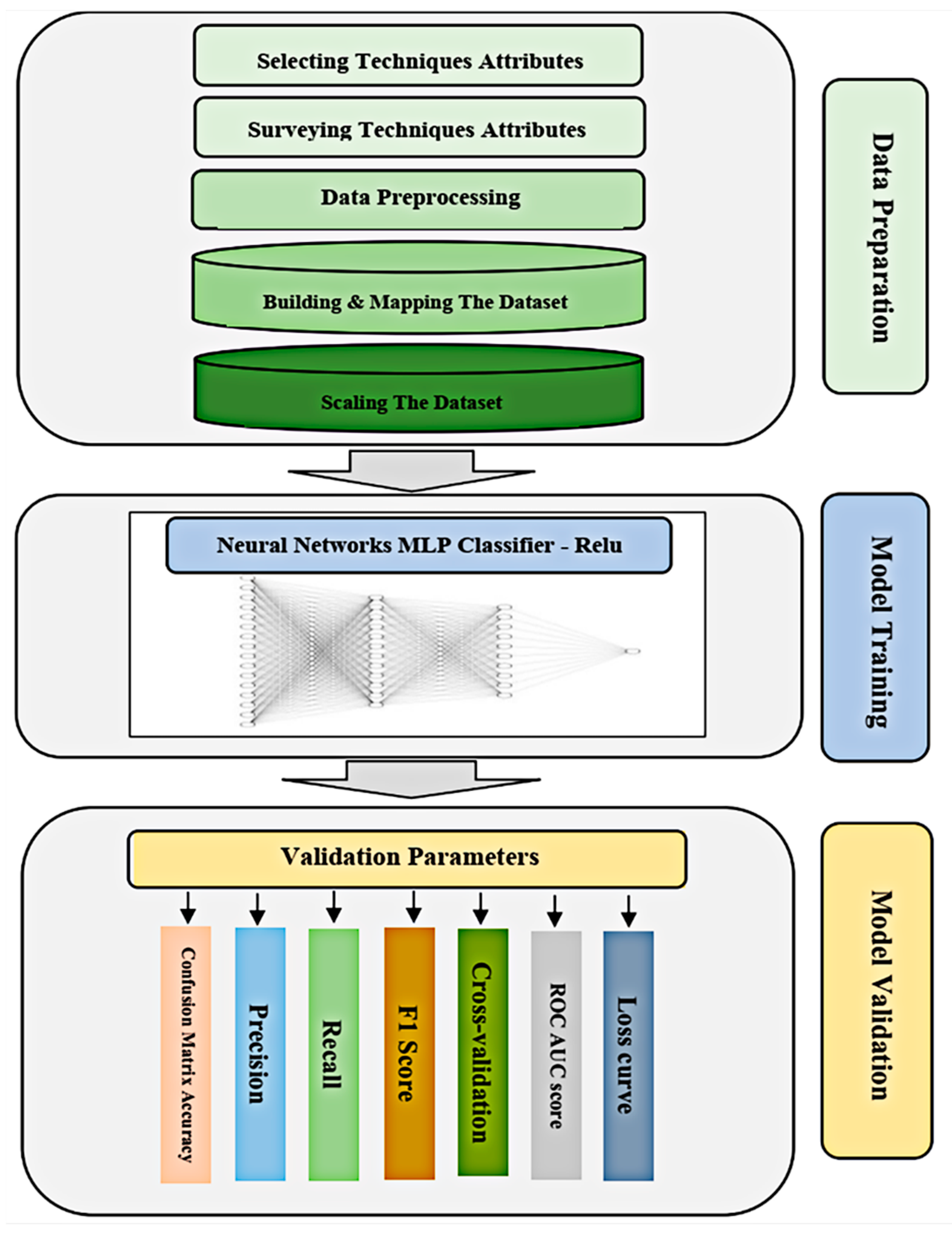
3. Methodology and Materials
The Methodology Strategy
4. Data Preparation
4.1. Technique Selection Attributes
4.2. Data Collection
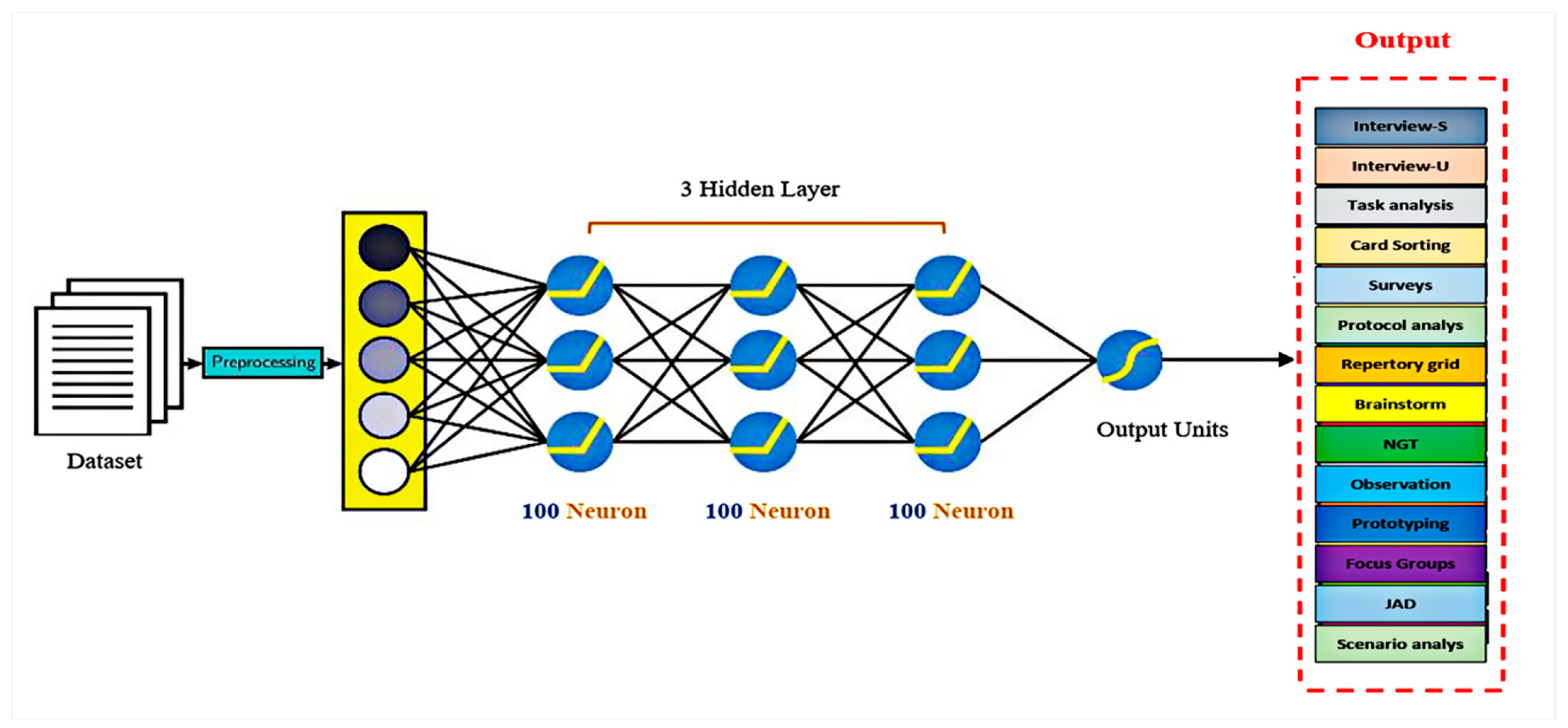
5. Deep Learning Model
5.1. Artificial Neural Networks Based Model
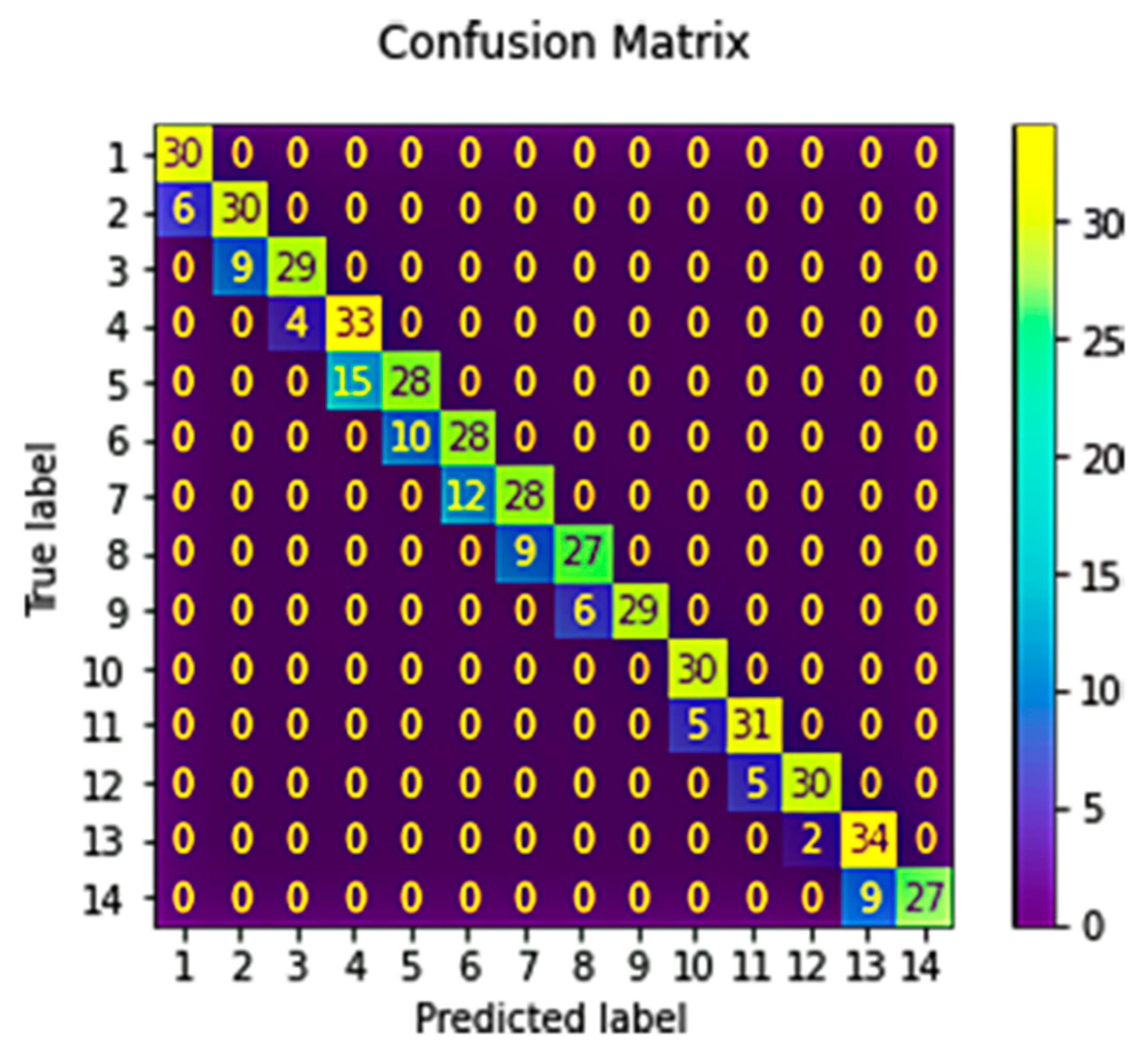
5.2. Analysis and Results
Model Validation
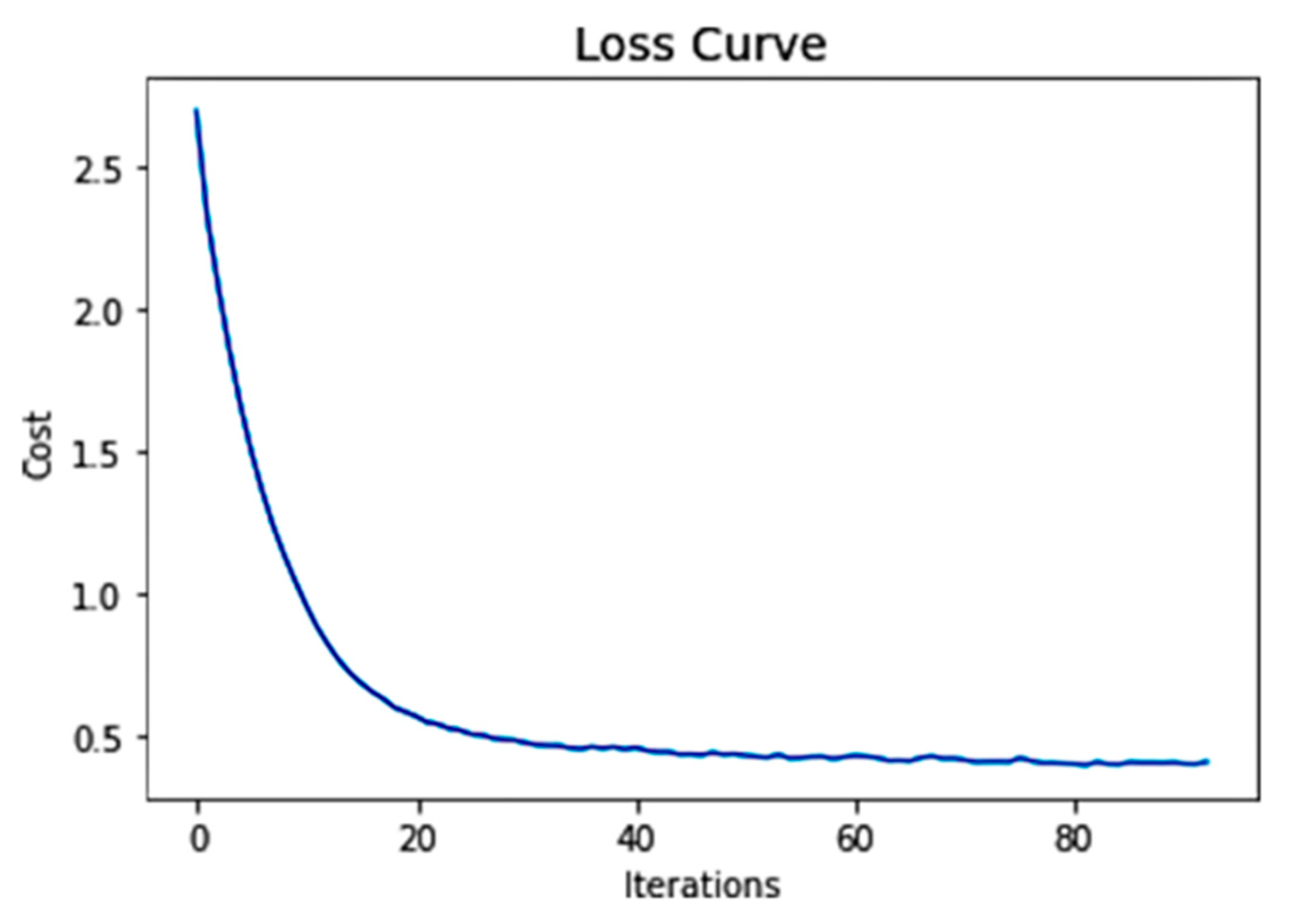
Loss Curve
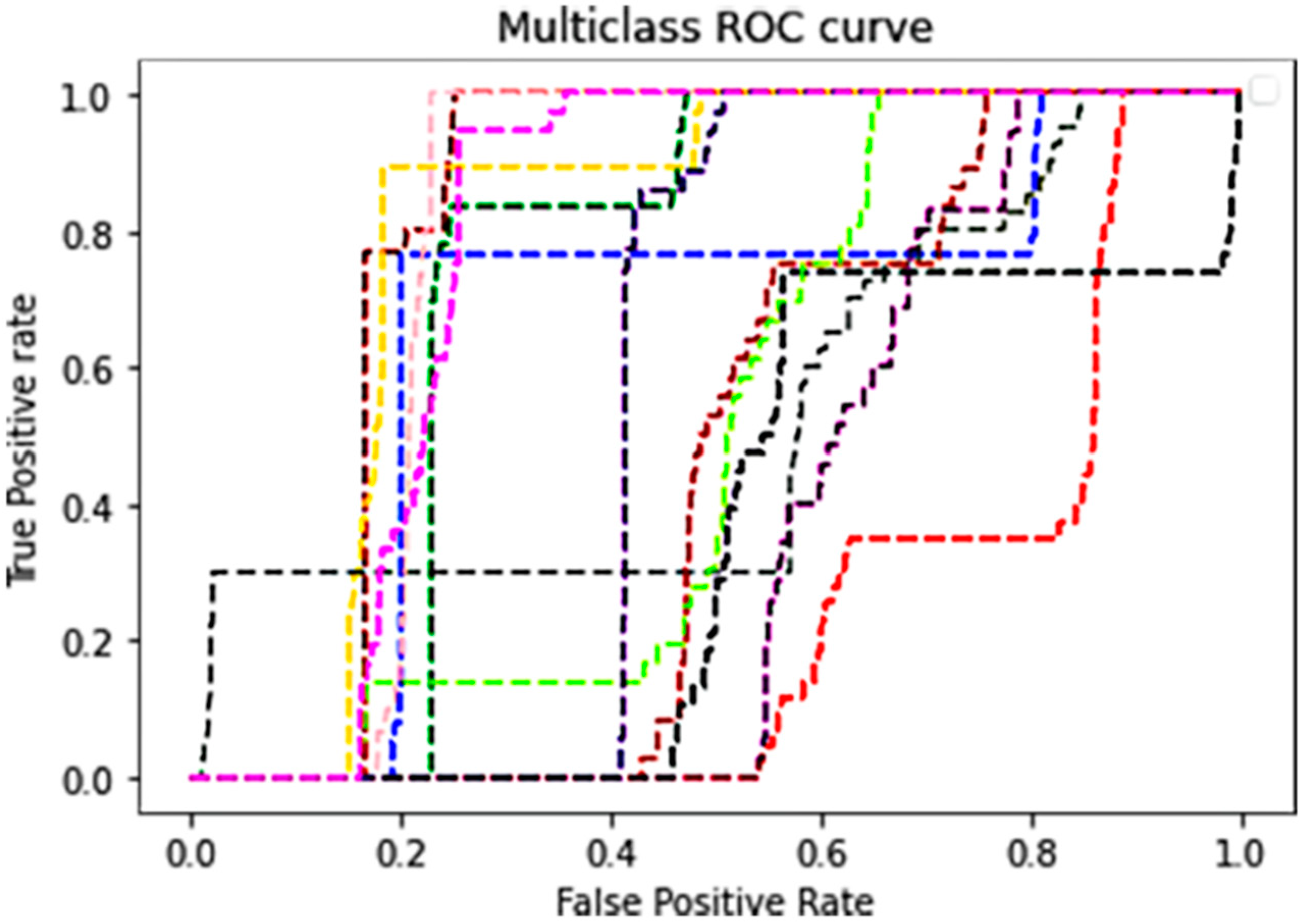
The Area under the ROC Curve (AUC)
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Johnson, J.; Boucher, K.D.; Connors, K.; Robinson, J. Collaborating on project success. Softw. Mag. 2001, 7, 15. [Google Scholar]
- Carrizo, D.; Dieste, O.; Juristo, N. Systematizing requirements elicitation technique selection. Inf. Softw. Technol. 2014, 56, 644–669. [Google Scholar] [CrossRef]
- Lim, S.; Henriksson, A.; Zdravkovic, J. Data-Driven Requirements Elicitation: A Systematic Literature Review. SN Comput. Sci. 2021, 2, 16. [Google Scholar] [CrossRef]
- Ahmad, A.; Feng, C.; Khan, M.; Khan, A.; Ullah, A.; Nazir, S.; Tahir, A. A systematic literature review on using machine learning algorithms for software requirements identification on stack overflow. Secur. Commun. Netw. 2020, 2020, 19. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2022, 24, 2449–2460. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human–Computer Interaction. IEEE Trans. Ind. Inform. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Nisar, S.; Nawaz, M. Review Analysis on Requirement Elicitation and its Issues. Int. J. Comput. Commun. Syst. Eng. 2015, 2, 484–489. [Google Scholar]
- Rahman, A.N.; Sahibuddin, S. Extracting Soft Issues during Requirements Elicitation: Preliminary Study. Int. J. Inf. Electron. Eng. 2011, 1, 126. [Google Scholar]
- Darwish, N.R.; Mohamed, A.A.; Abdelghany, A.S. A hybrid machine learning model for selecting suitable requirements elicitation techniques. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 1–12. [Google Scholar]
- Vitharana, P.; Zahedi, M.F.; Jain, H.K. Enhancing analysts’ mental models for improving requirements elicitation: A two-stage theoretical framework and empirical results. J. Assoc. Inf. Syst. 2016, 17, 1. [Google Scholar] [CrossRef]
- Bodnarchuk, I.; Lisovyi, V.; Kharchenko, O.; Galai, I. Adaptive Method for Assessment and Selection of Software Architecture in Flexible Techniques of Design. In Proceedings of the 2018 IEEE 13th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 11–14 September 2018; Volume 1, pp. 292–297. [Google Scholar]
- Ibrahim, H.M.E.; Ahmad, N.; Rehman, M.B.; Ahmad, I.; khan, R. Implementing and automating elicitation technique selection using machine learning. In Proceedings of the International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 564–569. [Google Scholar]
- Gupta, A.K.; Deraman, A. A framework for software requirement ambiguity avoidance. Int. J. Electr. Comput. Eng. 2019, 9, 5436. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.A.; Abdulgabber, M.A. StakeQP: A semi-automated stakeholder quantification and prioritisation technique for requirement selection in software system projects. Decis. Support Syst. 2019, 121, 94–108. [Google Scholar] [CrossRef]
- Giraldo, S.M.; Aguilar, L.J.; Giraldo, L.M.; Toro, I.D. Techniques for the identification of organizational knowledge management requirements. J. Knowl. Manag. 2019, 23, 1355–1402. [Google Scholar] [CrossRef]
- Li, J.; Ullah, A.; Li, J.; Nazir, S.; Khan, H.U.; Ur Rehman, H.; Haq, A.U. Attributes-based decision making for selection of requirement elicitation techniques using the analytic network process. Math. Probl. Eng. 2020, 2020, 13. [Google Scholar] [CrossRef]
- Dafallaa, H.M.E.I.; Ahmad, N.; Rehman, M.B.; Ahmad, I.; khan, R. Chapter 3 Automating Elicitation Technique Selection using Machine Learning in Cloud Environment. In Deepak Gupta, Aditya Khamparia Fog, Edge, and Pervasive Computing in Intelligent IoT Driven Applications, 1st ed.; Wiley-IEEE Press: Piscataway, NJ, USA, 2020; pp. 47–65. [Google Scholar]
- Rehman, M.B.; Dafallaa HM, E.I.; Ahmad, N.; Ahmad, I.; Rashid, M.; Khan, R. Requirement elicitation: Requirements conflict resolution and communication model for Telecommunication Sector. In Proceedings of the 2nd International Conference on ICT for Digital, Smart, and Sustainable Development ICIDSSD, Jamia Hamdard, New Delhi, India, 27–28 February 2020; p. 457. [Google Scholar]
- Panichella, S.; Ruiz, M. Requirements-collector: Automating requirements specification from elicitation sessions and user feedback. In Proceedings of the 2020 IEEE 28th International Requirements Engineering Conference, IEEE, Zurich, Switzerland, 31 August 2020–4 September 2020; pp. 404–407. [Google Scholar]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inform. 2022, 18, 4361–4371. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Saeeda, H.; Dong, J.; Wang, Y.; Abid, M.A. A proposed framework for improved software requirements elicitation process in SCRUM: Implementation by a real-life Norway-based IT project. J. Softw. Evol. Process 2020, 32, e2247. [Google Scholar] [CrossRef]
- Mougouei, D.; Mougouei, E.; Powers, D.M.W. Partial Selection of Software Requirements: A Fuzzy Method. Int. J. Fuzzy Syst. 2021, 23, 2067–2079. [Google Scholar] [CrossRef]
- Naumcheva, M. Deep Learning Models in Software Requirements Engineering. arXiv 2021, arXiv:1508.04409. [Google Scholar]
- Li, B.; Li, Z.; Yang, Y. NFRNet: A Deep Neural Network for Automatic Classification of Non-Functional Requirements. In Proceedings of the IEEE 29th International Requirements Engineering Conference (RE), Notre Dame, IN, USA, 20–24 September 2021; pp. 434–435. [Google Scholar]
- Sagrado, J.D.; Águila, I.M.D. Assisted requirements selection by clustering. Requir. Eng. 2021, 26, 167–184. [Google Scholar] [CrossRef]
- Elhassan, H.; Abaker, M.; Abdelmaboud, A.; Rehman, M.B. Requirements Engineering: Conflict Detection Automation Using Machine Learning. Intell. Autom. Soft Comput. 2022, 33, 259–273. [Google Scholar] [CrossRef]
- Li, D.; Liu, H.; Zhang, Z.; Lin, K.; Fang, S.; Li, Z.; Xiong, N.N. CARM: Confidence-aware recommender model via review representation learning and historical rating behavior in the online platforms. Neurocomputing 2021, 455, 283–296. [Google Scholar]
- Liu, T.; Wang, J.; Yang, B.; Wang, X. NGDNet: Nonuniform Gaussian-label distribution learning for infrared head pose estimation and on-task behavior understanding in the classroom. Neurocomputing 2021, 436, 210–220. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Classification |
|---|---|
| Analyst Experience | Classifies the system analyst experience, the level of involvement in software development projects and familiarity of the system analyst with the elicitation technique. |
| Technique Attribute | Classifies the range of individuals that could be accommodated by the elicitation |
| Technique Time | Classifies the time duration of the elicitation technique |
| Level of Information | Classifies the scale of the information extractions |
| Analyst Experience | Technique Attribute | Technique Time | Level of Information |
|---|---|---|---|
| Low | Single | Low | Low |
| Medium | Group | Medium | Medium |
| High | Large Group | High | High |
| Attributes | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 1 | 0.83 | 0.83 | 0.82 | 30 |
| 2 | 077 | 0.83 | 0.80 | 36 |
| 3 | 0.88 | 0.76 | 0.82 | 38 |
| 4 | 0.69 | 0.89 | 0.78 | 37 |
| 5 | 0.74 | 0.65 | 0.69 | 43 |
| 6 | 0.70 | 0.74 | 0.72 | 38 |
| 7 | 0.76 | 0.70 | 0.73 | 40 |
| 8 | 0.82 | 0.75 | 0.78 | 36 |
| 9 | 1.00 | 0.83 | 0.91 | 35 |
| 10 | 0.86 | 1.00 | 0.92 | 30 |
| 11 | 0.86 | 0.86 | 0.86 | 36 |
| 12 | 0.94 | 0.86 | 0.90 | 35 |
| 13 | 0.79 | 0.94 | 0.86 | 36 |
| 14 | 1.00 | 0.75 | 0.86 | 36 |
| Accuracy | 0.82 | 506 | ||
| Macro avg | 0.83 | 0.83 | 0.82 | 506 |
| Weighted avg | 0.83 | 0.82 | 0.82 | 506 |
| One-vs-One ROC AUC Scores | One-vs-Rest ROC AUC Scores |
|---|---|
| 0.745365 (macro) | 0.754880 (macro) |
| 0.750311 (weighted by prevalence) | 0.755098 (weighted by prevalence) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dafaalla, H.; Abaker, M.; Abdelmaboud, A.; Alghobiri, M.; Abdelmotlab, A.; Ahmad, N.; Eldaw, H.; Hasabelrsoul, A. Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques. Appl. Sci. 2022, 12, 9060. https://doi.org/10.3390/app12189060
Dafaalla H, Abaker M, Abdelmaboud A, Alghobiri M, Abdelmotlab A, Ahmad N, Eldaw H, Hasabelrsoul A. Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques. Applied Sciences. 2022; 12(18):9060. https://doi.org/10.3390/app12189060
Chicago/Turabian StyleDafaalla, Hatim, Mohammed Abaker, Abdelzahir Abdelmaboud, Mohammed Alghobiri, Ahmed Abdelmotlab, Nazir Ahmad, Hala Eldaw, and Aiman Hasabelrsoul. 2022. "Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques" Applied Sciences 12, no. 18: 9060. https://doi.org/10.3390/app12189060
APA StyleDafaalla, H., Abaker, M., Abdelmaboud, A., Alghobiri, M., Abdelmotlab, A., Ahmad, N., Eldaw, H., & Hasabelrsoul, A. (2022). Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques. Applied Sciences, 12(18), 9060. https://doi.org/10.3390/app12189060