
Automatic Cause–Effect Graph Tool with Informal Korean Requirement Specifications


Abstract
:1. Introduction
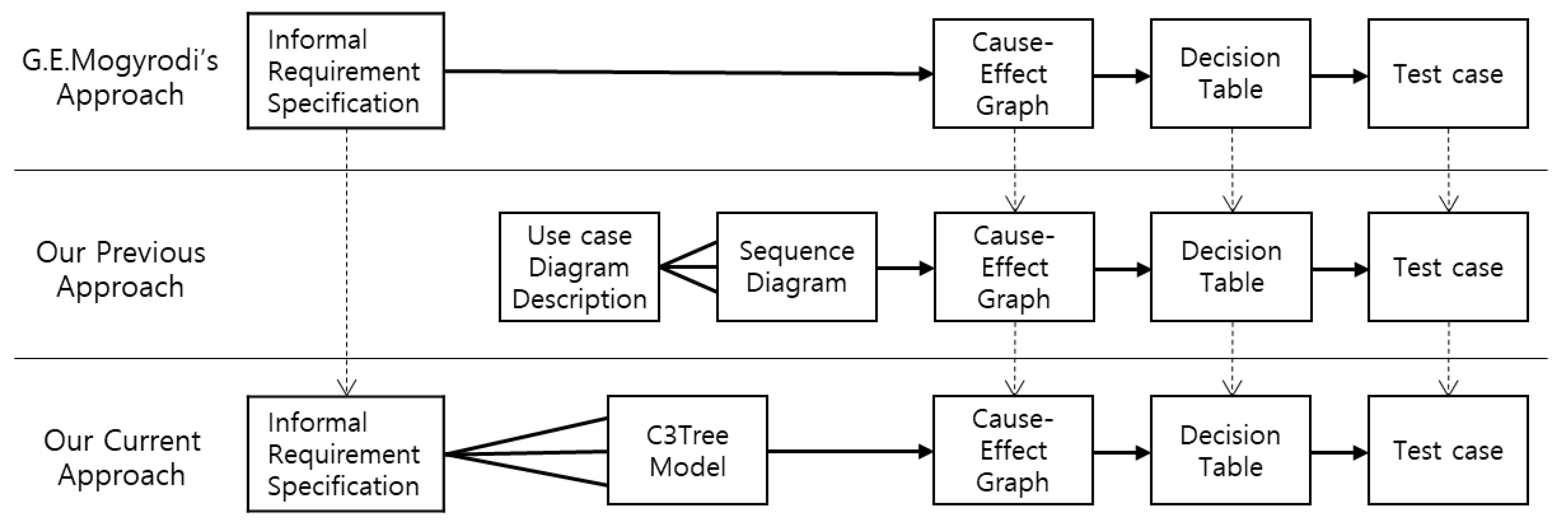
2. Related Studies
3. Automatic Generation for Cause–Effect Graph from Informal Korean Requirements
3.1. Automatic Generation Process for Cause–Effect Graph from Korean Requirements on Our Informal Korean-Based Requirement Analyzer
- Step 0. Input Informal Korean Requirements
- Step 1. Identify Morpheme
- Step 2. Simplify Complex Requirement Sentences
- Identify the positive and negative condition relationships;
- Identify the AND or the OR conjunction relationships;
- Normalize corpus;
- Identify the order of different clauses in a complex requirement sentence.
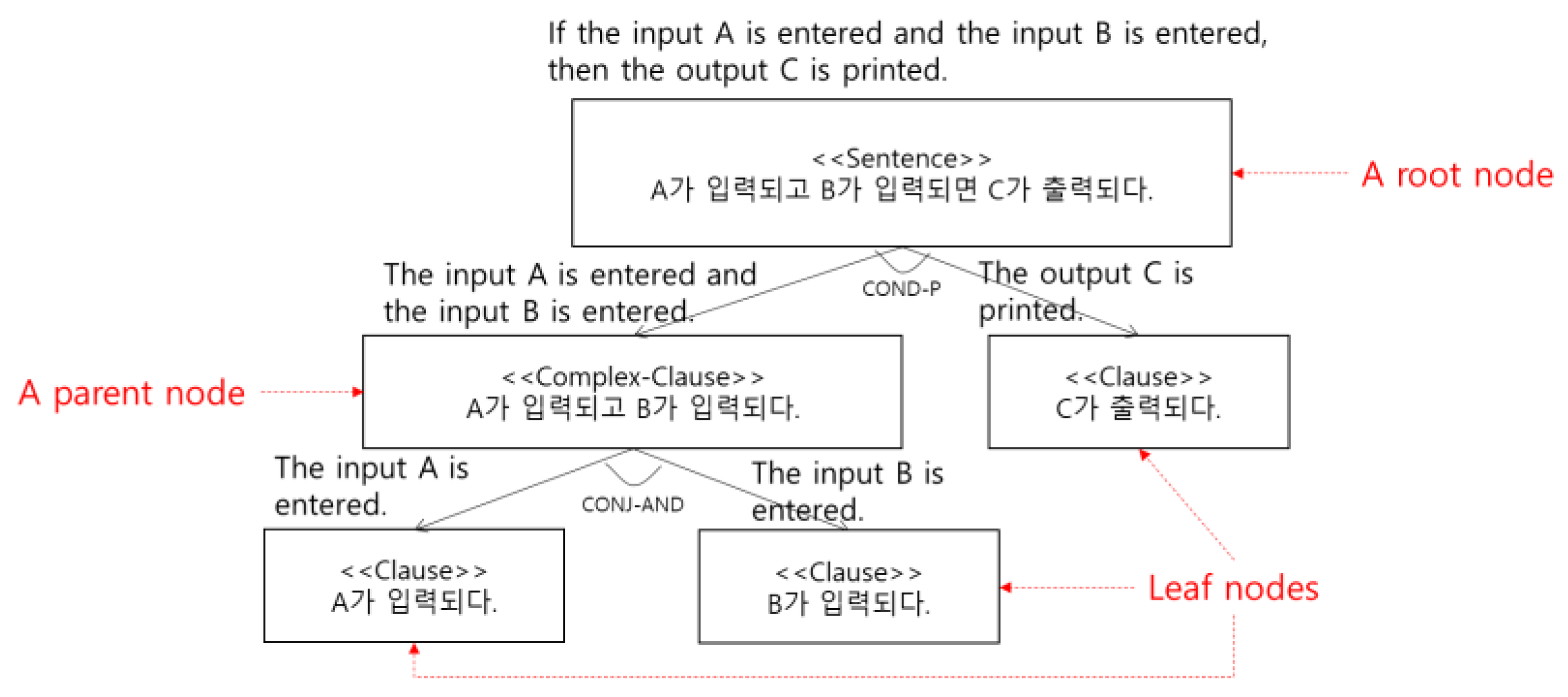
- Step 3. Generate Condition/Conjunction/Clause Tree (C3Tree) Model
- Step 4. Unify with Two Similar Nodes in C3Tree Models
- Step 5. Transform C3Tree Model to Cause–Effect Graph
3.2. A Cae Study with Our KRA-CE Analyzer
- ①
- Identification of morpheme: identify morphemes in sentences;
- ②
- Simplification of complex requirements: (1) slice the requirement sentence into clause units and (2) identify a conditional clause, a result clause, and a conjunction clause with AND role/OR role [16,17]; (3) convert the sliced clauses into simplified sentences; (4) convert a passive sentence into an active sentence [18,19];
- ③
- Generation of C3Tree model: simplify complex sentences;
- ④
- Unification of similar nodes in the C3Tree model: (1) identify similar nodes among terminal nodes of all C3Tree models and (2) combine similar nodes into one;
- ⑤
- Transformation C3Tree model to cause–effect graph: (1) transform the <<Clause>> of the C3Tree model into a node of the cause–effect graph and (2) transform the link of the C3Tree model into the relationship of the cause–effect graph;
- ⑥
- In the near future, we will work on the KRA-Test Case Generation as follows: (1) transform the cause–effect graph to the decision table; (2) transform the decision table to the test case; (3) transform the test case to the test script.
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kwon, O.S.; Hong, S.N. Effective Iterative Testing based on Log. In Proceedings of the Korea Society of Management Information Systems Fall Conference, Seoul, Korea, 6 November 2009; pp. 685–690. [Google Scholar]
- Myers, G.L. The Art of Software Testing; Wiley-Interscience: London, UK, 1979. [Google Scholar]
- Jang, W.S.; Kim, R.Y.C. Automatic Generation Mechanism of Cause-Effect Graph with Informal Requirement Specification based on Korean Language. Appl. Sci. 2021, 11, 11775. [Google Scholar] [CrossRef]
- Farooq, M.S.; Tahreem, T. Requirement-Based Automated Test Case Generation: Systematic Literature Review. VFAST Trans. Softw. Eng. 2021, 9, 133–142. [Google Scholar]
- Adler, M.; Gray, M.A. A Formalization of Myers Cause-Effect Graphs for Unit Testing. ACM SIGSOFT Softw. Eng. Notes 1983, 8, 24–33. [Google Scholar] [CrossRef]
- Kim, W.Y.; Kim, R.Y.C. A Study on Modeling Heterogeneous Embedded S/W Components based on Model Driven Architecture with Extended xUML. Korea Inf. Process. Soc. Trans. Part D 2007, 14, 83–88. [Google Scholar]
- BenderRBT, BenderRBT. Available online: https://www.benderrbt.com (accessed on 5 April 2022).
- Bekiroglu, B. A cause-effect graph software testing tool. Eur. J. Comput. Sci. Inf. Technol. 2017, 5, 11–24. [Google Scholar]
- Mogyorodi, G.E. Requirements-Based Testing-Cause-Effect Graphing. Softw. Test. Serv. 2005, 1–12. [Google Scholar]
- Son, H.S.; Kim, R.Y.C.; Park, Y.B. Test Case Generation from Cause-Effect Graph based on Model Transformation. In Proceedings of the International Conference on Information Science & Applications (ICISA), Seoul, Korea, 6–9 May 2014; pp. 1–4. [Google Scholar]
- Woo, S.J.; Son, H.S.; Kim, W.Y.; Kim, J.S.; Kim, R.Y.C. A Study Testcase Extraction based M&S for Pre-Testing. In Proceedings of the Korea Conference on Software Engineering, Jeju, Korea, 22–25 November 2012; Volume 14, pp. 181–183. [Google Scholar]
- Vo, N.P.A.; Manotas, I.; Popescu, O.; Cerniauskas, A.; Sheinin, V. Recognizing and Splitting Conditional Sentences for Automation of Business Processes Management. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Varna, Bulgaria, 9–10 September 2021; pp. 1490–1497. [Google Scholar]
- Mecab-Ko-Dic. Available online: https://bitbucket.org/eunjeon/mecab-ko-dic (accessed on 5 April 2022).
- Agresti, A. Categorical Data Analysis; John Wiley and Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Lim, S.J.; Kwon, M.J.; Kim, J.S.; Kim, H.K. Korean Proposition Bank Guidelines for ExoBrain. In Proceedings of the 27th Annual Conference on Human & Cognitive Language Technology, Atlanta, GA, USA, 28–31 May 2015; pp. 250–254. [Google Scholar]
- Ha, J.M. A Contrastive Study on Korean Conditional Connective Ending and Chinese Conditional Conjunction Expression; Kyunghee University: Seoul, Korea, 2007. [Google Scholar]
- Kim, K.S. A Comparative study on conjoined sentence between modern Mongolian and Korean. Korean Assoc. Mong. Stud. 2009, 151–186. [Google Scholar]
- Cho, J.M.; Cho, Y.H.; Kim, G.C. A Corpus Formalization for Extracting the Syntactic Relations. In Proceedings of the 8th Annual Conference on Human & Cognitive Language Technology, Daejeon, Korea, 11–12 October 1996; pp. 207–215. [Google Scholar]
- Cho, J.M.; Kim, G.C. A Corpus Formalization for Extracting the Syntactic Relations. Korean Soc. Cogn. Sci. 1996, 7, 39–56. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HiMEM [6] | Bender RBT [7] | Berk Bekiroglu’s Tool [8] | KRA-CE [3] | |
|---|---|---|---|---|
| Automatic test case generation based on cause–effect graph | O | O | O | O |
| Automatic cause–effect generation with requirements | X | X | X | O |
| Support for design methods with cause–effect graph | O | O | O | X |
| Support various OS environments | X | X | X | O |
| Modify a GUI-based cause–effect graph | X | O | X | X |
| Directly input informal requirement specifications | X | X | X | O |
| Simplify complex requirements | X | X | X | O |
| Represent clauses of requirements on nodes | X | X | X | O |
| Extract the incomplete requirements sentence | X | X | X | O |
| Korean | A가 입력되고 B가 입력되면 C가 출력된다. |
|---|---|
| English | If the input A is entered and the input B is entered, then the output C is printed. |
| Formula | Order of Identification | Formula | Order of Identification | ||
|---|---|---|---|---|---|
| 1 | CF identification | 4 | CF identification after CR identification | ||
| 2 | CR identification | 5 | CF identification after CR identification | ||
| 3 | CR identification after CF identification | 6 | CR identification after CF identification |
| Theta-Role | Description |
|---|---|
| Agent | An object that causes an action with the intention expressed by the predicate. |
| Experience | The entity that recognizes an action or a state, not causing action with the intention. |
| Patient | The person or thing that undergoes the action. |
| Theme | An object that is the most central in the theta-role discussion. This is influenced by actions or processes, not controlling them. |
| Goal | The entity on activity that is directed |
| Source | The entity that starts a change when a predicate includes the identity of a person, a quality of a thing. |
| Instrument | The entity indicates either a physical or abstract starting point when a verb includes a meaning related to moving or changing. |
| Language | Requirements |
|---|---|
| Korean | 1. 사용자가 시스템 시작 시(N1,C1) 로그인 옵션이 수동 로그인으로 적용되어(N2,C2) 있으면 프로그램은 아이디/비밀번호를 묻는 창을 연다(N3,E1). 2. 아이디/비밀번호를 묻는 창이 열리면(N3,C3) 사용자는 아이디와 비밀번호를 입력할 수 있다(N4,E2). 3. 사용자가 아이디와 비밀번호를 입력하면(N4,C4) 프로그램은 서버를 통해 아이디/비밀번호를 검증한다(N5,E3). 4. 사용자가 로그인 옵션 미선택 시(N6,C5) 자동 로그인 옵션이 선택된다(N7,E4). 5. 자동 로그인 옵션 선택 시(N7,C6) 옵션 정보가 쿠키 파일로 저장된다(N8,E5). |
| English | 1. When the user starts the system (N1,C1), if the login option is set to manual login (N2,C2), it opens a window asking for ID/password (N3,E1). 2. When a window asking for an ID/password opens( N3,C3), the user can enter the ID and password (N4,E2). 3. When the user enters the ID and password (N4,C4), the program verifies the ID/password through the server (N5,E3). 4. If the user does not select a login option (N6,C5), the automatic login option is selected (N7,E4). 5. When selecting the automatic login option (N7,C6), options information is stored as a cookie file (N8,E5). |
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, W.S.; Kim, R.Y.C. Automatic Cause–Effect Graph Tool with Informal Korean Requirement Specifications. Appl. Sci. 2022, 12, 9310. https://doi.org/10.3390/app12189310
Jang WS, Kim RYC. Automatic Cause–Effect Graph Tool with Informal Korean Requirement Specifications. Applied Sciences. 2022; 12(18):9310. https://doi.org/10.3390/app12189310
Chicago/Turabian StyleJang, Woo Sung, and R. Young Chul Kim. 2022. "Automatic Cause–Effect Graph Tool with Informal Korean Requirement Specifications" Applied Sciences 12, no. 18: 9310. https://doi.org/10.3390/app12189310
APA StyleJang, W. S., & Kim, R. Y. C. (2022). Automatic Cause–Effect Graph Tool with Informal Korean Requirement Specifications. Applied Sciences, 12(18), 9310. https://doi.org/10.3390/app12189310