
A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function

Abstract
:1. Introduction
- We propose a redefined imbalance degree for imbalanced encrypted traffic datasets, and take it as the indicator to construct a weight function to reassign the weights of each category;
- According to the performance tendency problems caused by imbalanced datasets, we propose a re-weighted CEFL loss function to expand the inter-class distance and increase the effective loss gap between the majority and minority samples;
- We improved the channel attention module (CAM) in CBAM with the redefined imbalance degree, which can make the model pay more attention to the characteristics of the minority categories, and increase the representation ability of these samples.
2. Related Work
3. Methodology
3.1. Imbalance Degree Based on Information Entropy
3.2. Channel–Spatial Domain Attention Module
3.3. Heavily Weighted Cross-Entropy Focal Loss Function
3.3.1. CE Loss Function
3.3.2. Focus Loss Function
3.3.3. CEFL Loss Function
4. Experiment and Analysis
4.1. Dataset and Pre-Processing
- Data splitting: since the CNN model requires the input data to be of the same size, we split the traffic data at the session level and pick the first 784 bytes;
- Data cleaning: we remove the packets in .pcap format without application layer data to avoid generating bin files with no actual content;
- Image generation: we convert the file with the length of 784 bytes into a grayscale image in binary form, one byte for one grayscale pixel value.
4.2. Evaluate Metrics
4.3. Results and Analysis
4.3.1. Parameter Settings
4.3.2. Compare Experiment
5. Conclusions, Discussion, and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, C.; Zhang, C.; Lu, Z.; Liu, B.; Jiang, B. CETAnalytics: Comprehensive effective traffic information analytics for encrypted traffic classification. Comput. Netw. 2020, 176, 107258. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, X.; Yang, J. Deep Learning-Based Encrypted Network Traffic Classification and Resource Allocation in SDN. J. Web Eng. 2021, 20, 2319–2334. [Google Scholar] [CrossRef]
- Mills, G.A.; Pomary, P.; Togo, E.; Sowah, R.A. Detection and Management of P2P Traffic in Networks using Artificial Neural Networks. J. Netw. Syst. Manag. 2022, 30, 26. [Google Scholar] [CrossRef]
- Islam, F.U.; Liu, G.; Zhai, J.; Liu, W. VoIP Traffic Detection in Tunneled and Anonymous Networks Using Deep Learning. IEEE Access 2021, 9, 59783–59799. [Google Scholar] [CrossRef]
- Huang, Y.F.; Lin, C.B.; Chung, C.M.; Chen, C.M. Research on QoS Classification of Network Encrypted Traffic Behavior Based on Machine Learning. Electronics 2021, 10, 1376. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification. In Proceedings of the 2022 ACM Web Conference (WWW), Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Zhang, X.Q.; Zhao, M.; Wang, J.Y.; Li, S.; Zhou, Y.; Zhu, S.N. Deep-Forest-Based Encrypted Malicious Traffic Detection. Electronics 2022, 11, 977. [Google Scholar] [CrossRef]
- Yao, H.P.; Liu, C.; Zhang, P.Y.; Wu, S.; Jiang, C.X.; Yu, S. Identification of Encrypted Traffic Through Attention Mechanism Based Long Short Term Memory. IEEE Trans. Big Data 2022, 8, 241–252. [Google Scholar] [CrossRef]
- Lu, B.; Luktarhan, N.; Ding, C.; Zhang, W. ICLSTM: Encrypted Traffic Service Identification Based on Inception-LSTM Neural Network. Symmetry 2021, 13, 1080. [Google Scholar] [CrossRef]
- Li, Y.; Lu, Y. ETCC: Encrypted Two-Label Classification Using CNN. Secur. Commun. Netw. 2021, 2021, 6633250. [Google Scholar] [CrossRef]
- Hu, X.; Gu, C.; Chen, Y.; Wei, F. CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method. Sensors 2021, 21, 8231. [Google Scholar] [CrossRef] [PubMed]
- Bai, L.; Lu, H.; Liu, Y. High-Efficiency Observations:Compressive Sensing and Recovery of Seismic Waveform Data. Pure Appl. Geophys. 2020, 177, 469–485. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.H.; Choo, K.R.; Shen, J. A Cost-Sensitive Deep Learning-Based Approach for Network Traffic Classification. IEEE Trans. Netw. Serv. Manag. 2022, 19, 661–670. [Google Scholar] [CrossRef]
- Zhang, F.; Shang, T.; Liu, J. Imbalanced Encrypted Traffic Classification Scheme Using Random Forest. In Proceedings of the 2020 International Conferences on Internet of Things (iThings), Rhodes, Island, 2–6 November 2020; pp. 837–842. [Google Scholar]
- Park, S.; Park, H. Combined oversampling and undersampling method based on slow-start algorithm for imbalanced network traffic. Computing 2021, 103, 401–424. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wu, S. Research on Smoke Detection Algorithm Based on Convolutional Neural Network. Ph.D. Thesis, Southwest Jiaotong University, Chengdu, China, 2020. [Google Scholar]
- Peng, X.T. Method Study on Classification of Unbalanced Data Sets Based on Deep Learning. Master’s Thesis, Beijing University of Chemical Technology, Beijing, China, 2021. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.M.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Mahdy, A.M.S. A numerical method for solving the nonlinear equations of Emden-Fowler models. J. Ocean. Eng. Sci. 2022. [Google Scholar] [CrossRef]
- Choorod, P.; Weir, G. Tor Traffic Classification Based on Encrypted Payload Characteristics. In Proceedings of the 2021 National Computing Colleges Conference (NCCC), Taif, Saudi Arabia, 27–28 March 2021; pp. 1–6. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]




{kind=link}
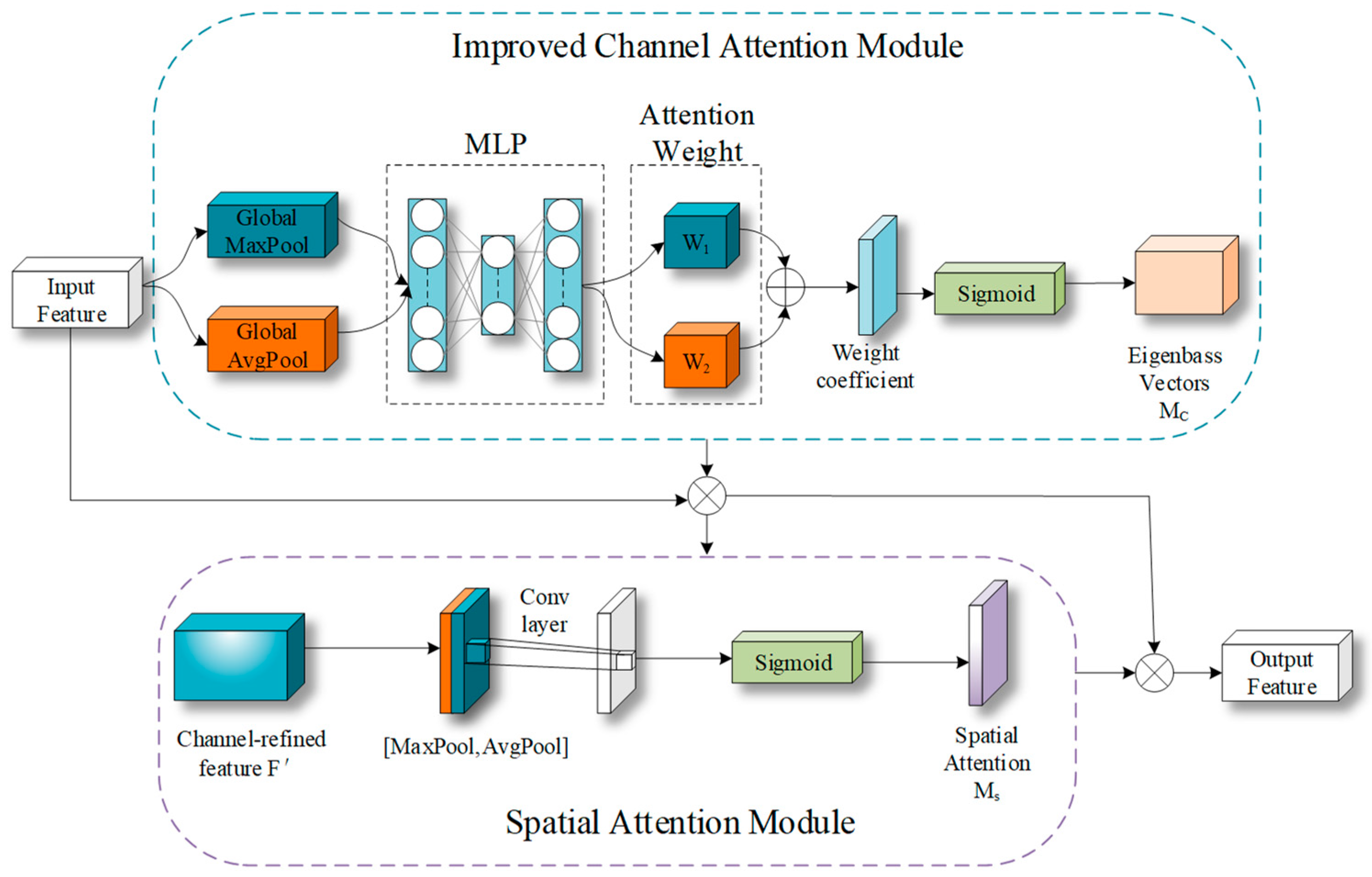{kind=link}
{kind=link}
| Category Distribution | ID | ID′ |
|---|---|---|
| [1,1,1,1,10] | 10 | 0.8000 |
| [2,4,6,8,10] | 5 | 0.2831 |
| [1,10,10,10,10] | 10 | 0.2000 |
| [10,10,10,10,10] | 1 | 0 |
| [1,10,100,1000,10000] | 10,000 | 2 |
| Category Distribution | ||
| [1,1,1,1,10] | 0.8000 | [3.1623,3.1623,3.1623,3.1623,1] |
| [2,4,6,8,10] | 0.2831 | [2.2361,1.5811,1.2910,1.1180,1] |
| [1,10,10,10,10] | 0.2000 | [3.1623,1,1,1,1] |
| [10,10,10,10,10] | 0 | [1,1,1,1,1] |
| [1,10,100,1000,10000] | 2 | [10,5.6234,3.1623,1.7783,1] |
| Service Category | Sample Size | Proportion (%) |
|---|---|---|
| VoIP | 684,601 | 54.20% |
| File transfer | 271,804 | 21.52% |
| P2P | 228,300 | 18.07% |
| Browsing | 39,323 | 3.11% |
| Video-streaming | 16,923 | 1.34% |
| Audio-streaming | 13,727 | 1.09% |
| 5076 | 0.40% | |
| Chat | 3419 | 0.27% |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Loss Function | |||||
| CE Loss | 69.95% | 73.71% | 79.82% | 81.34% | |
| 78.42% | 82.52% | 84.65% | 85.35% | ||
| 76.04% | 77.23% | 81.53% | 83.79% | ||
| 75.18% | 74.26% | 81.81% | 84.92% | ||
| 82.17% | 78.82% | 85.35% | 88.50% | ||
| 81.86% | 77.74% | 85.73% | 88.63% | ||
| 82.39% | 79.91% | 86.49% | 89.14% | ||
| 87.42% | 89.91% | 90.25% | 92.70% | ||
| 87.65% | 87.56% | 89.12% | 93.77% | ||
| 88.07% | 87.77% | 91.05% | 92.35% | ||
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Loss Function | |||||
| CE Loss | 72.33% | 71.62% | 74.07% | 71.19% | |
| 72.99% | 67.75% | 72.20% | 71.16% | ||
| 69.94% | 69.14% | 66.78% | 71.66% | ||
| 71.40% | 72.83% | 69.05% | 68.55% | ||
| 68.83% | 79.62% | 63.29% | 76.13% | ||
| 73.10% | 83.36% | 67.50% | 78.50% | ||
| 71.94% | 77.25% | 69.84% | 76.78% | ||
| 89.87% | 85.25% | 82.66% | 84.61% | ||
| 87.83% | 88.36% | 80.21% | 85.02% | ||
| 87.12% | 88.77% | 81.79% | 85.42% | ||
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Loss Function | |||||
| CE Loss | 71.12% | 72.65% | 76.84% | 75.93% | |
| 75.61% | 74.41% | 77.93% | 77.61% | ||
| 72.86% | 72.96% | 73.42% | 77.25% | ||
| 73.24% | 73.54% | 74.89% | 75.86% | ||
| 74.91% | 79.22% | 72.68% | 81.85% | ||
| 77.23% | 80.45% | 75.53% | 83.26% | ||
| 76.81% | 78.56% | 77.28% | 82.50% | ||
| 88.63% | 87.52% | 86.29% | 88.47% | ||
| 87.74% | 87.96% | 84.43% | 89.18% | ||
| 87.59% | 88.27% | 86.17% | 88.75% | ||
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Added Modules | |||||
| No attention module | 75.21% | 74.17% | 78.47% | 77.24% | |
| Spatial domain attention module | 77.85% | 75.88% | 78.89% | 77.17% | |
| Channel domain attention module | 75.59% | 77.29% | 79.27% | 79.55% | |
| CBAM module | 79.83% | 79.25% | 80.88% | 82.23% | |
| Improved CBAM module | 83.52% | 85.81% | 87.22% | 85.64% | |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Added Modules | |||||
| No attention module | 72.39% | 73.28% | 72.98% | 75.42% | |
| Spatial domain attention module | 71.84% | 75.14% | 74.51% | 77.09% | |
| Channel domain attention module | 74.51% | 75.53% | 75.26% | 76.15% | |
| CBAM module | 77.37% | 77.88% | 78.16% | 79.27% | |
| Improved CBAM module | 84.21% | 85.42% | 86.29% | 85.51% | |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | |
|---|---|---|---|---|---|
| Added Modules | |||||
| No attention module | 73.77% | 73.72% | 75.61% | 77.74% | |
| Spatial domain attention module | 74.71% | 75.51% | 76.63% | 78.99% | |
| Channel domain attention module | 74.05% | 76.40% | 77.21% | 78.65% | |
| CBAM module | 79.99% | 78.56% | 81.81% | 80.25% | |
| Improved CBAM module | 83.86% | 85.61% | 86.75% | 86.07% | |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 |
|---|---|---|---|---|
| Not CEFL loss | 75.21% | 74.17% | 78.47% | 77.24% |
| 87.42% | 89.91% | 90.25% | 92.70% | |
| Improved CBAM module | 83.52% | 85.81% | 87.22% | 85.64% |
| 89.04% | 90.53% | 90.75% | 93.28% |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 |
|---|---|---|---|---|
| Not CEFL loss | 72.39% | 73.28% | 72.98% | 75.42% |
| 89.87% | 85.25% | 82.66% | 84.61% | |
| Improved CBAM module | 84.21% | 85.42% | 86.29% | 85.51% |
| 90.26% | 89.84% | 90.17% | 91.71% |
| Classification Model | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 |
|---|---|---|---|---|
| Not CEFL loss | 73.77% | 73.72% | 75.61% | 77.74% |
| 88.63% | 87.52% | 86.29% | 88.47% | |
| Improved CBAM module | 83.86% | 85.61% | 86.75% | 86.07% |
| 91.14% | 90.68% | 91.44% | 92.49% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Liu, G.; Duan, K. A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function. Appl. Sci. 2022, 12, 9631. https://doi.org/10.3390/app12199631
Qin J, Liu G, Duan K. A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function. Applied Sciences. 2022; 12(19):9631. https://doi.org/10.3390/app12199631
Chicago/Turabian StyleQin, Jiayu, Guangjie Liu, and Kun Duan. 2022. "A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function" Applied Sciences 12, no. 19: 9631. https://doi.org/10.3390/app12199631
APA StyleQin, J., Liu, G., & Duan, K. (2022). A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function. Applied Sciences, 12(19), 9631. https://doi.org/10.3390/app12199631