Abstract
Emergency response systems require precise and accurate information about an incident to respond accordingly. An eyewitness report is one of the sources of such information. The research community has proposed diverse techniques to identify eyewitness messages from social media platforms. In our previous work, we created grammar rules by exploiting the language structure, linguistics, and word relations to automatically extract feature words to classify eyewitness messages for different disaster types. Our previous work adopted a manual classification technique and secured the maximum F-Score of 0.81, far less than the static dictionary-based approach with an F-Score of 0.92. In this work, we enhanced our work by adding more features and fine-tuning the Linguistic Rules to identify feature words related to Twitter Eyewitness messages for Disaster events, named as LR-TED approach. We used linguistic characteristics and labeled datasets to train several machine learning and deep learning classifiers for classifying eyewitness messages and secured a maximum F-score of 0.93. The proposed LR-TED can process millions of tweets in real-time and is scalable to diverse events and unseen content. In contrast, the static dictionary-based approaches require domain experts to create dictionaries of related words for all the identified features and disaster types. Additionally, LR-TED can be evaluated on different social media platforms to identify eyewitness reports for various disaster types in the future.
1. Introduction
In this digital age, the social media platforms such as Instagram, Twitter, and Facebook are commonly used by people across the globe in their daily routines. People share their ideas, information, opinions, and reviews about various things, topics, etc., [1,2] on these platforms. Twitter is widely used among these social media platforms due to its unique friendship model. Twitter follows a distinctive unidirectional relationship model where users do not have to follow back their followers to confirm their connections. Twitter handles 6000+ tweets every second, corresponding to over 500 million tweets daily by active users. The statistics are increasing by 30% a year (https://www.internetlivestats.com/twitter-statistics/ accessed on 15 June 2021) Over 130 million active users on Twitter are consuming and disseminating messages resulting in the collection of massive amounts of information. The users can get an overwhelming response with this massive amount of information. The true importance of such platforms can only be realized when timely information is extracted from the enormous amount of data shared by the users [3].
The capacity of Twitter in terms of event detection was also studied widely, and various techniques were proposed to detect events from tweets [4,5]. Researchers in this domain have proposed systems for news recommendations [6,7], sentiment analysis [8,9,10], disaster and emergency alerts [11], response systems [12,13], etc. Analyzing such data is essential for event detection, especially in emergency conditions due to natural disasters such as floods, hurricanes, fires, or earthquakes [1,14]. The studies have proven the importance of the credible information required for responding to such emergency conditions and that the eyewitness of the event can be a valuable resource for information relating to the events [14].
Twitter has proven its potential to be considered a news breaker. Studies have proven that 85% of Twitter’s trending topics are news headlines [3]. How does Twitter do that? The answer is by extracting valuable information from the tweets of eyewitness users. Following are some events that prove the capacity of Twitter for breaking the news:
- Delta Aircraft flight’s Emergency landing (http://channelnewsasia.com/news/world/delta-flight-middle-of-the-ocean-seattle-beijing-emergency-land-11062706, accessed on 20 July 2021): A tweet posted by one of the passengers of the flight about its emergency landing on a remote island in Alaska due to the potential engine failure was the source for the news agency about the incident.
- California Earthquake (https://latimesblogs.latimes.com/technology/2008/07/twitter-earthqu.html, accessed on 20 July 2021): Half a dozen tweets were available on Twitter about the earthquake, a minute before the recorded USGS (https://www.usgs.gov/, accessed on 20 July 2021) time.
- New York Airplane crashes at Hudson Bay (https://www.telegraph.co.uk/technology/twitter/4269765/New-York-plane-crash-Twitter-breaks-the-news-again.html, accessed on 25 July 2021): An eyewitness tweeted about the crash, and the information became the headline of the “Daily Telegraph”.
- Boston Bombing (https://en.wikipedia.org/wiki/Boston_Marathon_bombing, accessed on 25 July 2021): The eyewitness tweets about the bombing incident were available well before any news channel covered the incident.
- Westgate Shopping Mall attack (https://en.wikipedia.org/wiki/Westgate_shopping_mall_attack, accessed on 25 July 2021): This attack in Nairobi, Kenya, was on Twitter thirty-three minutes before any TV news channels.
A detailed study of the literature shows that the information shared by an eyewitness can clearly explain the severity of an incident. An eyewitness cannot be identified by just finding disaster-related keywords. The keywords may have come as a reference in the past, or from replies, re-tweets, or hashtags. Removing noise from such tweets is vital for accurately identifying a disaster event’s nature and severity.
Furthermore, the institutions responsible for responding to disastrous events need to rely on credible information from eyewitness sources to estimate the actual intensity and impact. Based on this reliable information, the agencies must take adequate measures to take control of the situation. Therefore, credible information is vital for such systems or institutions, and an eyewitness to the event is key in providing such information.
We identified from a comprehensive literature study that state-of-the-art approaches have adopted different techniques and features for identifying eyewitness reports. For instance, Zahra et al. [14] created an extensive feature list with domain experts’ help for extracting feature words to classify eyewitness tweets. The features description of manually crafted categories with example words in each category is shown in Table 1. For example, if a tweet contains “window shaking” or “water in basement”, that tweet is classified under “reporting small details of surroundings” and so on.

Table 1.
Characteristics for Eyewitness Identification (Zahra et al. [14]).
In our previous work [15], we implemented the grammar-rules-based approach for all the features identified in the baseline work of the dictionary-based approach adopted by Zahra et al. [14]. We exploited the linguistic features, language structure, and existing word relationships within a sentence. We identified that the relationship among the words in a sentence could be exploited to extract the feature words automatically. For the automatic extraction of features, we defined grammar rules and adopted the manual rule-based classification approach to classify the category of eyewitness messages and achieved the maximum F-Score of 0.81 [15]. In this work, we further fine-tuned the grammar rules and proposed new features for the identification of eyewitness messages. We used feature characteristics and labeled datasets to train several machine learning and deep learning classifiers for classifying eyewitness messages and secured a maximum F-score of 0.93.
The contributions of this work are summarized as follows:
- A generalized linguistic rule-based methodology (LR-TED) that is scalable to other domains to automatically extract eyewitness reports without relying on domain experts or platform-specific metadata, such as Twitter.
- Crafting and evaluating grammar rules to extract linguistic features from the textual content of a message and using them for annotating eyewitness messages.
- Using disaster-related linguistic features to train and evaluate several machine learning and deep learning models to classify the real-world Twitter dataset into “Eyewitness”, “Non-Eyewitness”, and ‘Unknown” classes.
- Comparative analysis of the proposed methodology with a baseline manually crafted dictionary-based approach using several evaluation metrics such as precision, recall, and F-score.
The rest of the paper is structured as follows—Section 2 reviews related work to summarize previous research on disaster event classification. Section 3 describes the methodology adopted for fine-tuning grammar rules to extract eyewitness features automatically. Evaluation and comparison results are discussed in Section 4. The concluding discussion and future work are presented in Section 5.
2. Literature Review
The effectiveness of a disaster management system relies on reliable information as input to the system. The research community has discussed the importance and effectiveness of information input to a disaster management system and its responses for relief and related recommendations [16,17]. One of the practical examples is the Twitter Earthquake Detector (TED) program, funded by the American Recovery and Reinvestment Act. It gathers real-time earthquake-related messages and applies location, time, and keyword filtering to track earthquakes to generate alerts and reports, such as USGS (https://gcn.com/articles/2009/12/21/usgs-earthquake-twitter-tweets.aspx accessed on 30 July 2021, https://www.usgs.gov/connect/social-media accessed on 30 July 2021). Similarly, San Diego State University has developed an emergency warning system (SDSU (https://phys.org/news/2014-10-viral-messaging-twitter-based-emergency.html accessed on 30 July 2021)) based on social media platforms for broadcasting emergency warnings to San Diego citizens. The institutions responsible for responding and providing relief services need precise, credible, and accurate information [18]. The person who witnesses an event (eyewitness) can accurately offer details such as the event’s intensity, precise location, number of fatalities, and other related information regarding an event. Extracting eyewitness reports from a large amount of Twitter data is challenging and still an open research area. Diakopoulos et al. [19] proposed the SRSR (Seriously Rapid Source Review) system to identify the eyewitness reports from millions of tweets associated with journalism. Olteanu et al. [20] proposed a systematic approach for examining a diverse set of information from criminal justice and natural disasters with the help of professional emergency managers as annotators.
On the other hand, Kumar et al. [21] utilized the users’ location information to identify local and remote users for a disaster event. Likewise, Morstatter et al. [22] used semantic patterns to identify a feature set to classify disaster events automatically. These studies adopted semantic patterns and location information to identify the sources. However, the concept of identifying an eyewitness account was not considered.
Processing millions of tweets to identify eyewitness reports remains a perplexing task and an open research area. Truelove et al. [23] presented and evaluated a theoretical model for identifying witness accounts and related accounts for various events. The study was evaluated using the incidents of shark sightings, concerts, protests, and cyclones, and the findings describe the impact of various factors that directly affect witnessing characteristics. Similarly, Doggett and Cantarero [24] presented a set of linguistic features to categorize disaster event-related tweets into two categories of “eyewitness” and “non-eyewitness”. The study utilized linguistic features such as filters to calculate the semantic similarity of the documents. The identified features demonstrated their importance in surfing the breaking news from social media platforms.
Various researchers further exploit the importance of linguistic features. For instance, Fang et al. [25] proposed an eyewitness identification approach by combining linguistics with meta-features. For topic classification, the authors adapted the word dictionary of LIWC (http://www.liwc.net/ accessed on 5 August 2021) and OpenCalais (http://www.opencalais.com/opencalais-api/ accessed on 5 August 2021) API. Similarly, Tanev et al. [26] presented a set of eyewitness features using metadata, stylistic, lexical, and semantics characteristics. The semantics dimensions cater to the “category definitions words”, e.g., “Shelter Needed”.
The summary of eyewitness feature-based techniques discussed above is presented in Table 2 with findings and limitations. The critical analysis shows that the research community has previously exploited different features to identify direct eyewitness sources, which are considered more credible. The existing research either focuses on retrieving location-related keywords or users’ location information from Twitter metadata to search for the local residents of disaster-hit areas. However, identifying location-related keywords does not guarantee that a disaster event has occurred at the location mentioned in the tweets. Using users’ location through GPS information attached to their posts is more reliable; however, the research reveals that only 1–3% of Tweets are geotagged, and relying solely on them may not provide enough data for decision-making [1,27].
Table 2.
Summary of Eyewitness Identification Techniques.
Recently, Zahra et al. [14] developed a comprehensive taxonomy and list of features to identify direct eyewitness posts independent from platform-specific metadata such as geoid. The authors proposed a methodology to categorize tweets using expert-driven engineering for disaster events. They identified a comprehensive feature list called domain-expert features based on their previous work, Zahra et al. [28]. The technique combines the textual features (bag of words) with domain-expert features to identify whether a source is an eyewitness or not. However, the work utilized a static-dictionary-based approach to annotate the Twitter dataset for classification. In this research, we have proposed the rule-based linguistic approach to automatically identify eyewitness tweets without relying on platform-specific metadata or human intervention. Hence, the approach is scalable to any domain and can be adopted to any type of disaster event.
3. Methodology
A block diagram of the overall design of the proposed system is shown in Figure 1. It consists of three main modules: pre-processing, feature extraction, and disaster event classification.
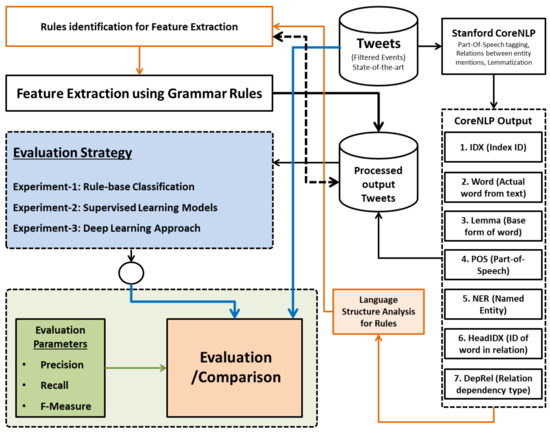
Figure 1.
Proposed “Linguistic Rules to classify Twitter Eyewitness messages for Disaster events (LR-TED)” approach.
First, we processed each tweet through a pre-processing module to remove any noise. Afterwards, the noise-free tweets were tokenized and annotated using the part-of-speech (POS) tagger. The selected tagger can also perform the lemmatization, NER, and entity-relationship functions. We used the CoreNLP tools that label every tweet word to the corresponding part-of-speech (POS) tag and also recognize the relationship among the words within the sentence. The output was then critically analyzed to identify the grammar rules for all features shown in Table 1.
The manually identified grammar rules were then converted into automatic functions and applied to the dataset to automatically extract feature words for each category. The next step was to identify the class of the tweets, such as “eyewitness”, “non-eyewitness”, or “Unknown” source, based on the extracted features. Machine learning and deep learning approaches were used for the classification task rather than manual rule-based classification. The following subsections briefly describe each process, from data set selection to results evaluation.
3.1. Gold-Standard Dataset
This work took advantage of an open dataset from CrisisNLP repository released by Zahra et al. [14]: https://crisisnlp.qcri.org/, accessed on 25 January 2021. The original dataset contained 25 million tweets from July 2016 to May 2018, collected using Twitter streaming APIs [28]. The dataset was refined by selecting the tweets that contained the focused keywords, such as “earthquake”, “foreshock”, “aftershock”, “hurricane”, “fire”, “forest fire”, “flood”, etc. We portioned the dataset into training and testing as follows:
Training Dataset: From these 25 million tweets, 2000 tweets representing each of three disaster types, hurricane, flood, and earthquake, were taken as the first dataset from 1 August 2017 to 28 August 2017 for manual analysis. The details of sample tweets taken for training and analysis of the proposed approach are shown in Table 3.
Table 3.
Statistics of Training Dataset.
Testing Dataset: The second dataset comprises 8000 tweets, excluding those used in the training dataset. These were picked randomly from the original collection and annotated using the state-of-the-art crowdsourcing methodology. The detail of the testing dataset is presented in Table 4. The dataset equally represents each disaster type, such as earthquake, flood, hurricane and wildfire.
Table 4.
Statistics of Evaluation Dataset.
The dataset also includes the annotated data gathered through manual analysis and crowdsourcing. Therefore, to compare the results generated by the proposed technique, we used the same dataset as the gold standard.
3.2. Pre-Processing
The language used in tweets generally does not follow the grammar rules of writing and needs some cleaning of data before being used by a system. In the pre-processing module, we used core NLP tools for removing hashtags, HTML tags, special symbols, extra white spaces, etc. The pre-processed data is then fed to the next phase of the proposed system for linguistic processing.
3.3. Linguistics Processing
Part-of-speech (POS) tagging is one of the most important tasks for language processing. Previously, many approaches have been used to parse tweets, for instance, Kong et al. presented TweeboParser by exploiting the TurboParser [29]. Similarly, Liu et al. analyzed tweets with universal dependencies (UD) by defining the extended guidelines for tweets tokenization [30]. Jurafsky [31] have comprehensively discussed the part-of-speech (POS) tagging and different tag-sets and the related approaches to adopting those tag-sets. The Stanford, Lancaster Oslo/Bergen (LOB), CLAWS, VOLSUNGA, POS Tagger, etc., are briefly introduced, and Stanford NER achieved an accuracy of 97.4%, among others [31]. Therefore, it was widely applied to various text types and for diverse entity types, such as blogs, tweets, newspapers, locations, fictions, persons, chemicals, etc.
The list of all requirements with part-of-speech tagging to understand the structure and linguistics features of content includes the following.
- Tokens: Tokenization of the tweet content.
- POS: Part-of-speech for tagging of each word.
- NER: Named entity recognition for entity identification.
- LEMMA: Lemmatization for getting the base word.
- DepRel: Relation dependency among words.
The Stanford CoreNLP is a natural language processing (NLP) toolkit that includes various grammatical analysis tools, including a parser, named entity recognizer (NER), part-of-speech (POS) tagger, sentiment analysis, and open information extraction tools, etc. and its worth is well proven in the domain of natural language processing [32,33]. The accuracy of its NER and POS tagging is exploited by researchers of this domain with high accuracy of around 97.4%. It also has the edge over similar approaches in that it has a complete package of different grammar rules.
3.4. Evaluation Strategy
Each tweet of the dataset was annotated, and the results were saved in a separate dataset for detailed study and evaluation. From a comprehensive study of the annotated dataset, it was identified that the structure of the language and the dependency relationship of words could be exploited to extract the feature words from the tweets’ content automatically. We have proposed language structure-based grammar rules for every identified feature, whereas Zahra’s approach adopted the manually created static dictionaries for feature extraction. The grammar rules for each identified feature are discussed in Section 4 with examples.
The defined rules were then applied to each annotated tweet from the dataset that was saved separately from the benchmark dataset. Zahra’s approach has not discussed any approach or methodology that explains the process of marking a tweet, with identified feature-word, as an eyewitness, non-eyewitness, or unknown. For example, if a tweet contains a feature word that explains the surrounding details, and no other feature is identified even with the human eye, what is the threshold to accept that tweet as an eyewitness? Our previous work presented a manual approach to answering this problem [15]. In this work, we have conducted different experiments by adopting supervised machine learning and deep learning models to classify different disaster types automatically. We aim to select the best model for the proposed LR-TED approach based on its performance.
Different evaluation metrics, such as precision, recall, and F-measures, are used to evaluate the proposed LE-TED approach. Previously, researchers have used the same measure to evaluate results in similar domains. For instance, Zahra et al. [14] utilized the same measure to evaluate the performance of classification algorithms trained on text-based and human expert features. Similarly, in our previous work [15], we adopted the same evaluation parameters for calculating the effectiveness of the rule-based classification technique for disaster event classification.
4. Grammar Rule-Based Feature Extraction
Recent approaches for the identification of eyewitnesses adopted the technique of feature identification and were comprehensively discussed and exploited by researchers in this domain [14,25,26]. Based on the idea of identifying eyewitnesses by features from content, a recent approach proposed a diversified set of features for identifying eyewitnesses from the text. Learning and applying the concept of automatically extracting the feature words using grammar rules to identify eyewitness reports without human interaction is the main contribution of this work. The rules are presented in our previous work [15], and in this work, we have fine-tuned those grammar rules, and added some new rule-based features for eyewitness identification, explained in the following sections.
4.1. Parsing of Tweets (Stanford CoreNLP)
We adapted a Java suite of Core NLP tools [34] for our initial work [15]. The annotated result of each tweet is stored in the same database to evaluate further and compare the results. For example, as explained above, we have the tweet’s text: “The house is shaking…Its an earthquake”. The CoreNLP output in CoNLL format (https://nlp.stanford.edu/nlp/javadoc/javanlp-3.5.0/edu/stanford/nlp/pipeline/CoNLLOutputter.html accessed on 16 August 2021), the standard output of Stanford CoreNLP corresponding to this tweet, is shown in Table 5.
Table 5.
Stanford CoreNLP Output.
In Table 5, the first column, “IDX”, is the Index-ID of the word. Column-2 contains the actual word extracted directly from the text. The third column, “Lemma”, has the base word. Column-4 “POS” has the corresponding fine-grained part-of-speech tag of the word, which is defined using Penn-Treebank-Tagset (see https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html/ accessed on 4 September 2021). Column-5 is “NER”, which has the corresponding Named-Entity tag of the focused word. Columns 6 and 7, “HeadIDX” and “DepRel”, where “HeadIDX” represents Index-IDs of the related word or zero, and DepRl represents the dependency relation type, and the details are available on https://nlp.stanford.edu/software/dependencies_manual.pdf/ accessed on 10 September 2021.
4.2. Feature Extraction
In this work, we have adopted thirteen disaster-related static dictionary-based features identified by Zahra et al. [14]. We added one new feature labeled “No URL”, directly indicating whether the information is firsthand or has been referred from other sources. The feature is adopted by different researchers for the identification of firsthand information. We coded grammar rules to extract these features automatically, as shown in Table 6. The comment column explains how rules are crafted and feature dropped by the static-dictionary-based approach for extracting direct eyewitness reports. Static dictionary-based implementation has adopted only four features, namely, “Words indicating perceptual senses”, “First-person pronouns and adjectives”, “Exclamation and question marks”, and “Expletives”. For the feature “Short length of tweet”, a straightforward approach to the word count was used. For the remaining features, grammar rules are explained in Table 6.
Table 6.
Grammar-Rules for Extraction of Feature-Words.
5. Experiments and Results
In the following subsections, we have briefly explained the results generated by each machine-learning and deep learning model adopted for the proposed approach.
5.1. Dataset Description and Pre-Processing
In our previous work, we evaluated our approach by adopting the dataset of 8000 tweets on earthquakes, hurricanes, floods, and wildfires. In this work, we used the same database to perform our experiments with machine-learning and deep-learning models. Since each tweet in the dataset contains the annotations performed by using Zahra’s approach [14]. The statistics of each category, “Eyewitness”, “Non-Eyewitness”, and “Unknown”, are illustrated in Table 4 in Section 3.1.
Since the dataset is already utilized and updated by [14,15], it contained only a few tweets that required the pre-processing steps. As the same database was used in our previous experiments on rules-based classification, we already have pre-processed data. A total of 2942 such tweets exist with “ ’ “ or comma as a character that might disturb our rules. Such tweets were handled through the pre-processing phase. The annotated results were added to the same database against each tweet. In this work, we used the same dataset as the benchmark to compare the results of the proposed LR-TED with the static dictionary-based approach [14].
5.2. Parsing and Extracting Features
In the next step, basic pre-processing was done to perform tokenization, part-of-speech (POS) tagging, named entity recognition (NER), lemmatization, and dependency relation. The Stanford CoreNLP tool was used for pre-processing. Each tweet from the dataset is processed through the Stanford CoreNLP tool. As a result, 22,932 rows were generated with all essential features discussed in Section 4.1.
In the next step, the feature words for each category were extracted using grammar rules. Since there is no automatic way to validate the correctness of the rule-based features, we manually validated the correctness of extracted feature words with the help of a domain expert. The comparative results of manually extracted feature words by the language expert and automatically extracted feature words by the rule-based module are shown in Table 7.
Table 7.
Comparison of rule-based feature words extraction with manual extraction.
From Table 7, it is evident that automatically extracting the feature words using linguistic grammar rules achieved a significant F-score for each feature category. There is a slight difference in feature extraction compared to features extracted by the language expert, except for Feature-13, which corresponds to location of a disaster event. The reason is that location can be expressed in many ways, such as country, state, region, city, street etc. and more complex rules/understanding is required to map a location precisely. In future, we intend to define more complex rules for extracting location features; however, in this research, we only focus on reasonable feasibility of adapting linguistic rules for automatic feature extraction to classify eyewitness messages.
5.3. Impact of Dropped and New Features
This subsection discusses the impact of the dropped and added new features corresponding to the static dictionary-based approach by Zahra et al. [14]. The results are shown in Table 8, Table 9 and Table 10 using the evaluation parameter “Pr” for precision, “Re” for recall, and “F1” for F-Score.
Table 8.
Experiment-1: Manual Classification (F-Scores) 10-Features.
Table 9.
Experiment-1: Manual Classification (F-Scores) 13-Features.
Table 10.
Experiment-1: Manual Classification (F-Scores) with New Feature.
5.4. Results of Proposed LR-TED Approach
We evaluated Random Forest, Naive Bayes, and SVM models from the machine learning category of classification models on the selected dataset of tweets for each disaster type; earthquake, flood, hurricane, and wildfire. The 10-fold cross-validation strategy was used to evaluate the results. For the deep learning category of classification models, we experimented with Artificial Neural Network (ANN), Recurrent Neural Network (RNN), and Convolutional Neural Networks (CNN) models. Implementation of these models is done through WEKA GUI tools (https://www.cs.waikato.ac.nz/ml/weka/ accessed on 3 October 2021). WEKA is a GUI (graphical user interface) based open source machine learning software used by researchers in similar applications [35,36,37]. Based on the performance of the models, we selected the ANN model for the proposed LR-TED approach. The results of each model are further evaluated and discussed in the following section.
5.5. Comparison of Proposed LR-TED Approach with the Static-Dictionary-Based Approach
We independently evaluated all thirteen features used in the static approach and the newly added feature. The results are compared with the static-dictionary-based approach [14] for each disaster type and feature category. The F-Scores comparison of the LR-TED approach by adopting the ANN deep-learning model for classification and the F-scores of the dictionary-based approach is shown in Table 11. The category names are denoted as; “Ew” for eyewitness, “Un” for unknown, and “NEw” for non-eyewitness. It can be observed from Table 11 that Zahra’s approach achieved the best f-score of “0.92” for the earthquake type. The LR-TED approach, using the grammar rules, secured the best F-score of “0.93” for the same disaster type. Furthermore, the results for both eyewitness and non-eyewitness classes for earthquake events were higher than those produced by Zahra’s approach. However, this work eventually identifies eyewitness reports from tweet content without utilizing any static dictionary and human intervention.
Table 11.
Comparison of LR-TED and Zahra’s Approach.
In the hurricane disaster category, LR-TED has shown a better F-score for eyewitnesses (“0.60”) as compared to Zahra’s approach, which is “0.51”. Similarly, low F-scores were observed for wildfire disasters by Zahra’s approach. Likewise, comparative results were observed for flood and wildfire disaster categories by the LR-TED approach. Overall, it is evident from the comparative results that the LR-TED approach generated competitive results for the eyewitness category but did not beat the results secured by Zahra’s approach in all categories. The reason for such results could be the training dataset, which contains a small number of tweets to train the model. To implement the concept of a generalized approach, such variations in the performance of the LR-TED approach are acceptable.
5.6. Comparison of Proposed LR-TED Approach with Zahra’s Approach (All Experiments)
In this subsection, we present the complete results achieved from each model in our experiments. Table 12 illustrates the F-scores achieved using different models for each disaster type “eyewitness” class. Similarly, Table 13 is for the “non-eyewitness” class, and Table 14 is for the “unknown” class.
Table 12.
Comparison of Results—Eyewitness (All Experiments).
Table 13.
Comparison of Results—Non-Eyewitness (All Experiments).
Table 14.
Comparison of Results—Unknown (All Experiments).
In this work, our focus is to identify the “eyewitness” class and all the results discussed in the above sections are at the model level. From Table 12, for the comparison of different experiments of eyewitness class, the maximum f-scores achieved are 0.93, 0.52, 0.60, and 0.26 for earthquake, flood, hurricane, and wildfire events, respectively. As an individual approach for eyewitness class, the LR-TED approach has produced better results for three out of four disaster types and comparative results for flood disaster types. The LR-TED outperformed Zahra’s approach for earthquake and hurricane disaster types and produced comparative scores for the remaining two disaster types. These scores can be considered significant scores by an automated process without using a static dictionary.
From the above experiments, LR-TED, SVM, Naive Bayes, and Random Forest algorithms performed best for eyewitness, non-eyewitness, and unknown categories, respectively. LR-TED scores remained the best among other models for each disaster type. When comparing the scores with Zahra’s approach, we have demonstrated that the proposed LR-TED approach performs best or achieved comparative results considering that LR-TED is a fully automatic approach without using the static dictionary as the baseline approach. After a comprehensive study and detailed experiments, we finally selected the ANN model as part of the LR-TED approach for classifying eyewitness tweets. The same observation is found in Zahra’s approach, where the identified features perform best for earthquake events. Table 15 shows the comparative results of precision, recall, and F-score for the ANN model based on LR-TED and Zahra’s approach.
Table 15.
A comparative analysis of the ANN model.
Since the proposed LR-TED technique automatically extracts the feature words without involving any human interaction to create and maintain the dictionary of feature words manually, hence, we can claim that the grammar rule-based LR-TED approach could be deemed a potential method for identifying eyewitness tweets, particularly in scenarios where potentially millions of tweets need to be processed quickly and for unknown events.
6. Conclusions and Future Work
Identifying eyewitnesses from Twitter is useful for supporting disaster relief activities. It is an active research area, and diverse methods have been proposed in the literature. In this work, we proposed a method that utilizes language structure, linguistics, and word relation to extract the feature set automatically. We proposed a generic approach that covers different disaster types. The proposed approach is evaluated on the benchmark dataset, and results are compared with a baseline static-dictionary-based approach. The evaluation results show that the proposed LR-TED approach achieved an F-score of 0.93 and competes with the high score achieved by the manually crafted dictionary-based approach in the same category. The implication of the proposed technique can be recognized when we have to process potentially millions of tweets to respond to the event at the earliest.
The implication of this research work can be a potential contribution to various applications in this domain, such as disaster management systems, disaster or emergency alert systems, emergency response for institutes and agencies, etc. In the future, the use of manually created static dictionaries will not be required for the identification of the important feature terms from the text for eyewitness identification. Furthermore, the proposed LR-TED approach is saleable on social media platforms other than Twitter and for various disaster types.
This research has opened a debate on adapting linguistic rules for feature extraction instead of relying on manually crafted dictionaries to automatically classify eyewitness messages. The proposed LR-TED approach has the capability to dynamically extract feature terms using linguistic rules, hence, scalable to diverse disaster types and unseen contents in the English language. The main limitation of the proposed LR-TED approach is its lack of applicability to other languages. Since each language has its own set of grammar rules and structure, it is difficult to adapt linguistic features of one language to others. In future, we plan to extend LR-TED capabilities to other languages by developing more general and language specify rules.
Author Contributions
Conceptualization, S.H., A.M., S.K. and M.T.A.; funding acquisition, S.K. and M.A.; methodology, S.H., A.M., S.K. and M.T.A.; project administration, A.M. and S.K.; resources, S.K. and M.A.; supervision, A.M. and M.T.A.; validation, S.H., A.M. and M.A.; writing—original draft, S.H.; Writing—review and editing, S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deputyship for Research and Innovation, Ministry of Education in Saudi Arabia, project number 523.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research and Innovation, Ministry of Education in Saudi Arabia, for funding this research work through project number 523.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: A survey. ACM Comput. Surv. (CSUR) 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Vieweg, S.; Hughes, A.L.; Starbird, K.; Palen, L. Microblogging during Two Natural Hazards Events: What Twitter May Contribute to Situational Awareness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 1079–1088. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 591–600. [Google Scholar]
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Khatoon, S.; Alshamari, M.A.; Asif, A.; Hasan, M.M.; Abdou, S.; Elsayed, K.M.; Rashwan, M. Development of social media analytics system for emergency event detection and crisismanagement. Comput. Mater. Contin. 2021, 68, 3079–3100. [Google Scholar]
- Anandhan, A.; Shuib, L.; Ismail, M.A. Microblogging Hashtag Recommendation Considering Additional Metadata. In Intelligent Computing and Innovation on Data Science; Lecture Notes in Networks and Systems; Springer: Singapore, 2020; Volume 118, pp. 495–505. [Google Scholar]
- Jain, D.K.; Kumar, A.; Sharma, V. Tweet recommender model using adaptive neuro-fuzzy inference system. Future Gener. Comput. Syst. 2020, 112, 996–1009. [Google Scholar] [CrossRef]
- Khatoon, S.; Romman, L.A.; Hasan, M.M. Domain independent automatic labeling system for large-scale social data using Lexicon and web-based augmentation. Inf. Technol. Control 2020, 49, 36–54. [Google Scholar] [CrossRef]
- AlGhamdi, N.; Khatoon, S.; Alshamari, M. Multi-Aspect Oriented Sentiment Classification: Prior Knowledge Topic Modelling and Ensemble Learning Classifier Approach. Appl. Sci. 2022, 12, 4066. [Google Scholar] [CrossRef]
- Abu Romman, L.; Syed, S.K.; Alshmari, M.; Hasan, M.M. Improving Sentiment Classification for Large-Scale Social Reviews Using Stack Generalization. In Proceedings of the International Conference on Emerging Technologies and Intelligent Systems; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2021; Volume 322, pp. 117–130. [Google Scholar] [CrossRef]
- AlAbdulaali, A.; Asif, A.; Khatoon, S.; Alshamari, M. Designing Multimodal Interactive Dashboard of Disaster Management Systems. Sensors 2022, 22, 4292. [Google Scholar] [CrossRef] [PubMed]
- Khatoon, S.; Asif, A.; Hasan, M.M.; Alshamari, M. Social Media-Based Intelligence for Disaster Response and Management in Smart Cities. In Artificial Intelligence, Machine Learning, and Optimization Tools for Smart Cities: Designing for Sustainability; Pardalos, P.M., Rassia, S.T., Tsokas, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 211–235. [Google Scholar]
- Imran, M.; Castillo, C.; Lucas, J.; Meier, P.; Vieweg, S. AIDR: Artificial intelligence for disaster response. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 159–162. [Google Scholar]
- Zahra, K.; Imran, M.; Ostermann, F.O. Automatic identification of eyewitness messages on twitter during disasters. Inf. Process. Manag. 2020, 57, 102107. [Google Scholar] [CrossRef]
- Haider, S.; Afzal, M.T. Autonomous eyewitness identification by employing linguistic rules for disaster events. CMC-Comput. Mater. Contin. 2021, 66, 481–498. [Google Scholar] [CrossRef]
- Haworth, B.; Bruce, E. A review of volunteered geographic information for disaster management. Geogr. Compass 2015, 9, 237–250. [Google Scholar] [CrossRef]
- Landwehr, P.M.; Carley, K.M. Social media in disaster relief. In Data Mining and Knowledge Discovery for Big Data; Springer: Berlin/Heidelberg, Germany, 2014; Volume 1, pp. 225–257. [Google Scholar] [CrossRef]
- Truelove, M.; Vasardani, M.; Winter, S. Towards credibility of micro-blogs: Characterising witness accounts. GeoJournal 2015, 80, 339–359. [Google Scholar] [CrossRef]
- Diakopoulos, N.; De Choudhury, M.; Naaman, M. Finding and Assessing Social Media Information Sources in the Context of Journalism. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 2451–2460. [Google Scholar]
- Olteanu, A.; Vieweg, S.; Castillo, C. What to expect when the unexpected happens: Social media communications across crises. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 994–1009. [Google Scholar]
- Kumar, S.; Morstatter, F.; Zafarani, R.; Liu, H. Whom should I follow? Identifying relevant users during crises. In Proceedings of the 24th ACM Conference on Hypertext and Social Media, Paris, France, 1–3 May 2013; pp. 139–147. [Google Scholar]
- Morstatter, F.; Lubold, N.; Pon-Barry, H.; Pfeffer, J.; Liu, H. Finding eyewitness tweets during crises. arXiv 2014, arXiv:1403.1773. [Google Scholar]
- Truelove, M.; Vasardani, M.; Winter, S. Testing a model of witness accounts in social media. In Proceedings of the 8th Workshop on Geographic Information Retrieval, Fort Worth, TX, USA, 4–7 November 2014; pp. 1–8. [Google Scholar]
- Doggett, E.; Cantarero, A. Identifying eyewitness news-worthy events on twitter. In Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media, Austin, TX, USA, 1 November 2016; 2016; pp. 7–13. [Google Scholar]
- Fang, R.; Nourbakhsh, A.; Liu, X.; Shah, S.; Li, Q. Witness identification in twitter. In Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media, Austin, TX, USA, 1 November 2016; pp. 65–73. [Google Scholar]
- Tanev, H.; Zavarella, V.; Steinberger, J. Monitoring disaster impact: Detecting micro-events and eyewitness reports in mainstream and social media. In Proceedings of the 14th ISCRAM Conference, Albi, France, 21–24 May 2017. [Google Scholar]
- Essam, N.; Moussa, A.M.; Elsayed, K.M.; Abdou, S.; Rashwan, M.; Khatoon, S.; Hasan, M.M.; Asif, A.; Alshamari, M.A. Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models. Appl. Sci. 2021, 11, 11328. [Google Scholar] [CrossRef]
- Zahra, K.; Ostermann, F.O.; Purves, R.S. Geographic variability of Twitter usage characteristics during disaster events. Geo-Spat. Inf. Sci. 2017, 20, 231–240. [Google Scholar] [CrossRef]
- Kong, L.; Schneider, N.; Swayamdipta, S.; Bhatia, A.; Dyer, C.; Smith, N.A. A dependency parser for tweets. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1001–1012. [Google Scholar]
- Liu, Y.; Zhu, Y.; Che, W.; Qin, B.; Schneider, N.; Smith, N.A. Parsing tweets into universal dependencies. arXiv 2018, arXiv:1804.08228. [Google Scholar]
- Jurafsky, D. Speech & Language Processing; Pearson Education: London, UK, 2000; ISBN ISBN 9788131716724. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C.D. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Gui, T.; Zhang, Q.; Huang, H.; Peng, M.; Huang, X.-J. Part-of-speech tagging for twitter with adversarial neural networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2411–2420. [Google Scholar]
- CoreNLP. Available online: https://stanfordnlp.github.io/CoreNLP/ (accessed on 15 December 2021).
- Barua, K.; Chakrabarti, P.; Panwar, A.; Ghosh, A. A Predictive Analytical Model in Education Scenario based on Critical Thinking using WEKA. Int. J. Technol. Res. Manag. 2018, 5. Available online: https://www.academia.edu/36468698/A_Predictive_Analytical_Model_in_Education_Scenario_based_on_Critical_Thinking_using_WEKA (accessed on 15 December 2021).
- Desai, A.; Sunil, R. Analysis of machine learning algorithms using WEKA. Int. J. Comput. Appl. 2012, 975, 8887. [Google Scholar]
- Sharma, P. Comparative analysis of various clustering algorithms using WEKA. Int. Res. J. Eng. Technol. 2015, 2, 107–112. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).