1. Introduction
Unlike using recommendations of relatives and friends in the past, people increasingly make hotel booking decisions relying on online reviews on various online travel platforms in the modern era. Hotel online reviews are posted by numerous customers according to their experiences in hotels, which are perceived as more objective, trustworthy and helpful than information provided by hotels [
1,
2]. Online reviews generally consist of online ratings and textual reviews. Online ratings signal customer satisfaction or dissatisfaction with hotels. Textual reviews contain customers’ actual expectations, feelings and perceptions about hotel services. According to bounded rationality model, customers are unable to elaborate and extract useful information from numerous and heterogeneous data, thus driving them to prefer and rely more on ratings than on textual reviews [
3]. As more and more potential customers regard the online ratings as one of the direct references of hotel quality when selecting hotels, it is crucial for hotels to obtain high customer ratings to achieve the goal of improving online bookings [
4,
5]. Therefore, exploring what contributes to the difference in online ratings between satisfied and dissatisfied customers is particularly important for hotels. In other words, for the purpose of being competitive sustainably in the hospitality industry, it is critical for hotels to understand the determinants of customer satisfaction and dissatisfaction which are proxied by online ratings [
6,
7].
Existing studies have proved that the performance of multiple hotel attributes is strongly correlated with customer satisfaction [
8,
9,
10]. Most studies have investigated the hotel attributes that lead to customer satisfaction and dissatisfaction through surveys [
11,
12,
13]. Recently, with the development of data mining techniques, online reviews serve as the promising data source for customer satisfaction analysis. Several scholars have analyzed the attribute performance through online reviews using sentiment analysis methods, and hence found the determinants of customer satisfaction in the hotel industry [
14,
15]. However, these studies processed hotel reviews as a whole dataset, neglecting discriminating positive and negative reviews. Processing hotel reviews as a whole can compare the overall performance of multiple attributes from the perspective of all customers but could not distinguish between contributors of customer satisfaction and factors resulting in customer dissatisfaction. Previous studies have found that dual-valence (that is, featuring both positive and negative sentiment) reviews existing in hotels of one–five-star ratings [
16,
17]. The presence of negative sentiment toward attributes in positive reviews and positive sentiment toward attributes in negative reviews was observed [
18,
19,
20]. In other words, even if the performance of several hotel attributes does not meet customer expectations, customers are still satisfied with the hotel and give high ratings to the hotel because of the good performance of other hotel attributes. Meanwhile, customers can be very dissatisfied with the hotel and give low ratings to hotels when the performance of some certain hotel attributes is poor, even though they think other hotel attributes perform well. Therefore, it’s necessary to investigate the following question:
Research Question 1 (RQ1). Which hotel attribute with good performance contributes to high customer ratings and which hotel attribute with poor performance causes low customer ratings?
In fact, it should be pointed out that customers’ expectations and perceptions vary across different market segments, such as different hotel star ratings [
14,
21]. Exploring the determinants of customer satisfaction and dissatisfaction of each market segment is beneficial for making more appropriate and precise strategies [
10]. Moreover, it is helpful for hotel managers to understand customer demands for different star hotels in the decision-making of marching into new markets through comparing the difference of attribute performance in different star hotels. However, whether the hotel attribute contributing to high/low customer ratings varies across different star hotels has not been verified. Therefore, this study intends to investigate the following question:
Research Question 2 (RQ2). Does the hotel attribute contributing to high/low customer ratings vary across different star hotels?
To answer the above two questions, it is necessary to analyze the effect of attribute performance on customer satisfaction. Customers’ preferences, expectations and perceptions on each hotel attribute are influenced by comprehensive factors, thus driving positive and negative customer evaluations toward the bidirectional (good and poor) performance of hotel attributes [
22]. Traditionally, one unit increase in good performance and one unit decrease in poor performance concerning a certain hotel attribute should cause the same change of customer satisfaction, thus the relationship between attribute performance and customer satisfaction is assumed to be linear or symmetric [
23]. However, some studies have demonstrated that some attributes provide more satisfaction than dissatisfaction [
24,
25,
26]. In other words, hotel attributes can have asymmetric effects on customer satisfaction [
24]. The Kano model was proposed by Kano et al. (1984) to identify these non-linear or asymmetric relationships between attribute performance and customer satisfaction. The Kano model is often applied to classify hotel attributes into different categories in terms of customer demands, which is helpful for hotel managers to better understand customer expectations and perceptions [
27,
28]. Meanwhile, considering the limited hotel resources, it is critical to determine attribute priority to maximize customer satisfaction through service improvement. Many studies have shown that applying a combination of the Kano model and importance-performance analysis (IPA) in customer satisfaction analysis can not only analyze customer requirements toward service attributes, but also determine attribute priority [
10,
29,
30,
31,
32,
33]. The IPA is a common and effective technique to formulate improvement strategies according to the importance and performance of the attribute [
34]. However, existing studies concerning the Kano-IPA model are mainly based on surveys, and few studies use online reviews as a data source for the Kano-IPA model. There are two main reasons limiting the application of the Kano-IPA model in online reviews. On the one hand, online textual reviews are unstructured and therefore need to be processed before they can be converted into usable structured data. On the other hand, there is a question of how to apply the processed data to the customer satisfaction model to obtain different Kano categories. Considering online reviews serving as promising data source for analyzing and improving hotel services, this study intends to apply feature extraction and natural language processing (NLP) techniques to conduct Kano-IPA model through online reviews.
In summary, this study aims to identify the well-performed attributes contributing to high customer ratings and poorly performed attributes causing low customer ratings for different star hotels. For this, firstly, we distinguish between positive and negative reviews for different star hotels according to online ratings. Next, we apply feature extraction and sentiment analysis techniques to explore bidirectional performance of hotel attributes. In particular, a new sentiment lexicon for hospitality domain was built from numerous online reviews using the PolarityRank algorithm. To further understand customers’ rating behaviors and demands for hotel service, this study intends to conduct the Kano-IPA model through online reviews for attribute classification and prioritizing. We propose an approach to classify attributes into the Kano model, which provides convenience for the application of the Kano model in textual reviews. Lastly, the comparative analysis of attribute performance and priority rankings is carried out to enhance the understanding of customers’ demands for different star hotels.
The remainder of this paper is organized as follows.
Section 2 briefly reviews the relevant literature to provide the motivation for this study.
Section 3 presents the framework and methodology employed in this study.
Section 4 presents the results and provides some discussion of this study.
Section 5 concludes and offers theoretical and practical implications, limitations, and directions for future research.
3. Materials and Methods
The main objective of this study is to explore what contributes to the difference in hotel customer ratings for different star hotels. Specifically, this study identifies well-performed attributes contributing to high customer ratings and poorly performed attributes causing low customer ratings in terms of hotel star ratings by exploring the bidirectional performance of hotel attributes. This study also aims to apply the Kano-IPA model in online textual reviews for a better understanding of customers’ rating behaviors and demands, and hence provides effective attribute improvement strategies for different star hotels.
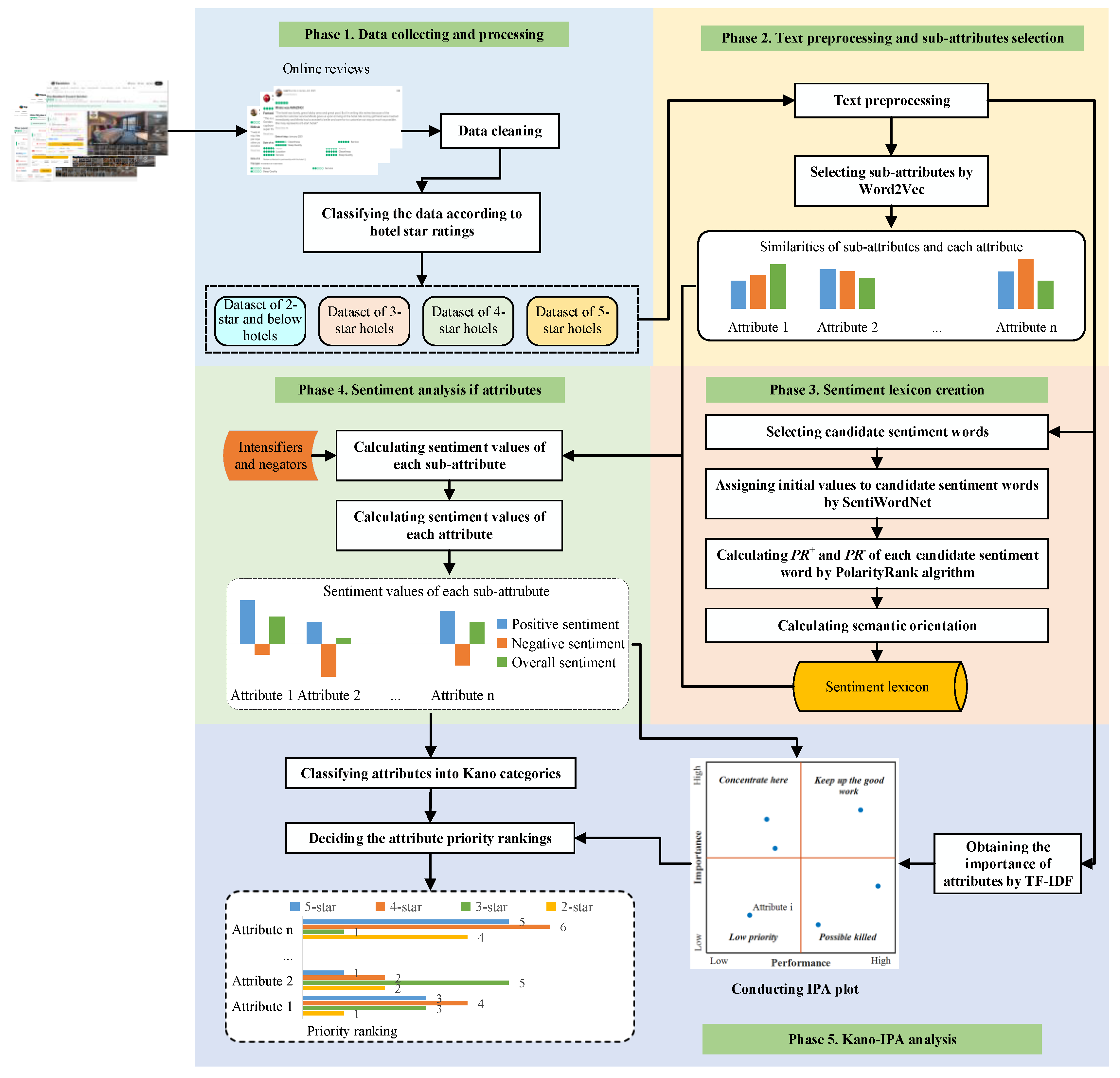
In this section, we propose a methodology to realize the above objectives and the structure of this methodology framework is shown in
Figure 3. First, we collected data from TripAdvisor.com and processed the data according to hotel star ratings and customer ratings. Second, sub-attributes of six hotel attributes (value, location, service, room, cleanliness and sleep quality) that customers mentioned in online reviews were extracted. Specifically, similar terms and the similarity under each attribute are identified through the Word2Vec algorithm. Third, a sentiment lexicon for the hospitality domain to obtain sentiment values of each attribute and sub-attribute was obtained through the PolarityRank algorithm. Fourth, well-performed attributes that contribute to customer satisfaction and poorly performed attributes that cause customer dissatisfaction were identified for hotels of different star ratings through sentiment analysis. Finally, the above results by text mining were applied to conduct the Kano-IPA analysis for different star hotels. In particular, a novel approach for Kano model classification is proposed. Thus, the improvement strategies and priority of attributes are provided for different star hotels.
3.1. Data Collecting and Processing
We collected hotel online reviews in London from TripAdvisor.com, which is the world’s largest travel-sharing website. TripAdvisor.com contains millions of unbiased user-generated reviews from customers worldwide; thus, it’s feasible to collect a large volume of online reviews. The data collection and processing steps in this paper are as follows.
First, hotels in London were selected as data source for this research. London is one of the largest financial centers in Europe, as well as one of the world’s most famous tourist attractions. It attracts millions of customers across the world. Statistically, London recorded 28.47 million bed nights of domestic tourists and 118.9 million nights of international visitors in 2019 [
89,
90].
Second, we crawled all available information at both hotel-level and review-level in London using a Python program. The hotels with fewer than 400 reviews in English were removed to ensure the credibility of this research sample. A total of 640 hotels with 1,090,341 reviews in English satisfied our requirements. Hotel-level information contains hotel name, star, rating, number of reviews and address. Each review-level data contains reviewer, travel type, posting time, stay time, textual review, overall rating and ratings on six hotel attributes (value, location, service, room, cleanliness and sleep quality).
Finally, we classified the hotel reviews into different datasets according to the hotel star ratings and review overall ratings. Following the studies in [
9,
91], we categorized the online reviews into four datasets, namely, two-star and below hotels (1-, 1.5-, 2- and 2.5-stars hotels), three-star hotels (3- and 3.5-stars hotels), four-star hotels (4- and 4.5-stars hotels) and five-star hotels according to the hotel star ratings. Review classification based on the review overall rating is controversial [
18]. The main argument is whether the 3-score rating reviews should be classified as neutral or negative. Studies have shown that a 3-score evaluation is close to the service failure for most of potential customers [
18,
92]. Therefore, in this study, according to review overall ratings, online reviews of each hotel star were divided into two sub-datasets respectively, 1–3-score rating reviews as negative reviews and 4–5-score rating reviews as positive reviews. Let
and
respectively indicate the negative and positive dataset of
-star hotels,
. The final distribution of sub-datasets is shown in
Table 2.
3.2. Text Preprocessing and Sub-Attributes Selection
3.2.1. Text Preprocessing
Several standard steps were adopted to complete the text preprocessing task by using modules of the Natural Language Toolkit in Python programming environment, including:
Correcting spelling errors and transforming words with variant spellings (e.g., isn’t and is not);
Sentence segmentation and word tokenization;
Transforming capital letters to lowercases;
Removing non-English characters, punctuations and stopwords (an existing stopwords list from
https://www.ranks.nl/stopwords) (accessed on 30 October 2021);
POS tagging;
Lemmatization (reduce the inflectional forms to their root forms, e.g., rooms and room).
3.2.2. Sub-Attributes Selection
In this study, six key attributes including value, location, service, room, cleanliness and sleep quality [
9,
10,
35,
36,
46] are selected to explore the role of their bidirectional performance on customer overall ratings. These six attributes are provided by TripAdvisor.com as significant factors for customers to review [
35]. Hotel customers use a variety of elements to evaluate the performance of the same attribute [
46,
93,
94]. For example, customers may use “locate”, “place” and “distance” to describe the attribute “location”. Therefore, extracting words that are semantically similar to each hotel attribute is essential to comprehensively understand customers’ opinions.
In this study, we use Word2Vec algorithm to extract words semantically similar to each hotel attribute from textual reviews. Word2Vec is a generative similarity analysis method used to compare the degrees of semantic similarity between two words or two texts. Given a text corpus, Word2Vec learns a vector for each word in the vocabulary using the Continuous Bag-of-Words or the Skip-Gram neural network architectures [
95]. Continuous Bag-of-Words is suitable for a small corpus, while Skip-Gram performs better in a large corpus. After training the word vector model, the similarity of the words can be obtained. For this study, gensim is used as library which provides ready-made implementation of Word2Vec algorithm. We trained word vectors from each dataset of different hotel star using the Skip-Gram model. With the pre-trained Word2Vec model for each dataset, the similarity value between attribute
and each word in dataset is calculated, where
. The words with similarity value under attribute
greater than 0.5 are selected as the sub-attribute
of attribute
, where
is the number of sub-attributes. Let
denoted the similarity value between sub-attribute
and attribute
.
3.3. Sentiment Lexicon Creation
We used the PolarityRank algorithm to create a sentiment lexicon from hotel reviews, which has achieved reasonable accuracy without training for domain-specific sentiment analysis [
63,
96]. The PolarityRank algorithm is a non-supervised sentiment analysis method based on PageRank, with the ability to consider the relevance between nodes, and spread both positive PolarityRank (
) and negative PolarityRank (
) of one node to other nodes through the relevance by edges of weights in a graph [
63,
96,
97]. The main idea behind PolarityRank is to calculate two measures of relevance, the positive and the negative for each node in the graph [
63].
Given a text, a graph can be built based on lexical and syntactical dependency, which is named a dependency-based parse tree in NLP. The lexical graph is defined as
, where
is a set of nodes and
is a set of bidirectional edges between pairs of nodes according to the syntactic dependencies and between all nodes contained in descendant branches. The edge
between node
and
contains an associated weight denoted by
. An example of lexical graph is given, shown in
Figure 4. After generating the graph, propagation process with
and
of each node begins. The detailed descriptions of implementation steps are given in
Section 3.3.1,
Section 3.3.2 and
Section 3.3.3 3.3.1. Selecting Candidate Sentiment Words
After text preprocessing, the words were lemmatized as nouns, verbs, adjectives, adverbs, pronouns, etc. Previous studies selected the lemmatized nouns, adjectives and verbs as candidate sentiment words, discarding adverbs for they merely alter the degree of the polarity of the words they modify, but do not carry an inherent sentiment polarity [
96,
98]. Actually, many adverbs carry sentiment polarity, such as the adverb “luckily” in sentence “Luckily, there was one room available” expresses positive emotion.
To accurately analyze customers’ feelings, we used all the lemmatized nouns (n), verbs (v), adjectives (a) and adverbs (ad) as candidate sentiment words. The nodes of the graph corresponding to candidate sentiment words from hotel reviews are connected by the bidirectional edges. Following the study of Fernández-Gavilanes et al. [
96], the co-occurrence frequency of node
and
in the whole dataset is assigned to the weight
of edge
joining node
and
.
3.3.2. Assigning Initial Values to Candidate Sentiment Words
In this section, the candidate sentiment words are assigned initial positive value
and negative value
by SentiWordNet 3.0 through encoding a Python program. SentiWordNet 3.0 is a general sentiment lexicon publicly available for researchers, with three sentiment scores for each word, namely positive, negative and objective scores [
99]. For each candidate sentiment word, we assigned the positive value from SentiWordNet 3.0 to
and the negative value from SentiWordNet 3.0 to
. For the words excluded in SentiWordNet 3.0, the
and
are equal to zero.
3.3.3. Calculation of and
With weights for edges and pairs of initial sentiment values for nodes, calculation of
and
could commence. Let
be a set of indices
of the nodes for which there exists an edge to node
. Then, suppose
and
be the initial positive and negative values of node
respectively. The parameter
is set to 0.85 based on the original definition of PageRank, which is a damping factor to ensure convergence [
63,
97]. The
and
are estimated as follows:
The propagation process is stopped until the calculation converges or iteration times reach a fixed approximation threshold. In this study, after testing this process, a maximum of 300 iterations is set as the stopping criterion.
3.3.4. Calculation of Semantic Orientation
With the final values
and
, referred to Cruz et al. [
63], semantic orientation
of each candidate sentiment word is normalized as:
Finally, we dropped the candidate sentiment words with a zero . Thus, the sentiment lexicon from hotel reviews consists of the words with nonzero . Let two-tuple denote sentiment word and the corresponding sentiment value , where and , with representing the number of words in the lexicon.
3.4. Sentiment Analysis of Attributes
3.4.1. Calculation of Sub-Attribute Sentiment Values
According to the principle of Lexicon-based methods to sentiment analysis, the polarity of a sentence can be obtained from the polarities of words in that sentence [
62]. To obtain the sentiment value of each sub-attribute from different sub-datasets, we calculate the sentiment value of each sentence in different sub-datasets and record whether sub-attribute
exists in that sentence. For a single dataset, let
be a two-tuple consisting of the
sentiment word
and corresponding sentiment value
of the
sentence, where
, with
denoting the number of sentences in the dataset,
, with
denoting the number of sentiment words, and
belongs to the sentiment lexicon we created. Then, let
be a set of pairs of sentiment words and the corresponding sentiment values in the
lth sentence. For sub-attribute
existing in the
sentence, the sentiment value of
in the
sentence is calculated by the following
:
where
, with
denoting the number of sentences in the dataset.
To improve the accuracy of sub-attributes sentiment polarities, it is important to take the intensifiers and negators into account since these words can affect the sentiment values [
46,
56]. The sentiment propagation for intensification and negation is described as follows.
Propagation 1: Intensification.
Intensifiers are linguistic terms that primarily combine with adjectives, as well as modify nouns, adverbs and verbs. These words serve to influence the strength of the sentiment word, enhancing or diminishing the sentiment strength. The most common way of identifying these valence shifters is using a list of words, such as adverbs and adjectives, associated with fixed values for intensifiers [
100,
101]. In this study, we used a list of intensifiers, adapted from Brooke, where each element is a modifier that emphasizes or attenuates words [
102]. Let
represent the shift value of intensifier
, where
. Following the above description of sentiment calculation, for a dataset, if there’re intensifiers existing in
lth sentence, the sum of these shift values
is calculated. If not, the
is assigned zero. The propagation of
is represented as:
where
, with
denoting the number of sentences in the dataset.
Propagation 2: Negation.
In sentiment analysis, negators are the words like “not” that cause negation. Negators could alter the meaning of a word, sentence or provide a negation context, like converting an affirmative statement into a negative statement. The most common way to process negators is attaching these terms to the nearest words [
96]; i.e., in “This story is not interesting”, the word “interesting” is converted into “NOT-interesting”. In this processing method, negators are considered as polarity shifters of polar expressions that produce the opposite polarity. In other words, the polarity value was simply inverted if a polar expression fell within the negation scope [
101]. Thus, as the term “perfect” assigned a positive sentiment value of
, “NOT-perfect” has the sentiment value of
. However, some researchers hold the opinion that it is more reasonable to decrease the strength of sentiment words rather than directly invert them [
96,
102]. We use a list of negators, adapted from Brooke, where the negators are used as sentiment shifter with a default shift value of 4 [
102]. If there’s at least one negator existing in the
lth sentence, the negation propagation begins and is represented by
:
where
, with
denoting the number of sentences in the dataset.
3.4.2. Calculation of Attribute Sentiment Values
For the purpose of ensuring that we get the pure positive sentiment value of attribute
in each positive dataset, only the positive sentiment value of each sub-attribute under attribute
is retained. In other words, the negative sub-attribute sentiment values in the positive dataset are re-assigned to zero, i.e., in the
sentence of five-star positive dataset
, the sentiment value of sub-attribute
is equal to
denoting
, and then it should be re-assigned to zero. Similarly, the positive sub-attribute sentiment values in each negative dataset are re-assigned to zero. Let
indicate the re-assigned sentiment value of sub-attribute
in the
sentence of the positive dataset, and
indicate the re-assigned sentiment value of sub-attribute
in the
sentence of the negative dataset. These two concepts can be computed as follows:
where
, with
denoting the number of sentences in the dataset.
Given that the sub-attribute
is the homonymsemantic similar word of attribute
but not exactly equal to
, it’s necessary to consider the semantic similarity between sub-attribute
and attribute
. Let
indicate the positive sentiment value of sub-attribute
under attribute
in the positive dataset, and
indicate the negative sentiment value of sub-attribute
under attribute
in the negative dataset. Considering the semantic similarity between sub-attribute
and attribute
,
and
are estimated as follows:
Finally, with sub-attribute overall sentiment values, the sentiment values of each attribute in different datasets can be calculated. The sentiment values of attribute
in the positive dataset and negative dataset are calculated respectively, as shown in Equations (11) and (12):
In addition, we also calculate the sentiment values of each attribute without re-assigned propagation for the following studies. The positive and negative datasets of the same hotel star are merged, and let
represent the overall sentiment value of attribute
without discriminating positive and negative reviews, which is estimated as:
where
, with
indicating the total number of sentences in the review datasets of different hotel star ratings.
3.5. Kano-IPA Analysis
In this study, the Kano-IPA analysis contains three relevant parts. First, the six hotel attributes of each hotel star rating are classified into different categories in order to understand the effect of attribute performance on customer satisfaction. Second, we construct the IPA plot for hotels of different star ratings through analyzing the attributes’ importance and performance. Finally, the attribute priority rankings for improvement and resource allocation are given, so the different improvement strategies are provided for hotels of different star ratings. A detailed description of the Kano-IPA analysis is given as below.
3.5.1. Classifying Attributes into Kano Categories
In this study, a new approach to classify hotel attributes into Kano categories is proposed. As the above descriptions in our study, the positive sentiment value
of attribute
is obtained from customers whose expectations toward hotel attribute
has been met or even exceeded. So
of attribute
indicates the customer satisfaction that attribute
can bring when it performs well. Likewise, the negative sentiment value
of attribute
is obtained from customers who think the attribute realistic performance hasn’t met their expectations, which represents customer dissatisfaction that attribute
causes when its performance is poor. The overall sentiment value
of attribute
is obtained from all customers stayed in the hotels of the same star. Thus, the
is regarded as the expectant customer satisfaction that attribute
should generate. In accordance with the obtained
,
and
, following the previous index value classifying methods [
10,
24], here we define an index
to compare the effects of the attributes’ good performance and poor performance on customer satisfaction in hotels of the same star rating, and the
index of attribute
can be calculated as:
Obviously, . The index indicates the ratio of the customer satisfaction of good performance to the customer dissatisfaction of poor performance comparing with the expectant customer satisfaction of the overall performance concerning attribute . To determine the Kano category of each hotel attributes, a cut-off point is defined subjectively. According to the testing results based on different assignment methods in these review datasets, we define , where and represent the largest and smallest values of the index among the six hotel attributes. Moreover, the mean of the index among the six hotel attributes is calculated, denoting . Hence, hotel attributes can be classified into Kano categories as follows:
If , attribute is regarded as basic factor, indicating attributes in this category bring more customer dissatisfaction compared to other attributes.
If , attribute is regarded as performance factor, indicating attributes in this category bring equal or approximate customer satisfaction and dissatisfaction compared to other attributes.
If , attribute is regarded as excitement factor, indicating attributes in this category bring more customer satisfaction compared to other attributes.
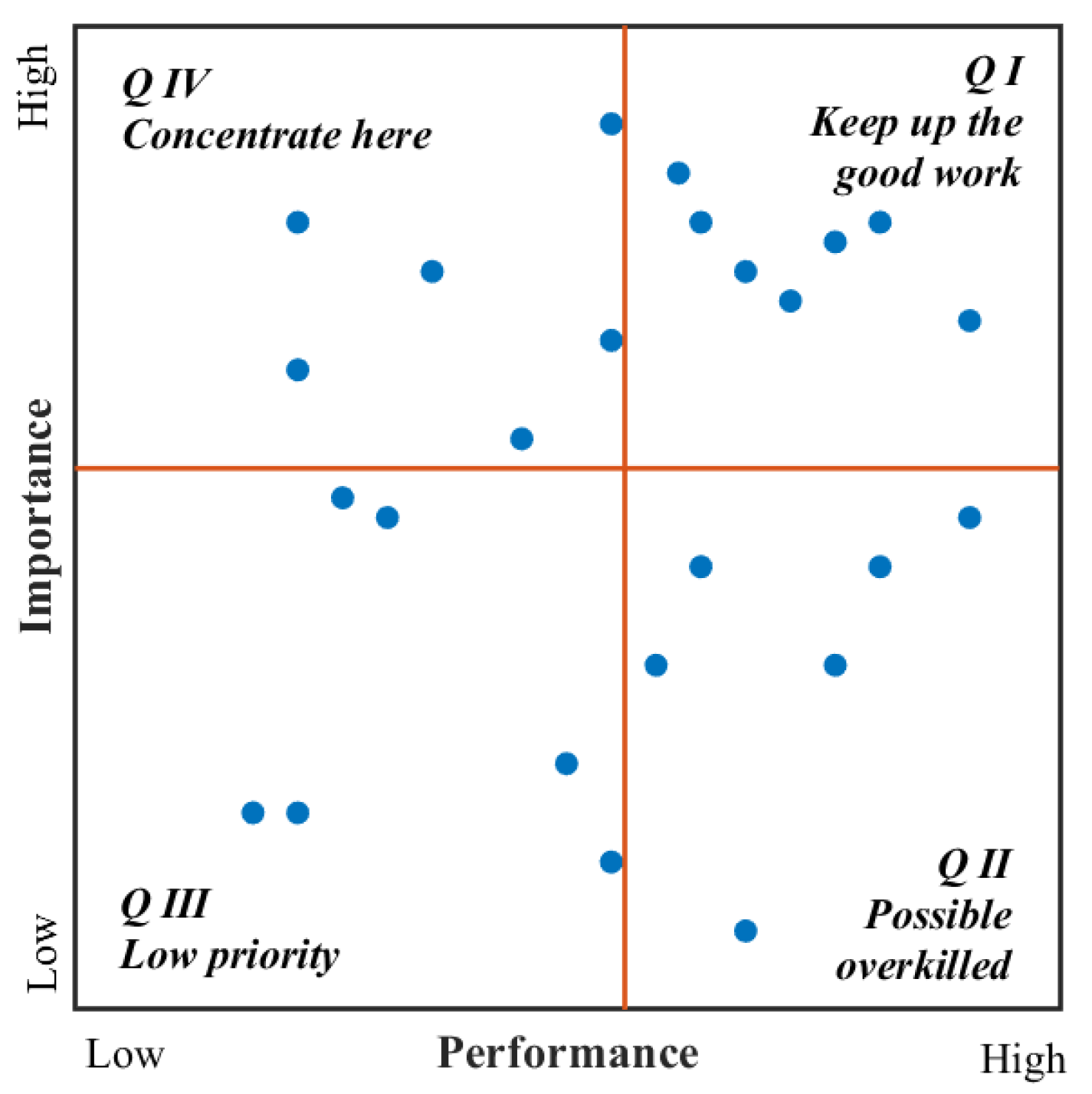
3.5.2. Constructing the IPA Plot
In this section, we try to construct an IPA plot of the six attributes. From
Section 4.4,
indicating the overall performance of each attribute
, so our next task is to estimate the importance of each attribute. In this study, the term frequency-inverse document frequency (TF-IDF) algorithm is utilized to estimate the importance of each sub-attribute. TF-IDF is a statistical method, which is widely used to evaluate the relative importance of a word to a particular document in a set of documents or a corpus [
35,
103]. The term’s importance increases as it appears more frequently in the document, but at the same time, its importance decreases as the frequency it appears increases in the whole corpus. Based on TF-IDF algorithm, we defined
indicating the weight of sub-attribute
. As mentioned above, the sub-attribute
is semanticly similar to the attribute
and the similarity
indicating the degree of semantic proximity. Therefore, we adopted the processing method of attribute importance from the study of Wang et al. [
35], and the attribute importance is calculated as follows:
With the performance and importance of each attribute, the IPA plot can be constructed. The IPA plot is drawn with importance on the vertical axis and performance on the horizontal axis, with the crosshair located inside based on the data-centered method [
104], as shown in
Figure 2. According to IPA, hotel managers should improve the attributes in Q IV and Q III in that order, maintain the attributes in Q I, and finally consider reducing investment for attributes in Q II [
10,
29].
3.5.3. Analyzing the Attribute Priority Rankings
Due to the limitation of hotel resource and efforts, the detailed priority rankings for resource allocation in the same quadrant still need to be determined. The Kano model indicates that the effect of attribute performance on customer satisfaction varies from different Kano categories. According to product lifecycle, the attributes of a product or service are regarded as excitement, performance and basic factors [
32], which provides a guideline for resource allocation. Specifically, the basic factors should be given the first priority to fulfill, the performance factors should be put in the second order to fulfill, and the excitement factors are given the lower priority to fulfill [
10,
29]. Therefore, based on the integrated Kano-IPA model, the attribute priority rankings for resource allocation are as shown in
Table 3.
5. Conclusions
5.1. Theoretical Implications
This study explored the attribute bidirectional performance by dividing online reviews into positive reviews and negative reviews. The Kano-IPA model was used for further understanding of customer’s rating behaviors and demands for hotel service. The proposed methodology in five phases of sentiment analysis and Kano-IPA model enriches the research on online hotel reviews. The main theoretical contributions introduced are as follows:
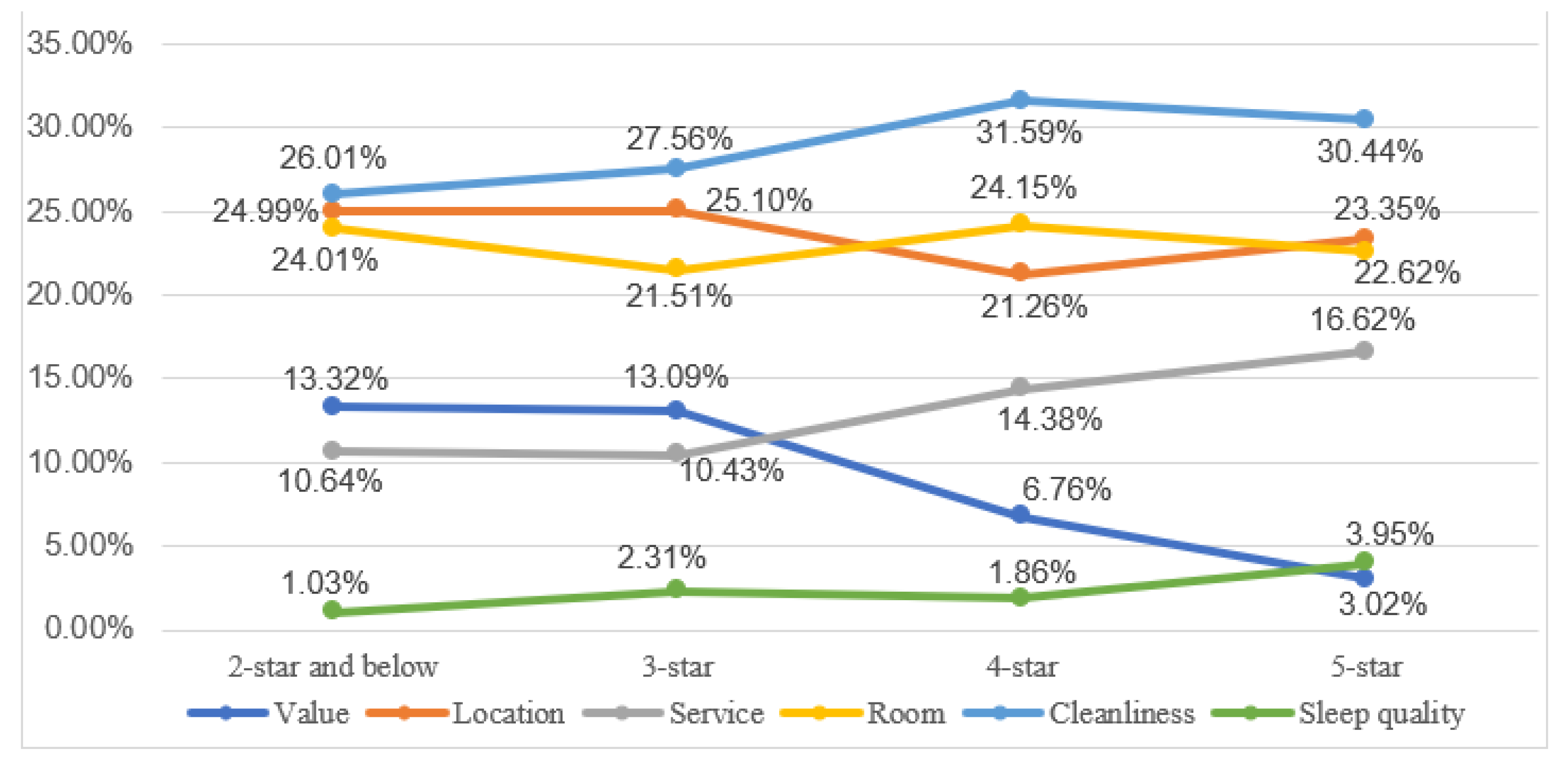
First, this study explores the well-performed attributes contributing to high customer ratings and the poorly performed attributes causing low customer ratings. By dividing 1,090,341 online reviews into positive and negative reviews, the six attributes’ good performance (positive sentiment values) in positive reviews and poor performance (negative sentiment values) in negative reviews are calculated through sentiment analysis. Our findings suggest that room, cleanliness and location are the most crucial determinants of both high and low customer ratings for hotels of these four levels. By contrast, other attributes, including value, service and sleep quality, have less impact on customers’ rating behaviors. Therefore, the most crucial hotel attributes influencing customer satisfaction and dissatisfaction are exactly the same. Focusing on improving service quality of these general attributes including room, cleanliness and location is the key to win high customer ratings for all hotels. Thus, the effect of good/poor performance concerning location, value, service on high/low customer ratings varies across hotel star ratings.
Second, comparative analysis of attribute bidirectional performance concerning four hotel star ratings was conducted to verify the difference of hotel attributes contributing to high/low customer ratings among different hotel star ratings. This study indicates that the impact of several attributes on high/low customer ratings varies across different star hotels. On one hand, the impact of value and service’s poor performance on low customer ratings varies across hotel star ratings. With the improvement in the hotel level, the impact of value’s poor performance on low customer ratings shows a downward trend, while the impact of service’s poor performance on low customer ratings shows an upward trend. For three-star and below hotels, value’s poor performance contributes more to low customer ratings than service’s poor performance. In contrast, for four and five star hotels, service’s poor performance has greater impact on low customer ratings. On the other hand, the good performance in room, location, value, service and sleep quality contributes to high customer ratings differently among different star hotels, where the impact of value and service’s good performance on high customer ratings shows a larger range of changes. Interestingly, for value and service, with the improvement in the hotel level, the impact of their good performance on high customer ratings shows the same trend as the impact of their poor performance on low customer ratings. These findings indicate that customers’ expectations and perceptions on the good/poor performance of each attribute may vary across hotel star ratings. Thus, it is necessary to take hotel star ratings into consideration on customer satisfaction research.
Third, this study suggests that the effect of good performance on high customer ratings may not be equal to the effect of poor performance on low customer ratings for the same hotel attribute. In other words, the effect of attribute performance on customer satisfaction is asymmetric. For this reason, the Kano-IPA model was applied to better understand customer’s rating behaviors and demands for hotel service. The Kano categories of five attributes (location, service, room, cleanliness and sleep quality) vary across different hotel star ratings. Furthermore, suggestions on priority for attribute improvement are formulated for hotels of the four star ratings according to the results of Kano-IPA model.
Fourth, this study proposes a methodology for hotel attribute sentiment analysis based on the automated textual analysis techniques including the Word2Vec and PolarityRank algorithms. A new sentiment lexicon was created from user generated reviews based on the PolarityRank algorithm, contributing to sentiment analysis in the hotel domain. The advance in the sentiment lexicon creation contains the following two points. On the one hand, we adopted more words (i.e., adverbs) than existing studies for PolarityRank propagation [
63,
96], which avoids missing some important sentiment words. On the other hand, initial both positive and negative sentiment values of each candidate sentiment word are assigned by a function from SentiWordNet instead of assigning positive seed words and negative seed words sentiment values manually, which is considered more objective and trustworthy. In addition, to our best knowledge, our sentiment lexicon built from the 1,090,341 textual reviews is the instructive application of the PolarityRank algorithm in million-level datasets. Thus, the comprehensive and complete sentiment propagation provides a guarantee of more precise sentiment calculation.
Lastly, this study proposed a novel index approach for Kano model classification and further makes it possible to apply the Kano-IPA model to numerous textual reviews. The index is defined to represent the satisfaction-stimulating ability of any one hotel attribute. Then the six attributes are classified into three Kano categories by comparing each index with the average index value for hotels of each star rating. The proposed approach enriches the existing research on the classification of the Kano model. Additionally, based on the TF-IDF algorithm, the importance of each attribute is obtained to construct the IPA plot. This study is a preferable attempt to apply online reviews to explore the effects of attribute performance on customer satisfaction to understand customers’ rating behaviors.
5.2. Practical Implications
As consumers’ reliance on the Internet grows, online reviews are increasingly important since customers usually browse a lot of hotel reviews when making hotel choices. It is important to analyze how hotel attributes contribute to high and low customer ratings. This study enables hotel managers and hotel online platforms to understand customers’ rating behaviors, expectations and perceptions on hotel attributes. Furthermore, our findings and discussions provide a reference for hotel managers to allocate resources for attribute improvement and prioritization to achieve higher customer ratings.
First, due to the findings that the final attribute priority rankings for improvement are divided into two groups, two strategies for attribute improvement are given to low-star (three stars and below) and high-star (four- and five-star) hotels, respectively. For low-star hotels, room, which is an excitement factor, should be given the highest priority for resource allocation for improvement. Effective measures such as refurnishing, renovating, providing tidy and spacious rooms and proper decoration could be taken to improve room’s performance in order to enhance customer satisfaction. Service, sleep quality and value are of lower priority for improvement, and they are basic, basic, and excitement factors, respectively. Some effective measures should be taken to enhance the performance of service and sleep quality in order to reduce customer dissatisfaction, which might include, for instance, staff training for work skill and attitude improvement, quality improvement in beds, pillows and soundproofing. With sufficient resource, low-star hotel managers should also provide attractive discounts or reasonable prices to customers since value for money is highly important for them. For high-star hotels, though nothing calls for urgent improvement, there still a need for better performance in service, sleep quality and value. Service and sleep quality are performance factors, and their importance is significantly higher for customers in high-star hotels. Service improvement (i.e., higher staffing levels, proactive, pet-friendly and infant-related services and multilingual receptionists) and providing better sleeping conditions (i.e., better bedding and soundproofing) are preferable methods to enhance customer satisfaction. Moreover, providing proper discounts and price for customers is also needed.
Second, some strengths should be well maintained for different star hotels. For low-star hotel managers, cleanliness and location are the strengths to win customer satisfaction. Since cleanliness and location are performance or basic factors and of high importance for customers in low-star hotels, it is necessary to invest sufficient resource to ensure their high quality. For high-star hotel managers, cleanliness, room and location are the strengths that need to be well maintained. In contrast to customers in low-star hotels, cleanliness and location are, respectively, basic and excitement factors for customers in high-star hotels. Investing more in hotel location is a preferable way for high-star hotels to enhance customer satisfaction. While it is hard to transform the existing locations, some convenient transportation services can be offered to improve access to attractions or traffic stations, such as free shuttles, attraction brochures. Additionally, room is a unique strength for high-star hotels, while it is a weakness of low-star hotels. These findings are in line with the hotel star rating system offered by the Automobile Association that room is a basic and quantitative indicator for hotel star rating [
109]. Therefore, hotel managers should pay great attention to room improvement for higher star ratings.
Third, this study indicates that attribute improvement priorities are the same for hotels of three stars, two stars and below. However, compared with two-star and below hotels, service and sleep quality’s importance is higher but performance is worse in three-star hotels. Service and sleep quality are basic factors, so their poor performance is more likely to cause great customer dissatisfaction. Customers pay more for a better hotel, so their expectations increase [
110]. Thus, three-star hotel managers should pay more attention to improve performance in service and sleep quality to reduce customer dissatisfaction, and further enhance the competitive strengths against two-star and below hotels. Similarly, five-star hotel managers should keep alert for the pursuit of higher service quality since the SI index values of location, service, room, cleanliness and sleep quality show a downward trend compared to four-star hotels. This can be explained as follows: customers place much higher expectations on five-star hotels than four-star hotels, so very minor service failures can also cause great complaints. Compared to four-star hotels, investing resources to provide customers more attentive service and better sleep quality is necessary for five-star hotels.
Last but not least, for hotel online platforms, two aspects of practical significance are as follows. On the one hand, this study serves as references for online websites to recommend hotels to customers when they filter hotel star ratings. Our findings imply that customers have different expectations, preferences and demands for the six attributes when they choose hotels of different star ratings. Thus, different weights assigned to each hotel attribute according to hotel star ratings can be considered when designing the hotel recommendation system. On the other hand, we suggest that the six evaluation dimensions on the website should be upgraded. For example, considering the sub-attribute lists of room and cleanliness are similar, they can be merged into one dimension or given some notes for each attribute to help customers to distinguish between them.
5.3. Limitations
This study also has several limitations, which might serve as avenues for future research. First, the data were collected from one online travel website, which may not provide the complete information about customers’ opinions. In addition, not all customers write textual reviews and give ratings to the hotels after leaving. Therefore, hotel reviews can be collected from multiple online websites and customers who book hotels offline. Second, although this study explores the differences in the categories and performance of six attributes across four hotel star ratings, attribute differences between different traveling purposes or different regions may exist. Customers with different traveling purposes and from different districts have different preferences on hotel attributes, which may influence attribute performance and further influence attribute classification in the Kano model. In the future, classifying online reviews based on other methods involves complex research. Third, for each hotel, its star rating may move up or down when the hotel makes some changes such as redecoration, management mode upgrades or becoming run-down. Although the cost of improving hotel star ratings is very high, some hotels may attempt to make efforts for higher star ratings. As a result, for some hotels, earlier online reviews may not reveal their quality appropriately in the current star ratings. This will affect the attribute bidirectional performance analysis results among different hotel star ratings. Thus, it is preferable to select online reviews during the current star rating period or exclude the hotels with changes in star ratings in the future research. Additionally, exploring the difference in determinants of customer satisfaction and dissatisfaction between the previous and current hotel star ratings is a future research direction. Finally, the attributes used in this study are the six evaluation dimensions on TripAdvisor.com, which may not include all topics expressed in textual reviews. To comprehensively understand customer demands, different categories of attributes can be extracted from textual reviews in future research.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}