
Development of a Stock Price Prediction Framework for Intelligent Media and Technical Analysis



Abstract
:1. Introduction
2. Materials and Methods
2.1. Theoretical Fundamentals
2.1.1. Forecasting Using Sentiment Analysis
2.1.2. Forecasting Using Recurrent Neural Networks
2.1.3. Forecasting Using Hybrid CNNxLSTM and ConvLSTM Network
2.1.4. Stock Market Prediction
2.2. Background
2.2.1. Machine Learning Models
2.2.2. Deep Learning Models
2.3. Methodology
2.3.1. Sentiment Classifier
2.3.2. Fundamental Analysis
2.3.3. Technical Analysis
3. The Developed Model
3.1. Data Summary
3.2. Experiments
3.3. Results from Fundamental and Technical Analysis Experiments
3.3.1. Fundamental Analysis: Experiment 1
3.3.2. Technical Analysis: Experiment 2
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurieff, K. Snapchat Stock Loses $1.3 Billion after Kylie Jenner Tweet. CNN. 23 February 2018. Available online: https://money.cnn.com/2018/02/22/technology/snapchat-update-kylie-jenner/index.html (accessed on 1 May 2020).
- Bursztynsky, J. Tesla Shares Tank after Elon Musk Tweets the Stock Price Is ‘too high’. CNBC. 1 May 2020. Available online: https://www.cnbc.com/2020/05/01/tesla-ceo-elon-musk-says-stock-price-is-too-high-shares-fall.html (accessed on 18 February 2012).
- Dev, S.; Haruna, I.; Farhana, Z. Predicting the Effects of News Sentiments on the Stock Market. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Wu, D.D.; Ren, R.; Liu, T. Forecasting Stock Market Movement Direction Using Sentiment Analysis and Support Vector Machine. IEEE Syst. J. 2019, 13, 760–770. [Google Scholar]
- Li, H.; Shen, Y.; Zhu, Y. Stock Price Prediction Using Attention-based Multi-Input LSTM. In Proceedings of the Machine Learning Research, Beijing, China, 14–16 November 2018; pp. 454–469. [Google Scholar]
- Minh, D.L.; Sadeghi-Niaraki, A.; Huy, H.D.; Min, K.; Moon, H. Deep Learning Approach for Short-Term Stock Trends Prediction Based on Two-Stream Gated Recurrent Unit Network. IEEE Access 2018, 6, 55392–55404. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, December 2015. [Google Scholar]
- Lee, S.W.; Kim, H.Y. Stock market forecasting with super-high dimensional time-series data. Expert Syst. Appl. 2020, 161, 113704. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Chen, X.; Xie, X.; Teng, D. Short-term Traffic Flow Prediction Based on ConvLSTM Model. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC 2020), Chongqing, China, 12–14 June 2020. [Google Scholar]
- Khan, W.; Ghazanfar, M.A.; Azam, M.A.; Karami, A.; Alyoubi, K.H.; Alfakeeh, A.S. Stock market prediction using machine learning classifiers and social media, news. J. Ambient Intell. Humaniz. Comput. 2020, 11, 1–24. [Google Scholar] [CrossRef]
- Khan, W.; Malik, U.; Ghazanfar, M.A.; Azam, M.A.; Alyoubi, K.H.; Alfakeeh, A.S. Predicting stock market trends using machine learning algorithms via public sentiment and political situation analysis. Soft Comput. 2020, 8, 11019–11043. [Google Scholar] [CrossRef]
- Vargas, M.R.; Anjos, C.E.M.d.; Bichara, G.L.G.; Evsukoff, A.G. Deep Learning for Stock Market Prediction Using Technical Indicators and Financial News Articles. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Chen, C.-H.; Shih, P. A Stock Trend Prediction Approach based on Chinese News and Technical Indicator Using Genetic Algorithms. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation, Wellington, New Zealand, 10–13 June 2019. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Modern Information Retrieval, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Izenman, A.J. Discriminant Analysis and Other Linear. In Modern Multivariate; Springer: New York, NY, USA, 2013; pp. 237–238. [Google Scholar]
- Tan, P.-N.; Steinbach, M.; Kumar, V. Classification: Basic Concepts, Decision Trees, and Model Evaluation. In Introduction to Data Mining; University of Minnesota: Minnesota, MN, USA, 2006; pp. 145–205. [Google Scholar]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. Mach. Learn. 2011, 45, 157–176. [Google Scholar]
- Olah, C. Understanding LSTM Networks. Github. 27 August 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 2 June 2020).
- Henrique, J. Get Old Tweets Python. 21 November 2018. Available online: https://pypi.org/project/GetOldTweets3/ (accessed on 28 January 2020).
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification using Distant Supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, preprint. arXiv:1810.04805. [Google Scholar]
- Face, H. BERT. Hugging Face. 2020. Available online: https://huggingface.co/transformers/model_doc/bert.html (accessed on 10 September 2020).
- Markets, A. An Introduction to Fundamental Analysis in Forex. Admiral Markets. 2 September 2020. Available online: https://admiralmarkets.com/education/articles/forex-analysis/introduction-to-forex-fundamental-analysis (accessed on 14 September 2020).
- Ronaghan, S. Data Preparation for Machine Learning: Cleansing, Transformation & Feature Engineering. Towards Data Science. 20 September 2019. Available online: https://towardsdatascience.com/data-preparation-for-machine-learning-cleansing-transformation-feature-engineering-d2334079b06d (accessed on 26 August 2020).
- Scikit Learn. Sklearn. Preprocessing. MinMaxScaler. Scikit Learn. 4 August 2007. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 26 August 2020).
- The PyData Development Team. Pandas-datareader. PyData. 21 August 2020. Available online: https://pandas-datareader.readthedocs.io/en/latest/ (accessed on 21 August 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Accuracy |
|---|---|
| Support vector machine | 44% |
| Decision tree | 46% |
| Random forest | 49% |
| Models | Accuracy |
|---|---|
| Support vector machine | 54% |
| Decision tree | 75% |
| Random forest | 66% |
| Linear discriminant analysis | 94% |
| Models | Accuracy |
|---|---|
| Support vector machine | 49% |
| Decision tree | 82% |
| Random forest | 74% |
| Linear discriminant analysis | 96% |
| Models | Ordinary LSTM | Stacked LSTM | Bidirect LSTM | CNN LSTM | Conv LSTM |
|---|---|---|---|---|---|
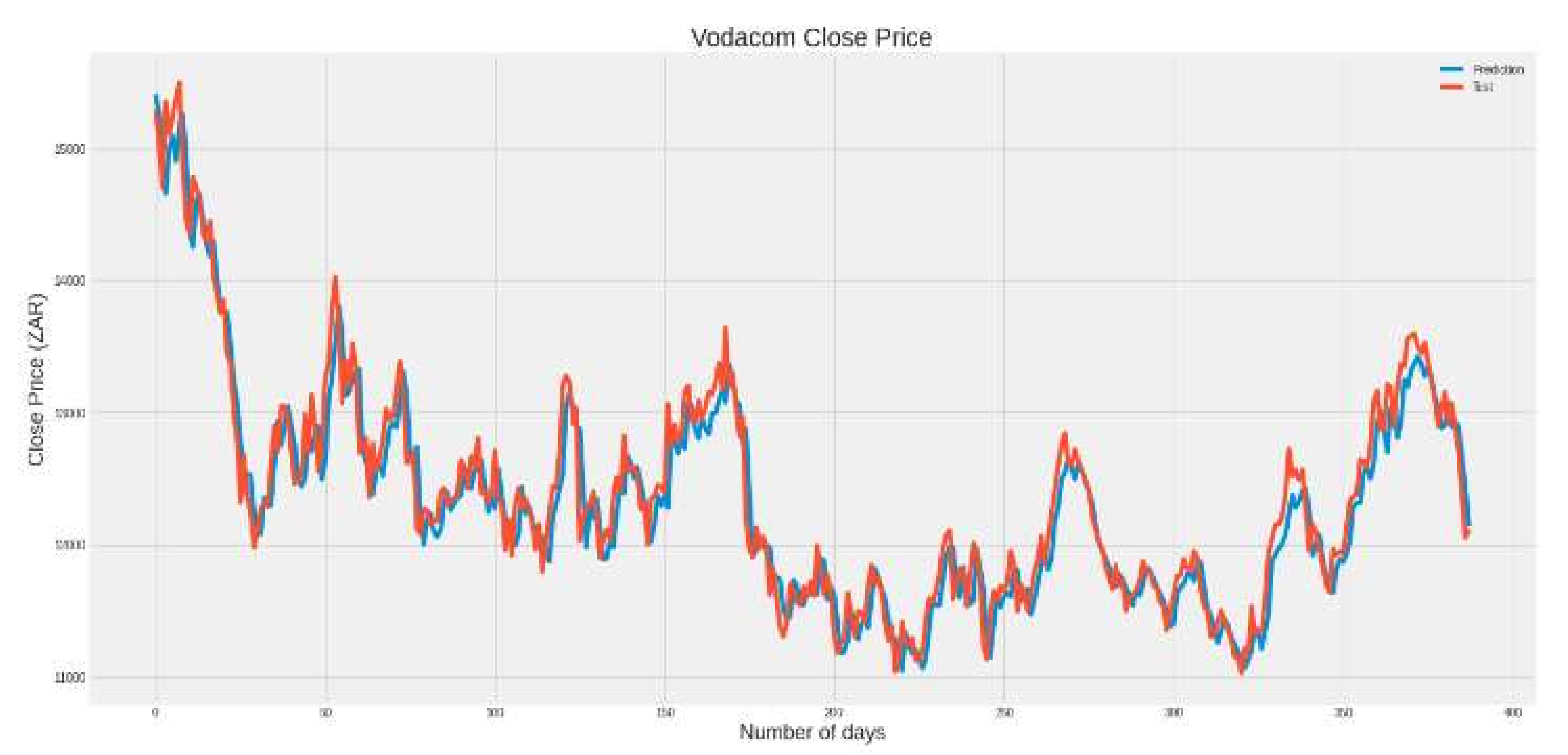
| MSE | 48,991.89 | 48,766.52 | 48,946.1 | 53,773.47 | 54,060.72 |
| RMSE | 221.34 | 220.83 | 221.23 | 231.8 | 232.51 |
| Models | Ordinary LSTM | Stacked LSTM | Bidirect LSTM | CNN LSTM | Conv LSTM |
|---|---|---|---|---|---|
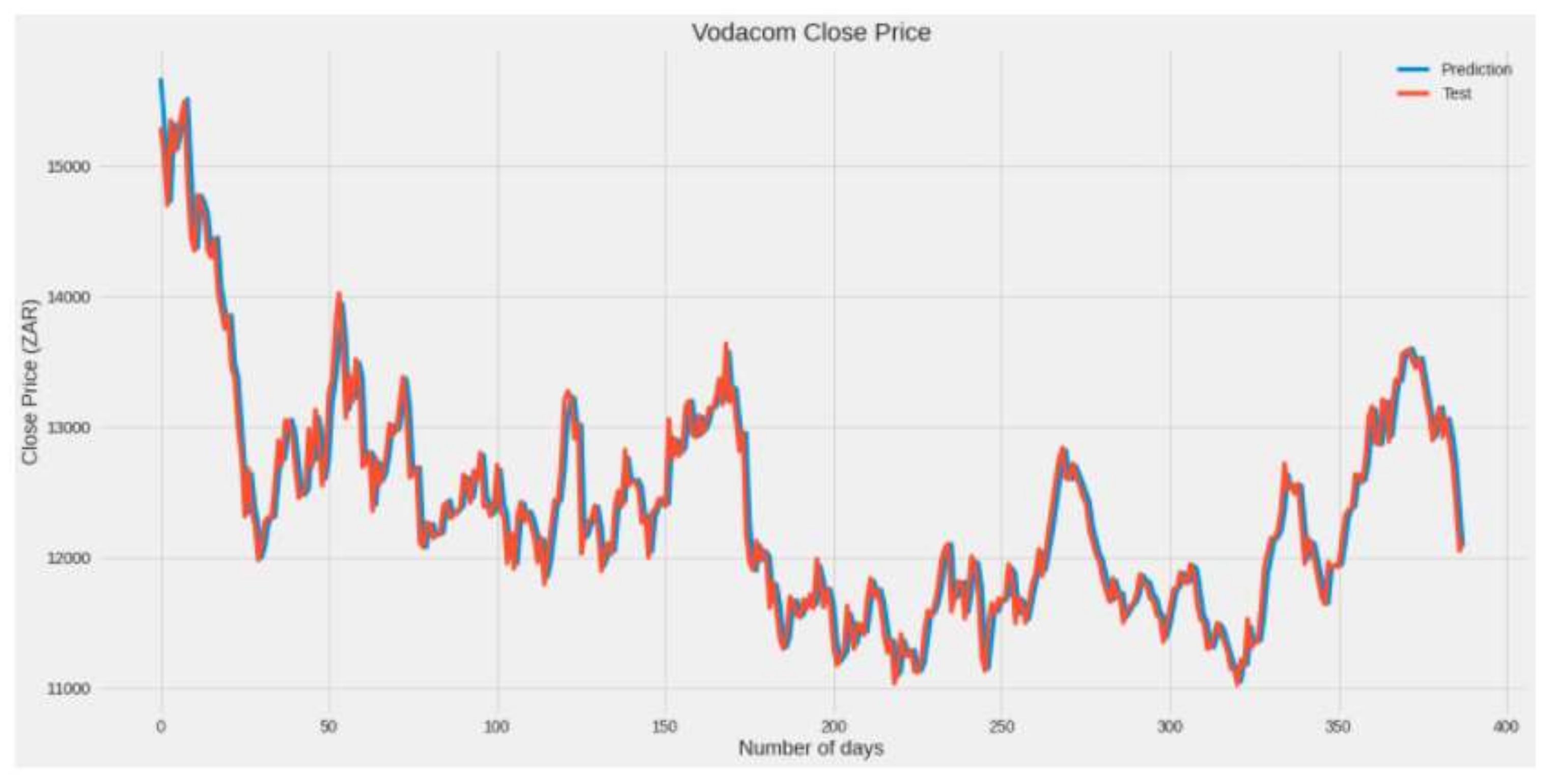
| MSE | 5706.57 | 17,627.8 | 28,181 | 62,873.73 | 9295.55 |
| RMSE | 75.54 | 132.77 | 167.87 | 250.75 | 96.41 |
| Test Data (ZAR) | Predictions (ZAR) |
|---|---|
| 12,901 | 12,901.025 |
| 12,700 | 12,700.019 |
| 12,376 | 12,376.02 |
| 12,051 | 12,051.023 |
| 12,112 | 12,112.027 |
| Test Data (ZAR) | Predictions (ZAR) |
|---|---|
| 12,901 | 12,959.947 |
| 12,700 | 12,939.186 |
| 12,376 | 12,875.924 |
| 12,051 | 12,830.503 |
| 12,112 | 12,801.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mndawe, S.T.; Paul, B.S.; Doorsamy, W. Development of a Stock Price Prediction Framework for Intelligent Media and Technical Analysis. Appl. Sci. 2022, 12, 719. https://doi.org/10.3390/app12020719
Mndawe ST, Paul BS, Doorsamy W. Development of a Stock Price Prediction Framework for Intelligent Media and Technical Analysis. Applied Sciences. 2022; 12(2):719. https://doi.org/10.3390/app12020719
Chicago/Turabian StyleMndawe, Sibusiso T., Babu Sena Paul, and Wesley Doorsamy. 2022. "Development of a Stock Price Prediction Framework for Intelligent Media and Technical Analysis" Applied Sciences 12, no. 2: 719. https://doi.org/10.3390/app12020719
APA StyleMndawe, S. T., Paul, B. S., & Doorsamy, W. (2022). Development of a Stock Price Prediction Framework for Intelligent Media and Technical Analysis. Applied Sciences, 12(2), 719. https://doi.org/10.3390/app12020719