
Human Activity Classification Using the 3DCNN Architecture





Abstract
:1. Introduction
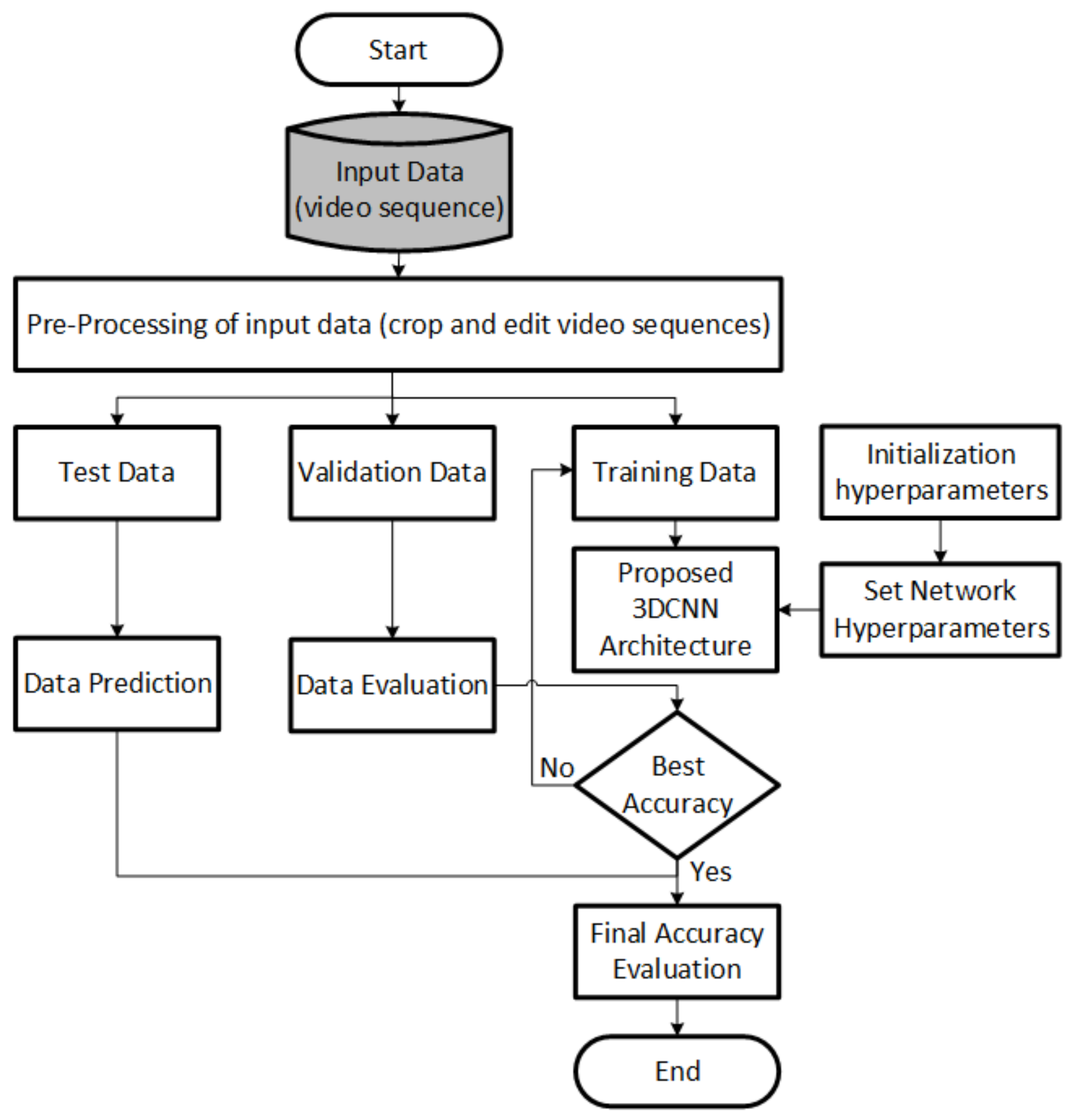
2. Materials and Methods
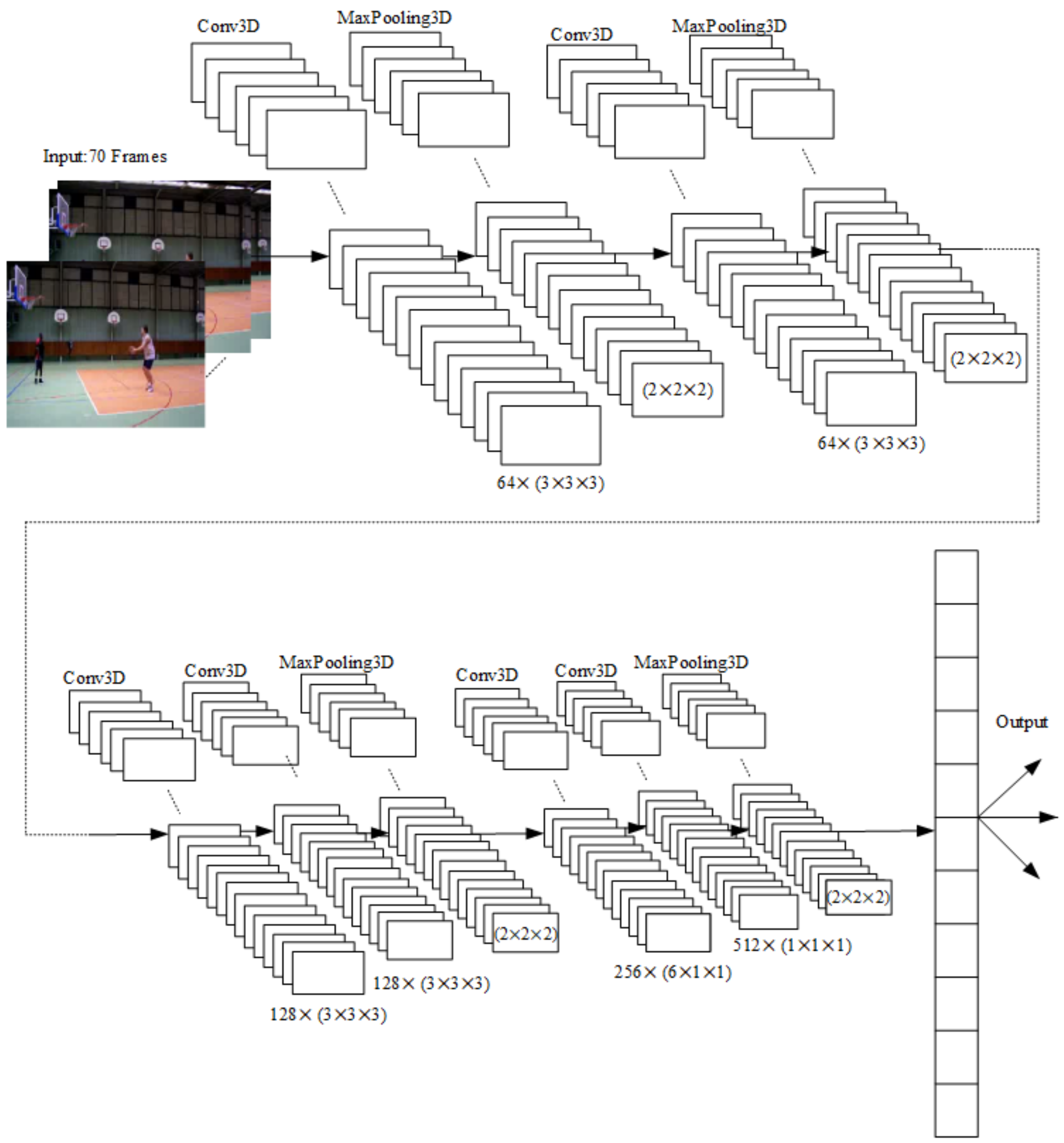
2.1. 3DCNN Architecture

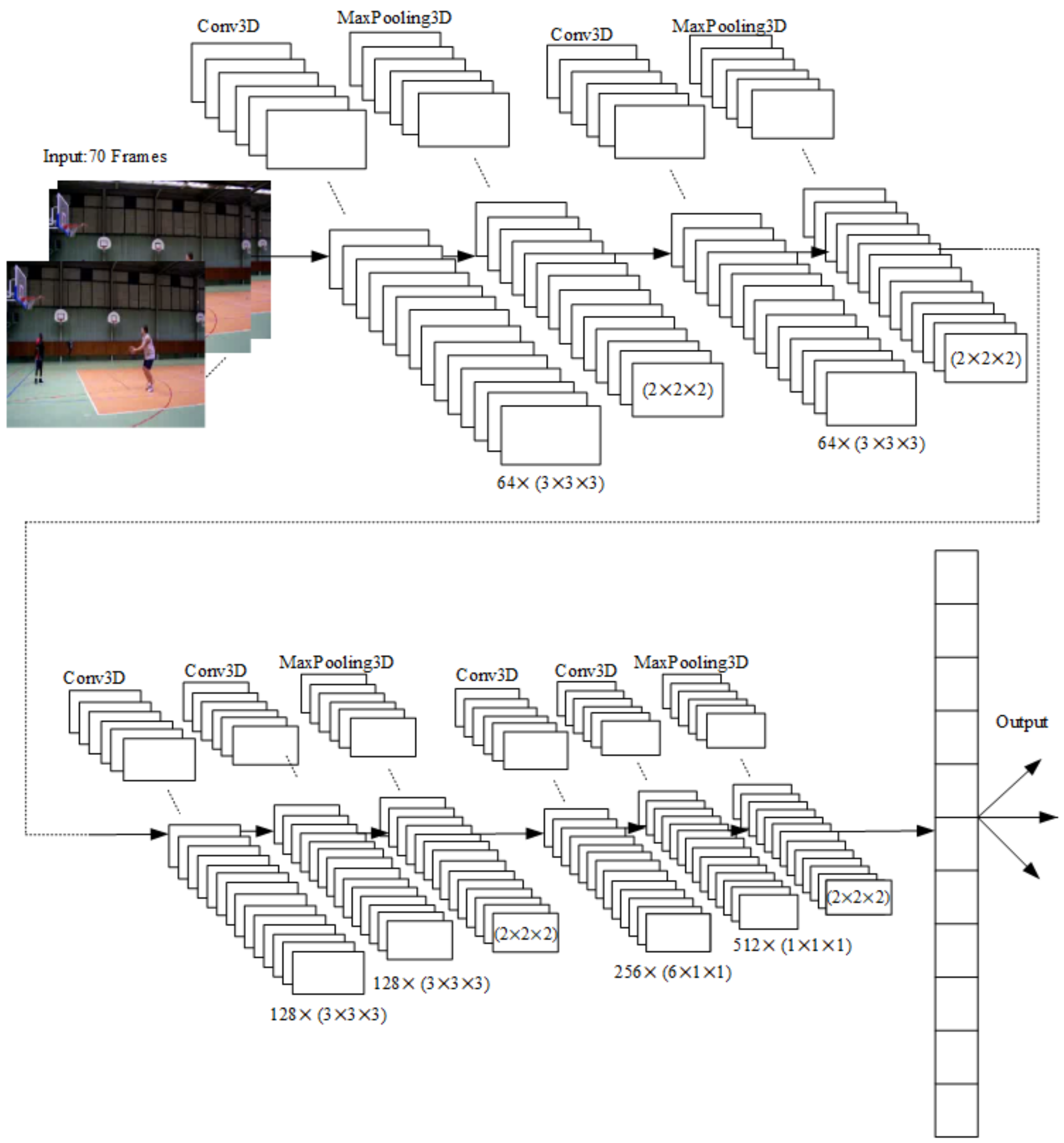
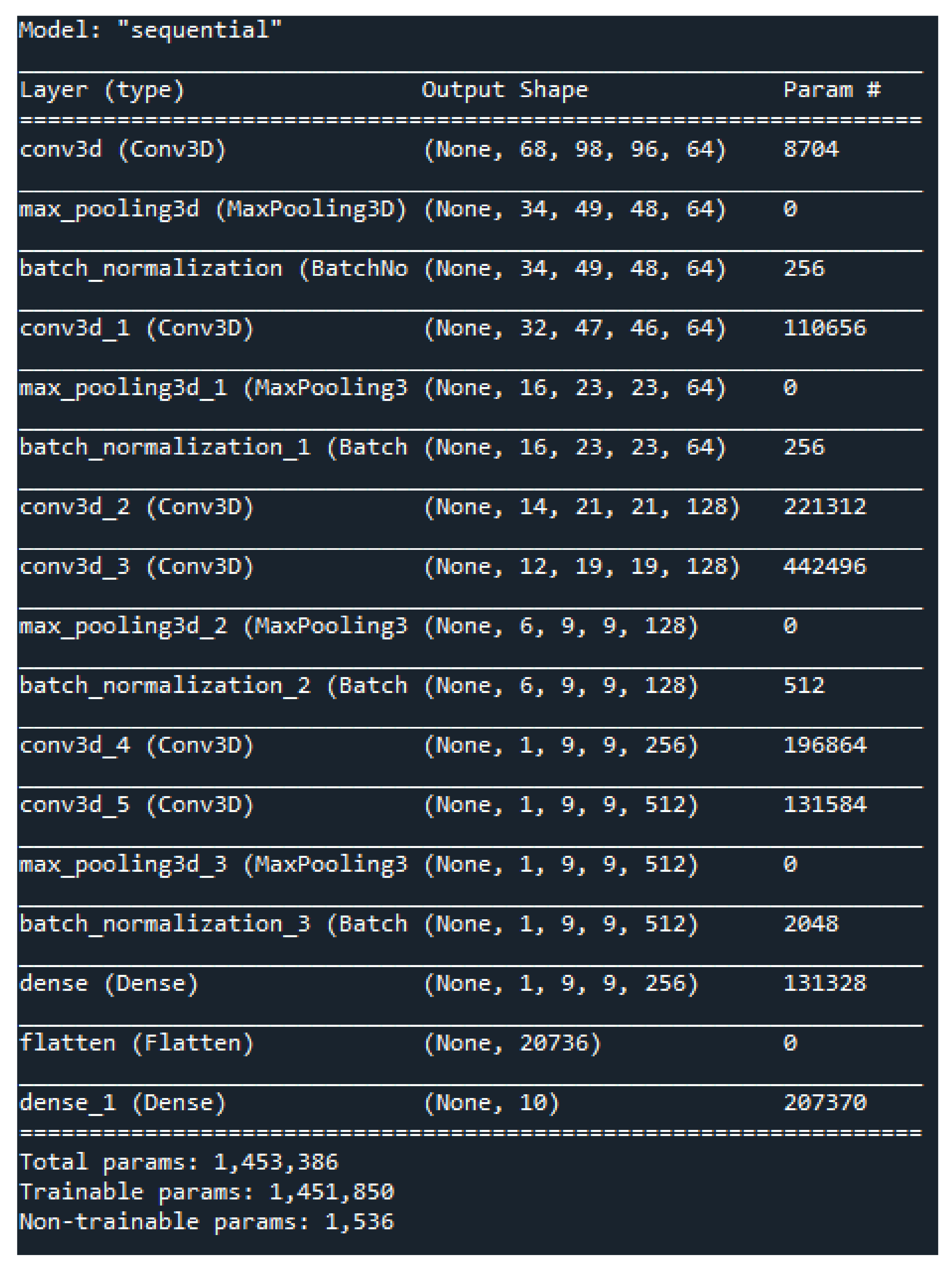
2.2. Proposed 3DCNN Architecture
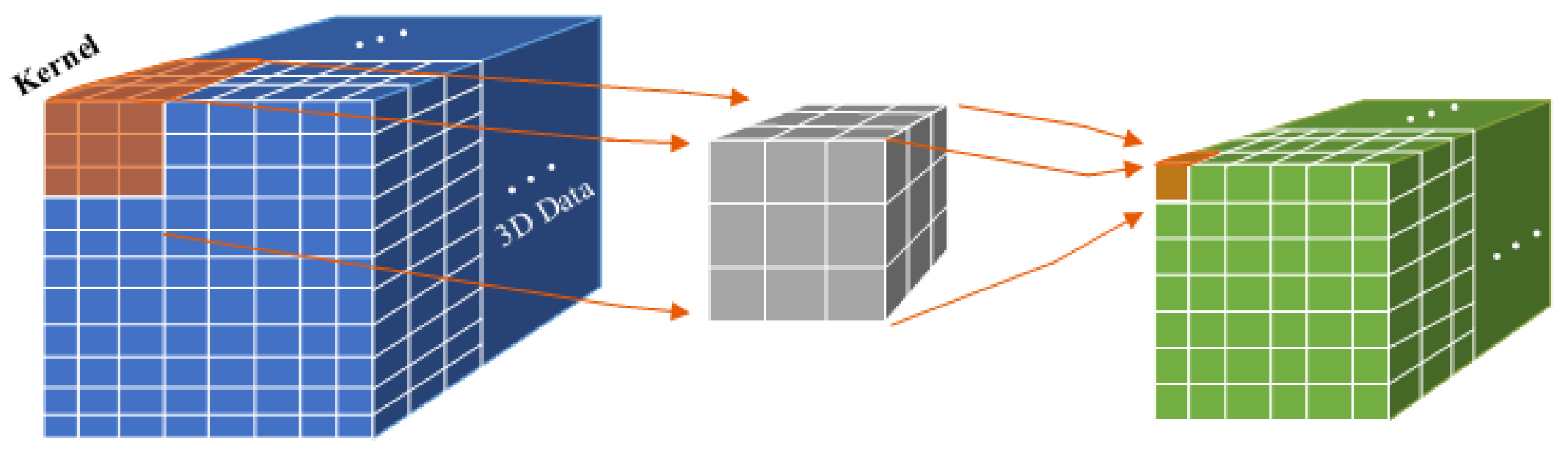
- 3DCNN layers, which improve the identification of 3D and moving images. Each layer contains a three-dimensional filter that moves in three directions (x, y, z). During the 3D convolution, a convolutional map is created, which is needed for data analysis as well as time and volumetric context.
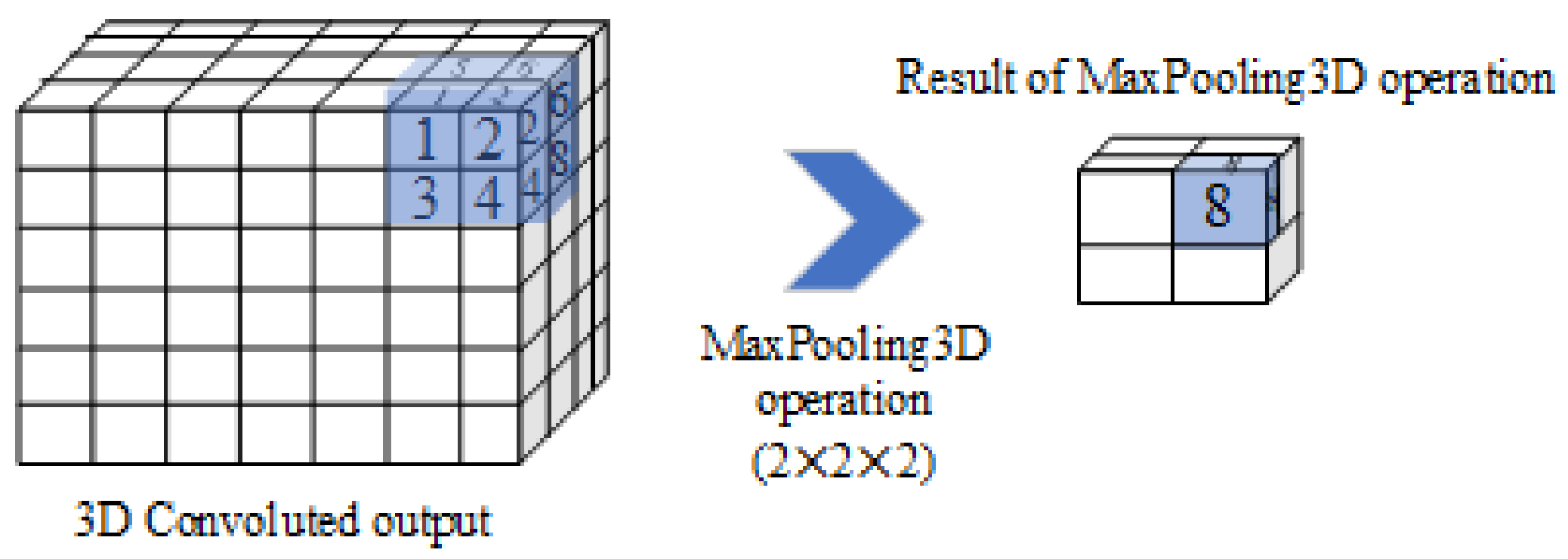
- MaxPooling layers for 3D data (MaxPooling3D), which are used to reduce the size of the image data. MaxPooling3D is a mathematical operation for 3D data as well as for spatial or spatiotemporal data. The layers are defined using n × n × n regions as corresponding filters for the max pooling operations. Additionally, a stride is defined, which sets the number of pixels that the filter moves in each step as it slides across The image.
- Batch normalization is structure which is used to normalize the previous layer for each batch. Batch normalization transform standard deviation to 1 and mean activation to 0.
- A dense layer, which is usually one of the last layers and mainly fully interconnected neurons.
- A flatten layer, which is located at the end of the neural network and causes the matrix to be converted to an output vector.
| Algorithm 1 Pseudo-code of the proposed 3DCNN architecture. |
|
3. Experimental Results
3.1. UCF YouTube Action Dataset
3.2. UCF101 Dataset
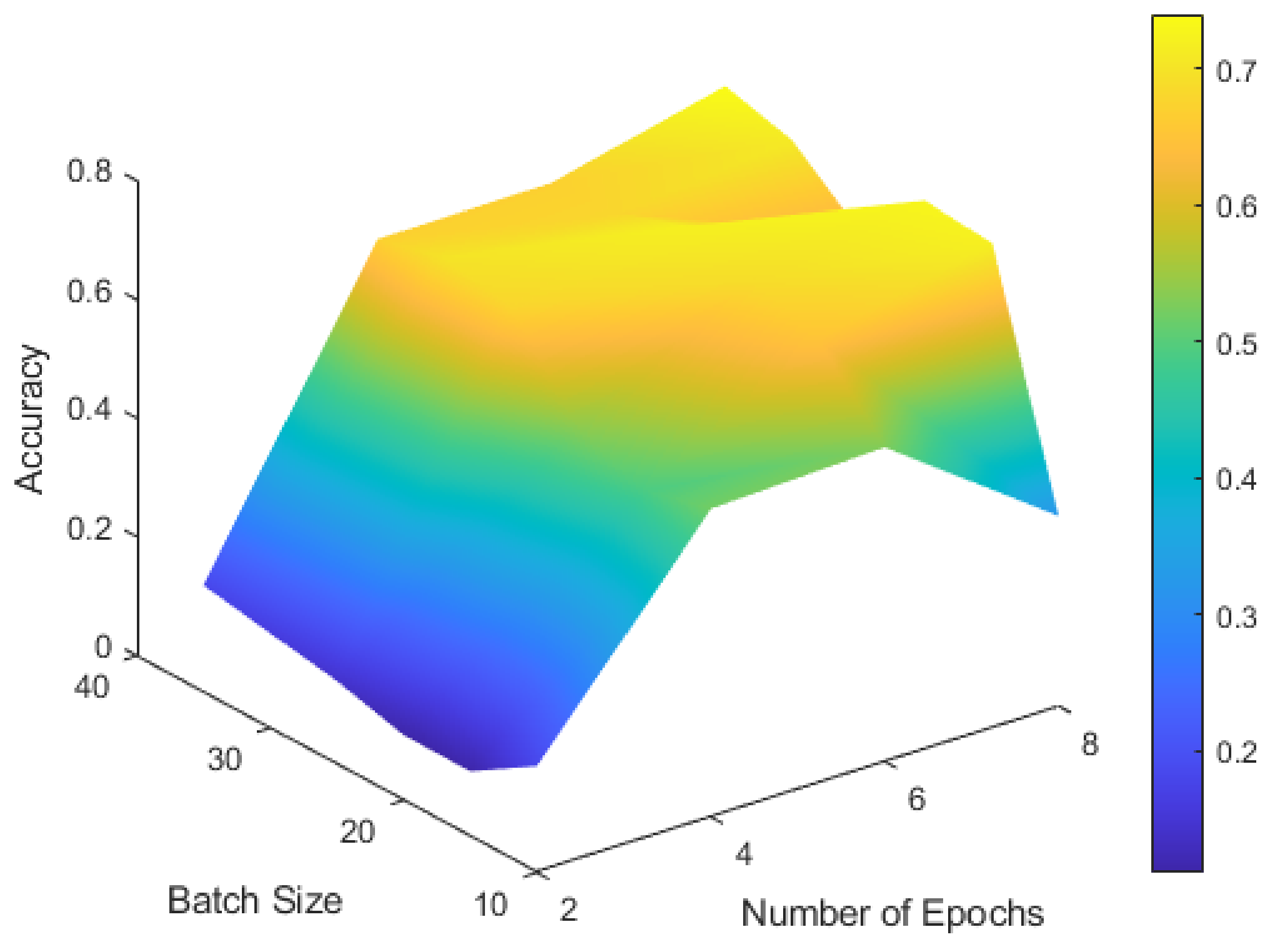
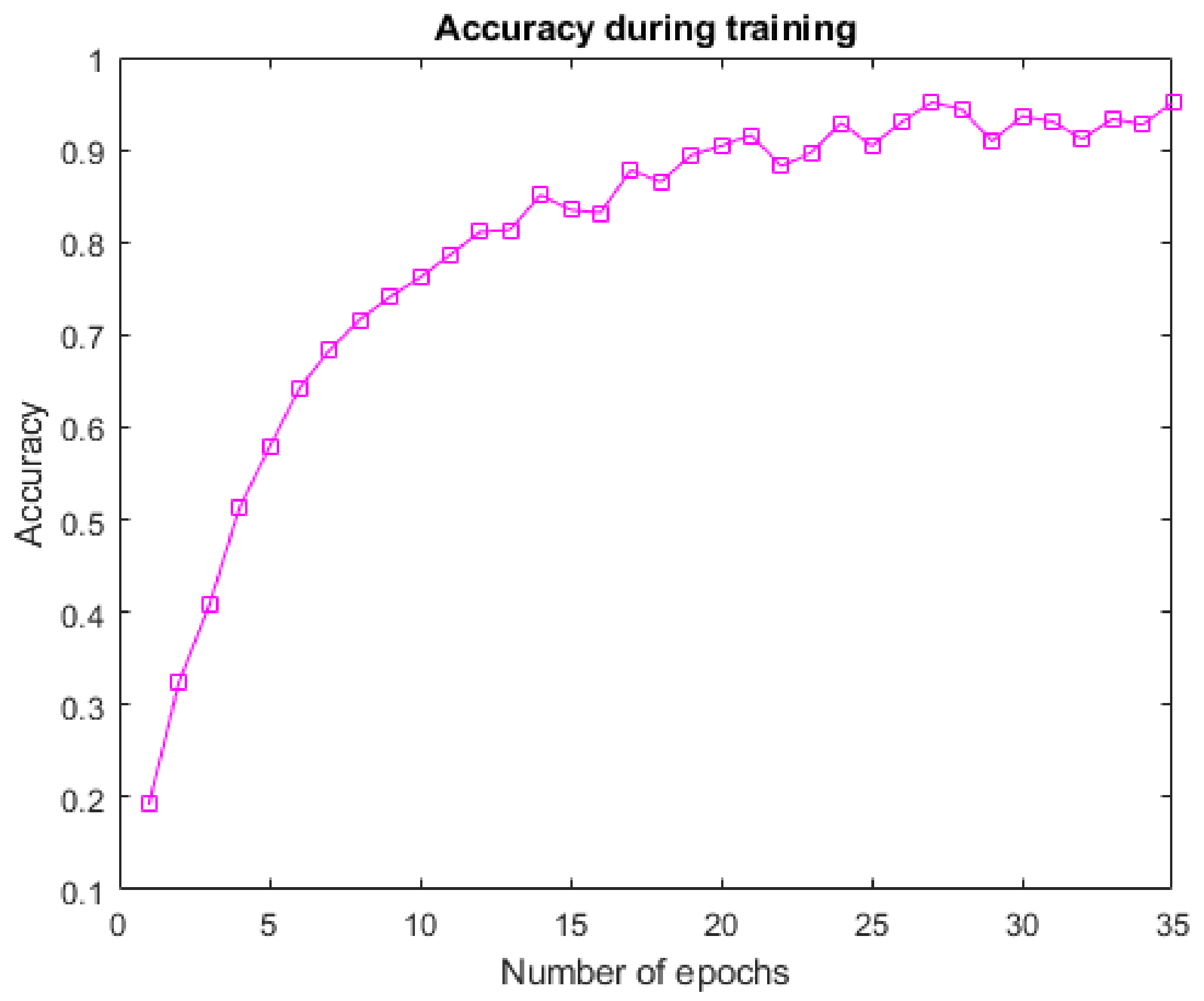
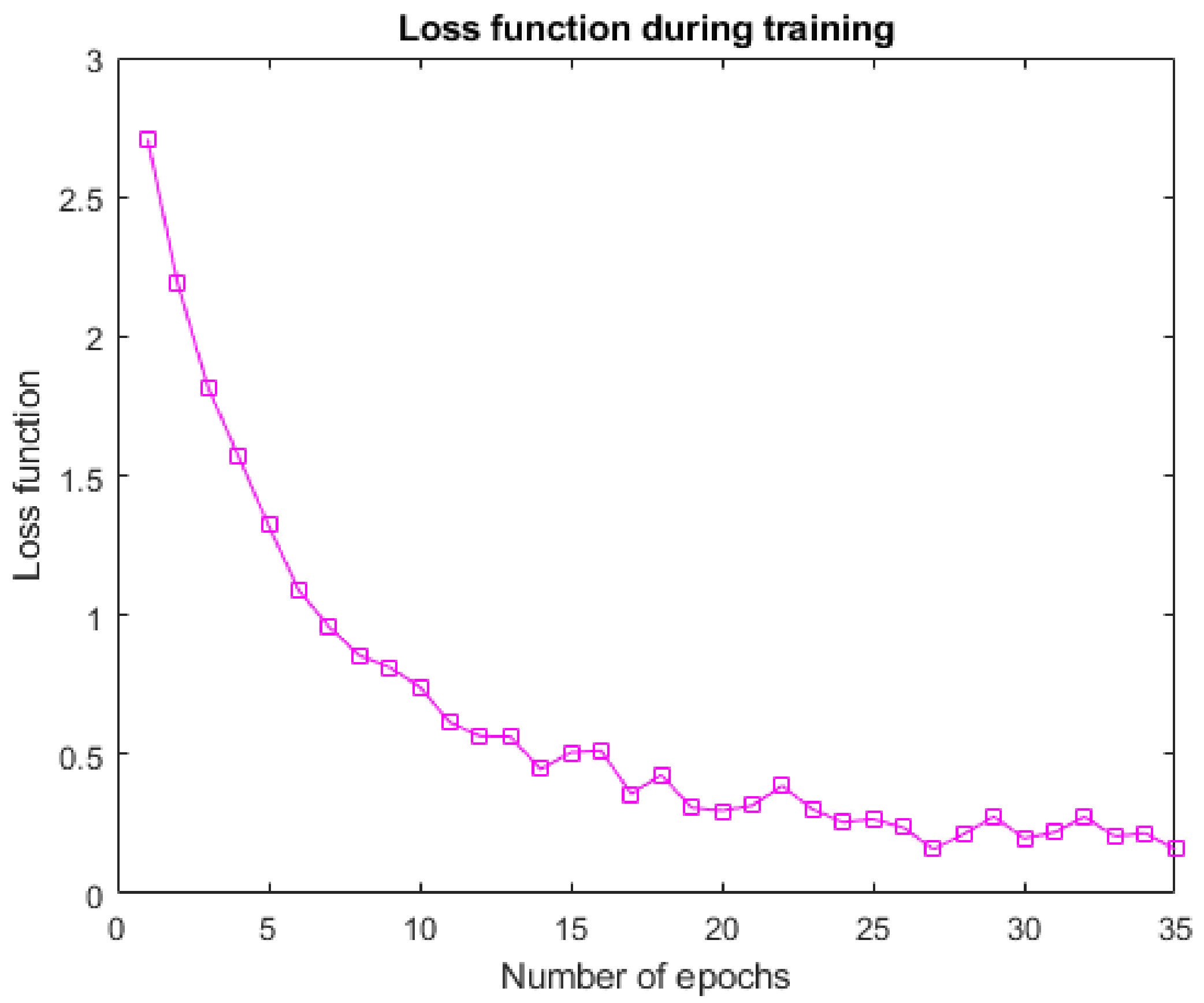
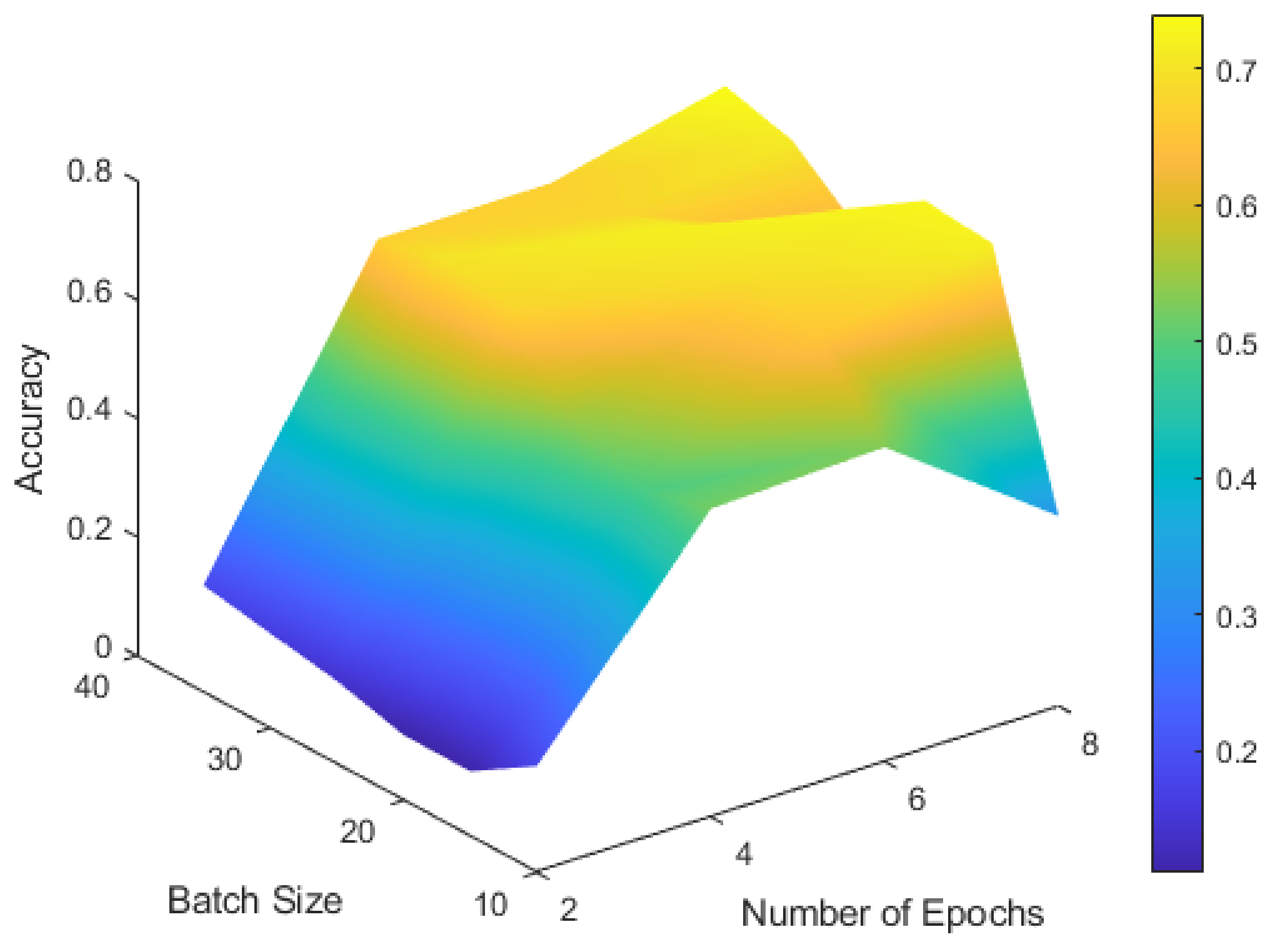
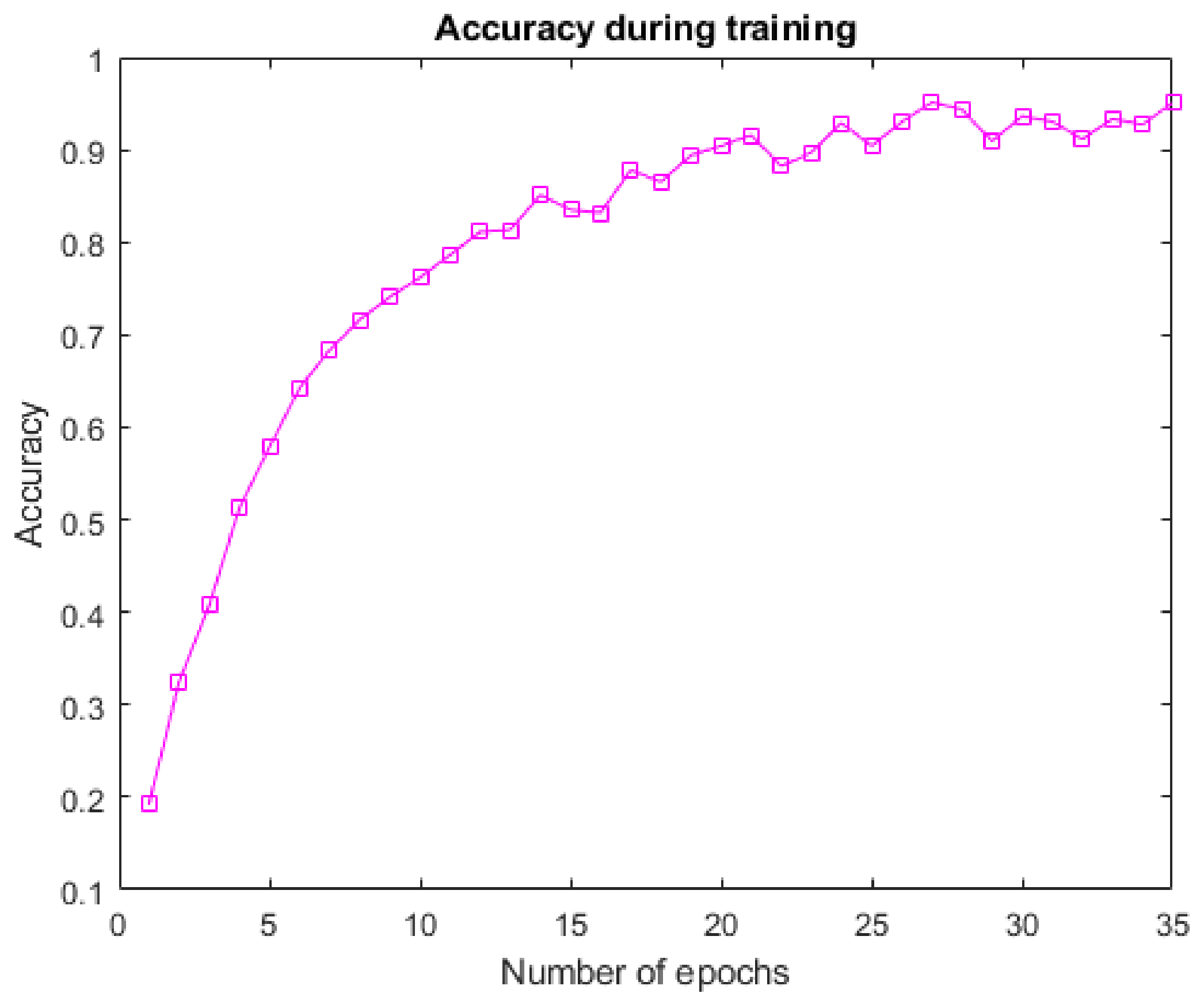
3.3. Results
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three-Dimensional |
| 3DCNN | 3D Convolutional Neural Network |
| ATM | Automated Teller Machine |
| CNN | Convolutional Neural Network |
| ConvLSTM | Convolutional Long Short-Term Memory |
| Conv2D | Two-Dimensional Convolution layer |
| LSTM | Long Short-Term Memory |
References
- Olmos, R.; Tabik, S.; Herrea, F. Automatic handgun detection alarm in videos using deep learning. Neurocomput. J. 2017, 275, 66–72. [Google Scholar] [CrossRef] [Green Version]
- Dhiman, C.H.; Vischakarma, D. High dimensional abnormal human activity recognition using histogram oriented gradients and Zernike moments. In Proceedings of the International Conference on Computational Intelligence and Computing Research (ICCIC), Coimbatore, India, 14–16 December 2017; pp. 869–872. [Google Scholar]
- Peixoto, B.; Avila, S.; Dias, Z.; Rocha, A. Breaking down violence: A deep-learning strategy to model and classify violence in videos. In Proceedings of the International Conference on Availability, Reliability and Security (ARES), Hamburg, Germany, 27–30 August 2018; pp. 1–7. [Google Scholar]
- Ramzan, M.; Abid, A.; Khan, H.A. Review on state-of-the-art violence detection techniques. IEEE Access 2019, 7, 107560–107575. [Google Scholar] [CrossRef]
- Liu, J.; Yang, Y.; Shah, M. Learning Semantic Visual Vocabularies using Diffusion Distance. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Liu, J.; Luo, J.; Shah, M. Recognizing Realistic Actions from Videos “in the Wild”. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Zhang, X.; Yao, L.; Huang, C.; Sheng, Q.Z.; Wang, X. Intent recognition in smart living through deep recurrent neural networks. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017; Volume 10634, pp. 748–758. [Google Scholar]
- Guo, Z.H.; Chen, Y.; Huang, W.; Zhang, J.H.; Wang, X. An Efficient 3D-NAS Method for Video-Based Gesture Recognition. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Munich, Germany, 17–19 September 2019; Volume 11729, pp. 319–329. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Hand sign language recognition using multi-view hand skeleton. Expert Syst. Appl. 2020, 150, 113336. [Google Scholar] [CrossRef]
- Wang, T.; Li, J.K.; Zhang, M.Y.; Zhu, A.C.; Snoussi, H. An enhanced 3DCNN-ConvLSTM for spatiotemporal multimedia data analysis. Concurr. Comput.-Pract. Exp. 2021, 33, e5302. [Google Scholar] [CrossRef]
- Castro-Vargas, J.; Zapata-Impata, B.; Gil, P.; Garcia-Rodriguez, J.; Torres, F. 3DCNN Performance in Hand Gesture Recognition Applied to Robot Arm Interaction. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM), Prague, Czech Republic, 19–21 February 2019; pp. 802–806. [Google Scholar]
- Mishra, B.; Garg, D.; Narang, P.; Mishra, V. A hybrid approach for search and rescue using 3DCNN and PSO. Neural Comput. Appl. 2021, 33, 10813–10827. [Google Scholar] [CrossRef]
- Wang, Y.H.; Dantcheva, A. A video is worth more than 1000 lies. In Comparing 3DCNN approaches for detecting deepfakes. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, Buenos Aires, Argentina, 16–20 November 2020; pp. 515–519. [Google Scholar]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.A.; Mekhtiche, M.A. Hand Gesture Recognition for Sign Language Using 3DCNN. IEEE Access 2020, 8, 550–559. [Google Scholar] [CrossRef]
- De Oliveira Lima, J.P.; Figueiredo, C.M.S. Temporal Fusion Approach for Video Classification with Convolutional and LSTM Neural Networks Applied to Violence Detection. Intel. Artif. 2021, 24, 40–50. [Google Scholar] [CrossRef]
- Tomei, M.; Baraldi, L.; Calderara, S.; Bronzin, S.; Cucchiara, R. Video action detection by learning graph-based spatio-temporal interactions. Comput. Vis. Image Underst. 2021, 206, 103187. [Google Scholar] [CrossRef]
- Castro-Vargas, J.; Zapata-Impata, B.; Gil, P.; Garcia-Rodriguez, J.; Torres, F. Mobile Neural Architecture Search Network and Convolutional Long Short-Term Memory-Based Deep Features Toward Detecting Violence from Video. Arab. J. Sci. Eng. 2021, 46, 8549–8563. [Google Scholar]
- Lin, W.; Gao, J.; Wang, Q.; Li, X. Learning to detect anomaly events in crowd scenes from synthetic data. Neurocomputing 2021, 436, 248–259. [Google Scholar] [CrossRef]
- Ahad, M.A.R.; Ahmed, M.; Antar, A.D.; Makihara, Y.; Yagi, Y. Action recognition using kinematics posture feature on 3D skeleton joint locations. Pattern Recognit. Lett. 2021, 145, 216–224. [Google Scholar] [CrossRef]
- Sultani, W.; Shah, M. Human Action Recognition in Drone Videos using a Few Aerial Training Examples. Comput. Vis. Image Underst. 2021, 206, 103186. [Google Scholar] [CrossRef]
- Hou, H.; Li, Y.; Zhang, C.; Liao, H.; Zhang, Y.; Liu, Y. Vehicle Behavior Recognition using Multi-Stream 3D Convolutional Neural Network. In Proceedings of the 2021 36th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanchang, China, 28–30 May 2021; Volume 32, pp. 355–360. [Google Scholar]
- Vrskova, R.; Hudec, R.; Sykora, P.; Kamencay, P.; Radilova, M. Education of Video Classification Based by Neural Networks. In Proceedings of the International Conference on Emerging eLearning Technologies and Applications (ICETA), Košice, Slovakia, 12–13 November 2020; pp. 762–767. [Google Scholar]
- Vrskova, R.; Hudec, R.; Sykora, P.; Kamencay, P.; Benco, M. Violent Behavioral Activity Classification using Artificial Neural Network. In Proceedings of the New Trends in Signal Processing (NTSP), Demanovska Dolina, Slovakia, 14–16 October 2020; pp. 1–5. [Google Scholar]
- Partila, P.; Tovarek, J.; Ilk, G.H.; Rozhon, J.; Voznak, M. Deep learning serves voice cloning: How vulnerable are automatic speaker verification systems to spooting trial. IEEE Commun. Mag. 2020, 58, 100–105. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chengping, R.; Yang, L. Three-dimensional convolutional neural network (3D-CNN) for heterogeneous material homogenization. Comput. Mater. Sci. 2020, 184, 109850. [Google Scholar]
- Vrskova, R.; Sykora, P.; Kamencay, P.; Hudec, R.; Radil, R. Hyperparameter Tuning of ConvLSTM Network Models. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 15–18. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Trnovszky, T.; Kamencay, P.; Orjesek, R.; Benco, M.; Sykora, P. Animal recognition system based on convolutional neural network. Adv. Electr. Electron. Eng. 2017, 15, 517–525. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted/Targeted | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 24 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 2 | 3 | 20 | 0 | 1 | 3 | 1 | 4 | 0 | 0 | 0 | 3 |
| 3 | 0 | 0 | 29 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 0 | 24 | 1 | 1 | 0 | 4 | 0 | 0 | 1 |
| 5 | 0 | 3 | 0 | 0 | 30 | 0 | 1 | 0 | 2 | 0 | 1 |
| 6 | 0 | 1 | 0 | 0 | 1 | 16 | 0 | 0 | 1 | 0 | 0 |
| 7 | 0 | 1 | 1 | 0 | 2 | 1 | 20 | 2 | 2 | 1 | 1 |
| 8 | 2 | 1 | 0 | 1 | 2 | 0 | 0 | 26 | 1 | 0 | 0 |
| 9 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 18 | 0 | 0 |
| 10 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 17 | 0 |
| 11 | 1 | 2 | 1 | 2 | 2 | 1 | 0 | 0 | 2 | 1 | 16 |
| Predicted/Targeted | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 28 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 2 | 0 | 0 |
| 2 | 0 | 13 | 0 | 2 | 0 | 0 | 0 | 4 | 2 | 0 | 0 | 4 | 2 | 3 | 0 |
| 3 | 0 | 0 | 21 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 20 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 0 | 0 | 0 | 26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 20 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 26 | 4 | 0 | 0 | 2 | 0 | 0 | 1 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 2 | 12 | 0 | 1 | 0 | 0 | 0 |
| 11 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 0 | 1 | 1 | 0 |
| 12 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 1 | 4 | 1 | 1 | 17 | 1 | 2 | 0 |
| 13 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 2 | 14 | 1 | 0 |
| 14 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 4 | 0 | 0 | 3 | 3 | 24 | 1 |
| 15 | 0 | 1 | 2 | 0 | 0 | 0 | 1 | 3 | 1 | 0 | 0 | 1 | 1 | 0 | 16 |
| Evaluation Metrics | UCF YouTube Action Dataset | Modified UCF101 Dataset | Full UCF50 Dataset | Full UCF101 Dataset |
|---|---|---|---|---|
| Precision (P) | 87.4% | 82.7% | 80.6% | 78.5% |
| Recall (R) | 85.6% | 87.7% | 84.8% | 81.2% |
| F1 score (F1) | 86.5% | 85.1% | 82.6% | 80.3% |
| Train/ Test Parameters | UCF YouTube Action Dataset | Modified UCF101 Dataset | Full UCF50 Dataset | Full UCF101 Dataset |
|---|---|---|---|---|
| Train loss | 0.08 | 0.07 | 0.14 | 0.21 |
| Train accuracy | 97.6% | 98.5% | 91.2% | 87.8% |
| Test loss | 1.51 | 1.43 | 1.61 | 1.79 |
| Test accuracy | 85.2% | 84.4% | 82.2% | 79.9% |
| Algorithm for Recognition | Accuracy [%] |
|---|---|
| Architecture for motion features [7] | 65.4 |
| Architecture for static features [7] | 63.1 |
| Architecture for hybrid features [7] | 71.2 |
| Proposed 3DCNN architecture previous research [22] | 29 |
| Proposed architecture | 85.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vrskova, R.; Hudec, R.; Kamencay, P.; Sykora, P. Human Activity Classification Using the 3DCNN Architecture. Appl. Sci. 2022, 12, 931. https://doi.org/10.3390/app12020931
Vrskova R, Hudec R, Kamencay P, Sykora P. Human Activity Classification Using the 3DCNN Architecture. Applied Sciences. 2022; 12(2):931. https://doi.org/10.3390/app12020931
Chicago/Turabian StyleVrskova, Roberta, Robert Hudec, Patrik Kamencay, and Peter Sykora. 2022. "Human Activity Classification Using the 3DCNN Architecture" Applied Sciences 12, no. 2: 931. https://doi.org/10.3390/app12020931
APA StyleVrskova, R., Hudec, R., Kamencay, P., & Sykora, P. (2022). Human Activity Classification Using the 3DCNN Architecture. Applied Sciences, 12(2), 931. https://doi.org/10.3390/app12020931