
Human Activity Recognition for Assisted Living Based on Scene Understanding



Abstract
:1. Introduction
2. Related Work
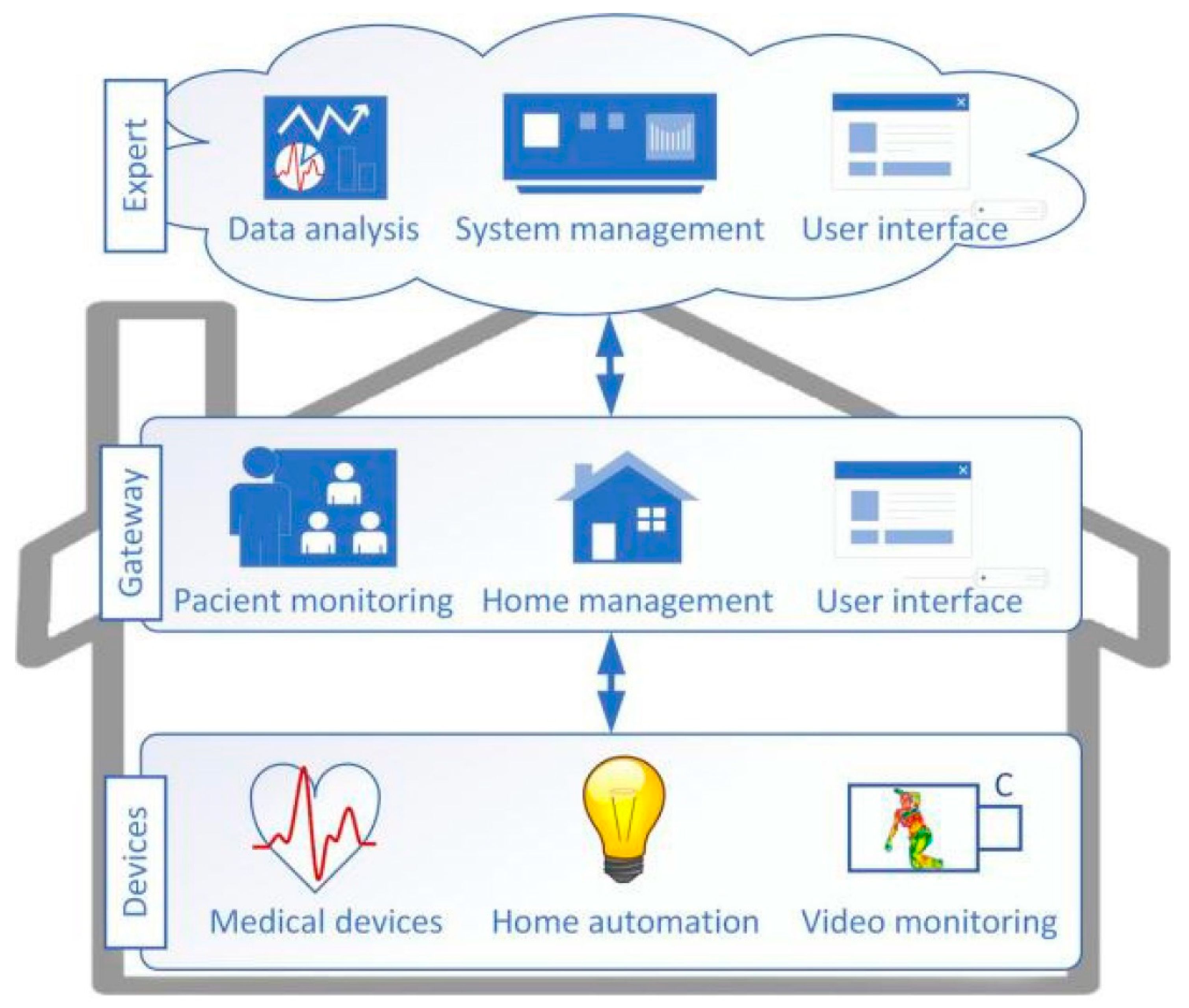
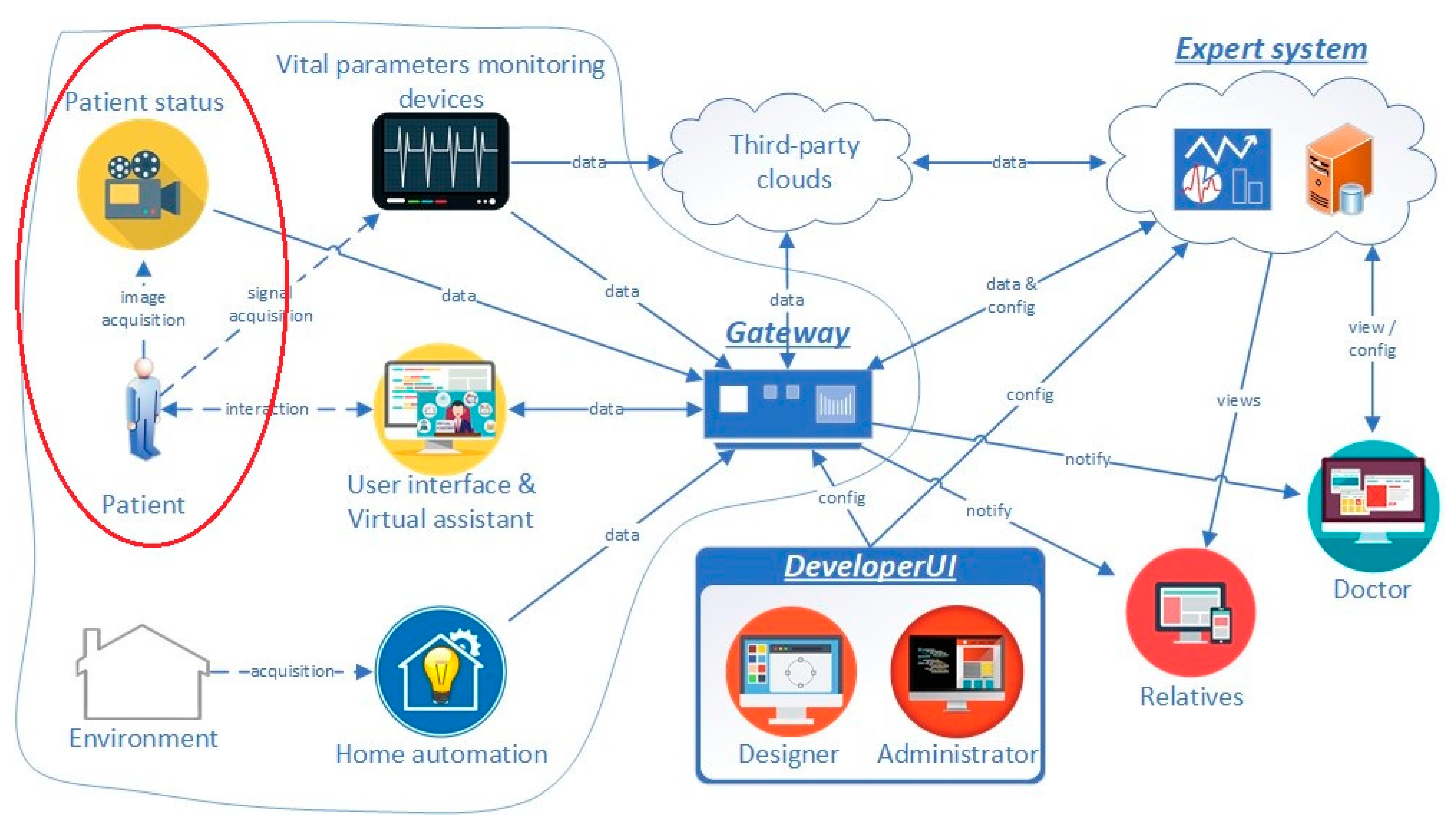
3. Human Activity Recognition in the SmartCare System
- Gateway: Implements the communication and interfaces with the installed telemedicine devices, actuators, as well as with the video monitoring component;
- Expert System: Cloud service that implements the intelligent processing of information from the sensor network and other stand-alone components by defining and following predefined monitoring and alerting rules;
- DeveloperUI: Graphical user interface that facilitates the design of solutions for specific home care applications. The patient’s needs differ from case to case, according to the medical conditions.
3.1. Monitoring Scenarios
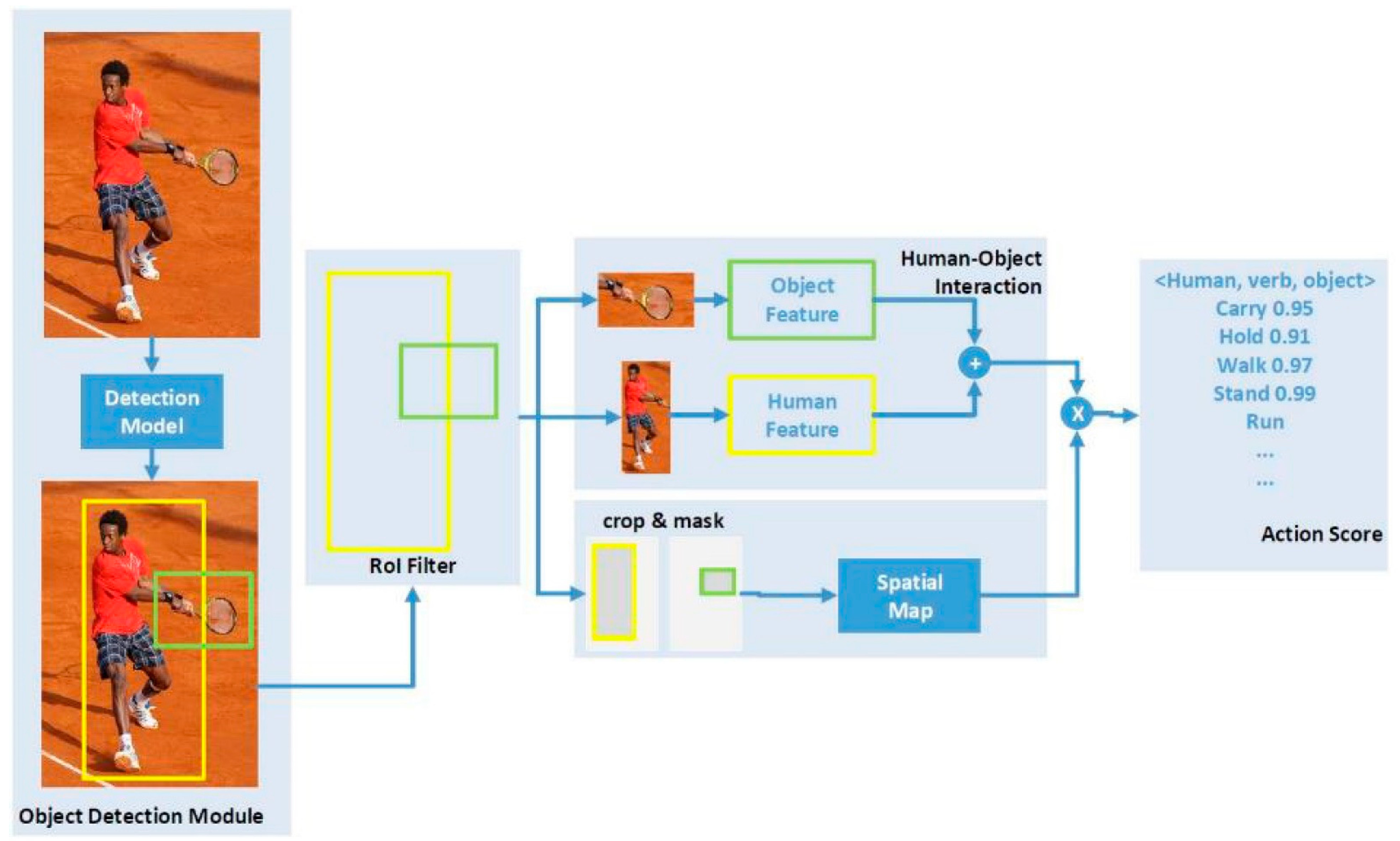
3.2. Object Detection and Human–Object Interaction Detection in HAR
- Scenario 1 (S1): in test cases with missing annotations for role a prediction for agent is correct if the action is correct and the person boxes overlap is >0.5 and the corresponding role is empty. This evaluation scenario is fit for missing roles due to occlusion.
- Scenario 2 (S2): in test cases with missing annotations for role, a prediction for agent is correct if the action is correct and the person boxes overlap is >0.5 (the corresponding role is ignored). This evaluation scenario is fit for cases with roles outside the COCO classes.
4. Used Datasets for Object Detection and HOI Detection
4.1. Common Objects in Context (COCO)
4.2. Verbs in Common Objects in Context (V-COCO)
- <agent, verb>: walk, smile, run, stand;
- <agent, verb, object>: cut, kick, eat, carry, throw, look, read, hold, catch, hit, point;
- <agent, verb, instrument>: surf, ski, ride, talk on the phone, work on computer, sit, jump, lay, drink, eat, hit, snowboard, skateboard.
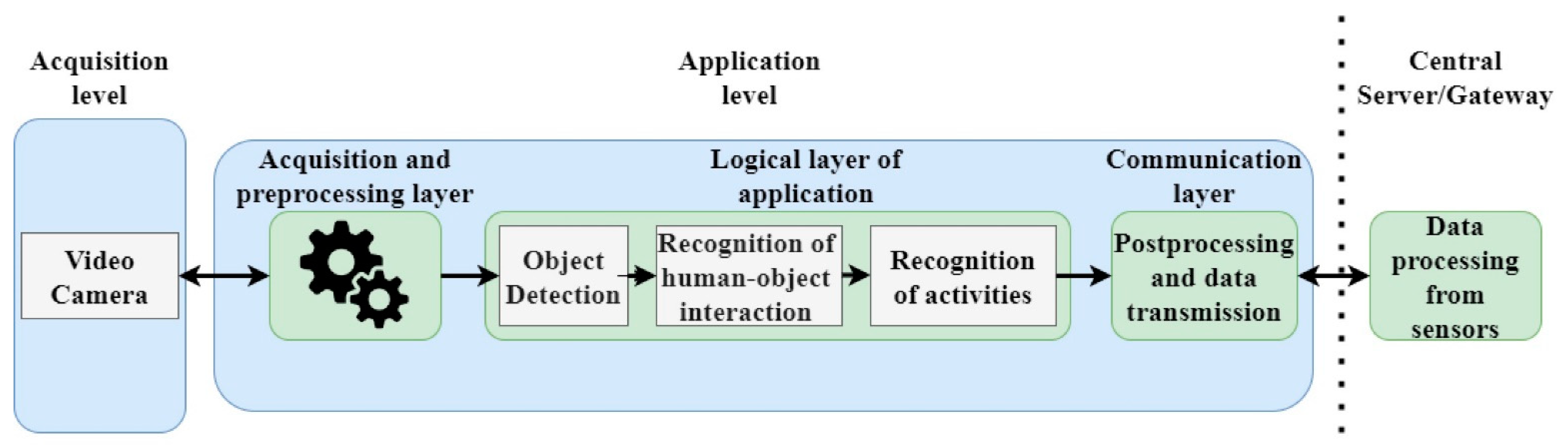
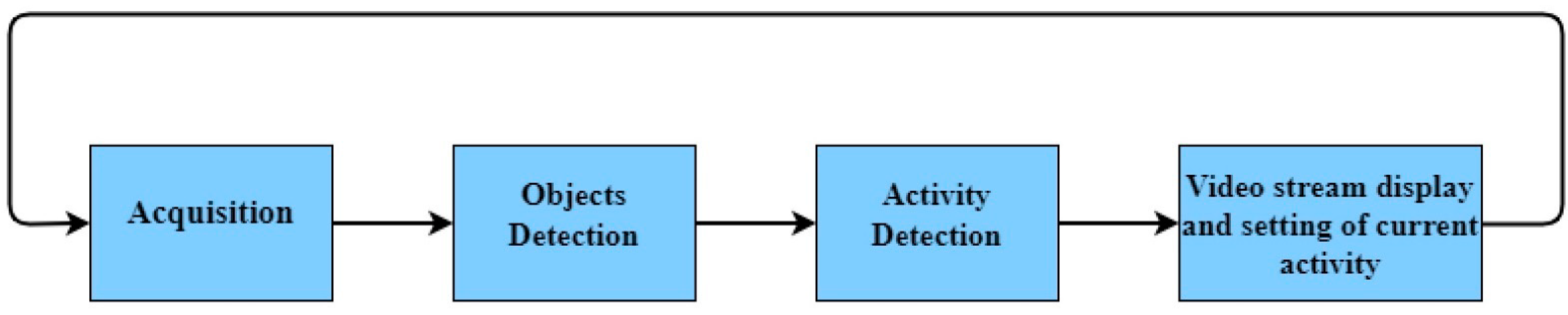
5. Human Activity Recognition Module Architecture
- The first layer acquires images and preprocesses them in order to be fed to the logic layer.
- In the logic layer, two neural networks are used: one for human and object detection and another one for human–object interaction detection. Based on the interactions, the activities which are performed by the monitored patient are determined.
- The communication layer prepares the data and transmits it to the server. The communication between the HAR system and the Gateway is carried out over the MQTT protocol. Based on a voting procedure that takes into consideration other sensor results as well, the Gateway decides when notification alerts are sent to the family or the medical doctor.
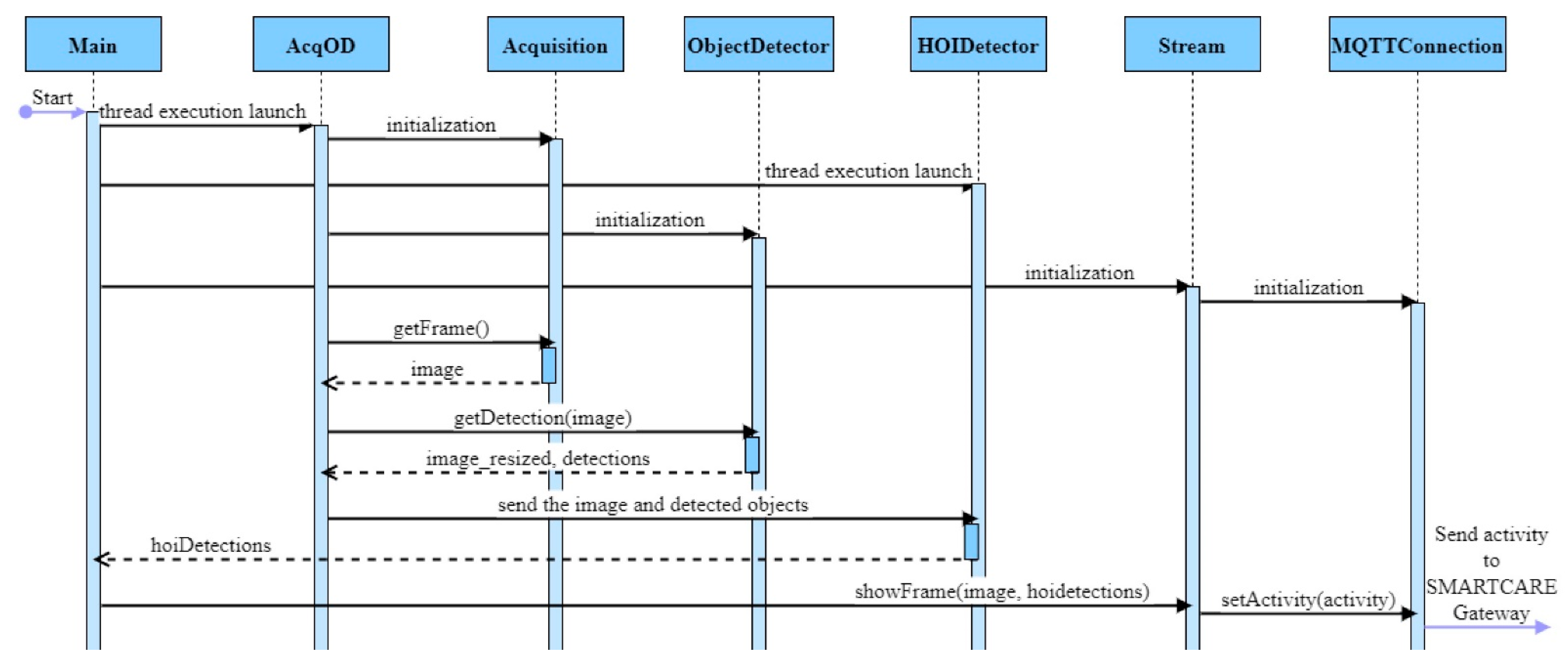
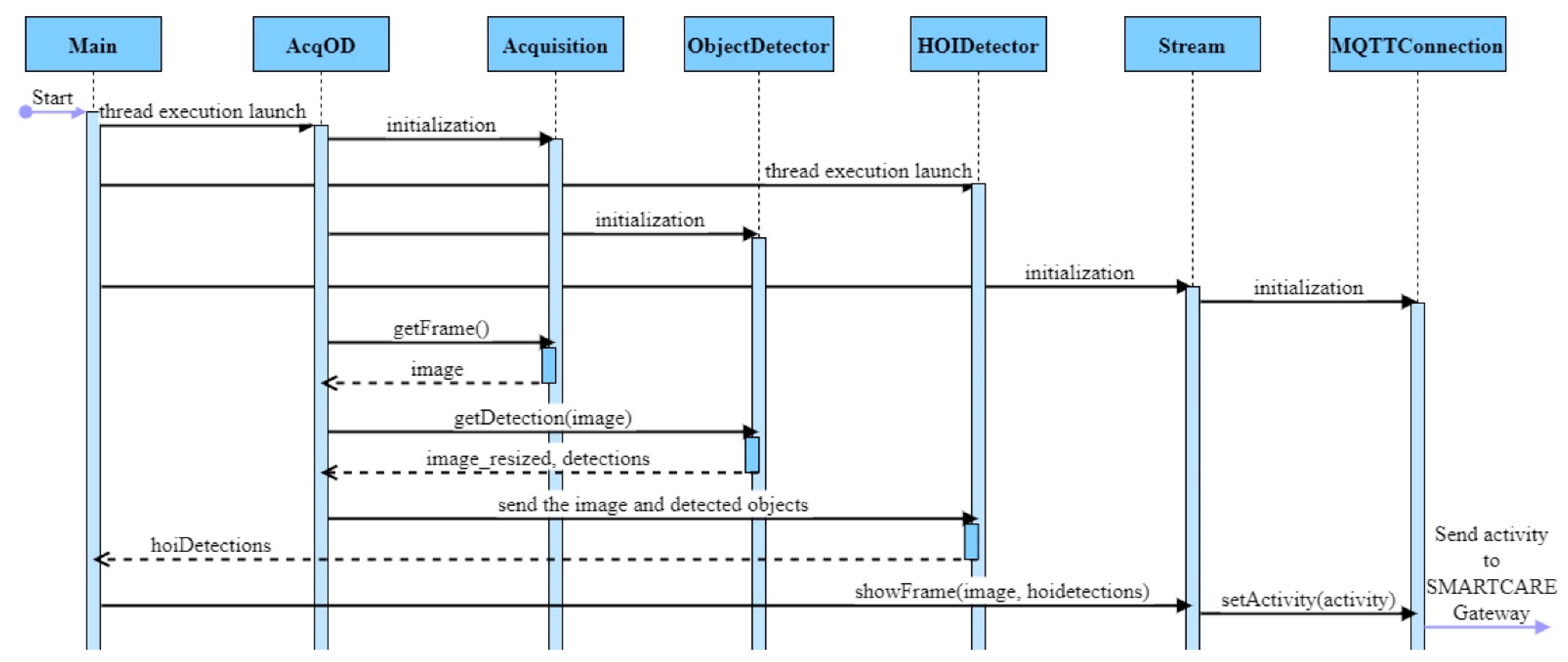
6. Design and Implementation
- CameraAcquisition and ZEDAcquisition implement the functionalities of IAcquisition interface: we considered the option of using a generic camera or the ZED camera (default option);
- AcquisitionAndObjectDetect thread is used for image acquisition and object detection;
- queueImageToHOI stores the object detection results;
- HOIDetector thread reads from queueImageToHOI, performs human–object interaction detection;
- queueHOIToMain stores the detected HOIs;
- MQTTConnection thread initiates the connection with the MQTT agent to which the Gateway is connected.
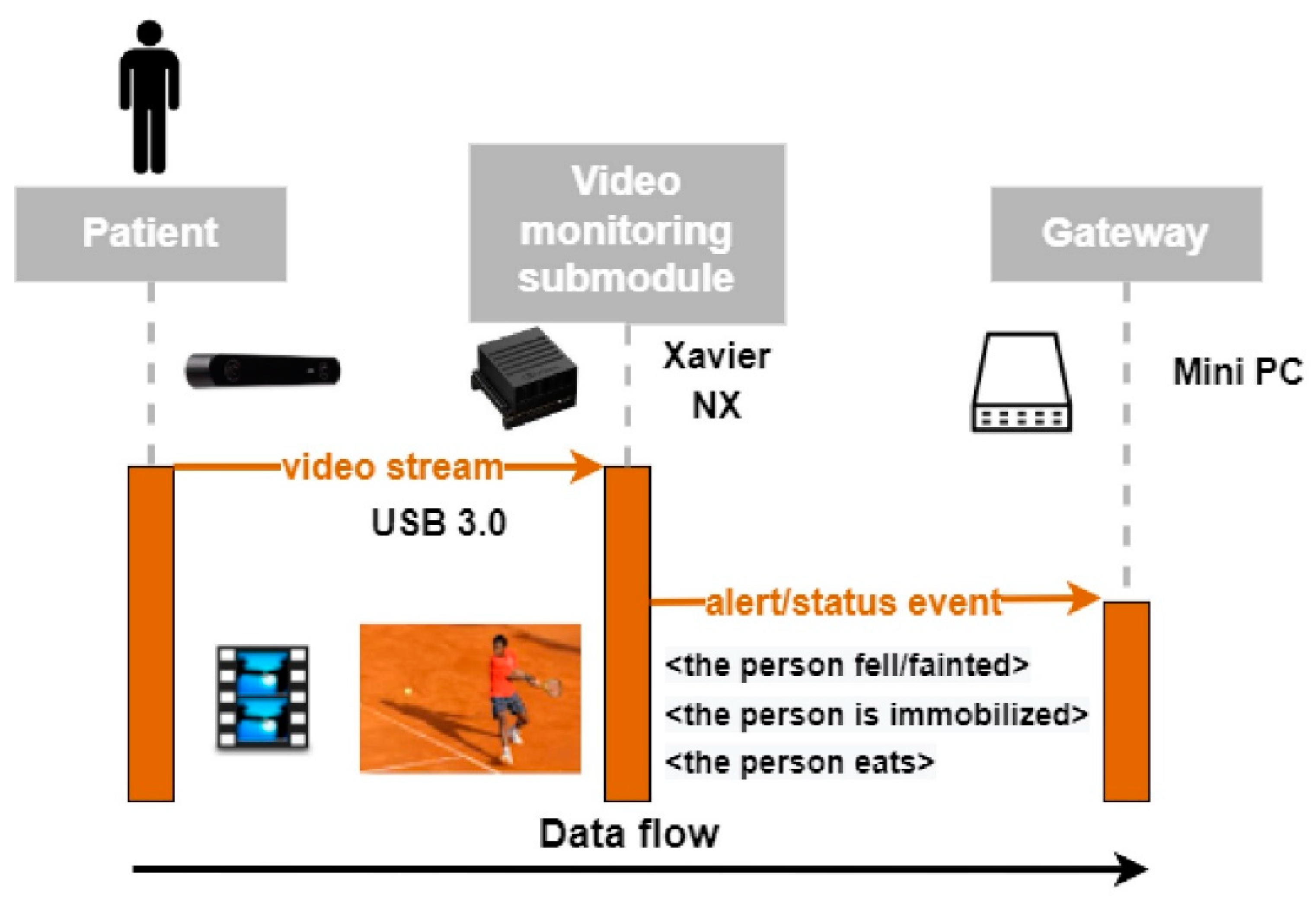
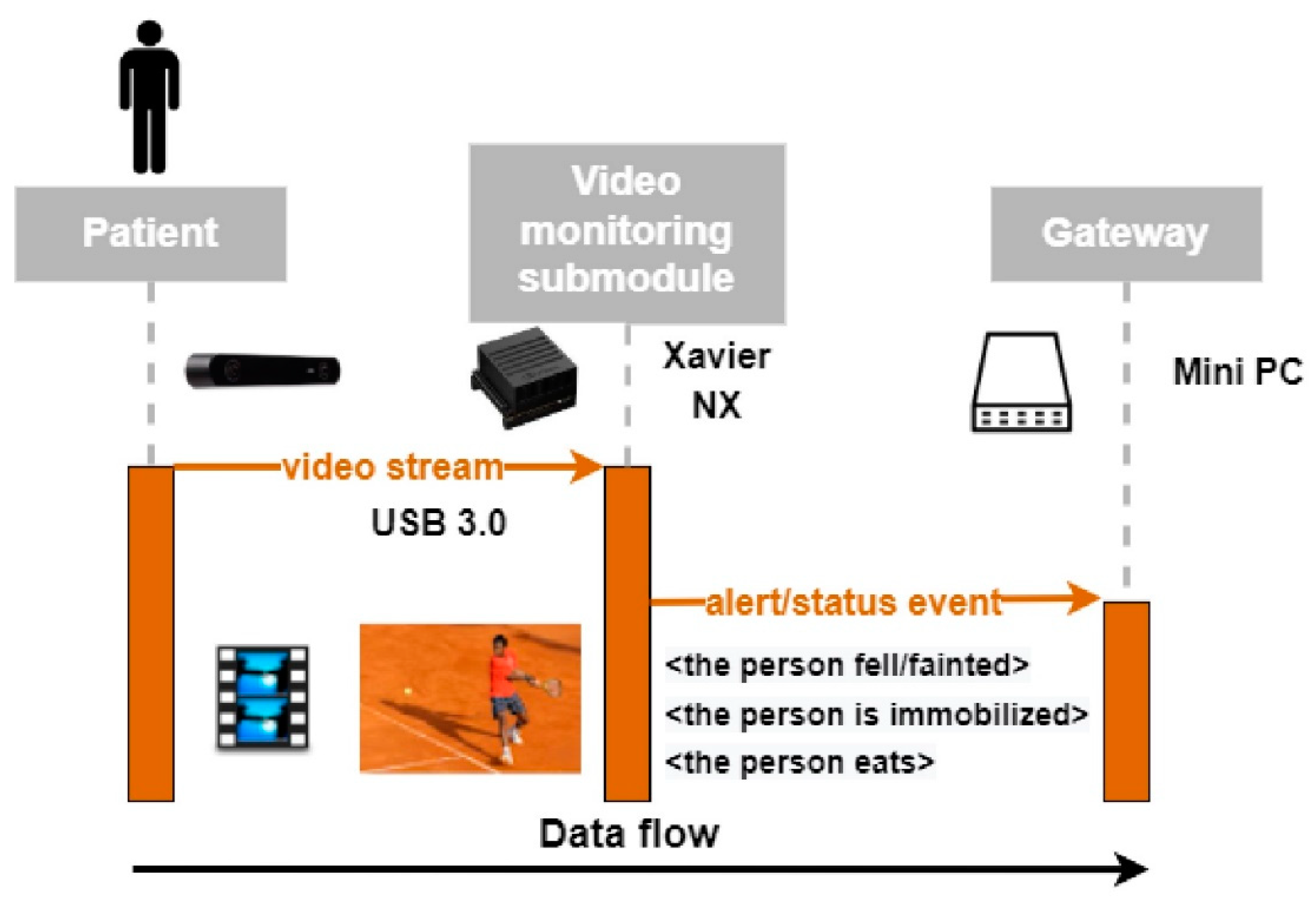
6.1. Forwarding Detected Activities to the SmartCare Gateway
- gateway/register;
- video-monit/1/activity/response-get;
- video-monit/1/activity/response-async-get.
- gateway/discover;
- video-monit/1/activity/get;
- video-monit/1/activity/async-get.
- gateway/register and gateway/discover are used for a handshake protocol: bridges from each device in the network (including the HAR system) subscribe to gateway/discover to receive a “get acquainted” message from the server, after which they publish device details to gateway/register to get recognized by the server.
- video-monit/1/activity/get and video-monit/1/activity/response-get: under the video-monit/bridge name we have 1/device enrolled with a resource of type activity/. The Gateway publishes an inquiring operation on the get/subtopic and the video monitoring system responds on the response-get/subtopic with the patient activity details. This message exchange is represented in Figure 13.
- video-monit/1/activity/async-get and video-monit/1/activity/response-async-get: similar with the above get/response-get topics, an asynchronous behavior is triggered by an ‘on’/‘off’ message. An example of asynchronous communication is illustrated in Figure 14.
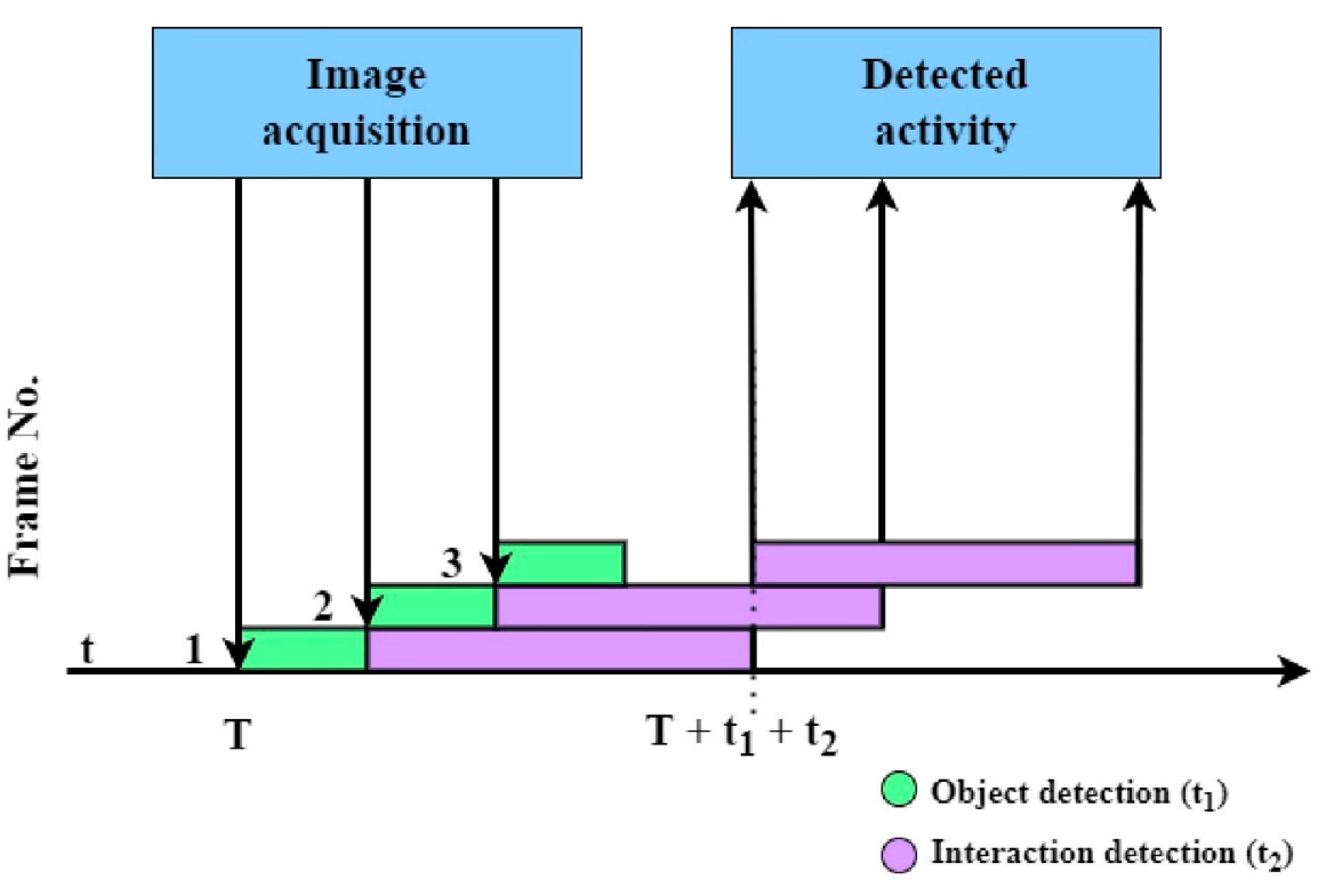
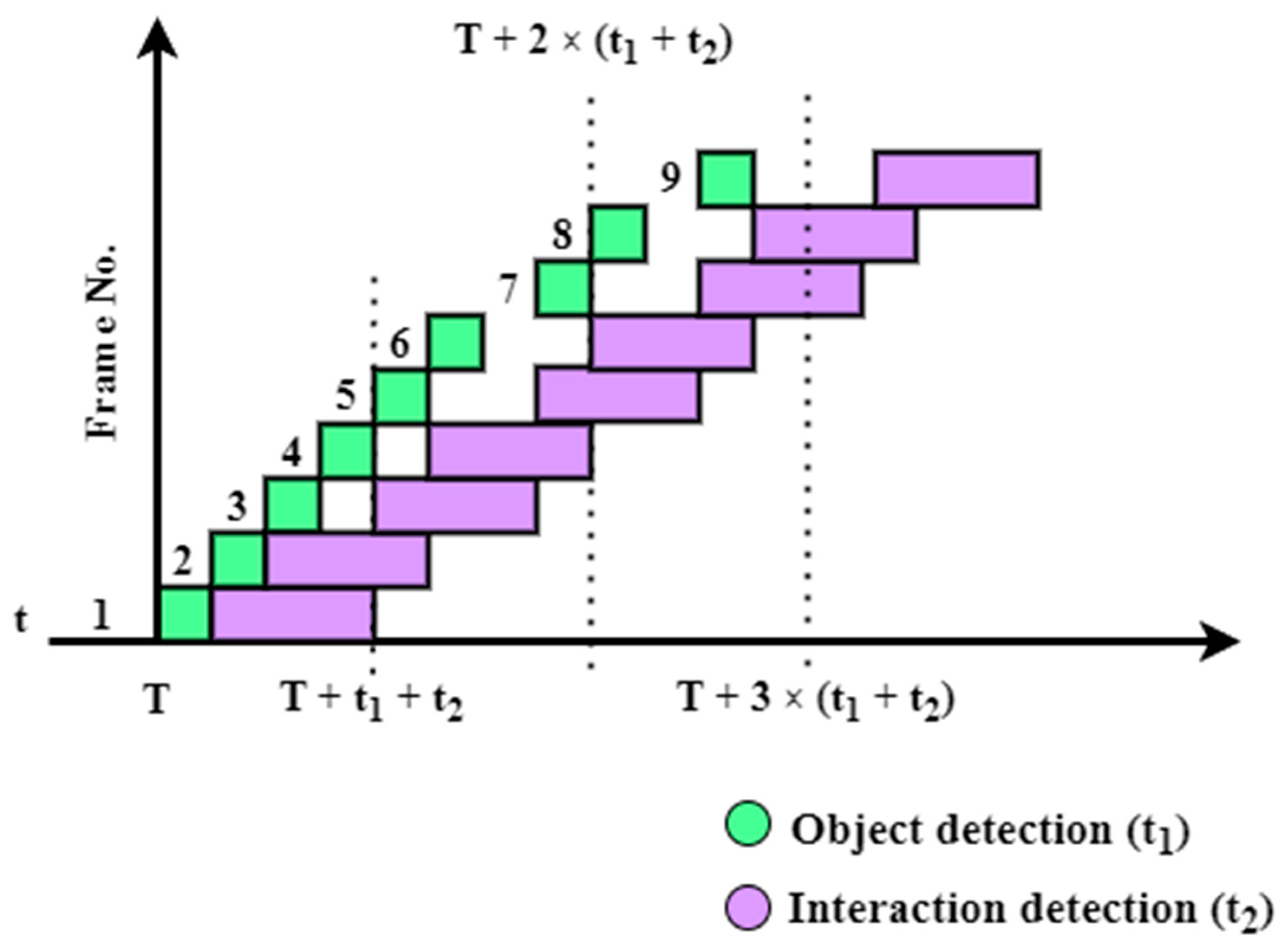
6.2. Thread Experiments
6.2.1. Configuration 1: Single Thread for Acquisition, Object Detection, and Activity Detection
6.2.2. Configuration 2: One Thread for Acquisition and Object Detection, Another One for Activity Detection
6.2.3. Configuration 3: One Thread for Acquisition and Object Detection, Two Threads for Activity Detection
6.3. Using HAR Results in the SmartCare System
- Vital parameters: heart rate (Fitbit Versa Smartwatch), blood pressure (Omron), blood glucose meter (Contour Plus), etc.
- Home automation: smart dimmer (AD146), smart switch (Fibaro Double Switch 2), valve actuator (Popp Flow Stop 2), smart lock (Danalock V3), waterleak detector (Abus Z-wave SHMW), panic button (Orvibo HS1EB), smart light bulb (Osram Smart A60), ambient temperature, gas sensor, etc.
- Physical activity: steps, fall detection, consumed calories (Fitbit Versa), the video monitoring system.
- Alzheimer’s disease: mandatory (smart lock, water tap, flood sensor, panic button), recommendation (switch, ambient temperature), nice to have (smart bulb, vibration sensor, humidity, HAR).
- Diabetic: mandatory (blood pressure, blood sugar), recommendation (oxygen saturation), nice to have (panic button, HAR, ambient temperature, humidity).
- Hypertensive: mandatory (blood pressure, heart rate), recommendation (oxygen saturation), nice to have (panic button, HAR, ambient temperature, humidity).
- Obese: mandatory (blood pressure, blood sugar), recommendation (heart rate), nice to have (HAR, ambient temperature).
- etc.
- If the light intensity is below 300 lux (which is the recommended value for an adult’s bedroom), the light is turned on (the dimmer is at a value greater than 0) and the patient is detected (HAR), then the light intensity value is increased step by step up to 300 lux.
- If the patient is using the sink (HAR) and a leak is detected, then the electricity is turned off (smart switch, smart plug), the tap is closed and the caregiver is alerted.
- If the patient serves the meal (HAR) and the blood sugar is above the upper limit for diabetes, then the patient and the caregiver are alerted.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mshali, H.; Lemlouma, T.; Moloney, M.; Magoni, D. A Survey on Health Monitoring Systems for Health Smart Homes. Int. J. Ind. Ergon. 2018, 66, 26–56. [Google Scholar] [CrossRef] [Green Version]
- Dang, L.M.; Piran, M.J.; Han, D.; Min, K.; Moon, H. A Survey on Internet of Things and Cloud Computing for Healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef] [Green Version]
- European Commission. The 2015 Ageing Report: Economic and Budgetary Projections for the 28 EU Member States (2013–2060); Publications Office of the European Union: Luxembourg, 2015.
- Vayyar. Smart Home-Vayyar. Available online: https://vayyar.com/smart-home (accessed on 20 October 2022).
- Ahmed, A.; Adewale, A.L.; James, A.; Mikail, O.O.; Umar, B.U.; Samuel, E. Human Vital Physiological Parameters Monitoring: A Wireless Body Area Technology Based Internet of Things. J. Teknol. Dan Sist. Komput. 2018, 6, 13039. [Google Scholar] [CrossRef] [Green Version]
- Borelli, E.; Paolini, G.; Antoniazzi, F.; Barbiroli, M.; Benassi, F.; Chesani, F.; Chiari, L.; Fantini, M.; Fuschini, F.; Galassi, A.; et al. HABITAT: An IoT Solution for Independent Elderly. Sensors 2019, 19, 1258. [Google Scholar] [CrossRef] [Green Version]
- Cubo, J.; Nieto, A.; Pimentel, E. A Cloud-Based Internet of Things Platform for Ambient Assisted Living. Sensors 2014, 14, 14070–14105. [Google Scholar] [CrossRef] [Green Version]
- CareStore Project. Available online: https://cordis.europa.eu/project/rcn/105930/factsheet/en (accessed on 20 October 2022).
- ACTIVAGE Project. Available online: https://cordis.europa.eu/project/rcn/206513/factsheet/en (accessed on 20 October 2022).
- Shao, D.; Yang, Y.; Liu, C.; Tsow, F.; Yu, H.; Tao, N. Non-contact Monitoring Breathing Pattern, Exhalation Flow Rate and Pulse Transit Time. IEEE Trans. Biomed. Eng. 2014, 61, 2760–2767. [Google Scholar] [CrossRef]
- Marques, G.; Pitarma, R. An Indoor Monitoring System for Ambient Assisted Living Based on Internet of Things Architecture. Int. J. Environ. Res. Public Health 2016, 13, 1152. [Google Scholar] [CrossRef] [Green Version]
- Gwak, J.; Shino, M.; Ueda, K.; Kamata, M. An Investigation of the Effects of Changes in the Indoor Ambient Temperature on Arousal Level, Thermal Comfort, and Physiological Indices. Appl. Sci. 2019, 9, 899. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, L.; Lanza, J.; Olsen, R.; Bauer, M.; Girod-Genet, M. A Generic Context Management Framework for Personal Networking Environments. In Proceedings of the 2006 Third Annual International Conference on Mobile and Ubiquitous Systems: Networking & Services, San Jose, CA, USA, 17–21 July 2006; pp. 1–8. [Google Scholar] [CrossRef]
- Höllerer, T.; Hallaway, D.; Tinna, N.; Feiner, S. Steps Toward Accommodating Variable Position Tracking Accuracy in a Mobile Augmented Reality System. In Proceedings of the 2nd International Workshop on Artificial Intelligence in Mobile Systems (AIMS’01), Seattle, WA, USA, 4 August 2001. [Google Scholar]
- Tsetsos, V.; Anagnostopoulos, C.; Kikiras, P.; Hadjiefthymiades, S. Semantically enriched navigation for indoor environments. Int. J. Web Grid Serv. 2006, 2, 453–478. [Google Scholar] [CrossRef]
- Chen, L.; Tee, B.K.; Chortos, A.; Schwartz, G.; Tse, V.; Lipomi, D.J.; Wang, H.-S.P.; McConnell, M.V.; Bao, Z. Continuous wireless pressure monitoring and mapping with ultra-small passive sensors for health monitoring and critical care. Nat. Commun. 2014, 5, 5028. [Google Scholar] [CrossRef] [Green Version]
- Lyardet, F.; Grimmer, J.; Mühlhäuser, M. CoINS: Context Sensitive Indoor Navigation System. In Proceedings of the Eigth IEEE International Symposium on Multimedia, San Diego, CA, USA, 11–13 December 2006. [Google Scholar] [CrossRef]
- Mshali, H.H. Context-Aware e-Health Services in Smart Spaces. Ph.D. Thesis, Université de Bordeaux, Bordeaux, France, 2017. [Google Scholar]
- Malasinghe, L.P.; Ramzan, N.; Dahal, K. Remote patient monitoring: A comprehensive study. J. Ambient Intell. Human Comput. 2019, 10, 57–76. [Google Scholar] [CrossRef] [Green Version]
- Buzzelli, M.; Albé, A.; Ciocca, G. A Vision-Based System for Monitoring Elderly People at Home. Appl. Sci. 2020, 10, 374. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is Faster R-CNN Doing Well for Pedestrian Detection? In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Hsieh, J.-T.; Balachandar, N.; Yeung, S.; Pusiol, G.; Luxenberg, J.; Li, G.; Li, L.-J.; Downing, N.; Milstein, A.; et al. Computer Vision-Based Descriptive Analytics of Seniors’ Daily Activities for Long-Term Health Monitoring. Mach. Learn. Healthc. 2018, 2, 1–18. [Google Scholar]
- Karen, S.; Andrew, Z. Two-Stream Convolutional Networks for Action Recognition in Videos. Adv. Neural Inf. Process. Syst. 2014, 568–576. [Google Scholar] [CrossRef]
- Lee, R.Y.; Carlisle, A.J. Detection of falls using accelerometers and mobile phone technology. Age Ageing 2011, 40, 690–696. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-López, J.R.; Ferrández-Pastor, F.J.; Nieto-Hidalgo, M.; Flórez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef] [Green Version]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. An Efficient Approach for Multi-view Human Action Recognition Based on Bag-of-Key-Poses. In Human Behavior Understanding; HBU 2012; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-López, J.R.; Climent-Pérez, P.; Flórez-Revuelta, F. Evolutionary joint selection to improve human action recognition with RGB-D devices. Expert Syst. Appl. 2014, 41, 786–794. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Jalal, A.; Mahmood, M. Vision-Based Human Activity Recognition System Using Depth Silhouettes: A Smart Home System for Monitoring the Residents. J. Electr. Eng. Technol. 2019, 14, 2567–2573. [Google Scholar] [CrossRef]
- Vishwakarma, V.; Mandal, C.; Sural, S. Automatic Detection of Human Fall in Video. In Proceedings of the Pattern Recognition and Machine Intelligence, Kolkata, India, 18–22 December 2007. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A Short Note on the Kinetics-700 Human Action Dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar] [CrossRef]
- Smaira, L.; Carreira, J.; Noland, E.; Clancy, E.; Wu, A.; Zisserman, A. A Short Note on the Kinetics-700-2020 Human Action Dataset. arXiv 2020, arXiv:2010.10864. [Google Scholar] [CrossRef]
- Monfort, M.; Pan, B.; Ramakrishnan, K.; Andonian, A.; McNamara, B.A.; Lascelles, A.; Fan, Q.; Gutfreund, D.; Feris, R.; Oliva, A. Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Monfort, M.; Jin, S.; Liu, A.; Harwath, D.; Feris, R.; Glass, J.; Oliva, A. Spoken Moments: Learning Joint Audio-Visual Representations From Video Descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14871–14881. [Google Scholar] [CrossRef]
- Achirei, S.; Zvorișteanu, O.; Alexandrescu, A.; Botezatu, N.; Stan, A.; Rotariu, C.; Lupu, R.; Caraiman, S. SMARTCARE: On the Design of an IoT Based Solution for Assisted Living. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Jetson-Inference. Available online: https://github.com/dusty-nv/jetson-inference (accessed on 20 October 2022).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Scharwächter, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision. 2015. Available online: https://www.cityscapes-dataset.com/wordpress/wp-content/papercite-data/pdf/cordts2015cvprw.pdf (accessed on 20 October 2022).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Valada, A.; Oliveira, G.; Brox, T.; Burgard, W. Deep Multispectral Semantic Scene Understanding of Forested Environments Using Multimodal Fusion. In 2016 International Symposium on Experimental Robotics. ISER 2016. Springer Proceedings in Advanced Robotics; Springer: Cham, Switzerland, 2017; pp. 465–477. [Google Scholar] [CrossRef]
- Zhao, J.; Li, J.; Cheng, Y.; Sim, T.; Yan, S.; Feng, J. Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 792–800. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar] [CrossRef]
- YOLO v4 and YOLO v4 Tiny Implementation by Darknet. Available online: https://github.com/pjreddie/darknet (accessed on 20 October 2022).
- Joseph, R.; Farhadi, A. Yolov3: An Incremental Improvement. 2018. Available online: https://doi.org/10.48550/arXiv.1804.02767 (accessed on 20 October 2022).
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Chen, G.; Zou, Y.; Huang, J. iCAN: Instance-centric attention network for human-object interaction detection. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar] [CrossRef]
- Gupta, S.; Malik, J. Visual Semantic Role Labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar] [CrossRef]
- Chao, Y.; Liu, Y.; Liu, X.; Zeng, H.; Deng, J. Learning to Detect Human-Object Interactions. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar] [CrossRef]
- Chao, Y.; Wang, Z.; He, Y.; Wang, J.; Deng, J. HICO: A Benchmark for Recognizing Human-Object Interactions in Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient is active | Person, chair, couch, bed | To run, to sit, to lay | <human, sits on, chair> <human, lays on, bed> |
| The patient serves the meal (after a diet recommended by the doctor) | Person, dining table, pizza, banana, apple, sandwich, orange, broccoli, carrot, hot dog, donut, cake, fork, knife, spoon, bowl, plate, oven, microwave, toaster, fridge, chair | To eat, to hold, to cut, to catch, to sit, to carry | <human, eats, sandwich> <human, eats, broccoli> <human, sits on, chair> <human, holds, fork> <human, eats, pizza> |
| The patient drinks liquids | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, drinks from, cup> <human, holds, bottle> <human, drinks from, wine glass> |
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient serves the meal (too often due to the condition, eats too much) | Person, food (different types of food: pizza, banana, apple, sandwich, hot fog, etc.), dining table, fork, knife, spoon, bowl, oven, toaster, fridge, microwave | To eat, to sit, to hold, to cut, to carry | <human, eats, donut> <human, carry, fork> <human, holds, bowl> <human, cuts with, knife> <human, holds, spoon> |
| The patient drinks liquids (too often) | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, drinks from, cup> <human, holds, bottle> |
| The patient opens the tap (and may forget it opened) | Person, sink | To stand, to hold, to point | <human, stands, -> <human, points at, sink> |
| The patient opens the gas while cooking (and may forget it opened) | Person, oven, bowl | To hold, to carry, to point | <human, holds, bowl> <human, points at, oven> <human, carry, bowl> |
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient is active | Person, chair, couch, bed | To run, to sit, to lay | <human, runs, -> <human, lays on, bed> |
| The patient serves the meal (after a diet recommended by the doctor) | Person, dining table, pizza, banana, apple, sandwich, orange, broccoli, carrot, hot fog, donut, cake, fork, knife, spoon, bowl, plate, oven, microwave, toaster, fridge, chair | To eat, to hold, to cut, to catch, to sit, to carry | <human, holds, spoon> <human, holds, bowl> <human, sits at, dining table> <human, eats, apple> <human, eats, cake> |
| The patient drinks liquids | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, holds, bottle> <human, carry, cup> <human, drinks from, wine glass> |
| Object Detector | Average Agent AP | Average Role AP [S1] | Average Role AP [S2] | Average Agent AP | Average Role AP [S1] | Average Role AP [S2] |
|---|---|---|---|---|---|---|
| Threshold = 0.2 | Threshold = 0.5 | |||||
| SSD-Mobilenet-v2 [39,42] | 25.78% | 11.75% | 12.99% | 26.43% | 13.43% | 14.80% |
| YOLO v4 tiny [41,43] | 26.62% | 13.41% | 15.09% | 26.79% | 14.92% | 16.70% |
| SSD-Inception-v2 [40,42] | 29.80% | 14.26% | 15.94% | 30.02% | 14.78% | 17.56% |
| YOLO v4 [41,43] | 56.68% | 37.77% | 43.20% | 57.05% | 40.07% | 45.72% |
| Detected Activity | SSD—Mobilenet—v2 | YOLO v4 Tiny | SSD—Inception—v2 | YOLO v4 |
|---|---|---|---|---|
| To eat | 4.24% | 7.06% | 4.14% | 32.11% |
| To drink | 0.75% | 5.76% | 2.13% | 25.69% |
| To lay on | 9.09% | 0.32% | 13.43% | 10.68% |
| To sit on | 17.17% | 7.91% | 22.59% | 34% |
| To stand | 48.88% | 53.27% | 54.35% | 78.51% |
| To hold an object/instrument | 7.85% | 9.48% | 9.03% | 34.78% |
| Category | Verbs with Associated Attribute Type |
|---|---|
| Essential verbs for SmartCare | walk, eat_object, sit_instrument, lay_instrument, drink_instrument, eat_instrument, hold_object, stand |
| Util verbs for SmartCare | cut_instrument, cut_object, talk_on_phone_instrument, work_on_computer_instrument, carry_object, smile, look_object, point_instrument, read_object, run, jump_instrument |
| Unnecessary verbs for SmartCare | surf_instrument, ski_instrument, ride_instrument, kick_object, hit_instrument, hit_object, snowboard_instrument, skateboard_instrument, catch_object |
| Acquisition and OD Threads | HOI Threads | Queue Size | FPS |
|---|---|---|---|
| 0 | 0 | 0 | 2.17 |
| 1 | 1 | 1 | 2.43 |
| 1 | 2 | 2 | 2.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Achirei, S.-D.; Heghea, M.-C.; Lupu, R.-G.; Manta, V.-I. Human Activity Recognition for Assisted Living Based on Scene Understanding. Appl. Sci. 2022, 12, 10743. https://doi.org/10.3390/app122110743
Achirei S-D, Heghea M-C, Lupu R-G, Manta V-I. Human Activity Recognition for Assisted Living Based on Scene Understanding. Applied Sciences. 2022; 12(21):10743. https://doi.org/10.3390/app122110743
Chicago/Turabian StyleAchirei, Stefan-Daniel, Mihail-Cristian Heghea, Robert-Gabriel Lupu, and Vasile-Ion Manta. 2022. "Human Activity Recognition for Assisted Living Based on Scene Understanding" Applied Sciences 12, no. 21: 10743. https://doi.org/10.3390/app122110743
APA StyleAchirei, S.-D., Heghea, M.-C., Lupu, R.-G., & Manta, V.-I. (2022). Human Activity Recognition for Assisted Living Based on Scene Understanding. Applied Sciences, 12(21), 10743. https://doi.org/10.3390/app122110743