1. Introduction
Recently, Facebook announced a name change to Meta and the launch of the Metaverse project, dedicated to creating a virtual world which allows people to work and live in a virtual environment, thereby overcoming the limitations of space via networks and VR/AR devices. To popularize the Metaverse, many international manufacturers have invested in the development of software and hardware such as virtual/augmented reality headsets and 3D digital content to provide reasonable device prices and optimal applications for users. At present, virtual/augmented reality (VR/AR) is being applied in various fields. For example, virtual medical imaging [
1,
2] allows doctors and medical staff to conduct accurate surgical treatment diagnoses or training through real-time high-resolution virtual organ images. Virtual museums [
3] enable the public to view antiquities in 360 degrees. Virtual shopping malls [
4] allow consumers to watch and try products without going to physical stores. Virtual classrooms [
5] support students operating virtual instruments and equipment, allowing them to conduct experiments and interact with each other, which can also reduce the risk of the spread of diseases due to crowds gathering in confined spaces. In virtual/augmented reality games, players can be immersed in the game world through a combination of virtual and real scenes. As previously described, VR/AR has dramatically enriched people’s life experience and improved work convenience and efficiency.
However, the traditional process of developing VR/AR content and applications is very time-consuming and expensive. To emulate the real world, generating 3D image models for real-world objects is essential. Digital content developers usually have to manually use 3D drawing software such as 3ds Max [
6] or Solidwork [
7] to draw objects, or use expensive equipment such as light detection and ranging (LiDAR) to scan objects. Fortunately, with the recent rapid development of Graphics Processing Units (GPUs), artificial intelligence (AI) has undergone tremendous development. Moreover, large-scale 3D model datasets such as ShapeNet [
8] and ModelNet [
9] have been released to support deep learning models to learn to reconstruct 3D object models from 2D images. Therefore, the deep learning approach to 3D model reconstruction has recently become a research hotspot and a cost-effective solution to minimize the development cost of VR/AR applications.
The methods of constructing a 3D object model from a 2D image can be divided into three categories [
10]: voxel, point cloud, and mesh, which is the output structure of the 3D model. The full name of a voxel is volume pixel; this represents a value on a regular grid in three-dimensional space. A point cloud is composed of high-density points in a limited 3D space. A mesh is a triangle or quadrilateral surface composed of points and edges in space. The point cloud is easy to render. The mesh can make the surface of the object models smooth by increasing the number of polygons. Both the point cloud and mesh are represented by a geometric form. By contrast, voxels are represented by a rasterized format. Consequently, they can be directly used by convolution neural networks (CNNs) [
11] to extract object features in order to construct 3D models. This paper focuses on the discussion and research of voxel-based 3D model reconstruction methods.
In the past, voxel-based 3D model reconstruction methods often required additional image data or precise condition control to achieve acceptable quality. For example, the method proposed by [
12,
13] requires cameras with depth sensors to create the depth data of images. Some approaches [
14] require multi-view images of objects. This equipment and data collection requirements restrict the development of AR/VR applications. To overcome this restriction, recent research [
15,
16,
17] proposed several methods to construct a voxel-based model using only a single image. The architecture of these methods may be divided into two parts. The first is called the encoder; this is responsible for extracting features from the input image. The second part is called the decoder; this is responsible for mapping the 2D image features into 3D structures. These methods have achieved an acceptable level for some object categories such as cars and airplanes while they leave a significant room of improvement for many other object categories. Accordingly, the design of the encoder and decoder architecture is an emergency research issue for 2D to 3D model reconstruction.
With this in mind, in this paper, we propose a voxel generator called VoxGen, based on the autoencoder architecture. The architectural characteristics of this voxel generator may be described as follows.
First, VoxGen uses VGG16 [
18] and ResNet18 [
19] for image feature extraction. The VGG16 network consists of 13 convolutional layers and 5 pooling layers. The ResNet18 network consists of 17 convolutional layers and one pooling layer. Consequently, VoxGen can extract more image features with a deeper network and effectively avoid the problem of gradient disappearance through the residual network. Moreover, VoxGen modifies VGG16 and ResNet18 by deepening and widening the fully connected network in order to learn the mapping between image features into latent variables.
Second, VoxGen provides an option of using a global average pooling layer or a fully- flattened layer in the flattened layer of the encoder architecture. This option allows users to minimize the time cost of training the voxel generator or optimize the accuracy of the 3D model reconstruction.
Third, VoxGen mixes deconvolution and convolution in the decoder architecture to map image features into a voxel model. Past methods often use up-pooling or deconvolution to map feature values to voxels. However, up-pooling fills the null value of the enlarged voxel map with 0 or a specific value. Although it is fast, it is not effective for accurate voxel reconstructions. By contrast, deconvolution is superior to up-pooling in terms of the accuracy of the model because it can properly estimate the values in the enlarged voxel map by training the filter parameters. Therefore, VoxGen also uses deconvolution to construct voxels while adding convolutional layers to enhance the features of the reconstructed voxels, thereby further improving the accuracy of the generated voxels.
In this paper, we have implemented the proposed voxel generator and have evaluated the performance impact of the above-mentioned architectural features. We also have compared the performance of the proposed voxel generator with other related approaches. The experimental results show that our proposed generator has better performance than the others in terms of the accuracy of generated voxels.
The rest of this paper is organized as follows.
Section 2 discusses related research;
Section 3 introduces the architecture of VoxGen;
Section 4 discusses the results of the performance evaluation; and finally,
Section 5 presents the conclusions of this research and discusses future work.
2. Related Work
Reconstructing 3D models from 2D images is one of the important applications in the field of computer vision. In recent years, research methods have been continuously proposed. For example, Liu, S. et al. [
20] proposed using 1000 perspective images with a 360° range of the object and a fixed angle change to reconstruct a 3D point cloud model of an object. Henry, P. et al. [
21] reconstructed 3D models from depth-capable cameras and RGB images. These methods require that images be taken by professionally calibrated cameras and be reconstructed geometrically.
By contrast, Choy, C.B., Xu, D., and Gwak, J. [
15] proposed a learning-based method called 3DR2N2 which takes a sequence of images from arbitrary viewpoints as input to generate a 3D voxel model as output. This method consists of two 2D-CNN encoders, an LSTM [
22]-based recurrence model and a 3D deconvolution decoder. When 3DR2N2 sees a new object, the LSTM-based recurrence model can effectively determine what should be retained or updated in the network memory. However, the performance of the model is dependent on the sequence of input images, and it can easily lose long-term memory.
Tahir, R., Sargano, A.B., and Habib, Z. [
16] proposed a method called V3DOR-AE to reconstruct a 3D model from a single image. This method is based on an autoencoder [
23]; it consists of seven convolutional layers to form the encoder and six 3D deconvolutional layers to form the decoder. The encoder is responsible for extracting the eigenvalues of the input image and converting them into latent variables. The decoder then maps the latent variables to voxel models. Xie, H. et al. [
17] proposed a method called Pix2Vox, which is also based on the autoencoder architecture. This method can infer the generated 3D model from single or multiple images as input. When multiple images are used, this method will generate multiple voxel models and merge them to refine the output. Although this process effectively improves the performance of Pix2Vox, it also significantly increases the computation cost of 3D model reconstruction. In addition, it does not convert the output of the encoder into the latent variables by a neural network to form the input of the decoder in order to contract 3D models. Therefore, it lacks stochastic learning capability in the mapping between the extracted image features and the reconstructed 3D models. Peng, K. et al. [
24] used a transformer-based encoder–decoder called TMVNet, which outperforms previous methods for 3D reconstruction. This method uses 2D CNN encoders to extract multiple-viewpoint image features and passes the extracted features to two transformer encoders to generate 3D feature vectors. Finally, it uses 3D CNN decoders to map the 3D vectors into voxel features and fuses these features to generate the output voxel. However, this method is not effective enough for reconstructing detail and non-smooth edges of object voxels.
In contrast to the aforementioned voxel-based methods, Pontes J.K. et al. [
25] designed a mesh-based method called Image2Mesh to reconstruct a 3D mesh model using a single image. This method comprises two parts. The first makes use of a convolutional neural network to extract the features of the image and determine the shape of the object through a neural network. The second part generates multiple grids from the features and then linearly combines the grids to refine the mesh structure. Wang, N. et al. [
26] proposed Pixel2Mesh, which uses an initialized ellipsoid mesh mode and then refines the initial mesh mode by gradually increasing the number of vertices of the grid and the image features extracted by the CNN. However, the initial mesh model is prone to the problem of holes that cannot be fitted. Using the same idea, Afifi, A.J. et al. [
27] published Pixel2Point, based on a CNN architecture, with an initial point cloud. This approach extracts the features of the input image and concatenates them with an initial point cloud of 256 space points to create a new feature with a size of 256 × 259. Then, it predicts the output point cloud by feeding the new features into a four-layer neural network.
By referencing previous research, in this paper, we propose a voxel model generator based on the autoencoder architecture. Different from the previously described voxel-based approaches, the proposed generator adopts modified VGG16 and ResNet18 to extract the features of input images with a deeper encoder architecture. It then translates the extracted features into latent variables to heuristically learn the process of 3D model reconstruction. Moreover, it mixes the deconvolution layer with the convolution layer in the decoder architecture to polish the voxel model.
3. VoxGen
The VoxGen voxel generator consists of an encoder and a decoder. It generates the output voxel for an input image as shown in
Figure 1.
The first step is data preprocessing, which adapts the size of the input image to 128 × 128 and then transforms the color image into a gray image by calling the cvtColor() function of OpenCV [
28] with the parameter of COLOR_BGR2GRAY. Finally, it normalizes the gray value to be between 0 and 1. In this paper, we use a 3D dataset ShapeNet that provides multiple-view color images to train VoxGen while it generates a 3D voxel model using only a single image. Grayscale images require only one-third of the storage space of color images. To reduce the computation cost, VoxGen adopts one channel in its encoder and decoder, like V3DOR-VE.
The second step is to extract the features of the preprocessed input image and then transform them into latent variables through the encoder. Currently, VoxGen has two encoder structures. One was constructed by modifying VGG16 and the other by modifying ResNet, including ResNet18, 34, and 50. In the modified-VGG16 encoder, as shown in
Figure 2, the front part is composed of five convolution blocks, each ending with a max pooling layer (2 × 2, stride = 2). These five convolution blocks are (3 × 3, 64, stride = 2) × 2, (3 × 3, 128, stride = 2) × 2, (3 × 3, 256, stride = 2) × 3, (3 × 3, 512, stride = 2) × 3, and (3 × 3, 512, stride = 2) × 3. The rear part consists of a flattened layer and two fully connected layers of 1 × 8192 and 1 × 4096; it is used to generate the output, which is reshaped as a 1 × 1 × 1 × 4096 latent variable.
As shown in
Figure 3, in the modified-ResNet18 encoder, the front part has a convolution layer (7 × 7, 64, stride = 2) and a max pooling layer (3 × 3, stride = 2) at the beginning, and four different-sized convolution layer blocks, i.e.,
× 2,
× 2,
× 2,
× 2, after the max pooling layer. The rear part is as same as in the VGG16-modified encoder. As for the modified ResNet34 and ResNet50 encoders, their architectures are similar to that of the modified ResNet18 encoder. The difference is that the four different-sized convolution blocks of the ResNet34 are
× 3,
× 4,
× 6, and
× 3, while those of ResNet50 are
× 3,
× 4,
× 6, and
× 3.
It is worth mentioning that the original VGG16 has three fully connected layers; their sizes are 1 × 4096, 1 × 4096, and 1 × 1000. By contrast, the original ResNet18, 34, and 50 have a global average pooling layer and one 1 × 1000 fully connected layer. Based on our experiments, the depth and width of the fully connected network of the original VGG16 and ResNet were not suitable to achieve sufficient accuracy of the generated 3D voxel models. Consequently, we increased the depth and width of the fully connected networks in the VGG16-encoder and ResNet18, 34, 50-modified encoders. Moreover, the flattened layer of the original VGG16 is fully flattened, while that of the original ResNet 18, 34, and 50 is a global average pooling layer, as shown in
Figure 4. Generally speaking, fully flattened layers are useful for improving the accuracy of generated 3D voxel models, as they retain all of the extracted features; however, they require massive data computation if the number of feature maps is large. Conversely, the global average pooling layer helps save on the computation cost of the neural network but may also degrade the accuracy of generated 3D voxel models because it reduces a feature map to a single value. Currently, VoxGen allows users to choose between the fully flattened or global average pooling layer according to their need to either optimize accuracy or minimize computation cost.
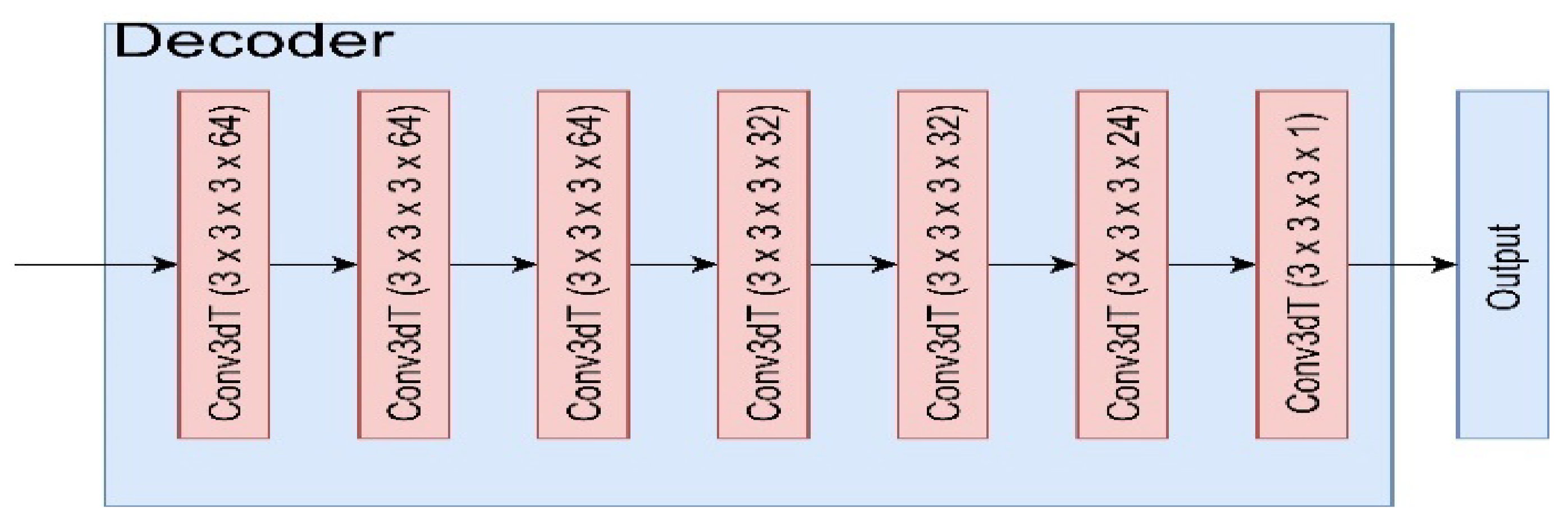
The step next to encoding is to generate the 3D mode voxel according to the latent variables through the decoder network. VoxGen has three decoder architectures, i.e., deconvolution, mixed-single convolution, and mixed-multiple convolution. The deconvolution decoder is composed of seven deconvolution layers. The parameters (filter number, filter dimension, stride) of these seven deconvolution layers are as follows: (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (24, 3 × 3 × 3, 1), (1, 3 × 3 × 3, 1), as shown in
Figure 5.
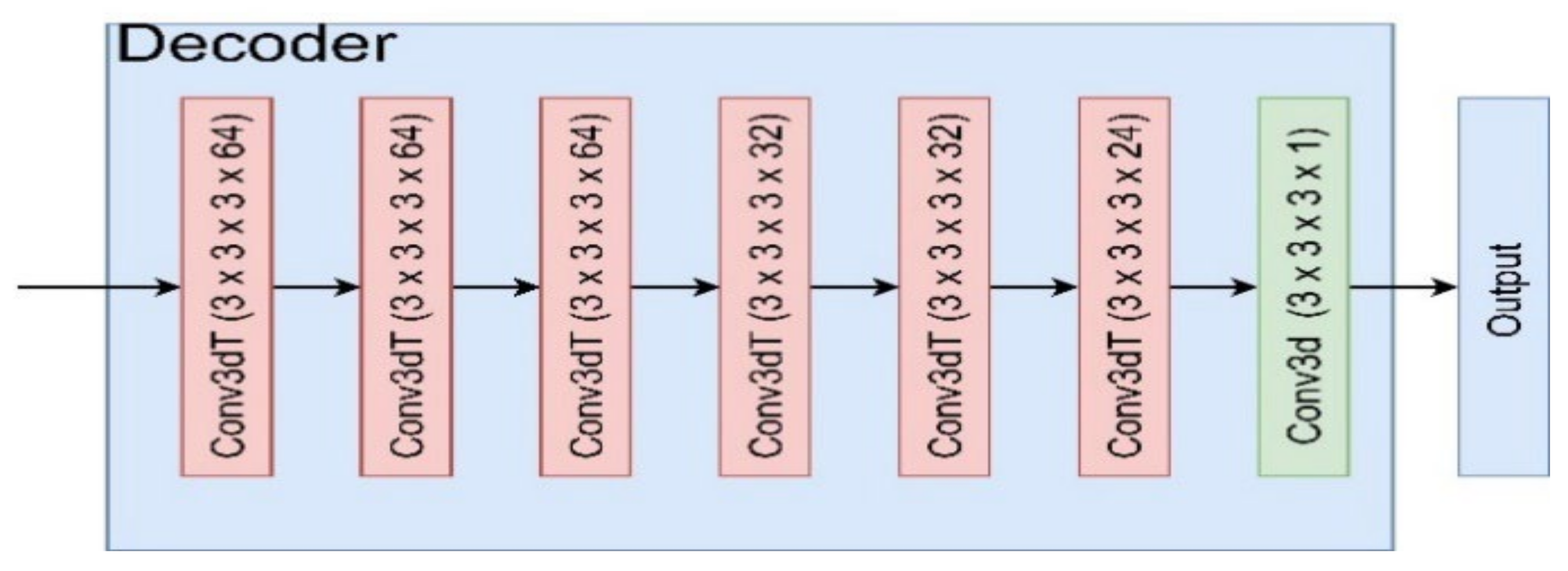
The mixed-single convolution decoder consists of six 3D deconvolution layers and one convolution layer, as shown in
Figure 6. The parameters of the six deconvolution layers are (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (24, 3 × 3 × 3, 1). The parameter of the 3D convolution layer is (1, 3 × 3 × 3, 1).
The mixed-multiple convolution decoder is composed of six deconvolution layers interleaved with six convolution layers, as shown in
Figure 7. The parameters of the six deconvolution layer are as follows: (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (64, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (32, 3 × 3 × 3, 2), (24, 3 × 3 × 3, 1). The parameters of the six 3D convolution layers are as follows: (64, 3 × 3 × 3, 1), (64, 3 × 3 × 3, 1), (64, 3 × 3 × 3, 1), (32, 3 × 3 × 3, 1), (32, 3 × 3 × 3, 1), (1, 3 × 3 × 3, 1).
Adding the convolution layer to the decoder is useful to highlight the features of the generated voxel model and polish the model edges; however, this increases the computation cost of the decoder network and may induce the overfitting problem. The performance of these three decoders will be compared in
Section 4.2.
Finally, the loss function used by VoxGen is Mean Squared False Error (MSFE) [
29], denoted as follows.
In this formula, the False Positive Error (FPE) and False Negative Error (FNE) estimate the errors in the negative and positive classes, respectively. Their formulas are as follows.
where
N is the negative-sample number,
P is the positive-sample number,
is the ground truth value,
is the predicted value,
i denotes the
i-th sample, and
n denotes the
n-th class.
Compared with MSE, and cross-entropy loss, MSFE can balance the weights between the negative and positive classes. In other words, the class of a small sample number can be valued equally to that of a large sample number. Consequently, it is possible to avoid the voxel generation model being dominated by a class with a massive sample number.
4. Performance Evaluation
In this paper, we have implemented VoxGen and undertaken a series of performance evaluations. The implementation language was Python3.7 [
30], the applied deep learning framework was TensorFlow 2.8 [
31], and the accelerator function library was CUDA 11.3. The experimental environment platform was a personal computer with Intel
® Xeon(R) Silver 4210 CPU @ 2.20 GHz CP, Nvidia GeForce
® GTX 3090 GPU, 64 GB DDR4 2933 MHz 288P Reg. ECC RAM and 1TB SSD. The operating system was 18.04.5 LTS (GNU/Linux 4.15.0-177-generic x86_64). The performance evaluation index was a volumetric Intersection over Union (volumetric IOU). The formula of IOU is as follows:
where
is the generated voxel model and
is the ground-truth voxel model.
In our experiment, the 3D data output by the voxel generator was a floating point number representing the probability of that point. In this study, the threshold was set to 0.5. If the probability was above the threshold, the data output would be 1; otherwise, it would be 0, and then the IOU value could be calculated. In this study, we used four classes, i.e., 3389 cars, 2199 chairs, 2318 lamps, and 2539 tables, in ShapeNet as the datasets for our performance evaluation. We randomly selected 80% of them as the training set and used the remaining 20% as the test set. The total numbers of training and test data were 481,896 and 120,164, respectively. The number of training epochs (Epoch) of the voxel generator network was 500, the batch size (Batch Size) was 128, and the optimizer (Optimizer) used Adam.
In the following subsections, we will discuss the impact of different encoders, flattening layers, and decoders on the IOU value of the generated voxel model. Finally, we will compare the performance of VoxGen with those of other related methods.
4.1. Comparison of Different Encoders
In this experiment, we used the V3DOR-AE feature extraction network, the modified GG16, ResNet18, ResNet34, and ResNet50 to play the encoder of VoxGen, and then evaluated the IOU performance of the VoxGen using the global pooling layer and the mixed single convolution decoder. The experimental results are shown in
Table 1.
First, it can be seen that when VoxGen uses any one of the modified-VGG16 (labeled as MVGG16), ResNet18, ResNet34, and ResNet50 encoders, it can generate voxel models with better IOU values compared with the V3DOR-AE encoder. This result proves that a deeper feature extraction network is indeed helpful for the quality of the generated voxel models. Moreover, a comparison of the modified ResBet18, ResNet34, and ResNet50 (labeled as MResNet18, MResNet34, and MResNet50) showed that continuously increasing the depth of the feature extraction network, while increasing the computational cost, does not guarantee that the IOU performance will improve. On the other hand, the experimental results showed that the modified VGG16 encoder was the best for cars and lamps, while the modified ResNet18 was the best for chairs and tables. It seems that these two decoders have their strengths and weaknesses for different classes of voxel generation. In consideration of efficiency, we focus only on these two encoder networks in the following tests.
4.2. Comparison of Different Decoders
In this experiment, we used three decoders, i.e., deconvolution (labeled as Deconv), mixed-single convolution (labeled as MSConv), and mixed-multiple convolution (labeled as MMConv) in VoxGen, respectively. In addition, we used the modified-VGG16 and the modified-ReseNet18 encoders and evaluated the performance of the two encoders combined with the three decoders. The flattened layer of VoxGen was global average pooling. The experimental results are shown in
Table 2. When the encoder was MVGG16, MSConv was better than Deconv, while MMConv was no better than Deconv for the performance of VoxGen in any of the four classes. By contrast, both of MSConv and MMConv outperformed Deconv in all four classes when the encoder was MResNet18. Moreover, MMConv was superior to MsConv in the chair, lamp, and table classes. On the other hand, the combination of MVGG16 and MSConv was the best for the car and lamp classes, while the combination of MResNet18 and MMConv was the best for the chair and table classes.
According to these experimental results, we can conclude that mixing one convolution layer is beneficial for the performance of the voxel generator, while mixing more convolution layers is unnecessary. MMConv seems to be more suitable than MSConv for a deeper encoder network such as MResNet18. When the shape of objects such as chairs and tables was complex and irregular, the combination of MResNet18 and MMConv was better in terms of the quality of generated voxel models.
4.3. Comparison of Different Flatten Layers
In this experiment, we used the fully flattened (FF) layer and the global average pooling (GAP) layer as the flattened layer of the MVGG16 and MResNet18, Then, we evaluated the impact of the FF and GAP layers on the performance of VoxGen.
Table 3 depicts the parameter number and model size of VoxGen with the FF layer and the GAP layer, respectively. It can be seen that the parameter number and model size of VoxGen using the GAP layer was about one-half of that using the FF layer, no matter which encoder-decoder combination was used. It also implies that the voxel generator reduces the computational requirements by around 50%. On the other hand,
Table 4 depicts the impact of different types of flattened layers on different encoder–decoder combinations. It can be seen that FF was more effective than GAP for most of the encoder–decoder combinations, especially for the MVGG16–MMConv one, due to the fact that this combination retained the complete extracted features. The special case was that when the MVGG16-MSConv combination was used, the GAP layer was better than the FF layer for the car class because the car shape was common and the GAP layer is useful for making features regular. By contrast, the MResNet18–MMConv combination using the FF layer was the best for the other three classes. As previously discussed, users can select the FF layer or the GAP layer to optimize the performance of the voxel generator or reduce the demand for computation resources.
4.4. Comparison with Related Approaches
In this experiment, we compared the proposed voxel generator with related approaches including 3D-R2N2, V3DOR-AE, Pix2Vox, and TMVNet in terms of IOU. The experimental results are shown in
Table 5. For the car and chair class, TMVNet could generate the highest IOU value, i.e., 0.870 and 0.721. By contrast, VoxGen yielded the best IOU values, i.e., 0.597, and 0.716, for the lamp and table classes, respectively, when it used the MResNet18 encoder, the FF layer, and the MMConv decoder. It seems that these two methods have different strengths and weaknesses with different object classes. VoxGen has a deeper and wider encoder network and a loss function, which can prevent the large-number of samples from dominating the output voxel. In contrast, the strength of TMVNet is its efficacy at aggregating the position information from multiple-view images.
On the other hand, VoxGen outperformed 3D-R2N2 for the four object classes, regardless of which combination of encoder, decoder, and flattened layer was used. The main reason for this is that 3D-R2N2 uses LSTM, which is sensitive to the sequence of input images, as well as the up-pooling that always adds zero in the empty entries in the generated voxel models. By contrast, VoxGen adopts CNN, which is independent of the sequence of input images and the deconvolution layer that can properly estimate the values added to the empty entries in the generated voxel models. The same situation also occurred in the comparison between VoxGen and V3DOR-AE. VoxGen adopts a deeper encoder network for extracting image features and a wider fully connected network to increase learning ability than V3DOR-AE. In addition, it adds the convolution layer behind the deconvolution layer in the decoder to enhance the properties of the generated voxels, while V3DOR-AE only uses deconvolution. These differences allowed VoxGen to outperform V3DOR-AE.
Figure 8 is a visual comparison of voxels generated by our approach and Pix2Vox. As shown in
Table 5, our approach was worse than Pix2Vox only for the car class in some combinations of encoder, decoder, and flattened layer. Although the feature-extraction network of Pix2Vox is the same as that of VGG16, it has no neural network between the encoder and the decoder. Consequently, it does not have non-linear learning ability, in contrast to VoxGen. Even though Pix2Vox merges multiple generated voxels in order to refine the final output, this does not guarantee that the quality of the output voxel will be improved. As previously discussed, VoxGen is more effective than the three other approaches in terms of the quality of generated voxels, due to its superior architecture.
5. Conclusions and Future Work
We have successfully developed a voxel generator called VoxGen, based on an autoencoder. This voxel generator adopts the modified VGG16 and ResNet18 to improve the effectiveness of feature extraction and mixes the deconvolution layer with the convolution layer in the decoder to generate and polish the output voxels. Moreover, it allows users to select the fully flattened or the global average pooling layer to optimize the quality of the generated voxels or reduce the computational cost of model training, respectively.
We performed a set of experiments to evaluate the impact of different combinations of encoders, decoders, and flattened layers. The conclusions derived from our experiments are as follows. First, a deep feature extraction network is essential for the quality of the generated voxels, especially when the object shape is complex and irregular. However, increasing the depth of the feature extraction network does not always improve the quality of generated voxels, as they are also dependent on the selected flattened layer and the network architecture of the used decoder. Second, adding a convolution layer at the end of consecutive deconvolution layers is useful for improving the quality of the generated voxels. However, adding a convolution layer behind each deconvolution layer does not promise further improvements in the quality of the generated voxels because its effect is dependent on the combined encoder architecture and the object-shape complexity. Third, the fully flattened layer is essential for the quality of the generated voxels, especially when the object shape is complex and irregular. Conversely, the global average pooling layer is useful for increasing the efficiency of the voxel generator, especially when the resolution of the voxels or the architecture complexity of the encoder and decoder is very high. Forth, the best architecture combination of VoxGen for the car class is MVGG16+MSConv+GAP, while that for the chair, lamp, and table classes is MResNet18+MMConv+FF. Consequently, carefully selecting a proper architecture is important for the performance of the voxel generator. Finally, the proposed generator is more effective than approaches such as 3DR2N2, V3DOR-AE, or Pix2Vox because of its better encoder or decoder architecture. However, VoxGen and TMVNet demonstrated different strengths and weaknesses for different object classes.
Even though we have achieved a significant performance improvement in voxel generation, we will continue to improve the architecture of VoxGen in the future. For example, we will try to decompose objects into a set of components, and then generate the voxel for each component before merging the generated voxel to form a complete voxel model for the object. On the other hand, the voxel resolution of VoxGen is currently only 32 × 32. We will try to increase the resolution of the generated voxels while maintaining the efficiency of the voxel generator.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}