
Robustness Analysis on Graph Neural Networks Model for Event Detection


Abstract
:1. Introduction
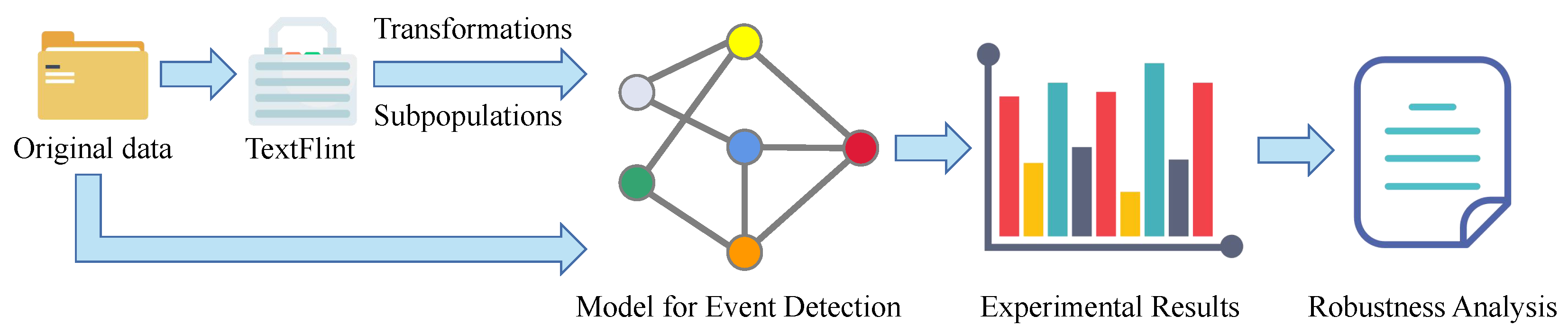
- In the absence of current research on the robustness of ED models, we propose a Robustness Analysis Framework on an ED Model that facilitates the comprehensive analysis of the ED model’s robustness.
- We propose a new multi-order distance representation method and an edge representation update method based on attention weights to enhance EE-GCN, then design an innovative GNN-based ED model named A-MDL-EEGCN. Our experiments illustrate that the performance of this model is better than that of the previously proposed GNN-based ED models on the ACE2005 dataset, especially when adversarial data exists.
- Using the robustness analysis framework on the ED model, we perform extensive experiments to evaluate the performance of several GNN-based ED models, and the comprehensive robustness analysis according to experimental results brings new insights to the evaluation and design of robust ED models.
2. Related Work
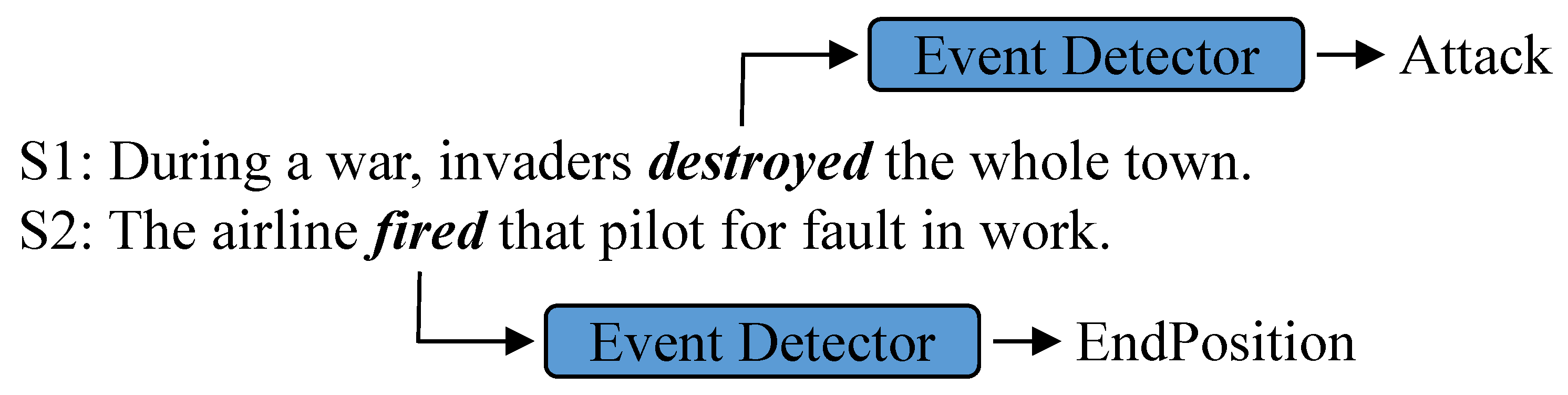
2.1. Event Detection
2.2. Robustness Research in Natural Language Processing
3. Robustness Analysis Framework on Event Detection Model
3.1. Text Transformations
3.2. Subpopulations
4. Model
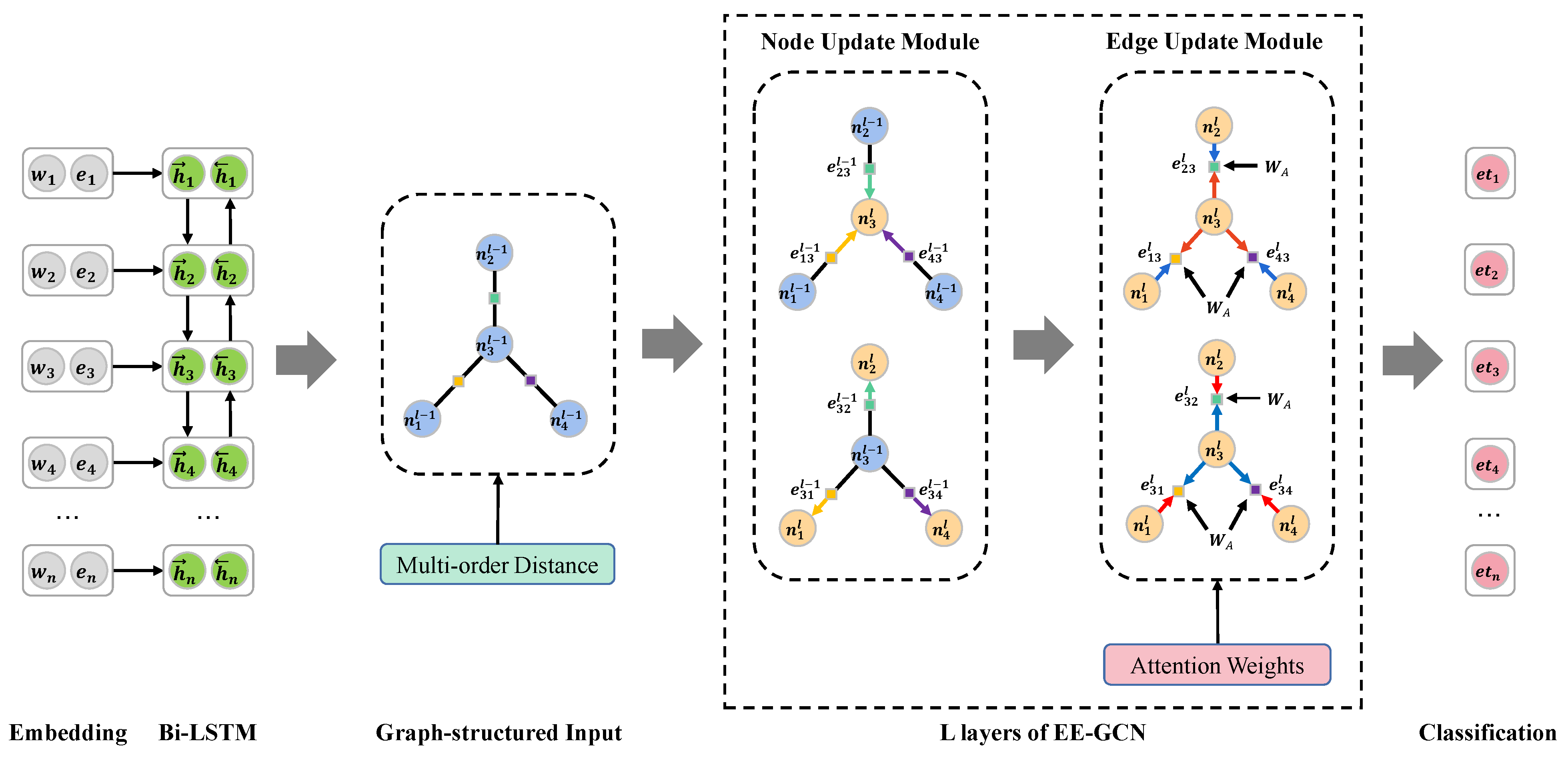
4.1. Edge-Enhanced Graph Convolution Networks
4.2. Enhancement of EE-GCN
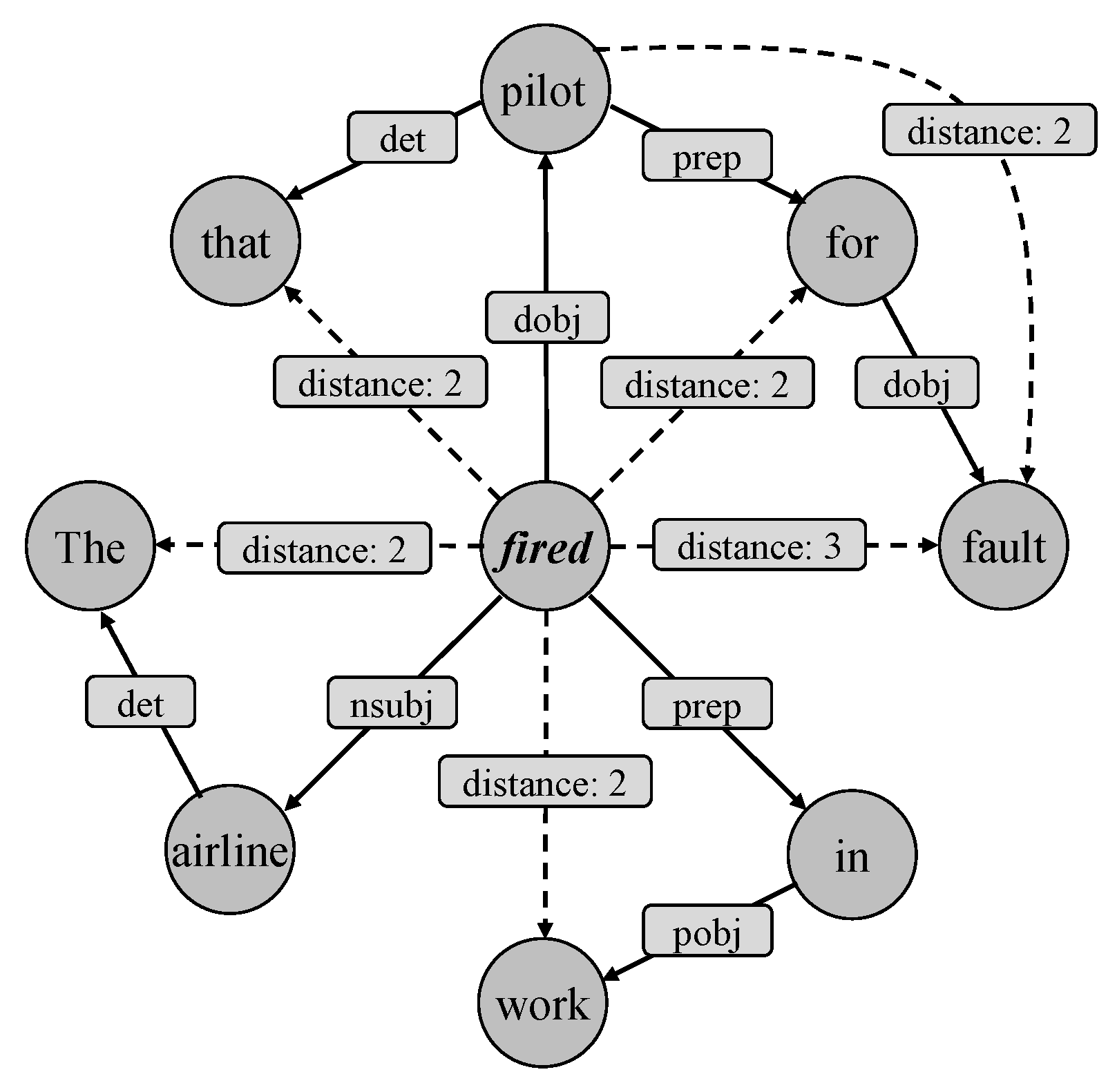
4.2.1. Multi-Order Distance Representation Method
4.2.2. Edge Representation Update Method Based on Attention Weights
5. Experiments
5.1. Implementation Details
5.2. Model Performance on the Original Data
5.3. Model Performance on the Adversarial Data
5.3.1. Model Robustness to Character-Level Transformations
- The perturbation caused by Typos is irregular, and the transformed words will almost certainly be OOV words, so the robustness of models to Typos is very weak.
- Although Ocr simulates possible errors in reality, the robustness of the model to it is also weak. We believe that because the corpus for training word vectors is manually typed rather than recognized from pictures, errors caused by Ocr rarely appear in the corpus.
- SpellingError and Keyboard simulate errors that may be caused by humans and appear in the corpus, so models are more robust to these two text transformations than the other two.
5.3.2. Model Robustness to Word-Level Transformations
- Transforming all verb tenses basically does not change the meaning of the sentence, and the semantic difference between verbs in different tenses is small; the corresponding word vectors should be very similar, thus Tense causes little perturbation to the original sentence.
- Replacing words with synonyms slightly changes the meaning of the sentence (e.g., the degree of emotion); although word vectors of synonyms should also be similar, SwapSyn causes perturbation to the original sentence a little more than Tense.
5.3.3. Model Robustness to Combining Text Transforms
5.3.4. Model Robustness to Data Subpopulations
- In the program, the model masks the filled placeholder (padding) at the end of the input sequence. When reading, humans also ignore meaningless symbols at the end of sentences. Therefore, a short sentence filled with placeholders still retains the original meaning.
- On the contrary, truncation affects the structural and semantic integrity of a long sentence (i.e., making the sentence incomplete and difficult to understand for both humans and machines); thus the important information may be lost.
6. Conclusions
- This paper only focuses on GNN-based ED models, while other models are also worthy of in-depth study and analysis. We expect more novel and robust model structures to emerge in the future.
- Text transformations and subpopulations contained in the Robustness Analysis Framework on an ED model were limited, and we encourage future studies focused on ED model robustness to consider more types (or combinations) of adversarial text attacks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Doddington, G.R.; Mitchell, A.; Przybocki, M.A.; Ramshaw, L.A.; Strassel, S.M.; Weischedel, R.M. The automatic content extraction (ace) program-tasks, data, and evaluation. In Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC), Lisbon, Portugal, 26–28 May 2004; pp. 837–840. [Google Scholar]
- Han, R.; Zhou, Y.; Peng, N. Domain Knowledge Empowered Structured Neural Net for End-to-End Event Temporal Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5717–5729. [Google Scholar]
- Zuo, X.; Cao, P.; Chen, Y.; Liu, K.; Zhao, J.; Peng, W.; Chen, Y. LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1: Long Papers, pp. 3558–3571. [Google Scholar]
- Marujo, L.; Ribeiro, R.; Gershman, A.; de Matos, D.M.; Neto, J.P.; Carbonell, J. Event-based summarization using a centrality-as-relevance model. Knowl. Inf. Syst. 2017, 50, 945–968. [Google Scholar] [CrossRef]
- Campos, R.; Dias, G.; Jorge, A.M.; Jatowt, A. Survey of temporal information retrieval and related applications. ACM Comput. Surv. (CSUR) 2014, 47, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Jatowt, A.; Färber, M.; Yoshikawa, M. Improving question answering for event-focused questions in temporal collections of news articles. Inf. Retr. J. 2021, 24, 29–54. [Google Scholar] [CrossRef]
- Ahn, D. The stages of event extraction. In Proceedings of the Workshop on Annotating and Reasoning about Time and Events, Sydney, Australia, 23 July 2006; pp. 1–8. [Google Scholar]
- Ji, H.; Grishman, R. Refining Event Extraction through Cross-Document Inference. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 15–20 June 2008; pp. 254–262. [Google Scholar]
- Liao, S.; Grishman, R. Using Document Level Cross-Event Inference to Improve Event Extraction. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 789–797. [Google Scholar]
- Hong, Y.; Zhang, J.; Ma, B.; Yao, J.; Zhou, G.; Zhu, Q. Using Cross-Entity Inference to Improve Event Extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1127–1136. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. In Proceedings of the Advances in Neural Information Processing Systems 13 (NIPS 2000), Denver, CO, USA, 1 January 2000. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Event Detection and Domain Adaptation with Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 365–371. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Modeling Skip-Grams for Event Detection with Convolutional Neural Networks. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 886–891. [Google Scholar]
- Ghaeini, R.; Fern, X.; Huang, L.; Tadepalli, P. Event Nugget Detection with Forward-Backward Recurrent Neural Networks. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 369–373. [Google Scholar]
- Nguyen, T.; Grishman, R. Graph convolutional networks with argument-aware pooling for event detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Liu, X.; Luo, Z.; Huang, H. Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1247–1256. [Google Scholar]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event Detection with Multi-Order Graph Convolution and Aggregated Attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5766–5770. [Google Scholar]
- Cui, S.; Yu, B.; Liu, T.; Zhang, Z.; Wang, X.; Shi, J. Edge-Enhanced Graph Convolution Networks for Event Detection with Syntactic Relation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 2329–2339. [Google Scholar]
- Lai, V.D.; Nguyen, T.N.; Nguyen, T.H. Event Detection: Gate Diversity and Syntactic Importance Scores for Graph Convolution Neural Networks. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5405–5411. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 784–789. [Google Scholar]
- Dwork, C.; Feldman, V.; Hardt, M.; Pitassi, T.; Reingold, O.; Roth, A. The reusable holdout: Preserving validity in adaptive data analysis. Science 2015, 349, 636–638. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting adversarial input sequences for recurrent neural networks. In Proceedings of the MILCOM 2016-2016 IEEE Military Communications Conference, Baltimore, MD, USA, 1–3 November 2016; pp. 49–54. [Google Scholar]
- Alzantot, M.; Sharma, Y.; Elgohary, A.; Ho, B.J.; Srivastava, M.; Chang, K.W. Generating Natural Language Adversarial Examples. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2890–2896. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1085–1097. [Google Scholar]
- Morris, J.; Yoo, J.Y.; Qi, Y. TextAttack: Lessons learned in designing Python frameworks for NLP. In Proceedings of the Second Workshop for NLP Open Source Software (NLP-OSS), Online, 19 November 2020; pp. 126–131. [Google Scholar]
- Zeng, G.; Qi, F.; Zhou, Q.; Zhang, T.; Ma, Z.; Hou, B.; Zang, Y.; Liu, Z.; Sun, M. OpenAttack: An Open-source Textual Adversarial Attack Toolkit. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, Online, 1–6 August 2021; pp. 363–371. [Google Scholar]
- Wang, X.; Liu, Q.; Gui, T.; Zhang, Q.; Zou, Y.; Zhou, X.; Ye, J.; Zhang, Y.; Zheng, R.; Pang, Z.; et al. TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, Online, 1–6 August 2021; pp. 347–355. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Lin, H.; Han, X.; Sun, L. Distilling Discrimination and Generalization Knowledge for Event Detection via Delta-Representation Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4366–4376. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, K.; Jia, Y.; Sheng, Z. How Does Context Matter? On the Robustness of Event Detection with Context-Selective Mask Generalization. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 2523–2532. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Zhu, H.; Xiao, K.; Ou, L.; Wang, M.; Liu, L.; Huang, H. Attention-Based Graph Convolution Networks for Event Detection. In Proceedings of the 2021 7th International Conference on Big Data and Information Analytics (BigDIA), Chongqing, China, 29–31 October 2021; pp. 185–190. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations(ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformations | Descriptions |
|---|---|
| Keyboard | Simulates the errors of how people type words with the use of keyboard. |
| Ocr | Simulates Ocr error by random values. |
| SpellingError | Simulate possible mistakes in the spelling of words. |
| Tense | Transforms all verb tenses in a sentence. |
| Typos | Randomly inserts, deletes, and swaps a letter within one word. |
| SwapSyn | Replaces one word with its synonym provided by WordNet [34]. |
| EntTypos | Applies Typos for words with entity type label. |
| Hyper-Parameters | Values |
|---|---|
| Dimension of word vectors () | 100 |
| Dimension of entity types vectors () | 50 |
| Dimension of edge labels vectors (p) | 50 |
| Dimension of Bi-LSTM () | 100 |
| Dimension of GCN () | 150 |
| Layers of GCN (L) | 2 |
| Learning rate | 0.001 |
| Optimizer | Adam [38] |
| Bias weight of loss function () | 5 |
| Batch size | 30 |
| Epoch | 100 |
| Maximum text length | 50 |
| Model | P | R | F1 |
|---|---|---|---|
| GCN-ED [18] | 77.9 | 68.8 | 73.1 |
| JMEE [19] | 76.3 | 71.3 | 73.7 |
| MOGANED [20] | 79.5 | 72.3 | 75.7 |
| GatedGCN [22] | 78.8 | 76.3 | 77.6 |
| EE-GCN [21] | 76.7 | 78.6 | 77.6 |
| MDL-EEGCN | 78.9 | 75.6 | 77.2 |
| A-EEGCN | 77.6 | 78.4 | 78.0 |
| A-MDL-EEGCN | 78.2 | 78.7 | 78.4 |
| Adversarial Data | A-MDL-EEGCN | EE-GCN | MOGANED | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Keyboard | 72.1 | 58.1 | 64.3 | 70.9 | 59.5 | 64.7 | 70.8 | 48.4 | 57.5 |
| Ocr | 69.6 | 52.6 | 59.9 | 73.2 | 47.9 | 57.9 | 71.5 | 42.7 | 53.5 |
| SpellingError | 71.1 | 56.7 | 63.1 | 73.4 | 55.1 | 62.9 | 69.2 | 47.5 | 56.3 |
| Typos | 71.7 | 49.9 | 58.8 | 71.0 | 47.7 | 57.0 | 71.9 | 40.7 | 52.0 |
| EntTypos | 74.5 | 77.5 | 75.8 | 71.8 | 75.9 | 73.8 | 71.8 | 65.3 | 68.4 |
| Tense | 71.1 | 77.2 | 74.0 | 71.3 | 74.9 | 73.1 | 72.2 | 63.9 | 67.8 |
| SwapSyn | 73.2 | 72.4 | 72.8 | 69.6 | 68.5 | 69.1 | 73.7 | 60.0 | 66.2 |
| Tense + Typos | 70.5 | 51.9 | 59.8 | 69.6 | 49.0 | 57.5 | 66.2 | 39.5 | 49.5 |
| SwapSyn + Typos | 68.9 | 41.9 | 52.1 | 70.3 | 40.3 | 51.2 | 67.4 | 34.3 | 45.5 |
| Length ≤ 50 | 79.2 | 79.1 | 79.1 | 78.0 | 78.6 | 78.3 | 79.7 | 72.6 | 76.1 |
| Length > 50 | 63.6 | 71.8 | 67.5 | 59.0 | 59.0 | 59.0 | 73.4 | 56.3 | 63.7 |
| Perplexity-0-50% | 69.8 | 77.0 | 73.2 | 68.8 | 74.4 | 71.5 | 73.6 | 66.1 | 69.7 |
| Perplexity-0-20% | 65.8 | 75.0 | 70.1 | 67.0 | 70.9 | 68.9 | 69.6 | 64.9 | 67.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Zhu, H.; Wu, J.; Xiao, K.; Huang, H. Robustness Analysis on Graph Neural Networks Model for Event Detection. Appl. Sci. 2022, 12, 10825. https://doi.org/10.3390/app122110825
Wei H, Zhu H, Wu J, Xiao K, Huang H. Robustness Analysis on Graph Neural Networks Model for Event Detection. Applied Sciences. 2022; 12(21):10825. https://doi.org/10.3390/app122110825
Chicago/Turabian StyleWei, Hui, Hanqing Zhu, Jibing Wu, Kaiming Xiao, and Hongbin Huang. 2022. "Robustness Analysis on Graph Neural Networks Model for Event Detection" Applied Sciences 12, no. 21: 10825. https://doi.org/10.3390/app122110825
APA StyleWei, H., Zhu, H., Wu, J., Xiao, K., & Huang, H. (2022). Robustness Analysis on Graph Neural Networks Model for Event Detection. Applied Sciences, 12(21), 10825. https://doi.org/10.3390/app122110825