
Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation

Abstract
:1. Introduction
- A context fusion strategy guided by spatial details is proposed, which effectively reconstructs the spatial information lost in the global environment, so that the detailed information can still be retained in the deeper features, and improves the segmentation performance of small and thin objects.
- A semantic information supplement path is designed to further supplement the semantic information of the lightweight network, increase the connection between local information and global information and further improve the accuracy of image segmentation.
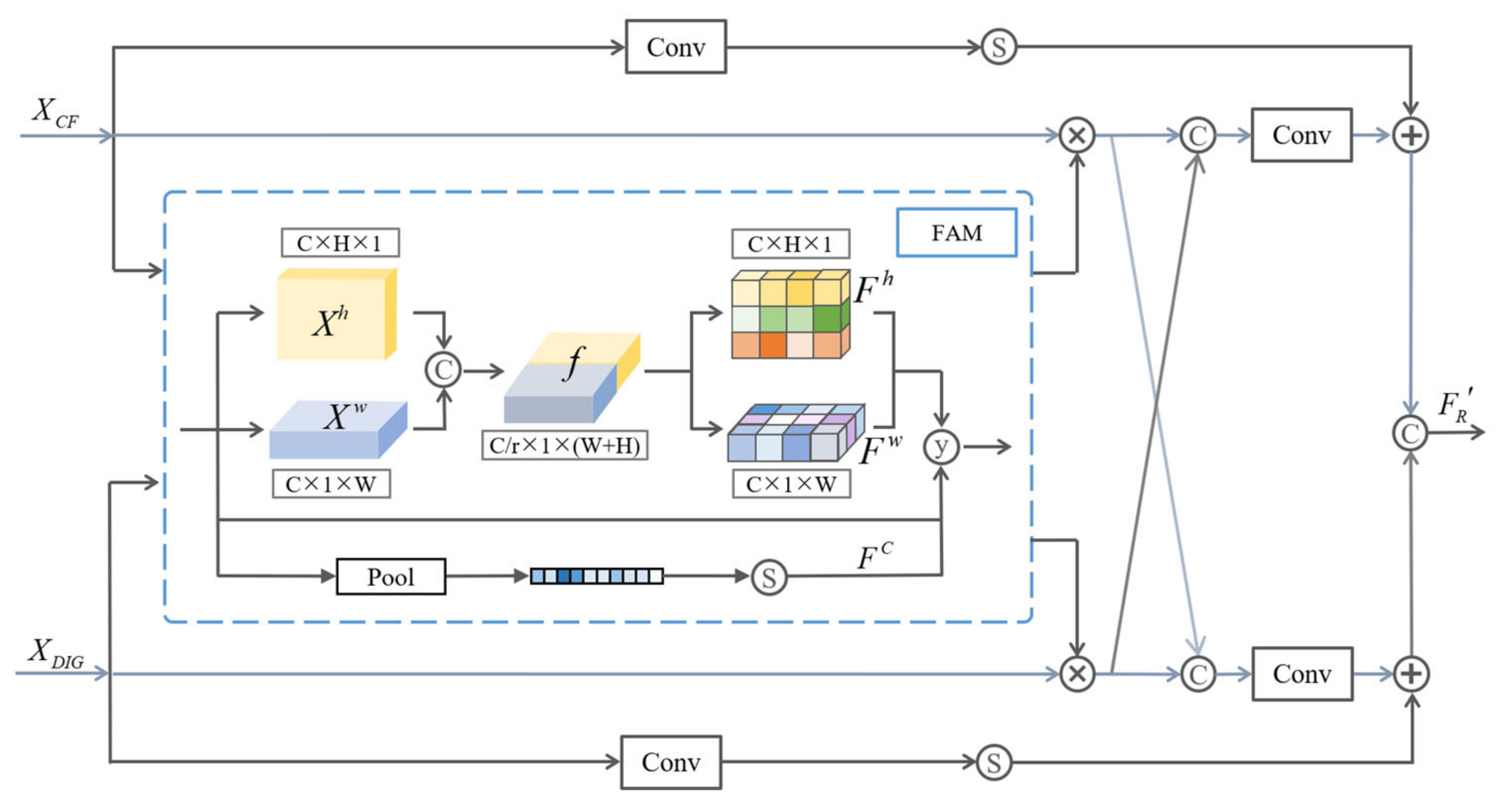
- A three-path feature fusion module based on full attention is designed, so that the features with different information output from the three paths can be effectively fused, and the features are refined to guide the network to extract more valuable features, to improve the image segmentation ability.
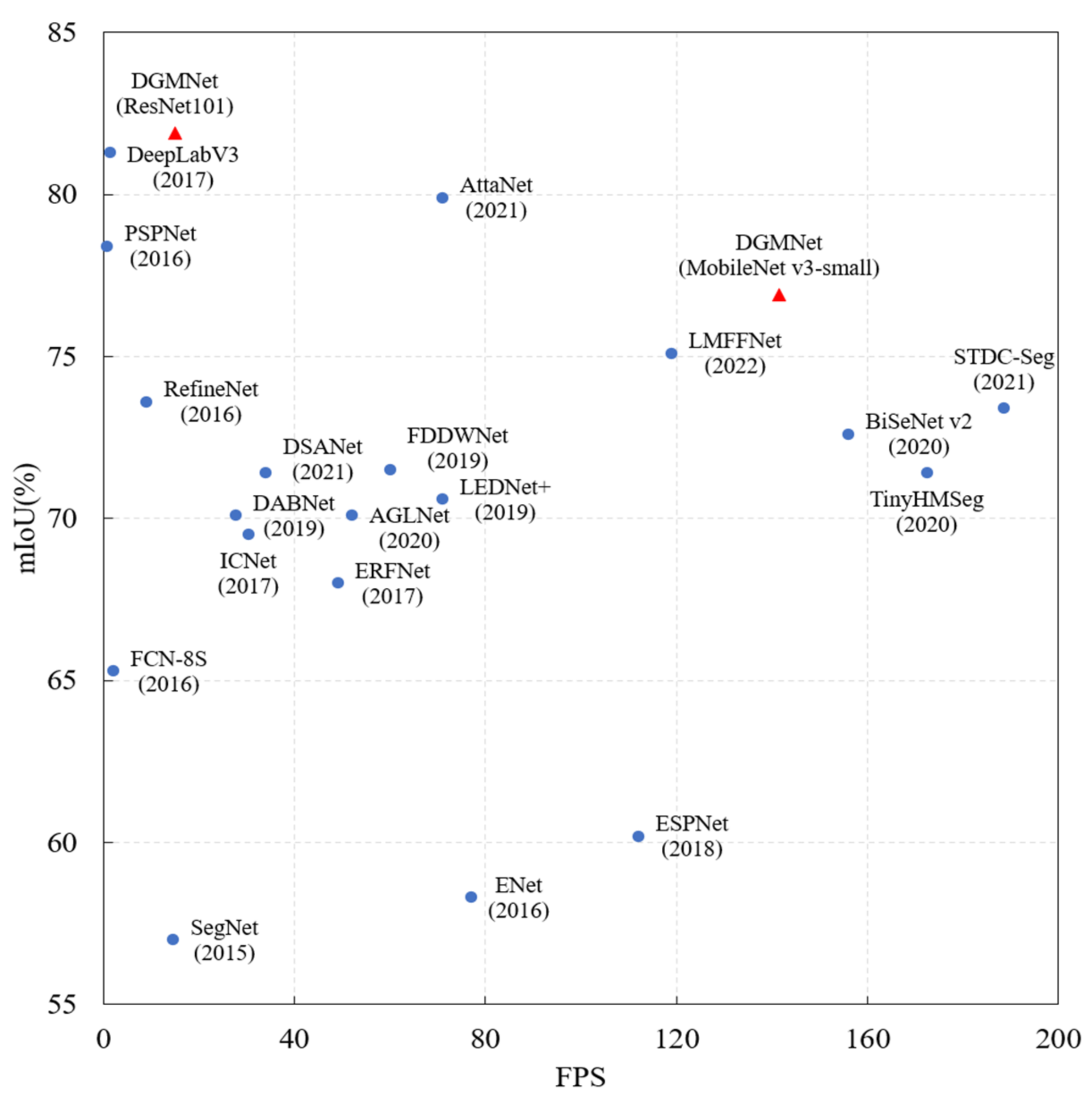
- DGMNet achieved good segmentation results on Cityscapes [10] and CamVid [11] datasets. Specifically, for the Cityscapes dataset with a resolution of 512 × 1024 and the CamVid dataset with a resolution of 960 × 720 on the NVIDIA RTX 2080Ti, the mIoU value can reach 76.9% and 74.8% at 141.5FPS and 121.4FPS, respectively.

2. Related Works
2.1. Generic Semantic Segmentation
2.2. Real-Time Semantic Segmentation
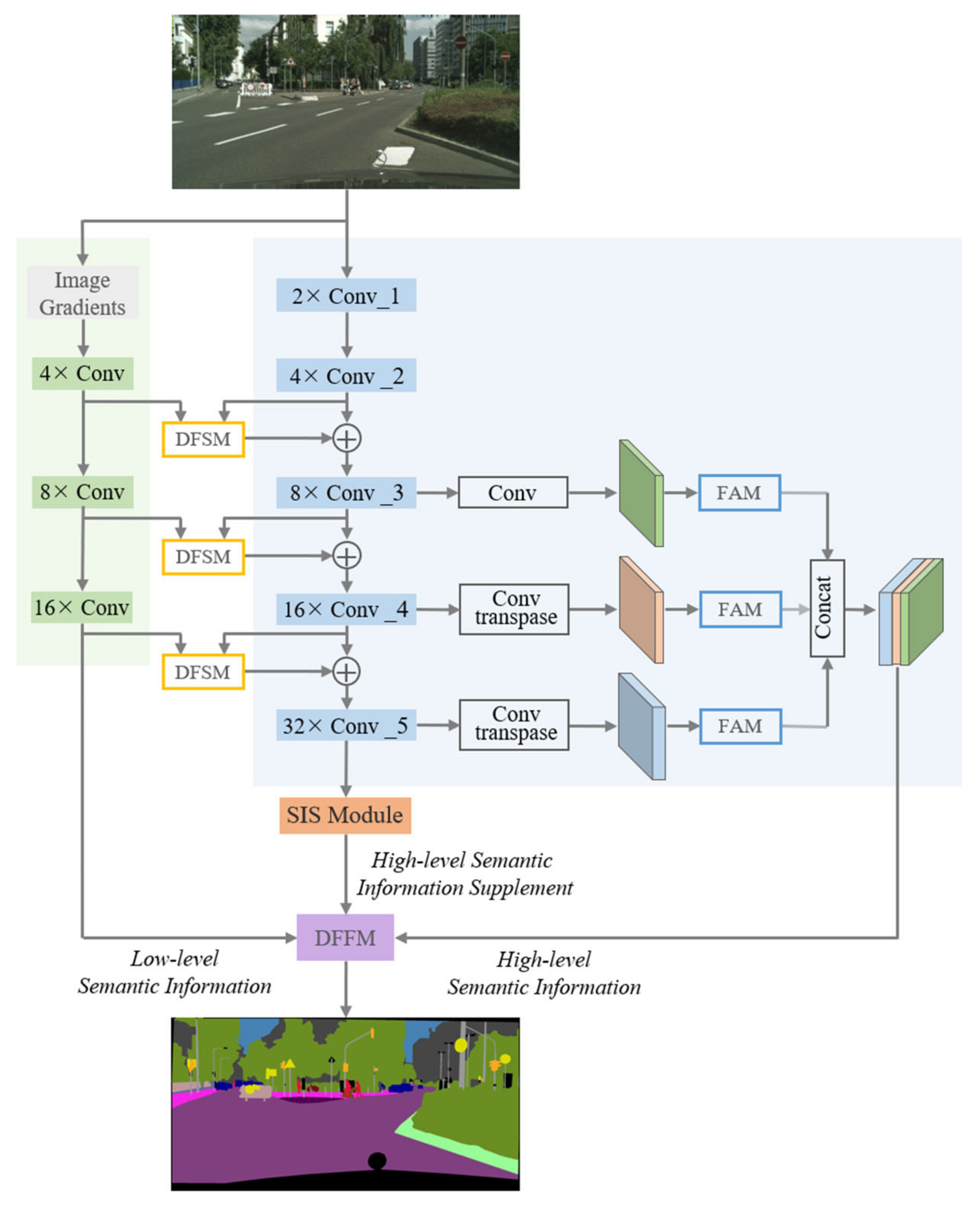
3. Detail Guided Multilateral Segmentation Network
3.1. Network Structure
3.2. Network Structure
3.2.1. Context Fusion Path
3.2.2. Detail Information Guidance Path
3.2.3. Semantic Information Supplement Path
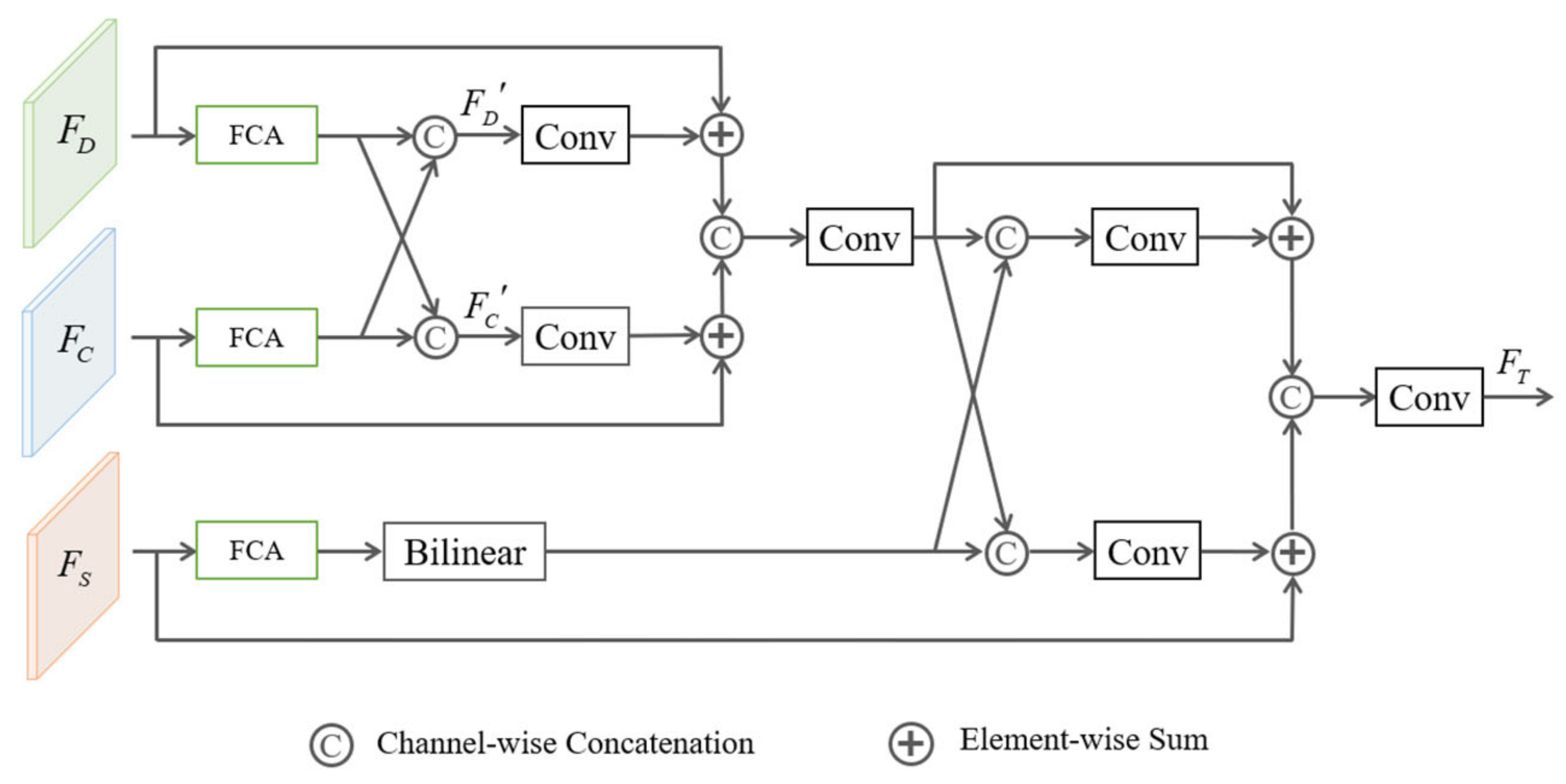
3.2.4. Three-Path Feature Fusion Module
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
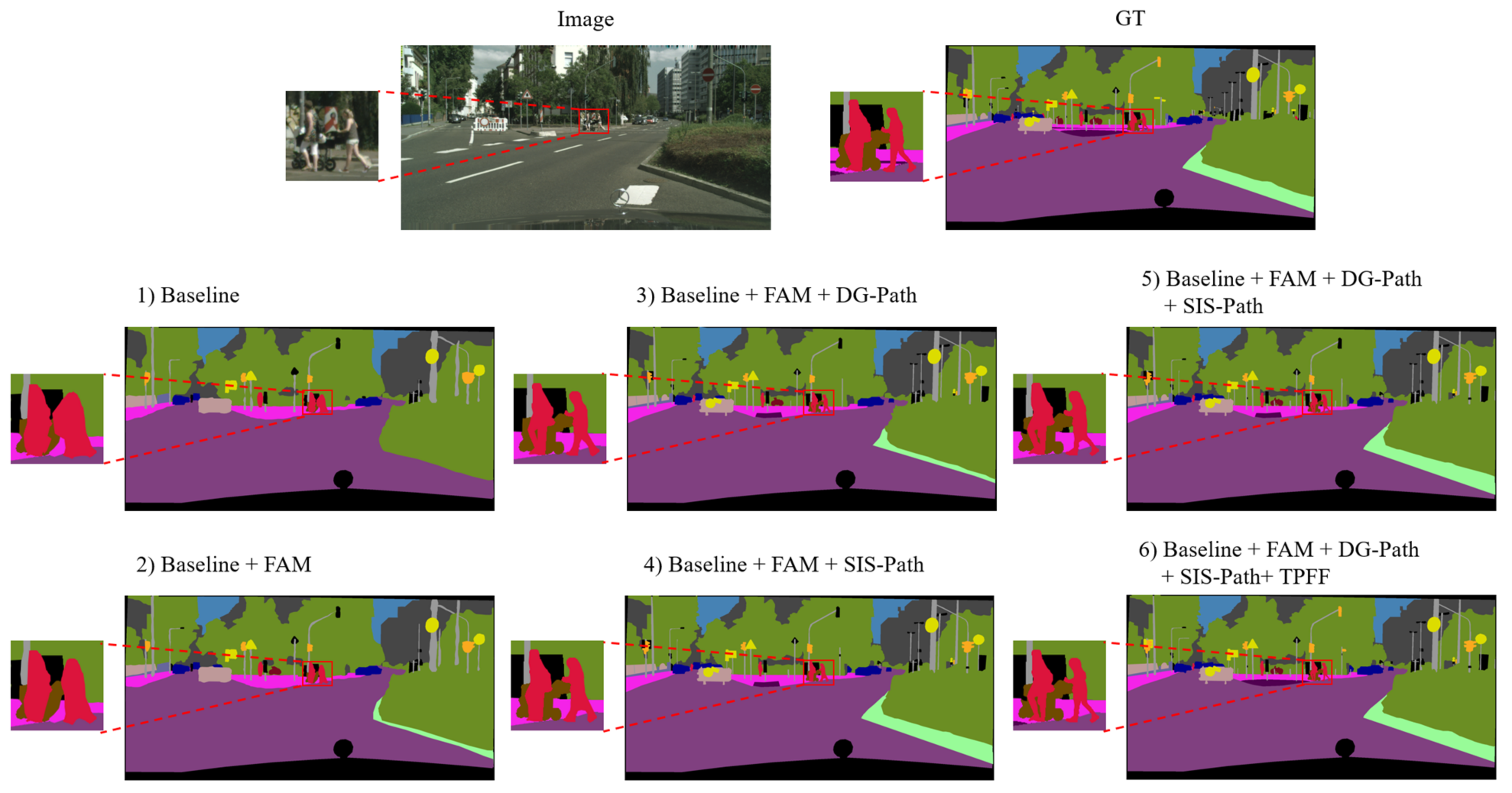
4.3. Ablation Experiment
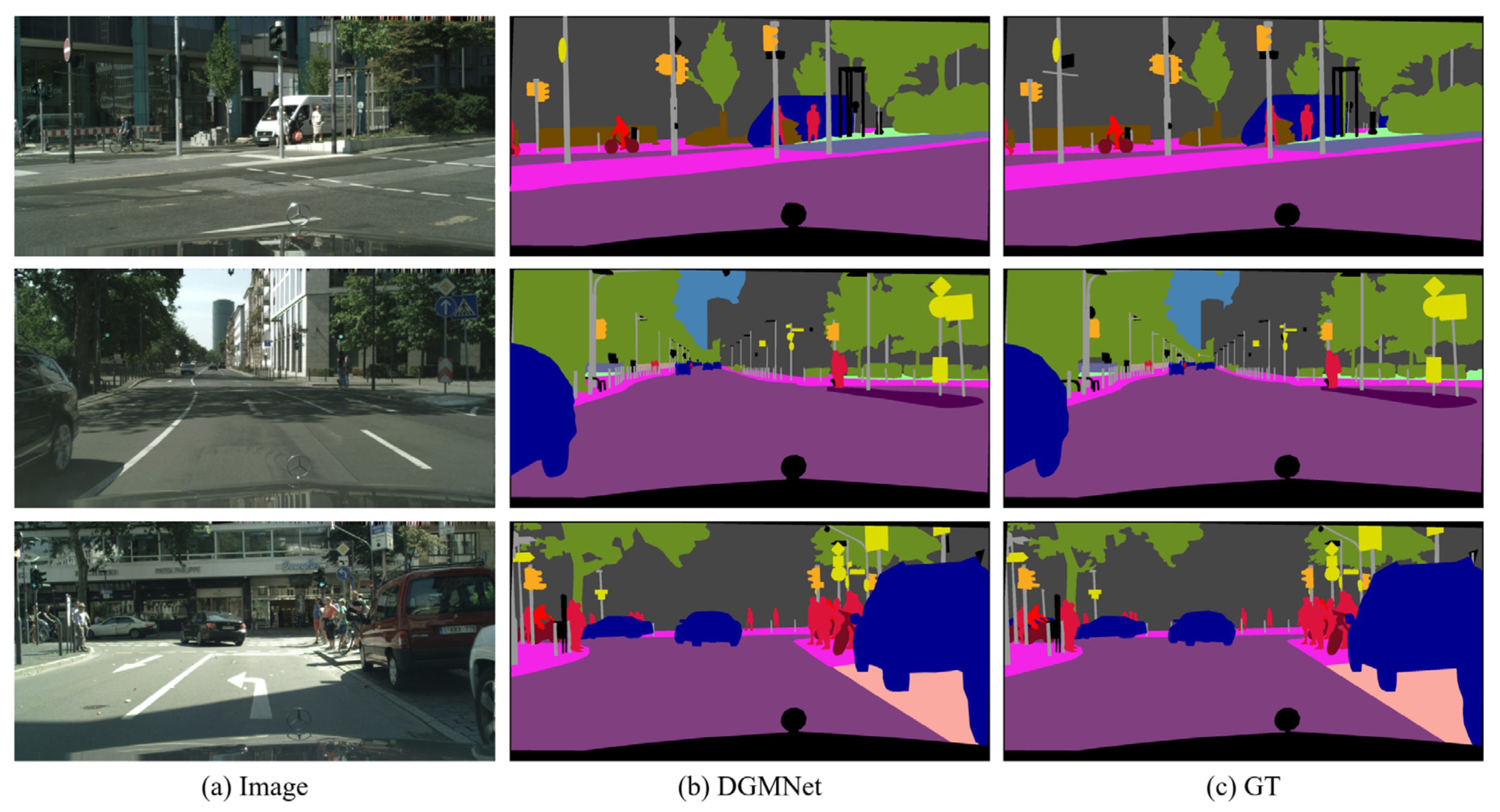
4.4. Comparison to State-of-the-Art Methods
4.4.1. Comparative Experiments in Cityscapes
4.4.2. Comparative Experiments in Camvid
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Bhattacharya, S.; Lane, N.D. Sparsification and separation of deep learning layers for constrained resource inference on wearables. In Proceedings of the 14th ACM Conf. Embedded Network Sensor System (CD-ROM), Stanford, CA, USA, 14–16 November 2016; pp. 176–189. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electric Network, Nashville, TN, USA, 19–25 June 2021; pp. 9711–9720. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5228–5237. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and Recognition Using Structure from Motion Point Clouds. In Proceedings of the 10th European Conference on Computer Vision (ECCV 2008), Marseille, France, 12–18 October 2008; pp. 44–57. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Ronneberger, O. Invited Talk: U-Net Convolutional Networks for Biomedical Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2017; p. 3. [Google Scholar]
- Liang-Chieh, C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. Trans. Pattern Anal. Mach. Intell. 2018, 40, 17600089. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H.J. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Sangpil, K.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J.; Soc, I.C. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9514–9523. [Google Scholar]
- Li, X.; Zhou, Y.; Pan, Z.; Feng, J.; Soc, I.C. Partial Order Pruning: For Best Speed/Accuracy Trade-off in Neural Architecture Search. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9137–9145. [Google Scholar]
- Lin, P.; Sun, P.; Cheng, G.; Xie, S.; Li, X.; Shi, J. Graph-guided Architecture Search for Real-time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electric Network, Seattle, DC, USA, 14–19 June 2020; pp. 4202–4211. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 270–286. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y.; Soc, I.C. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7511–7520. [Google Scholar]
- Zhou, Z.; Zhou, Y.; Wang, D.; Mu, J.; Zhou, H. Self-attention feature fusion network for semantic segmentation. Neuro-Computing 2021, 453, 50–59. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Song, Q.; Mei, K.; Huang, R. AttaNet: Attention-Augmented Network for Fast and Accurate Scene Parsing. In Proceedings of the 11th Symposium on Educational Advances in Artificial Intelligence, Electric Network, Virtual, 2–9 February 2021; pp. 2567–2575. [Google Scholar]
- Song, Q.; Li, J.; Li, C.; Guo, H.; Huang, R.J. Fully Attentional Network for Semantic Segmentation. arXiv 2021, arXiv:2112.04108. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 561–580. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, Y.; Fan, Y.W.; Wu, X.F.; Zhang, S.F.; Kang, B.; Latecki, L.J. AGLNet: Towards real-time semantic segmentation of self-driving images via attention-guided lightweight network. Appl. Soft Comput. 2020, 96, 106682. [Google Scholar] [CrossRef]
- Li, G.; Yun, I.; Kim, J.; Kim, J.J. DABNet: Depth-wise Asymmetric Bottleneck for Real-time Semantic Segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. LEDNET: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation. In Proceedings of the 26th IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar]
- Elhassan, M.A.M.; Huang, C.; Yang, C.; Munea, T.L. DSANet: Dilated spatial attention for real-time semantic segmentation in urban street scenes. Expert Syst. Appl. 2021, 183, 115090. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, Q.; Qiang, Y.; Kang, B.; Wu, X.; Zheng, B. FDDWNET: A Lightweight Convolutional Neural Network for Real-Time Semantic Segmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 2373–2377. [Google Scholar]
- Shi, M.; Shen, J.; Yi, Q.; Weng, J.; Huang, Z.; Luo, A.; Zhou, Y. LMFFNet: A Well-Balanced Lightweight Network for Fast and Accurate Semantic Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Orsic, M.; Kreso, I.; Bevandic, P.; Segvic, S.; Soc, I.C. In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12599–12608. [Google Scholar]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y.J. Vision Transformer Adapter for Dense Predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Yan, H.; Zhang, C.; Wu, M.J. Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention. arXiv 2022, arXiv:2201.01615. [Google Scholar]
- Li, P.; Dong, X.; Yu, X.; Yang, Y. When Humans Meet Machines: Towards Efficient Segmentation Networks. In Proceedings of the 31st British Machine Vision Virtual Conference BMVC, Cardiff, UK, 7–10 September 2020. [Google Scholar]
- Zhang, Y.; Qiu, Z.; Liu, J.; Yao, T.; Liu, D.; Mei, T.; Soc, I.C. Customizable Architecture Search for Semantic Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11633–11642. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Method | mIoU (%) | |||
|---|---|---|---|---|---|
| FAM | DIG-Path | SIS-Path | TPFF | ||
| model_1 (baseline) | 56.3 | ||||
| model_2 | ✓ | 61.1 | |||
| model_3 | ✓ | ✓ | 66.7 | ||
| model_4 | ✓ | ✓ | 67.9 | ||
| model_5 | ✓ | ✓ | ✓ | 73.2 | |
| model_6 (DGMNet) | ✓ | ✓ | ✓ | ✓ | 76.9 |
| Fusion Method | mIoU (%) |
|---|---|
| Add | 71.5 |
| Add + Attention | 74.3 |
| Concat | 73.2 |
| Concat + Attention | 75.6 |
| TPFF | 76.9 |
| Method | Roa | Sid | Bui | Wal | Fen | Pol | Lig | Sig | Veg | Ter | Sky | Tra | Tru | Bus | Car | Mot | Bic | Per | Rid | mIoU(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet [4] | 96.4 | 73.2 | 84.0 | 28.4 | 29.0 | 35.7 | 39.8 | 45.1 | 87.0 | 63.8 | 91.8 | 44.1 | 38.1 | 43.1 | 89.3 | 35.8 | 51.9 | 62.8 | 42.8 | 57.0 |
| FCN [12] | 97.4 | 78.4 | 89.2 | 34.9 | 44.2 | 47.4 | 60.1 | 65.0 | 91.4 | 69.3 | 93.9 | 46.5 | 35.3 | 48.6 | 92.6 | 51.6 | 66.8 | 77.1 | 51.4 | 65.3 |
| DeepLabv2 [15] | 97.9 | 81.3 | 90.3 | 48.8 | 47.4 | 49.6 | 57.9 | 67.3 | 91.9 | 69.4 | 94.2 | 57.2 | 56.5 | 67.5 | 93.7 | 57.7 | 68.8 | 79.8 | 59.8 | 70.4 |
| SA-FFNet [25] | 98.6 | 78.1 | 91.5 | 48.9 | 45.4 | 54.4 | 65.0 | 71.1 | 92.9 | 56.0 | 95.1 | 72.6 | 77.0 | 86.0 | 92.9 | 56.8 | 69.7 | 78.8 | 58.8 | 73.1 |
| RefineNet [26] | 97.9 | 81.3 | 90.3 | 48.8 | 47.4 | 49.6 | 57.9 | 67.3 | 91.9 | 69.4 | 94.2 | 57.5 | 56.5 | 67.5 | 93.7 | 57.7 | 68.8 | 79.8 | 59.8 | 73.6 |
| PSPNet [13] | 98.6 | 86.2 | 92.9 | 50.8 | 58.8 | 64.0 | 75.6 | 79.0 | 93.4 | 72.3 | 95.4 | 73.8 | 68.2 | 79.5 | 95.9 | 69.5 | 77.2 | 86.5 | 71.3 | 78.4 |
| AttaNet [27] | 98.7 | 87.0 | 93.5 | 55.9 | 62.6 | 70.2 | 78.4 | 81.4 | 93.9 | 72.8 | 95.4 | 78.0 | 71.2 | 84.4 | 96.3 | 68.6 | 78.2 | 87.9 | 74.7 | 80.5 |
| FLANet [28] | 98.8 | 87.7 | 94.3 | 64.1 | 64.9 | 72.4 | 78.9 | 82.6 | 94.2 | 73.5 | 96.2 | 91.6 | 80.2 | 93.8 | 96.6 | 74.3 | 79.5 | 88.7 | 76.0 | 83.6 |
| ENet [18] | 96.3 | 74.2 | 75.0 | 32.2 | 33.2 | 43.4 | 34.1 | 44.0 | 88.6 | 61.4 | 90.6 | 48.1 | 36.9 | 50.5 | 90.6 | 38.8 | 55.4 | 65.5 | 38.4 | 58.3 |
| ESPNet [29] | 95.6 | 73.2 | 86.4 | 32.7 | 36.4 | 46.9 | 46.7 | 55.2 | 89.7 | 65.9 | 92 | 40.6 | 39.9 | 47.7 | 89.8 | 36.3 | 54.8 | 68.3 | 45.7 | 60.2 |
| ICNet [5] | 98.0 | 81.9 | 90.3 | 46.4 | 46. 5 | 50. 5 | 57.3 | 64.2 | 91.7 | 68.2 | 94.4 | 63.8 | 53.7 | 72.5 | 93.6 | 48.6 | 64.6 | 77.1 | 57.9 | 69.5 |
| ERFNet [30] | 97.9 | 82.1 | 90.7 | 45.2 | 50.4 | 59.0 | 62.6 | 68.4 | 91.9 | 69.4 | 94.2 | 53.7 | 52.3 | 60.8 | 93.4 | 49.9 | 64.2 | 78.5 | 59.8 | 69.7 |
| AGLNet [31] | 97.8 | 80.1 | 91.0 | 51.3 | 50.6 | 58.3 | 63.0 | 68.5 | 92.3 | 71.3 | 94.2 | 42.1 | 48.4 | 68.1 | 93.8 | 52.4 | 67.8 | 80.1 | 59.6 | 70.1 |
| DABNet [32] | 97.9 | 82.0 | 90.6 | 45.5 | 50.1 | 59.3 | 63.5 | 67.7 | 91.8 | 70.1 | 92.8 | 56.0 | 52.8 | 63.7 | 93.7 | 51.3 | 66.8 | 78.1 | 57.8 | 70.1 |
| LEDNet [33] | 98.1 | 79.5 | 91.6 | 47.7 | 49.9 | 62.8 | 61.3 | 72.8 | 92.6 | 61.2 | 94.9 | 52.7 | 64.4 | 64.0 | 90.9 | 44.4 | 71.6 | 76.2 | 53.7 | 70.6 |
| DSANet [34] | 96.8 | 78.5 | 91.2 | 50.5 | 50.8 | 59.4 | 64.0 | 71.7 | 92.6 | 70.0 | 94.5 | 50.6 | 56.1 | 75.6 | 92.9 | 50.6 | 66.8 | 81.8 | 61.9 | 71.4 |
| FDDWNet [35] | 98.0 | 82.4 | 91.1 | 52.5 | 51.2 | 59.9 | 64.4 | 68.9 | 92.5 | 70.3 | 94.4 | 48.6 | 56.5 | 68.9 | 94.0 | 55.7 | 67.7 | 80.8 | 59.8 | 71.5 |
| BiSeNet v2 [7] | 98.2 | 82.9 | 91.7 | 44.5 | 51.1 | 63.5 | 71.2 | 75.0 | 92.9 | 71.1 | 94.9 | 56.8 | 60.5 | 68.7 | 94.9 | 61.5 | 72.7 | 83.6 | 65.4 | 73.8 |
| LMFFNet [36] | 98.3 | 84.1 | 92.0 | 56.1 | 55.1 | 62.2 | 69.0 | 72.7 | 93.0 | 71.3 | 95.0 | 64.1 | 60.6 | 76.7 | 95.0 | 60.6 | 71.7 | 83.8 | 66.1 | 75.1 |
| SwiftNet [37] | 98.3 | 83.9 | 92.2 | 46.3 | 52.8 | 63.2 | 70.6 | 75.8 | 93.1 | 70.3 | 95.4 | 71.9 | 63.9 | 78.0 | 95.3 | 61.6 | 73.6 | 84.0 | 64.5 | 75.5 |
| DGMNet | 98.1 | 87.1 | 93.1 | 59.7 | 58.7 | 68.4 | 74.3 | 79.6 | 92.8 | 70.5 | 94.9 | 68.8 | 64.1 | 77.3 | 94.8 | 61.1 | 73.5 | 85.7 | 69.3 | 76.9 |
| Method | Pretrain | Backbone | Resolution | Device | Params (M) | GFLOPs | FPS | mIoU |
|---|---|---|---|---|---|---|---|---|
| SegNet [4] | ImageNet | VGG16 | 360 × 640 | - | 29.5 | 286.0 | 14.6 | 57.0 |
| FCN-8S [12] | ImageNet | VGG16 | 512 × 1024 | - | 136.2 | 2.0 | 65.3 | |
| DeepLabv2 [15] | ImageNet | ResNet101 | 512 × 1024 | Titan X | 44 | 457.8 | <1 | 70.4 |
| SA-FFNet [25] | ImageNet | ResNet101 | 768 × 768 | Titan X | 57.5 | - | - | 73.1 |
| RefineNet [26] | ImageNet | ResNet101 | 512 × 1024 | Titan X | 118.1 | 428.3 | 9 | 73.6 |
| PSPNet [13] | ImageNet | ResNet101 | 713 × 713 | Titan X | 250.8 | 412.2 | 0.78 | 78.4 |
| FLANet [28] | ImageNet | HRNetV2-W48 | 768 × 768 | - | 436 | 19.37 | - | 78.9 |
| AttaNet [27] | ImageNet | DF2 | 512 × 1024 | GTX 1080Ti | - | - | 71 | 79.9 |
| DeepLabV3 [17] | ImageNet | ResNet101 | 769 × 769 | Tesla K80 | - | - | 1.3 | 81.3 |
| Lawin [38] | ImageNet | Swin-L | 1024 × 1024 | Tesla V100 | - | 1797 | - | 84.4 |
| ViT-Adapter-L [39] | ImageNet | ViT-Adapter-L | 896 × 896 | Tesla V100 | 571 | - | - | 85.2 |
| ENet [18] | No | No | 630 × 630 | Titan X | 0.4 | 4.4 | 76.9 | 58.3 |
| ESPNet [29] | No | ESPNet | 512 × 1024 | Titan X | 0.36 | 4.0 | 112 | 60.2 |
| ERFNet [30] | ImageNet | VGG16 | 512 × 1024 | Titan X | 2.1 | 26.8 | 49 | 68.0 |
| ICNet [5] | ImageNet | PSPNet50 | 1024 × 2048 | TitanX | 26.5 | 29.8 | 30.3 | 69.5 |
| AGLNet [31] | No | No | 512 × 1024 | GTX 1080Ti | 1.12 | 13.9 | 52 | 70.1 |
| DABNet [32] | No | No | 1024 × 2048 | GTX 1080Ti | 0.76 | 10.5 | 27.7 | 70.1 |
| LEDNet [33] | No | SSNet | 512 × 1024 | GTX 1080Ti | 0.94 | 11.5 | 71 | 70.6 |
| TinyHMSeg [40] | No | No | 768×1536 | GTX 1080Ti | 0.7 | 3.0 | 172.4 | 71.4 |
| DSANet [34] | No | FDSSNet | 512 × 1024 | GTX 1080Ti | 3.47 | 37.4 | 34 | 71.4 |
| FDDWNet [35] | No | No | 512 × 1024 | GTX 2080Ti | 0.8 | 8.5 | 60 | 71.5 |
| BiSeNet v2 [7] | No | No | 512 × 1024 | GTX 1080Ti | - | 11.5 | 156 | 72.6 |
| STDC-Seg [8] | No | STDC | 512 × 1024 | GTX 1080Ti | - | - | 188.6 | 73.4 |
| LMFFNet [36] | No | LMFFNet | 512 × 1024 | GTX 3090 | - | 16.7 | 118.9 | 75.1 |
| DGMNet | No | MobileNet v3-small | 512 × 1024 | GTX 2080Ti | 2.4 | 13.4 | 141.5 | 76.9 |
| DGMNet_2 | No | ResNet 101 | 512 × 1024 | GTX 2080Ti | 97.2 | 264.6 | 14.9 | 81.8 |
| Method | Resolution | Device | FPS | mIoU (%) |
|---|---|---|---|---|
| ENet [18] | 720 × 960 | Titan X | 61.2 | 51.3 |
| ESPNet [29] | 720 × 960 | Titan X | 219.8 | 55.6 |
| ICNet [5] | 720 × 960 | Maxwell TitanX | 34.5 | 67.1 |
| ERFNet [30] | 720 × 960 | Titan X | 139.1 | 67.7 |
| DABNet [32] | 360 × 480 | GTX 1080Ti | 146 | 66.4 |
| BiSeNetV1 [6] | 720 × 960 | Titan XP | 116.3 | 68.7 |
| AGLNet [31] | 720 × 960 | GTX 1080Ti | 90.1 | 69.4 |
| DSANet [34] | 360 × 480 | GTX 1080Ti | 75.3 | 69.93 |
| CAS [41] | 720 × 960 | Titan XP | 169 | 71.2 |
| TinyHMSeg [40] | 720 × 960 | GTX 1080Ti | 278.5 | 71.8 |
| GAS [21] | 720 × 960 | Titan XP | 153.1 | 72.8 |
| BiSeNet v2 [7] | 360×480 | GTX 1080Ti | 124.5 | 72.4 |
| STDC2-Seg [8] | 720 × 960 | GTX 1080Ti | 152.2 | 73.9 |
| DGMNet | 720 × 960 | GTX 2080Ti | 121.4 | 74.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Q.; Dai, J.; Rui, T.; Shao, F.; Hu, R.; Du, Y.; Zhang, H. Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation. Appl. Sci. 2022, 12, 11040. https://doi.org/10.3390/app122111040
Jiang Q, Dai J, Rui T, Shao F, Hu R, Du Y, Zhang H. Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation. Applied Sciences. 2022; 12(21):11040. https://doi.org/10.3390/app122111040
Chicago/Turabian StyleJiang, Qunyan, Juying Dai, Ting Rui, Faming Shao, Ruizhe Hu, Yinan Du, and Heng Zhang. 2022. "Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation" Applied Sciences 12, no. 21: 11040. https://doi.org/10.3390/app122111040
APA StyleJiang, Q., Dai, J., Rui, T., Shao, F., Hu, R., Du, Y., & Zhang, H. (2022). Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation. Applied Sciences, 12(21), 11040. https://doi.org/10.3390/app122111040