Abstract
Deep neural networks (DNNs) have successfully delivered cutting-edge performance in several fields. With the broader deployment of DNN models on critical applications, the security of DNNs has become an active and yet nascent area. Attacks against DNNs can have catastrophic results, according to recent studies. Poisoning attacks, including backdoor attacks and Trojan attacks, are one of the growing threats against DNNs. Having a wide-angle view of these evolving threats is essential to better understand the security issues. In this regard, creating a semantic model and a knowledge graph for poisoning attacks can reveal the relationships between attacks across intricate data to enhance the security knowledge landscape. In this paper, we propose a DNN poisoning attack ontology (DNNPAO) that would enhance knowledge sharing and enable further advancements in the field. To do so, we have performed a systematic review of the relevant literature to identify the current state. We collected 28,469 papers from the IEEE, ScienceDirect, Web of Science, and Scopus databases, and from these papers, 712 research papers were screened in a rigorous process, and 55 poisoning attacks in DNNs were identified and classified. We extracted a taxonomy of the poisoning attacks as a scheme to develop DNNPAO. Subsequently, we used DNNPAO as a framework by which to create a knowledge base. Our findings open new lines of research within the field of AI security.
1. Introduction
Deep neural networks (DNNs) have brought innovative changes and introduced new dimensions in many fields. With the rapid growth of the use of DNNs for diversified purposes, DNNs have proven to be a very effective technique in producing models that have become the core of critical applications. DNN models are usually used in solving routine problems and applied in automating daily labor, computer vision, such as object detection [1], pedestrian and face recognition [2], linear algebra [3], mobility [4], natural language processing (NLP) [5,6], solar forecasting [7], medical diagnosis [8,9], smart cities [10], forensic sciences [11], and supporting cybersecurity applications [12,13,14].
A typical neural network has input, hidden, and output layers. A deep neural network (DNN) consists of many hidden layers that can be seen as a black box for a DNN model. A layer consists typically of individual, interconnected units called neurons, nodes, or perceptrons. Typically, each neuron receives input from one or more sources that may be other neurons or input data. This input is usually in a floating point or binary. Then, a neuron multiplies each of these inputs by weights and passes this sum of multiplications to an activation function. Some neural networks may not use activation functions. This is the structure of just one building block of a neural network. The different architectures between hidden layers define the interaction in a neural network. During the training of a DNN, the settings of both hyperparameters and training parameters have an impact on the neural network’s performance.
Based on the experience that DNN algorithms are allowed to have during the learning process, they can be categorized as supervised, semi-supervised, unsupervised, or reinforcement. In supervised learning, the target y teaches the neural network to produce the ideal output. Each training iteration calculates how close the actual output is to the target y, which is the ideal output. The error rate can be decreased in each iteration by modifying the internal weight matrices of the neural network to an acceptably low level. The unsupervised learning algorithm must learn to make sense of the data without a guide or a teacher. In unsupervised training, there is no ideal output to measure the error rate. Thus, we can just iterate for a fixed number of iterations. In the semi-supervised learning approach, both labeled and unlabeled versions are used to estimate the outputs. In this context, the goal of semi-supervised learning is to learn a representation so that examples from the same class have similar representations. In the reinforcement learning paradigm, an autonomous agent can learn to perform a task by learning from mistakes in a specific environment without any human guidance.
Therefore, as shown above, DNNs rely upon their input data, structure, and parameters, and any change might mislead the DNNs. This sensitivity of DNNs makes them brittle against adversarial attacks. Attackers can mislead the DNNs by corruption parameters, maximizing error functions, or manipulating the datasets. Recent research demonstrates that the robustness of DNNs is a critical weakness against malicious attacks. Moreover, the robustness of DNNs is vital due to the emerging concepts of responsible and green artificial intelligence [15,16] which aims to preserve ethics, fairness, democracy, and the explainability of AI-based decision systems.
The attacks against DNNs can be classified according to three main categories: (1) attacks at the training phase such as data or model poisoning attacks, (2) attacks at the training and testing phase such as backdoor attacks and Trojan attacks, and (3) attacks at the testing/inference phase only, which are called evasion attacks and are specifically known as adversarial example attacks. In general, poisoning attacks occur at the training phase of DNNs. Poisoning attacks can be split into two types: poisoning attacks and backdoor poisoning attacks. In poisoning attacks, adversaries seek to insert poisoned samples into training datasets, known as data poisoning attacks, or change training parameters, known as model poisoning attacks, which can decrease the trained network’s performance and can be considered an availability attack. The inserted poisoned data in backdoor poisoning attacks has no effect on the network’s performance or accuracy. However, during the inference phase, adversaries can activate injected triggers to manipulate the network’s results, which is considered an integrity attack.
Several studies have attempted to review attacks against DNNs [17,18,19]. Although there have been numerous studies to explore and survey attacks in DNNs, the majority of the studies that have investigated DNNs focused on adversarial examples; only a few have focused on poisoning attacks. For example, Xu et al. [17] have provided a systematic overview of adversarial attacks for images, graphs, and text applications. However, the examination only focuses on the key adversarial example attacks without concentrating on the poisoning attacks. Moreover, this is a standard review, not a systematic literature review. We will establish the case for this work further in Section 2 where we provide an overview of the survey papers on the poisoning attacks.
Meanwhile, with the rapid use of DNNs, evaluating the robustness of DNNs involves exploring weaknesses in these deep nets. Traditional security management and threat analysis lacks methods for intelligent responses to new threats. Ontologies in the field of DNN security can serve as a communication tool between experts. On the other hand, ontologies serve as a standard framework for describing, examining, and assessing the security landscape. A knowledge graph provides more information by utilizing an ontology as a framework. A semantic knowledge representation of security attacks is a significant way to retrieve data for analysts, whether they are human or AI agents. In addition, there is still a lack of semantic knowledge graphs and intelligent reasoning technologies for emerging attacks.
Thus, motivated by this research gap, this paper proposes an ontology of poisoning and backdoor attacks in DNNs. The ontology is extendable. We focus in this paper on the first two types of attacks, and we call both of them poisoning attacks, which means that we focus on poisoning attacks in the training phase and the backdoor attacks and Trojan attacks that begin in the training phase and can continue to the testing or inference phase. We investigated poisoning and backdoor attacks from papers published between 2013 and the middle of 2021 through a systematic literature review. We collected 28,469 papers from the IEEE, ScienceDirect, Web of Science, and Scopus databases, and from these papers, 712 research papers were screened in a rigorous process. After a further screening, 52 papers were selected, which were fully read and analyzed. From these 52 papers, a total of 55 poisoning attacks in DNNs were detected and categorized. We extracted a taxonomy of the poisoning attacks as a scheme to develop the DNN poisoning attacks ontology (DNNPAO). Subsequently, we used DNNPAO as a framework to create a knowledge base.
The rest of this paper is organized as follows. Section 2 presents related work. Section 3 describes the research methodology of the paper, including the systematic review methodology. Section 4 presents the poisoning attacks taxonomy extracted from the systematic review. Section 5 provides a review of the selected 52 papers. Section 6 describes the architecture of the DNNPAO and the poisoning attacks knowledge base. Section 7 discusses and demonstrates how to use the DNNPAO.Finally, Section 8 concludes the paper and suggests some directions for future research. Figure 1 shows the organization of the article.
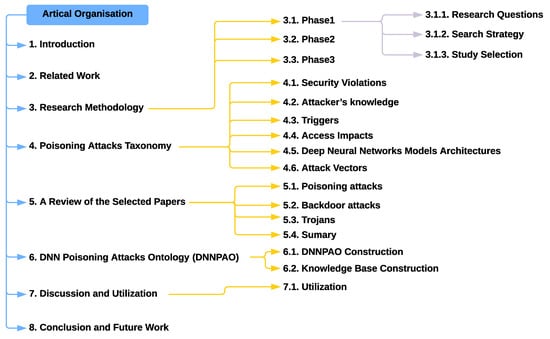
Figure 1.
Article organisation.
2. Related Work
This section discusses related works in the context of surveying and classifying poisoning and backdoor attacks against DNNs that are retrieved from our dataset and selected by the systematic review methodology described in Section 3. Most studies that surveyed attacks in deep neural networks have focused on evasion attacks (adversarial examples), and only a few were considered poisoning attacks. Although some research has been carried out on surveying attacks in deep neural networks, only three studies have taxonomic poisoning attacks, and only two have taxonomic backdoor attacks in DNNs.
Most related studies [18,19] have provided taxonomies and considered poisoning attacks in DNNs, as shown in Table 1. Pitropakis et al. [18] proposed a taxonomy and a survey of attacks against machine learning systems. The authors attempted to unify the field by classifying the different papers that propose attacks against machine learning. The taxonomy also helped in the identification of pending problems that may lead to new fields of study. Their taxonomy of adversarial attacks on machine learning is divided into two separate phases: preparation and manifestation. They provided attack models with two attack types: poisoning and evasion. This survey did not investigate defense mechanisms. Dang et al. [19] briefly reviewed data poisoning attacks (backdoor, and Trojan attacks) and some of the defense methods. They focused on backdoor attacks, and they summarized specific defense proposals (data defense, model defense, and training defense). Although poisoning attacks can violate the integrity or availability of a neural network, they are very hard to defend, and defenses are still in their infancy.

Table 1.
Summaries of the related publications of survey papers in the dataset that focus on or include poisoning or backdoor attacks in deep learning.
In a similar context, studies [20,21,22] have provided taxonomies but focused on a specific application. Jere et al. [20] provided a taxonomy of attacks against federated learning systems, concerning both data privacy and model performance with a comprehensive review. They started with a federated learning overview before developing a framework for robust threat modeling in order to survey model performance and data privacy attacks. Finally, they presented some of the existing defense strategies. Isakov et al. [21] proposed an attack taxonomy against DNNs in edge devices. In their work, they cover the attacks and their countermeasure landscapes. Chen et al. [22] conducted an assessment of existing backdoor attacks and their mitigation in outsourced cloud environments. The authors classified attack and defense approaches into different groups on the basis of the adversary’s resources and whether the detection occurs during runtime or not. They also presented a comparison of these approaches and used experiments to evaluate a portion of the attack schemes.
Several studies, such as [23,24], have only focused on Trojaning. Liu et al. [23] summarized both neural Trojan attack and defense mechanisms. The outsourced training procedure is considered to be a reason for attacks. This paper emphasizes that the machine learning supply chain, such as the machine learning as a service (MLaaS) provider, might be a serious risk for any MLaaS consumer. The authors offered three types of neural Trojan attacks: training data poisoning, and training algorithm-based and binary-level attacks. These main categories can be used to classify any other neural Trojan attack. The defense techniques were classified into four classes: neural network verification, Trojan trigger detection, compromised neural network restoration, and Trojan bypass techniques. The authors also showed that Trojans might be used for protection as well. According to the authors, the majority of the research in this field has been done in the previous three years, and the combat between attackers and defenders in the context of the neural Trojan is expected to continue. Xu et al. [24] provided a comprehensive survey of the attacks against DNN on the hardware surfaces. The authors focused on hardware Trojan insertion, fault injection, and side-channel analysis. Furthermore, they categorized the attack methods and defenses to provide a comprehensive view of hardware-related security issues in neural networks.
Other papers [25,26,28] are more general survey papers. Xue et al. [25] provided a systematic analysis of the security issues of machine learning. Systematically, they reviewed attacks and defenses in both the training and testing phases. Machine learning algorithms were classified into two types: neural network (NN) algorithms and non-NN algorithms. In addition, threats and attack models were presented. The authors identified three main machine learning vulnerabilities. The first is the outsourcing of the training process. The second is the use of pre-trained models from third parties. The third one includes the ineffective data validations on the network. The paper also included defense strategies and responses for the most common forms of attacks. Their paper contributed to a comprehensive understanding of security and robustness of machine learning systems.
He et al. [26] provided a survey of DNN attacks and defense mechanisms. The authors concentrated on four types of attacks: adversarial, model extraction, model inversion, and poisoning attacks. The paper also proposed 18 results in connection with these attacks. Furthermore, some potential security vulnerabilities and mitigation strategies were discussed for future research in this emerging field. Miller et al. [28] provided a comprehensive review of adversarial learning attacks. The authors also discussed recent research on test-time evasion, data poisoning, backdoor attacks, and reverse engineering attacks, as well as the defense methods.
For these emerging attacks, there is still a lack of semantic knowledge graphs and intelligent reasoning systems. Hence, the focus of our research has been on existing poisoning attacks in DNNs. This study intends to remedy this issue by providing a systematic review and attempting to develop an ontology of these attacks. Summaries of the related survey papers are provided in Table 1. In addition, Figure 2 shows some statistical information on the related survey papers.
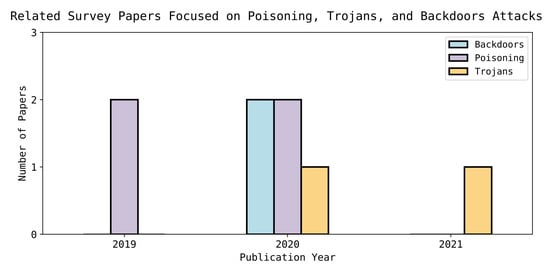
Figure 2.
Shows the number of survey papers on Trojans, poisoning and backdoor attacks and the year of publication.
3. Research Methodology
This section describes the methodology used in this paper. The work is divided into three phases, each with its own method. The first phase is the systematic literature review which was focused on identifying the security threats against DNNs and the related works in prior studies. The second phase involves developing a taxonomy scheme based on the literature. In the third phase, the DNN poisoning attack ontology was built on the basis of the taxonomy and then a poisoning attack knowledge base was created. Figure 3 shows the overall research process that has been carried out in this study, and each phase is described in detail.
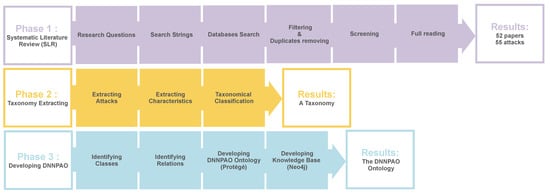
Figure 3.
Overall research process in this study.
3.1. Phase1
We performed a systematic literature review (SLR) to understand the existing poisoning attacks, their characteristics, and related works [29]. From a total of 28,469 collected papers, 712 research papers were screened, and 52 papers were fully read. Our SLR protocol had three main phases: (1) research questions, (2) search strategy, and (3) study selection. Furthermore, in the SLR protocol, these keywords were used: deep neural networks, deep learning, vulnerabilities, threats, attacks, security, taxonomy, ontology, poisoning, Trojan, backdoor.
3.1.1. Research Questions
We initially framed our main research questions (MRQs) to address our general goal. Then, we defined subresearch questions (SRQ) on the basis of the main ones. Thus, the following questions were defined:
- MRQ1: What are the existing poisoning and backdoor attacks against deep neural networks?
- MRQ2: How can the identified attacks be classified according to their characteristics? (ontology).
- SRQ2.1: What are the main dimensions (classes) of the existing poisoning and backdoor attacks? (taxonomy).
- SRQ2.2: What are the characteristics (subclasses) of these dimensions? (taxonomy).
3.1.2. Search Strategy
On the basis of the research questions, we identified the main keywords. Then, we formulated the search string before starting the search in databases by applying the boolean operator OR for synonyms and boolean AND operator for linking keywords. Table 2 shows the formulated search strings.
Table 2.
Search strings.
Well-known academic databases and libraries have been used to collect the papers as listed in Table 3. The results of the database searches are shown in Figure 4. To select the primary studies, inclusion and exclusion criteria have been used. Furthermore, automation tools have been used (Rayyan.io [30] and ASReview [31]) to review, filter, and screen relevant and irrelevant papers.
Table 3.
Digital Libraries and Databases.
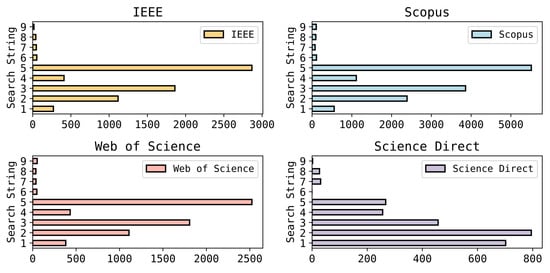
Figure 4.
Search string results on databases.
3.1.3. Study Selection
The search strings described in Table 2 have been applied to the databases listed in Table 3. Due to the fact that the first report of an attack against a DNN was in 2013, we chose to limit the search to the period between 2013 to 2021. Furthermore, the search did not focus on papers on adversarial example attacks or that applied DNNs as approaches to other security issues.
The established inclusion and exclusion criteria have helped to extract the studies that proposed poisoning and backdoor attacks only. The inclusion criteria are as follows:
- papers that have been published in journals or conference proceedings;
- papers that were published in the period between 2013 and 2021;
- papers that address the research questions;
- papers that involve the research keywords; and
- papers that have proposed a poisoning, backdoor, or Trojan attack.
The exclusion criteria are as follows:
- papers that used deep neural networks as approaches but did not focus on them;
- papers that were not written in English;
- papers that do not address the research questions;
- papers that are not related to the research questions such as non-poisoning attacks in DNNs; and
- papers that have not proposed a poisoning, backdoor, or Trojan attack.
The initial search yielded a total of 28,469 papers, 5685 from IEEE, 2537 from Science Direct, 6428 from Web of Science, and 13,819 from Scopus. Then, after removing the duplicated papers using (Refworks, Rayyan [30], Zotero, Mendeley) there were a total of 12,460 papers. Following that, we proceeded to the filtering, skimming, and screening of the titles and abstracts by utilizing (Rayyan.io [30] and ASReview [31]). The inclusion and exclusion criteria were applied throughout the entire process. From a total of 712 screened papers, 52 papers were selected, and 55 poisoning and backdoor attacks were extracted after thorough reading, as shown in Figure 5.
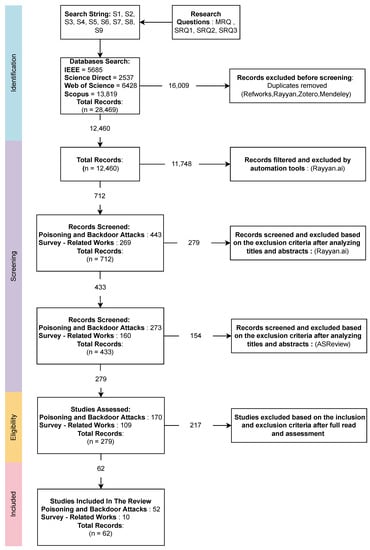
Figure 5.
Research process for paper selection.
In summary, the method followed in this study consisted in the SLR steps listed below:
- defining pertinent research questions;
- providing search strings derived from keywords and research questions;
- defining the databases;
- filtering irrelevant papers;
- skimming titles and abstracts to exclude unrelated articles; and
- reviewing the remaining papers in light of the research questions.
3.2. Phase2
In this phase, we extracted a poisoning attack taxonomy. To enhance the comprehensive view of the threat landscape, we have used abstraction layers to classify the attacks according to key characteristics. The taxonomy included six main dimensions called classes and 36 subclasses which can be used to describe the individual attacks as shown in Figure 6. These classes have been extracted from the full reading and review of the literature.
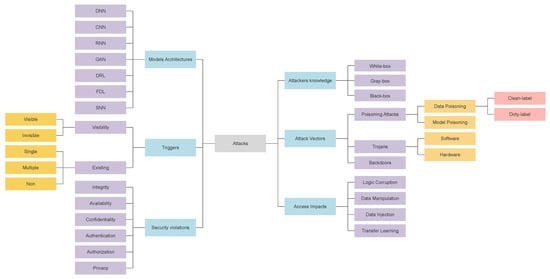
Figure 6.
Extracted poisoning Attack taxonomy.
3.3. Phase3
In this phase, our ontology (DNNPAO) was built. We developed the ontology on the basis of the proposed taxonomy; however, to create our ontological knowledge base, the attacks were added as individuals and the DNNPAO was used as a framework for the creation of the knowledge base. To develop the ontology knowledge base, we used the OWL semantic language with the Protégé tool [32] and webprotege.stanford.edu [32]. To build the knowledge base, we used the Neo4j graph database [33] with the Neosemantics plugin [34] to import the ontology in Neo4j.
4. Poisoning Attack Taxonomy
Taxonomies can help to explain similarities and differences among described objects. From the systematic literature review, we have taxonomized the main characteristics of poisoning attacks to build a high-level structure and domains. As shown in, Figure 6 the extracted taxonomy has six main domains and 36 characteristics. These are the core concepts that have later on been used in our ontology. Thus, we call these domains main classes and the corresponding characteristics subclasses. We have only chosen these to keep the taxonomy scheme and ontology as simple as possible; however, it can be extended to more theoretical classes. The main classes in the poisoning attack taxonomy are shown in Figure 6: security violations, attackers’ knowledge, access impacts, models’ architectures, triggers, and attack vectors. Each one of these classes has subclasses that are described in the sections below.
4.1. Security Violations
In cybersecurity, confidentiality, integrity, and availability is a broadly used information security model, known as the CIA triad, to guide information security policies aimed toward securing organizations’ data by authentication. Authorization, and privacy are other security principles that are related to the CIA triad. For instance, violating confidentiality for sensitive information can result in violating privacy. From a security perspective, confidentiality means that only authorized users can access the data. Confidentiality in DNNs means that only authorized users have access to the DNN models or training datasets. Thus, attacks on confidentiality endeavor to expose the models’ structure and their parameters or the datasets that are used to train the models.
Integrity refers to the incorrect results that occur due to manipulation attacks or system failures. In DNNs, integrity refers to the misclassification outputs or behaviors of the DNN models due to model failures or attacks according to Li et al. [35]. Usually, false-positive results in DNNs are caused by an integrity violation. Availability means that users can access both data and services at any time. In DNNs, availability attacks mean that DNNs are not available where the attackers endeavor to prevent authorized users from accessing meaningful model outputs. Usually, false-negative results in DNNs are caused by an availability violation.
Authentication and authorization characteristics are a process of verifying someone and what he/she can access. Deep neural network models are usually used in authentication systems, such as facial and biometric recognition where attacks against these neural networks can violate authentication and authorization systems. Privacy violation in DNNs is a security threat whereby an unauthorized attacker can gain sensitive information from the training data. A summary of security violations for each attack is provided in Table 4.
Table 4.
A summary of security violations for each attack.
4.2. Attackers’ Knowledge
Attackers’ knowledge characteristics define the knowledge of the targeted model that an adversary has. The attacker might have zero knowledge about the model and the trained parameters that are used in the network, which is referred to as a black-box attack. In a white-box attack, the adversary knows the target model and has complete knowledge of the used algorithms and the parameters. If the attacker has only some of this knowledge that he/she can utilize, it is referred to as a gray-box attack. Although white-box attacks have higher success rates than black-box attacks, the scenario of white-box attacks may be unrealistic, and the black-box attacks might be more applicable in real-world applications [18]. A summary of attackers knowledge for each attack is provided in Table 5.
Table 5.
A summary of attackers’ knowledge and triggers for each attack.
4.3. Triggers
The triggers are a hidden malicious functionality known only by the attacker that can be inserted at the training phase and can remain cleverly concealed until the chosen time to activate Trojans or backdoor attacks in later phases. In some attacks, triggers may not exist, such as in triggerless poisoning attacks or in triggerless backdoor attacks. In addition, one attack may only use a single trigger but it can also use multiple triggers for the same attack as a pattern to activate the attack and make it more difficult to detect. Triggers can also be visible to humans, such as changes in the shapes or sizes of images or they might be invisible for humans to detect the changes between clear data and poisoned data. Although triggers might be visible to humans, they could be easily deployable and difficult to detect with big datasets or in the real world such as by using tattoos or glasses. A summary of triggers for each attack is provided in Table 5.
4.4. Access Impacts
The concern of the adversaries of DNNs is the ability of the attackers to gain access to the network and what impact attackers can have on the network as a result of this access. We consider four different possibilities of impact as a result of access to the DNNs. The first scenario is the logic corruption whereby the adversaries can evade and corrupt the learning algorithms which can usually be seen on the neural Trojan attacks. The second scenario is data manipulation, whereby the attacker can modify the data such as labels and learning parameters. Another scenario is data injection whereby the attackers can inject new parts, such as triggered images. These can be seen in many attack scenarios, such as data positioning and backdoor attacks. The fourth scenario of access impacts is transfer learning, which exists when using pre-trained models or teacher and student models. A summary of access impacts for each attack is provided in Table 6.
Table 6.
A summary of access impacts for each attack.
4.5. Deep Neural Network Models’ Architectures
In machine learning, when a neural network only has an input and an output layer and may have one hidden layer, we call this neural network a shallow neural network [87]. If the neural networks have multiple hidden layers with more complex ways of connecting these layers and neurons, we call these deep neural networks. Thus, DNNs are based on layers that have a collection of perceptrons, called neurons, to determine the outputs. These are some of the common neural network architectures: CNN, RNN, GAN, DRL, FDL, and SNN.
The convolutional neural network (CNN) is a DNN that has at least one convolutional layer that convolves with a multiplication or other dot product and can extract the features from unstructured data with no requirement for human interaction [88]. A feed-backward architecture that uses back-propagation for backward connections of the neurons is called a recurrent neural network (RNN) [89]. The outputs on the network are dependent on the previous calculation in a sequence. RNNs can automatically manage the input data and may not provide the same output for the same input each time.
Goodfellow et al. [90] introduced the generative adversarial network (GAN) for estimating generative models via an adversarial process. The GAN corresponds to a two-player game between discriminator (output) and generator (input). Its role is to produce samples identical to the training set of the discriminator. GAN has been used as a semi-supervised or unsupervised learning and applied in many domains such as motion and game development. Radford et al. [91] improved the version of GAN with a deep convolutional GAN (DCGAN), which makes the network more stable to train and overcomes some of GAN’s constraints.
Reinforcement learning (RL) is a type of machine learning that uses an agent in an environment to learn behaviors through trial and error [92]. Deep reinforcement learning (DRL) uses DNNs to obtain an approximation of the reward function which can take large data as inputs compared with traditional RL environments and can solve complex reinforcement learning problems. Theoretically, a spiking neural network (SNN) is a bio-inspired information processing network, where the communication signals between neurons are sparse in time and asynchronously binary and known as spikes [93]. In principle, deep spiking neural networks can reduce redundant information by exploiting event-based and data-driven updates which preserve the potential for enhancing the latency and energy performance of DNNs [93]. Deep SNNs are suitable architectures for developing efficient brain-like applications such as pattern recognition.
In the distributed DNN paradigm, the deep federated learning (DFL) approach has been developed to address privacy-preserving of deep networks among participating devices that have their own copies of pre-trained models and on-device data [94]. In fact, the level of privacy in a certain model is decided by the updating of the model’s minimally essential information [94]. A summary of DNN models’ architectures for each attack is provided in Table 7.
Table 7.
A summary of model architectures for each attack.
4.6. Attack Vectors
Attack vectors are the mechanisms that hackers can use to exploit system vulnerabilities. As the scope of this paper, poisoning attacks can be generally categorized into three main attacks: triggerless poisoning, backdoor attacks, and Trojan attacks. Triggerless poisoning occurs at the training phase and does not require modification at the test phase. Data poisoning attacks occur when adversaries insert poisoned samples into the training datasets. Model poisoning occurs when adversaries exploit the model knowledge during the training time. Data and model poisoning attacks are both types of triggerless poisoning attacks, usually known as poisoning attacks. Backdoor attacks, on the other hand, use poisoning attacks to insert triggers that can activate the backdoors at testing (inference) phase. The early backdoor attack cases changed the label of the poisoned data known as dirty-label attacks; however, clean-label attacks now exist which do not change the labels of the poisoned data. In DNNs, Trojans are similar to backdoor attacks and can cause misclassification or bad behavior of the targeted models without raising suspicions. Trojan-embedding methods can be at the hardware level, such as accessing to merely the memory bus data or at the software level, for example by utilizing poisoning attacks to inset triggers. Data poisoning and model poisoning attacks may affect the accuracy of the DNNs, but backdoor and Trojan attacks remain silent until the activation of the triggers and may never affect the accuracy which makes them difficult to be discovered even after the attack occurs. A summary of attack vectors for each attack is provided in Table 8.
Table 8.
A summary of attack vectors for each attack.
5. A Review of the Selected Papers
This section provides a review of the 52 poisoning attack papers selected from the systematic review process described in Section 3. The structure of this review is based on the primary attack vectors (as mentioned in Section 4) classified into three categories: poisoning attacks (Section 5.1), backdoor attacks (Section 5.2), and Trojan attacks (Section 5.3). A summary of this review section is provided in Section 5.4, highlighting the relevance of the reviewed works to the main topic of this paper and their limitations.
5.1. Poisoning Attacks
Many developers employ third-party tools and datasets due to the amount of large data and the computing time required to train DNN models. Attackers can poison the datasets with malicious data in order to train the models based on the attacker’s desired outcomes. These poisoning attacks can be either targeted or untargeted. The DNN models themselves are another attack surface that could be poisoned. Notably, many libraries and models built by third parties may contain backdoor attackers or Trojans.
Early papers [73,82,84,95] were published in 2017–2018. Muñoz–González et al. [73] proposed a multiclass poisoning attack that can target a range of DNN algorithms. The attack scenarios can violate the availability and integrity of such a system by exploiting the back-gradient optimization. The first scenario is a generic error poisoning attack to cause a denial of service. The second scenario is a specific error poisoning attack that targeted a specific multiclass based on the desired misclassifications. The result shows that the attack could be a significant threat to DNNs. The authors showed that a small fraction of poisoning in the training data can compromise learning algorithms. Ji et al. [95] focused on model-reuse attacks that can be used in deep learning. They provided empirical and analytical justification and concluded that this is a fundamental issue to many deep learning systems. Garofalo et al. [82] were the first to implement a poisoning attack against a face authentication system by injecting a poisonous image into the retraining data. They showed that the proposed poisoning attack could violate the integrity and availability of the face authentication system by increasing the number of false positives and false negatives. The successful result of the authentication error poses a threat against modern face authentication systems. Li et al. [84] proposed a poisoning attack against targeted wireless intrusion-detection systems (IDSs). The presented strategy crafts high-quality adversarial samples by using the generated substitute models from a proposed stealing model attack. The results show that by using DNN algorithms, the attack’s strategy can effectively impair the performance of IDSs.
In the year 2019, refs. [38,69,78,80,85] were published as poisoning attacks papers in the systematic literature review. Zhu et al. [69] proposed a clean-label transferable poisoning attack in which the poison images are designed to be convex around the targeted image in feature space. The result shows that when poisoning only 1% of the training set, the success rates of the attack can reach 50% even without accessing the targeted network’s outputs and architecture. Bhagoji et al. [38] demonstrated the possibility of model poisoning attacks on a federated learning global model, resulting in high model error rates. To overcome the effects of other agents, the attack targets the model by boosting the malicious agent’s update. They improve attack stealth by employing an alternating minimization technique that optimizes for stealth and the adversarial aim alternately. This research shows that federated learning is subject to model poisoning attacks. Zhang et al. [85] proposed a poisoning attack against federated learning based on generative adversarial nets (GAN). In this attack, the adversaries can successfully attack the federated learning as participants. The attacker’s goal is to generate poisoning samples by using GAN to update the global model to be compromised. Kwon et al. [78] proposed a selective poisoning attack that decreases the accuracy of only a selected class in the neural networks by training harmful training data corresponding to the selected class while keeping the normal accuracy of the remaining classes. Zeng et al. [80] presented a perturbation-based causative attack that targets DNN pre-trained models for supply chain in the VANET. The results show that such a perturbation-based misguiding of a DNN classifier in the VANET is effective.
Papers on poisoning attacks that were published in the year 2020 are [36,42,44,57,58,68,74,76,83], and there was only one paper [79] in 2021, at the time when this literature review was conducted. Lee et al. [36] developed a show-and-tell model that identifies a photograph of a construction site to determine safety. This poisoning attack generates adversarial data by adjusting a small bit of the (red, green, and blue) RGB values that are not recognized by humans. The authors repeated this process forward and backward until the feature value was close to the target picture feature but the distance was close to the base image. Liu et al. [44] proposed a data poisoning attack in lithographic hotspot detection by poisoning both non-hotspot training and test layout clips. By adding a trigger shape in the input, hotspots in a layout clip can be hidden during inference time. This shows that training data poisoning attacks are viable and stealthy in CAD systems, highlighting the need for ML-based systems in CAD to be more robust.
Huai et al. [42] first introduced adversarial attacks on DRL interpretations. The authors proposed MPDRLI, a model poisoning attack against DRL interpretations. The attacker directly manipulates the pre-trained model parameters obtained during the training phase. With only modest impact on the performance of the original DRL model, the attack can have a considerable impact on the interpretation outcomes. An unseen poisoning attack was postulated by Chen et al. [57] named the invisible poisoning attack (IPA). The poison-training examples in this attack were perceptually unnoticeable from the benign ones, making it extremely stealthy. With fewer poison-training examples in the training phase and a better attack success rate in the testing process, the IPA is capable of executing targeted poisoning attacks. The provided poisoning instances can both be invisible and effective in targeting DNN models.
Chen et al. [58] proposed a poisoning attack named deep poison. To fool the target model, the proposed attack uses three-player GAN to create stealthy poisoned instances embedded with the victim class features. The poisoning is accomplished through the use of massively generated poisoned samples for training attack models. The experiments demonstrated that the suggested poisoning attack that can reach a high success rate with only 7% poisoned samples in the datasets. Zhou et al. [68] proposed a data poisoning attack against a graph autoencoder recommender system by injecting fake users that mimic the rating behavior of normal users. In the attack scenario, they assumed that a white-box attack might be unrealistic to apply in real-world recommender systems. Tolpegin et al. [83] show that federated learning (FL) systems are vulnerable to poisoning attacks, in which a subset of malicious participants can poison the trained global model. Their proposed label-flipping attack indicates that poisonous samples can reduce the classification accuracy and cause an availability impact to the FL systems even though the participants do not know the model type or parameters. Li et al. [74] proposed a data poisoning attack against deep reinforcement learning (TruthFinder). In this approach, malicious workers jeopardize with TruthFinder while hiding themselves. According to this method, malicious workers can continuously learn from their attack efforts and adapt their poisoning strategies. The findings reveal that even if the malicious workers only have access to local information, they can devise successful data poisoning attack tactics to interfere with crowdsensing systems by using TruthFinder. Xu et al. [76] proposed an adversarial sample attack by using a poisoning attack method on RNNs. To limit the number of samples required for a poisoning attack, they optimized the generation approach and confined the sample search space by using abnormal event gradient information. Cole et al. [79] demonstrated a data poisoning attack that needs an adversarial photo injection to enable an attacker to easily mimic the victim model of the existing facial authentication systems with no need of any knowledge from the server side. Adversaries can compromise the victim’s web accounts and log into their services.
5.2. Backdoor Attacks
Regarding backdoor attacks, early papers [47,53,54,60,62,70,96] in the systematic literature were published between 2017 and 2019. Chen et al. [96] proposed backdoor poisoning attacks where the attacker can bypass a DNN authentication system by creating a backdoor by using data poisoning attacks, for instance, deep neural authentication systems that use face recognition and fingerprint identification. This attack can be considered as a black box with a success rate of above 90% when injecting only around 50% poisoning samples. Wu et al. [53] performed a backdoor attack against obstacle recognition and processing system (ORPS) by poisoning the dataset to embed the mask R-CNN in the ORPS (DCNN-based models). When triggering the backdoor in the target model, the accuracy of the backdoored model may be changed, which may cause serious accidents in self-driving vehicles. The authors claim that this is the first work on this topic in the literature. The experiment reveals how to exploit DNN models (such as the ORPS) by embedding backdoor attacks.
Barni et al. [54] described a backdoor attack that only corrupted samples of the target class without requiring poisoning of the labels. The attack’s versatility and stealth are substantially increased in this manner; however, the percentage of samples that must be corrupted is considerable. The implementation looked at two classification tasks: MNIST digit recognition and traffic sign classification. The backdoor signal’s invisibility was easier in the first implementation; nevertheless, the results demonstrated a nearly invisible backdoor in the second version. Yao et al. [60] identified a latent backdoor attack for transfer learning. Latent backdoor attacks are capable of being embedded in teacher models and automatically inherited by multiple student models via transfer learning. Any student model with the targeted label of the backdoor can be activated after the neural network recognizes the trigger of the attack’s target label.
Bhalerao et al. [62] proposed a backdoor attack targeting a DNN-based anti-spoofing video rebroadcast detector. The authors claim that this is the first time that a backdoor attack has been utilized to compromise an anti-spoofing mechanism. The attack showed robustness against geometric transformations by using a predesigned sinusoidal function to verify the average luminance of the video frames. Gu et al. [70] proposed a backdoor attack named BadNet. The implementation of the BadNet attack considered the MNIST handwritten digit recognition system; and in a more complex scenario, they performed the attack against a traffic sign detection system. The authors demonstrated that BadNets can be a malicious real-world attack that can reliably misclassify stop signs as speed-limit signs by using a Post-it note. These results show that backdoor attacks in deep neural networks are both effective and invisible. Dai et al. [47] implemented a backdoor attack against LSTM-based text classification by using data poisoning. To generate poisoning text samples, the attack employs a random insertion approach. The backdoor injected into the model has little effect on performance, but the trigger attack is stealthy. The testing results showed that the attack can reach around 96% success rate with 1% poisoning rate in a black-box situation and through sentiment analysis.
In the year 2020, many studies were published that proposed backdoor attacks. Dumford and Scheirer [37] suggested an attack that targeted certain layers inside a CNN in order to create an attacker-accessible backdoor. The attack requires no prior access to training data; nevertheless, access to the pre-trained model is required. Zhong et al. [41] proposed generating approaches of a backdoor attack that are invisible in poisoning the DNNs. Backdoor injection can be performed either before or after model training. The backdoor employs data poisoning to inject the trigger with a small poisoning percentage that does not interfere with the usual operation of the learned process. The results show that even under the most weak assumptions, such as in a black-box situation, attacks can be effective and achieve a high attack success rate at a low cost in terms of model accuracy loss and injection rate. Such attacks might exploit a deep learning system’s vulnerability invisibly and possibly cause havoc in a variety of actual applications, such as destroying an autonomous vehicle or impersonating another person to gain illegal access. Xue et al. [43] offered two techniques to backdoor attacks. The first is known as One-to-N, and it can trigger multiple backdoor targets by varying the intensities of the same backdoor. The second is known as N-to-One, and it is triggered when all N backdoors are satisfied. Against some defense techniques, the suggested One-to-N and N-to-One attacks are effective and stealthy. Zhao et al. [48] proposed a clean-label backdoor attack against deep neural networks in video recognition models. The attack makes use of the adversarial approach (PGD) to generate videos with a universal adversarial backdoor trigger. The results demonstrated that the suggested backdoor attack can influence state-of-the-art video models and can be utilized as a baseline for enhancing the robustness of video models, as well as to improve picture backdoor attacks.
Liu et al. [49] proposed Refool, a clean-label backdoor attack inspired by an important natural phenomenon: reflection and employing mathematical modeling of physical reflection models. The empirical findings demonstrate a high success rate and a slight loss in clean accuracy. Reflection backdoors are easy to create and impervious to state-of-the-art protection measures. Tan and Shokri [51] proposed an adversarial backdoor embedding attack that uses adversarial regularization to maximize the discriminator’s loss in order to avoid network detection algorithms. The findings reveal that a skilled attacker may readily conceal the signals of backdoor images in the latent representation, rendering the defense ineffective. This research asks for the development of adversary-aware defense techniques for backdoor detection. Lovisotto et al. [86] proposed a template poisoning attack against face recognition that allows the adversary to inject a backdoor. This biometric backdoor allows the adversary to grant discreet long-term access to the biometric system by using craft-colored glasses. The result shows that with the white-box scenario, the attack success rate is acceptable, which is over 70% of cases; however, the attack success rate decreases in the black-box scenario to around 15% of cases.
Li et al. [35] aim to raise awareness of the seriousness of invisible triggers that can misguide both machine learning models and human users. In this matter, detection becomes significantly more difficult than with current backdoor triggers. In this work, the first invisible backdoor attack employed steganography techniques to conceal the manually created trigger. The authors embedded concealed data into a cover image using the least significant bit (LSB). On the CIFAR-10 dataset, the trigger’s invisibility decreases as its size increases. The second attack in this study makes the shape and size of trigger patterns undetectable by using Lp-norm regularization. The authors used three universal backdoor attacks that targeted the penultimate layer (L2, L0, and regularization-based). Using the Lp-norm ensures that the noise is modest; nonetheless, the threshold value used to end the optimization has an effect on the attack success rate. Utilizing a large stop threshold makes the trigger visible to human inspectors, whereas using a smaller stop threshold makes injecting the backdoor into the DNN more difficult.
Xiong et al. [55] proposed two backdoor attacks capable of effectively inserting the backdoor while evading two state-of-the-art detection mechanisms (the neural cleanse and DeepInspect). The distinction between the first and second attacks is that the second one increases both attack ability and detection difficulties by decreasing the ratio of the trigger size. The triggers of their backdoor attack strategy can be generally hidden and reconstruction-resistant incorporated into DNN models. The results show that the proposed attacks are capable of evading detection systems. Kwon et al. [56] developed TargetNet, a backdoor attack that induces misclassification in multi-targeted models by utilizing a single trigger with a different label for each of the targeted models. The experimental results show a high success attack rate with nearly ordinary accuracy. He et al. [26] proposed an invisible hidden backdoor attack method named BHF2 against face recognition systems whereby the attacker can inject a small batch that can successfully let the attacker log in into the system as the victim. The results suggest that the BHF2 method can obtain a high attack success rate while sacrificing only a low percentange of accuracy. Quiring and Rieck [61] proposed a combining clean-label poisoning attack and a backdoor attack that benefits from image-scaling to hide the trigger. These attacks enable the manipulation of images when scaled to a specific resolution with an almost constant performance.
KWON et al. [64] proposed a multi-targeted backdoor that misleads different DNN models into distinct classes. This technique trains multiple models with data that includes specific triggers that cause misclassification into related classes by distinct models. The proposed techniques can be applied to the audio and visual domains. Venceslai et al. [77] proposed a hardware backdoor named NeuroAttack, which is a cross-layer attack that against the spiking neural networks (SNNs). By attacking low-level reliability vulnerabilities with high-level attacks, this attack triggers a fault-injection-based sneaky hardware backdoor via a carefully prepared adversarial input noise. Liao et al. [41] demonstrated that the backdoor injection attacks with a small loss accuracy rate and a small injection rate can achieve high success. The authors proposed a data poisoning attack which triggered CNN models to recognize particular embedded patterns with a target label in a covert manner without compromising the accuracy of the victim models.
In the year 2021, at the time of the literature review, there were three [39,59,71] papers. Zhou et al. [39] presented a unique optimization-based model poisoning attack on federated learning by injecting adversarial neurons in a neural network’s redundant space by using the regularization term in the objective function. The results demonstrated that the proposed attack mechanism outperformed backdoor attacks in terms of performance effectiveness, durability, and robustness. Furthermore, Xue et al. [59] introduced another hidden backdoor attack method known as BHF2N, which also conceals the created backdoors in facial features (eyebrows and beard). The proposed methods provide the hiding of backdoor attacks and can be used in cases requiring strong identity authentication. As a result, the suggested invisible backdoor attacks are stealthy and possible for more rigorous face recognition scenarios, emphasizing the importance of creating strong defenses against DNN-based biometric recognition systems. Guo et al. [71] proposed a backdoored attack against a face verification system that matches a master face to give a positive answer against any other face. They consider a white-box scenario in which the adversary can have full knowledge of the target system such as in MLaaS systems. The experiments showed that the attack is effective to the siamese network that conforms images of two faces belonging to the same person.
5.3. Trojans
As the effort required to train deep neural network models dramatically increased in recent years due to the high hardware requirement and time consumption, machine-learning-as-a-service becomes the option for many users. Early Trojan papers [40,67,72,75,97,98] in the systematic review were published between 2017 and 2019. Liu et al. [97] demonstrated that malicious samples can be embedded in the training dataset of the deep neural networks. These malicious samples might be activated in later stages, and this hidden malicious functionality is known as a neural Trojan. Training data poisoning-based attacks Zou et al. [98] proposed a neural-level Trojan named PoTrojan. The authors claim that PoTrojan was the first proposal of an attack on pre-trained DNN models. Attackers can insert additional malicious neurons into a pre-trained DNN that would remain inactive until they are triggered to cause malfunction of the DNN. However, this might be hard to achieve in practice because the attackers need to have full knowledge of the target DNNs. Binary-level attack Trojans can also be embedded by using the binary code of neural networks. Li et al. [75] proposed a hardware–software collaborative neural Trojans attack in which neural Trojans are hidden into a well-structured subnet during the training process and triggered by hardware Trojans at the appropriate time.
Liu et al. [67] proposed a low-cost neural Trojan attack named stealth infection on neural network (SIN2) that can threaten an intelligent supply chain system by performing malicious payloads to cause misclassification in such a service. The trigger is injected into the victim DNN model through a proposed embedding method to replace selected weight parameters. The infected DNN model performs a normal service until the malicious payloads are extracted and executed at the victim side on the runtime which can violate the confidentiality, integrity, and efficiency of such a system. The rising dangers in this intelligent supply chain scenario enable a novel practical neural Trojan attack that has no effect on the quality of intelligent services.
Clements and Lao [72] proposed a hardware neural Trojan attack. This novel technique injects hardware Trojans into computational blocks of a DNN implementation in order to achieve an adversarial aim by triggering the logic operation that targets the activation functions. The results show that the different scenarios of this hardware Trojans can be worthwhile. Davaslioglu and Sagduyu [40] proposed a Trojan attack against a deep wireless communications classifier model. They use raw (I/Q) samples as features and modulation types as labels to categorize wireless signals. The trigger injects into a few training data samples by changing their phases and labeling them with a target label. During testing, the adversary emits signals with the identical phase shift that was added as a trigger during training. The Trojan attack remains hidden until the trigger that bypasses a signal classifier, such as an authentication, is activated.
In the systematic review of Trojan attacks, papers that were published between 2020 and 2021 are [45,46,50,52,63,65,66,81]. Tang et al. [52] proposed a training-free Trojan attack strategy in which a little Trojan module named TrojanNet is inserted into the target model. The authors claim that this method differs from past similar attacks in that the Trojan behaviors are injected by retraining the DNN model on a poisoned dataset. TrojanNet is an all-label Trojan attack that can inject the Trojan into all labels at the same time and achieves a 100% attack success rate without impacting the model accuracy on original tasks. The results have shown that the proposed approach can mislead cutting-edge Trojan detection algorithms, causing TrojanNet attacks to go undetected.
Lin et al. [46] introduced a composite attack, a more adaptable and covert Trojan attack that avoids backdoor detectors by utilizing Trojan triggers constructed of existing benign subjects/features from several labels. In this attack, training is outsourced to a malicious agent with the goal of providing the user with a pre-trained model that contains a backdoor. The infected model performs well on normal inputs but predicts the target label when the inputs match particular composition rules and meet attacker-chosen attributes. The attack demonstrates that a DNN with a constructed backdoor may achieve accuracy comparable to its original version on benign data while misclassifying when the composite trigger is present. Chen et al. [50] presented SPA, a unique stealthy Trojan attack technique. A generative adversarial network is used to generate the poisoned samples. Experiments have shown that SPA may obtain a high success rate for a Trojan attack with only a few poisoned samples in well-known datasets such as LFW and CASIA.
Costales et al. [63] presented a live Trojan attack that can exploit a DNN model’s parameters in memory at runtime to achieve predefined malicious behavior on a certain set of inputs. They demonstrate the feasibility of this attack by using a method of performing patches with clean and Trojaned images after retraining against multiple real-world deep learning systems. Liu et al. [65] proposed a hardware Trojan attack that leverages a specific sequence of normal images as a trigger. The result shows that this triggering technique is more robust to the pixel-bit triggering to evade the image pre-processing and is also invisible to human beings.
Rakin et al. [66] proposed a neural Trojan attack named targeted bit Trojan (TBT), which inserts a neural Trojan in the main memory such as a DRAM to target the DNN weights by using a bit-flip attack. At the inference phase, the DNN operates as normal with the normal accuracy until the trigger is activated, which violates availability because the network is forced to classify all inputs to a certain target class. Pan [81] proposed a black box Trojan attack that can induce malicious inferences to any deep neural network model with simple steps. The attack operates in different modes from normal behavior to false positives and false negative errors which alter the integrity and availability of any deep learning image classification system. The trigger vector could manipulate the weights to cause specific types of errors and change of the modes. Hu et al. [45] proposed a hardware Trojan attack on DNN by merely accessing the memory bus data. The attack injects malicious logics into the memory controllers of DNN systems without the need for toolchain manipulation or access to the victim model, making it viable for usage.
5.4. Summary
We now summarize and conclude this section. According to the literature review presented earlier in this section, most of the attacks violate the integrity and/or availability of the DNN models. In general, availability is caused by triggerless poisoning attacks, whether they are data or model poisoning attacks. As mentioned in Section 4, these attacks reduce the accuracy of DNNs, which means that system owners can recognize this and react after an attack has occurred. For example, the poisoning attack in [73] targets back-gradient optimization. This was one of the early poisoning attack methods. Although targeting the back-gradient optimization of the DNN violates the availability, and the limitation of this method is that the reaction after an attack can reduce the benefits of these kinds of poisoning attacks. Garofalo et al. [82] overcame back-gradient optimization attacks that violate availability and were the first to introduce a poisoning attack against integrity. The issue with their attack is that it increases the number of false positives and false negatives, which means the availability of the targeted system will be compromised.
Backdoor and Trojan attacks, on the other hand, violate integrity, which means that system owners may fail to realize that the DNN models were trained with poisoned data or may fail to notice that an attack occurred after the trigger was activated. There is an increasing number of backdoor and Trojan attacks in the literature, and triggerless poisoning attacks have become only a step in these attacks to inject their triggers. Although the defence is beyond the scope of this paper, the systematic review shows that the research on reacting after the attacks is insufficiently explored.
Another improvement in poisoning attacks is the increase in the success rates of the attack while reducing the amount of data that needs to be poisoned. For example, Chen et al. [58] suggested a poisoning attack that can reach a high success rate with only 7% of poisoned samples in the dataset. However, the design that Zhu et al. have used to convex a poison image around the target shows that only 1% of the datasets need to be poisoned.
Few attacks have been proposed in real-world scenarios, such as [63,68,70]; however, there is less consistency in the literature on real-world scenarios. Most of the early attacks as well as current attacks focus on computer vision, which is the core of most AI real-world applications. Furthermore, there is an increasing emphasis in the literature on black-box attacks, which may be more practical in real-world applications. Thus, one of the tough challenges for researchers in this domain is determining whether a practical poisoning attack will occur in a real-world application. Semantic data, such as that found in ontologies and knowledge graphs, can assist experts in identifying attack characteristics, vulnerabilities, and defiance mechanisms in order to detect and respond to attacks. Furthermore, semantic features can help in the integration of information into AI applications.
6. DNN Poisoning Attacks Ontology (DNNPAO) and Knowledge Base Construction
In this section, an ontology and a knowledge base is presented in order to obtain semantic information about the poisoning attacks. To determine the domain and scope of the ontology, we used our extracted taxonomy as a scheme. The DNN poisoning attacks ontology (DNNPAO) maps all the classes that were introduced in the poisoning attack taxonomy in Section 4 into a single concept, and maps all the attacks that were systematically reviewed as individuals with their relationships. The basic aim of the proposed ontology is to express the complex knowledge of poisoning attacks against DNNs. Thus, we built a knowledge base by using the DNNPAO as a framework.
6.1. DNNPAO Construction
An ontology is a piece of semantic information that is written by using a semantic language to describe things and the relationships between these things. There are several semantic languages; in this paper, we use the web ontology language (OWL) to describe our ontology. To develop the ontology by using the OWL semantic language, the Protégé tool [32] and webprotege.stanford.edu [32] were used. The DNNPAO ontology has 45 classes that include the main classes and subclasses as shown in Figure 7. The definition of the main classes of the DNNPAO ontology are described in Table 9. Table 10 shows object properties, which are the relationships between the class (nodes), which has domains, and ranges. In addition, it has 107 individuals that are the 55 attacks and the 52 papers that propose these attacks are shown in Table 11.
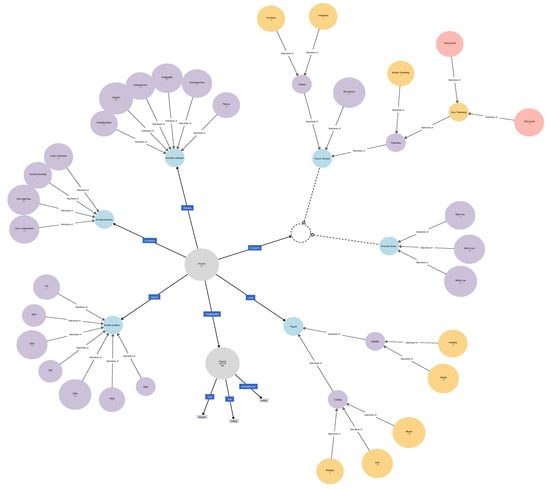
Figure 7.
The DNNPAO ontology including classes and properties.
Table 9.
The definition of the main classes in DNNPAO.
Table 10.
Definition of the main relationships in DNNPAO.
Table 11.
A list of individuals in DNNPAO.
We have mapped the 55 extracted attacks as individuals, which were added to the DNNPAO ontology with their relations to the corresponding classes and subclasses; these attacks connected with their papers as shown in Table 11. As shown in Figure 8, these three examples of individuals (attacks) appear in the DNNPAO ontology at webprotege.stanford.edu [32]. Attack1, Attack3, and Attack34 are individuals that have relations with multiple classes and subclasses; in other words, they are instances of these classes. In addition, they have a “PublishedBy” relationship with other individuals that are the papers where these attacks were published. For a full list of individuals (attacks) in DNNPAO, please refer to Appendix A.
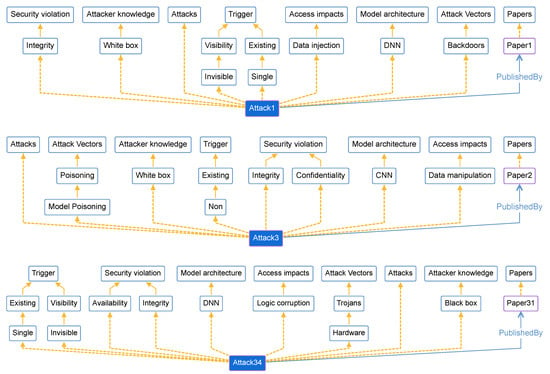
Figure 8.
Three individuals (i.e., attacks), Attack1, Attack3, and Attack34, as instances of DNNPAO classes and sub-classes.
Figure 8 provides examples of three individuals, that is, attacks, Attack1, Attack3, and Attack34, as instances of DNNPAO classes and subclasses. For instance, Attack1 is an instance of the class “Integrity” which is a subclass of the superclass “Security violation”. In addition, Attack1 is connected to Paper1 which is another individual or instance of the class “Papers”. Because Attack1 and Paper1 are both individuals they have the relationship “PublishedBy”. The other examples, Attack3 and Attack4, are created similarly. For a full list of individuals (attacks) in DNNPAO, please refer to Appendix A.
6.2. Knowledge Base Construction
Our main topic is DNN security, but it is useful for the field and community to get to share complex knowledge by using an ontology and knowledge base. Thus, we have built the knowledge base by using DNNPAO as a framework. To do so, we chose the Neo4j database [33] with Neosemantics plugin [34] that enables an OWL ontology to be imported into Neo4j database. Figure 9 shows the DNNPAO classes and subclasses, as well as their relationships, that were imported into the Neo4j database. In addition, Figure 10 shows a DNNPAO meta-graph from the Neo4j database.
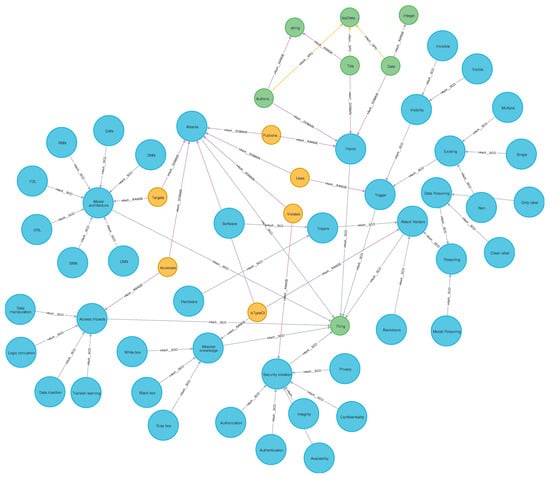
Figure 9.
DNNPAO classes and subclasses with their relationships in Neo4j database.
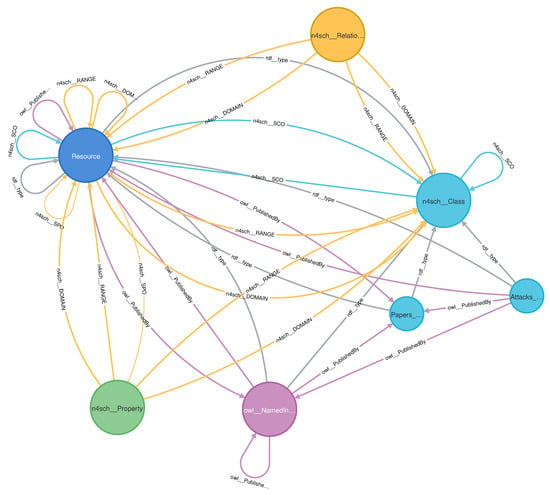
Figure 10.
Meta-graph of the DNNPAO in Neo4j database.
We now evaluate performance of DNNPAO by using a few simple tests. The objective of these tests is to demonstrate the viability of using DNNPAO on a standard personal machine. Because the DNNPAO is based on the (OWL) ontology, we focused on query performance testing. This test is conducted on a standard laptop machine, and the neo4j graph database is examined with a tool called Apache-Jmeter-5.5 [99] and the Bolt protocol. The laptop contains a core 2.40 GHz (Intel Core i7) CPU with Ubuntu 20.04.5 LTS OS, 16 GB RAM, and 1TB HDD.
We have tested three different types of queries. The first is the K-hops, which counts the number of hops around a target node. The second query type is the shortest path from a node to another node. The third query type is a query that retrieves all the nodes in the graph database to test the system load. We have provided complete details of the queries and their results on our project GitHub page [100].
The goal of the K-hop query test is to conduct K-hop queries that count the number of hops around a target node and evaluate their performance at the runtime by using the Apache-Jmeter tool. In our test, we ran five queries (Query1 to Query5) to count the number of neighbor nodes from the node “Attacks”. The results show that there were no errors. The distinct count in the result shows that the number of classes and subclasses have a relationship with the “Attacks” class. For example, as Figure 11 shows, Query1 (1-hop) results in 1 counted hop, which is the class named “Thinks”. The 2-hop query results in 8 counted hops, which are the other 6 classes as shown in the taxonomy (see Figure 6) plus the “Thinks” and “Papers” classes. The load time shows that retrieval time in the memory for Query1 is 299 ms, and subsequently the load times of the other 4 queries were dramatically reduced to around 25 ms.
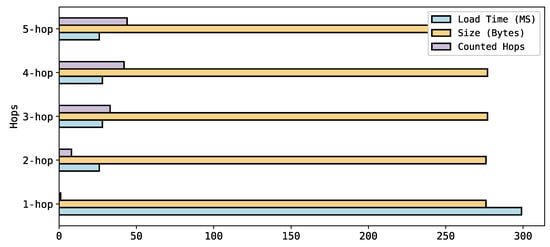
Figure 11.
The results for the K-hop queries from Query1 to Query5.
The purpose of the shortest path queries is to find the shortest path between two nodes. In our test, we used the Apache-Jmeter tool to run two shortest path queries in Cypher. The Query6 sought to find the shortest distance between “Attack1” and “Attack5”. The outcome is depicted in Figure 12, which indicates that both “Attack1” and “Attack5” violate integrity, making the “Integrity” class the path between them. The query completed without error in 35 ms.
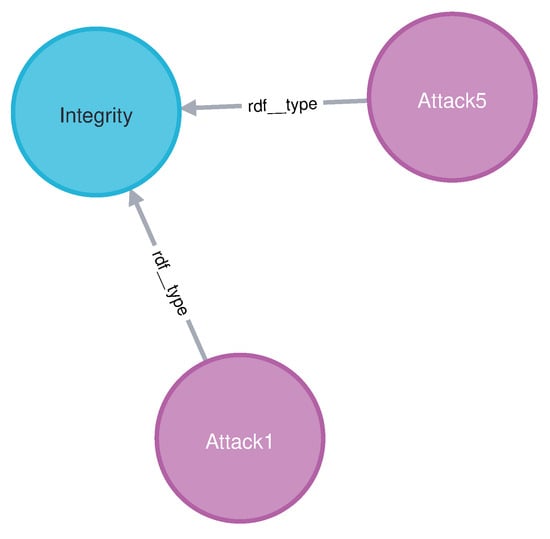
Figure 12.
The result of the shortest path Query6.
In Query7, we utilized nodes with no direct relationship, such as “Attack10” and “Paper43”. The result shown in Figure 13 demonstrates the shortest path between them with no error.
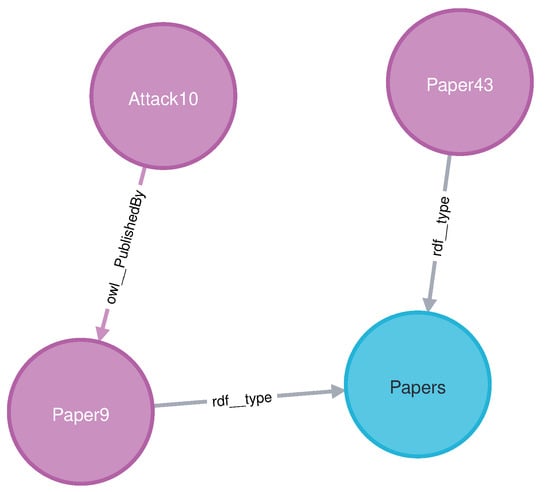
Figure 13.
The result of the shortest path Query7.
To evaluate the system’s load performance, we performed a query (Query8) that retrieves all nodes from the graph database by using Apache-Jmeter tool. The test consisted of 6686 samples, each of which had the Cypher query for retrieving all nodes from two users with a ramp-up time of one second and a duration of 10 s. Figure 14 shows that the load average time is two ms. Furthermore, it demonstrates that 90% of the samples took no longer than four milliseconds and 99% of the samples took no longer than seven ms.
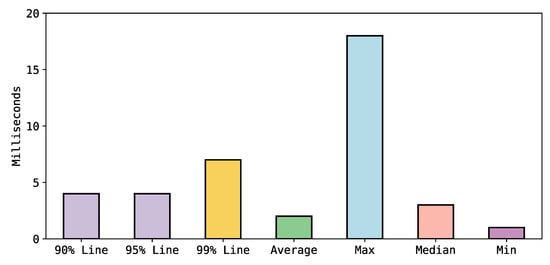
Figure 14.
The results of Query 8 for retrieving all nodes to test the DNNPAO load performance.
7. Discussion and Utilization
DNNs have brought innovative changes and introduced new dimensions in many fields. They rely upon their input data, structure, and parameters, and any change might mislead the DNNs and this sensitivity of DNNs makes them brittle against adversarial attacks. Attackers can mislead the DNNs by corruption parameters, maximizing error functions, or manipulating the datasets. Recent research demonstrates that the robustness of DNNs is a critical weakness against malicious attacks.
The robustness of DNNs is also vital due to the emerging concepts of responsible and green artificial intelligence that aim to preserve ethics, fairness, democracy, and explainability of AI-based decision systems. In addition, in smart cities, the Internet of things (IoT) is a critical component. Several innovative ML and DL approaches have been proposed to safeguard IoT network environments from cyberattacks [101,102,103,104]. However, the robustness of DNNs against adversarial attacks provides another point of view with which to prevent such environments form cyberattacks.
Although there are a growing number of research on adversarial attacks, only a few of them focus on poisoning attacks. Meanwhile, with the rapid use of DNNs, evaluating the robustness of DNNs involves exploring weaknesses in DNNs. Traditional security management and threat analysis lack methods for intelligent responses to new threats.
Utilization
A semantic knowledge representation of security attacks is a significant means of retrieving data for analysts whether they are human or AI agents. In addition, there is still a lack of semantic knowledge graphs and intelligent reasoning technologies for emerging attacks. The purpose of an ontological knowledge base is to derive knowledge that has not been clearly expressed. For instance, DNNPAO was queried in order to deduce some knowledge of the attacks, as seen in Figure 15. The intention of the queries is to demonstrate the viability of DNNPAO rather than to provide definitive answers to all passable questions.
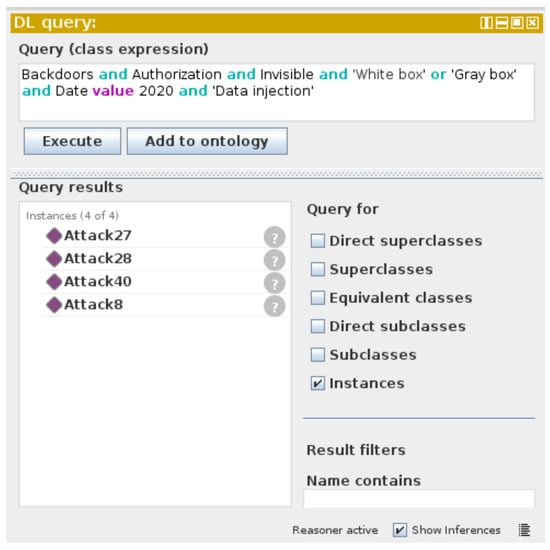
Figure 15.
Using the DL Query and the HermiT reasoner to query the DNNPAO in Protégé.
As illustrated in Figure 15 the query was carried out in Protégé by using the DL Query and the HermiT reasoner. It shows Attack8, Attack27, Attack28, and Attack40 as the results of the question of what are the invisible backdoor attacks that violate the authorization of the system and can be injected on the dataset from adversaries in white-box or gray-box scenarios. To restrict the reuse, we select the 2020 published attack; however, more complex queries can be conducted by using SPARQL or the Neo4j database [33]. Furthermore, more relevant graph exploration tools, such as SemSpect [105], can be used to represent the data from Neo4j by using a different visual interaction manner. Updating such a knowledge base with new attacks and countermeasures can result in more autonomous DNN security threat assessments.
For semantic data, comprehension queries are essential. Although an ontology in OWL format can be queried by using SQL queries such as SPARQL in Protégé, Neo4j employs a distinct query language known as Cypher, which is more suited to graph databases. In terms of performance, Neo4j might be faster compared to Protégé and can detect the patterns between nodes. However, for complex data and millions of nodes, Neo4j might not deliver high performance, especially for deleting and updating nodes. In addition, Neo4j is a single-model store that is not built to support multi-model stores. However, Neo4j is a famous graph database. A graph database such as ArangoDB might be more flexible with multi-model stores but it lacks query rules. GraphDB is also another graph database that supports SQL queries using SPARQL. Thus, there are several choices that depend on the aim of the graph database.
Our main goal in this paper is to develop an ontology of poisoning attacks against DNNs and subsequently utilize the ontology to provide a knowledge graph. We decided to use Neo4j because it is well-known and has a neosemantics tool for importing ontologies. We have a relatively small number of nodes, and therefore performance and scalability were not our main concerns. Evaluating and comparing the performance of Neo4j with other graph databases for developing ontologies or knowledge graphs is not the aim of this research. However, in the future, we intend to broaden the scope of the knowledge base of the DNN vulnerabilities and solutions and will consider the performance and scalability of the graph databases and the overall knowledge base development process.
We have provided access to the ontology on our GitHub page at [100] that a user can employ to generate interactive ontology graphs and investigate the viability of DNNPAO with additional queries.
8. Conclusions and Future Work
This paper proposed an ontology of poisoning and backdoor attacks in DNNs, called DNN poisoning attacks ontology (DNNPAO) that will enhance knowledge sharing and enable further advancements in the field. We performed a systematic review of the relevant literature to identify the current state, collected 28,469 papers and, through a rigorous process, 55 poisoning attacks in DNNs were identified and classified. We extracted a taxonomy of the poisoning attacks as a scheme to develop DNNPAO. Subsequently, we used DNNPAO as a framework to create a knowledge base.
Considering the literature, we can highlight some essential directions toward robust DNNs. As can be seen in Table 7, the CNN is the architecture of DNNs that has been attacked the most; however, that does not mean it is the most vulnerable architecture, but it is the most used architecture, especially for computer vision. In fact, the DRL and DFL might be at more risk if we consider the environment and participants as part of the training process.
Backdoor attacks and Trojans are usually based on the poisoning injections of the triggers; thus, filtering the data sets is an essential process in detecting the triggers. However, as shown in some of the attacks, triggers could be embedded in hardware, which means that scanning devices to detect these triggers are needed. In addition, triggers, if injected, might not affect the accuracy until they have been activated. Some of the attacks show that even a physical tool can be used to activate the triggers at the inference phase. Therefore, creating an effective trigger detection tool at this phase is also necessary. Such a tool should consider the invisible and multiple triggers.
Although there are growing intentions to better understand DNN security threats, only a few works deal with poisoning and backdoor attacks. Taxonomies are incapable of representing complex relationships, either between attacks and their characteristics or among other attacks. One approach to addressing this complexity is use of an ontology knowledge base. An ontology can cope with this information while enabling scalability, so that more complex information may be added. Thus in this paper, we proposed a seed ontology knowledge base. Our ontology was generated according to a taxonomic scheme that we developed on the basis of a systematic literature review. For further work, we will consider other inference phase attacks, such as adversarial example attacks, and we will add more attack characteristics. In addition, we plan to use the complete ontology to train a DNN model to detect attacks toward better robustness of DNNs. Finally, we have mentioned several applications wherein DNNs are used; some of these are developed as part of our broader work in DNNs. As part of this strand of research, we plan to explore various DNN attacks on these applications in the future. We envision that the work presented in this paper will open new directions within the field of AI security.
Author Contributions
Conceptualization, M.A. and R.M.; methodology, M.A. and R.M.; software, M.A.; validation, M.A. and R.M.; formal analysis, M.A., R.M., F.A., T.Y. and J.M.C.; investigation, M.A., R.M., F.A., T.Y. and J.M.C.; resources, R.M. and F.A.; data curation, M.A.; writing—original draft preparation, M.A.; writing—review and editing, R.M., F.A., T.Y. and J.M.C.; visualization, M.A.; supervision, R.M. and F.A.; project administration, R.M.; funding acquisition, R.M. All authors have read and agreed to the published version of the manuscript.
Funding
The authors acknowledge with thanks the technical and financial support from the Deanship of Scientific Research (DSR) at the King Abdulaziz University (KAU), Jeddah, Saudi Arabia, under Grant No. RG-11-611-38.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in this paper will be made publicly available at https://github.com/MajedCS/DNNPAO (accessed on 25 August 2022).
Acknowledgments
The work carried out in this paper is supported by the HPC Center at the King Abdulaziz University.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DNN | Deep neural networks |
| DNNPAO | DNN Poisoning Attacks Ontology |
| NLP | Natural Language Processing |
| SLR | Systematic Literature Review |
| AI | Artificial Intelligence |
| MRQs | Main Research Questions |
| SRQ | Sub Research Questions |
| S1 | Search String 1 |
| S2 | Search String 2 |
| S3 | Search String 3 |
| S4 | Search String 4 |
| S5 | Search String 5 |
| S6 | Search String 6 |
| S7 | Search String 7 |
| S8 | Search String 8 |
| S9 | Search String 9 |
| MLaaS | Machine Learning as a Service |
| NN | Neural Network |
| CIA | Confidentiality, Integrity, and Availability |
| LSB | Least Significant Bit |
| SIN2 | Stealth Infection on Neural Network |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| GAN | Generative Adversarial network |
| DCGAN | Deep Convolutional GAN |
| RL | Reinforcement Learning |
| SNN | Spiking Neural Network |
| DFL | Deep Federated Learning |
| RGB | Red, Green, and Blue |
| IDSs | Intrusion Detection Systems |
| TBT | Targeted Bit Trojan |
| OWL | Web Ontology Language |
| IoT | Internet of Things |
Appendix A. List of Individuals (Attacks) in DNNPAO



References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Mohammed, T.; Albeshri, A.; Katib, I.; Mehmood, R. DIESEL: A Novel Deep Learning-Based Tool for SpMV Computations and Solving Sparse Linear Equation Systems. J. Supercomput. 2021, 77, 6313–6355. [Google Scholar] [CrossRef]
- Aqib, M.; Mehmood, R.; Alzahrani, A.; Katib, I.; Albeshri, A.; Altowaijri, S. Rapid Transit Systems: Smarter Urban Planning Using Big Data, In-Memory Computing, Deep Learning, and GPUs. Sustainability 2019, 11, 2736. [Google Scholar] [CrossRef]
- Fathi, E.; Maleki Shoja, B. Chapter 9—Deep Neural Networks for Natural Language Processing. In Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications; Gudivada, V.N., Rao, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Volume 38, pp. 229–316. [Google Scholar] [CrossRef]
- Ahmad, I.; Alqurashi, F.; Abozinadah, E.; Mehmood, R. Deep Journalism and DeepJournal V1.0: A Data-Driven Deep Learning Approach to Discover Parameters for Transportation. Sustainability 2022, 14, 5711. [Google Scholar] [CrossRef]
- Alkhayat, G.; Mehmood, R. A review and taxonomy of wind and solar energy forecasting methods based on deep learning. Energy AI 2021, 4, 100060. [Google Scholar] [CrossRef]
- Piccialli, F.; Somma, V.D.; Giampaolo, F.; Cuomo, S.; Fortino, G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Janbi, N.; Mehmood, R.; Katib, I.; Albeshri, A.; Corchado, J.M.; Yigitcanlar, T. Imtidad: A Reference Architecture and a Case Study on Developing Distributed AI Services for Skin Disease Diagnosis over Cloud, Fog and Edge. Sensors 2022, 22, 1854. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Butler, L.; Windle, E.; Desouza, K.C.; Mehmood, R.; Corchado, J.M. Can Building “Artificially Intelligent Cities” Safeguard Humanity from Natural Disasters, Pandemics, and Other Catastrophes? An Urban Scholar’s Perspective. Sensors 2020, 20, 2988. [Google Scholar] [CrossRef]
- Alotaibi, H.; Alsolami, F.; Abozinadah, E.; Mehmood, R. TAWSEEM: A Deep-Learning-Based Tool for Estimating the Number of Unknown Contributors in DNA Profiling. Electronics 2022, 11, 548. [Google Scholar] [CrossRef]
- Pawlicki, M.; Kozik, R.; Choraś, M. A survey on neural networks for (cyber-) security and (cyber-) security of neural networks. Neurocomputing 2022, 500, 1075–1087. [Google Scholar] [CrossRef]
- Muhammed, T.; Mehmood, R.; Albeshri, A.; Katib, I. UbeHealth: A Personalized Ubiquitous Cloud and Edge-Enabled Networked Healthcare System for Smart Cities. IEEE Access 2018, 6, 32258–32285. [Google Scholar] [CrossRef]
- Mohammed, T.; Albeshri, A.; Katib, I.; Mehmood, R. UbiPriSEQ—Deep Reinforcement Learning to Manage Privacy, Security, Energy, and QoS in 5G IoT HetNets. Appl. Sci. 2020, 10, 7120. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Corchado, J.M.; Mehmood, R.; Li, R.Y.M.; Mossberger, K.; Desouza, K. Responsible urban innovation with local government artificial intelligence (Ai): A conceptual framework and research agenda. J. Open Innov. Technol. Mark. Complex. 2021, 7, 71. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Mehmood, R.; Corchado, J.M. Green Artificial Intelligence: Towards an Efficient, Sustainable and Equitable Technology for Smart Cities and Futures. Sustainability 2021, 13, 8952. [Google Scholar] [CrossRef]
- Xu, H.; Ma, Y.; Liu, H.C.; Deb, D.; Liu, H.; Tang, J.L.; Jain, A.K. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. Int. J. Autom. Comput. 2020, 17, 151–178. [Google Scholar] [CrossRef]
- Pitropakis, N.; Panaousis, E.; Giannetsos, T.; Anastasiadis, E.; Loukas, G. A taxonomy and survey of attacks against machine learning. Comput. Sci. Rev. 2019, 34, 100199. [Google Scholar] [CrossRef]
- Dang, T.K.; Truong, P.T.T.; Tran, P.T. Data Poisoning Attack on Deep Neural Network and Some Defense Methods. In Proceedings of the 2020 International Conference on Advanced Computing and Applications (ACOMP), Quy Nhon, Vietnam, 25–27 November 2020; pp. 15–22. [Google Scholar] [CrossRef]
- Jere, M.S.; Farnan, T.; Koushanfar, F. A Taxonomy of Attacks on Federated Learning. IEEE Secur. Priv. 2021, 19, 20–28. [Google Scholar] [CrossRef]
- Isakov, M.; Gadepally, V.; Gettings, K.M.; Kinsy, M.A. Survey of Attacks and Defenses on Edge-Deployed Neural Networks. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, D.; Yu, N.; Zhang, Y.; Fritz, M. GAN-Leaks: A Taxonomy of Membership Inference Attacks against Generative Models. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS ’20), Virtual, 9–13 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 343–362. [Google Scholar] [CrossRef]
- Liu, Y.; Mondal, A.; Chakraborty, A.; Zuzak, M.; Jacobsen, N.; Xing, D.; Srivastava, A. A Survey on Neural Trojans. In Proceedings of the 2020 21st International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 25–26 March 2020; pp. 33–39. [Google Scholar] [CrossRef]
- Xu, Q.; Arafin, M.T.; Qu, G. Security of Neural Networks from Hardware Perspective: A Survey and Beyond. In Proceedings of the 26th Asia and South Pacific Design Automation Conference (ASPDAC ’21), Tokyo, Japan, 21–24 January 2019; Association for Computing Machinery: New York, NY, USA, 2021; pp. 449–454. [Google Scholar] [CrossRef]
- Xue, M.; Yuan, C.; Wu, H.; Zhang, Y.; Liu, W. Machine Learning Security: Threats, Countermeasures, and Evaluations. IEEE Access 2020, 8, 74720–74742. [Google Scholar] [CrossRef]
- He, Y.; Meng, G.; Chen, K.; Hu, X.; He, J. Towards Security Threats of Deep Learning Systems: A Survey. IEEE Trans. Softw. Eng. 2022, 48, 1743–1770. [Google Scholar] [CrossRef]
- Chen, Y.; Gong, X.; Wang, Q.; Di, X.; Huang, H. Backdoor Attacks and Defenses for Deep Neural Networks in Outsourced Cloud Environments. IEEE Netw. 2020, 34, 141–147. [Google Scholar] [CrossRef]
- Miller, D.J.; Xiang, Z.; Kesidis, G. Adversarial Learning Targeting Deep Neural Network Classification: A Comprehensive Review of Defenses Against Attacks. Proc. IEEE 2020, 108, 402–433. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, P. A systematic review of systematic review process research in software engineering. Inf. Softw. Technol. 2013, 55, 2049–2075. [Google Scholar] [CrossRef]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef] [PubMed]
- van de Schoot, R.; de Bruin, J.; Schram, R.; Zahedi, P.; de Boer, J.; Weijdema, F.; Kramer, B.; Huijts, M.; Hoogerwerf, M.; Ferdinands, G.; et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat. Mach. Intell. 2021, 3, 125–133. [Google Scholar] [CrossRef]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef]
- Neo4j-Graph Data Platform. Available online: https://neo4j.com/ (accessed on 14 May 2021).
- Barrasa, J. Neosemantics—A Plugin That Enables the Use of RDF in Neo4j. Available online: https://github.com/neo4j-labs/neosemantics (accessed on 15 March 2022).
- Li, S.; Xue, M.; Zhao, B.Z.H.; Zhu, H.; Zhang, X. Invisible Backdoor Attacks on Deep Neural Networks Via Steganography and Regularization. IEEE Trans. Dependable Secur. Comput. 2021, 18, 2088–2105. [Google Scholar] [CrossRef]
- Lee, D.; Kim, H.; Ryou, J. Poisoning attack on show and tell model and defense using autoencoder in electric factory. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 538–541. [Google Scholar] [CrossRef]
- Dumford, J.; Scheirer, W. Backdooring Convolutional Neural Networks via Targeted Weight Perturbations. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September 2020–1 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S.B. Analyzing Federated Learning through an Adversarial Lens. Proc. Int. Conf. Mach. Learn. 2018, 97, 634–643. [Google Scholar]
- Zhou, X.; Xu, M.; Wu, Y.; Zheng, N. Deep Model Poisoning Attack on Federated Learning. Future Internet 2021, 13, 73. [Google Scholar] [CrossRef]
- Davaslioglu, K.; Sagduyu, Y.E. Trojan Attacks on Wireless Signal Classification with Adversarial Machine Learning. In Proceedings of the 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhong, H.; Liao, C.; Squicciarini, A.C.; Zhu, S.; Miller, D. Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation. In Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy (CODASPY ’20), New Orleans, LA, USA, 16–18 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 97–108. [Google Scholar] [CrossRef]
- Huai, M.; Sun, J.; Cai, R.; Yao, L.; Zhang, A. Malicious Attacks against Deep Reinforcement Learning Interpretations. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; ACM: New York, NY, USA, 2020; pp. 472–482. [Google Scholar] [CrossRef]
- Xue, M.; He, C.; Wang, J.; Liu, W. One-to-N & N-to-One: Two Advanced Backdoor Attacks Against Deep Learning Models. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1562–1578. [Google Scholar] [CrossRef]
- Liu, K.; Tan, B.; Karri, R.; Garg, S. Poisoning the (Data) Well in ML-Based CAD: A Case Study of Hiding Lithographic Hotspots. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 15 June 2020; pp. 306–309. [Google Scholar] [CrossRef]
- Hu, X.; Zhao, Y.; Deng, L.; Liang, L.; Zuo, P.; Ye, J.; Lin, Y.; Xie, Y. Practical Attacks on Deep Neural Networks by Memory Trojaning. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2021, 40, 1230–1243. [Google Scholar] [CrossRef]
- Lin, J.; Xu, L.; Liu, Y.; Zhang, X. Composite Backdoor Attack for Deep Neural Network by Mixing Existing Benign Features. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security; ACM: New York, NY, USA, 2020; pp. 113–131. [Google Scholar] [CrossRef]
- Dai, J.; Chen, C.; Li, Y. A Backdoor Attack Against LSTM-Based Text Classification Systems. IEEE Access 2019, 7, 138872–138878. [Google Scholar] [CrossRef]
- Zhao, S.; Ma, X.; Zheng, X.; Bailey, J.; Chen, J.; Jiang, Y.G. Clean-Label Backdoor Attacks on Video Recognition Models. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14431–14440. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, X.; Bailey, J.; Lu, F. Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12355, pp. 182–199. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, L.; Zheng, H.; Xuan, Q. SPA: Stealthy Poisoning Attack. In Proceedings of the ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2020; pp. 303–309. [Google Scholar] [CrossRef]
- Tan, T.J.L.; Shokri, R. Bypassing Backdoor Detection Algorithms in Deep Learning. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020; pp. 175–183. [Google Scholar] [CrossRef]
- Tang, R.; Du, M.; Liu, N.; Yang, F.; Hu, X. An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; ACM: New York, NY, USA, 2020; pp. 218–228. [Google Scholar] [CrossRef]
- Wu, J.; Lin, X.; Lin, Z.; Tang, Y. A security concern about deep learning models. In Science of Cyber Security. SciSec 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11287, pp. 199–206. [Google Scholar] [CrossRef]
- Barni, M.; Kallas, K.; Tondi, B. A New Backdoor Attack in CNNS by Training Set Corruption Without Label Poisoning. In Proceedings of the 2019 IEEE International Conference on Image Process, Taipei, Taiwan, 22–25 September 2019; pp. 101–105. [Google Scholar] [CrossRef]
- Xiong, Y.; Xu, F.; Zhong, S.; Li, Q. Escaping Backdoor Attack Detection of Deep Learning. In Proceedings of the IIFIP International Conference on ICT Systems Security and Privacy Protection, Maribor, Slovenia, 21–23 September 2020; Springer: Cham, Switzerland, 2020; Volume 580, pp. 431–445. [Google Scholar] [CrossRef]
- Kwon, H.; Roh, J.; Yoon, H.; Park, K.W. TargetNet Backdoor: Attack on Deep Neural Network with Use of Different Triggers. In Proceedings of the ACM Internet Conference Proceeding Series; ACM: New York, NY, USA, 2020; pp. 140–145. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, H.; Su, M.; Du, T.; Lin, C.; Ji, S. Invisible Poisoning: Highly Stealthy Targeted Poisoning Attack. In Information Security and Cryptology. Inscrypt 2019; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12020, pp. 173–198. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, L.; Zheng, H.; Wang, X.; Ming, Z. DeepPoison: Feature Transfer Based Stealthy Poisoning Attack. arXiv 2021, arXiv:2101.02562. [Google Scholar] [CrossRef]
- Xue, M.; He, C.; Wang, J.; Liu, W. Backdoors hidden in facial features: A novel invisible backdoor attack against face recognition systems. Peer-to-Peer Netw. Appl. 2021, 14, 1458–1474. [Google Scholar] [CrossRef]
- Yao, Y.; Zheng, H.; Li, H.; Zhao, B.Y. Latent backdoor attacks on deep neural networks. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; ACM: New York, NY, USA, 2019; pp. 2041–2055. [Google Scholar] [CrossRef]
- Quiring, E.; Rieck, K. Backdooring and Poisoning Neural Networks with Image-Scaling Attacks. In Proceedings of the 2020 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21–21 May 2020; pp. 41–47. [Google Scholar] [CrossRef]
- Bhalerao, A.; Kallas, K.; Tondi, B.; Barni, M. Luminance-based video backdoor attack against anti-spoofing rebroadcast detection. In Proceedings of the 2019 IEEE 21st IInternational Workshop on Multimedia Signal Processing, Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Costales, R.; Mao, C.; Norwitz, R.; Kim, B.; Yang, J. Live Trojan Attacks on Deep Neural Networks. Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 3460–3469. [Google Scholar] [CrossRef]
- Kwon, H.; Yoon, H.; Park, K.W. Multi-Targeted Backdoor: Indentifying Backdoor Attack for Multiple Deep Neural Networks. IEICE Trans. Inf. Syst. 2020, E103.D, 883–887. [Google Scholar] [CrossRef]
- Liu, Z.; Ye, J.; Hu, X.; Li, H.; Li, X.; Hu, Y. Sequence Triggered Hardware Trojan in Neural Network Accelerator. In Proceedings of the 2020 IEEE 38th VLSI Test Symposium, San Diego, CA, USA, 5–8 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Rakin, A.S.; He, Z.; Fan, D. TBT: Targeted Neural Network Attack With Bit Trojan. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13195–13204. [Google Scholar] [CrossRef]
- Liu, T.; Wen, W.; Jin, Y. SIN2: Stealth infection on neural network—A low-cost agile neural Trojan attack methodology. In Proceedings of the 2018 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), Washington, DC, USA, 30 April 2018–4 May 2018; pp. 227–230. [Google Scholar] [CrossRef]
- Zhou, Q.; Ren, Y.; Xia, T.; Yuan, L.; Chen, L. Data Poisoning Attacks on Graph Convolutional Matrix Completion. In Algorithms and Architectures for Parallel Processing; Wen, S., Zomaya, A., Yang, L.T., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 11945, pp. 427–439. [Google Scholar] [CrossRef]
- Zhu, C.; Ronny Huang, W.; Shafahi, A.; Li, H.; Taylor, G.; Studer, C.; Goldstein, T. Transferable clean-label poisoning attacks on deep neural nets. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 2019, pp. 13141–13154. [Google Scholar] [CrossRef]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Guo, W.; Tondi, B.; Barni, M. A Master Key backdoor for universal impersonation attack against DNN-based face verification. Pattern Recognit. Lett. 2021, 144, 61–67. [Google Scholar] [CrossRef]
- Clements, J.; Lao, Y. Hardware Trojan Design on Neural Networks. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security; ACM: New York, NY, USA, 2017; pp. 27–38. [Google Scholar] [CrossRef]
- Li, M.; Sun, Y.; Lu, H.; Maharjan, S.; Tian, Z. Deep Reinforcement Learning for Partially Observable Data Poisoning Attack in Crowdsensing Systems. IEEE Internet Things J. 2020, 7, 6266–6278. [Google Scholar] [CrossRef]
- Li, W.; Yu, J.; Ning, X.; Wang, P.; Wei, Q.; Wang, Y.; Yang, H. Hu-Fu: Hardware and Software Collaborative Attack Framework Against Neural Networks. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018; pp. 482–487. [Google Scholar] [CrossRef]
- Xu, J.; Wen, Y.; Yang, C.; Meng, D. An Approach for Poisoning Attacks Against RNN-Based Cyber Anomaly Detection. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 1680–1687. [Google Scholar] [CrossRef]
- Venceslai, V.; Marchisio, A.; Alouani, I.; Martina, M.; Shafique, M. NeuroAttack: Undermining Spiking Neural Networks Security through Externally Triggered Bit-Flips. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Kwon, H.; Yoon, H.; Park, K.W. Selective Poisoning Attack on Deep Neural Network to Induce Fine-Grained Recognition Error. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Sardinia, Italy, 3–5 June 2019; pp. 136–139. [Google Scholar] [CrossRef]
- Cole, D.; Newman, S.; Lin, D. A New Facial Authentication Pitfall and Remedy in Web Services. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2635–2647. [Google Scholar] [CrossRef]
- Zeng, Y.; Qiu, M.; Niu, J.; Long, Y.; Xiong, J.; Liu, M. V-PSC: A Perturbation-Based Causative Attack Against DL Classifiers’ Supply Chain in VANET. In Proceedings of the 2019 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), New York, NY, USA, 1–3 August 2019; pp. 86–91. [Google Scholar] [CrossRef]
- Pan, J. Blackbox Trojanising of Deep Learning Models: Using Non-Intrusive Network Structure and Binary Alterations. In Proceedings of the 2020 IEEE Region 10 Conference, Osaka, Japan, 16–19 November 2020; pp. 891–896. [Google Scholar] [CrossRef]
- Garofalo, G.; Rimmer, V.; hamme, T.V.; Preuveneers, D.; Joosen, W. Fishy Faces: Crafting Adversarial Images to Poison Face Authentication. In Proceedings of the 12th USENIX Workshop on Offensive Technologies (WOOT 18), Baltimore, MD, USA, 13–14 August 2018; USENIX Association: Baltimore, MD, USA, 2018. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data Poisoning Attacks Against Federated Learning Systems. In Computer Security—ESORICS 2020; Chen, L., Li, N., Liang, K., Schneider, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 480–501. [Google Scholar]
- Li, P.; Zhao, W.; Liu, Q.; Liu, X.; Yu, L. Poisoning Machine Learning Based Wireless IDSs via Stealing Learning Model. In Wireless Algorithms, Systems, and Applications; Chellappan, S., Cheng, W., Li, W., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 10874, pp. 261–273. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, J.; Wu, D.; Chen, B.; Yu, S. Poisoning Attack in Federated Learning using Generative Adversarial Nets. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing And Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 374–380. [Google Scholar] [CrossRef]
- Lovisotto, G.; Eberz, S.; Martinovic, I. Biometric Backdoors: A Poisoning Attack Against Unsupervised Template Updating. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020; pp. 184–197. [Google Scholar] [CrossRef]
- Fofanov, G.A. Problems of Neural Networks Training. In Proceedings of the 2018 19th International Conference of Young Specialists on Micro/Nanotechnologies and Electron Devices (EDM), Erlagol, Russia, 29 June–3 July 2018; pp. 6403–6405. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. Artif. Intell. Stat. 2017, 54, 1273–1282. [Google Scholar]
- Ji, Y.; Zhang, X.; Ji, S.; Luo, X.; Wang, T. Model-Reuse Attacks on Deep Learning Systems. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2019; Association for Computing Machinery: New York, NY, USA, 2018; pp. 349–363. [Google Scholar] [CrossRef]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Liu, Y.; Xie, Y.; Srivastava, A. Neural Trojans. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 45–48. [Google Scholar] [CrossRef]
- Zou, M.; Shi, Y.; Wang, C.; Li, F.; Song, W.; Wang, Y. PoTrojan: Powerful neural-level trojan designs in deep learning models. arXiv 2018, arXiv:1802.03043. [Google Scholar]
- The Apache Software Foundation (ASF). Apache JMeter. Available online: https://jmeter.apache.org (accessed on 19 October 2022).
- Altoub, M. DNNOAO-DNN Poisoning Attacks Ontology. Available online: https://github.com/MajedCS/DNNPAO (accessed on 22 October 2022).
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. CorrAUC: A Malicious Bot-IoT Traffic Detection Method in IoT Network Using Machine-Learning Techniques. IEEE Internet Things J. 2021, 8, 3242–3254. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. IoT malicious traffic identification using wrapper-based feature selection mechanisms. Comput. Secur. 2020, 94, 101863. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Sun, Y.; Du, X.; Guizani, M. Selection of effective machine learning algorithm and Bot-IoT attacks traffic identification for internet of things in smart city. Future Gener. Comput. Syst. 2020, 107, 433–442. [Google Scholar] [CrossRef]
- Albulayhi, K.; Abu Al-Haija, Q.; Alsuhibany, S.A.; Jillepalli, A.A.; Ashrafuzzaman, M.; Sheldon, F.T. IoT Intrusion Detection Using Machine Learning with a Novel High Performing Feature Selection Method. Appl. Sci. 2022, 12, 5015. [Google Scholar] [CrossRef]
- SemSpect-Scalable Graph Exploration Tool for Neo4j. Available online: https://www.semspect.de/ (accessed on 20 July 2022).















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).