
Fault Diagnosis Algorithm of Beam Pumping Unit Based on Transfer Learning and DenseNet Model

Abstract
:1. Preface
2. Fault Diagnosis Model and Application Method
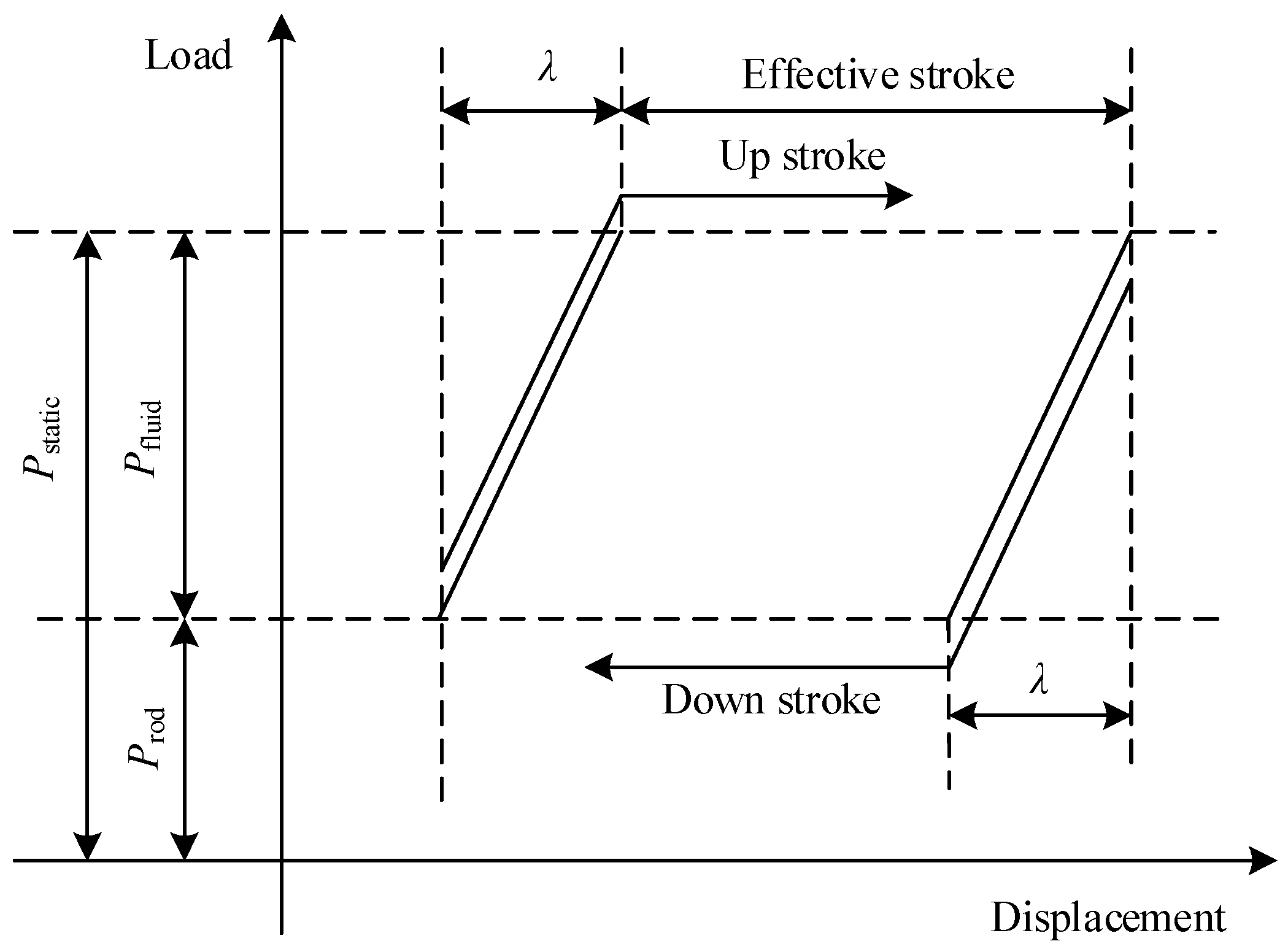
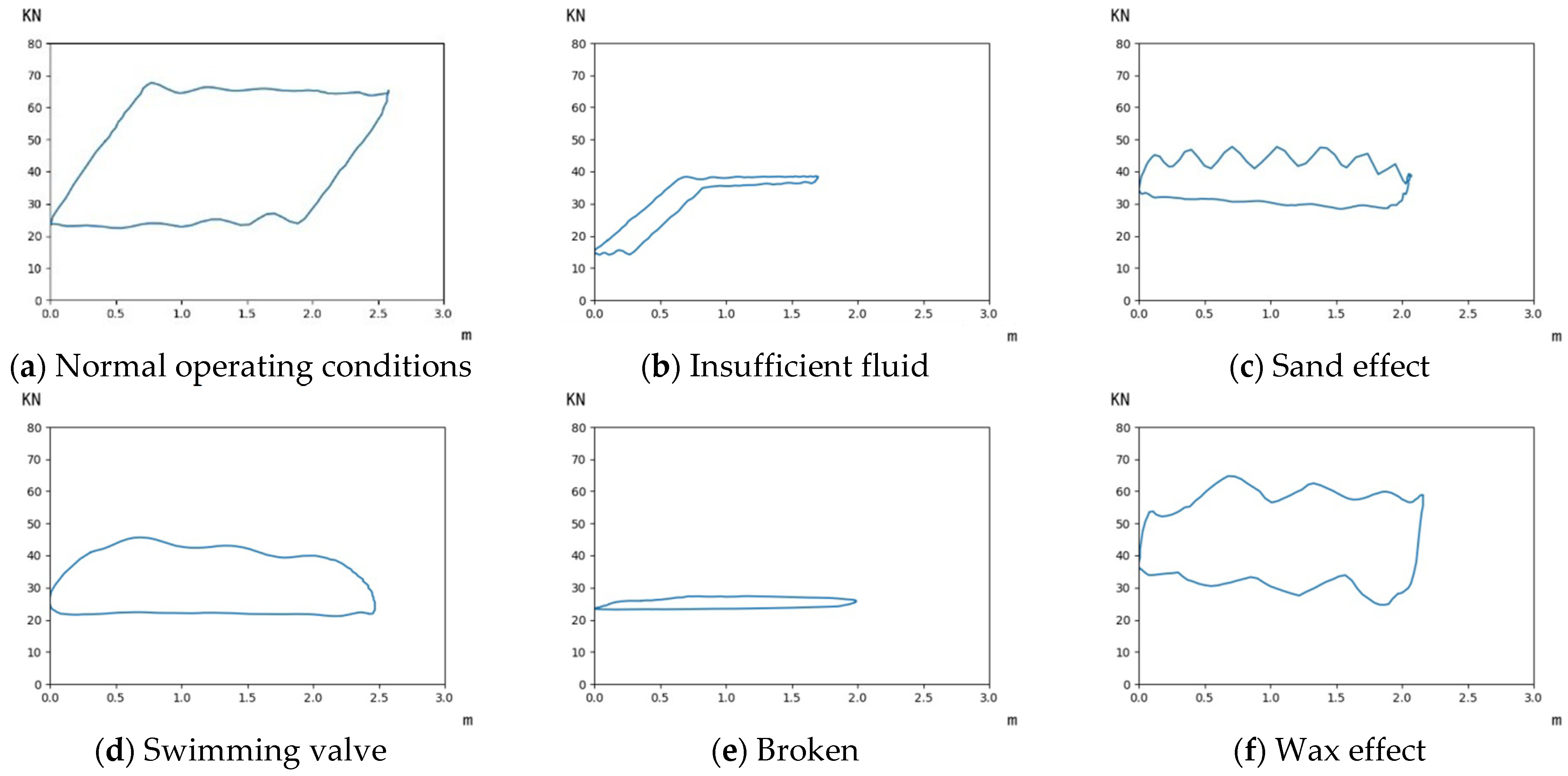
2.1. Sucker Rod Pump Fault Diagnosis
2.2. Fault Diagnosis Model
2.2.1. Convolutional Neural Network and Transfer Learning
- S—characteristic coefficient;
- X—input matrix;
- W—convolution kernel matrix;
- (i, j)—the position of the variable in the feature matrix;
- (m, n)—the position of the convolution kernel element.
- —step length;
- A—output value;
- f—size of pooling layer;
- p—optional coefficient, when p = 1, the value of A(i, j) is denoted as L1(A), called mean pooling; when p = ∞, the value of A(i, j) is denoted as L∞(A), called maximum pooling;
- —the random parameter is determined by the actual operation;
- k value—calculated channel position;
- l—calculate channel position.
- Feature transfer can improve the generalization performance of the model, even when the target dataset is very large.
- When the parameters are fixed and the number of layers increases, the transfer accuracy between two tasks with low similarity increases faster than that between two tasks with high similarity. The greater the difference between the two datasets, the worse the effect of feature transfer.
- Migration is better than using random parameters in any task.
- Initializing the network with migration parameters can still improve the generalization performance, even if the target task has been heavily tuned.
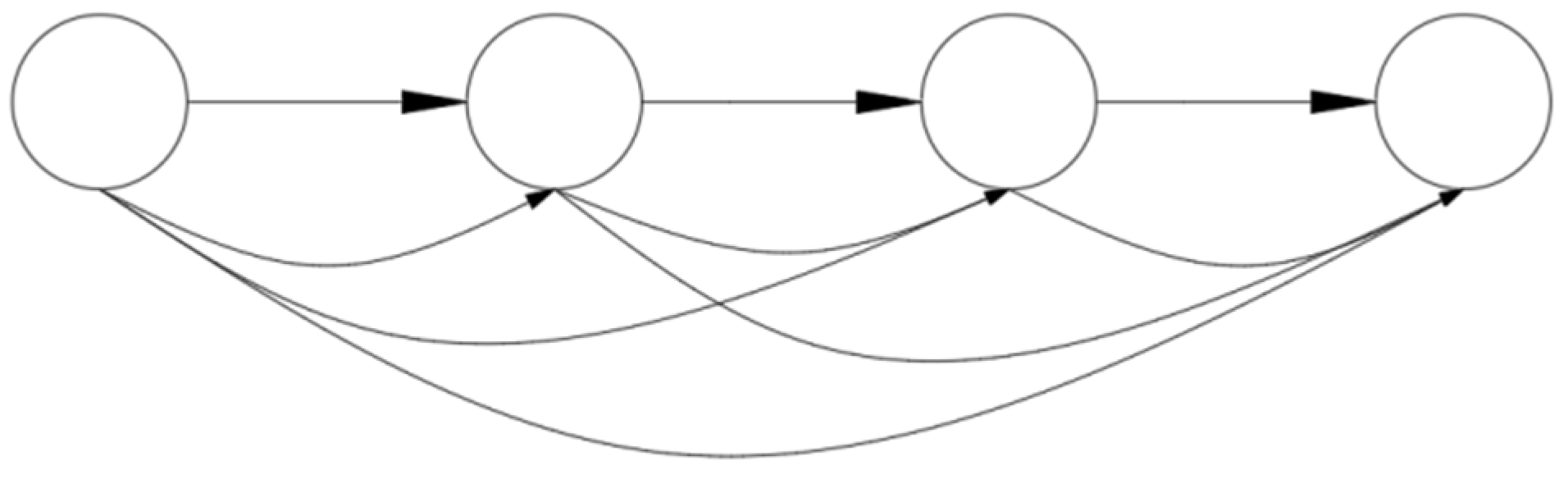
2.2.2. Neural Network Framework
3. Dynamometer Classification Model Based on the Transfer Learning Method
3.1. Data Preprocessing
- —Represents the pixel value of i th pixel of the sample after normalization;
- —The i th pixel value of the sample, the purpose is to classify all pixels as [−1, 1].
3.2. Transfer Learning Model Based on DenseNet
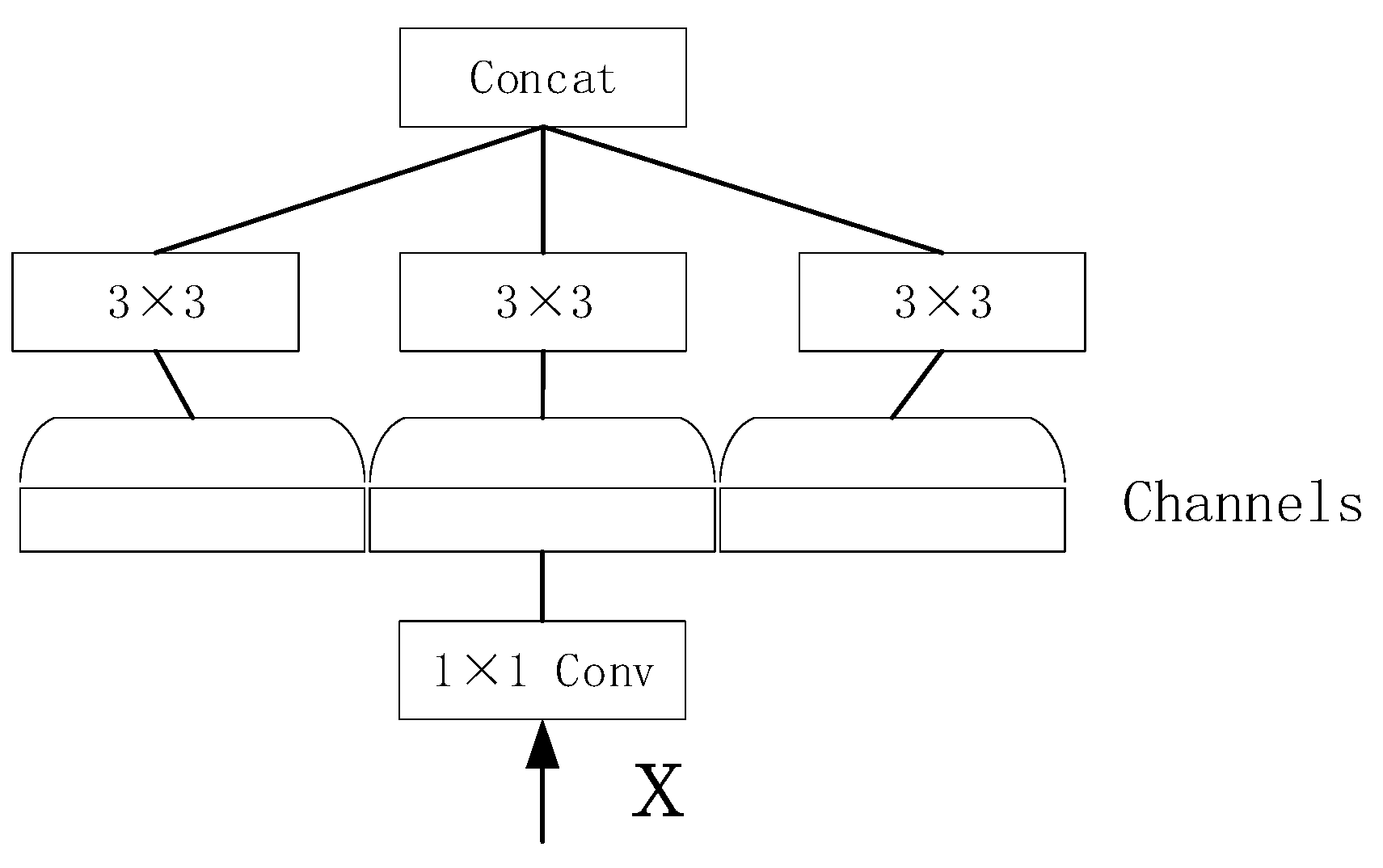
3.2.1. DenseNet Model Structure
- —Input parameters for each layer;
- —is a compound function composed of Batch Normalization (BN), activation function (ReLU), pooling function, and convolution layer (Conv).
- Bernoulli function—r generates a vector r with Bernoulli distribution;
- —the output value of the l-th layer;
- —the weighted value of the neural network of the l + 1 th layer;
- —the offset value;
- —determined by the number of neurons in the fully connected layer.
- l—the amount of loss;
- K—the number of classifications;
- —the actual label, ;
- —the predicted label, .
3.2.2. Model Training Mechanism
- and —the first-order momentum and second-order momentum;
- and —usually take 0.9 and 0.999 for the power value;
- —the parameters of the model in the t-th iteration;
- —the gradient value of the loss function with respect to the parameter W in the t-th iteration;
- —The minimal constant (usually takes its value to the 10−8 to avoid a zero denominator);
- —the initial learning rate.
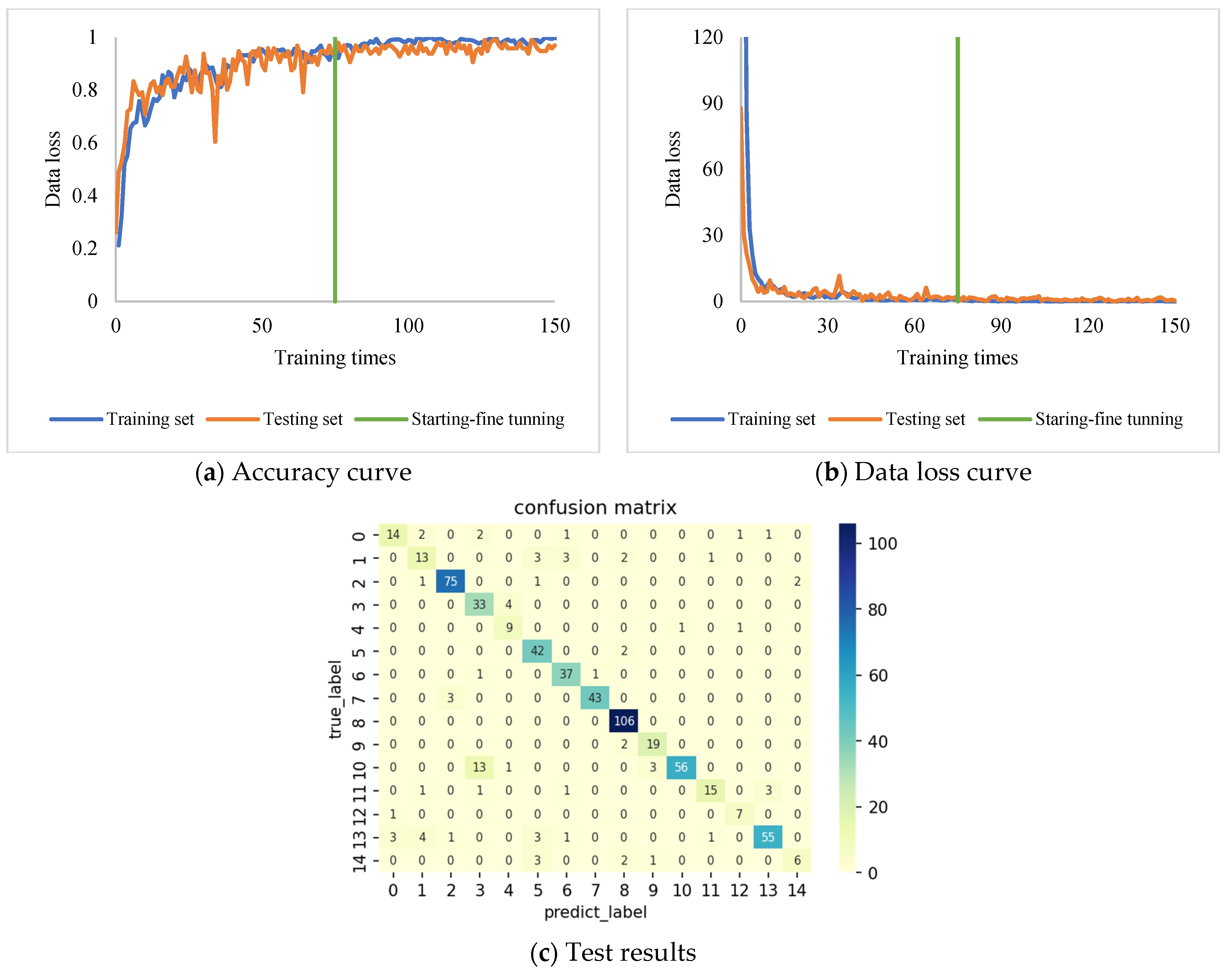
3.3. Training Results and Discussion
3.3.1. Training Results Based on Transfer Learning
3.3.2. Comparative Experiments of Different Depth Convolutional Network Models
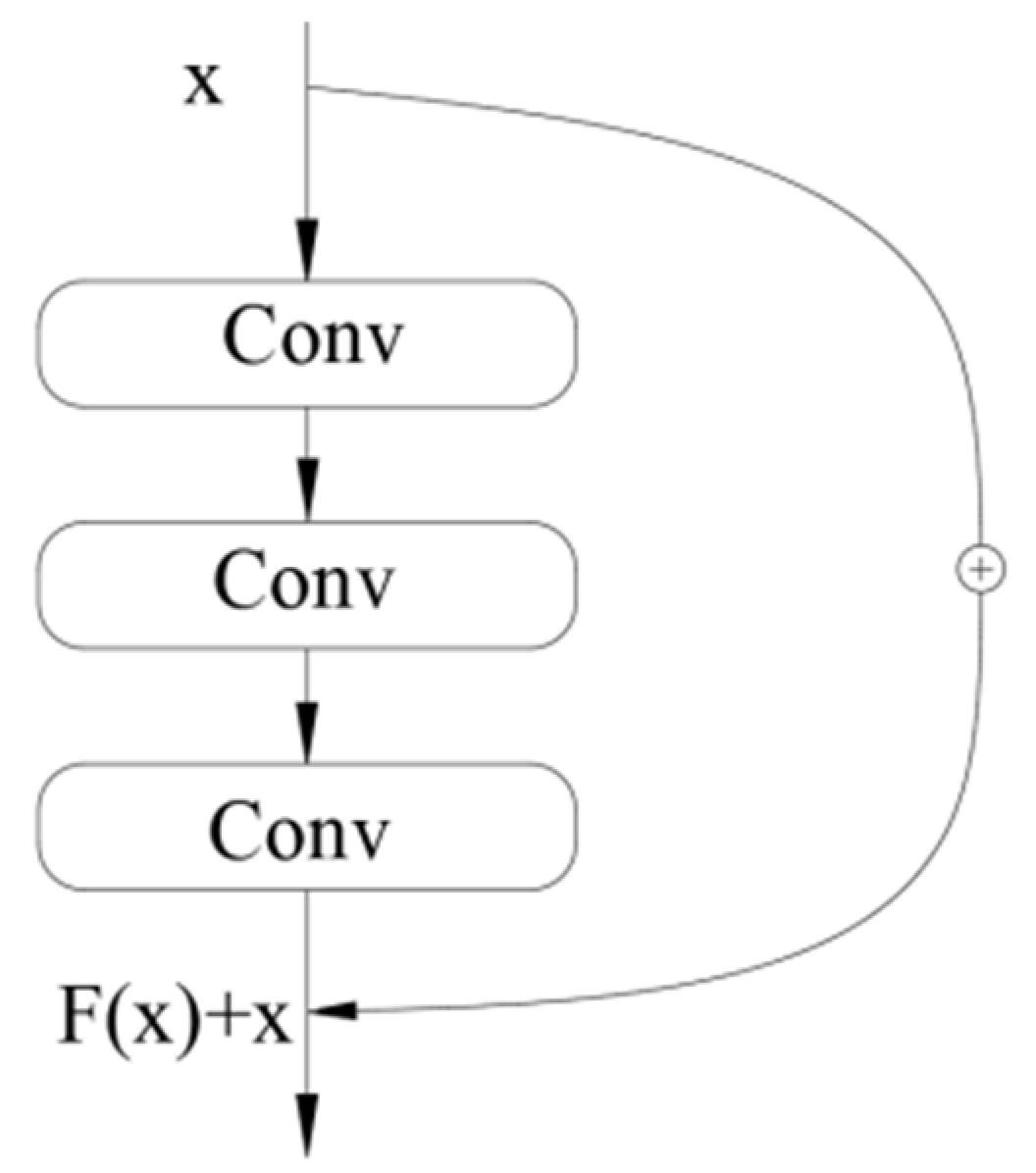
- —the output of the residual block;
- —input feature vector for the lth layer;
- —the mapping function that needs to be learned;
- —the projection matrix.
4. Conclusions
- The DenseNet model is an image classification model with the characteristics of parameter reuse, which can effectively use limited training images to obtain feature information. In this paper, based on the DenseNet model, an indicator diagram classification model is established employing transfer learning, good classification results are obtained, and the accuracy rate of the test set can reach 96.9%.
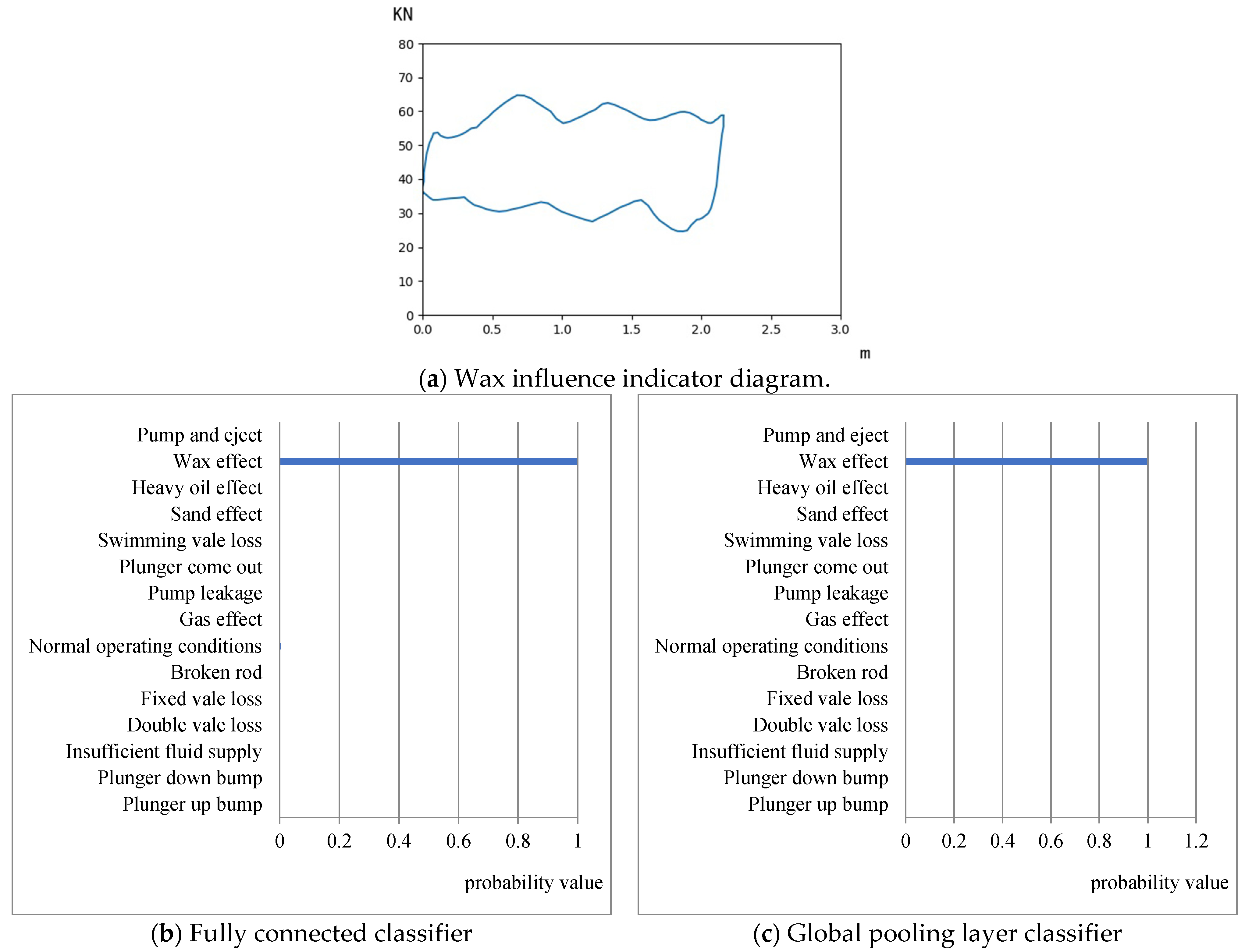
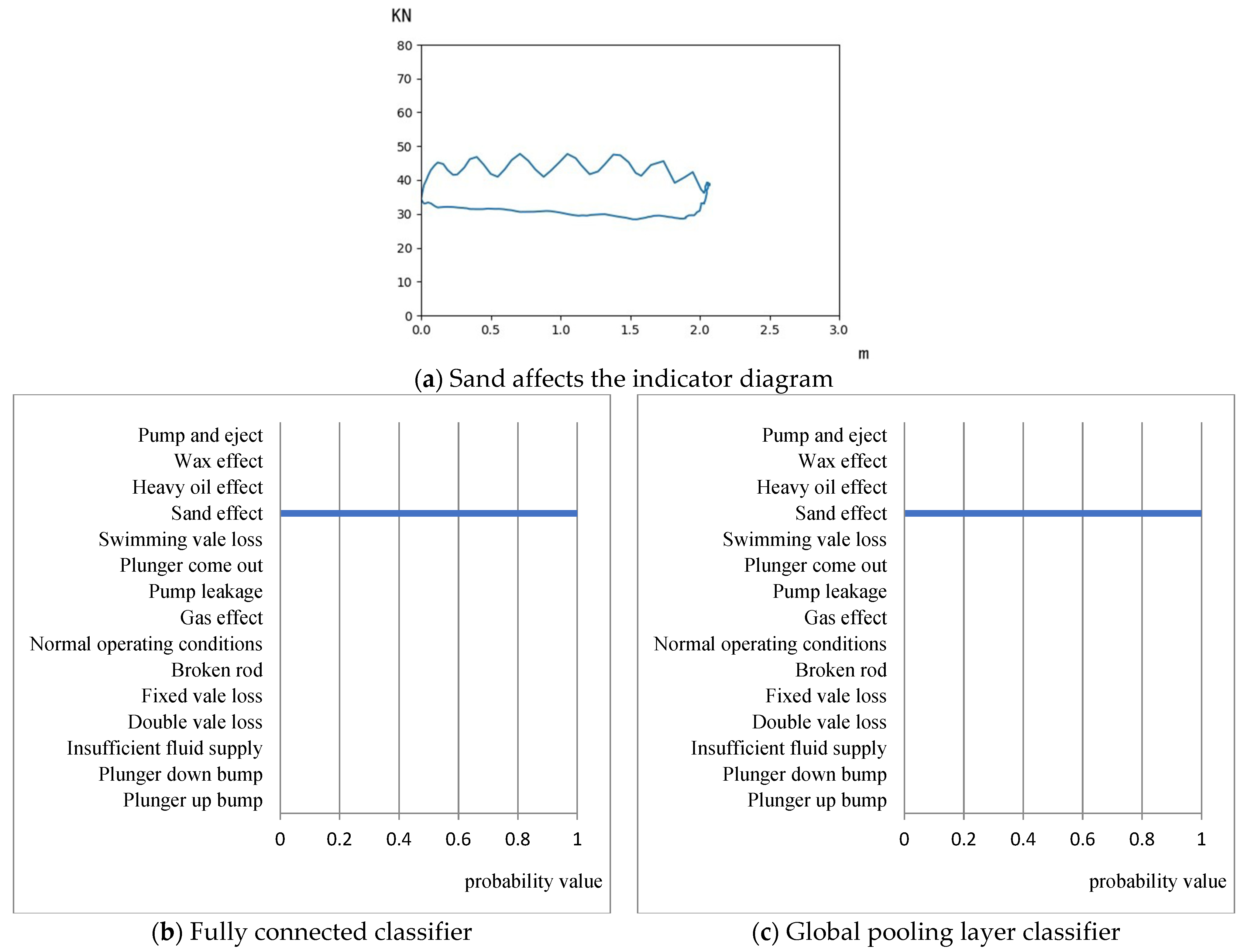
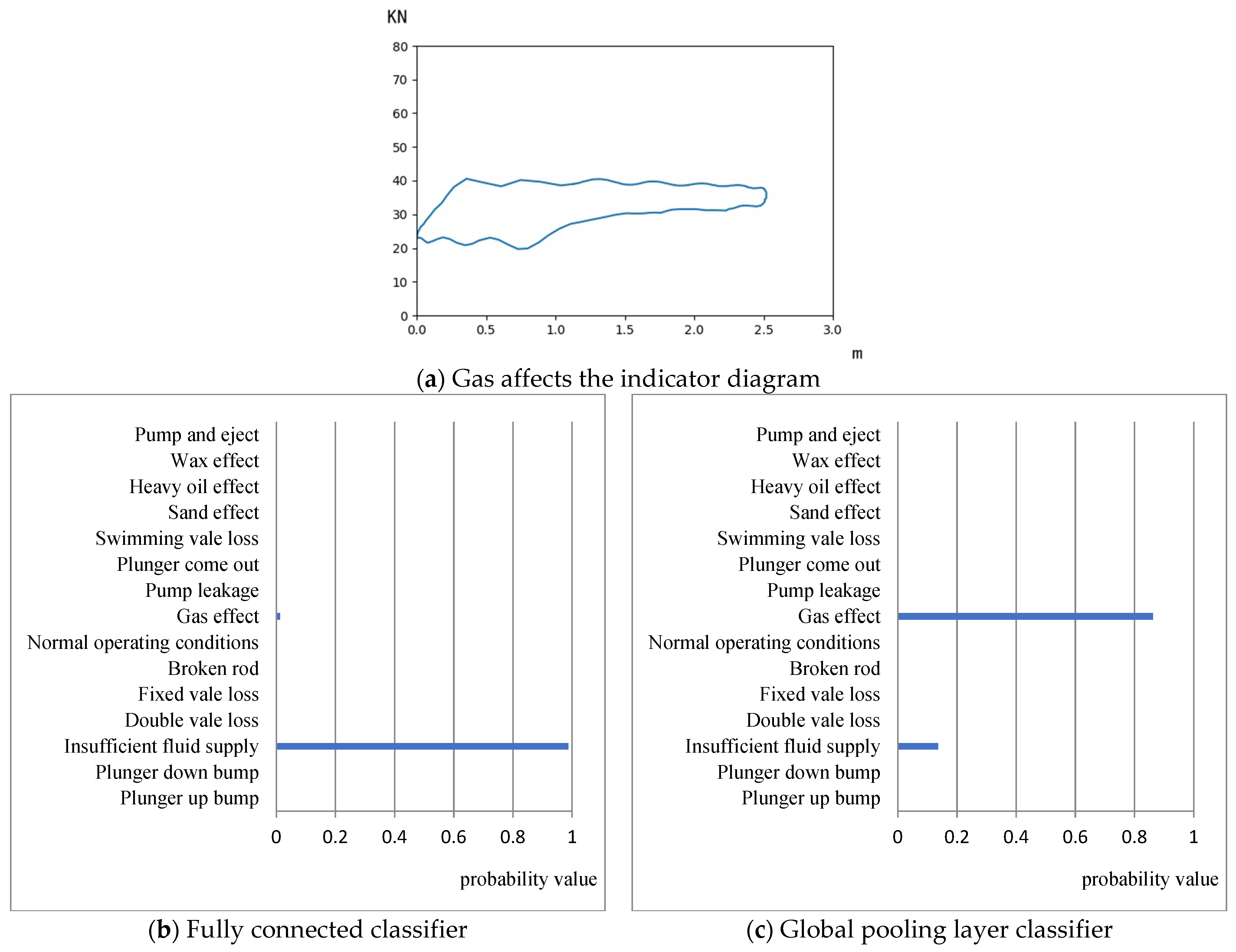
- The full connection classifier and the global pooling classifier are used to build the classification model, respectively. The results of the two types of models under the same training mechanism and using the same data set for transfer learning show that the classification effect of the global pooling classification model is better than that of the full connection. The layer classification model can be well adapted to the classification task of the indicator diagram, and the recognition rate of various working conditions generally reaches more than 90%. Among them, the recognition rate of double valve loss and pump and eject reached 100%, the lowest recognition rate was 87%, under the influence of heavy oil, and the average recognition rate of 15 types of operating conditions was 95.8%, far exceeding the control group
- The training results of the transfer learning classification model based on DenseNet show that the parameter reuse structure and transfer learning method can improve the overfitting problem of small data sets in machine learning models. The difference between the average accuracy of the training set and the test set of the DenseNet transfer learning classification model in the flat interval is only 2.7%, which can avoid the problem of a small number of samples falling in classification due to uneven data. The recognition rates of the ResNet, MobileNet, and Xception models for plunger-up bump conditions are all below 30%. The MobileNet model has a recognition rate of only 4.3% for plunger bump, while the DenseNet-based transfer learning classification model has a recognition rate of 91.3% for plunger bump.
- The comparison of the recognition model shows that the overall accuracy rate of the data set is basically the same as that of the DenseNet-based transfer learning model compared with ResNet, MobileNet, and Xception. However, compared with the control group model, the accuracy of a single type, such as plunger up bump, plunger down bump, and heavy oil effect, has been significantly improved, and the number of classifications can be further explored.
- The fault diagnosis model of the pumping unit based on the DenseNet model and transfer learning can solve the problem that the automatic fault technology based on the machine learning algorithm cannot recognize all kinds of working conditions due to insufficient production data and uneven quantity of all kinds of data. The model expands the number of identifiable working conditions and can better adapt to the actual working conditions, further supplementing the theory and technology of fault diagnosis for pumping wells.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Derek, H.J.; Jennings, J.W.; Morgan, S.M. Sucker Rod Pumping Unit Diagnostics Using an Expert System. In Proceedings of the Permian Basin Oil and Gas Recovery Conference, Midland, TX, USA, 10–11 March 1988. [Google Scholar] [CrossRef]
- Rogers, J.D.; Guffey, C.G.; Oldham, W.J.B. Artificial Neural Networks for Identification of Beam Pump Dynamometer Load Cards. In Proceedings of the SPE Annual Technical Conference and Exhibition, New Orleans, LA, USA, 23–26 September 1990. [Google Scholar] [CrossRef]
- Nazi, G.M. Application of Neural Artificial Network to Pump Card Diagnosis. SPE Comput. Appl. 1994, 10, 9–14. [Google Scholar] [CrossRef]
- Wen, B.L.; Wang, Z.Q.; Jin, Z.Z.; Xu, M.; Shi, Z. Diagnosis of Pumping Unit with Combing Indicator Diagram with Fuzzy Neural Networks. Comput. Syst. Appl. 2016, 25, 121–125. [Google Scholar]
- Rauber, T.W.; Boldt, F.A.; Varejão, F.M. Heterogeneous feature models and feature selection applied to bearing fault diagnosis. IEEE Trans. Ind. Electron. 2014, 62, 637–646. [Google Scholar] [CrossRef]
- Chine, W.; Mellit, A.; Lughi, V.; Malek, A.; Sulligoi, G.; Massi Pavan, A. A novel fault diagnosis technique for photovoltaic systems based on artificial neural networks. Renew. Energy 2016, 90, 501–512. [Google Scholar] [CrossRef]
- Dumidu, W.; Ondrej, L.; Milos, M.; Craig, R. FN-DFE: Fuzzy-neural data fusion engine for enhanced resilient state-awareness of hybrid energy systems. IEEE Trans. Cybern. 2014, 44, 2065–2075. [Google Scholar] [CrossRef]
- Chen, H.P.; Hu, N.Q.; Cheng, Z.; Zhang, L.; Zhang, Y. A deep convolutional neural network based fusion method of two-direction vibration signal data for health state identification of planetary gearboxes. Measurement 2019, 146, 268–278. [Google Scholar] [CrossRef]
- Olivier, J.; Viktor, S.; Bram, V.; Kurt, S.; Mia, L.; Steven, V.; Rik, V.W.; Sofie, V.H. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, J.; Gao, P. A deep learning approach for condition-based monitoring and fault diagnosis of rod pump system. Serv. Trans. Internet Things 2017, 1, 32–42. [Google Scholar] [CrossRef]
- Wang, X.; He, Y.F.; Li, F.J.; Dou, X.J.; Wang, Z.; Xu, H.; Fu, L.P. A Working Condition Diagnosis Model of Sucker Rod Pumping Wells Based on Big Data Deep Learning. In Proceedings of the International Petroleum Technology Conference, Beijing, China, 26–28 March 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Cheng, H.; Yu, H.; Zeng, P.; Osipov, E.; Li, S.; Vyatkin, V. Automatic Recognition of Sucker-Rod Pumping System Working Conditions Using Dynamometer Cards with Transfer Learning and SVM. Sensors 2020, 20, 5659. [Google Scholar] [CrossRef] [PubMed]
- Mao, W.T.; He, L.; Yan, Y.J.; Wang, J.W. Online sequential prediction of bearings imbalanced fault diagnosis by extreme learning machine. Mech. Syst. Signal Process. 2017, 83, 450–473. [Google Scholar] [CrossRef]
- Bengio, G.L.; Courville, Y. A Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1, pp. 326–366. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Yu, D.J.; Wang, H.L.; Chen, P.Q.; Wei, Z.H. Mixed pooling for convolutional neural networks. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Shanghai, China, 24–26 October 2014; Springer: Cham, Switzerland, 2014; pp. 364–375. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.; Kilian, Q.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Adam, B.J. A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
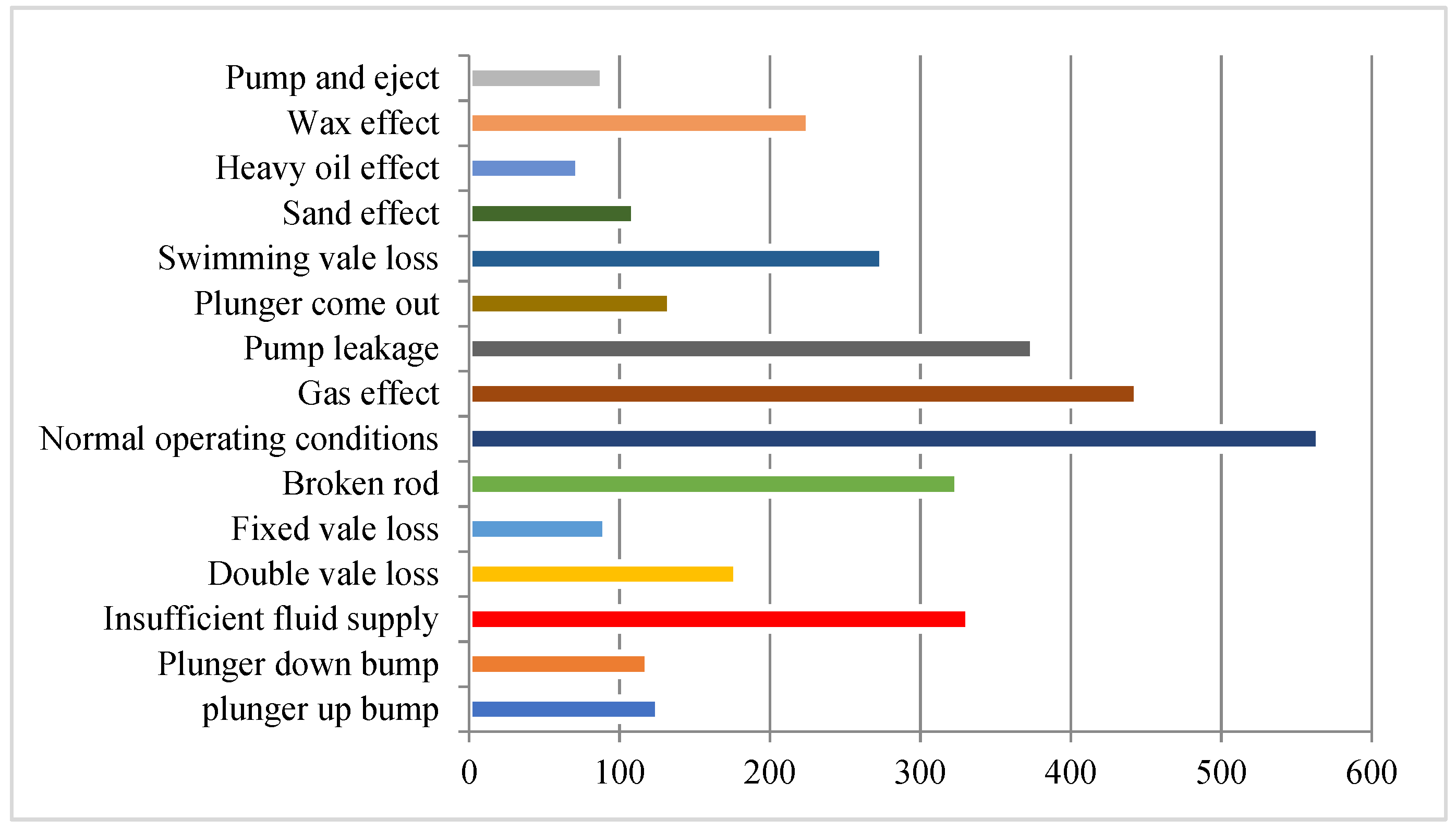
| Fault Type | Index | Number |
|---|---|---|
| Plunger up bump | 0 | 126 |
| Plunger down bump | 1 | 119 |
| Insufficient fluid supply | 2 | 332 |
| Double valve loss | 3 | 178 |
| Fixed valve loss | 4 | 91 |
| Broken rod | 5 | 325 |
| Normal operating conditions | 6 | 565 |
| Gas effect | 7 | 444 |
| Pump leakage | 8 | 375 |
| Plunger come out | 9 | 134 |
| Swimming valve loss | 10 | 275 |
| Sand effect | 11 | 110 |
| Heavy oil effect | 12 | 73 |
| Wax effect | 13 | 226 |
| Pump and eject | 14 | 89 |
| Fault Type | Recognition Rate | |
|---|---|---|
| Fully Connected Layer | Global Pooling Layer | |
| plunger up bump | 66.0% | 91.3% |
| plunger down bump | 59.1% | 90.9% |
| insufficient fluid supply | 94.9% | 97.5% |
| double valve loss | 62.9% | 100.0% |
| fixed valve loss | 81.8% | 90.9% |
| broken rod | 95.5% | 97.7% |
| normal operating conditions | 94.9% | 100.0% |
| gas effect | 93.5% | 97.8% |
| pump leakage | 100.0% | 99.1% |
| plunger come out | 90.5% | 100.0% |
| swimming valve loss | 76.7% | 98.6% |
| sand effect | 71.4% | 90.5% |
| heavy oil effect | 87.5% | 87.5% |
| wax effect | 80.9% | 95.6% |
| pump and eject | 50.0% | 100.0% |
| training set accuracy | 99.6% | 100.0% |
| test set accuracy | 96.9% | 96.9% |
| Fault Type | Recognition Rate | |||
|---|---|---|---|---|
| ResNet | MobileNet | Xception | DenseNet | |
| plunger up bump | 8.6% | 4.3% | 21.7% | 91.3% |
| plunger down bump | 22.7% | 54.5% | 45.5% | 90.9% |
| insufficient fluid supply | 86.6% | 75.9% | 67.1% | 97.5% |
| double vale loss | 89.1% | 48.6% | 48.6% | 100.0% |
| fixed vale loss | 0% | 18.2% | 45.5% | 90.9% |
| broken rod | 95.4% | 77.3% | 100.0% | 97.7% |
| normal operating conditions | 100% | 46.2% | 84.6% | 100.0% |
| gas effect | 97.8% | 41.3% | 91.3% | 97.8% |
| pump leakage | 86.9% | 94.3% | 47.2% | 99.1% |
| plunger come out | 0% | 28.6% | 23.8% | 100.0% |
| swimming vale loss | 80.8% | 47.9% | 54.8% | 98.6% |
| sand effect | 19% | 95.2% | 71.4% | 90.5% |
| heavy oil effect | 0% | 12.5% | 62.5% | 87.5% |
| wax effect | 91.1% | 97.1% | 58.8% | 95.6% |
| pump and eject | 0% | 16.7% | 66.7% | 100.0% |
| Training set | 100.0% | 99.3% | 98.6% | 99.8% |
| Testing set | 95.3% | 97.4% | 95.3% | 96.9% |
| Average recognition rate | 51.8% | 50.5% | 59.3% | 95.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Feng, Z.; Liang, J.; Liu, Q.; Sun, D. Fault Diagnosis Algorithm of Beam Pumping Unit Based on Transfer Learning and DenseNet Model. Appl. Sci. 2022, 12, 11091. https://doi.org/10.3390/app122111091
Wu Y, Feng Z, Liang J, Liu Q, Sun D. Fault Diagnosis Algorithm of Beam Pumping Unit Based on Transfer Learning and DenseNet Model. Applied Sciences. 2022; 12(21):11091. https://doi.org/10.3390/app122111091
Chicago/Turabian StyleWu, Yu, Ziming Feng, Jing Liang, Qichen Liu, and Deqing Sun. 2022. "Fault Diagnosis Algorithm of Beam Pumping Unit Based on Transfer Learning and DenseNet Model" Applied Sciences 12, no. 21: 11091. https://doi.org/10.3390/app122111091