1. Motivation and Introduction
In recent times, the construction of bounded distributions has grown tremendously. The unit distributions are necessary for modelling proportions, scores, rates, indices, etc. The benefit of these bounded distributions is that they allow the basic distribution to be more flexible throughout the unit interval without introducing new parameters. The well-known beta distribution is perhaps the first model that was employed for data observed in the interval (0, 1). Besides this, Kumaraswamy’s distribution (Kumaraswamy [
1]) and the Topp–Leone distribution (Topp and Leone [
2]) deserve attention.
Recently, several notable models have been presented as alternatives to the beta and Kumaraswamy distributions in order to improve modelling flexibility using appropriately transformed methods. The transformation of the well-known continuous distributions has frequently been used to present the newly suggested unit distributions. The transformations of the form
and
are popularly used when
X is a positive-valued random variable. Several probability distributions have been developed in this area for dealing with restricted datasets in various domains using the previous transformation. Among the most notable distributions are: unit gamma (Grassia [
3] and Tadikamalla [
4]), unit logistic (Tadikamalla and Johnson [
5] and Menezes et al. [
6]), unit Birnbaum–Saunders (Mazucheli et al. [
7]), unit Weibull (Mazucheli et al. [
8,
9]), unit inverse Gaussian (Ghitany et al. [
10]), unit Gompertz (Mazucheli et al. [
11]), unit Lindley (Mazucheli et al. [
12]), unit generalized half-normal (Korkmaz [
13]), unit modified Burr-III (Haq et al. [
14]), unit Burr-XII (UBXII) (Korkmaz and Chesneau [
15]), unit gamma/Gompertz (Bantan et al. [
16]), unit log-logistic (Ribeiro-Reis [
17]), and unit generalized log Burr XII (UGLBXII) (Bhatti et al. [
18]). In addition to the preceding transformations, Cancho et al. [
19] and Rodrigues et al. [
20] developed a broad strategy based on the cumulative distribution function (CDF)-quantile function (QF).
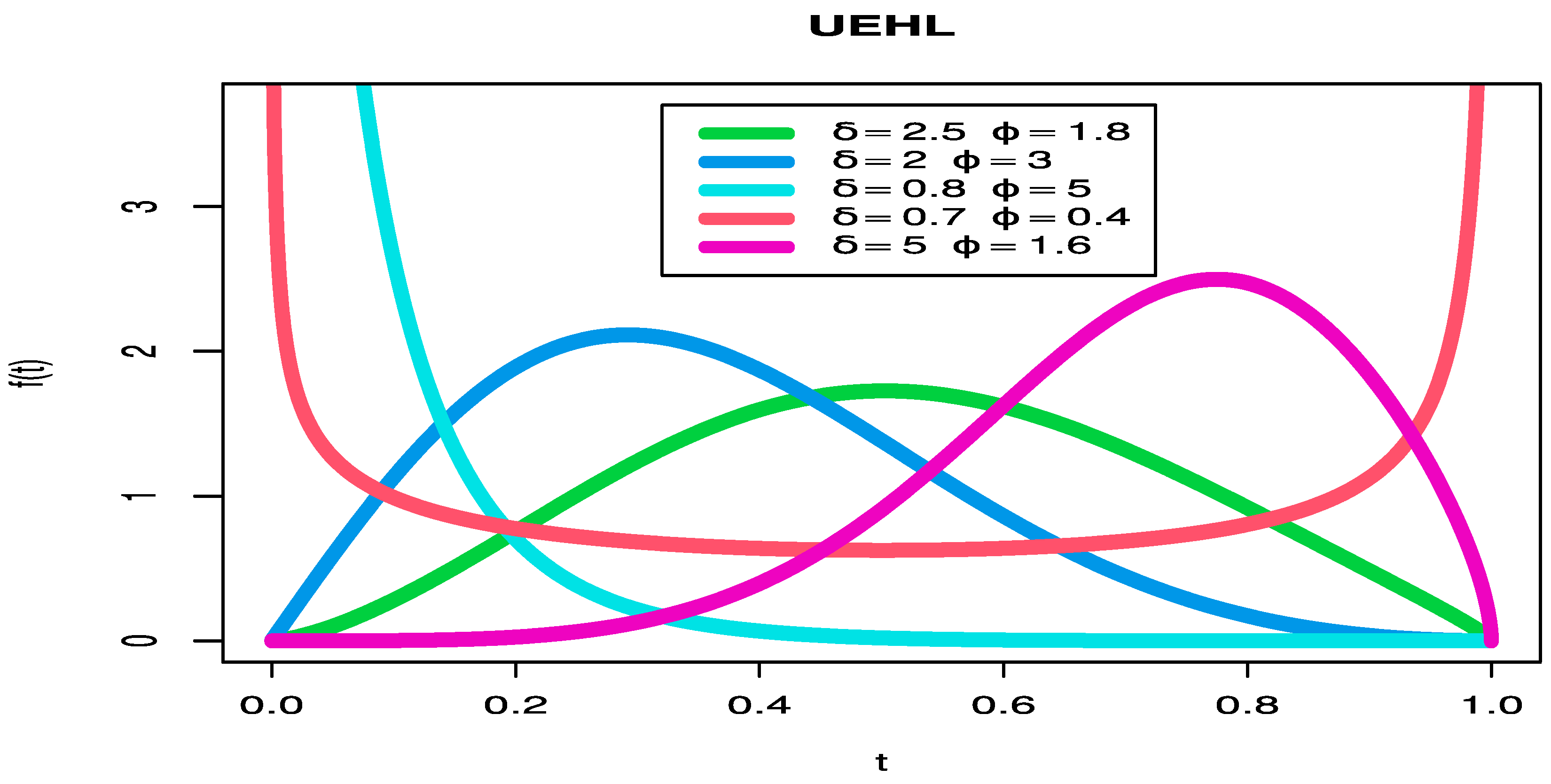
In a wide range of academic and professional fields, lifetime modeling and analysis are essential components of statistical work. A complete explanation of an event that only happens once in a lifetime typically follows a thorough data analysis based on a carefully chosen statistical model. The development of new probability distributions was necessary as a result of several attempts to construct models with different features. Lifetime distributions, a crucial statistical technique, can be used to model the numerous properties of lifetime datasets. These datasets can be analyzed using rather complicated distributions found in the statistical literature. One of the most-significant lifetime models is the exponentiated half-logistic distribution (EHLD). It has a number of characteristics that make it a viable alternative to well-known distributions, and at the same time, it has the ability to model various real datasets. It has been used in a variety of fields, including insurance, engineering, medical, and education. The probability density function (PDF) and CDF of the EHLD are represented by:
where
and
are the scale and shape parameters, respectively. PDF (1) gives the half-logistic distribution (HLD) for
. The EHLD has recently caught the interest of a large number of academics. The parameters and reliability estimators of the EHLD utilizing the maximum likelihood (ML) and Bayesian techniques were examined using a progressive censoring scheme [
21,
22,
23]. Cordeiro et al. [
24] enhanced the EHLD by proposing the notion of the EHLD as a generator to produce the family of continuous distributions with the goal of making the distributions more practical. Seo and Kang [
25] examined the moment and ML estimators of the EHLD parameters. EHLD’s ML, inverse moment, and modified inverse moment estimators, as well as the joint confidence regions were investigated by Gui [
26]. Naidu et al. [
27] created a reliability test strategy for the EHLD. Jeon and Kang [
28] used multiple Type-I hybrid censoring to look at estimators of the EHLD parameters. Adaptive progressive censoring was used by Xiong and Gui [
29] to investigate the parameter estimators of the EHLD.
The goal of this essay is to construct a new probability, called the unit-EHLD (UEHLD) by using transformation T = e−Y, where Y is the EHLD. We were motivated to propose the UEHLD due to the following:
- (i)
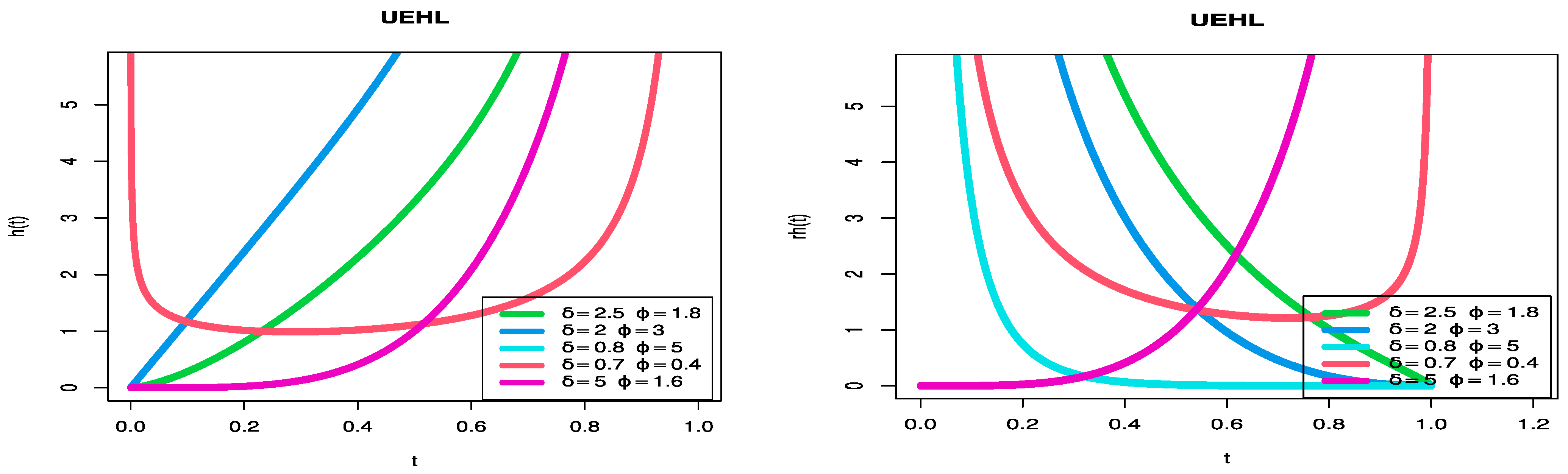
To create various forms for the hazard rate function (HRF) and PDF.
- (ii)
With a range of 0 to 1, the UEHLD is versatile and may be used to describe a variety of datasets. It can be seen as a useful model for fitting skewed data that might not be effectively fit by other popular distributions.
- (iii)
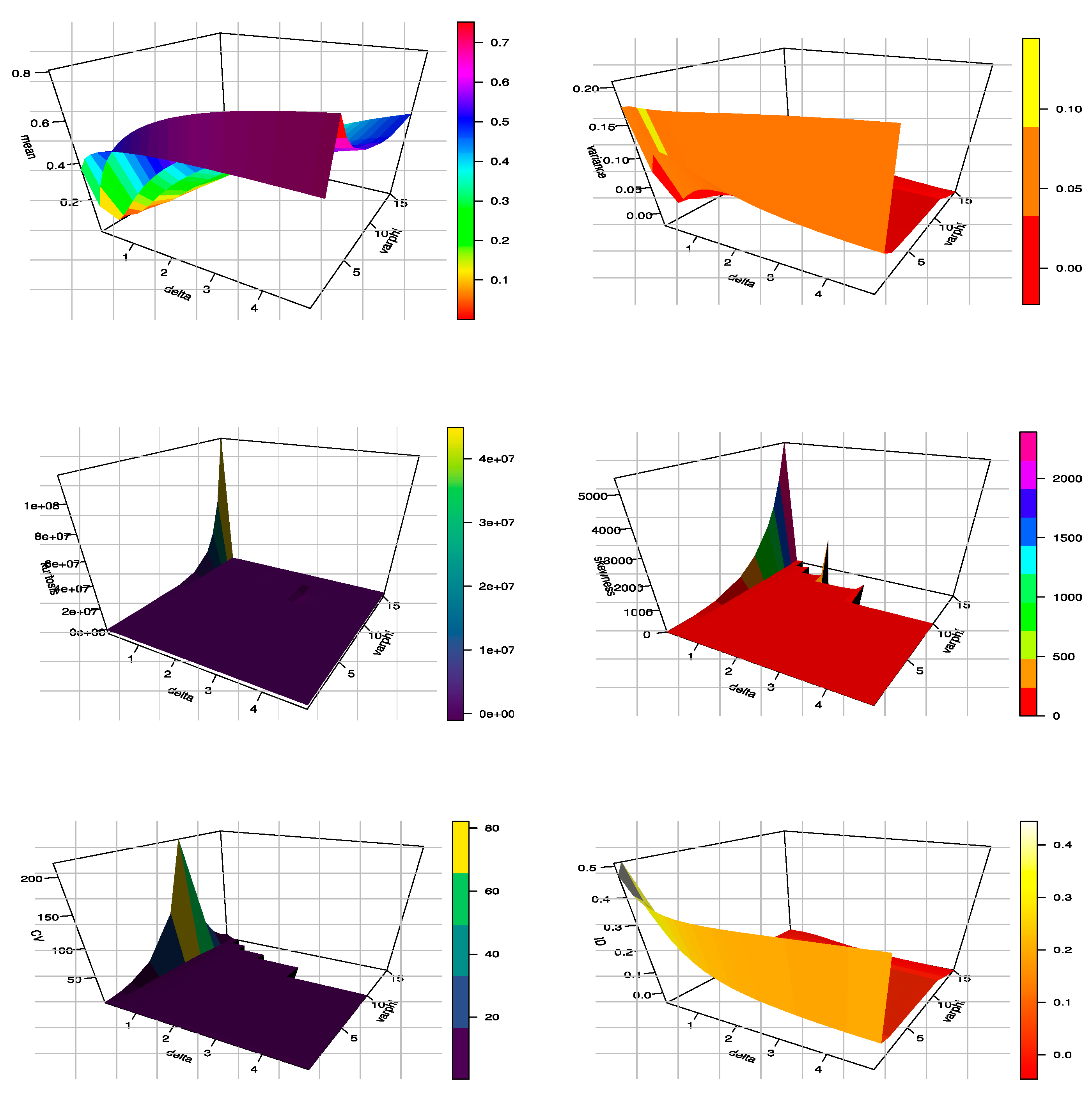
To give a comprehensive comparison of three approaches for estimating the UEHLD parameters, as well as an examination of the performance of such estimators for various parameter values and sample sizes. Our investigations were limited to the ML, maximum product of spacing (MPS), and Bayesian methods. It is difficult to theoretically examine the behaviors of different estimating approaches; thus, we carried out extensive simulation studies to evaluate the behaviors of different estimators with the bias, mean-squared error (MSE), and length of the confidence interval (CI) criteria.
- (iv)
To describe some practical uses in many disciplines, such as economic growth data, tensile strength data, and COVID-19 data.
This article’s structure is as follows: In
Section 2, we develop a brand-new model known as the UEHLD. Some moments’ measures are deduced in
Section 3. The stress–strength model and some information measures are described in
Section 4.
Section 5 discusses a few of the various techniques for estimating the model parameters.
Section 6 carries out a numerical investigation using Monte Carlo simulations.
Section 7 conducts a numerical examination of real datasets, and
Section 8 gives the findings.
7. Real Data Applications
We used the traditional value of criteria (VC) to compare the fit models, such as the Akaike information criterion (AIVC), consistent AIVC (CAIVC), Bayesian information criterion (BIVC), Hannan–Quinn information criterion (HQIVC), Anderson–Darling value (ADV), Cramer–von Mises value (CMV), Kolmogorov–Smirnov distance (KSD),
p-value of Kolmogorov–Smirnov (PKS), and standard error (SE). Our primary statistical goal was to use a fitting approach model to examine three real datasets that are significant in different fields. In this respect, we compared the fit of the proposed UEHLD with that of the unit Weibull (UW), the Kumaraswamy (K), beta (Beta), Kumaraswamy–Kumaraswamy (KK) (El-Sherpieny and Ahmed [
33]), Marshall–Olkin–Kumaraswamy (MOK) (George and Thobias [
34]), UBXII, and UGLBXII distributions.
The effectiveness of the parameter estimator for the UEHLD for the three datasets under consideration was also assessed using the ML, MPS, and Bayesian techniques via the standard error and confidence interval length criteria measures. We obtained the estimators of the new model for three techniques for the datasets under consideration, with the exception of the first dataset, for which the MPS approach was not employed because it has more equal values. For further clarification, the log-likelihood of the suggested model is supplied, along with examples of the contour plots with various parameter values. We also provide plots of the posterior distributions of the parameters, as well as histograms for the marginal posterior density estimates for three datasets.
Dataset I: The trade share dataset takes into account the values of the trade share variable used in the renowned “Determinants of Economic Growth Data”. Along with factors that may be associated with growth, the growth rates of up to 61 different countries were taken into consideration. The information is publicly accessible online as an addition to Stock and Watson [
35]. The trade share dataset consists of the following numbers: 0.1405, 0.1566, 0.1577, 0.1604, 0.1608, 0.2215, 0.2994, 0.3131, 0.3246, 0.3247, 0.3295, 0.3300, 0.3379, 0.3397, 0.3523, 0.3589, 0.3933, 0.4176, 0.4258, 0.4356, 0.4421, 0.4444, 0.4505, 0.4558, 0.4683, 0.4733, 0.4846, 0.4889, 0.5096, 0.5177, 0.5278, 0.5347, 0.5433, 0.5442, 0.5508, 0.5527, 0.5606, 0.5607, 0.5671, 0.5753, 0.5828, 0.6030, 0.6050, 0.6136, 0.6261, 0.6395, 0.6469, 0.6512, 0.6816, 0.6994, 0.7048, 0.7292, 0.7430, 0.7455, 0.7798, 0.7984, 0.8147, 0.8230, 0.8302, 0.8342, 0.9794.
Dataset II: This dataset includes 30 measurements of polyester fibers’ tensile strength made by Quesenberry and Hales [
36]. The data are 0.023, 0.032, 0.054, 0.069, 0.081, 0.094, 0.105, 0.127, 0.148, 0.169, 0.188, 0.216, 0.255, 0.277, 0.311, 0.361, 0.376, 0.395, 0.432, 0.463, 0.481, 0.519, 0.529, 0.567, 0.642, 0.674, 0.752, 0.823, 0.887, 0.926.
Dataset III: COVID-19 of Britain: This dataset covered a period of 82 days, from 1 May 2021 to 16 July 2021 (see Abu El Azm et al. [
37]). The following information is created using daily new deaths (DNDs), daily cumulative cases (DCCs), and daily cumulative deaths (DCDs): 0.0023, 0.0023, 0.0023, 0.0046, 0.0065, 0.0067, 0.0069, 0.0069, 0.0091, 0.0093, 0.0093, 0.0093, 0.0111, 0.0115, 0.0116, 0.0116, 0.0119, 0.0133, 0.0136, 0.0138, 0.0138, 0.0159, 0.0161, 0.0162, 0.0162, 0.0162, 0.0163, 0.0180, 0.0187, 0.0202, 0.0207, 0.0208, 0.0225, 0.0230, 0.0230, 0.0239, 0.0245, 0.0251, 0.0255, 0.0255, 0.0271, 0.0275, 0.0295, 0.0297, 0.0300, 0.0302, 0.0312, 0.0314, 0.0326, 0.0346, 0.0349, 0.0350, 0.0355, 0.0379, 0.0384, 0.0394, 0.0394, 0.0412, 0.0419, 0.0425, 0.0461, 0.0464, 0.0468, 0.0471, 0.0495, 0.0501, 0.0521, 0.0571, 0.0588, 0.0597, 0.0628, 0.0679, 0.0685, 0.0715, 0.0766, 0.0780, 0.0942, 0.0960, 0.0988, 0.1223, 0.1343, and 0.1781.
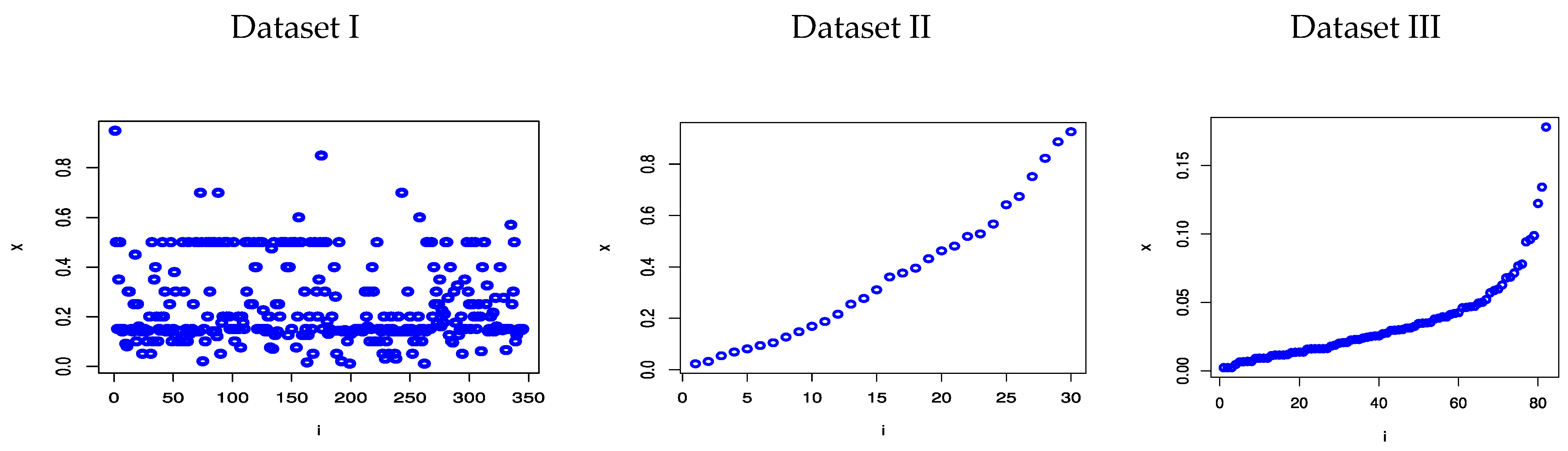
Some descriptive statistics for the proposed datasets are displayed in
Table 5 and represented in
Figure 4.
The analysis of the three real datasets is discussed in more detail in the following subsections.
7.1. Analysis of First Dataset
First, in order to compare the fit models, we employed the aforementioned criterion measurements included in
Table 6.
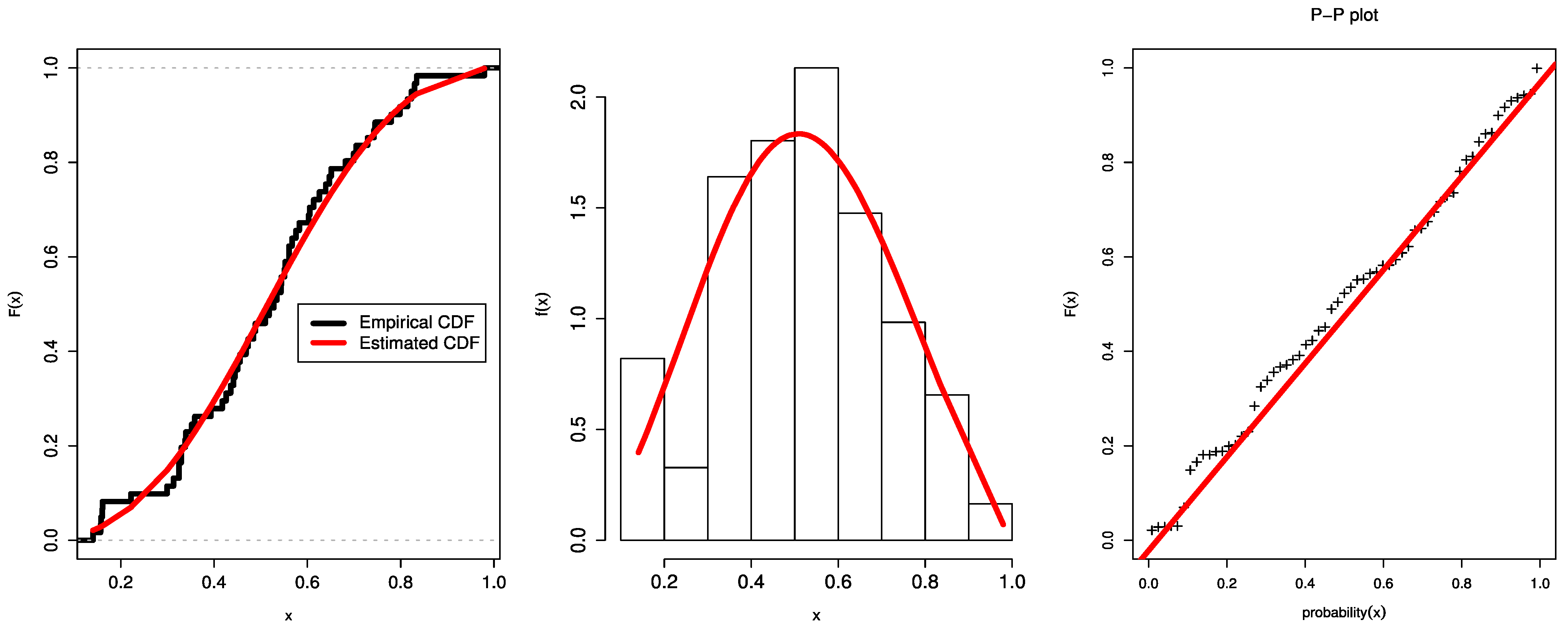
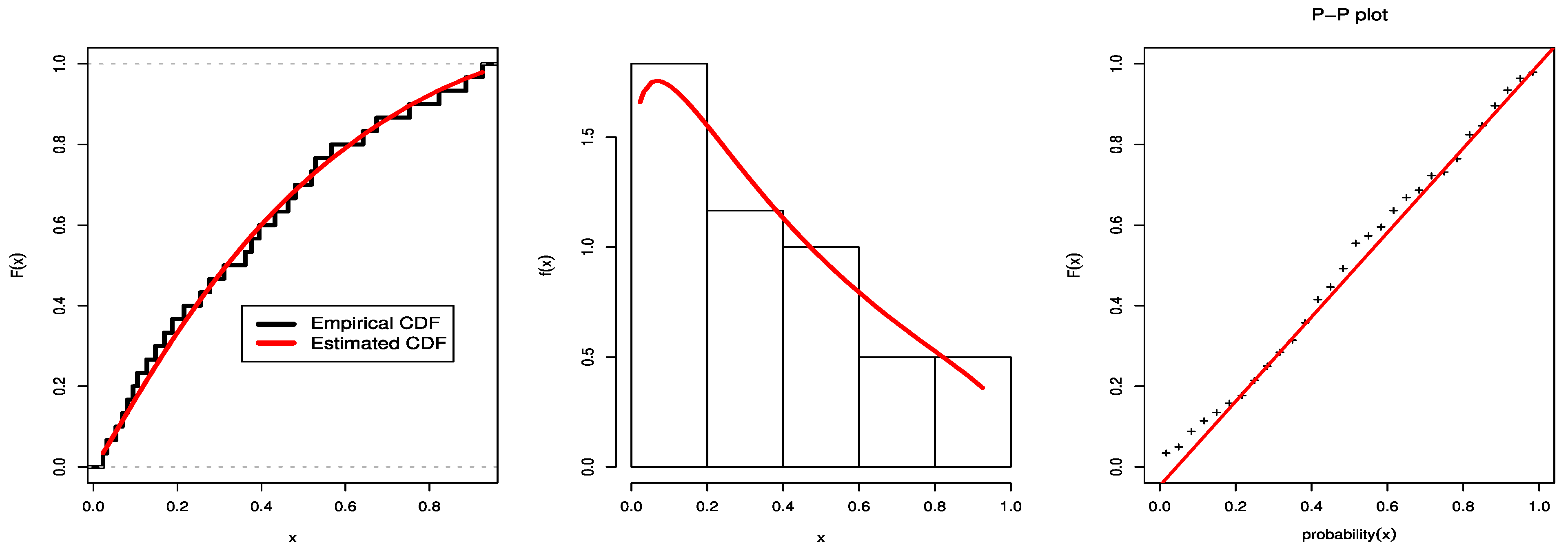
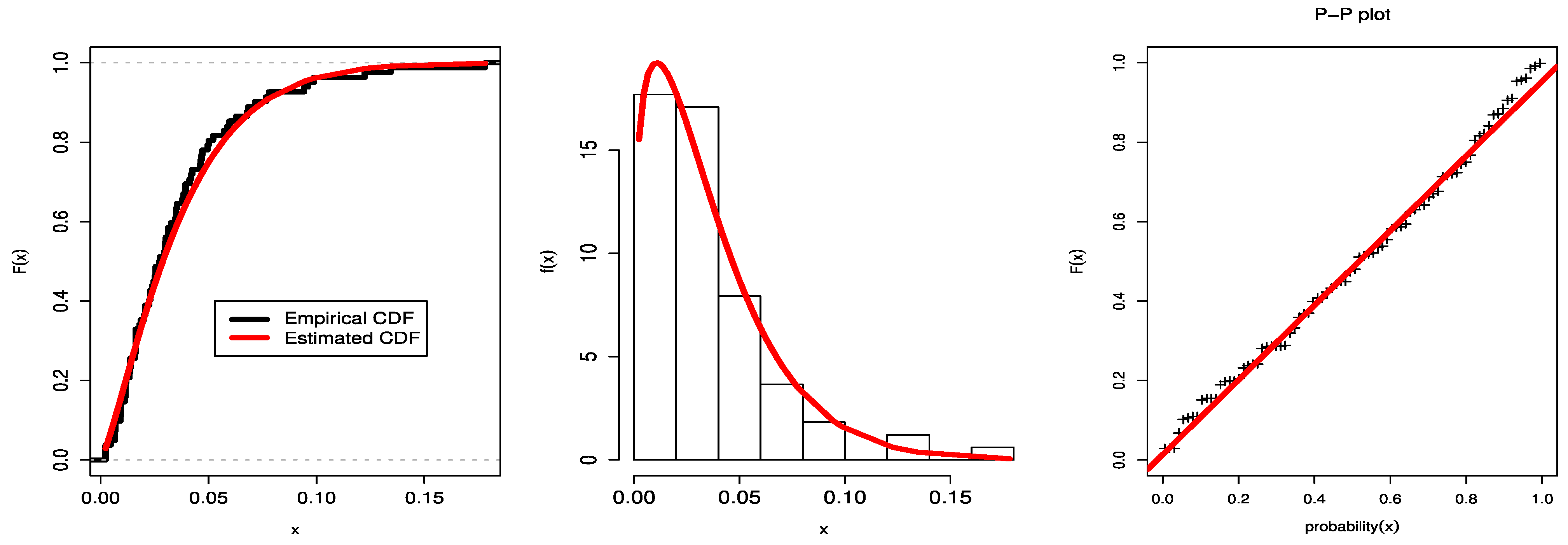
Figure 5 displays the dataset’s P-P plots, the fit UEHLD PDF plots with their empirical CDF, and the relative histogram with the fit UEHLD. These graphical goodness-of-fit methods in
Figure 5 also corroborate the results in
Table 6.
Second, from
Table 5 and
Figure 4, we cannot use the MPS method to estimate the parameters of Dataset I because this dataset has more equal values, then
is equal to zero at most observations. Consequently,
Table 7 only contains the ML and Bayesian estimates with the SELF of the UEHLD’s parameters. 10,000 MCMC samples were generated using the MCMC method. To apply the MCMC sampler process, the starting values of the unknown parameters were assumed to represent their MLEs.
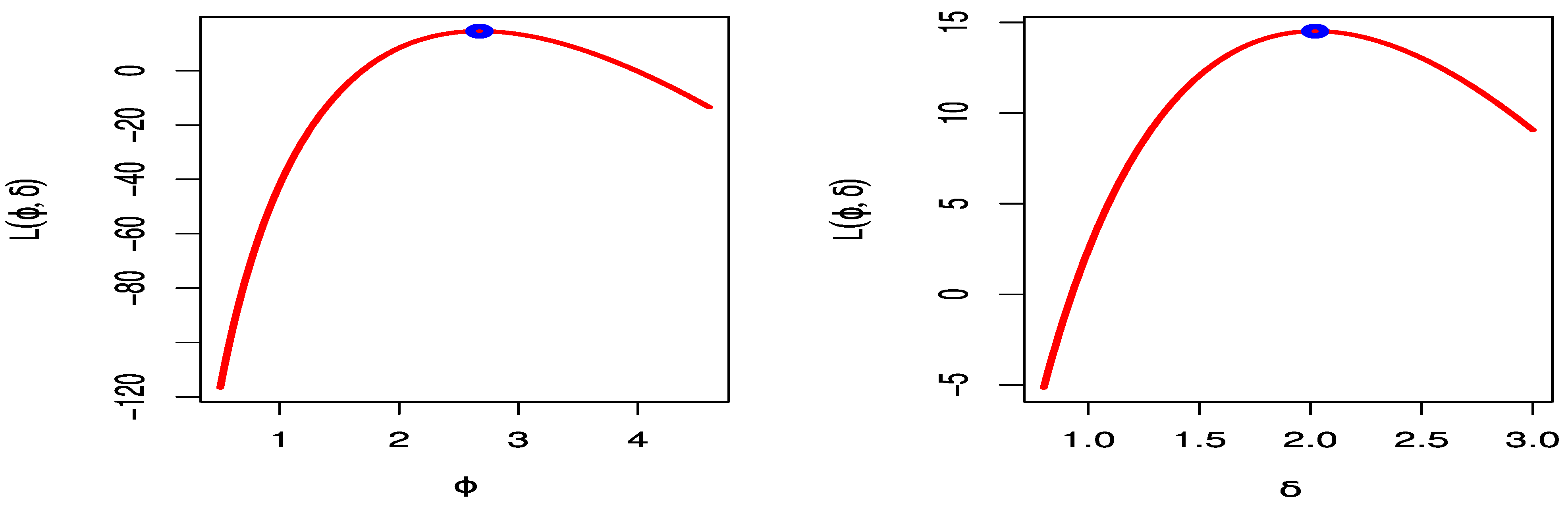
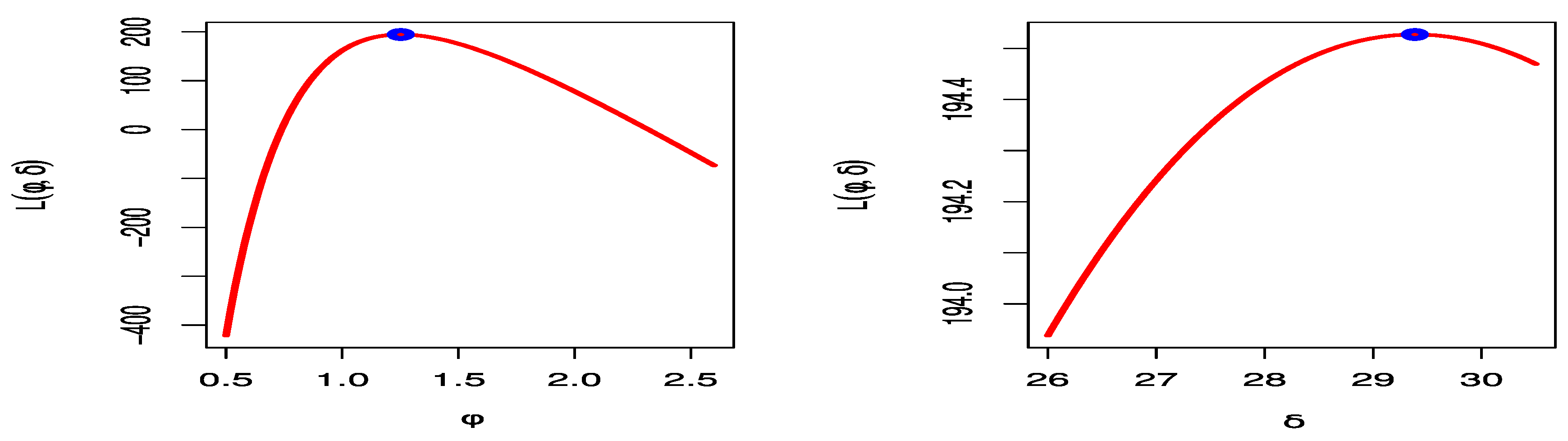
Figure 6 sketches the profile log-likelihood of the UEHLD for each parameter by fixing one parameter and varying the other. The figures show that the trade share dataset behaves very well, as we can see that the two roots of the parameters are global maxima.
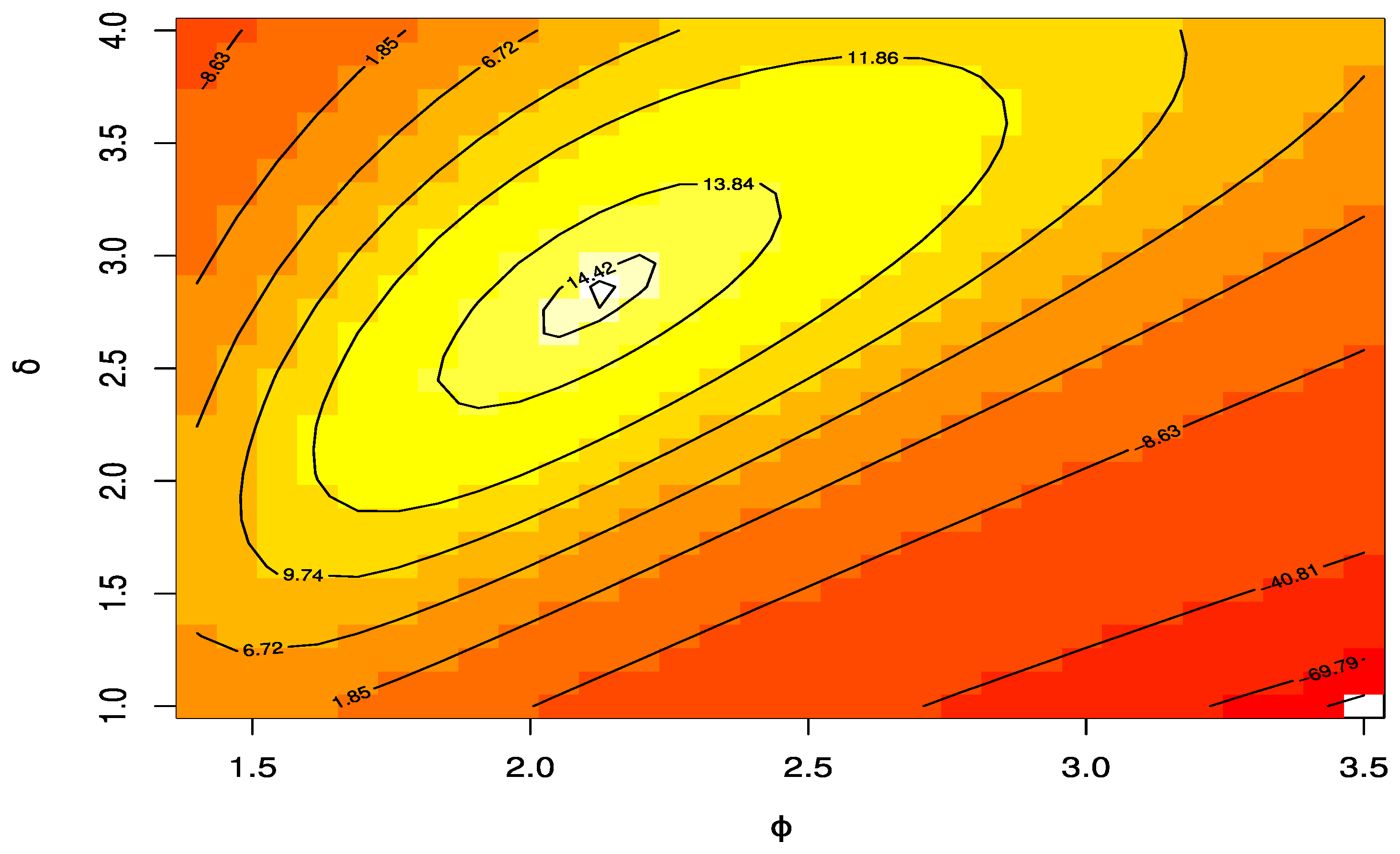
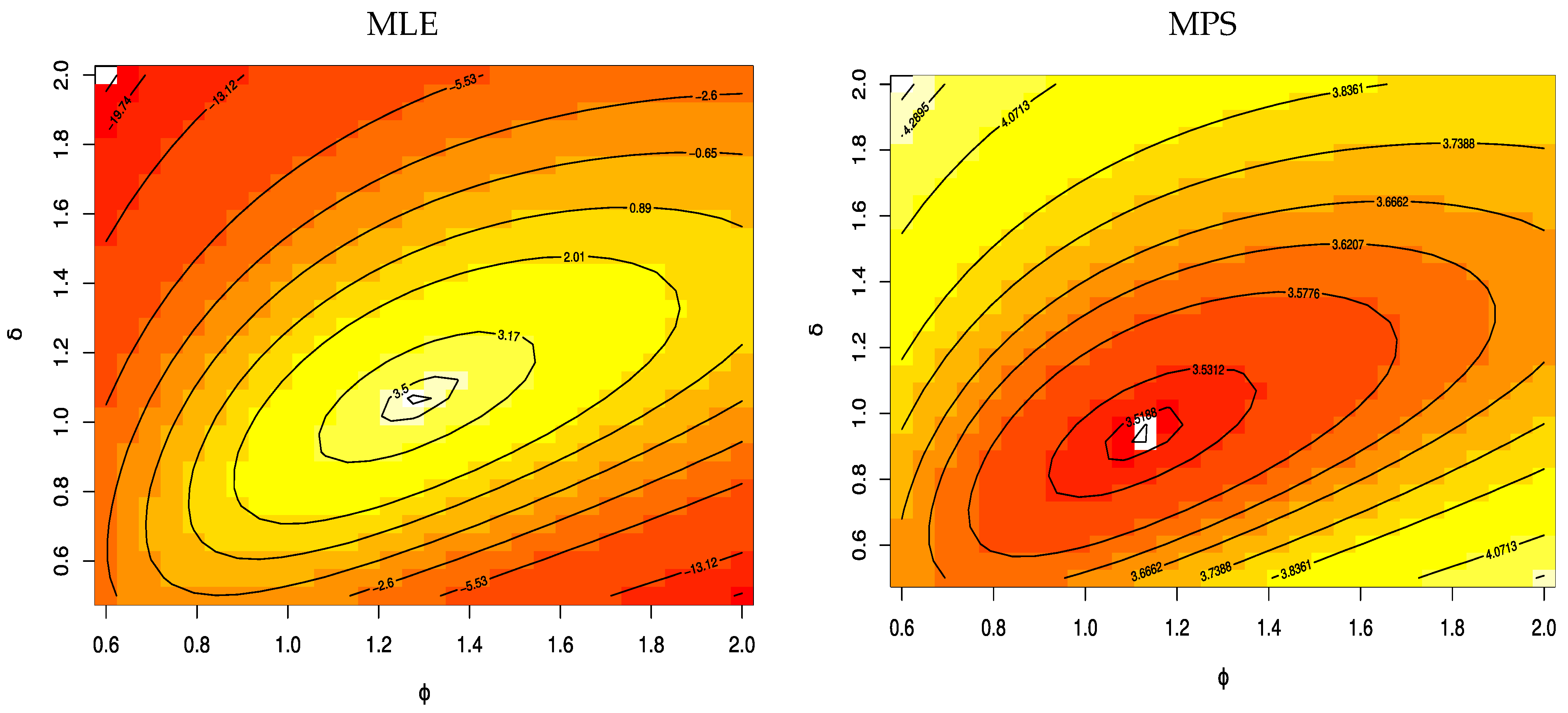
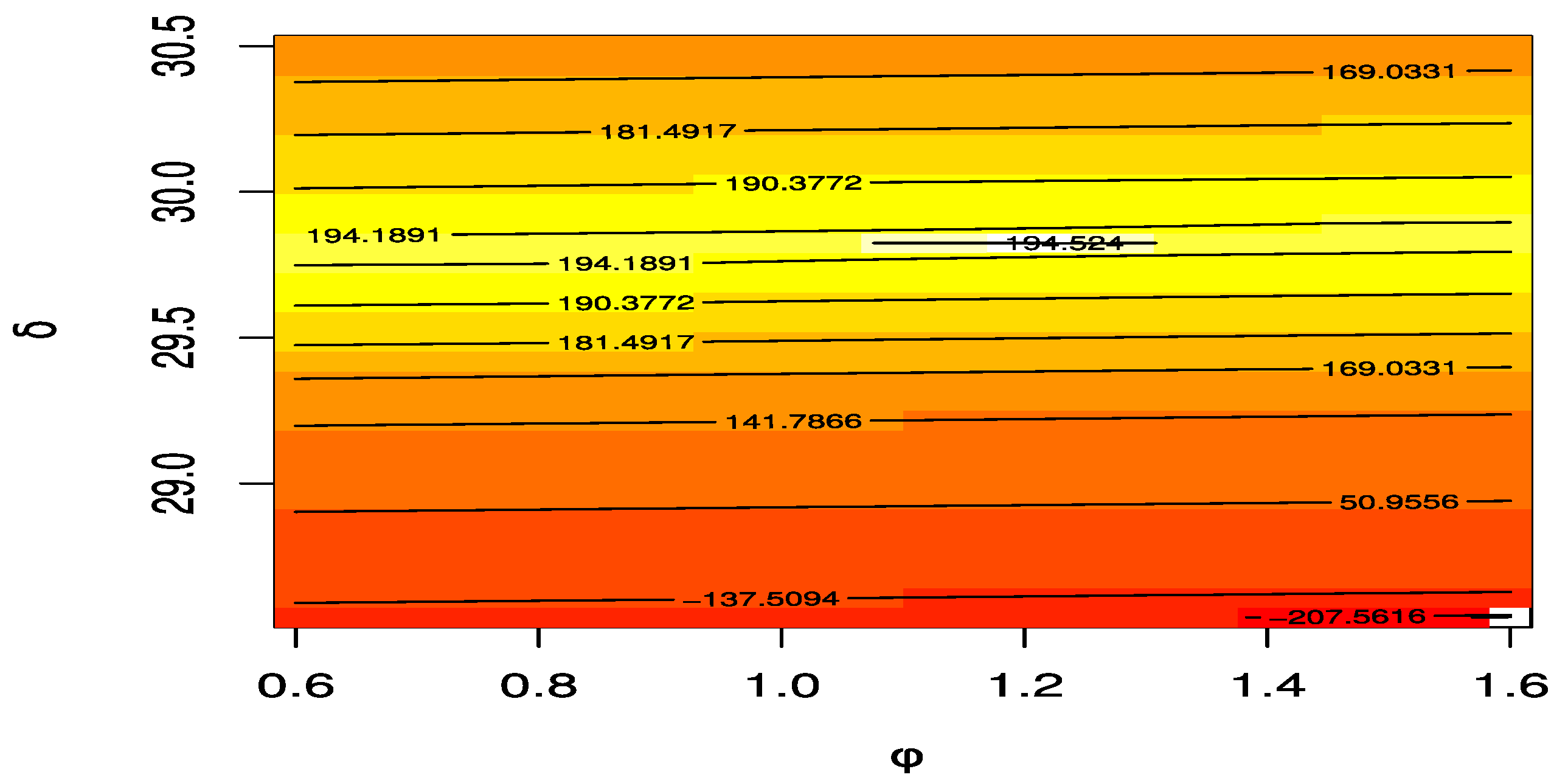
Figure 7 gives the contour plot with varying parameters and log-likelihoods of the UEHLD to confirm the estimates have unique points.
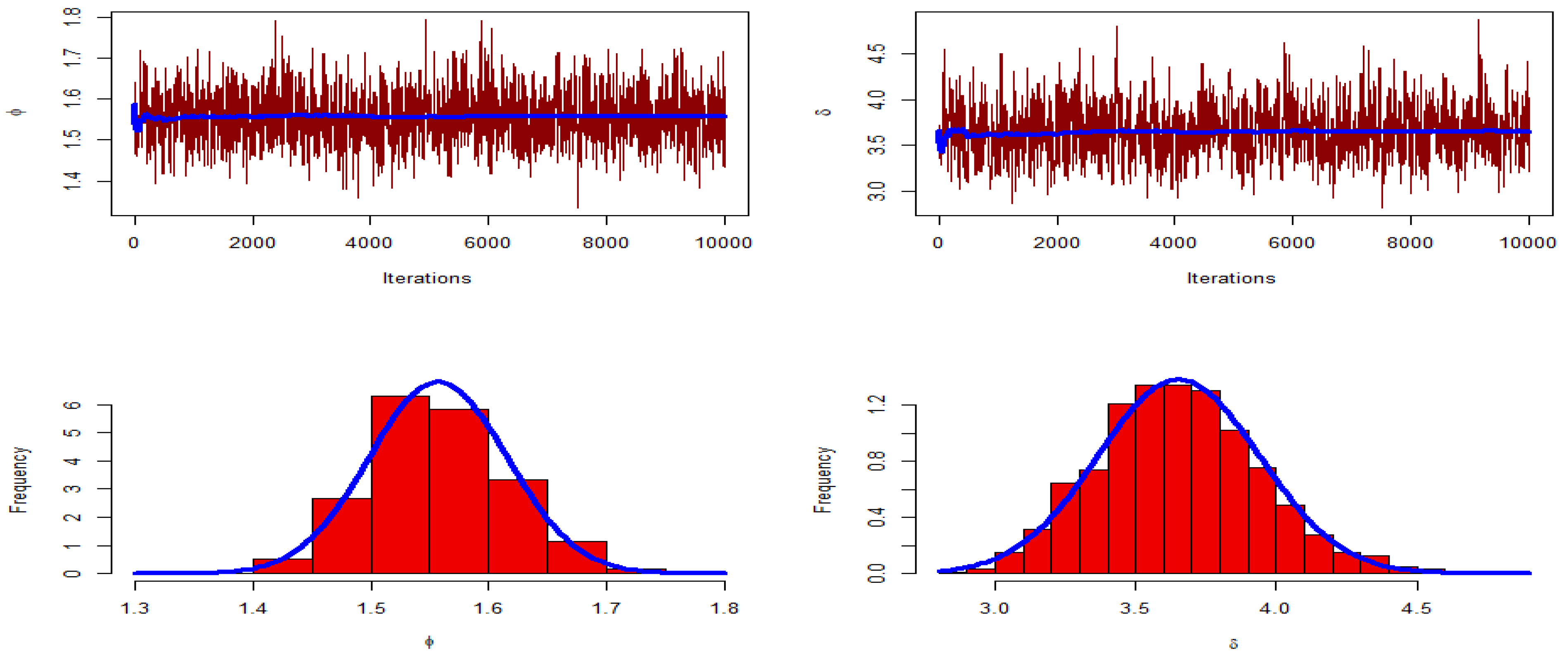
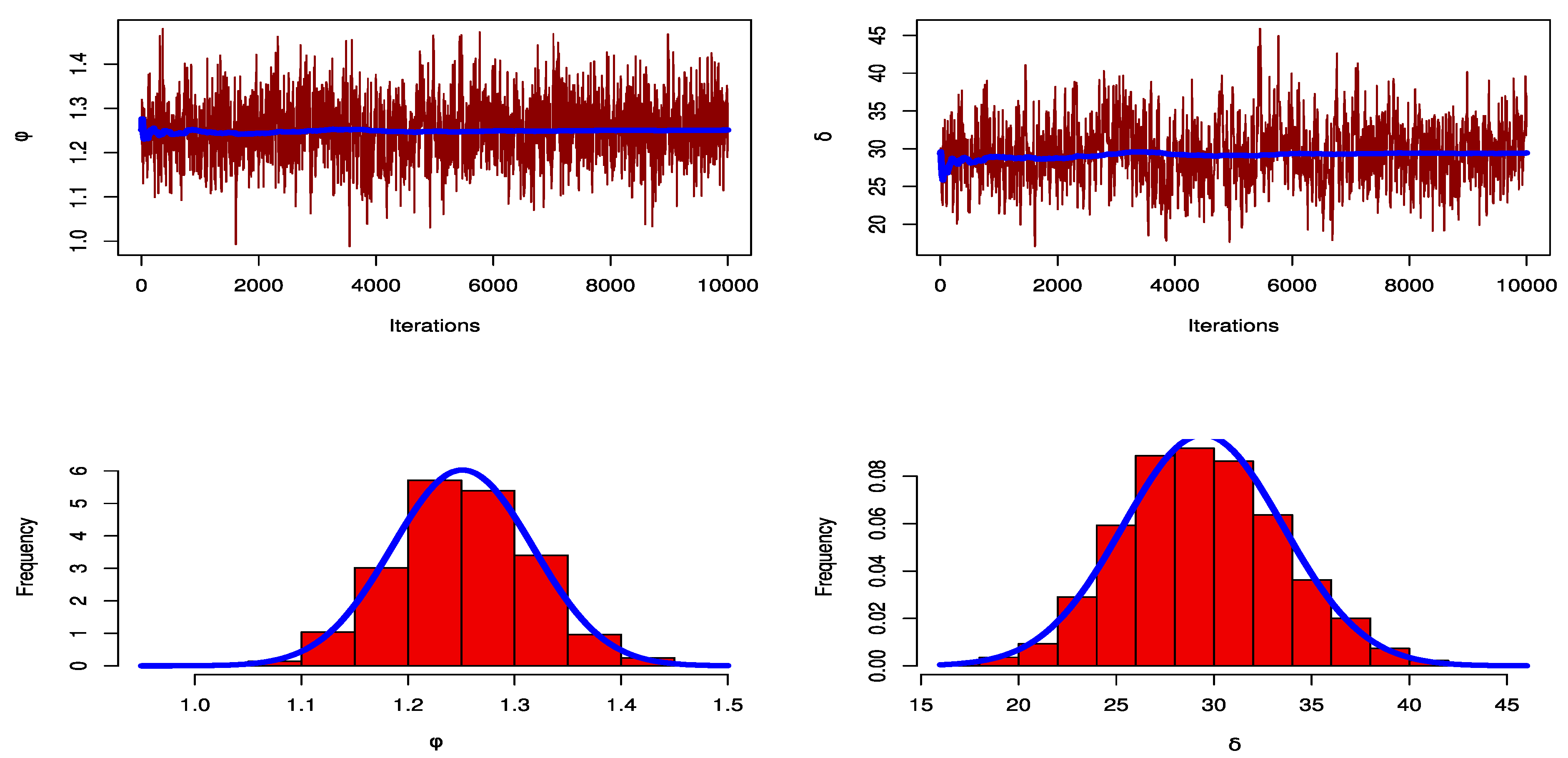
Figure 8 shows the trace plots of the posterior distributions of the parameters to track the convergence of the MCMC outputs. This figure shows how well the MCMC process converges. Furthermore, this shows the histograms for the marginal posterior density estimates of the parameters based on 10,000 chain values and the Gaussian kernel. The estimations clearly show that all of the generated posteriors are symmetric with respect to the theoretical posterior density functions.
7.2. Analysis of Second Dataset
First, we compared the fit of the proposed UEHLD with that of the beta, K, KK, MOK, UB, UBXII, and UGLBXII distributions. We used the aforementioned criterion measurements found in
Table 8 to compare the fit models.
Table 8 reveals that the UEHLD has smaller measures than the other competing distributions, indicating that it offers a superior fit.
The estimated PDF, empirical CDF, and P-P plots for Dataset II are shown in
Figure 9. These graphical plots support the outcomes in
Table 9.
Second, utilizing the information on the tensile strength of the fibers, we determined the ML, MPS, and Bayesian estimates using the SELF of the UEHLD’s parameters, which are listed in
Table 9. We used the mentioned MCMC algorithm to generate 10,000 MCMC samples. The initial values of the unknown parameters were taken to be their MLEs in order to use the MCMC sampling procedure.
For the data on the tensile strength of polyester fibers,
Figure 10 draws the profile log-likelihood of the UEHLD for each parameter by fixing one parameter and changing the others. This figure demonstrates the excellent behavior of the aforementioned data, since the two roots of the parameters are global maxima.
Figure 11 shows a contour plots with variable parameters, the log-likelihood function, and the log-product spacing function of the UEHLD to verify that the estimates have unique points.
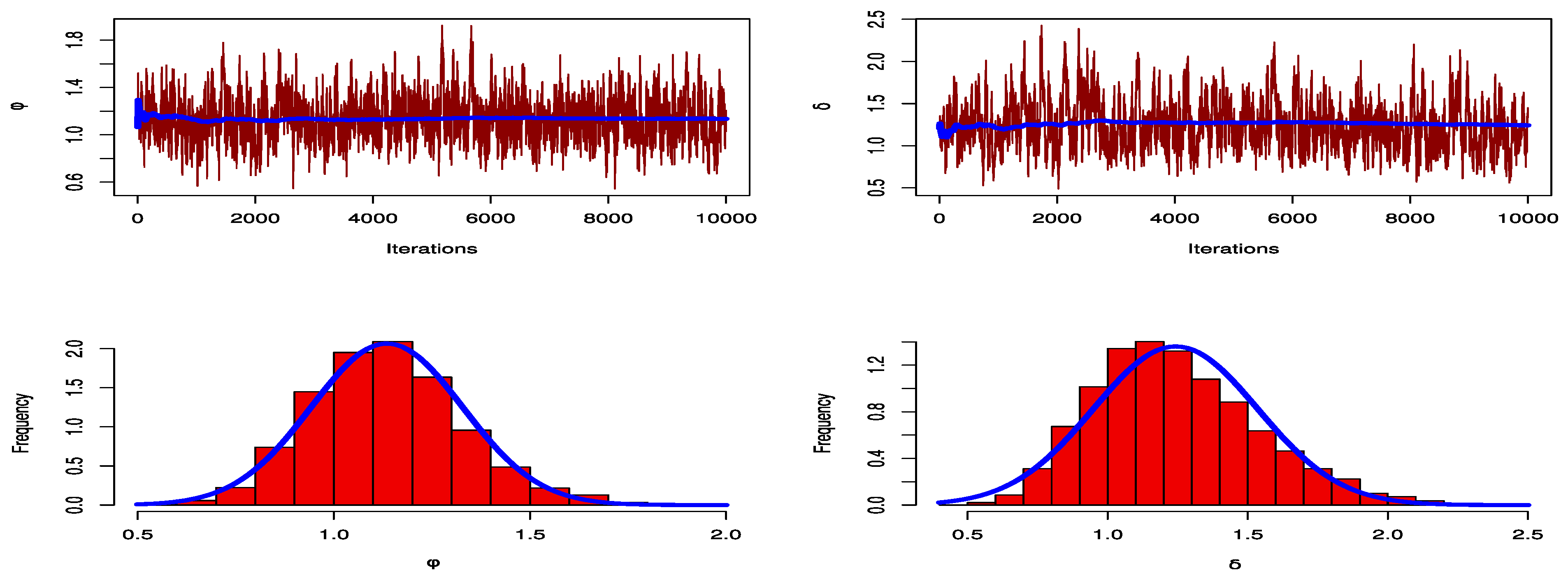
Figure 12 shows trace plots of the posterior distributions of the parameters to track the convergence of the MCMC outputs. Additionally, they display the histograms for the marginal posterior density estimates of the parameters based on 10,000 chain values and the Gaussian kernel, demonstrating how effectively the MCMC process converges. All of the produced posteriors are symmetric with regard to the theoretical posterior density functions, as shown by the estimations.
7.3. Analysis of COVID-19 Data
First, we compared the fit of the proposed UEHLD with that of the UW, K, KK, MOK, and UG distributions. We used the aforementioned criterion measurements found in
Table 10 to compare the fit models.
Table 10 reveals that the UEHLD has smaller measures than other competing distributions, indicating that it offers a superior fit for COVID-19 data. We should also point out that, in comparison to the models reported by Abu El Azm et al. [
37], the findings of our new model yield superior measure values.
The estimated PDF, empirical CDF, and P-P plots for the COVID-19 data are shown in
Figure 13. These graphical plots support the outcomes in
Table 10.
Second, for the COVID-19 data, we determined the ML, MPS, and Bayesian estimates using the SELF of the UEHLD’s parameters for COVID-19 data, which are listed in
Table 11. We used the mentioned MCMC algorithm to generate 10,000 MCMC samples. The initial values of the unknown parameters were taken to be their MLEs in order to use the MCMC sampling procedure. For the COVID-19 data,
Figure 14 draws the profile log-likelihood of the UEHLD for each parameter by fixing one parameter and changing the others.
Figure 15 demonstrates the excellent behavior of the aforementioned data, since the two roots of the parameters are global maxima.
Figure 16 shows trace plots of the posterior distributions of the parameters to track the convergence of the MCMC outputs. Additionally, they display the histograms for the marginal posterior density estimates of the parameters based on 10,000 chain values and the Gaussian kernel, demonstrating how effectively the MCMC process converges. All of the produced posteriors are symmetric with regard to the theoretical posterior density functions, as shown by the estimations.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}