


Fuzzy MLKNN in Credit User Portrait †

Abstract
:1. Introduction
2. Literature Review
2.1. Multi-Label Learning
2.2. Application of Fuzzy Theory
3. Fuzzy MLKNN
3.1. Problem Definition
3.2. Basic Concepts of Intuitionistic Fuzzy Sets
3.3. Fuzzy MLKNN
4. Experiments
4.1. Evaluation Metrics
4.2. Experiment Setting
4.3. Comparison with Fuzzy MLKNN and Other Multi-Label Learning Algorithms
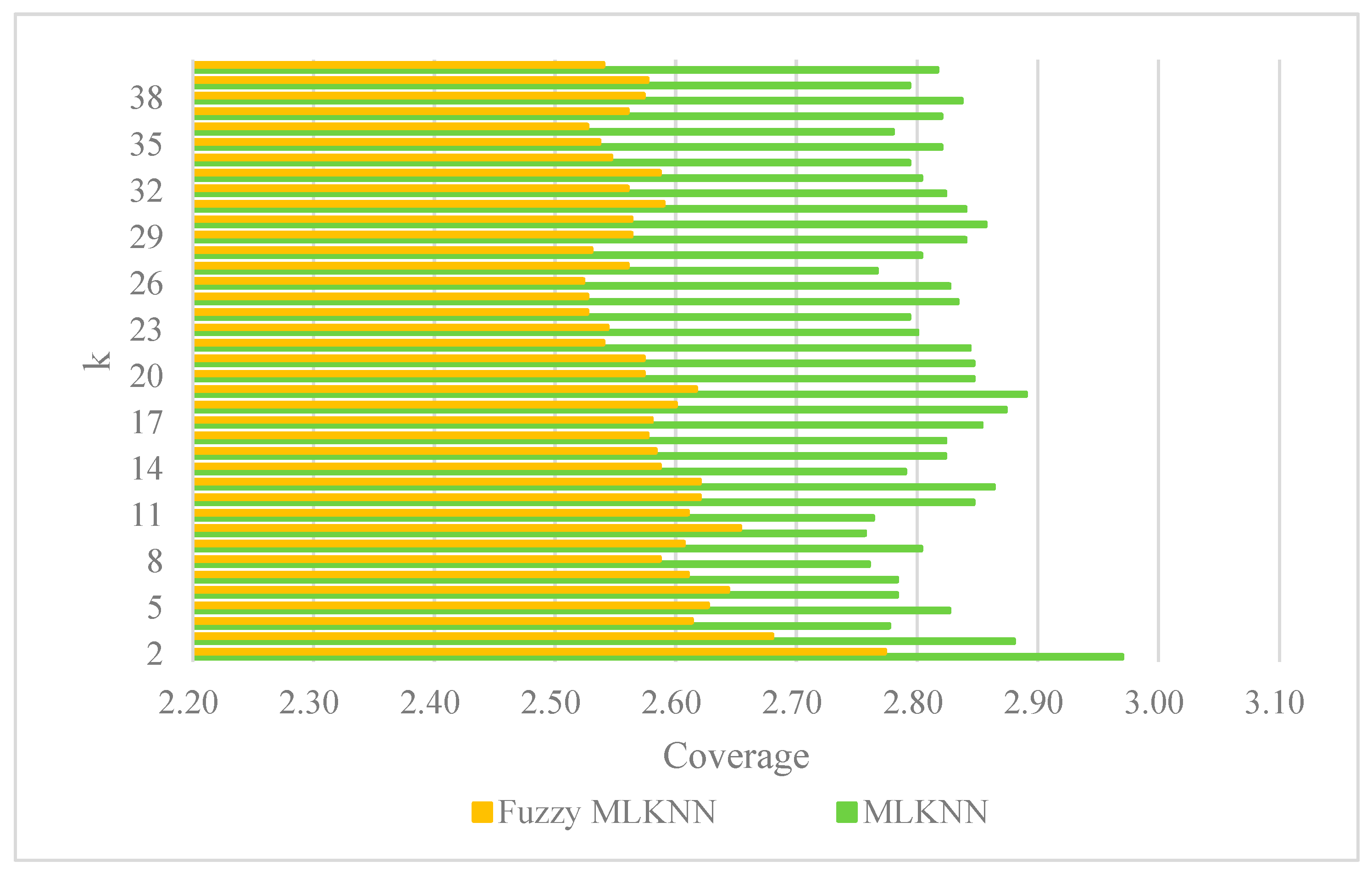
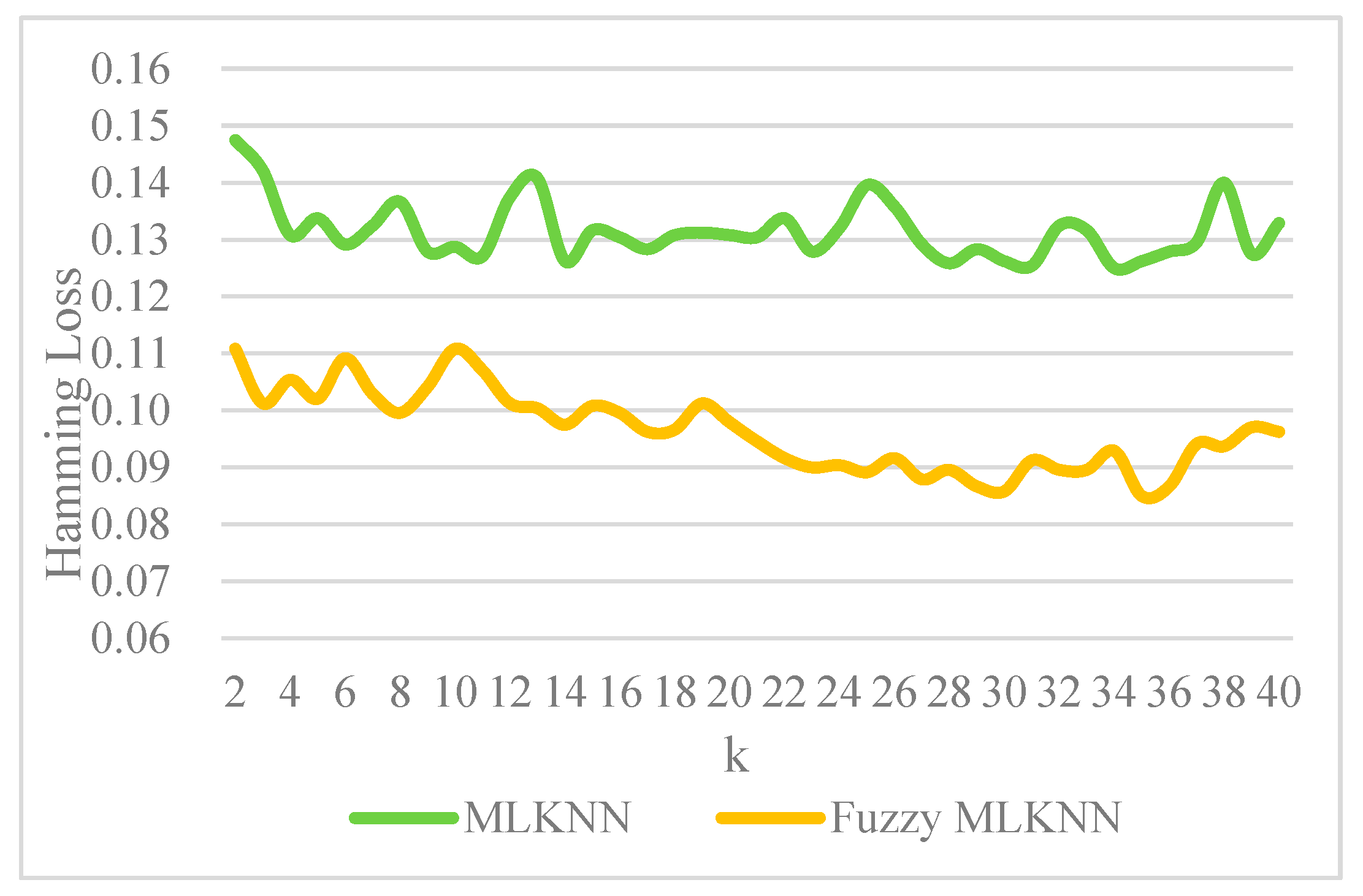
4.4. Comparative Analysis of Fuzzy MLKNN with MLKNN
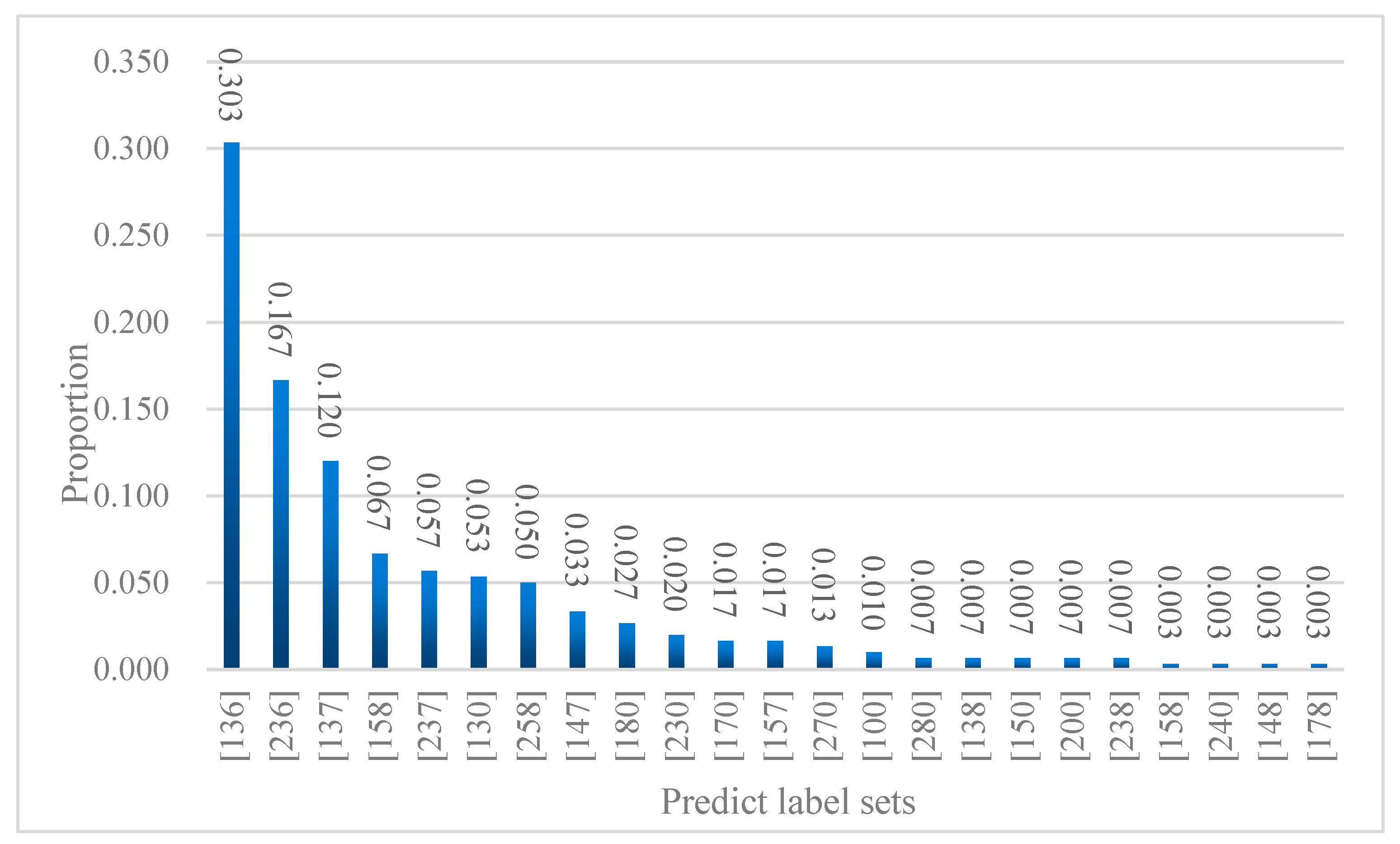
5. User Portrait
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- function [Prior,PriorN,Cond,CondN]=MLKNN_train(train_data,train_target,Num,Smooth)
- %MLKNN_train trains a multi-label k-nearest neighbor classifier
- %
- % Syntax
- %
- % [Prior,PriorN,Cond,CondN]=MLKNN_train(train_data,train_target,num_neighbor)
- %
- % Description
- %
- % KNNML_train takes,
- % train_data - An MxN array, the ith instance of training instance is stored in train_data(i,:)
- % train_target - A QxM array, if the ith training instance belongs to the jth class, then train_target(j,i) equals +1, otherwise train_target(j,i) equals -1
- % Num - Number of neighbors used in the k-nearest neighbor algorithm
- % Smooth - Smoothing parameter
- % and returns,
- % Prior - A Qx1 array, for the ith class Ci, the prior probability of P(Ci) is stored in Prior(i,1)
- % PriorN - A Qx1 array, for the ith class Ci, the prior probability of P(~Ci) is stored in PriorN(i,1)
- % Cond - A Qx(Num+1) array, for the ith class Ci, the probability of P(k|Ci) (0<=k<=Num), i.e., k nearest neighbors of an instance in Ci will belong to Ci, is stored in Cond(i,k+1)
- % CondN - A Qx(Num+1) array, for the ith class Ci, the probability of P(k|~Ci) (0<=k<=Num), i.e., k nearest neighbors of an instance not in Ci will belong to Ci, is stored in CondN(i,k+1)
- [num_class,num_training]=size(train_target);
- %Computing distance between training instances
- dist_matrix=diag(realmax*ones(1,num_training));
- for i=1:num_training-1
- if(mod(i,100)==0)
- disp(strcat('computing distance for instance:',num2str(i)));
- end
- vector1=train_data(i,:);
- for j=i+1:num_training
- vector2=train_data(j,:);
- dist_matrix(i,j)=sqrt(sum((vector1-vector2).^2));
- dist_matrix(j,i)=dist_matrix(i,j);
- end
- end
- %Computing Prior and PriorN
- for i=1:num_class
- temp_Ci=sum(train_target(i,:)==ones(1,num_training));
- Prior(i,1)=(Smooth+temp_Ci)/(Smooth*2+num_training);
- PriorN(i,1)=1-Prior(i,1);
- end
- %Computing Cond and CondN
- Neighbors=cell(num_training,1); %Neighbors{i,1} stores the Num neighbors of the ith training instance
- for i=1:num_training
- [temp,index]=sort(dist_matrix(i,:));
- Neighbors{i,1}=index(1:Num);
- end
- temp_Ci=zeros(num_class,Num+1);
- temp_NCi=zeros(num_class,Num+1);
- for i=1:num_training
- temp=zeros(1,num_class);
- neighbor_labels=[];
- for j=1:Num
- neighbor_labels=[neighbor_labels,train_target(:,Neighbors{i,1}(j))];
- end
- for j=1:num_class
- temp(1,j)=sum(neighbor_labels(j,:)==ones(1,Num));
- end
- for j=1:num_class
- if(train_target(j,i)==1)
- temp_Ci(j,temp(j)+1)=temp_Ci(j,temp(j)+1)+1;
- else
- temp_NCi(j,temp(j)+1)=temp_NCi(j,temp(j)+1)+1;
- end
- end
- end
- for i=1:num_class
- temp1=sum(temp_Ci(i,:));
- temp2=sum(temp_NCi(i,:));
- for j=1:Num+1
- Cond(i,j)=(Smooth+temp_Ci(i,j))/(Smooth*(Num+1)+temp1);
- CondN(i,j)=(Smooth+temp_NCi(i,j))/(Smooth*(Num+1)+temp2);
- end
- end
- Function [HammingLoss,RankingLoss,OneError,Coverage,Average_Precision,Outputs,Pre_Labels]=MLKNN_test(train_data,train_target,test_data,test_target,Num,Prior,PriorN,Cond,CondN)
- %MLKNN_test tests a multi-label k-nearest neighbor classifier.
- %
- % Syntax
- %
- % [HammingLoss,RankingLoss,OneError,Coverage,Average_Precision,Outputs,Pre_Labels]=MLKNN_test(train_data,train_target,test_data,test_target,Num,Prior,PriorN,Cond,CondN)
- %
- % Description
- %
- % KNNML_test takes,
- % train_data - An M1xN array, the ith instance of training instance is stored in train_data(i,:)
- % train_target - A QxM1 array, if the ith training instance belongs to the jth class, then train_target(j,i) equals +1, otherwise train_target(j,i) equals -1
- % test_data - An M2xN array, the ith instance of testing instance is stored in test_data(i,:)
- % test_target - A QxM2 array, if the ith testing instance belongs to the jth class, test_target(j,i) equals +1, otherwise test_target(j,i) equals -1
- % Num - Number of neighbors used in the k-nearest neighbor algorithm
- % Prior - A Qx1 array, for the ith class Ci, the prior probability of P(Ci) is stored in Prior(i,1)
- % PriorN - A Qx1 array, for the ith class Ci, the prior probability of P(~Ci) is stored in PriorN(i,1)
- % Cond - A Qx(Num+1) array, for the ith class Ci, the probability of P(k|Ci) (0<=k<=Num), i.e., k nearest neighbors of an instance in Ci will belong to Ci, is stored in Cond(i,k+1)
- % CondN - A Qx(Num+1) array, for the ith class Ci, the probability of P(k|~Ci) (0<=k<=Num), i.e., k nearest neighbors of an instance not in Ci will belong to Ci, is stored in CondN(i,k+1)
- % and returns,
- % HammingLoss - The hamming loss on testing data
- % RankingLoss - The ranking loss on testing data
- % OneError - The one-error on testing data as
- % Coverage - The coverage on testing data as
- % Average_Precision- The average precision on testing data
- % Outputs - A QxM2 array, the probability of the ith testing instance belonging to the jCth class is stored in Outputs(j,i)
- % Pre_Labels - A QxM2 array, if the ith testing instance belongs to the jth class, then Pre_Labels(j,i) is +1, otherwise Pre_Labels(j,i) is -1
- [num_class,num_training]=size(train_target);
- [num_class,num_testing]=size(test_target);
- %Computing distances between training instances and testing instances
- dist_matrix=zeros(num_testing,num_training);
- for i=1:num_testing
- if(mod(i,100)==0)
- disp(strcat('computing distance for instance:',num2str(i)));
- end
- vector1=test_data(i,:);
- for j=1:num_training
- vector2=train_data(j,:);
- dist_matrix(i,j)=sqrt(sum((vector1-vector2).^2));
- end
- end
- %Find neighbors of each testing instance
- Neighbors=cell(num_testing,1); %Neighbors{i,1} stores the Num neighbors of the ith testing instance
- for i=1:num_testing
- [temp,index]=sort(dist_matrix(i,:));
- Neighbors{i,1}=index(1:Num);
- end
- %Computing Outputs
- Outputs=zeros(num_class,num_testing);
- for i=1:num_testing
- % if(mod(i,100)==0)
- % disp(strcat('computing outputs for instance:',num2str(i)));
- % end
- temp=zeros(1,num_class); %The number of the Num nearest neighbors of the ith instance which belong to the jth instance is stored in temp(1,j)
- neighbor_labels=[];
- for j=1:Num
- neighbor_labels=[neighbor_labels,train_target(:,Neighbors{i,1}(j))];
- end
- for j=1:num_class
- temp(1,j)=sum(neighbor_labels(j,:)==ones(1,Num));
- end
- for j=1:num_class
- Prob_in=Prior(j)*Cond(j,temp(1,j)+1);
- Prob_out=PriorN(j)*CondN(j,temp(1,j)+1);
- if(Prob_in+Prob_out==0)
- Outputs(j,i)=Prior(j);
- else
- Outputs(j,i)=Prob_in/(Prob_in+Prob_out);
- end
- end
- end
- %Evaluation
- Pre_Labels=zeros(num_class,num_testing)
- for i=1:num_testing
- for j=1:num_class
- if(Outputs(j,i)>=0.5)
- Pre_Labels(j,i)=1;
- else
- Pre_Labels(j,i)=-1;
- end
- end
- end
- HammingLoss=Hamming_loss(Pre_Labels,test_target)
- RankingLoss=Ranking_loss(Outputs,test_target);
- OneError=One_error(Outputs,test_target);
- Coverage=coverage(Outputs,test_target);
- Average_Precision=Average_precision(Outputs,test_target);
References
- Chen, X. Empirical Research on the Early Warning of Regional Financial Risk Based on the Credit Data of Central Bank. Credit. Ref. 2022, 9, 17–24. [Google Scholar]
- Hou, S.Q.; Chen, X.J. Absence and Improvement of Legal Protection of Personal Credit Information Rights and Interests in the Era of Big Data. Credit. Ref. 2022, 9, 25–34. [Google Scholar]
- Chen, Y.H.; Wang, J.Y. The Rule of Law Applicable to the 2nd Generation Credit Information System under the Background of the Social Credit System. Credit. Ref. 2020, 38, 51–55. [Google Scholar]
- Li, Z. Research on the Development of Internet Credit Reference in China and the Supervision over It. Credit. Ref. 2015, 33, 9–15. [Google Scholar]
- Tian, K. Constructing the Market-oriented Individual Credit Investigation Ecosystem. China Financ. 2022, 8, 90–92. [Google Scholar]
- Han, L.; Su, Z.; Lin, J. A Hybrid KNN algorithm with Sugeno measure for the personal credit reference system in China. J. Intell. Fuzzy Syst. 2020, 39, 6993–7004. [Google Scholar] [CrossRef]
- Lessmann, S.; Baesens, B.; Seow, H.; Thomas, L.C. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. Eur. J. Oper. Res. 2015, 247, 124–136. [Google Scholar] [CrossRef] [Green Version]
- Moscato, V.; Picariello, A.; Sperlí, G. A benchmark of machine learning approaches for credit score prediction. Expert Syst. Appl. 2021, 165, 113986. [Google Scholar] [CrossRef]
- Tarekegn, A.N.; Giacobini, M.; Michalak, K. A review of methods for imbalanced multi-label classification. Pattern Recognit. 2021, 118, 107965. [Google Scholar] [CrossRef]
- Song, D.; Vold, A.; Madan, K.; Schilder, F. Multi-label legal document classification: A deep learning-based approach with label-attention and domain-specific pre-training. Inf. Syst. 2022, 106, 101718. [Google Scholar] [CrossRef]
- Tandon, K.; Chatterjee, N. Multi-label text classification with an ensemble feature space. J. Intell. Fuzzy Syst. 2022, 42, 4425–4436. [Google Scholar] [CrossRef]
- Chen, D.; Rong, W.; Zhang, J.; Xiong, Z. Ranking based multi-label classification for sentiment analysis. J. Intell. Fuzzy Syst. 2020, 39, 2177–2188. [Google Scholar] [CrossRef]
- Gibaja, E.L.; Ventura, S. A Tutorial on Multi-Label Learning. Acm Comput. Surv. 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Gui, X.; Lu, X.; Yu, G. Cost-effective Batch-mode Multi-label Active Learning. Neurocomputing 2021, 463, 355–367. [Google Scholar] [CrossRef]
- Mishra, N.K.; Singh, P.K. Feature construction and smote-based imbalance handling for multi-label learning. Inf. Sci. 2021, 563, 342–357. [Google Scholar] [CrossRef]
- Xu, X.; Shan, D.; Li, S.; Sun, T.; Xiao, P.; Fan, J. Multi-label learning method based on ML-RBF and laplacian ELM. Neurocomputing 2019, 331, 213–219. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining Multi-Label Data. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2009; pp. 667–685. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Read, J.; Pfahringer, B.; Holmes, G. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar]
- Lango, M.; Stefanowski, J. What makes multi-class imbalanced problems difficult? An experimental study. Expert Syst. Appl. 2022, 199, 116962. [Google Scholar] [CrossRef]
- Ruiz Alonso, D.; Zepeda Cortes, C.; Castillo Zacatelco, H.; Carballido Carranza, J.L.; Garcia Cue, J.L. Multi-label classification of feedbacks. J. Intell. Fuzzy Syst. 2022, 42, 4337–4343. [Google Scholar] [CrossRef]
- Yapp, E.K.Y.; Li, X.; Lu, W.F.; Tan, P.S. Comparison of base classifiers for multi-label learning. Neurocomputing 2020, 394, 51–60. [Google Scholar] [CrossRef]
- Lv, S.; Shi, S.; Wang, H.; Li, F. Semi-supervised multi-label feature selection with adaptive structure learning and manifold learning. Knowl. Based Syst. 2021, 214, 106757. [Google Scholar] [CrossRef]
- Tan, A.; Liang, J.; Wu, W.; Zhang, J. Semi-supervised partial multi-label classification via consistency learning. Pattern Recognit. 2022, 131, 108839. [Google Scholar] [CrossRef]
- Li, Q.; Peng, X.; Qiao, Y.; Hao, Q. Unsupervised person re-identification with multi-label learning guided self-paced clustering. Pattern Recognit. 2022, 125, 108521. [Google Scholar] [CrossRef]
- Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining KDD ’02, Edmonton, AB, Canada, 23–26 July 2002; ACM: New York, NY, USA, 2002; pp. 133–142. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Zhou, Z. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Zhu, D.; Zhu, H.; Liu, X.; Li, H.; Wang, F.; Li, H.; Feng, D. CREDO: Efficient and privacy-preserving multi-level medical pre-diagnosis based on ML-kNN. Inf. Sci. 2020, 514, 244–262. [Google Scholar] [CrossRef]
- Zhu, X.; Ying, C.; Wang, J.; Li, J.; Lai, X.; Wang, G. Ensemble of ML-KNN for classification algorithm recommendation. Knowl. Based Syst. 2021, 221, 106933. [Google Scholar] [CrossRef]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Comprehensive comparative study of multi-label classification methods. Expert Syst. Appl. 2022, 203, 117215. [Google Scholar] [CrossRef]
- Syropoulos, A.; Grammenos, T. A Modern Introduction to Fuzzy Mathematics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2020; pp. 39–69. [Google Scholar]
- Dunn, J.C. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Wu, C.; Wang, Z. A modified fuzzy dual-local information c-mean clustering algorithm using quadratic surface as prototype for image segmentation. Expert Syst. Appl. 2022, 201, 117019. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, B.; Li, C. A new robust fuzzy clustering framework considering different data weights in different clusters. Expert Syst. Appl. 2022, 206, 117728. [Google Scholar] [CrossRef]
- Wei, H.; Chen, L.; Chen, C.P.; Duan, J.; Han, R.; Guo, L. Fuzzy clustering for multiview data by combining latent information. Appl. Soft Comput. 2022, 126, 109140. [Google Scholar] [CrossRef]
- De Carvalho, F.D.A.T.; Lechevallier, Y.; de Melo, F.M. Relational partitioning fuzzy clustering algorithms based on multiple dissimilarity matrices. Fuzzy Sets Syst. 2013, 215, 1–28. [Google Scholar] [CrossRef]
- Vluymans, S.; Cornelis, C.; Herrera, F.; Saeys, Y. Multi-label classification using a fuzzy rough neighborhood consensus. Inf. Sci. 2018, 433–434, 96–114. [Google Scholar] [CrossRef]
- Zhao, X.; Nie, F.; Wang, R.; Li, X. Improving projected fuzzy K-means clustering via robust learning. Neurocomputing 2022, 491, 34–43. [Google Scholar] [CrossRef]
- Varshney, A.K.; Muhuri, P.K.; Danish Lohani, Q.M. PIFHC: The Probabilistic Intuitionistic Fuzzy Hierarchical Clustering Algorithm. Appl. Soft Comput. 2022, 120, 108584. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Li, G.Y.; Yang, B.R.; Liu, Y.H.; Cao, D.Y. Survey of data mining based on fuzzy set theory. Comput. Eng. Des. 2011, 32, 4064–4067+4264. [Google Scholar]
- Xu, Z.S. Intuitionistic Fuzzy Aggregation Operators. IEEE Trans. Fuzzy Syst. 2007, 15, 1179–1187. [Google Scholar]
- Zhang, Z.; Han, L.; Chen, M. Multi-label learning with user credit data in China based on MLKNN. In Proceedings of the 2nd International Conference on Information Technology and Cloud Computing (ITCC 2022), Qingdao, China, 20–22 May 2022; pp. 105–111. [Google Scholar]
- Zhang, C.; Li, Z. Multi-label learning with label-specific features via weighting and label entropy guided clustering ensemble. Neurocomputing 2021, 419, 59–69. [Google Scholar] [CrossRef]
- Hurtado, L.; Gonzalez, J.; Pla, F. Choosing the right loss function for multi-label Emotion Classification. J. Intell. Fuzzy Syst. 2019, 36, 4697–4708. [Google Scholar] [CrossRef]
- Shu, S.; Lv, F.; Yan, Y.; Li, L.; He, S.; He, J. Incorporating multiple cluster centers for multi-label learning. Inf. Sci. 2022, 590, 60–73. [Google Scholar] [CrossRef]
- Skryjomski, P.; Krawczyk, B.; Cano, A. Speeding up k-Nearest Neighbors classifier for large-scale multi-label learning on GPUs. Neurocomputing 2019, 354, 10–19. [Google Scholar] [CrossRef]
- Liu, B.; Blekas, K.; Tsoumakas, G. Multi-label sampling based on local label imbalance. Pattern Recognit. 2022, 122, 108294. [Google Scholar] [CrossRef]
- Lyu, G.; Feng, S.; Li, Y. Noisy label tolerance: A new perspective of Partial Multi-Label Learning. Inf. Sci. 2021, 543, 454–466. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Descriptions | Advantages | Disadvantages |
|---|---|---|---|
| Binary Correlation (BR) | Individual classifier for each label | Simple | Ignores label correlations |
| Label Power Set (LP) | Each unique label set as a class identifier | Simple | Not applicable to more labels |
| Chain of Classifiers (CC) | Extension of BR, String two classifiers into a chain for learning | Consider label correlations | Performance depends on the order of classifiers in the chain |
| RankSVM | Improvement to the traditional SVM | Performance improvement | Not suitable for dealing with high-dimensional samples |
| ML-DT | Improvement to the traditional DT | Performance improvement | Not suitable for processing continuous variables, large samples, and multi-class data |
| MLKNN | Improvement to the traditional KNN | Strong applicability, Performance improvement | Ignores label correlations |
| Variables | Description |
|---|---|
| Samples space | |
| Labels space | |
| Arbitrary i-th sample | |
| Feature vector of xi. The elements in αi are composed of intuitionistic fuzzy numbers. | |
| Label set of xi | |
| The label category vector | |
| Arbitrary single category label | |
| The set of K nearest neighbors of x identified in the training set | |
| The number of sample with label l in neighbor set | |
| the event that x has label l | |
| The event that x has not label l | |
| The event that, among the K nearest neighbors of x, there are exactly j instances with label l. |
| Coefficient of Correlation | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) |
|---|---|---|---|---|---|---|---|---|---|---|
| (1) year_income | 1 | 0 | 0 | 0 | 0.01 | 0.01 | 0 | 0 | 0.04 | 0.03 |
| (2) credit_over_amount | 0 | 1 | 0.02 | 0.03 | −0.02 | −0.03 | −0.02 | −0.02 | −0.01 | −0.02 |
| (3) loan_over_amount | 0 | 0.02 | 1 | 1 | −0.01 | −0.01 | −0.02 | −0.02 | 0 | −0.01 |
| (4) total_over_amount | 0 | 0.03 | 1 | 1 | −0.01 | −0.01 | −0.02 | −0.02 | 0 | −0.01 |
| (5) bank_legal_org_num | 0.01 | −0.02 | −0.01 | −0.01 | 1 | 0.99 | 0.94 | 0.94 | 0.58 | 0.64 |
| (6) bank_org_num | 0.01 | −0.03 | −0.01 | −0.01 | 0.99 | 1 | 0.93 | 0.93 | 0.59 | 0.65 |
| (7) credit_legal_org_num | 0 | −0.02 | −0.02 | −0.02 | 0.94 | 0.93 | 1 | 1 | 0.58 | 0.63 |
| (8) credit_org_num | 0 | −0.02 | −0.02 | −0.02 | 0.94 | 0.93 | 1 | 1 | 0.58 | 0.63 |
| (9) total_credit_amount | 0.04 | −0.01 | 0 | 0 | 0.58 | 0.59 | 0.58 | 0.58 | 1 | 0.52 |
| (10) query | 0.03 | −0.02 | −0.01 | −0.01 | 0.64 | 0.65 | 0.63 | 0.63 | 0.52 | 1 |
| Examples | Features | Labels | |||||
|---|---|---|---|---|---|---|---|
| train | test | Nominal | Numeric | Numbers | Cardinality | Density | Proportion |
| 700 | 300 | 2 | 9 | 8 | 3 | 0.375 | 0.018 |
| Attribute Name | Data Conversion Process |
|---|---|
| education | Primary school = 1; Secondary technical school = 2; Junior high school = 3; Senior middle school =4; Junior college = 5; University = 6; Postgraduate = 7 |
| year_income | 1~10,000 RMB = 1; 10,001~50,000 RMB = 2; 50,001~100,000 RMB = 3; 100,001~500,000 RMB = 4; 500,001~1,000,000 RMB = 5; more than 1,000,000 RMB = 6 |
| career | Soldier = 1; Heads of state agencies, party organizations, enterprises, and institutions = 2; Clerks and related personnel = 3; Production personnel in agriculture, forestry, animal husbandry, fishery, and water conservancy = 4; Commercial and service industry personnel = 5; Professional skill worker = 6; Production and transportation equipment operators and related personnel = 7 |
| credit_account | 1~5 = 1; 6~10 = 2; 11~20 = 3; 21~50 = 4; more than 50 = 5; |
| loan_strokecount | 0~2 times = 1; 3~5 times = 2; 6~8 times = 3; 9~11 times = 4; more than 11 times = 5 |
| total_credit_amount | 1~10,000 RMB = 1; 10,001~50,000 RMB = 2; 50,001~100,000 RMB = 3; 100,001~500,000 RMB = 4; 500,001~1,000,000 RMB = 5; More than 1,000,000 RMB = 6 |
| total_use_amount | 1~10,000 RMB = 1; 10,001~50,000 RMB = 2; 50,001~100,000 RMB = 3; 100,001~500,000 RMB = 4; 500,001~1,000,000 RMB = 5; More than 1,000,000 RMB = 6 |
| credit_amount_utilization_rate | 0~0.3 = 1; 0.3~0.6 = 2; 0.6~0.9 = 3; 0.9~1 = 4 |
| query | 1~5 times = 1; 6~10 times = 2; 11~20 times = 3; 21~50 times = 4; 51~100 times = 5; more than 100 times = 6 |
| credit_over_amount | No overdraft = 0; Overdraft = 1 |
| total_over_amount | No overdue = 0; Overdue = 1 |
| Attribute Name | Corresponding Intuitionistic Fuzzy Number |
|---|---|
| education | 1:(0.01, 0.99); 2:(0.10, 0.90); 3:(0.17, 0.83); 4:(0.41, 0.59); 5:(0.79, 0.21); 6:(0.98, 0.02); 7(1, 0) |
| year_income | 1:(0.01, 0.99); 2:(0.40, 0.60); 3:(0.73, 0.27); 4:(0.95, 0.05); 5:(0.98, 0.02); 6:(1, 0) |
| credit_amount_utilization_rate | 1:(0.09, 0.91); 2:(0.20, 0.80); 3:(0.58, 0.42); 4:(0.97, 0.03); 5:(1, 0) |
| Coding | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Labels Name | Personal development stability | Personal development instability | Low frequency of credit activities | Medium frequency of credit activities | High frequency of credit activities | Low attention to credit status | Normal attention to credit status | High attention to credit status |
| Binary Relevance | Classifier Chain | Rank SVM | Fuzzy MLKNN | |
|---|---|---|---|---|
| HammingLoss | 0.1947 | 0.2584 | 0.1688 | 0.0867 |
| Average_Precision | 0.8652 | 0.7542 | 0.8944 | 0.9436 |
| RankingLoss | 0.1281 | 0.2410 | 0.0900 | 0.0500 |
| OneError | 0.0852 | 0.2130 | 0.0667 | 0.0133 |
| Coverage | 3.0500 | 3.5200 | 2.9900 | 2.5267 |
| Label Code | Labels Name | Proportion |
|---|---|---|
| 1 | Personal development stability | 0.670 |
| 2 | Personal development instability | 0.330 |
| 3 | Low frequency of credit activities | 0.733 |
| 4 | Medium frequency of credit activities | 0.040 |
| 5 | High frequency of credit activities | 0.143 |
| 6 | Low attention to credit status | 0.470 |
| 7 | Medium attention to credit status | 0.260 |
| 8 | High attention to credit status | 0.173 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Han, L.; Chen, M. Fuzzy MLKNN in Credit User Portrait. Appl. Sci. 2022, 12, 11342. https://doi.org/10.3390/app122211342
Zhang Z, Han L, Chen M. Fuzzy MLKNN in Credit User Portrait. Applied Sciences. 2022; 12(22):11342. https://doi.org/10.3390/app122211342
Chicago/Turabian StyleZhang, Zhuangyi, Lu Han, and Muzi Chen. 2022. "Fuzzy MLKNN in Credit User Portrait" Applied Sciences 12, no. 22: 11342. https://doi.org/10.3390/app122211342
APA StyleZhang, Z., Han, L., & Chen, M. (2022). Fuzzy MLKNN in Credit User Portrait. Applied Sciences, 12(22), 11342. https://doi.org/10.3390/app122211342