1. Introduction
Radio frequency identification (RFID) has a variety of applications in the Internet of Things, such as supply chain management [
1,
2,
3,
4,
5], warehouse inventory [
6,
7,
8,
9,
10], object monitoring and tracking [
11,
12,
13,
14,
15], and posture recognition and localization [
16,
17,
18,
19,
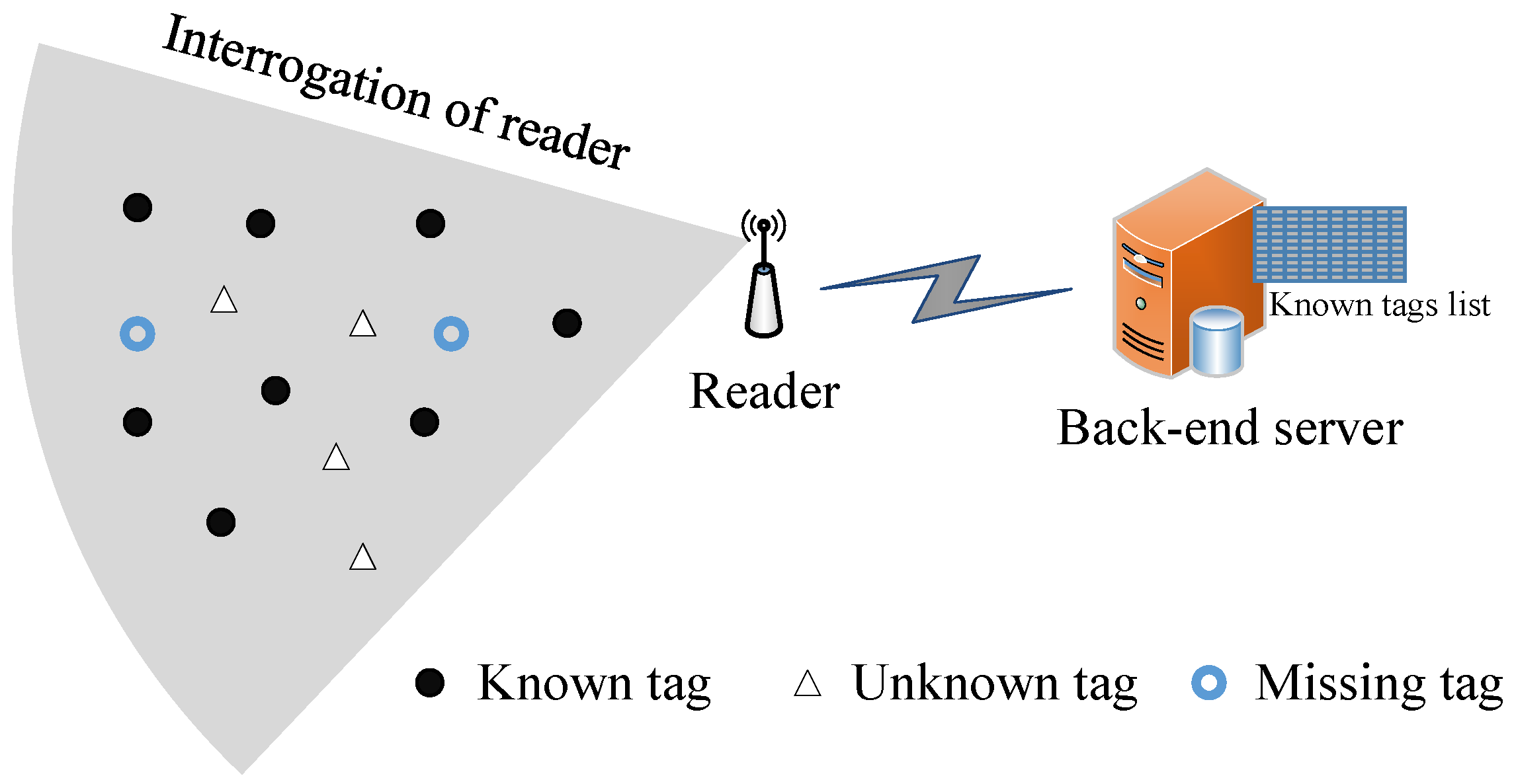
20]. In this broad range of RFID-enabled applications, unknown tag identification is crucial for collecting tag IDs from unexpected tags. For example, when a group of tagged objects is moved into a supermarket or warehouse such as Walmart, the manager needs to store these new tag IDs in the back-end database server for subsequent business operations such as daily inventory. In another example of a shopping mall, the customers often misplace frozen food with candy, causing the food to rot, or misplace oil near a lighter, causing great danger. The objective of unknown tag identification is to quickly identify newly added or misplaced tags from a large number of known tags. Considering a large-scale RFID system with millions of known tags whose IDs have already been stored in the back-end database previously, these known tags will participate in the identification of unknown tags, thus making it difficult to identify the unknown tags rapidly.
The existing unknown tag identification protocols are divided into two categories: probabilistic protocols [
21,
22,
23] and deterministic protocols [
24,
25,
26,
27,
28]. The probabilistic protocols can perform unknown tag detection quickly with an expected accuracy. The state-of-the-art probabilistic protocol is the
collision seeking detection (CSD) protocol [
23], which finds a collision seed to make many known tags collide in the last
N slots with a frame size of
f, thus saving the detection time and ensuring the desired detection accuracy. The deterministic protocol can correctly identify all unknown tags in a batch. Reference [
25] proposed a series of protocols to improve identification performance. The
basic unknown tag identification protocol (BUIP) separates known tags from unknown tags and deactivates them; the
single-pairing unknown tag identification protocol (SUIP) adopts a slot pairing method, and the
multi-pairing unknown tag identification protocol (MUIP) adopts multiple reselection methods to resolve the problem of known tag collisions. Meanwhile, the
filtering-based unknown tag identification protocol (FUTI) and the
interactive filtering-based unknown tag identification protocol (IFUTI) were investigated in [
27] to separate unknown tags from known tags and assign a status code to each singleton slot, thus reducing known–unknown collisions and identifying unknown tags at the bit level. Although the existing protocols can identify unknown tags, they do not have enough time efficiency and space efficiency in open RFID systems.
This paper investigates the problem of unknown tag identification in open RFID systems and proposes a deterministic unknown tag identification protocol called the filter-based and parallel unknown tag identification (FPUI) protocol. Considering the drawbacks of the existing protocols, the proposed protocol formulates a solution that satisfies the requirements of efficiency and accuracy by: (1) taking less time and space to achieve unknown tag identification; (2) accurately collecting the information of unknown tags. To achieve these goals, the FPUI consists of two phases: the separation phase and the collection phase. In the first phase, the FPUI adopts an RSQF-based filter [
29] to calculate the hash value for each known tag by
and divides the hash value into two parts:
and
. The
of tags with an identical
are placed in consecutive slots from small to large, and this sequence of slots is called a
. Meanwhile, the fingerprint filter assigns different fingerprints to multiple known tags in the same
to reconcile the collision slots and separate the known tags from unknown tags. In the second phase, the FPUI collects the IDs of multiple tags by using a CDMA-based parallel identification method.
The main contributions of this paper are summarized as follows:
(1) A complete and robust solution to unknown tag identification in open RFID systems is provided.
(2) An RSQF-based fingerprint filter is utilized to solve the problem of slot collisions and separate the known tags from unknown tags, thus improving slot utilization and reducing the false positive rate.
(3) A parallel identification method is adopted to collect the IDs of multiple unknown tags with high efficiency.
(4) The performance of the proposed protocol is formally analyzed. The impact of various parameters on the identification time of our protocol is investigated, and the parameters are optimized to obtain the shortest identification time.
(5) Theoretical analysis and extensive simulations are conducted. The results indicate that our protocol performs better and has a lower false positive rate than the existing advanced protocols.
The rest of the paper is organized as follows.
Section 2 introduces the related work.
Section 3 formulates our problem.
Section 4 proposes an efficient and complete unknown tag identification protocol called FPUI and theoretically analyzes its performance.
Section 6 evaluates our protocol.
Section 7 summarizes this paper.
2. Related Work
Many recent studies on RFID technology focus on functional applications, including information collection [
30,
31], cardinality estimation [
32,
33], tag grouping [
34,
35], searching a wanted tag set [
36,
37], and missing tag identification [
38,
39]. Unknown tag identification, as a research branch, is practically important because it helps identify the unknown tags that are misplaced or moved in the reader’s interrogation area. To solve this problem, two categories of protocols have been designed: the probabilistic protocol [
21,
22,
23] and the deterministic protocol [
24,
25,
26,
27,
28].
The probabilistic protocol can identify unknown tags rapidly with an expected accuracy. Liu et al. designed an unknown tag detection scheme for detecting unknown tags with an expected confidence level [
21]. Gong et al. proposed the
white paper (WP) protocol [
22], which constructs a composite message data structure consisting of all useful informative data from some independent detection synopses. This structure helps improve the unknown tag detection efficiency and decrease the failure probability. Although these probabilistic protocols can judge unknown tags in a fast way, they cannot identify the information of all unknown tags’ IDs. Compared with the probabilistic protocol for unknown tag identification, the deterministic protocol can collect all information of unknown tags’ IDs. For example, Sheng et al. firstly formulated the problem of unknown tag identification and presented an unknown tag identification protocol called
continuous scanning (CU), which can collect a specified fraction of intact unknown tags [
24]. However, CU only achieves incomplete unknown tag identification caused by randomized algorithms. Liu et al. proposed the BUIP, SUIP, and MUIP protocols [
25], which adopt indicator vectors to distinguish known tags from unknown tags and deactivate the known tags. Although they can identify the intact unknown tag set with higher efficiency, more time is needed. Liu et al. proposed the FUTI and IFUTI protocols [
27], which investigate the interactive filters to accelerate the process of unknown tag identification. Xie et al. proposed the unknown tag identification protocol based on a coded filtering vector [
26], which utilizes the coded filtering vector technique to separate unknown tags from known tags and assign each singleton slot a status code to reduce known–unknown collisions, thus improving the identification performance. Zhu et al. proposed the
physical-layer unknown tag identification (PUTI) protocol [
28], which identifies the unknown tags by aggregating physical layer signals. Although these deterministic protocols can identify unknown tags, they are time-consuming and suffer from a high false positive rate.
This paper proposes a filter-based and parallel unknown tag identification protocol called FPUI. The FPUI thoroughly separates known tags from unknown tags and deactivates all known tags by adopting an RSQF-based fingerprint filter, thus improving the slot utilization and the accuracy of the protocol. Meanwhile, the FPUI adopts a parallel identification method to collect multiple unknown tag IDs in parallel, thus increasing the efficiency of the protocol.
4. Filter-Based and Parallel Unknown Tag Identification Protocol
In this section, the filter-based and parallel unknown tag identification (FPUI) protocol is proposed, which can identify all unknown tags within the interrogation area efficiently and completely.
4.1. Basic Idea
Most of the existing unknown tag identification protocols are based on a slotted hash, and they have two drawbacks: large time consumption and low accuracy. Firstly, the existing protocols have lower slot utilization due to slot collisions. In this case, they need multiple rounds to deactivate all known tags, which is time-consuming. Secondly, a false positive occurs when an unknown tag and a known tag pick the same slot, resulting in this unknown tag being deactivated.
The idea of the FPUI is to identify unknown tags as quickly and precisely as possible by the following three design principles:
(1) Improving slot utilization: In the slotted-ALOHA-based protocol, multiple tags may choose a slot to respond to the reader, causing slot collisions and reducing slot utilization. This protocol modifies the RSQF filter to reconcile the collision slots to single slots, thus increasing the number of useful slots.
(2) Eliminating false positives: In real open RFID systems, unknown tags may select the same slot as known tags, which causes these unknown tags to be regarded as known tags and deactivated, i.e., a false positive problem. The key to tackling the problem is separating known tags from unknown tags thoroughly. In this paper, a unique fingerprint is provided for each known tag in a to distinguish known tags from unknown tags, thus eliminating false positives.
(3) Increasing the identification efficiency: Traditional tag identification protocols adopt ALOHA-based or tree-based methods to collect the tag ID information serially, so the process is time-consuming. This paper proposes a parallel tag ID collection scheme to concurrently identify multiple unknown tags, thus increasing the identification efficiency.
To achieve the above goals, the FPUI identifies unknown tags in two phases: the separation phase and the collection phase. In the first phase, an RSQF-based fingerprint filter is built to separate known tags from unknown tags. In the second phase, the IDs of unknown tags are concurrently collected by assigning a series of orthogonal address codes to multiple singleton unknown tags, which is similar to CDMA technology.
4.2. Separation Phase
In this phase, the reader first builds an RSQF-based filter to increase the number of useful slots. Then, the reader constructs a fingerprint filter to separate known tags from unknown tags. The process of the separation phase is described in detail below.
4.2.1. Building an RSQF-Based Filter
The reader first calculates the hash value for each known tag by , where is the tag’s ID and is a random seed. The RSQF filter divides into two parts: the first q-bit part is called , denoted by , and the second r-bit part is called , denoted by . In this paper, the original RSQF filter was modified to make it adapt to our problem. The modified RSQF-based filter maintains a vector to determine whether a slot is occupied or not. A position j is occupied and is set to “1” when there is at least one tag whose . The number of “1s” in the vector up to position j is counted as , and the total number of “1s” in the vector is counted as s. Furthermore, the RSQF-based filter maintains a vector Q in which there are N slots. Each slot with a size of r bits can store a . The of tags with an identical are placed in consecutive slots from small to large. In this paper, this sequence of slots is called a , and the number of tags in a is called the . When a tag is inserted, the RSQF-based filter tries to store its in the . Here, the linear probing scheme was adopted to store the in the same . As will be described below, the RSQF-based filter seeks out an unoccupied slot to save when its is already occupied.
A slot storing a
is called “used”, and a slot storing no
is called “unused”. Since the RSQF-based filter uses the linear probing scheme to store
, a slot may also be “used” even when its corresponding position in the
vector is not occupied. The RSQF-based filter always attempts to store the
in their
and only drifts a
when its
is occupied by another
. As shown in
Figure 2, the RSQF-based filter maintains three vectors to determine whether a slot is “used” or not and the actual slot in which each
is stored. Specifically, the
bit vector with a size of
is used to indicate the
of each tag, the
bit vector with a size of
N is used to indicate the number of tags having the same
, and the
vector (namely
Q array) is used to indicate the actual slot of each tag.
For the convenience of expression, two operations are defined for the RSQF-based filter:
and
. For a given bit vector
D,
returns the index of the
ith 1 in
D, and
returns the number of 1s preceding the
ith position in
D, i.e.,
. The two operations help seek out the
of any
. If
, there is no such
; otherwise,
is applied to calculate the number
of slots
, i.e., the number of
preceding the slot
, and then,
is applied to calculate the end position of the
th
. As shown in
Figure 2, the slot of tag
is in the
th
, where
. The end slot of this
is
, and the beginning slot of this
is
(we set
to be
). Thus, the size of this
can be obtained by
. The actual slot index of tag
falls between
and
. The tag
checks the
jth position in the
vector (
). When
and
,
is inserted
into the
jth position.
4.2.2. Building Fingerprint Filter
Although the RSQF-based filter can assign a slot to each known tag, it cannot solve the slot collision problem when multiple tags have the same
and
. Furthermore, it cannot separate known tags from unknown tags with the same
and
in open RFID systems. Therefore, this paper added a
vector to solve the above two problems. The reader generates a unique
-bit fingerprint via a hash function
for every tag in the same
, where
is another random seed. The reader inserts the fingerprint of each tag into the corresponding position of the
vector according to the
vector, as shown in
Figure 2.
The reader broadcasts a request with parameters
to all tags. After receiving the request, the tag
firstly calculates its occupieds index by
and obtains its
index
. Then, it obtains the beginning position
and the end position
in the
vector. Subsequently, it calculates its fingerprint
by
and checks
(
). If
, this tag regards itself as a known tag and deactivates itself. The flowchart of separation phase is shown in
Figure 3. After this phase, all known tags are deactivated without participating in the collection phase.
4.3. Collection Phase
In this phase, our objective was to efficiently collect the IDs from all unknown tags. To save the collection time, the IDs were collected concurrently from multiple singleton unknown tags through a CDMA-based method, and each tag needs to determine its address code before transmitting its ID to the reader. The accomplishment of this goal involves four stages.
4.3.1. Building Real Frame
The real frame is constructed based on the responses of all unknown tags. In particular, the reader broadcasts a request with the parameter
to issue the frame, where
f is the size of the real frame and
is a random seed. In this frame, each active unknown tag
randomly picks a slot by the hash function
f and sends a 1-bit response to the reader in this slot. The reader listens to the channel and records the status of each slot, i.e., empty and collision are recorded as “0” and singleton is recorded as “1”. Then, the reader obtains the real frame that reflects the actual responses from the unknown tags, and the frame is denoted by
.
is also referred to as the indicator vector, and its length is
f.
For example, as shown in
Figure 4, there are 10 unknown tags
and
. The tags
are mapped to the 1st, 3nd, 6th, 5th, and 10th singleton slots, respectively, and other tags are mapped to collision slots. Therefore, the real frame (also called the indicator vector) is denoted as “1010110001”.
4.3.2. Building Address Code Vector
The reader generates a series of orthogonal address codes and builds the address code vector with a length of , where is the number of “1s” in . Here, the sequence is employed to provide address codes. The sequence of order m can provide m different orthogonal address codes, and each address code is m bits long, which guarantees that m singleton unknown tags can respond in parallel. Every m singleton slot belongs to a . The address codes of all tags are different and orthogonal within a . Therefore, can be expressed as , where is the address code of the tag .
Taking
Figure 4 as an example, the reader generates four orthogonal address codes and builds the address code vector
.
4.3.3. Assigning Address Code
The reader broadcasts the request with parameters
to all tags. Upon receiving the request, each singleton tag obtains its address code. Specifically, if the tag
is mapped to the
jth slot and
, the address code of the tag is
, where
is the number of “1s” preceding the
jth element in
. As shown in
Figure 4, after receiving
and
, each tag checks its index and obtains its address code. For example, the indexes of
are
, and the corresponding address codes are “1111”, “1010”, “1100”, “1001”, and “1111”, respectively. So far, each singleton tag has an address code, which is different and orthogonal to the address codes of other singleton tags in its
.
4.3.4. Collecting IDs in Parallel
The reader broadcasts the request to issue the frame. Every m unknown tag sends its ID to the reader in the same slot. For an arbitrary unknown tag , it adopts the following encoding scheme in place of and .: (i) The tag transmits the true code of in the th slot if a bit of its ID is “1”.
(ii) The tag transmits the ones’ complement code of in the th slot if a bit of its ID is “0”.
Following the above rules, the number of real slots in the frame is . Considering the address code “1010” of , the tag traverses each binary bit of its ID. In the ID, each “0” bit in the ID is encoded by “0101”, and each “1” bit is encoded by “1010”; they are transmitted in the th slot. Upon receiving the overlapping information, the reader isolates each ID of the tag by calculating normalized inner products of each m code and the address code of this tag. If the normalized inner product is “1”, the bit received from this tag is “1”; if the normalized inner product is “−1”, the bit received from this tag is “0”; otherwise, this tag did not send information.
Take
Figure 5 for example. The tags
concurrently transmit their IDs in the 1st slot. The first two bits in the IDs of
are
. According to the rules (i) and (ii), the bits “1” and “0” are encoded by the true code and the one’ -complement code of each tag’s address code, respectively. Using “−1” to represent “0” and “+1” to represent “1”,
transmits
,
,
transmits
,
,
transmits
,
, and
transmits
,
in the first slot. Therefore, the reader receives the final overlapping information
. The normalized inner product of the overlapping code and the address code determine whether a tag has sent data and what data to be sent. For example, the normalized inner product of
and
is “1”, which indicates that the first bit
sent is “1”; the normalized inner product of
and
is “−1”, which indicates that the second bit
sent is “0”. Consequently, the reader knows that the first two bits of
’s ID are “10”. Similarly, the reader can obtain the IDs of the other three tags.
If , the unknown tags picking this slot will participate in the next round. Then, the collection phase will be executed for several rounds until the reader cannot detect replies from unknown tags in the channel.
6. Evaluation
This section evaluates the performance of our protocol and the existing CU [
24], BUIP and MUIP [
25], and FUTI and IFUTI protocols [
27]. Also, the execution time of our protocol is compared with that of state-of-the-art unknown identification protocols.
6.1. Simulation Setting
Our protocol was implemented in Matlab and run on a ThinkPad X1 Carbon desktop computer equipped with an Intel 2.40 GHz CPU. In the simulations, there was a 302 s interval between each pair of consecutive communications from the tag to the reader and from the reader to the tags. The transmission rates in different directions were not symmetric depending on specific physical implementations and practical environments. According to the specification of the Philips I-Code system [20] and the code, we have ms, ms, ms, ms, and ms. Our simulations were executed 100 times in Matlab, and the results were averaged.
6.2. Total Execution Time
In this section, the total execution time of our protocol is analyzed and the proposed FPUI protocol is compared with some state-of-the-art protocols, including CU, BUIP and MUIP, and FUTI and IFUTI. In different applications, the number of unknown tags also varies. Therefore, in the following simulation experiments, the number N of known tags was fixed to 10,000 and the number M of unknown tags was changed in different applications. To thoroughly evaluate the performance of our protocol, two sets of simulations were conducted under two application scenarios: the scenario of low-density unknown tags and the scenario of high-density unknown tags. Furthermore, a set of simulations was conducted to evaluate the impact of the size m of the address code on the execution time.
Low-density unknown tags scenario: In this scenario, a simulation was conducted for an RFID system under low-density unknown tags. Here, the number
M of unknown tags varied from 100 to 1000 with a step of 100. As shown in
Figure 7a, the simulation results demonstrated that our FPUI protocol outperformed the advanced protocols in [
25,
27]. Specifically, the took takes 5.6 s and MUIP 18.8 s to identify 200 unknown tags, respectively. By contrast, our proposed PFUI protocol just took 0.86 s to identify 200 unknown tags, showing 84.6% and 95.4% less execution time than the IFUTI and MUIP protocols, respectively.
High-density unknown tags scenario: In this scenario, a simulation was conducted for an RFID system under high-density unknown tags. Here, the number
M of unknown tags varied from 5000 to 14,000 with a step of 1000. As shown in
Figure 7b, the simulation results demonstrated that our FPUI protocol also performed better than the existing protocols in [
25,
27]. Concretely, the IFUTI protocol took 42.7 s and the MUIP protocol 107.9 s to identify 12,000 unknown tags, respectively. By contrast, our proposed FPUI protocol only took 31.9 to identify 12,000 unknown tags, showing 25.3% and 70.4% less execution time than the IFUTI and MUIP protocols, respectively.
The simulation results in
Table 2 also show that our FPUI protocol was more efficient under the RFID scenario with low-density unknown tags and high-density unknown tags.
6.3. Impact of Address Code Variation
In this group of simulation experiments, the execution time of our protocol in an RFID system with different
m values was evaluated. The size
m of the address code was varied from 4 to 64 with a step of 2x. Meanwhile, The number
M of unknown tags was changed from 1000 to 10,000 to observe the impact of
m on the total execution time. As seen in
Figure 8, the simulation results demonstrated that our FPUI protocol achieved the best performance when
. This is because, as
m increased, the data rate decreased and the reader needed to transmit more information to the tags for their address codes. This analysis was consistent with that presented in
Section 5.2.
6.4. Impact of Missing Tags
Since our protocol assigns a unique fingerprint to each known tag, all known tags can be deactivated to remove false positives. Then, a set of simulations was conducted to evaluate the impact of the number
n of missing tags on the deactivating accuracy. As shown in
Figure 9, our protocol always deactivated all known tags regardless of the number
n of missing tags, which indicates that our protocol can achieve better performance in real open RFID systems than other existing works.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}