Abstract
In the process of steel plate production, whether cold straightening is required is significant to reduce costs and improve product qualification rates. It is not effective by adopting classic machine learning judgment algorithms. Concerning the effectiveness of ensemble learning methods on improving traditional machine learning methods, a steel plate cold straightening auxiliary decision-making algorithm based on multiple machine learning competition strategies is proposed in this paper. The algorithm firstly adopts the rough set method to simplify the attributes of the conditional factors for affecting whether the steel plate cold straightening is required, and reduce the attribute dimensions of the steel plate cold straightening auxiliary decision-making data set. Secondly, the competition of training multiple different learners on the data set produces the optimal base classifier. Finally, the final classifier is generated by training weights on the optimal base classifier and combining it with a centralized strategy. While the hit rate of good products of the final classifier is 97.9%, the hit rate of defective products is 90.9%. As such, the accuracy rate is better than the single kind of simple machine learning algorithms, which effectively improves the product quality of steel plates in practical production applications.
1. Introduction
Currently, industrial real-time databases need AI data analysis technologies to solve the problems of defect detection [1], sorting identification [2], size detection [3], visual guidance [4], etc., which help enterprises to achieve flexible production [5] and high automation. For example, the intelligent defect detection makes the manual detection to be a laborious task as the human eye is not able to distinguish the fast moving tiny objects. Furthermore, the excessive use of eyes is much easier to miss objects. AI technologies can be used to overcome these difficulties and increase detection efficiency by means of adjusting the detection accuracy according to the product detection requirements. At the same time, AI technologies can realize automatic detection, automatic processing and reducing the rate of defective products and labor costs by means of cooperating with automatic production lines, which increase the production efficiency significantly [6].
However, the classical single AI algorithm applied in the current industrial production process is still insufficient. A single AI algorithm has different prediction capabilities for different data sets, and its adaptability to multiple production environments and multiple steel plates is also insufficient. It is also easier to fall into local optimization and cannot obtain the optimal solution.
Aiming at the shortcomings of classical single AI algorithm, this project proposes an ensemble learning algorithm based on multi-machine learning, which effectively compensates for the shortcomings of a single AI algorithm and improves the prediction performance.
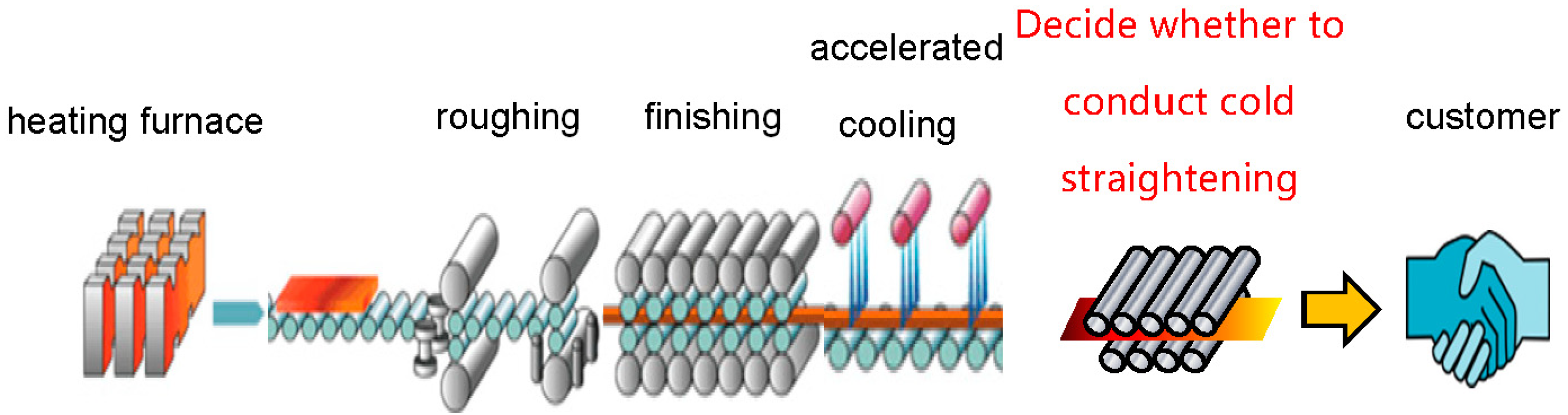
As shown in Figure 1, certain internal stress generates in the manufacturing process of steel plates [7]. The magnitude of internal stress plays a key role in the application of steel products and the effect on final products. The internal stress of steel plates is unqualified, which may cause deformation and cracks of steel plates. Detecting unqualified steel plates and performing cold straightening is the key to improving the production quality of steel plates. The accuracy of whether steel plates need cold straightening cannot be guaranteed if it is only judged by workers’ experience and naked eyes. Also, the effect is not ideal because it is usually affected by the status and quality of workers. These problems can be avoided by using AI technologies to make decisions on cold straightening of steel plates. The steel plate cold straightening auxiliary decision-making algorithm aims to predict whether the internal stress of steel products is qualified and cold straightening is necessary, which may lead to a more stable and accurate judgment on whether cold straightening is necessary in the steel plate production process.
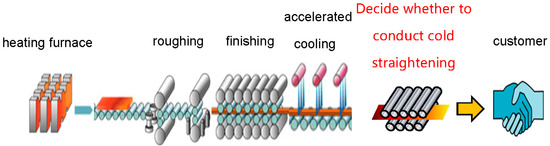
Figure 1.
Steel plate manufacturing process.
However, traditional single machine learning algorithms cannot adapt well to different types of steel plates (including steel plates of different sizes and different physical compositions, as their production environment and corresponding data can be very different) and production processes in actual production because they often fall into local optimum easily, and the adaptability of the model is limited [8]. Because a single kind of classical AI algorithm has different capabilities to process data sets with different characteristics, there is also a bias towards the data processing capabilities of different sizes and types of steel plates. Using the multi-classifier ensemble learning method can make up for the shortcomings of different classifiers and improve the final classification prediction effect. At present, it is an urgent and common problem in the steel production industry to propose a steel plate cold straightening auxiliary decision-making method with higher judgment accuracy and stronger model adaptability [9].
Ensemble learning [10] is a common statistical learning method, which is widely applied and effective. Ensemble learning usually achieves significantly better generalization performance than a single learner by combining multiple learners. In the classification problem, it enhances the performance of classification by changing the weights of training samples, learning multiple classifiers and combining these classifiers linearly.
Based on the above industrial background, this project adopts the strategy of ensemble learning to propose a new type of steel plate cold straightening auxiliary decision-making method. With the data of rough rolling [11], finishing [12] and steel plates that have not been cold straightened [13] after accelerated cold treatment [14], this project analyzes factors which play a pivotal role in the internal stress and uses ensemble learning methods to build a strong machine learning method which is able to predict if steel plate cold straightening is necessary.
By predicting the subplate that needs to be cold straightened more effectively, this model reduces the cold straightening rate, the customer quality objections caused by residual stress and is applied to improving the yield of steel products.
2. Introduction to the Steel Plate Cold Straightening Auxiliary Decision-Making Data
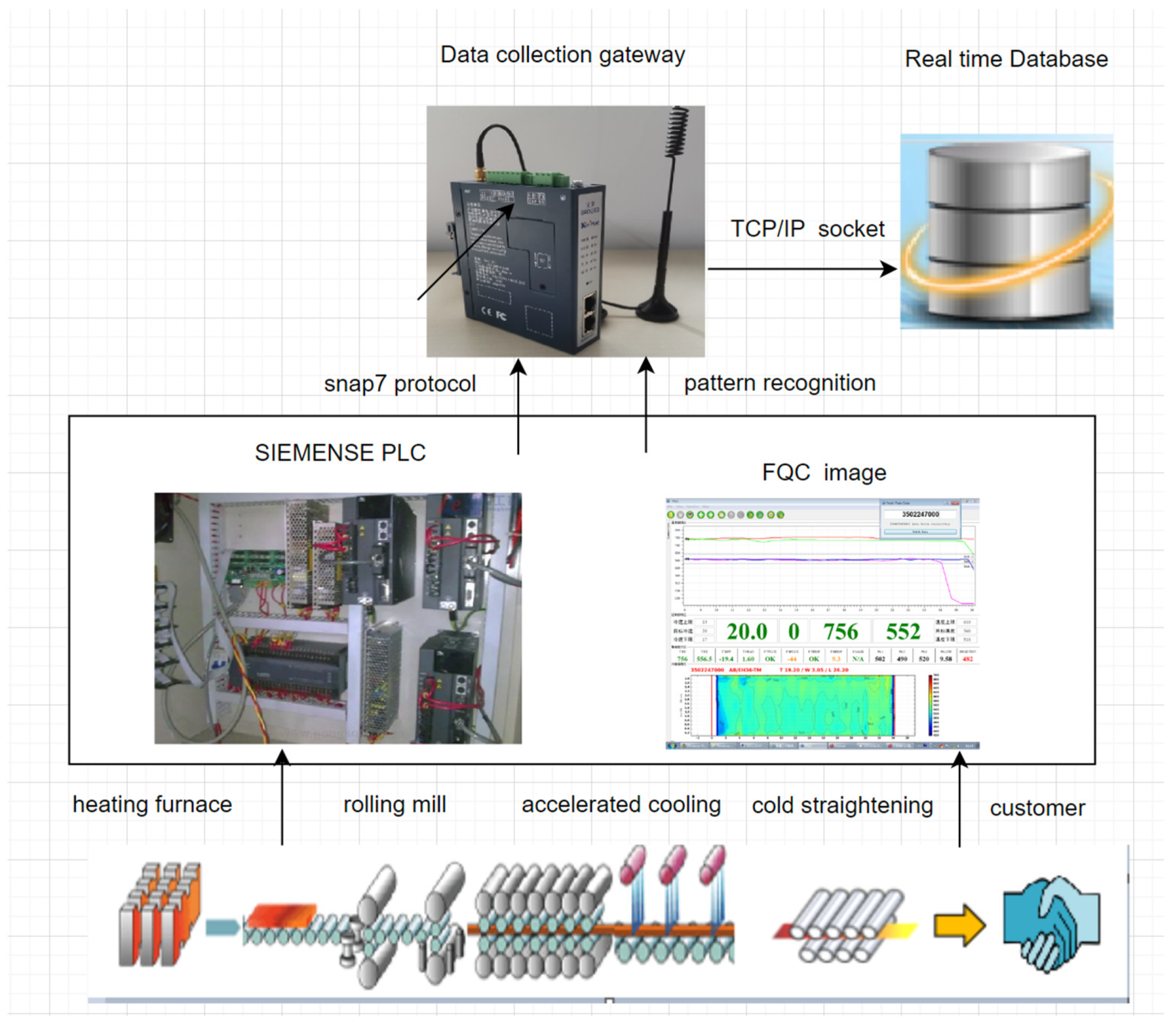
We used SIEMENSE PLC in the production of steel plates, which used snap7 technology to collect production data. In the cold straightening stage of steel plates, a patented technology that automatically recognizes the FQC image content of thick plates to obtain the corresponding data parameters in real time is used. Finally, the real-time database can be obtained by means of processing data by the data collection gateway.
The specific data acquisition process is shown in Figure 2.
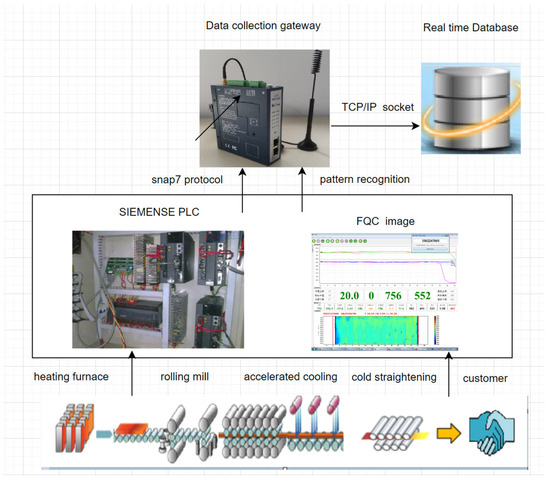
Figure 2.
Dataset acquisition process.
We selected Baosteel’s steel plates production data as the data source of this project. Since many of Baosteel’s subplates from May to July 2020 were cold straightened [15], this paper selects the data of subplates that have not been cold straightened from January to April 2020 as the subject in this study. The experiment is aimed at the steel plate production process and purposefully slices steel plates whose uniformity of preheating and sizes are different; the experimental data of the study is composed of factors about rolling thickness, temperature, torque, bending force at stages of rolling mill and finishing and attributes like the production intervals, whether the production happens in a single furnace.
The main influencing factors for the internal stress in the steel plate and whether cold straightening is required are summarized in the experimental data, which is shown in Table 1 below.

Table 1.
List of properties that may affect the internal stress in the steel plate and whether it is cold straightened or not.
3. Auxiliary Decision-Making System for Steel Plate Cold Straightening Based on Multi-Machine Learning
In the steel plate production and application, a single machine learning algorithm is usually used. However, a single learning algorithm lacks the ability to adapt to different steel plate types and manufacturing, which may lead to poor learning effects. As a result, the use of ensemble learning methods is an important strategy to effectively improve the accuracy and stability of learning.
Among numerous ensemble learning algorithms [16], the AdaBoost [17] algorithm, whose main strategy is weighted voting, is one of the most representative methods. Moreover, it follows the rule that the minority is subordinate to the majority. The AdaBoost algorithm constantly updates and optimizes the weight of each underlying algorithm through adequate training. Finally, the weight of the high-accuracy classifier is improved and the weight of the low-accuracy classifier is reduced. Consequently, the accuracy of the final integration decision is increased and the performance of the algorithm is improved during the voting process.
The rough set is an important theory for the reasoning of uncertain problems [18]. Data attribute reduction based on the rough set is a widely recognized method in dimensionality reduction of high-dimensional data [19]. This method which has been widely applied to various types of industrial data mining during recent years can be used to eliminate irrelevant attributes and reduce model complexity under basically the same decision and classification ability. The reduction result of taking the rough set is more objective and effective because it is not necessary to use any prior attribute distribution information. In this paper, a steel plate cold straightening auxiliary decision-making system based on multi-machine learning competitive strategy (MMLCS) is proposed. In addition, the rough set method is applied to blending the idea of ensemble learning and simplifying the attributes of multiple attribute factors that affect the magnitude of the internal stress and decide whether cold straightening is required in the steel plate. At the same time, the idea of ensemble learning is fused, and a multi-machine learning competitive strategy (MMLCS) is proposed.
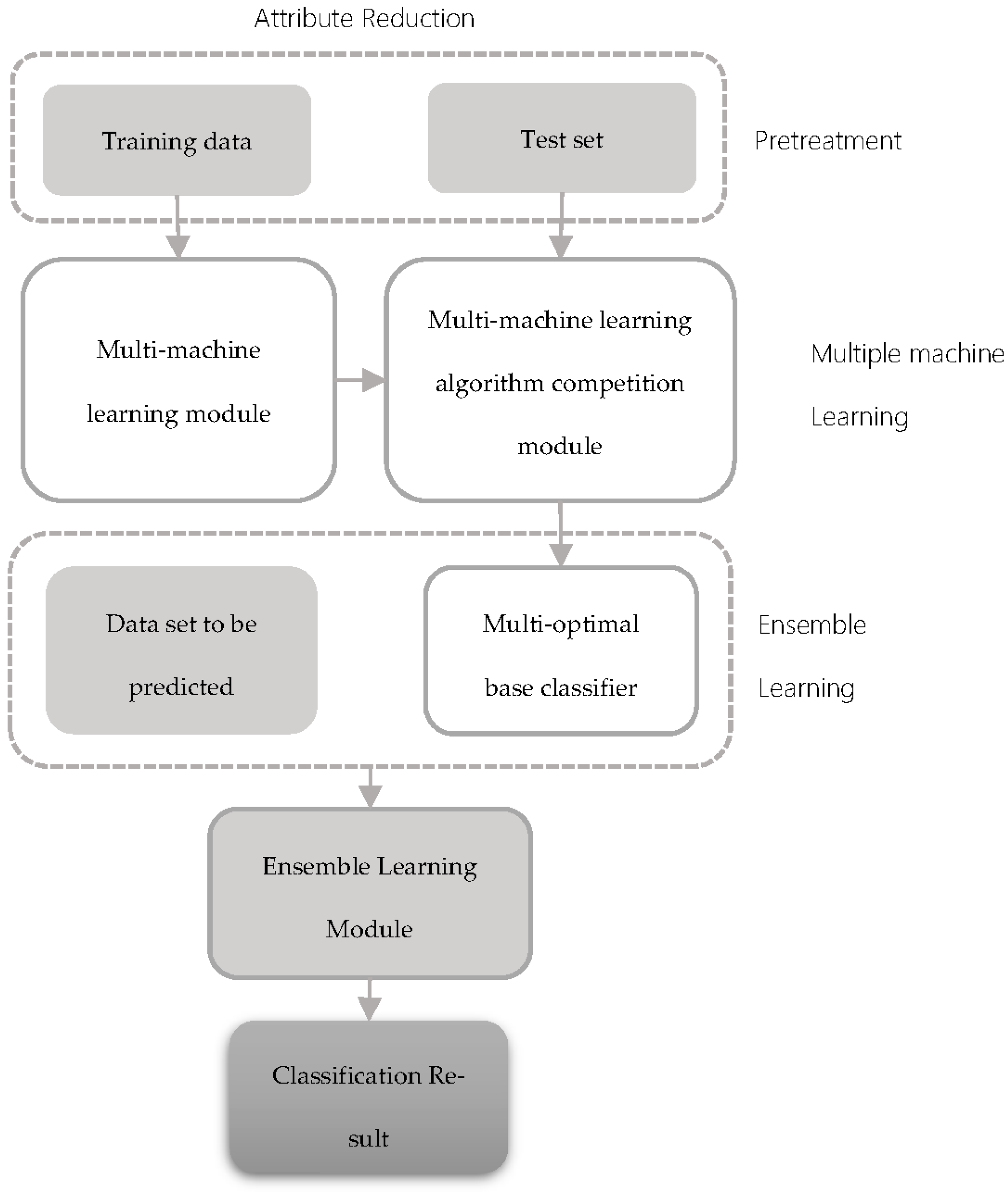
The industrial data mining algorithm model of the multi-machine learning competitive strategy is shown in Figure 3. The corresponding algorithmic framework of this model is as follows:
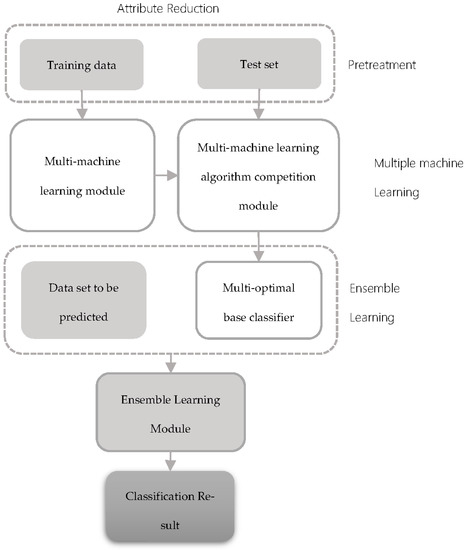
Figure 3.
Algorithmic framework of multi-machine learning competitive strategy.
This model includes data reduction modules (containing data cleaning, data discretization, rough set), multi-machine competition module, ensemble learning, and other main modules. The learning process was as follows: First, training data set attribute reduction should be done. Then, the result should be imported into the multi-machine competition module. In the multi-machine competition module, classifiers are trained through a competitive strategy. optimal classifiers (, is an odd number) are finally obtained and saved into the multi-optimal classifier module. In the end, in the ensemble learning module, a multi-optimal classifier is extracted, predicting the actual steel plate according to the integration strategy and calculating the optimal prediction results.
The following subsections will introduce some of the important modules involved in the model in detail.
3.1. Data Attribute Reduction
This cold straightening data set can be regarded as a knowledge expression system , wherein, represents the non-empty finite set of cold straightening data record objects(tuples), where the is the cold straightening record(tuple). is the set of all attributes of the cold straightening data, divided into two subsets that do not intersect, namely conditional attribute and decision attribute , conditional attribute includes all the attributes mentioned in Table 1, and the domain of decision attribute : , 1 means that cold straightening occurs, −1 means that no cold straightening occurs. : The set of values for conditional attribute , and is the domain of the property. : is an information function that assigns a value to any property of corresponding to any object , namely . The Cold Straightening Prediction Information System is a large, complex and diverse data collection containing many redundant attributes. To obtain a simplified decision table, further processing is required.
This project uses a rough set reduction method, and the reduction algorithm is introduced in the Algorithms 1:
| Algorithms 1 RS_Reduction |
| Input: Cold Straightening Forecast Information System |
| Output: after attribute reduction, wherein |
| For the algorithm steps, check Reference [20]. |
3.2. Multi-Machine Competition and Integration Modules
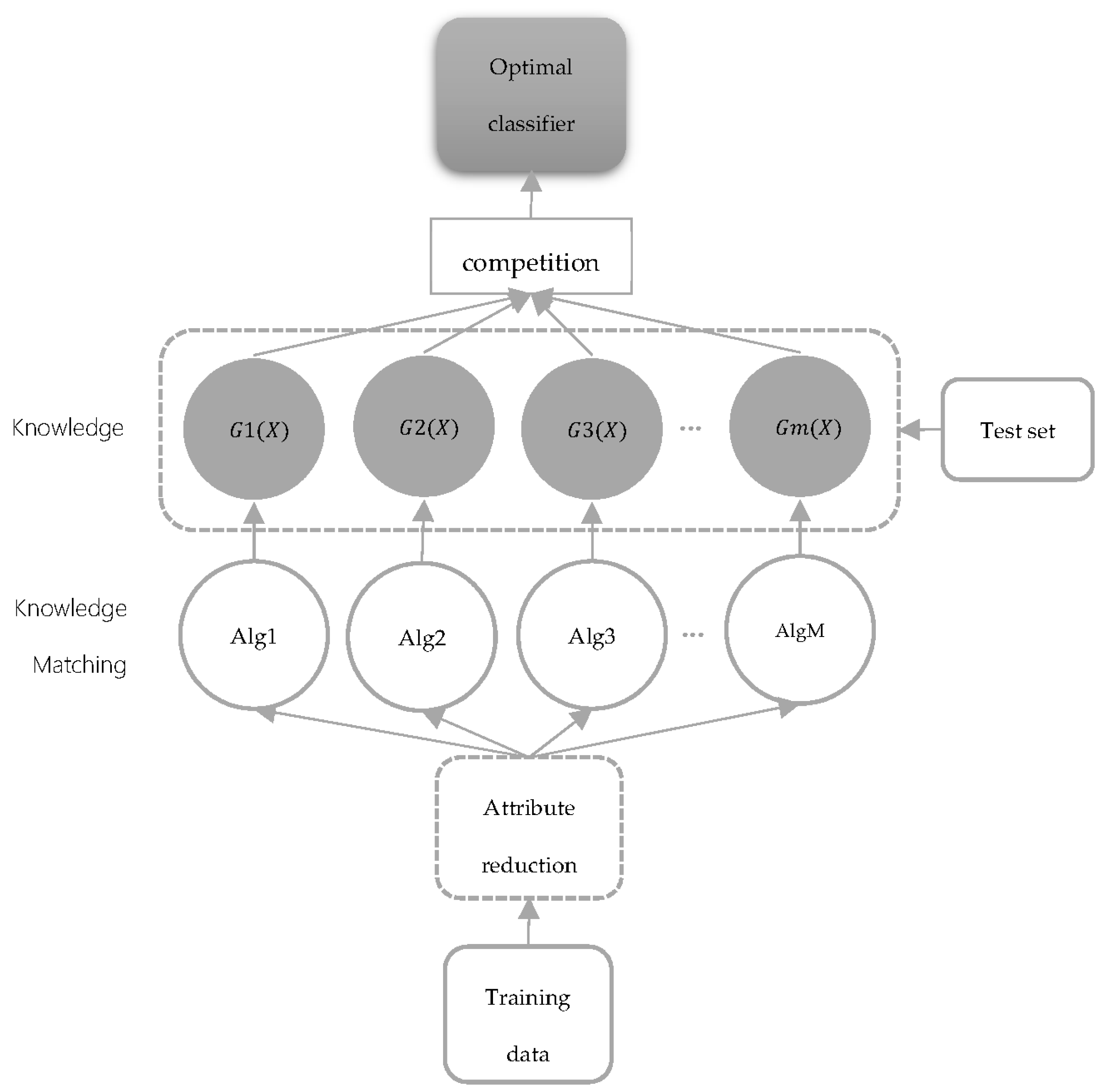
The classifier race process in multiple machine learning competitions is shown in Figure 4. Firstly, input the initialized training data, and use the rough set to reduce attributes. The simplified data is used to learn and train different algorithms, with different knowledge produced after learning. The test data is then applied to competing for knowledge. Finally, classifiers with the highest prediction accuracy are outputted and saved into the optimal classifier module.
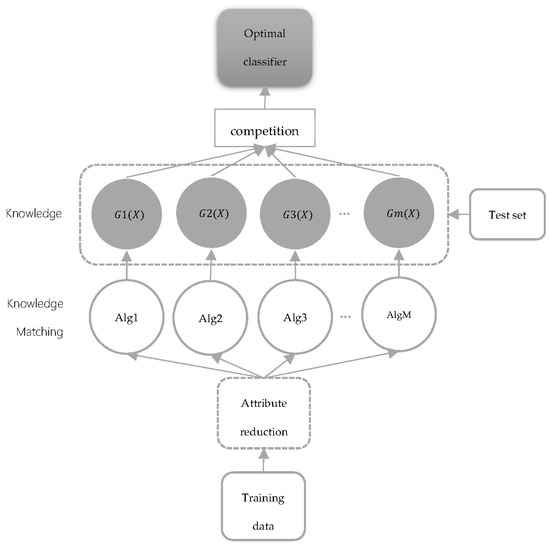
Figure 4.
Network structure of the classifier.
The key algorithmic steps in the Multiple Machine Learning Competition module are as follows:
| Algorithms 2 MML_competition |
| Input: alternative algorithm sets , |
| // |
| Training data set: Test data set: |
| // and are data sets with the same data structure as |
| Output: optimal classifiers set |
| ; |
| for (i=1; i< ; i++) |
| { |
| Substituting into for machine learning; |
| //learning process is omitted |
| Import the test data into the learned algorithm to obtain the accuracy of the prediction, recorded as . |
| //the calculation formula: |
| Wherein , , represents the number of sets, represents the conditional property of the record is substituted into algorithm , |
| } |
| for (I = l; I < ; i++) |
| { |
| for (j = l; j< ; j++) |
| { |
| Import the classifier with the best accuracy in this cycle and its accuracy into , and delete as well as =−1 in |
| } |
| } |
After obtaining the optimal classifier set , the method of ensemble learning can be applied to making predictions for cold straightening. The integration strategy uses accuracy and variance as weights, respectively. Accuracy is used as a weight for prediction first. When the outcome is uncertain, variance is used as an alternative weight for prediction.
The integration strategy is: At the initial learning stage, the prediction data set is used to learn the algorithms generated in the multi-machine learning competition module, and the prediction accuracy of the algorithms is used as the respective weights. Secondly, the prediction results in algorithms are divided into two groups according to the occurrence of cold straightening and non-occurrence of cold straightening. The weighted prediction accuracy as well as the number of algorithms in the group are counted separately. If the number of algorithms in the cold straightening group is greater than that in the no cold straightening group, and the sum of the prediction accuracy of the cold straightening group algorithm is greater than that of the no cold correction group algorithm, the prediction result is cold straightening; Alternatively, if the number of algorithms in the cold straightening group is fewer than that in the no cold straightening group, and the sum of the prediction accuracy of the cold straightening group algorithm is also fewer than that of the no cold straightening group algorithm, the prediction result is no cold straightening.
Otherwise, count the accuracy of the algorithm for the first five times separately, calculate and compare the variance of each algorithm in the group, and the smaller variance is the output of this forecast.
The specific algorithm pseudo code mentioned above is as follows:
| Algorithms 3 MML_decision |
| Input: Prediction data set:; Optimal classifiers set: ; |
| Output: Final prediction result |
| Initialize the variable ; |
| for (i = 1; I < ; i++) |
| { |
| //Learn thealgorithms in setseparately with the prediction dataset. //1 means that cold straightening occurs, −1 means that no cold straightening occurs; |
| Calculate ; and ResultList += . |
| //Count the prediction resultof each algorithm separately,and assign the accuracyof the algorithm inas a weight to. The calculation resultis added to the ResultList. |
| Coldstraightening = group(ResultList) |
| // Groupresults in the ResultList according to coldstraightening and no cold straightening, and calculate the prediction accuracy of each group. |
| } |
| ColdstraighteningCount = Count(Coldstraightening) |
| // Count the number of algorithms that coldstraightening occurs andcoldstraighteningdoes not occur respectively. |
| If |
| {(ColdstraighteningCount(1) > ColdstraighteningCount(−1) && (Coldstraightening(1) > Coldstraightening(−1)) |
| =1 |
| Else if |
| (ColdstraighteningCount(1)< ColdstraighteningCount(−1)&&(Coldstraightening(1)< Coldstraightening(−1)) |
| = −1 |
| } |
| Else |
| { |
| precisionList = Var() |
| // Compute the variance of last five accuracy of each algorithmby group, andhas the prediction accuracy ofalgorithms each time. |
| If(precisionList(1) > precisionList(−1)) |
| = −1 |
| Else |
| = 1 |
| } |
| Output the prediction result: . |
| // The value of the prediction result is the magnitude of the average which represents whether coldstraightening occurs |
| Update |
4. Experimental Results and Analysis of the Steel Plate Cold Straightening Auxiliary Decision-Making
4.1. Experimental Environment
This experiment uses the Windows10 system. Matlab7.1 and GrADS1.9 are used as the experimental platform. In the algorithmic framework of the multi-machine learning competitive strategy, the classification algorithm uses the SVM classification algorithm, C4.5 decision tree algorithm [21], random forest [22], naïve Bayes classifier [23], ANN artificial neural network classification algorithm [24] and k-near neighbor classification algorithm [25].
4.2. Experimental Data Preparation
As shown in Table 2, since many of Baosteel’s subplates from May to July 2020 were cold straightened [15], the data of subplates that were not cold straightened from January to April was selected as the subject in this study.
Table 2.
Current situation of cold straightening from January to July 2020.
The reduced attributes of the data are shown in Table 3.
Table 3.
Finally yield nine attribute variables that contribute to the key influencing factors of cold straightening.
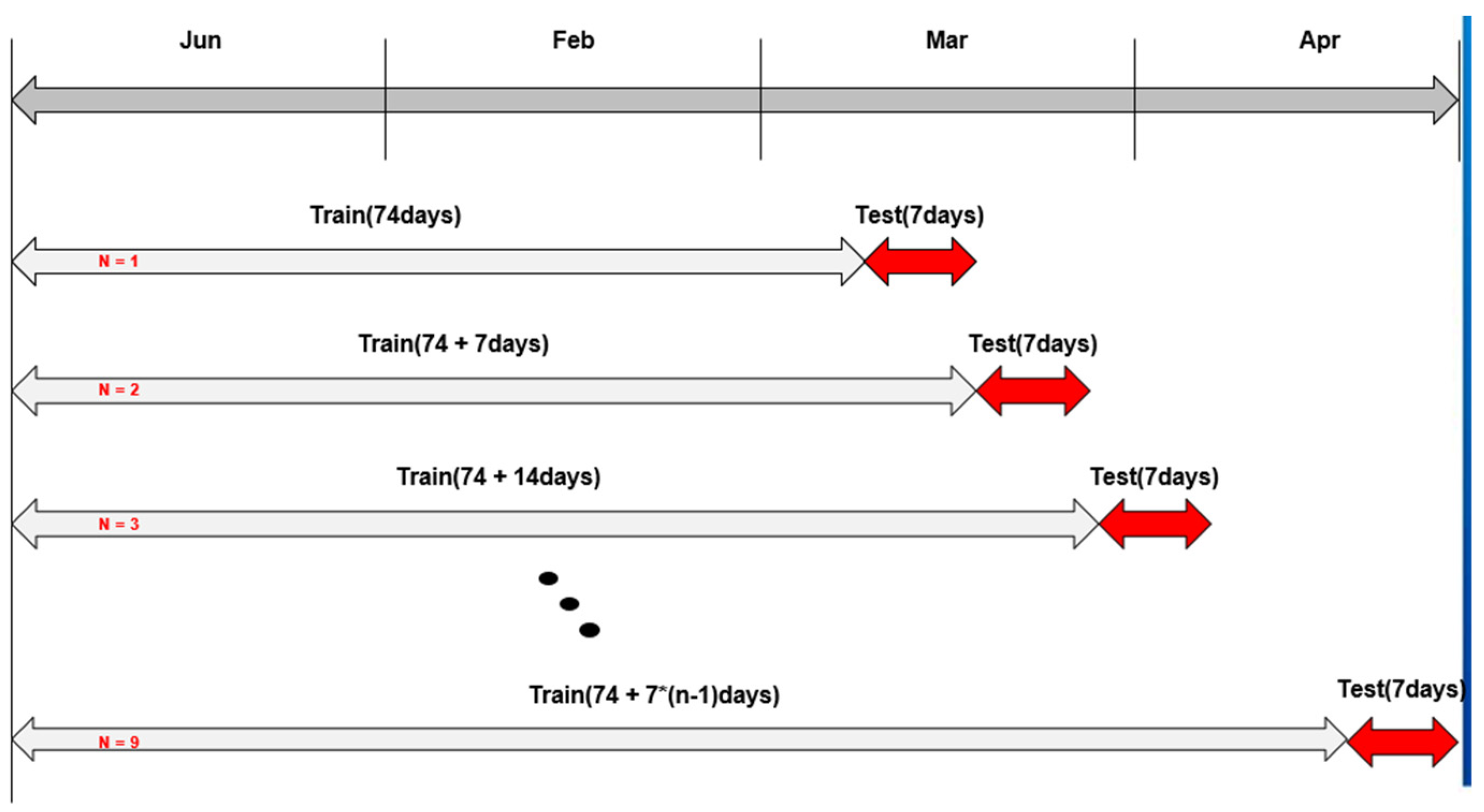
The model was cross-validated by the use of data from the first four months of 2020. The selection strategy of training data and test data is shown in Figure 5 below:
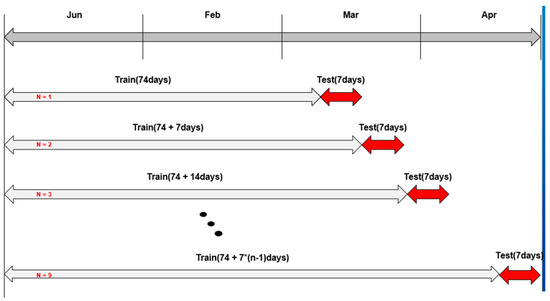
Figure 5.
Verify the rules of data selection.
The results of the cross-validation are shown in Table 4.
Table 4.
The results of the cross-validation.
Then, we choose the optimal model:
In the experiment, the calculation formulas of the classifier’s good hit rate and defective hit rate are as follows:
As shown in Table 5, by using the data from April to June 2020, the model predicts that the good hit rate is 97.9% and the defective hit rate is 90.9%.
Table 5.
Model accuracy confusion matrix.
The experimental results of this application indicate that the hit rate of good products is 97.9% and the hit rate of defective products is 90.9% by adopting the cold straightening prediction algorithm of steel plates based on the multi-machine learning competition strategy to predict whether the subplates should be cold straightened. This method improves the product quality of subplates effectively. Not only does this application solve the decision-making problem of whether subplates should be cold straightened or not, but also it reduces the costs of cold straightening of all products and the risk of product defects caused by cold straightening. Consequently, this application has important meanings in practical engineering application.
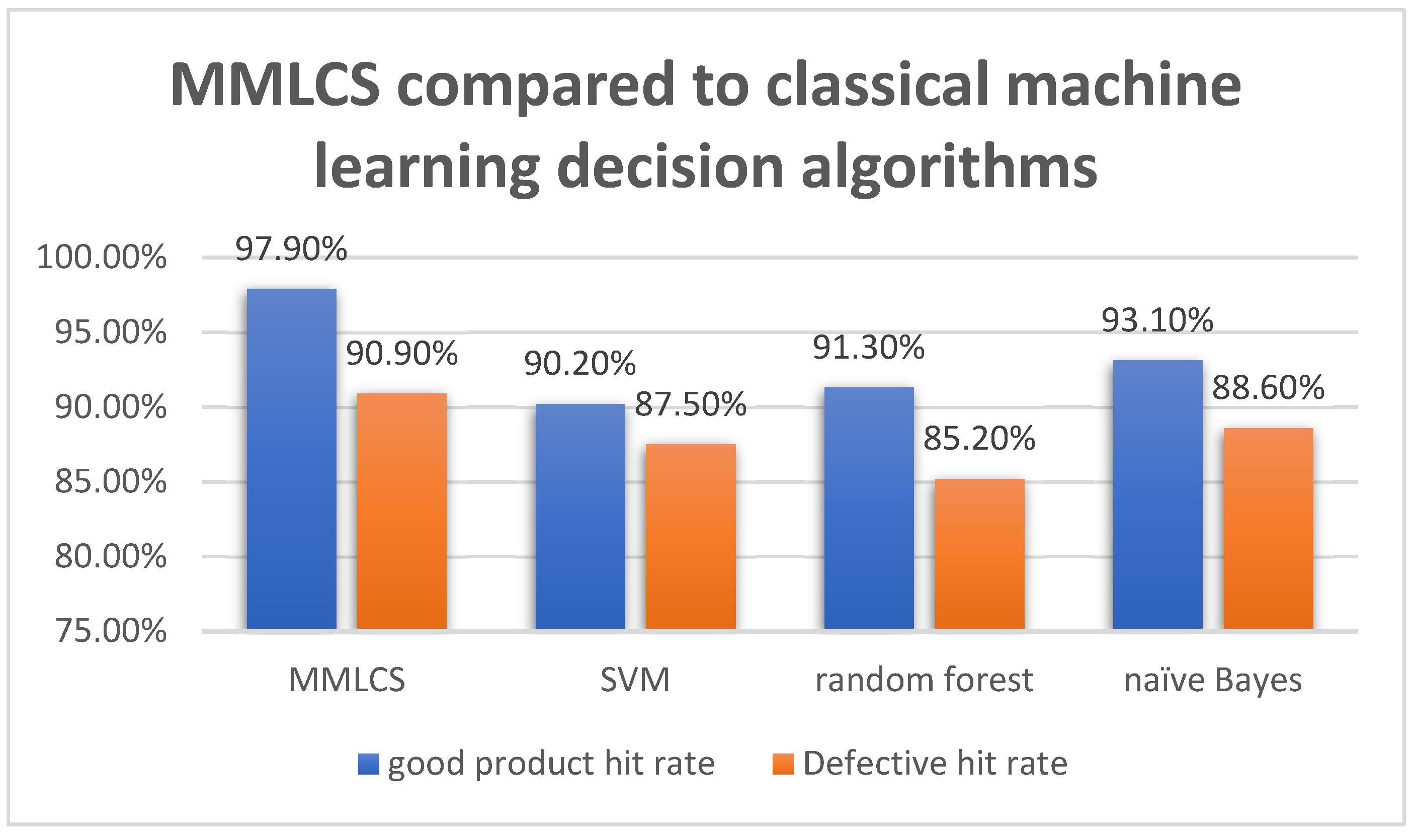
In order to compare the advantages and disadvantages of the MMLCS algorithm in this paper with other classical algorithms, we set up a comparative experiment. A contrast experiment which is used to predict the yield of steel plates is performed in the view of the steel plate cold straightening auxiliary decision algorithm based on the multi-machine learning competition strategy (MMLCS) and other classical machine learning decision algorithms (SVM, decision tree, and naïve Bayes algorithm as examples).
The experimental results are shown in Figure 6. In terms of the good product hit rate, naïve Bayes gets the highest hit rate (93.10%) among three classical machine learning decision algorithms. In comparison, the MMLCS gets 97.90% in the good product hit rate. In terms of the defective hit rate, naïve Bayes gets the best hit rate (88.60%) among the classical machine learning decision algorithms in the experiment, while MMLCS gets 90.90% in the defective hit rate, which achieves a better performance. In conclusion, the MMLCS steel plate cold straightening decision algorithm in this paper is better than the other three classic machine learning decision algorithms in terms of the good product hit rate and the defective hit rate.
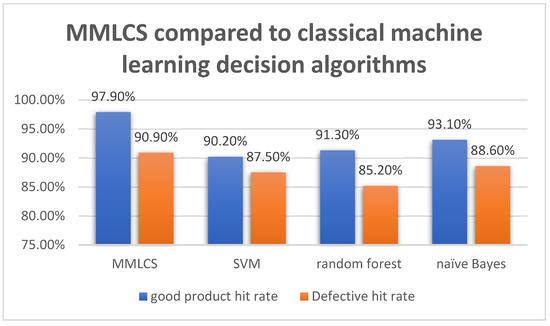
Figure 6.
MMLCS compared to classical machine learning decision algorithms.
5. Conclusions
This paper aims at solving the problem of whether cold straightening is required due to the influence of internal stress in the steel plate production process. To reduce the production cost of the steel plate and improve the qualified rate, an auxiliary decision-making method for cold straightening of steel plates is proposed. The algorithm adopts the multi-machine learning competition strategy. First of all, in order to reduce data dimension, the attributes of the conditional factors, which affect the internal stress and whether steel plates required to be cold straightened, should be reduced. Secondly, the competition of training multiple different learners on the data set produces the optimal base classifier. Finally, the final classifier is generated by training the weights on the optimal base classifier and combining it with a centralized strategy. Good application results are conducive to reducing the production cost of the steel plate and improving the qualified rate. In practical engineering, this research method can also form a series of cold straightening prediction model libraries related to actual model products and achieve the effect of intelligent production by establishing prediction models of subplates with different types. Additionally, product qualities are effectively improved and production costs are significantly reduced. In sum, the method proposed in this paper is well worth being popularized.
Author Contributions
Conceptualization, Z.-H.D., R.-H.W. and J.-H.G.; methodology, Z.-H.D.; software, R.-H.W. and J.-H.G.; validation, Z.-H.D., R.-H.W. and J.-H.G.; formal analysis, Z.-H.D.; investigation, Z.-H.D.; resources, R.-H.W.; data curation, Z.-H.D.; writing—original draft preparation, Z.-H.D.; writing—review and editing, R.-H.W.; visualization, R.-H.W.; supervision, Z.-H.D.; project administration, R.-H.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lu, L.; Hou, J.; Yuan, S.; Yao, X.; Li, Y.; Zhu, J. Deep learning-assisted real-time defect detection and closed-loop adjustment for additive manufacturing of continuous fiber-reinforced polymer composites. Robot. Comput. Integr. Manuf. 2023, 79, 102431. [Google Scholar] [CrossRef]
- Chen, X.; Huang, H.; Liu, Y.; Li, J.; Liu, M. Robot for automatic waste sorting on construction sites. Autom. Constr. 2022, 141, 104387. [Google Scholar] [CrossRef]
- PostureCo Inc.; Researchers Submit Patent Application. Method and System for Postural Analysis and Measuring Anatomical Dimensions from a Digital Image Using Machine Learning, for Approval (USPTO 20190347817). J. Robot. Mach. Learn. 2019. [Google Scholar]
- Zhang, F.; Niu, G. Research on Medical Image Processing Technology based on Machine Vision. Basic Clin. Pharmacol. Toxicol. 2020, 127, 156–157. [Google Scholar]
- Petrali, P.; Isaja, M.; Soldatos, J.K. Edge Computing and Distributed Ledger Technologies for Flexible Production Lines: A White-Appliances Industry Case. IFAC-Pap. 2018, 51, 388–392. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, W.; Wang, P. Design of machine vision system for inspection of rail surface defects. J. Electron. Meas. Instrum. 2010, 24, 6. [Google Scholar] [CrossRef]
- Zeng, J.; Su, L.; Xu, L.; Zhang, X.; Zhang, Q. Research on stress detection technology in inverse magnetostrictive effect steel plate. J. Mech. Eng. 2014, 50, 17–22. [Google Scholar] [CrossRef]
- Wu, Y.; Huang, S.; Ji, H.; Zheng, C.; Bai, C. A novel Bayes defect predictor based on information diffusion function. Knowl. Based Syst. 2018, 144, 1–8. [Google Scholar] [CrossRef]
- Qiang, W. High-strength sheet straightening machine after heat treatment. Metall. Management. 2022, 11, 22–24. [Google Scholar]
- Tsai, C.F.; Lin, W.C. Feature Selection and Ensemble Learning Techniques in One-Class Classifiers: An Empirical Study of Two-Class Imbalanced Datasets. IEEE Access 2021, 9, 13717–13726. [Google Scholar] [CrossRef]
- Xiao, X.; Ye, B.; Yong, H.; Dong, B. Study on the influence of furnace temperature on the final rolling temperature of a roughing mill. Ind. Heat. 2021, 50, 1–3, 11. [Google Scholar] [CrossRef]
- Xue, W.; Gong, D.; Wu, D.; Liu, X.; Wang, G. Research on the adaptive strategy of hot continuous rolling temperature control. Mater. Sci. Technol. 2009, 17, 389–392. [Google Scholar]
- He, X.; Lv, X.; Wu, Z.; Zhao, K.; Yang, M. Effect of cold treatment on M6C type carbides in 16Cr14Co12Mo5Ni2 bearing steel. Trans. Mater. Heat Treat. 2019, 40, 96–102. [Google Scholar]
- Zhao, L.; Zhang, Y. Research on internal stress simulation of reversible cold rolling and deformation control of vertical roller side rolling. J. Aeronaut. Mater. 2006, 26, 8–11. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Zhao, S. Risks and countermeasures of cold correction of thick plates and high-strength steel plates. Baosteel Technol. 2019, 69–74. [Google Scholar]
- Sun, J.; Wu, S.; Zhang, H.; Zhang, X.; Wang, T. Based on the multi-algorithm hybrid method to predict the slope safety factor-- stacking ensemble learning with bayesian optimization. J. Comput. Sci. 2022, 59, 101587. [Google Scholar] [CrossRef]
- Yan, J.H.; Bai, X.H.; Zhang, W.Y.; Xiao, Y.Q.; Chatwin, C.; Young, R.; Birch, P. No-reference image quality assessment based on AdaBoost BP neural network in wavelet domain. J. Syst. Eng. Electron. 2019, 30, 223–237. [Google Scholar]
- Liu, G.J.; Zhang, Y. Credit Assessment of Contractors: A Rough Set Method. Tsinghua Sci. Technol. 2006, 11, 357–362. [Google Scholar] [CrossRef]
- Zhang, W.X.; Qiu, G.F.; Wu, W.Z. A general approach to attribute reduction in rough set theory. Sci. China 2007, 50, 188–197. [Google Scholar] [CrossRef]
- Yang, X.; Wang, X.; Kang, J. Multi-granularity decision rough set attribute reduction algorithm under quantum particle swarm optimization. IET Cyber-Syst. Robot. 2022, 4, 25–37. [Google Scholar] [CrossRef]
- Jin, C.; Li, F.; Ma, S.; Wang, Y. Sampling scheme-based classification rule mining method using decision tree in big data environment. Knowl. Based Syst. 2022, 244, 108522. [Google Scholar] [CrossRef]
- Kang, M.; Liu, Y.; Wang, M.; Li, L.; Weng, M. A random forest classifier with cost-sensitive learning to extract urban landmarks from an imbalanced dataset. Int. J. Geogr. Inf. Sci. 2022, 36, 496–513. [Google Scholar] [CrossRef]
- Liu, P.; Zhao, H.-H.; Teng, J.-Y.; Yang, Y.-Y.; Liu, Y.-F.; Zhu, Z.-W. Parallel naive Bayes algorithm for large-scale Chinese text classification based on spark. J. Cent. South Univ. 2019, 26, 1–12. [Google Scholar] [CrossRef]
- Krishnamoorthy, K.; Sasikumar, T. ANN-based prediction of ultimate strength of carbon/epoxy tensile specimen using acoustic emission RMS data. Int. J. Mater. Prod. Technol. 2016, 53, 61. [Google Scholar] [CrossRef]
- Ghosh, S.; Singh, A.; Kavita; Jhanjhi, N.Z.; Masud, M.; Aljahdali, S. SVM and KNN Based CNN Architectures for Plant Classification. Comput. Mater. Contin. 2022, 71, 4257–4274. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).