
A Framework to Build a Big Data Ecosystem Oriented to the Collaborative Networked Organization

 , , and
, , and
Abstract
1. Introduction
2. Literature Review
2.1. Collaborative Networked Organization (CNO)
- (a)
- Goal-oriented continuous production-driven networks: These are CNOs that remain stable for a long period of time with well-defined roles. Examples of this kind of CNO are the supply chains (SC) and collaborative smart grids of all business sectors and Virtual Governments (VG), i.e., an alliance of governmental organizations (e.g., city hall, tax office, cadastre office and civil infrastructure office) that combine their services through the use of computer networks to provide integrated services to citizens through a common front-end.
- (b)
- Goal-oriented grasping opportunity-driven networks: These are CNOs composed of groups of independent organizations or individuals sharing skills and resources, dynamically created in response to some business opportunity within a limited time window. This kind of CNO can be classified as a Virtual Organization (VO), Dynamic Virtual Organization (DVO)/virtual enterprises (VE), Extended Enterprise (EEs) and Virtual Teams (VT). Examples of each one of these CNOs can be found in [11].
- (c)
- Long-term breeding environment networks (VBE), which are a group of organizations and supporting institutions committed to a long-term cooperation agreement, complying with common operation principles and infrastructures, with the main goal of increasing their preparedness for the rapid configuration of temporary alliances for collaboration in potential VOs. In the literature, four types of VBEs have been identified: industry clusters, composed of groups of inter-related industries geographically concentrated and inter-connected by the flow of goods and services, which drive wealth creation in a region, primarily through the export of goods and services; business ecosystems, a set of organizations that have resources and act together cooperatively or competitively to form a unique independent system (examples of these CNOs are platform-based ecosystems (Apple or Google), start-up ecosystems (Canvas) or mobility ecosystems (Uber)); disaster rescue networks, a strategic alliance of governmental/nongovernmental organizations specialized in rescue operations in case of disasters; virtual laboratories (VL), such as the project carried out by the Ministry of Education of India to provide remote access for students at all levels to laboratories in various disciplines of science and engineering, to perform the experiments remotely.
- (d)
- Long-term professional virtual communities (PVC): These are similar to VO breeding environment networks but composed of human professionals (self-employees, freelancers, etc.) that form a long-term strategic alliance to ensure they are prepared to react quickly to business opportunities through the dynamic creation of temporary VTs. An example of a PVC is the European Society of Concurrent Enterprising Network, a nonprofit association bringing together academics, researchers and industry to exchange ideas, views, practices and the latest research and developments in the field of concurrent enterprising.
2.2. Big Data in the CNO
2.3. Big Data Frameworks Oriented to a CNO
- None of the existing frameworks include all dimensions. Therefore, they lack the fundamental aspects for a big data ecosystem oriented to a CNO.
- Frameworks must complement the levels dimension, utilizing the sub-dimension explicit in the design of the CNO. Thus, they lack a graphic model that shows levels in any manifestation of CNO.
- Frameworks must extend the approaches dimension through the Inclusive sub-dimension, which can improve the processing of large datasets in the CNO.
- Frameworks do not indicate the degree of interoperability among the participants. Therefore, frameworks must complement the interoperability dimension through the sub-dimension maturity model.
- Frameworks do not include alternatives for big data analysis techniques. Therefore, frameworks must extend the big data assurance dimension using the sub-dimension techniques guide.
- Frameworks should add the programmable modules dimension, which allows the intelligent processing of big data in the CNO.
- Each framework limits its orientation to a specific CNO’s manifestation. Those of Li et al. [29], Ilie-Zudor et al. [30] and Wang et al. [31] are oriented to SC; Klievink et al.’s [32] is oriented to VG; Chen et al.’s [33] is oriented to PVC; Intezari and Gressel’s [34] is oriented to VBE; Sadic et al.’s [35] is oriented to VE; Brisimi et al.’s [36] is oriented to VO; Yi et al.’s [37] is oriented to VL; and Orenga-Roglá and Chalmeta’s [38] is oriented to EE.
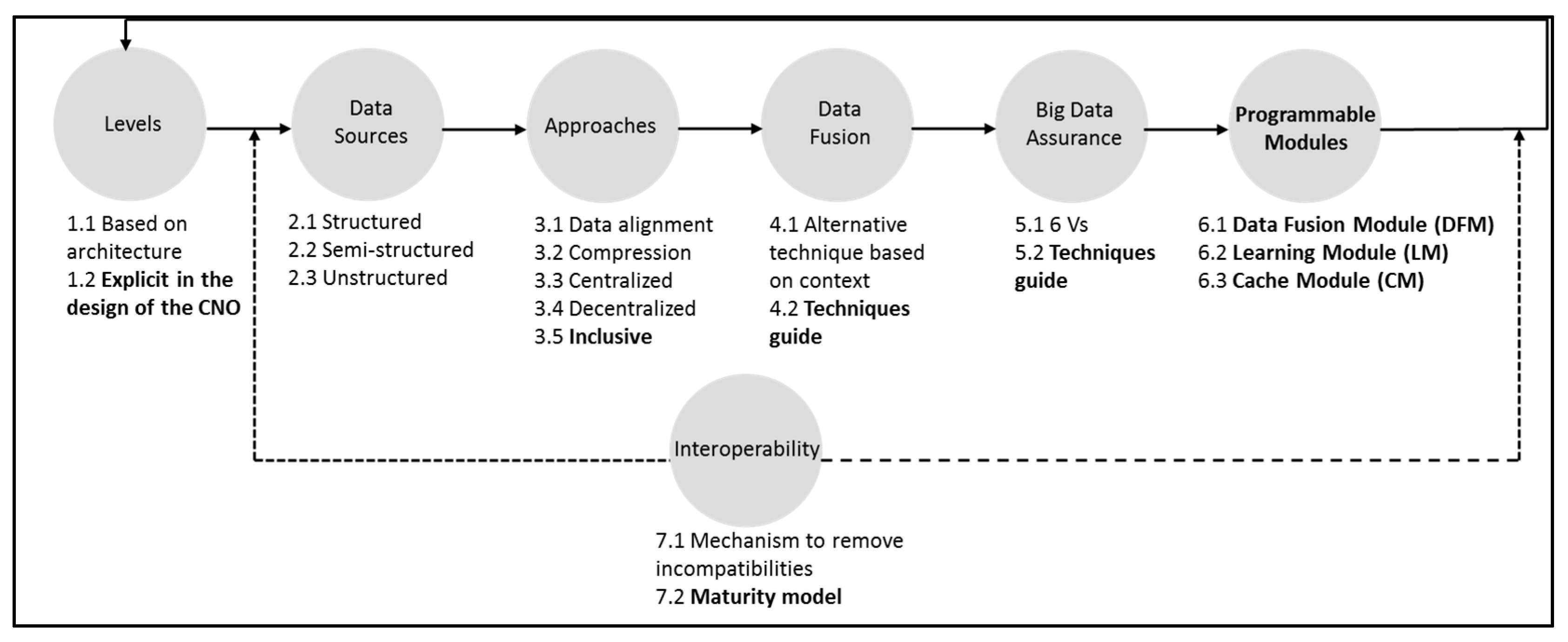
3. Proposed Framework
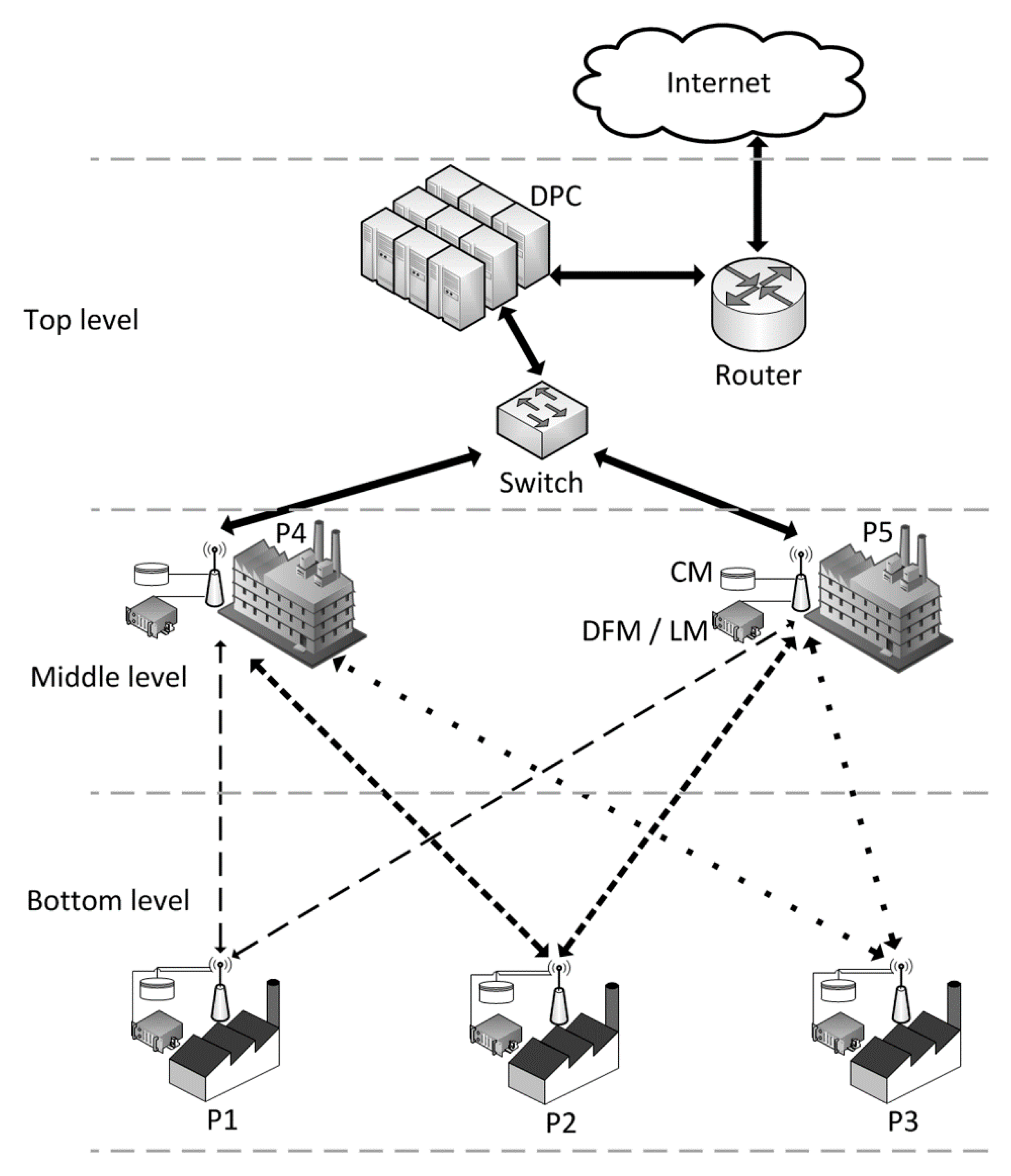
3.1. Levels Dimension
- The top level: A CNO’s participant is located here. It has the greatest processing resources and accessibility to the Internet. Participants’ requests are attended by a Data Processing Center (DPC). The DPC processes structured, semi-structured and/or unstructured datasets using two options: (1) the local environment: Hadoop, relational database management system, etc.; and (2) services in the cloud: Amazon Web Services (AWS), Microsoft Azure, etc. The DPC can access content in social networks, the information in the cloud, and so on.
- The middle level: From 1 to n participants are located here. They have mid-range infrastructures and are close to the DPC and function as intermediate nodes between the extreme levels. Additionally, they can process and respond to some bottom-level requests without consulting the DPC; see the approaches dimension. This level is linked at high speed with the DPC to allow the interoperability and fusion of global data in the shortest possible time. The DFM, LM and CM components are explained in the programmable modules dimension.
- The bottom level: From 0 to n participants are located here. They have low-end infrastructures or are further from the DPC compared to the middle level. They are served by multiple middle-level participants. The bottom level provides data to enrich the analysis carried out in the higher levels. However, it can store information processed and replicated by the middle level, such as the most popular information in the CNO. Just like the bottom level, the middle level can also store the most popular information.
3.2. Data Sources Dimension
3.3. Approaches Dimension
- Data alignment: This reduces errors in the data to be processed in the upper level. Each CNO’s participant must transform their data from its specific orientation to collaborative orientation before data fusion. This challenge can be overcome by using methods for data alignments, such as the primary key, indexes, heuristic matching, Monte Carlo simulations or cross-correlation analysis methods.
- Compression: This reduces the use of resources in the CNO, such as data transfer in the network, disk space, DPC processing and power consumption. The CNO may use lossy compression and lossless compression methods.
- Centralized: This sub-dimension combines a CNO’s global data sources in the DPC. Thus, a participant may request information from the DPC when: (1) local information is not enough or (2) the middle level does not satisfy the request. This approach processes data in two ways: streaming processing to obtain results in real time and batch processing for extended processing.
- Decentralized: This allows the participant to take advantage of the local and/or the most popular information of the CNO; the latter is replicated from the level immediately superior to the participant. Thus, the participant can make decisions without consulting their superior level. Therefore, when all participants need to send requests to the DPC (centralized), the decentralized approach can consume fewer resources, including during networking and processing.
- Inclusive: The centralized approach avoids robust local infrastructure for each participant because it moves computation to the top level. However, big data generated in the CNO can overwhelm this fully centralized approach. The CNO-BD framework extends this dimension through the inclusive sub-dimension to adaptively choose the processing, as follows: (1) local in each participant (decentralized), (2) distributed between local and other participants, (3) global in the DPC (centralized) and/or (4) simultaneous processing through the three previous types. This approach considers the content of the data and their relationships. Thus, the data processing is distributed among the participants which may balance the workload with many requests for large datasets. The distribution of data processing has two characteristics: (1) the data can be transferred to a participant from both DPC or requesting node and (2) data transfer can be avoided by using the most popular CNO information. As a result, the DPC only processes information that is not accessible at the two lower levels. The inclusive approach uses techniques and components of the data fusion dimension, the big data assurance dimension and the programmable modules dimension. This synergy allows the intelligent processing of big data.
3.4. Data Fusion Dimension
3.5. Big Data Assurance Dimension
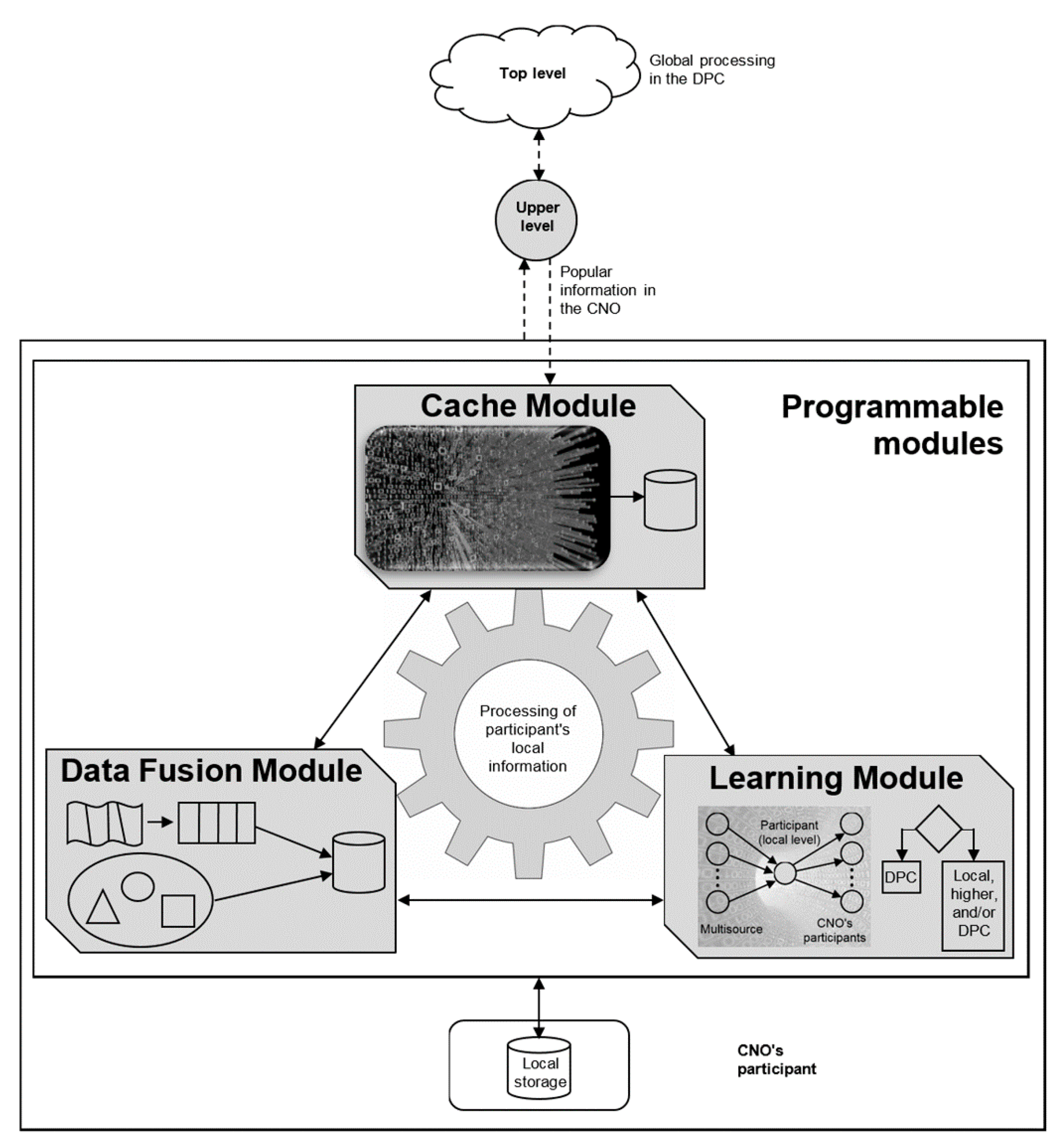
3.6. Programmable Modules Dimension
- Data Fusion Module (DFM): This module takes advantage of the CNO participant’s local data for two main purposes: The first is the preprocessing of data through the approaches: data alignment, compression, decentralized or inclusive (see the approaches dimension). Preprocessing fulfills the participant’s requirements. The second is data fusion based on the techniques shown in Table 3. Participants’ requests are resolved without consulting a higher level in most cases. Thus, data fusion uses the information of both the other two modules and the participants. If there is no success, the DFM notifies the Learning Module (LM), which takes control and decides on the proper processing approach. On the other hand, data fusion can be performed globally in the DPC; this process depends on the LM’s decisions.
- Learning Module (LM): This module has two main functions. First, it collects, mines and exploits the knowledge generated in a CNO. LM implements the big data analysis techniques shown in Table 5. It monitors and evaluates the information received or issued by each participant. Additionally, it generates information and patterns from incoming heterogeneous sources and output behavior. The former may be used in big data analysis types: descriptive, predictive and prescriptive. The second function of the LM happens after the DFM passes the processing control to LM. This is because local information is not enough to meet the participant’s request. Then, LM decides which of the two approaches proceed according to the learning and patterns generated: centralized or inclusive; see the approaches dimension. Regardless of the type of processing approach, the resulting information is replicated and given to the requesting participant.
- Cache Module (CM): This module reduces the number of requests of the next higher level and/or of the DPC by using cache. Cache allows each CNO’s participant to register and use both: (1) the most popular valuable information of the CNO and (2) metadata embedded in big data fragments that describe their attributes and characteristics. The acquired cache is quickly classified, compressed and adapted; this maximizes CM’s capabilities for big data and CNO’s dynamism. CM can substitute information based on cold data for information based on hot data by means of a data structure that orders the information based on its temperature. As a result, CM has the most popular information of the CNO. Additionally, the CM considers cache in real time, which allows information to be obtained on the fly through interoperability between participants. Thus, CM can answer some participant’s requests without consulting the superior level. Hence, CM can reduce the consumption of resources of the CNO.
3.7. Interoperability Dimension
- improvement strategies in the short and medium term (TO-BE situation);
- human resources’ view;
- the flexibility of use in scenarios of collaboration other than business such as VT, disaster rescue networks and PVC.
4. Framework Validation
4.1. Expert Assessment
4.2. Case Study
4.2.1. Case Study Selection
- Alpha University: This is a university that teaches undergraduate and graduate students and offers several academic programs. It periodically delivers results to the Admin Pub. Furthermore, it generates information related to educational indicators, student profiles, approval and dropout rates. Alpha University is a pseudonym used to refer to a CNO’s participant in this case study. Similarly, pseudonyms are used for other participants involved in the case study to preserve confidentiality.
- Admin Pub: This is the public administration that governs the state belonging to the country of Mexico. It issues information on events, achievements and areas of opportunity related to educational and social aspects. Although the Alpha University and the state work under the direction of the Admin Pub. The Admin Pub also has a social commitment with the Society Group to ensure the growth and well-being of the people.
- Society Group: This is a group of interrelated people in a common context in time and space. They often share belief systems and economic, ideological, political or educational philosophies. Society Group issues information on their degree of satisfaction with educational aspects that have been achieved or failed.
4.2.2. Understanding the Project
4.2.3. Data Collection
4.2.4. Data Analysis
5. Discussion
5.1. Contributions to Theory
- obtaining unfavorable results such as gaps related to interoperability analysis of the organizational structure, business processes or services [51];
- inadequate guides for the use of the different big data techniques [52];
- a lack of ability to filter out irrelevant information to reduce unnecessary costs [53];
- suboptimal handling of data connections [52];
- a lack of contextual information [54];
- a lack of adaptation to approaches according to requirements, that is, a lack of intelligent processing of big data [54].
5.2. Implications and Suggestions for Practice
5.3. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Camarinha-Matos, L.M.; Afsarmanesh, H.; Galeano, N.; Molina, A. Collaborative networked organizations—Concepts and practice in manufacturing enterprises. Comput. Ind. Eng. 2009, 57, 46–60. [Google Scholar] [CrossRef]
- Scavarda, M.; Reyes Levalle, R.; Lee, S.; Nof, S.Y. Collaborative e-work parallelism in supply decisions networks: The chemical dimension. J. Intell. Manuf. 2015, 28, 1337–1355. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M.; Afsarmanesh, H. Collaborative networks: A new scientific discipline. J. Intell. Manuf. 2005, 16, 439–452. [Google Scholar] [CrossRef]
- Gupta, K.; Yang, Z.; Jain, R.K. Urban Data Integration Using Proximity Relationship Learning for Design, Management, and Operations of Sustainable Urban Systems. J. Comput. Civ. Eng. 2019, 33, 1–44. [Google Scholar] [CrossRef]
- Kumari, A.; Tanwar, S.; Tyagi, S.; Kumar, N.; Parizi, R.M.; Choo, K.-K.R. Fog data analytics: A taxonomy and process model. J. Netw. Comput. Appl. 2019, 128, 90–104. [Google Scholar] [CrossRef]
- Ramkumar, D.; Annadurai, C.; Nirmaladevi, K. Continuous authentication consoles in mobile ad hoc network (MANET). Clust. Comput. 2017, 22, 7777–7786. [Google Scholar] [CrossRef]
- Chae, B. A General framework for studying the evolution of the digital innovation ecosystem: The case of big data. Int. J. Inf. Manag. 2019, 45, 83–94. [Google Scholar] [CrossRef]
- Khalifa, S.; Elshater, Y.; Sundaravarathan, K.; Bhat, A.; Martin, P.; Imam, F.; Rope, D.; McRoberts, M.; Statchuk, C. The Six Pillars for Building Big Data Analytics Ecosystems. ACM Comput. Surv. 2016, 49, 1–36. [Google Scholar] [CrossRef]
- Moreno, J.; Serrano, M.A.; Fernandez, E.B.; Fernández-Medina, E. Improving Incident Response in Big Data Ecosystems by Using Blockchain Technologies. Appl. Sci. 2020, 10, 724. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M.; Fornasiero, R.; Ramezani, J.; Ferrada, F. Collaborative Networks: A Pillar of Digital Transformation. Appl. Sci. 2019, 9, 5431. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M.; Afsarmanesh, H. Collaborative Networks; Springer: Boston, MA, USA, 2006; pp. 26–40. [Google Scholar]
- Rezaei, R.; Chiew, T.K.; Lee, S.P. An interoperability model for ultra large scale systems. Adv. Eng. Softw. 2014, 67, 22–46. [Google Scholar] [CrossRef]
- Chalmeta, R.; Pazos, V. A step-by-step methodology for enterprise interoperability projects. Enterp. Inf. Syst. 2014, 9, 436–464. [Google Scholar] [CrossRef]
- Ramadan, M.; Shuqqo, H.; Qtaishat, L.; Asmar, H.; Salah, B. Sustainable Competitive Advantage Driven by Big Data Analytics and Innovation. Appl. Sci. 2020, 10, 6784. [Google Scholar] [CrossRef]
- Demirdöğen, G.; Diren, N.S.; Aladağ, H.; Işık, Z. Lean Based Maturity Framework Integrating Value, BIM and Big Data Analytics: Evidence from AEC Industry. Sustainability 2021, 13, 10029. [Google Scholar] [CrossRef]
- Ponnusamy, V.K.; Kasinathan, P.; Madurai Elavarasan, R.; Ramanathan, V.; Anandan, R.K.; Subramaniam, U.; Ghosh, A.; Hossain, E. A Comprehensive Review on Sustainable Aspects of Big Data Analytics for the Smart Grid. Sustainability 2021, 13, 13322. [Google Scholar] [CrossRef]
- Van den Broek, T.; van Veenstra, A.F. Governance of big data collaborations: How to balance regulatory compliance and disruptive innovation. Technol. Forecast. Soc. Chang. 2018, 129, 330–338. [Google Scholar] [CrossRef]
- Storey, V.C.; Song, I.-Y. Big data technologies and Management: What conceptual modeling can do. Data Knowl. Eng. 2017, 108, 50–67. [Google Scholar] [CrossRef]
- Manogaran, G.; Varatharajan, R.; Lopez, D.; Kumar, P.M.; Sundarasekar, R.; Thota, C. A new architecture of Internet of Things and big data ecosystem for secured smart healthcare monitoring and alerting system. Future Gener. Comput. Syst. 2018, 82, 375–387. [Google Scholar] [CrossRef]
- Poongavanam, E.; Kasinathan, P.; Kanagasabai, K. Optimal Energy Forecasting Using Hybrid Recurrent Neural Networks. Intell. Autom. Soft Comput. 2023, 36, 249–265. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, J.; Zhu, X.; Zhang, C. Network Representation Learning: A Survey. IEEE Trans. Big Data 2020, 6, 3–28. [Google Scholar] [CrossRef]
- Jenkins, M.P.; Gross, G.A.; Bisantz, A.M.; Nagi, R. Towards context aware data fusion: Modeling and integration of situationally qualified human observations to manage uncertainty in a hard+soft fusion process. Inf. Fusion 2015, 21, 130–144. [Google Scholar] [CrossRef]
- Drosou, M.; Jagadish, H.V.; Pitoura, E.; Stoyanovich, J. Diversity in Big Data: A Review. Big Data 2017, 5, 73–84. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S. Expanded cloud plumes hiding Big Data ecosystem. Future Gener. Comput. Syst. 2016, 59, 63–92. [Google Scholar] [CrossRef]
- Saiz-pardo-Lizaso, M.; Molina-Fernandez, L.; Haro-Dominguez, C. Combined Effect of Information Technologies and the Knowledge Network on performance and Knowledge Transfer. Dyna 2021, 96, 454. [Google Scholar] [CrossRef]
- Bolander, P.; Werr, A.; Asplund, K. The practice of talent management: A framework and typology. Pers. Rev. 2017, 46, 1523–1551. [Google Scholar] [CrossRef]
- Ward, V. Why, whose, what and how? A framework for knowledge mobilisers. Evid. Policy 2017, 13, 477–497. [Google Scholar] [CrossRef]
- Battistella, C.; De Toni, A.F.; Pessot, E. Practising open innovation: A framework of reference. Bus. Process Manag. J. 2017, 23, 1311–1336. [Google Scholar] [CrossRef]
- Li, Q.; Luo, H.; Xie, P.-X.; Feng, X.-Q.; Du, R.-Y. Product whole life-cycle and omni-channels data convergence oriented enterprise networks integration in a sensing environment. Comput. Ind. 2015, 70, 23–45. [Google Scholar] [CrossRef]
- Ilie-Zudor, E.; Ekárt, A.; Kemeny, Z.; Buckingham, C.; Welch, P.; Monostori, L. Advanced predictive-analysis-based decision support for collaborative logistics networks. Supply Chain. Manag. Int. J. 2015, 20, 369–388. [Google Scholar] [CrossRef]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.T.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef]
- Klievink, B.; Romijn, B.-J.; Cunningham, S.; de Bruijn, H. Big data in the public sector: Uncertainties and readiness. Inf. Syst. Front. 2016, 19, 267–283. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.y.; Yuan, G.; Huang, L. An overview of online based platforms for sharing and analyzing electrophysiology data from big data perspective. WIREs Data Min. Knowl. Discov. 2017, 7, e1206. [Google Scholar] [CrossRef]
- Intezari, A.; Gressel, S. Information and reformation in KM systems: Big data and strategic decision-making. J. Knowl. Manag. 2017, 21, 71–91. [Google Scholar] [CrossRef]
- Sadic, S.; de Sousa, J.P.; Crispim, J.A. A two-phase MILP approach to integrate order, customer and manufacturer characteristics into Dynamic Manufacturing Network formation and operational planning. Expert Syst. Appl. 2018, 96, 462–478. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated Electronic Health Records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Yi, H.; Idaszak, R.; Stealey, M.; Calloway, C.; Couch, A.L.; Tarboton, D.G. Advancing distributed data management for the HydroShare hydrologic information system. Environ. Model. Softw. 2018, 102, 233–240. [Google Scholar] [CrossRef]
- Orenga-Roglá, S.; Chalmeta, R. Framework for implementing a big data ecosystem in organizations. Commun. ACM 2018, 62, 58–65. [Google Scholar] [CrossRef]
- Atrsaei, A.; Salarieh, H.; Alasty, A. Human Arm Motion Tracking by Orientation-Based Fusion of Inertial Sensors and Kinect Using Unscented Kalman Filter. J. Biomech. Eng. 2016, 138, 91005. [Google Scholar] [CrossRef]
- Alvarez, D.A.; Uribe, F.; Hurtado, J.E. Estimation of the lower and upper bounds on the probability of failure using subset simulation and random set theory. Mech. Syst. Signal Process. 2018, 100, 782–801. [Google Scholar] [CrossRef]
- Guo, J.; Yuan, X.; Han, C. Sensor selection based on maximum entropy fuzzy clustering for target tracking in large-scale sensor networks. IET Signal Process. 2017, 11, 613–621. [Google Scholar] [CrossRef]
- Dell’Orco, M.; Marinelli, M. Modeling the dynamic effect of information on drivers’ choice behavior in the context of an Advanced Traveler Information System. Transp. Res. Part C Emerg. Technol. 2017, 85, 168–183. [Google Scholar] [CrossRef]
- Chen, G.; Wu, Y.; Fu, L.; Bai, N. Fault diagnosis of full-hydraulic drilling rig based on RS–SVM data fusion method. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 140. [Google Scholar] [CrossRef]
- Zampieri, G.; Tran, D.V.; Donini, M.; Navarin, N.; Aiolli, F.; Sperduti, A.; Valle, G. Scuba: Scalable kernel-based gene prioritization. BMC Bioinform. 2018, 19, 23. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Jia, M.; Na, Z.; Lu, W.; Li, F. Multi-Modal Cooperative Spectrum Sensing Based on Dempster-Shafer Fusion in 5G-Based Cognitive Radio. IEEE Access 2018, 6, 199–208. [Google Scholar] [CrossRef]
- Giese, E.; Winkelmann, O.; Rohn, S.; Fritsche, J. Determining quality parameters of fish oils by means of (1)H nuclear magnetic resonance, mid-infrared, and near-infrared spectroscopy in combination with multivariate statistics. Food Res. Int. 2018, 106, 116–128. [Google Scholar] [CrossRef]
- Khaleghi, B.; Karray, F. Random set theoretic soft/hard data fusion framework. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 3068–3081. [Google Scholar] [CrossRef]
- Big Data and B2B Digital Platforms: The Next Frontier for Europe’s Industry and Enterprises. Available online: https://ec.europa.eu/newsroom/growth/items/48800/en (accessed on 5 January 2022).
- McLeod, L.; MacDonell, S.G.; Doolin, B. Qualitative research on software development: A longitudinal case study methodology. Empir. Softw. Eng. 2011, 16, 430–459. [Google Scholar] [CrossRef]
- Big Data in Business. Available online: https://www.ijser.org/onlineResearchPaperViewer.aspx?Big-Data-In-Business-2015.pdf (accessed on 5 January 2022).
- Buhalis, D.; Leung, R. Smart hospitality—Interconnectivity and interoperability towards an ecosystem. Int. J. Hosp. Manag. 2018, 71, 41–50. [Google Scholar] [CrossRef]
- Casey, E.; Ribaux, O.; Roux, C. The Kodak Syndrome: Risks and Opportunities Created by Decentralization of Forensic Capabilities. J. Forensic Sci. 2019, 64, 127–136. [Google Scholar] [CrossRef]
- Li, S.; Jiao, F.; Zhang, Y.; Xu, X. Problems and Changes in Digital Libraries in the Age of Big Data From the Perspective of User Services. J. Acad. Librariansh. 2019, 45, 22–30. [Google Scholar] [CrossRef]
- Pérez-González, C.J.; Colebrook, M.; Roda-García, J.L.; Rosa-Remedios, C.B. Developing a data analytics platform to support decision making in emergency and security management. Expert Syst. Appl. 2019, 120, 167–184. [Google Scholar] [CrossRef]
- Gonçalves, D.; Ferreira, L.; Campos, N. Enterprise architecture for high flexible and agile company in automotive industry. Procedia Comput. Sci. 2021, 181, 1077–1082. [Google Scholar] [CrossRef]
- Vargas, A.; Boza, A.; Cuenca, L. Towards Interoperability through Inter-Enterprise Collaboration Architectures; Springer: Berlin/Heidelberg, Germany, 2011; pp. 102–111. [Google Scholar]
- Gorski, T. Towards Enterprise Architecture for Capital Group in Energy Sector. In Proceedings of the 2018 IEEE 22nd International Conference on Intelligent Engineering Systems (INES), Las Palmas de Gran Canaria, Spain, 21–23 June 2018; pp. 239–244. [Google Scholar]
- Castillo-Zuñiga, I.; Lopez-Veyna, J.; Luna-Rosas, F.; Tirado-Estrada, G. Intelligent System for Detection of Cybercrime Vocabulary on Websites. Dyna 2020, 95, 464. [Google Scholar] [CrossRef]
- Mikel, N. The Future of Smart Industry: Technologies, Macro-Trends And Application Areas. Dyna 2021, 96, 561–562. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Levels | Approaches | Data Fusion | Inter Operability | Data Sources | Big Data Assurance | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Framework | Based on Architecture | Data Alignment | Compression | Centralized | Decentralized | Alternative Technique Based on Context | Mechanism to Remove Incompatibilities | Structured | Semi-Structured | Unstructured | 6 Vs |
| Li et al., 2015 [29] | ● | ● | ● | ● | ● | ● | ● | ● | |||
| Ilie-Zudor et al., 2015 [30] | ● | ● | ● | ● | ● | ● | |||||
| Wang et al., 2016 [31] | ● | ● | ● | ||||||||
| Klievink et al., 2016 [32] | ● | ● | ● | ● | ● | ● | |||||
| Chen et al., 2017 [33] | ● | ● | ● | ● | ● | ● | |||||
| Intezari et al., 2017 [34] | ● | ● | ● | ● | |||||||
| Sadic et al., 2018 [35] | ● | ● | ● | ● | |||||||
| Brisimi et al., 2018 [36] | ● | ● | ● | ● | ● | ● | ● | ● | |||
| Yi et al., 2018 [37] | ● | ● | ● | ● | ● | ||||||
| Orenga-Roglá et al., 2018 [38] | ● | ● | ● | ● | ● | ● | ● | ● | |||
| Approaches | CNO’s Architecture Levels | ||
|---|---|---|---|
| Bottom | Middle | Top | |
| Data alignment | ● | ● | |
| Compression | ● | ● | |
| Centralized | ● | ||
| Decentralized | ● | ● | |
| Inclusive | ● | ● | ● |
| Lit. | Technique/Level | Description |
|---|---|---|
| Atrsaei et al., 2016 [39] | Kalman filter/B, M and T | This technique estimates the current state of a system. It includes the fusion of current and past data collected from the system itself and can be used in streaming processing and/or batch processing applications. Therefore, it can be used in the centralized and decentralized approaches of the CNO-BD framework. Additionally, it allows the participants to recalculate corrupt or incomplete results. |
| Alvarez et al., 2018 [40] | Dempster–Shafer theory/B, M and T | This technique determines epistemic uncertainty and stochastic uncertainty. These are represented in parallel or individually by a probability box. Each participant that implements it can provide information to build a belief network. For example, some participants provide information to identify unitary elements, while other participants provide information to identify classes of elements. |
| Guo et al., 2017 [41] | Fuzzy set theory/B, M and T | This technique manages the lack of clarity in the data. It works with partial or vague data sources that are fuzzified with a membership function. This can convert the values of a CNO into qualitative attributes that can be evaluated with heuristic rules. This technique can be used in the transportation of products of an SC since decisions are made based on uncertainty and inaccurate data. |
| Dell’Orco et al., 2017 [42] | Possibility theory/B and M | Just like fuzzy set theory, possibility theory can use multisource data uncertainty; uncertainty is present in imprecise or vague knowledge. This technique considers human perception and behavior, and the distribution of information. For example, a CNO of the agrifood sector makes decisions based on humans’ perceptions, such as the quality control of the product. |
| Chen et al., 2018 [43] | Rough set theory/B, M and T | This technique can fuse inaccurate data by considering its granularity (internal structure), and does not require extra information. It avoids dimensional drawbacks, reduces the time factor, and can be implemented in the CNO to (1) preprocess and mine incoming data from multiple sources; (2) identify the data characteristics; (3) remove redundant information; and (4) discover patterns in the datasets. |
| Zampieri et al., 2018 [44] | Kernels/T | Kernels are similar measurements between data pairs. They can represent nonhomogeneous datasets as kernel arrays. Thus, different types of CNO data and/or formats can be transformed within kernels. Therefore, this technique can be implemented in the CNO’s top level to (1) obtain a unified global view of the current state and (2) use predictive models to support decision making. |
| Liu et al., 2018 [45] | Bayesian fusion/B and M | This combines multisource data to make inferences. Inferences allow the information extracted to be analyzed. This technique can fuse data from sensors, RFID, weather and images, which are collected at different time intervals. The fusion of these data can generate knowledge. Thus, the CNO’s participants can perform product management, monitoring, supply control, object detection, etc. |
| Giese et al., 2018 [46] | ANN/T | A CNO has cold data entry as hot data, and the output corresponds to the data fusion process. From both types of data, Artificial Neural Networks (ANN) can issue adequate forecasts. The ANN can indicate the expected trend of both a product or a CNO’s participant. As an example, the number of products that will be returned in a closed-loop SC may be estimated. |
| Khaleghi et al., 2014 [47] | Random set theory/T | Random set theory is known for a high computational and representational power. It can perform single-target Bayes filtering using generalized measurements that cannot be expressed as vectors. This technique can combine unstructured data sources from the CNO such as social networks, portals and text documents. Thus, participants can obtain new knowledge that supports decision making. |
| Technique | Description and Models/Algorithms | Example CNO Applications |
|---|---|---|
| Classification | This classifies data by comparing a set of data that was previously categorized. It is based on supervised learning. Models/algorithms: Logistic regression algorithms. Support vector machine. C4.5. | * Determination of the probability of success or failure to form a VE or a VO in a VBE. * Measurement of the behavior of a participant in a PVC. |
| Association rule learning | This is known as market basket analysis. It is based on association rules to identify the relevance of frequent relationships. Models/algorithms: Association rule mining algorithm. Eclat algorithm. | * Determination of the type of product and which channel it is returned by in a closed-loop SC. * Analysis of biological data to obtain new associations through a VL. |
| Statistical modeling | Although this is useful in a variety of problems, it is typically used to determine forecasts and trends. Models/algorithms: Linear regression algorithms. Markov models. Time series. | * Determination of the effect of a new policy on a VG established by external regulatory frameworks. * Estimation of status or condition of the equipment that uses IoT in Industry 4.0 (VE). |
| Cluster analysis | This classifies input data into different small groups according to the degree of similarity. It is based on unsupervised learning. Models/algorithms: K-means clustering. Hierarchical clustering. | * Management of user profile in an EE. * Marketing through the segmentation of customers in a DVO. |
| Data mining | This integrates statistical and machine learning techniques to discover patterns in large datasets. Models/algorithms: a priori. Pattern matching. Clustering. | * Analysis of text documents for scientific purposes in a PVC. * Processing of food images to determine their quality in a SC. |
| Genetic algorithms | These find true or approximate solutions to optimization and search problems. They are based on the process of natural evolution or survival of the fittest. Models/algorithms: Selection. Mutation. Crossover. | * Computer-aided molecular design for the treatment of diseases (e-Science). * Generation of products and sales campaigns for specific clients (VT oriented to marketing). |
| Natural language processing | This is based on artificial intelligence to analyze human’s natural language. It uses soft data. Models/algorithms: Part-of-speech tagging. Sentiment analysis. Speech recognition. | * Determination of the polarity (+, − or neutral) of some aspect in the VG according to social networks. * Analysis of contracts in an insurance agency (DVO) to detect fraud. * Analysis of audio calls of a customer service center of an EE. |
| Machine learning | This predicts a dependent variable (target) based on large known datasets. It creates artificial intelligence using statistical methods and inductive learning. Models/algorithms: Expectation maximization. Deep learning. Principal component analysis. | * Analysis of financial feelings using social networks of a VE. * Analysis of the closed circuit (video) of a VG for perimeter security. * Prediction of readmission rates of patients in a hospital (VO). |
| Crowdsourcing | People, in general, contribute to the accomplishment of a task. Therefore, it is a massive collaboration. It uses multiple formats and types of data. Models/algorithms: Knowledge discovery and management. Distributed human intelligence tasking. Broadcast search. | * Creation of a Kaizen system based on the report of the participants in a VE. * Open call from Disaster Rescue Networks (VBE) to help in a region impacted by a natural disaster. * A massive collaboration of a VL to solve empirical problems. |
| Dimension | Question Responded | Description of Dimension |
|---|---|---|
| Methodology | How is the measurement performed? | It systematically specifies the activities, tasks, resources and roles necessary to achieve EI. |
| Models and modeling languages | What models and modeling languages are used? | It is based on three approaches: (1) enterprise models (I*, UML 2.0 and BPMN); (2) model-driven interoperability (model-driven approaches composed of the CIM, PIM and PSM models); and (3) model morphisms. Additionally, it uses the MDKe-IRIS modeling language. |
| Techniques | What mechanisms are used to collect and record project information? | It uses three techniques to support the methodology: open-ended interviews, collaborative work sessions and templates. |
| Interoperability measurement system | How are problems and opportunities to improve EI identified? | It measures the potential interoperability through the MM-IRIS maturity model. It has these interoperability views: business, process management, knowledge, human resources, ICT and semantics. |
| Semantic alignment | How are the syntactic and semantic drawbacks of the domain solved? | It uses specific ontologies for each participant. Ontologies are based on the general-purpose thesaurus of the domain where the framework will be applied. |
| Technologies | What technologies are used? | It uses TAOM4E, agent-oriented software development, case tools for BPMN modeling, Olivanova, Eclipse, Java, Protégé, SOA and Incremental Commitment Model to define the testing strategy. |
| Use Case | Ecosystem’s Modules and Components | |||||||
|---|---|---|---|---|---|---|---|---|
| Target Knowledge | Objective | CNO’s Participant | Data Source | Input Variable Format | Approach | Interoperability View | Interface | Programmable Module |
| Students’ profiles at the beginning of their studies of whom have graduated | DE | AU AP SG | ST (SQL Server) SS (CSV, PDF) UN (Facebook API, Twitter API) | RDBMS Text published on social networks | CE | PM KN IS | SQL Script | DFM, LM, CM (EC2, free distribution software) |
| Degree of satisfaction | DE | AU AP SG | ST (SQL Server) SS (JSON, HTML, XML) UN (Facebook API, Twitter API, Word processing documents, PDF) | Documents Text published on social networks | CE DC | BU KN HR IS | Sheet Script Graphic | DFM, LM, CM (EC2, free distribution software) |
| Comparison of trends | PR | AU AP SG | ST (SQL Server) SS (JSON, HTML, XML) UN (Facebook API, Twitter API, Word processing documents, PDF) | RDBMS Documents Text published on social networks | IN | BU PM KN IS | SQL Sheet Script Visual | DFM, LM, CM (EC2, free distribution software) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Almazan, J.-A.; Chalmeta, R.; Roque-Hernández, R.V.; Machucho-Cadena, R. A Framework to Build a Big Data Ecosystem Oriented to the Collaborative Networked Organization. Appl. Sci. 2022, 12, 11494. https://doi.org/10.3390/app122211494
Hernandez-Almazan J-A, Chalmeta R, Roque-Hernández RV, Machucho-Cadena R. A Framework to Build a Big Data Ecosystem Oriented to the Collaborative Networked Organization. Applied Sciences. 2022; 12(22):11494. https://doi.org/10.3390/app122211494
Chicago/Turabian StyleHernandez-Almazan, Jorge-Arturo, Ricardo Chalmeta, Ramón Ventura Roque-Hernández, and Rubén Machucho-Cadena. 2022. "A Framework to Build a Big Data Ecosystem Oriented to the Collaborative Networked Organization" Applied Sciences 12, no. 22: 11494. https://doi.org/10.3390/app122211494
APA StyleHernandez-Almazan, J.-A., Chalmeta, R., Roque-Hernández, R. V., & Machucho-Cadena, R. (2022). A Framework to Build a Big Data Ecosystem Oriented to the Collaborative Networked Organization. Applied Sciences, 12(22), 11494. https://doi.org/10.3390/app122211494