
Prognostic Health Management of Pumps Using Artificial Intelligence in the Oil and Gas Sector: A Review
Abstract
:1. Introduction
- ✓ Provide an overview of the concepts of conventional maintenance strategies applied in previous studies.
- ✓ Analyze current trends in the state of the art regarding the application of machine learning works related to fault diagnosis and prognosis using various fault detection techniques in pumps.
- ✓ Develop a coherent understanding of machine learning in supervised, unsupervised, and semi-supervised algorithms.
- ✓ Develop an appreciation of the core merits of machine learning through a sector-wise view of the technology.
- ✓ Provide the current progress improvements, including their basics, pros and cons, and the standard commercially available Machine Learning (ML) tools.
- ✓ Provide practical insights for academia and industries on which algorithms are best-suited for certain problems and how to approach the problems, while enabling quicker and more efficient maintenance decision0making.
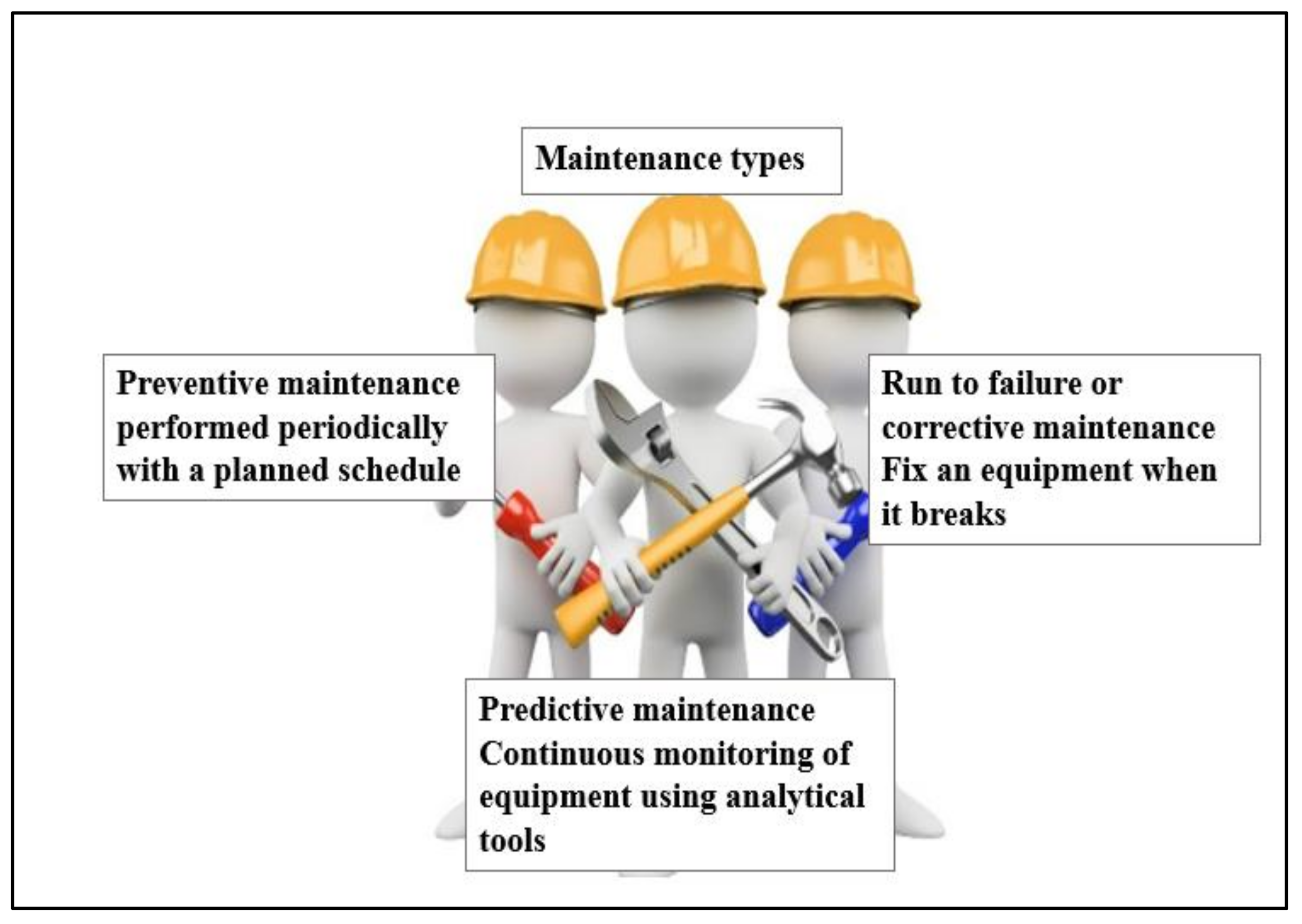
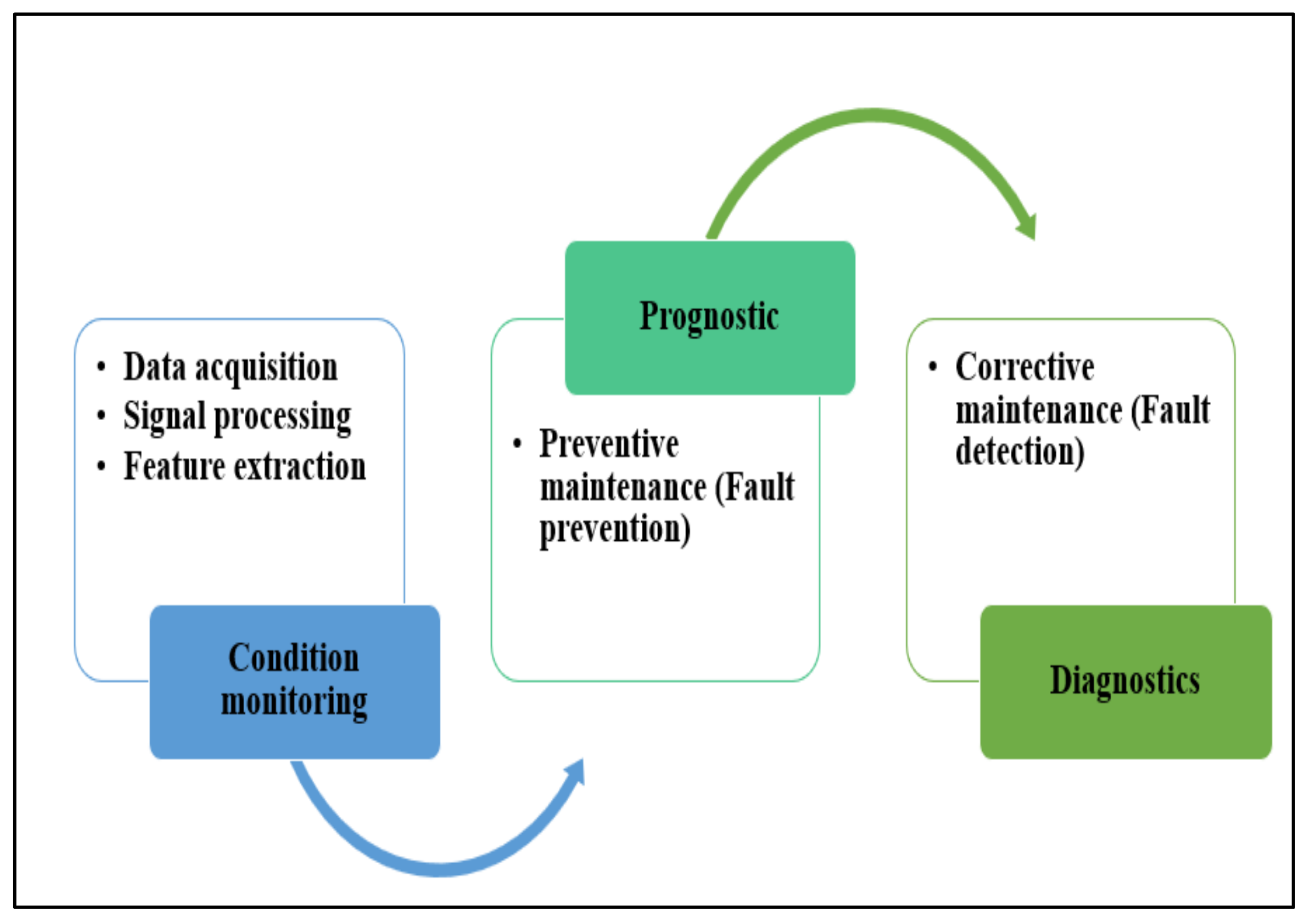
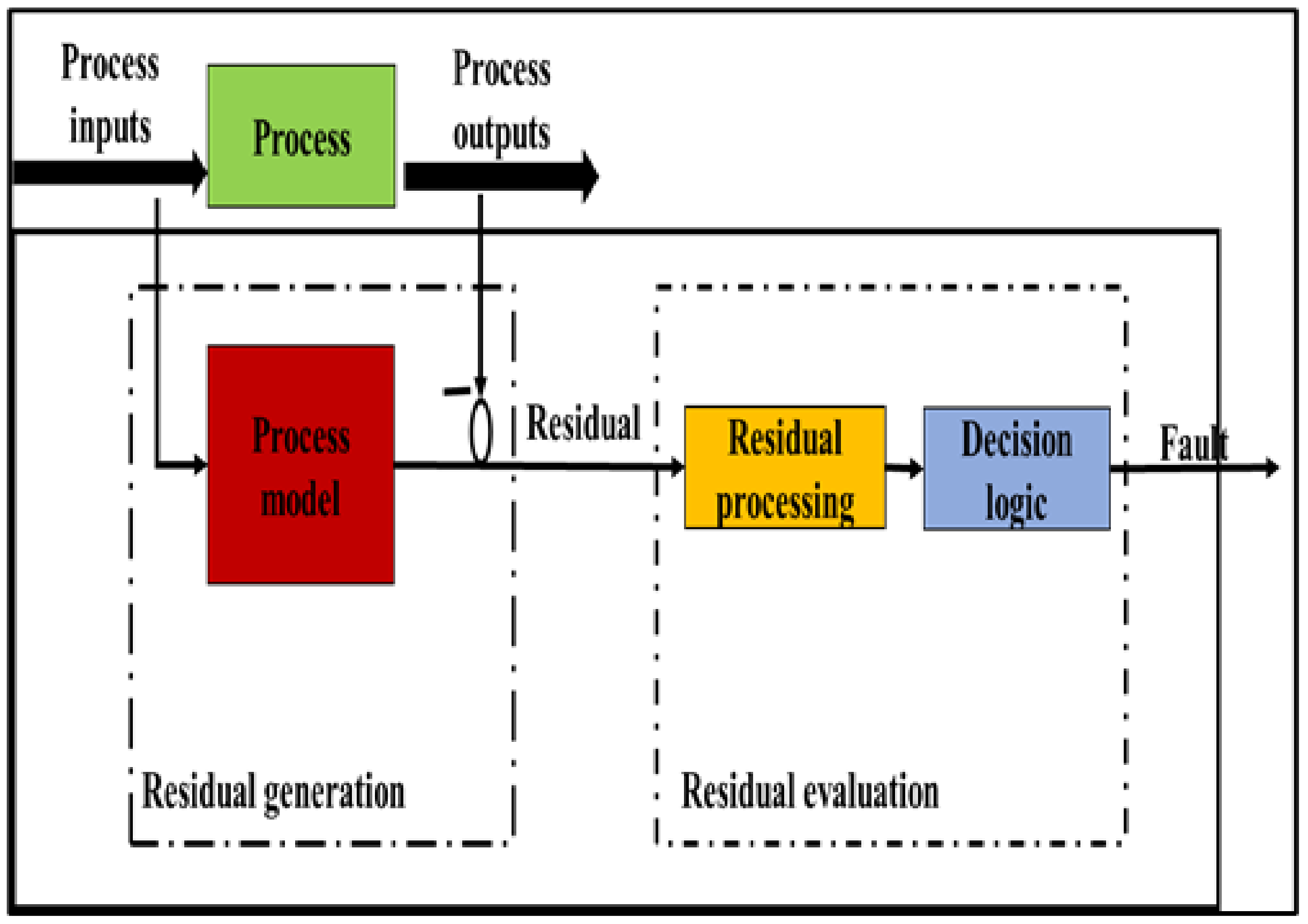
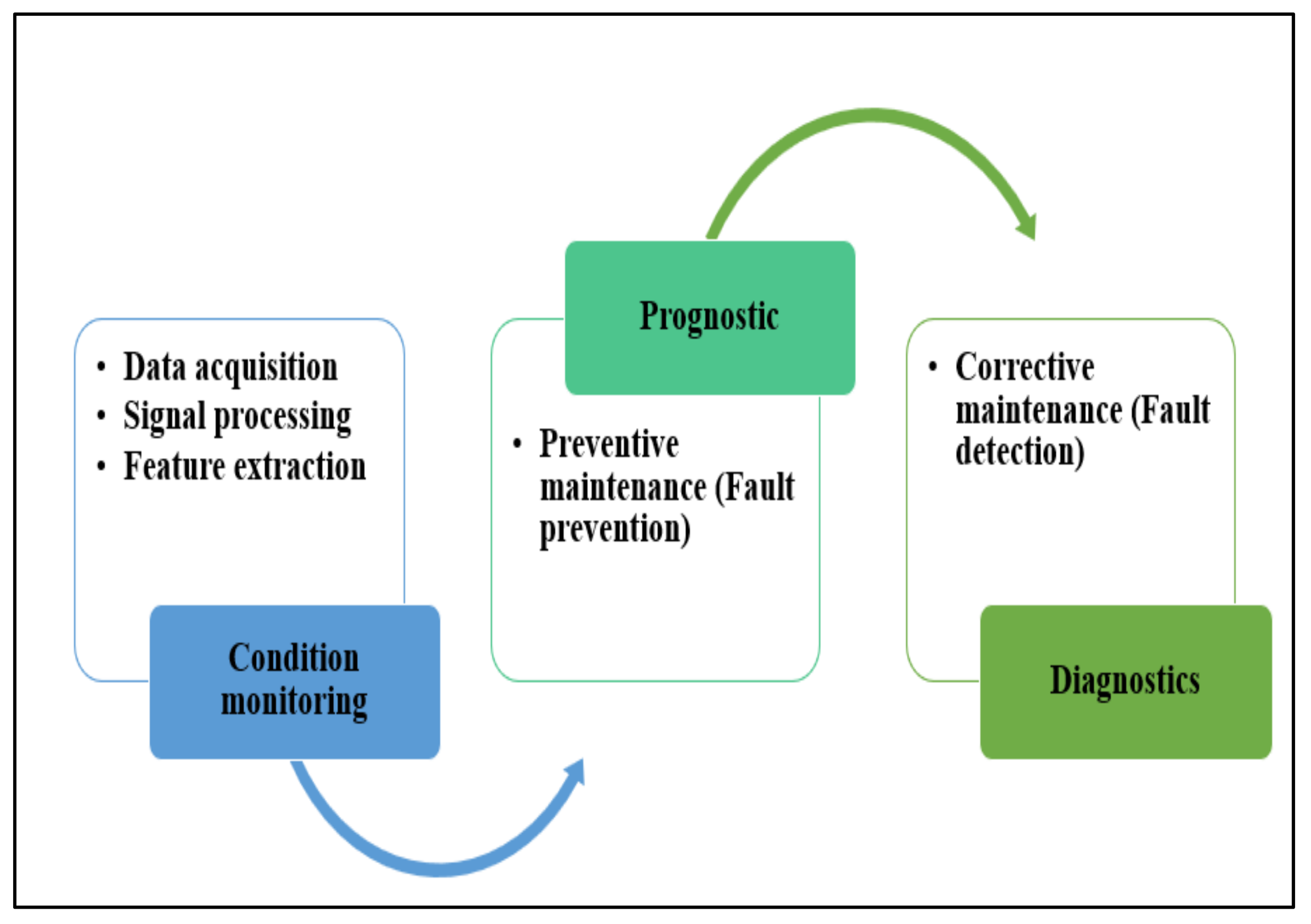
2. Diagnostics and Prediction of Faults in Pumps
3. Methodology
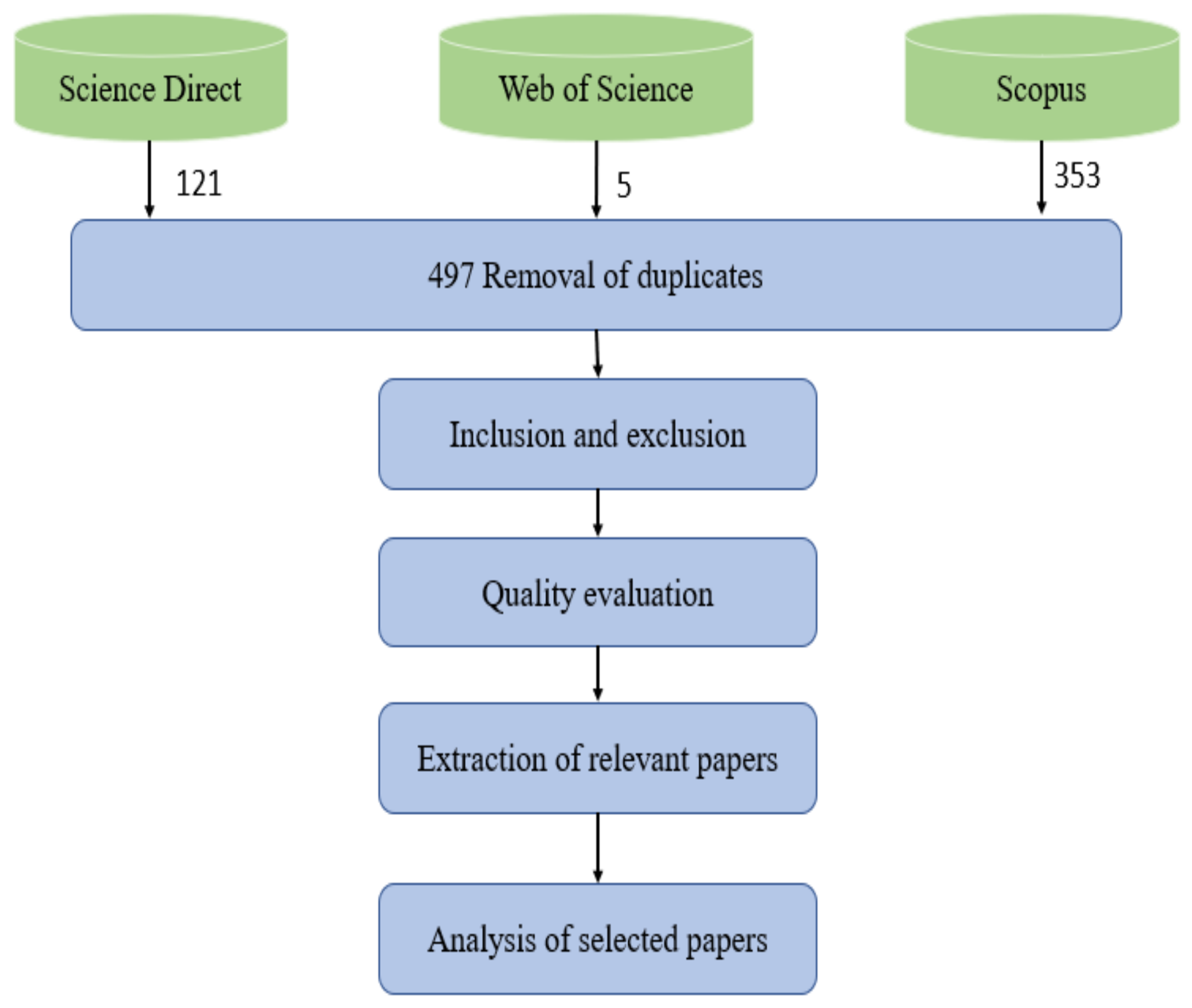
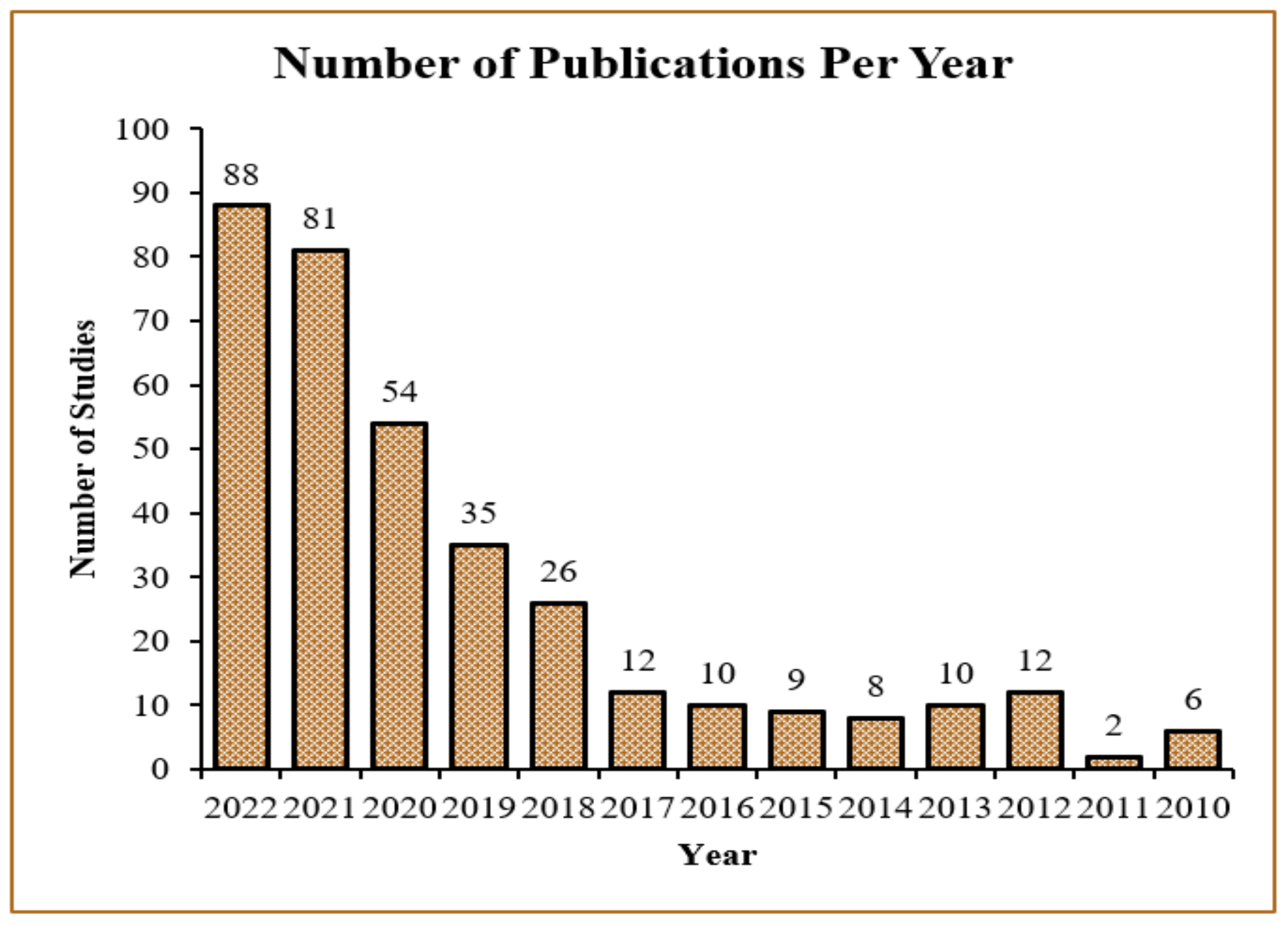
3.1. Search Methodology
3.2. Selection Criteria
3.3. Criteria for Inclusion and Exclusion
3.4. Quality Evaluation
3.5. Extraction of Data
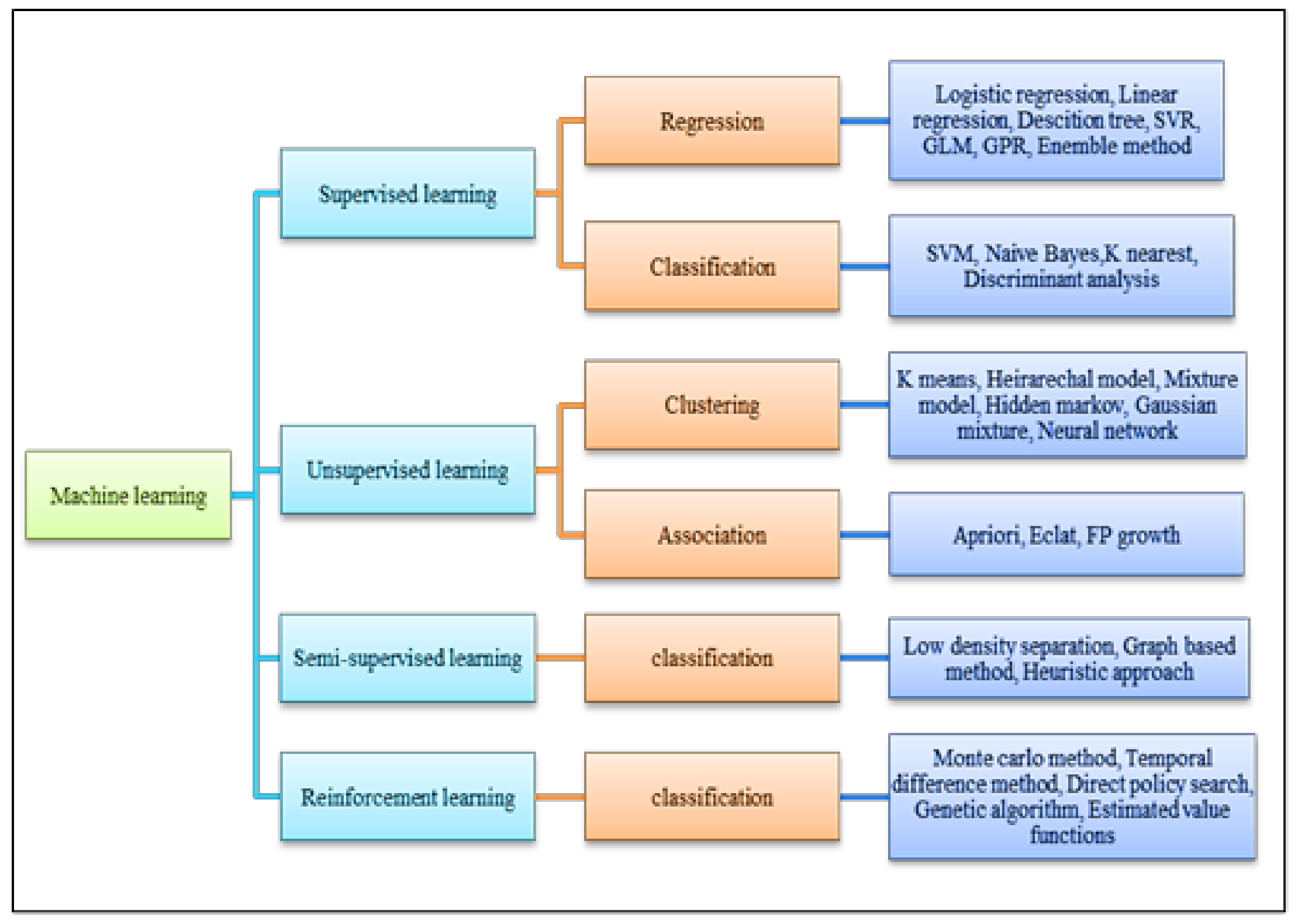
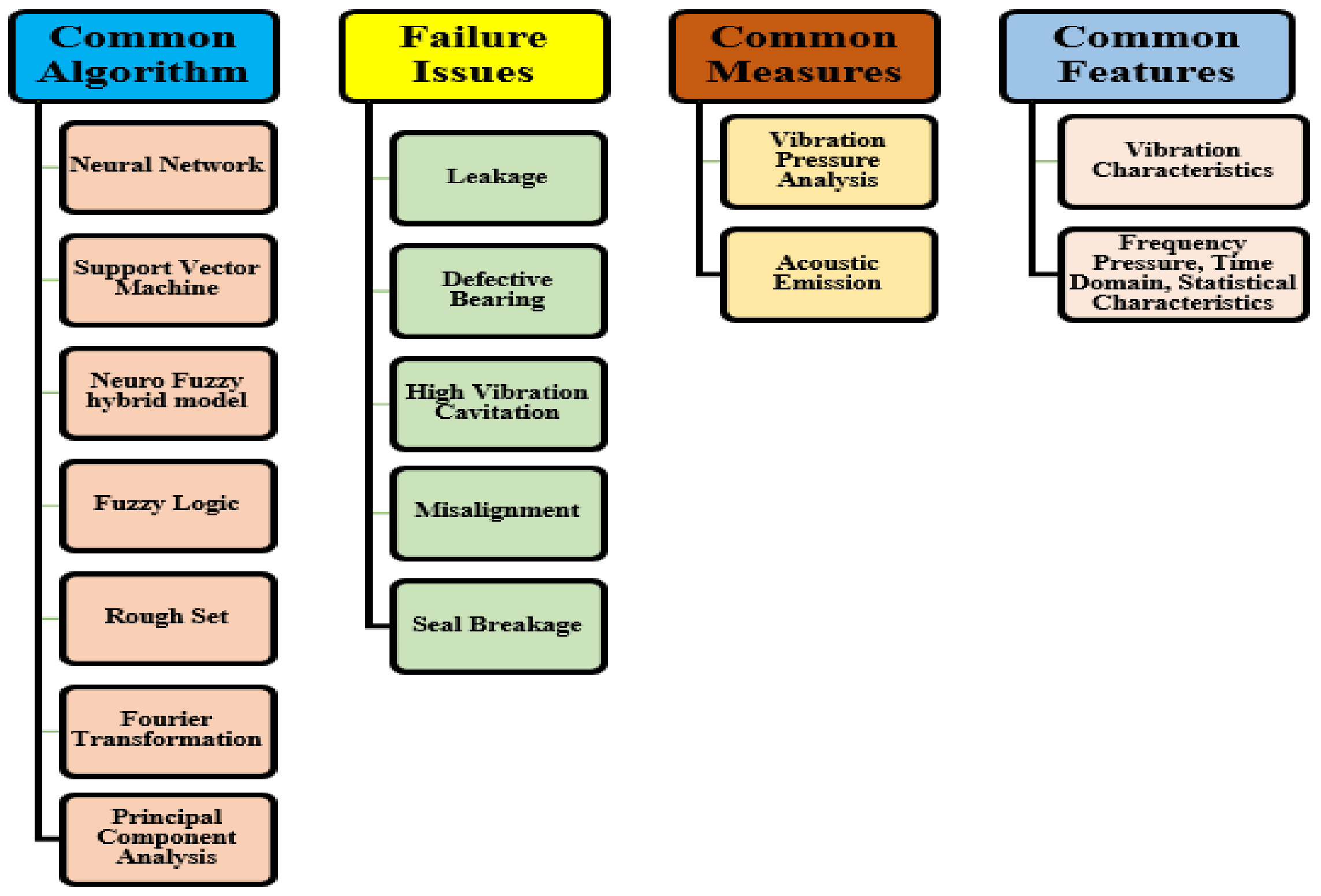
4. Machine Learning (ML) Algorithms
4.1. Progress of Machine Learning in Pumps Application
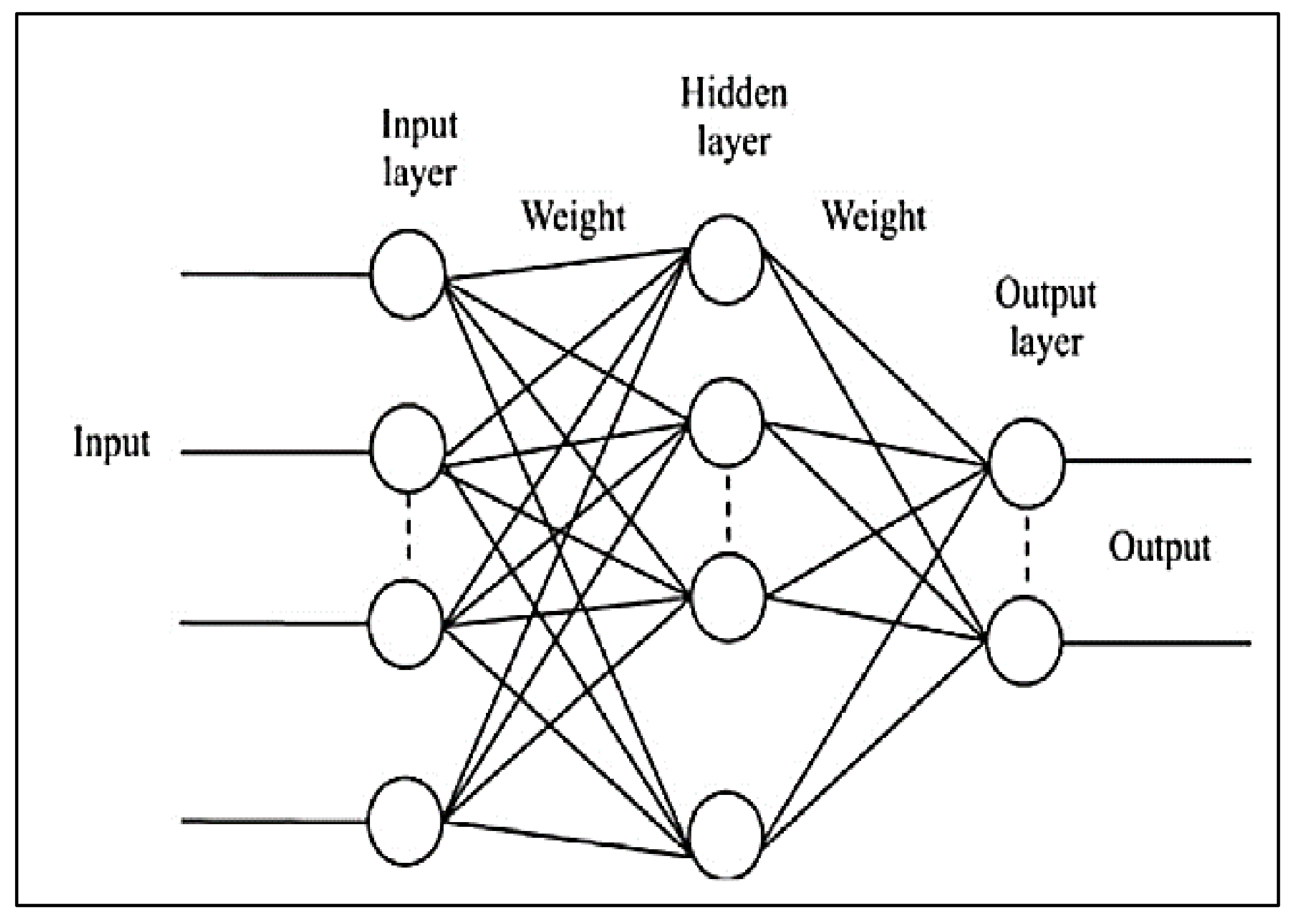
4.2. Artificial Neural Network (ANN)
4.3. Support Vector Machine (SVM)
4.4. Genetic Algorithms
4.5. Particle Swarm Optimization (PSO)
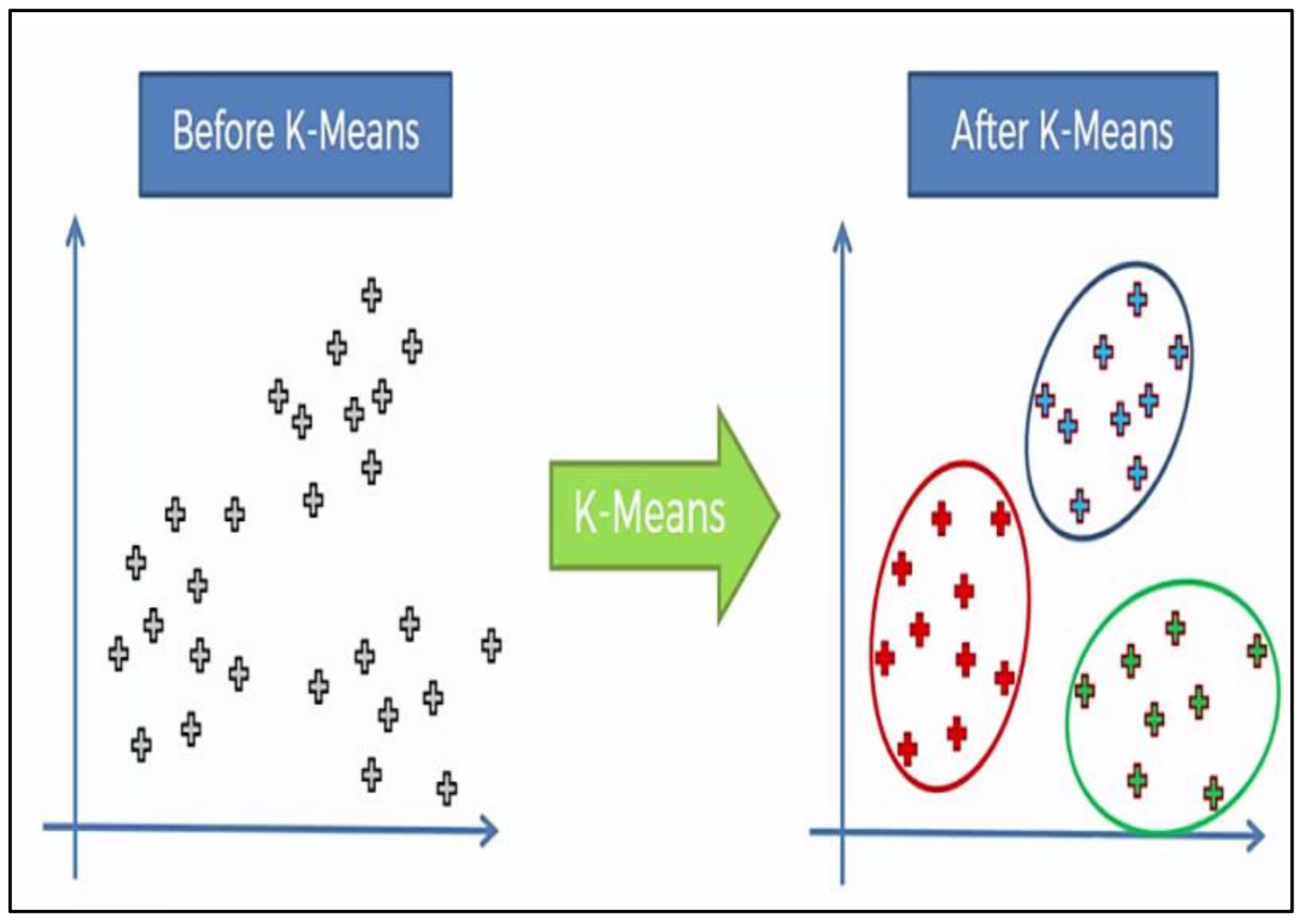
4.6. K-Means
4.7. Decision Trees
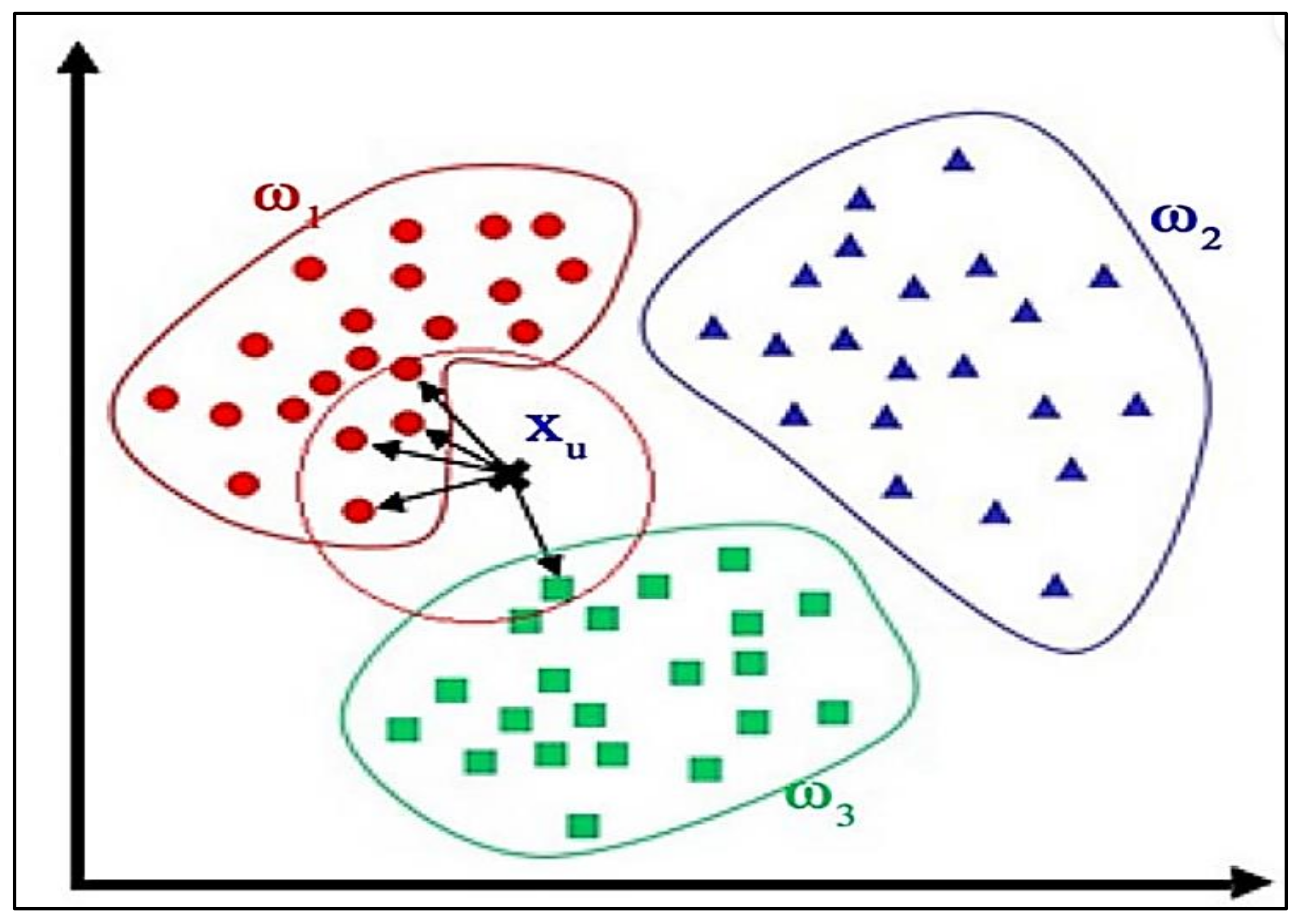
4.8. KNN
4.9. Random Forest (RF)
4.10. Analysis
5. Conclusions
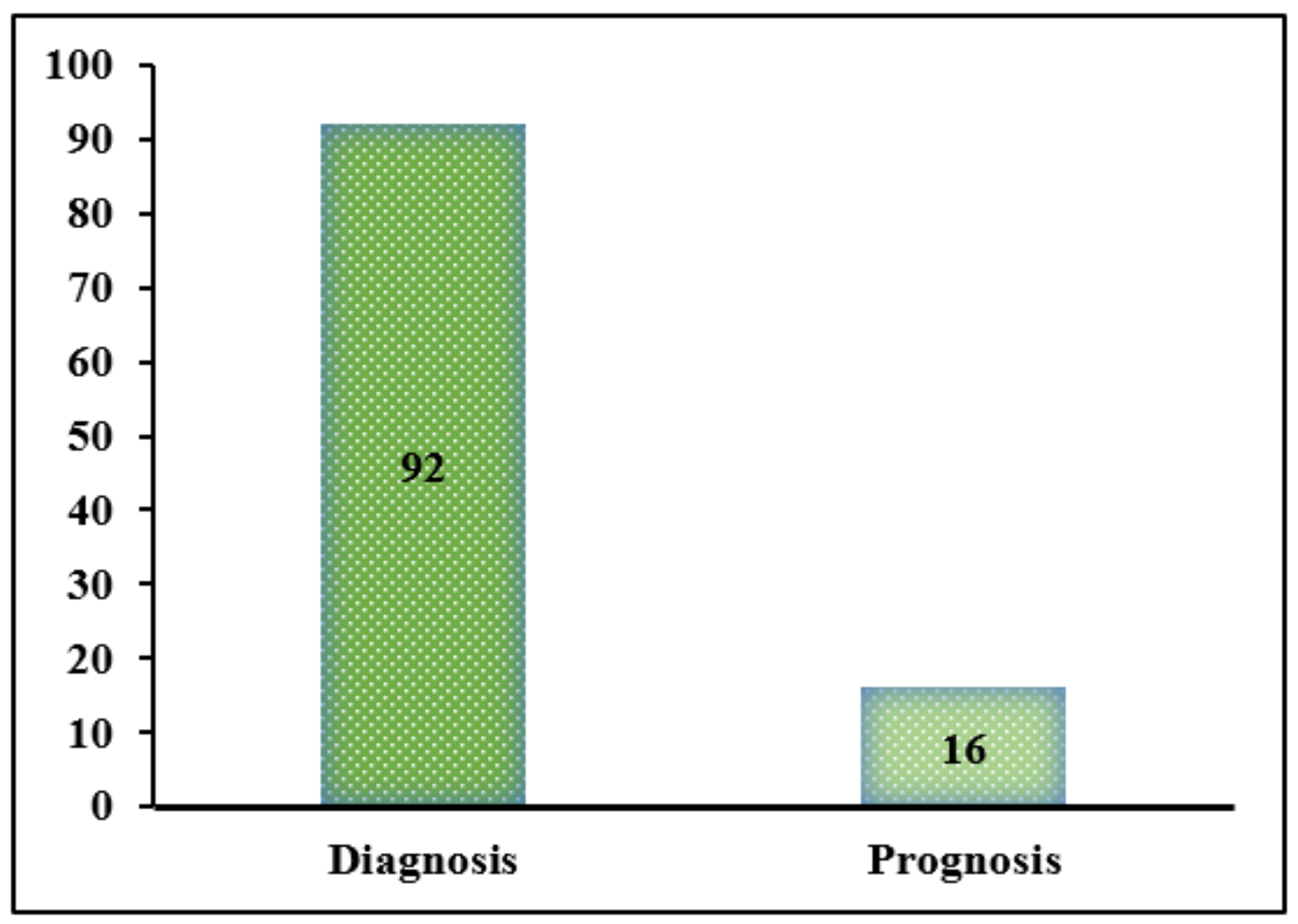
- It has been noticed that no specific method or algorithm exists for a given problem. The process relies on the type of data and the algorithm’s or method’s aptitude for resolving the provided errors. Among the various research studies on pump fault diagnosis and prognosis, the most frequently treated problem is that of a bearing fault, with a percentage of 46%, followed by cavitation. The published studies rank seal damage as the third most prevalent flaw. Leakage and obstruction are the least studied defects in research.
- Artificial neural networks, support vector machines, and hybrid models are the most frequently used machine learning models for evaluating the health of damaged oil and gas pumps.
- Due to their ability to incorporate the strengths of multiple machine learning models rather than just one, hybrid models were found to be the most successful of all the models tested. Depending on their location and medium, a wide range of factors can affect the health of oil and gas pumps; however, the most frequently used factors include pressure, temperature, flow, angular velocity, noise, vibration signals, and so on. However, neither reliability, nor precision, nor processing time was taken into account.
- The research question found that four different types of datasets were primarily used to create machine learning models, particularly datasets based on expert judgment, field data, experimental data, and simulation-based data. Simulated data and experimental datasets have frequently been produced using field data. The data side is currently under-researched, compared to the algorithmic side.
- The data types employed in the machine learning methods for pump fault diagnosis are mainly limited to vibration and flow, which may not be adequate to characterize the condition of pumps and their attributes. This can lead to false alarms and a lack of confidence in the predictions under the dynamic operational environments of pumps.
6. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tiwari, R.; Bordoloi, D.J.; Dewangan, A. Blockage and cavitation detection in centrifugal pumps from dynamic pressure signal using deep learning algorithm. Meas. J. Int. Meas. Confed. 2020, 173, 108676. [Google Scholar] [CrossRef]
- Balali, F.; Seifoddini, H.; Nasiri, A. Data-driven predictive model of reliability estimation using degradation models: A review. Life Cycle Reliab. Saf. Eng. 2020, 9, 113–125. [Google Scholar] [CrossRef]
- Alrabghi, A.; Tiwari, A. State of the art in simulation-based optimisation for maintenance systems. Comput. Ind. Eng. 2015, 82, 167–182. [Google Scholar] [CrossRef] [Green Version]
- Qingfeng, W.; Wenbin, L.; Xin, Z.; Jianfeng, Y.; Qingbin, Y. Development and application of equipment maintenance and safety integrity management system. J. Loss Prev. Process Ind. 2011, 24, 321–332. [Google Scholar] [CrossRef]
- De Jonge, B.; Scarf, P.A. A review on maintenance optimization. Eur. J. Oper. Res. 2020, 285, 805–824. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.d.P.; Basto, J.P.; Alcalá, S.G.S. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Rastegari, A.; Jackson, M.; Randall, R. Condition Based Maintenance in the Manufacturing Industry From Strategy to Implementation. Ph.D. Thesis, Mälardalen University, Västerås, Suedia, 2017. [Google Scholar]
- Narayan, V. Effective Maintenance Management: Risk and Reliability Strategies for Optimizing Performance; Industrial Press Inc.: New York, NY, USA, 2004. [Google Scholar]
- Kumar, U.; Galar, D.; Parida, A.; Stenström, C.; Berges, L. Maintenance performance metrics: A state-of-the-art review. J. Qual. Maint. Eng. 2013, 19, 233–277. [Google Scholar] [CrossRef] [Green Version]
- Peters, R.W. Defining maintenance strategies for critical equipment with reliability-centered maintenance (RCM). In Reliable Maintenance Planning, Estimating, and Scheduling; Elsevier: Amsterdam, The Netherlands, 2015; pp. 145–155. [Google Scholar] [CrossRef]
- Swanson, L. Linking maintenance strategies to performance. Int. J. Prod. Econ. 2001, 70, 237–244. [Google Scholar] [CrossRef]
- Er-Ratby, M.; Mabrouki, M. Optimization of the Maintenance and Productivity of Industrial Organization. Int. J. Appl. Eng. Res. 2018, 13, 6315–6324. [Google Scholar]
- Ku, S.; Kim, C. Development of a model for maintenance performance measurement: A case study of a gas terminal. J. Qual. Maint. Eng. 2019, 26, 69–86. [Google Scholar] [CrossRef]
- Vishnu, C.R.; Regikumar, V. Reliability Based Maintenance Strategy Selection in Process Plants: A Case Study. Procedia Technol. 2016, 25, 1080–1087. [Google Scholar] [CrossRef] [Green Version]
- Alrabghi, A.; Tiwari, A. A novel approach for modelling complex maintenance systems using discrete event simulation. Reliab. Eng. Syst. Saf. 2016, 154, 160–170. [Google Scholar] [CrossRef] [Green Version]
- Tran, V.T.; Yang, B.S. An intelligent condition-based maintenance platform for rotating machinery. Expert Syst. Appl. 2012, 39, 2977–2988. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.G.; Sutherland, J.W. Predictive maintenance of machine tool systems using artificial intelligence techniques applied to machine condition data. Procedia CIRP 2019, 80, 506–511. [Google Scholar] [CrossRef]
- Ravnestad, G.; Panesar, S.S.; Kayrbekova, D.; Markeset, T. Improving periodic preventive maintenance strategies using condition monitoring data. IFIP Adv. Inf. Commun. Technol. 2012, 384, 260–267. [Google Scholar] [CrossRef] [Green Version]
- Mkandawire, B.O.; Ijumba, N.M.; Whitehead, H. Application of maintenance tools and strategies in integrated risk management of critical physical assets. Int. J. Agil. Syst. Manag. 2011, 4, 261–279. [Google Scholar] [CrossRef]
- Elmi, M. Achievements and expected challenges of the current maintenance strategy. Soc. Pet. Eng. Abu Dhabi Int. Pet. Exhib. Conf. 2012 ADIPEC 2012 Sustain. Energy Growth People, Responsib. Innov. 2012, 2, 1118–1128. [Google Scholar] [CrossRef]
- Susto, G.A.; Beghi, A.; Luca, C.D. A predictive maintenance system for epitaxy processes based on filtering and prediction techniques. IEEE Trans. Semicond. Manuf. 2012, 25, 638–649. [Google Scholar] [CrossRef]
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine learning for predictive maintenance: A multiple classifier approach. IEEE Trans. Ind. Inform. 2015, 11, 812–820. [Google Scholar] [CrossRef] [Green Version]
- Soomro, A.A.; Mokhtar, A.A.; Kurnia, J.C.; Lashari, N.; Lu, H.; Sambo, C. Integrity assessment of corroded oil and gas pipelines using machine learning: A systematic review. Eng. Fail. Anal. 2021, 105810, 2022. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Soomro, A.A.; Mokhtar, A.A.; Kurnia, J.C.; Lu, H. Deep Learning-Based Reliability Model for Oil and Gas Pipeline Subjected to Stress Corrosion Cracking: A Review and Concept. J. Hunan Univ. Sci. 2021, 48, 189–198. [Google Scholar]
- Thomas, T.M. Predictive Motor Maintenance; SKF USA, Inc.: Lansdale, PA, USA, 2016; Available online: http://www.skf.com/binary/21-285423/Motor-PdM-primer.pdf (accessed on 9 October 2022).
- Fauzi, M.F.; Aziz, I.A.; Amiruddin, A. The prediction of remaining useful life (rul) in oil and gas industry using artificial neural network (ann) algorithm. In Proceedings of the 2019 IEEE Conference on Big Data and Analytics (ICBDA), Pulau Pinang, Malaysia, 19–21 November 2019; pp. 7–11. [Google Scholar] [CrossRef]
- LI, T.; Wang, S.; Shi, J.; Ma, Z. An adaptive-order particle filter for remaining useful life prediction of aviation piston pumps. Chinese J. Aeronaut. 2018, 31, 941–948. [Google Scholar] [CrossRef]
- Neuroth, M.; MacConnell, P.; Stronach, F.; Vamplew, P. Improved modelling and control of oil and gas transport facility operations using artificial intelligence. Knowl. Based Syst. 2000, 13, 81–92. [Google Scholar] [CrossRef]
- Sinha, S.K.; Pandey, M.D. Probabilistic neural network for reliability assessment of oil and gas pipelines. Comput. Civ. Infrastruct. Eng. 2002, 17, 320–329. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Braglia, M.; Frosolini, M.; Montanari, R. Failure rate prediction with artificial neural networks. J. Qual. Maint. Eng. 2005, 11, 279–294. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Figueroa Barraza, J.; Guarda Bräuning, L.; Benites Perez, R.; Morais, C.B.; Martins, M.R.; Droguett, E.L. Deep learning health state prognostics of physical assets in the Oil and Gas industry. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2020, 236, 598–616. [Google Scholar] [CrossRef]
- Waeyenbergh, G.; Pintelon, L. A framework for maintenance concept development. Int. J. Prod. Econ. 2002, 77, 299–313. [Google Scholar] [CrossRef]
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind turbine condition monitoring: State-of-the-art review, new trends, and future challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef]
- Panda, A.K.; Rapur, J.S.; Tiwari, R. Prediction of flow blockages and impending cavitation in centrifugal pumps using Support Vector Machine (SVM) algorithms based on vibration measurements. Meas. J. Int. Meas. Confed. 2018, 130, 44–56. [Google Scholar] [CrossRef]
- Dutta, N.; Umashankar, S.; Arun Shankar, V.K.; Padmanaban, S.; Leonowicz, Z.; Wheeler, P. Centrifugal Pump Cavitation Detection Using Machine Learning Algorithm Technique. In Proceedings of the International Conference on Environment and Electrical Engineering, Palermo, Italy, 12–15 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, J.; Luo, Y.; Zhang, W. Fault Prediction of Centrifugal Pump Based on Improved KNN. Shock. Vib. 2021, 2021, 7306131. [Google Scholar] [CrossRef]
- Sakthivel, N.R.; Nair, B.B.; Sugumaran, V. Soft computing approach to fault diagnosis of centrifugal pump. Appl. Soft Comput. J. 2012, 12, 1574–1581. [Google Scholar] [CrossRef]
- Giro, R.A.; Bernasconi, G.; Giunta, G.; Cesari, S. A data-driven pipeline pressure procedure for remote monitoring of centrifugal pumps. J. Pet. Sci. Eng. 2021, 205, 108845. [Google Scholar] [CrossRef]
- Brown, S.; Bessant, J.; Jia, F. Strategic Operations Management; Routledge: London, UK, 2018. [Google Scholar] [CrossRef]
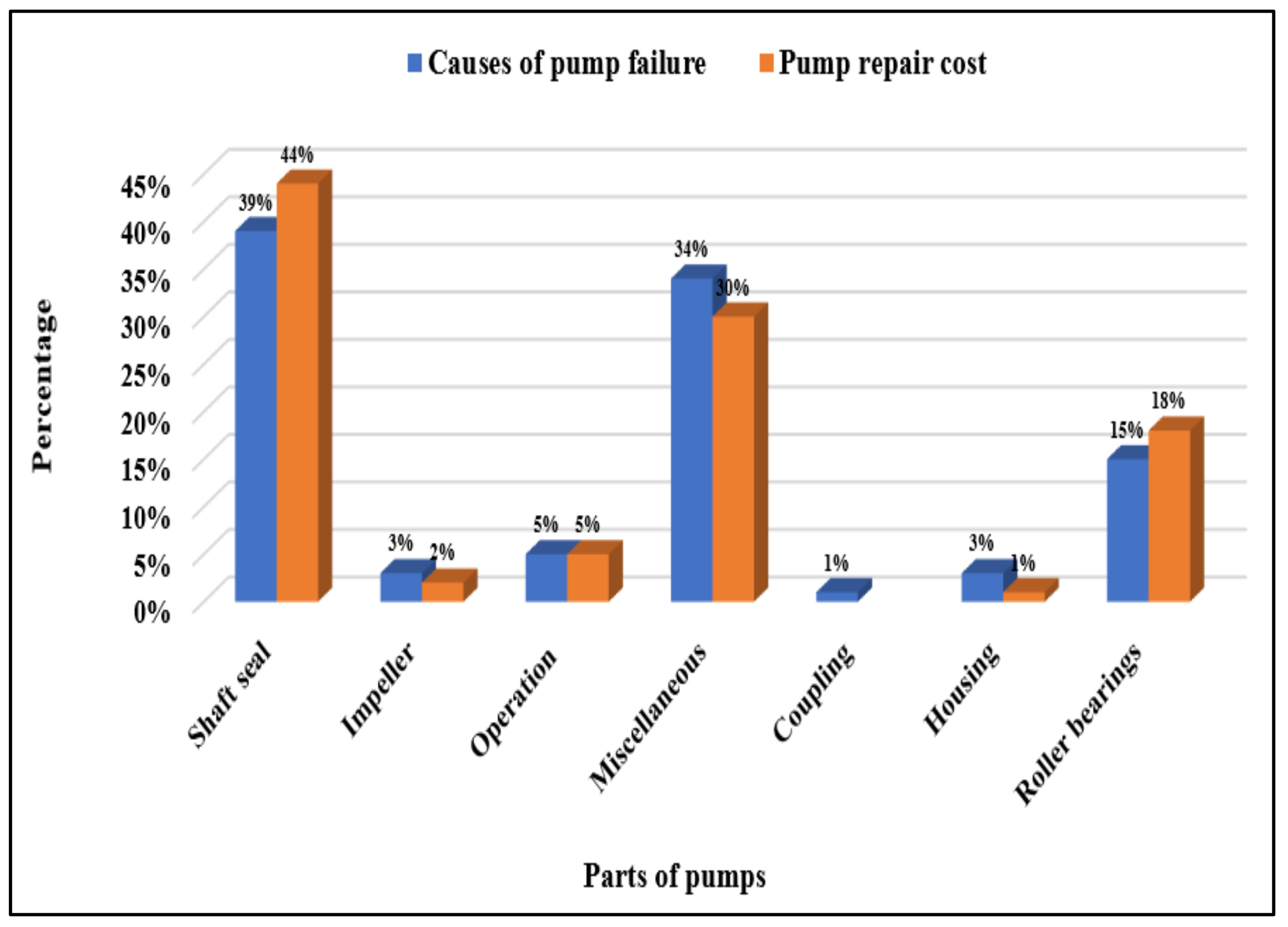
- McKee, K.; Forbes, G.; Mazhar, M.I.; Entwistle, R.; Howard, I. A review of major centrifugal pump failure modes with application to the water supply and sewerage industries. In Proceedings of the ICOMS Asset Management Conference Proceedings, Gold Coast, QLD, Australia, 16 May 2011; Asset Management Council: Oakleigh, VIC, Australia, 2011; pp. 1–12. [Google Scholar]
- Of, L.; With, P.; Pumps, C. Checklist of Problems with Centrifugal Pumps. Available online: https://www.osti.gov/biblio/6447621 (accessed on 8 December 2021).
- Grundfos Research and Technology. Mechanical Shaft Seals for Pumps. 2009, p. 105. Available online: http://www.grundfos.com/content/dam/GlobalSite/Industries&solutions/Industry/pdf/ShaftSeal_samlet.pdf (accessed on 8 October 2022).
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Fausing Olesen, J.; Shaker, H.R. Predictive maintenance for pump systems and thermal power plants: State-of-the-art review, trends and challenges. Sensors 2020, 20, 2425. [Google Scholar] [CrossRef]
- Mobley, R.K. Benefits of predictive maintenance 50/869 50. 1 Introduction. In Plant Engineer’s Handbook; Elsevier: Amsterdam, The Netherlands, 2001; pp. 867–888. [Google Scholar] [CrossRef]
- Dong, L.; Xiao, Q.; Jia, Y.; Fang, T. Review of research on intelligent diagnosis of oil transfer pump malfunction. Petroleum 2022, in press. [Google Scholar] [CrossRef]
- Orrù, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine learning approach using MLP and SVM algorithms for the fault prediction of a centrifugal pump in the oil and gas industry. Sustainability 2020, 12, 4776. [Google Scholar] [CrossRef]
- ALTobi, M.A.S.; Bevan, G.; Wallace, P.; Harrison, D.; Ramachandran, K.P. Fault diagnosis of a centrifugal pump using MLP-GABP and SVM with CWT. Eng. Sci. Technol. Int. J. 2019, 22, 854–861. [Google Scholar] [CrossRef]
- Zhang, X.L.; Chen, W.; Wang, B.J.; Chen, X.F. Intelligent fault diagnosis of rotating machinery using support vector machine with ant colony algorithm for synchronous feature selection and parameter optimization. Neurocomputing 2015, 167, 260–279. [Google Scholar] [CrossRef]
- Bilski, P. Application of Support Vector Machines to the induction motor parameters identification. Meas. J. Int. Meas. Confed. 2014, 51, 377–386. [Google Scholar] [CrossRef]
- Ebrahimi, E.; Javidan, M. Vibration-based classification of centrifugal pumps using support vector machine and discrete wavelet transform. J. Vibroeng. 2017, 19, 2586–2597. [Google Scholar] [CrossRef] [Green Version]
- Javaid, A.; Javaid, N.; Wadud, Z.; Saba, T.; Sheta Osama, E.; Saleem, M.Q.; Alzahrani, M.E. Machine learning algorithms and fault detection for improved belief function based decision fusion in wireless sensor networks. Sensors 2019, 19, 1334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Costello, J.J.A.; West, G.M.; McArthur, S.D.J. Machine learning model for event-based prognostics in gas circulator condition monitoring. IEEE Trans. Reliab. 2017, 66, 1048–1057. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Jin, T.; Wu, B.; Ding, F. Condition based maintenance optimization for wind power generation systems under continuous monitoring. Renew. Energy 2011, 36, 1502–1509. [Google Scholar] [CrossRef]
- Zouari, R.; Sieg-Zieba, S.; Sidahned, M. Fault Detection System for Centrifugal Pumps Using Neural Networks and Neuro-Fuzzy. Surveillance 2004, 5, 11–13. [Google Scholar]
- Jirdehi, M.A.; Rezaei, A. Parameters estimation of squirrel-cage induction motors using ANN and ANFIS. Alexandria Eng. J. 2016, 55, 357–368. [Google Scholar] [CrossRef] [Green Version]
- Asgari, H.; Chen, X.; Sainudiin, R. Applications of artificial neural networks (ANNs) to rotating equipment. 2011. Available online: https://ir.canterbury.ac.nz/handle/10092/6402 (accessed on 8 December 2021).
- Guedes, A.S.; Silva, S.M.; de Cardoso Filho, B.J.; Conceição, C.A. Evaluation of electrical insulation in three-phase induction motors and classification of failures using neural networks. Electr. Power Syst. Res. 2016, 140, 263–273. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, D.; Chen, W.; Hou, H. Oil-immersed Power Transformer Internal Fault Diagnosis Research Based on Probabilistic Neural Network. Procedia Comput. Sci. 2016, 83, 1327–1331. [Google Scholar] [CrossRef] [Green Version]
- Rajpal, P.S.; Shishodia, K.S.; Sekhon, G.S. An artificial neural network for modeling reliability, availability and maintainability of a repairable system. Reliab. Eng. Syst. Saf. 2006, 91, 809–819. [Google Scholar] [CrossRef]
- Sikorska, J.Z.; Hodkiewicz, M.; Ma, L. Prognostic modelling options for remaining useful life estimation by industry. Mech. Syst. Signal Process. 2011, 25, 1803–1836. [Google Scholar] [CrossRef]
- Manikandan, S.; Duraivelu, K. Fault diagnosis of various rotating equipment using machine learning approaches—A review. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2021, 235, 629–642. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Diez-Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Inf. Fusion 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2013, 42, 314–334. [Google Scholar] [CrossRef]
- Srivyas, P.D.; Singh, S.; Singh, B. Study of Various Maintenance Approaches Types of Failure and Failure Detection Techniques Used in Hydraulic Pumps: A Review. Ind. Eng. J. 2018, 10, 26–35. [Google Scholar] [CrossRef] [Green Version]
- Pennacchi, P. (Ed.) Proceedings of the 9th IFToMM International Conference on Rotor Dynamics; Springer: Berlin/Heidelberg, Germany, 2015; Volume 21. [Google Scholar] [CrossRef]
- Ranawat, N.S.; Kankar, P.K.; Miglani, A. Fault diagnosis in centrifugal pump using support vector machine and artificial neural network. J. Eng. Res. 2021, 9, 99–111. [Google Scholar] [CrossRef]
- Freeman, P.; Pandita, R.; Srivastava, N.; Balas, G.J. Model-based and data-driven fault detection performance for a small UAV. IEEE/ASME Trans. Mechatron. 2013, 18, 1300–1309. [Google Scholar] [CrossRef]
- Luo, Y.; Zhixiang, X.; Sun, H.; Yuan, S.; Yuan, J. Research on the induction motor current signature for centrifugal pump at cavitation condition. Adv. Mech. Eng. 2015, 7, 1–13. [Google Scholar] [CrossRef]
- Piltan, F.; Kim, J.M. Hybrid fault diagnosis of bearings: Adaptive fuzzy orthonormal-ARX robust feedback observer. Applied Sciences 2020, 10, 3587. [Google Scholar] [CrossRef]
- Wang, H.; Peng, C. Sequential Condition Diagnosis for Centrifugal Pump System Using Fuzzy Neural Network. Neural Inf. Processing-Lett. Rev. 2007, 11, 41–50. [Google Scholar] [CrossRef] [Green Version]
- Sakthivel, N.R.; Sugumaran, V.; Nair, B.B. Comparison of decision tree-fuzzy and rough set-fuzzy methods for fault categorization of mono-block centrifugal pump. Mech. Syst. Signal Process. 2010, 24, 1887–1906. [Google Scholar] [CrossRef]
- Soylemezoglu, A.; Jagannathan, S.; Saygin, C. Mahalanobis-Taguchi system as a multi-sensor based decision making prognostics tool for centrifugal pump failures. IEEE Trans. Reliab. 2011, 60, 864–878. [Google Scholar] [CrossRef]
- Xie, G.; Liu, J.; Chen, Z. Hierarchy fault diagnosis based on signed directed graphs model. In Proceedings of the 24th Chinese Control and Decision Conference, Taiyuan, China, 23–25 May 2012; pp. 2270–2274. [Google Scholar] [CrossRef]
- Cocquempot, V.; Izadi-zamanabadi, R. Pump applications. World Pumps 1984, 14, 170–171. [Google Scholar]
- Perovic, S.; Unsworth, P.J.; Higham, E.H. Fuzzy logic system to detect pump faults from motor current spectra. Conf. Rec. IAS Annu. Meet. IEEE Ind. Appl. Soc. 2001, 1, 274–280. [Google Scholar] [CrossRef]
- Rothe, U.; Siering, G.; Berger, D.; Fürstenow, J. Faunistische Untersuchungen im Gebiet der “Deetzer Erdelöcher” und Umgebung (Brandenburg, Potsdam-Mittelmark, Mittlere Havel). Available online: https://www.researchgate.net/publication/353370858_Faunistische_Untersuchungen_im_Gebiet_der_Deetzer_Erdelocher_und_Umgebung_Brandenburg_Potsdam-Mittelmark_Mittlere_Havel-_Teil_6_Untersuchung_zur_Wildbienenfauna_Hymenoptera_Apiformes_auf_zwei_Trockenr (accessed on 8 December 2021).
- Kafka, T. Aufbau Eines Störungsfrüherkennungssystems für Pumpen der Verfahrenstechnik mit Hilfe Maschinellen Lernens. Ph.D. Thesis, Univ. Kaiserlautern, Kaiserslautern, Germany, 1999. [Google Scholar]
- Kollmar, D. Störungsfrüherkennung an Kreiselpumpen mit Verfahren des Maschinellen Lernens; Lehrstuhl für Strömungs-und Verdrängermaschinen, Univ.: Kaiserslautern, Germany, 2002. [Google Scholar]
- Hellmann, H.P.D.; Kiggen, M. Forschungsberichte. Available online: https://embodiment.ch/research/researchpapers/FB11_2.pdf (accessed on 8 December 2021).
- Huaqing, W.; Peng, C. Intelligent Method for Condition Diagnosis of PumpSystem Using Discrete Wavelet Transform, Rough Sets and Neural Network. In Proceedings of the International Conference on Bio-Inspired Computing: Theories and Applications (BICTA 2007), Zhengzhou, China, 14–17 September 2007; pp. 24–28. [Google Scholar] [CrossRef]
- Mendel, M.; Mariano, L.Z.; Drago, I. Automatic bearing fault pattern recognition using vibration signal analysis. In Proceedings of the 2008 IEEE International Symposium on Industrial Electronics, Cambridge, UK, 30 June–2 July 2008; pp. 955–960. [Google Scholar] [CrossRef]
- Stopa, M.M.; Cardoso Filho, B.J.; Martinez, C.B. Incipient detection of cavitation phenomenon in centrifugal pumps. IEEE Trans. Ind. Appl. 2014, 50, 120–126. [Google Scholar] [CrossRef]
- Yunlong, Z.; Peng, Z. Vibration Fault Diagnosis Method of Centrifugal Pump Based on EMD Complexity Feature and Least Square Support Vector Machine. Energy Procedia 2012, 17, 939–945. [Google Scholar] [CrossRef] [Green Version]
- Harihara, P.P.; Parlos, A.G. Fault Diagnosis of Centrifugal Pumps Using Motor Electrical Signals. In Centrifugal Pumps; IntechOpen: London, UK, 2012. [Google Scholar] [CrossRef] [Green Version]
- Bachschmid, N.; Pennacchi, P.; Vania, A. Identification of multiple faults in rotor systems. J. Sound Vib. 2003, 254, 327–366. [Google Scholar] [CrossRef] [Green Version]
- Geiger, G. Technische Fehlerdiagnose Mittels Parameterschatzung und Fehlerklassifikation am Beispiel Einer Elektrisch Angetriebenen Kreiselpumpe; VDI Verlag: Düsseldorf, Germany, 1985. [Google Scholar]
- Nold, S. Wissensbasierte Fehlererkennung und Diagnose mit den Fallbeispielen Kreiselpumpe und Drehstrommotor; VDI Verlag: Düsseldorf, Germany, 1991. [Google Scholar]
- Liu, B.; Si, J. Fault Isolation Filter Design. IEEE Trans. Autom. Control 1994, 42, 704–707. [Google Scholar] [CrossRef]
- Patton, R.J.; Chen, J. Observer-based fault detection and isolation: Robustness and applications. Control Eng. Pract. 1997, 5, 671–682. [Google Scholar] [CrossRef]
- Hajizadeh, Y. Machine learning in oil and gas; a SWOT analysis approach. J. Pet. Sci. Eng. 2019, 176, 661–663. [Google Scholar] [CrossRef]
- Cook, D.J.; Mulrow, C.D.; Haynes, R.B. Systematic reviews: Synthesis of best evidence for clinical decisions. Ann. Intern. Med. 1997, 126, 376–380. [Google Scholar] [CrossRef]
- Amruthnath, N. A research study on unsupervised machine learning algorithms for early fault detection in predictive maintenance. In Proceedings of the 5th International Conference on Industrial Engineering and Applications, ICIEA 2018, Singapore, 26–28 April 2018; pp. 355–361. [Google Scholar] [CrossRef]
- Ghali, A.A.; Jamel, S.; Mohamad, K.M.; Yakub, N.A.; Deris, M.M. A review of iris recognition algorithms. JOIV Int. J. Inform. Vis. 2017, 1, 175–1781. [Google Scholar] [CrossRef] [Green Version]
- Ghali, A.A.; Jamel, S.; Pindar, Z.A.; Disina, A.H.; Daris, M.M. Reducing Error Rates for Iris Image using higher Contrast in Normalization process. IOP Conf. Ser. Mater. Sci. Eng. 2017, 226, 12110. [Google Scholar] [CrossRef] [Green Version]
- Ghali, A.A.; Jamel, S.; Mohamad, K.M.; Khalid, S.K.A.; Pindar, Z.A.; Deris, M.M. An improved low contrast image in normalization process for Iris recognition system. Adv. Intell. Syst. Comput. 2018, 700, 495–505. [Google Scholar] [CrossRef]
- Liu, Z.; Jia, Z.; Vong, C.M.; Bu, S.; Han, J.; Tang, X. Capturing High-Discriminative Fault Features for Electronics-Rich Analog System via Deep Learning. IEEE Trans. Ind. Inform. 2017, 13, 1213–1226. [Google Scholar] [CrossRef]
- Varga, A. Fault diagnosis. Stud. Syst. Decis. Control. 2017, 84, 27–56. [Google Scholar] [CrossRef]
- Janssens, O.; Van De Walle, R.; Loccufier, M.; Van Hoecke, S. Deep Learning for Infrared Thermal Image Based Machine Health Monitoring. IEEE/ASME Trans. Mechatron. 2018, 23, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Jiang, G.; He, H.; Xie, P.; Tang, Y. Stacked multilevel-denoising autoencoders: A new representation learning approach for wind turbine gearbox fault diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 2391–2402. [Google Scholar] [CrossRef]
- Rietman, E.A.; Beachy, M. A study on failure prediction in a plasma reactor. IEEE Trans. Semicond. Manuf. 1998, 11, 670–680. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, J.; Yan, R.; Mao, K. Machine health monitoring with LSTM networks. In Proceedings of the 2016 10th International Conference on Sensing Technology (ICST), Nanjing, China, 11–13 November 2016. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Çinar, Z.M.; Nuhu, A.A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine learning in predictive maintenance towards sustainable smart manufacturing in industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Amihai, I.; Gitzel, R.; Kotriwala, A.M.; Pareschi, D.; Subbiah, S.; Sosale, G. An industrial case study using vibration data and machine learning to predict asset health. In Proceedings of the International Conference on Business Informatics CBI, 20th IEEE, Vienna, Austria, 11–13 July 2018; pp. 178–185. [Google Scholar] [CrossRef]
- Wang, Y. The Application of Artificial Intelligence in Mechanical Manufacture Industry. IOP Conf. Series: Mater. Sci. Eng. 2019, 688, 33058. [Google Scholar] [CrossRef]
- Dutta, N.; Kaliannan, P.; Shanmugam, P. Application of machine learning for inter turn fault detection in pumping system. Sci. Rep. 2022, 12, 12906. [Google Scholar] [CrossRef]
- Bughin, J.; Seong, J.; Manyika, J.; Chui, M.; Joshi, R.; McKinsey Global Institute. Notes from the AI Frontier: Modeling the Impact of AI on the World Economy. Available online: https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-modeling-the-impact-of-ai-on-the-world-economy (accessed on 3 April 2021).
- Kubat, M. Neural networks: A comprehensive foundation by Simon Haykin, Macmillan, 1994, ISBN 0-02-352781-7. Knowl. Eng. Rev. 1999, 13, 409–412. [Google Scholar] [CrossRef]
- Lazakis, I.; Raptodimos, Y.; Varelas, T. Predicting ship machinery system condition through analytical reliability tools and artificial neural networks. Ocean Eng. 2018, 152, 404–415. [Google Scholar] [CrossRef] [Green Version]
- Samanta, B. Gear fault detection using artificial neural networks and support vector machines with genetic algorithms. Mech. Syst. Signal Process. 2004, 18, 625–644. [Google Scholar] [CrossRef]
- Azadeh, A.; Saberi, M.; Kazem, A.; Ebrahimipour, V.; Nourmohammadzadeh, A.; Saberi, Z. A flexible algorithm for fault diagnosis in a centrifugal pump with corrupted data and noise based on ANN and support vector machine with hyper-parameters optimization. Appl. Soft Comput. J. 2013, 13, 1478–1485. [Google Scholar] [CrossRef]
- Osisanwo, F.Y.; Akinsola, J.E.T.; Awodele, O.; Hinmikaiye, J.O.; Olakanmi, O.; Akinjobi, J. Supervised Machine Learning Algorithms: Classification and Comparison. Int. J. Comput. Trends Technol. 2017, 48, 128–138. [Google Scholar] [CrossRef]
- Omri, N.; Al Masry, Z.; Mairot, N.; Giampiccolo, S.; Zerhouni, N. Towards an adapted PHM approach: Data quality requirements methodology for fault detection applications. Comput. Ind. 2021, 127, 103414. [Google Scholar] [CrossRef]
- Hu, Q.; Ohata, E.F.; Silva, F.H.; Ramalho, G.L.; Han, T.; Reboucas Filho, P.P. A new online approach for classification of pumps vibration patterns based on intelligent IoT system. Measurement 2020, 151, 107138. [Google Scholar] [CrossRef]
- Li, H.; Yu, H.; Cao, N.; Tian, H.; Cheng, S. Applications of Artificial Intelligence in Oil and Gas Development. Arch. Comput. Methods Eng. 2021, 28, 937–949. [Google Scholar] [CrossRef]
- Kitchenham, B. Procedures for performing systematic reviews. Keele UK Keele Univ. 2004, 33, 1–26. [Google Scholar]
- Rajakarunakaran, S.; Venkumar, P.; Devaraj, D.; Rao, K.S.P. Artificial neural network approach for fault detection in rotary system. Appl. Soft Comput. J. 2008, 8, 740–748. [Google Scholar] [CrossRef]
- Nasiri, M.R.; Mahjoob, M.J. In Proceedings of the IEEE International Conference on Mechatronics, Taipei, Taiwan, 10–12 July 2005. [CrossRef]
- Azadeh, A.; Asadzadeh, S.M.; Salehi, N.; Firoozi, M. Condition-based maintenance effectiveness for series-parallel power generation system—A combined Markovian simulation model. Reliab. Eng. Syst. Saf. 2015, 142, 357–368. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, Z.; Lu, C.; Ma, J.; Li, L. Fault diagnosis for centrifugal pumps using deep learning and softmax regression. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 165–169. [Google Scholar] [CrossRef]
- Azizi, R.; Attaran, B.; Hajnayeb, A.; Ghanbarzadeh, A.; Changizian, M. Improving accuracy of cavitation severity detection in centrifugal pumps using a hybrid feature selection technique. Meas. J. Int. Meas. Confed. 2017, 108, 9–17. [Google Scholar] [CrossRef]
- Rapur, J.S.; Tiwari, R. Automation of multi-fault diagnosing of centrifugal pumps using multi-class support vector machine with vibration and motor current signals in frequency domain. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 278. [Google Scholar] [CrossRef]
- Moleda, M.; Momot, A.; Mrozek, D. Predictive maintenance of boiler feed water pumps using SCADA data. Sensors 2020, 20, 571. [Google Scholar] [CrossRef]
- Zhou, H.; McGinty, J.; Parlikad, A.K. Failure prediction of auxiliary lube oil pump in gas turbines: Applying Monte Carlo neural networks to an unbalanced dataset. IFAC PapersOnLine 2020, 53, 131–136. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Zheng, Y.; Wang, K. Adaptive prognosis of centrifugal pump under variable operating conditions. Mech. Syst. Signal Process. 2019, 131, 576–591. [Google Scholar] [CrossRef]
- Yang, R.; Huang, M.; Lu, Q.; Zhong, M. Rotating Machinery Fault Diagnosis Using Long-short-term Memory Recurrent Neural Network. IFAC PapersOnLine 2018, 51, 228–232. [Google Scholar] [CrossRef]
- Silvestrin, L.P.; Hoogendoorn, M.; Koole, G. A Comparative Study of State-of-the-Art Machine Learning Algorithms for Predictive Maintenance. In Proceedings of the IEEE Symposium Series on Computational Intelligence SSCI, Xiamen, China, 6–9 December 2019; pp. 760–767. [Google Scholar] [CrossRef]
- Bresser, P.; Griffiths, R. Machine Health Monitoring. SAE Technical Paper; SAE International: Warrendale, PA, USA, 1993; pp. 1–10. [Google Scholar] [CrossRef]
- Qian, W.; Wang, S.; Li, J.; Wu, Q. A novel supervised sparse feature extraction method and its application on rotating machine fault diagnosis. Neurocomputing 2018, 320, 129–140. [Google Scholar] [CrossRef]
- Alabied, S.; Hamomd, O.; Daraz, A.; Gu, F.; Ball, A.D. Fault diagnosis of centrifugal pumps based on the intrinsic time-scale decomposition of motor current signals. In Proceedings of the 23rd IEEE International Conference on Automation and Computing: Addressing Global Challenges through Automation and Computing ICAC, Huddersfiled, UK, 7–8 September 2017; pp. 7–8. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man, Cybern. Syst. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- Han, Y.; Zhao, D.; Hou, H. Oil-immersed Transformer Internal Thermoelectric Potential Fault Diagnosis Based on Decision-tree of KNIME Platform. Procedia Comput. Sci. 2016, 83, 1321–1326. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, M.; Lv, W.; Geng, X.; Li, Y. A novel method using adaptive hidden semi-Markov model for multi-sensor monitoring equipment health prognosis. Mech. Syst. Signal Process. 2015, 64–65, 217–232. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Parameter | Method | Fault |
|---|---|---|---|
| [74] Wang et al., 2007 | Statistical parameters | Neuro-Fuzzy classifier | Cavitation, impeller damage, and imbalance |
| [75] Sakthivel et al., 2010 | Statistical features extracted from vibration signals | Decision tree and rough sets Fuzzy classifiers | Bearing, seal, and impeller faults |
| [76] Soylemezoglu et al., 2011 | Sensors for lateral acceleration, vertical acceleration, and inlet and outlet pressure, as well as outlet flow | Mahalanobis–Taguchi System | Clogging of filter and seal faults or impeller |
| [77] Xie Gang et al., 2012 | Inlet upper flow rate of the tank, outlet flow of the pump, flow detection unit, inlet valve of the pump, tank level, the inlet pressure of the pump, liquid level detection unit, and outlet valve of the pump | Signed directed graphs | Motor circuit damage and power outage of the impeller and the drive shaft |
| [78,79] Kallesoe 2006 | Current spectrum signatures | Signal analysis | Different fault detection methods for blockages, cavitation, and damaged impellers |
| Authors | Parameter | Method | Fault |
|---|---|---|---|
| [80] Brandenburgischen 2015 | Pressure fluctuation and mechanical vibration signals | Neuro-fuzzy classifier | Impeller misalignment |
| [81] Kafka T 1999 | Pressures, temperatures, power, and flow | Fast Fourier transformation (FFT) | Imbalance, blockade, and wear |
| [82] Kollmar 2002 | Pressures, temperatures, power, and flow | Neural networks, discriminants, and Bayes classifiers | Imbalance, blockade, and wear |
| [83] Kiggen 2006 | Flow, temperature, angular velocity, pressure, and the magnetic field | Decision tree classifier | Gas fault states in fluid, cavitation, and blockade |
| [84] Wang et al., 2007 | Flow, temperature, angular velocity, pressure, and the magnetic field | Discrete wavelet transforms, a neuro-fuzzy classifier based on rough set theory | Cavitation, misalignment, and impeller damage |
| [85] Mendel et al., 2008 | Horizontal, axial, and vertical accelerations | K-nearest-neighbor approach, as well as a multi-layer perceptron neural network | Bearing faults |
| [86] Stopa et al., 2014 | Currents and rotor positions | Load torque signature analysis | Cavitation |
| [87] Yunlong et al., 2012 | Frequency spectra | Bayesian belief network, as well as a support vector machine | Incorrect alignment, imbalance, and foundation looseness |
| Authors | Parameter | Method | Fault |
|---|---|---|---|
| [90] Geiger 1985 | Input, output, and differences in pressure | Parameter estimation scheme | Bearing without lubrication, polluted bearing, increased ring backlash, impeller defect, volute defect, cavitation, insufficient ventilation, increased fluid temperature, and changed valve position |
| [91] Nold 1991 | Pressure, temperature, and flow signals | Parameter estimation | Wear of suction-sided seal gap, deposits, wear at the impeller outlet, impeller blade fracture, cavitation erosion at the impeller inlet |
| [92] Liu et al., 1994 | Motor current, voltage, angular velocity, and fluid speed | Observer-based fault diagnosis | Deviating coefficients in process and actuator, sensor faults |
| [93] Patton et al., 1997 | Motor current, suction, and discharge pressures | Observer-based fault diagnosis | Detection of multiple faults occurring at once |
| Principal Terms | Oil and Gas Pumps | Prognostic and Diagnostic | Reliability | Failure | Machine Learning |
|---|---|---|---|---|---|
| Derived terms | Crude oil pumps | Detection | Remaining useful life | Degradation | Artificial intelligence |
| Hydrocarbon pumps | Prevention | Integrity | Critical failure | ||
| Gas pumps | Probability of failure |
| Inclusion and exclusion criteria |
|
| Exclusion criteria |
|
| Tools | Annotations |
|---|---|
| TensorFlow IBM | Collection of open-source software for performing computational calculations. |
| IBM Watson Studio RapidMiner | ML framework developed specifically for an AI-driven business. |
| RapidMiner | Embraces the entirety of the data science lifecycle, including but not limited to data planning, machine learning, and the deployment of prediction algorithms. |
| Google Cloud AI Platform | Machine learning can learn from any data, in any amount. |
| Box skills | Organize your data, then, at scale, draw insights from it. |
| Google Cloud AutoML | Develop superior models that are tailored to their company’s demands. |
| SAS Enterprise Miner | Simplifies the data mining procedure so that models may be quickly created and the most important patterns for processes can be found. |
| MATLAB | A software package made by MathWorks that can be used for programming, modeling, and simulation. |
| IBM Watson Machine Learning | Use preexisting data for model development, testing, and production use in machine learning and deep learning. |
| Anaconda Enterprise | Leverage ML/AI/data science techniques. |
| Amazon SageMaker | Models may be constructed, trained, and deployed rapidly, regardless of scale. |
| IBM Decision Optimization | Uses both mathematical and AI methods to improve planning and scheduling decisions. |
| IBM Cloud Pak for Data | Transforms its data gathering and data analysis practices to integrate AI throughout its organization. |
| BigML | Learning through programmable machines. |
| H2O | Early disease identification, medication discovery, and individualized medical care. |
| Oracle Data Science Cloud Service | Model training, deployment, and management in the Oracle Cloud. |
| Domino | Accelerate the process of creating and deploying predictive models. |
| Deep Cognition | Build ML models without code. |
| KNIME Analytics | A platform for data analytics, reporting, and integration |
| Qubole | A platform for ML, streaming, and ad hoc analytics using data lakes. |
| Algorithms | Pros | Cons |
|---|---|---|
| Artificial Neural Network (ANN), multi-layer perceptron (MLE), feed-forward (FF), radial basis function (RBF) convolutional (CN) functional, (FN), and probabilistic (PN) | Powerful parallel distributed processing ability, strong distributed storage and learning ability, strong robustness and fault tolerance to noisy nerves, full approximation of complex nonlinear relations, associative memory function, etc. | Numerous parameters are required, including network topology, initial weight and threshold settings; output that is difficult to read; lengthy training period, etc. |
| Particle swarm optimization (PSO) | Free from the problem information, solve problems with real numbers, strong universality, few parameter adjustments, straightforward theory, simple implementation, collaborative search, and rapid convergence. | Low precision, prone to divergence, and dependent on parameters; the theory is imperfect. |
| Fuzzy logic | Robustness is strong and straightforward to accomplish; mathematical precision is unnecessary. | Low precision and absence of systematic design. |
| Support vector machine (SVM) | Appropriate for small-sample machine learning issues; can improve generalization performance, tackle high dimensional problems, address nonlinear problems, and avoid neural network structure selection and the local minimum point problem. | Nonlinear issues are sensitive to missing data, and no universal solution exists. |
| Genetic algorithm (GA) | Possibility of parallelism and resilience, simplicity, use of a probability mechanism to perform iterations with a given degree of unpredictability, extensible, and simple to connect with other algorithms. | After determining the ideal solution, complex programming, issue decoding, and more training time are necessary to arrive at an exact solution. |
| Decision tree (DT) | Nonlinearity among parameters has no effect on DT performance; explainable and interpretable. | Complex; duplication may occur for identical subtrees of different routes. |
| K nearest neighbors (KNN) | Classes do not require linear divisibility; modest and strong; understandable and easy to implement technique; can be trained quickly; robust in case of associated noise; it is mainly well suited for multimodal classification. | Tends to disregard the attributes’ importance; slow and expensive, and sensitive to local data structure; memory restriction. |
| Random forest | High performance gives rise to variable measures; quick in implementation; less complex; robust with noisy data and can learn in increments. | Computationally expensive over fit issues; does not depend on variables; disregards the original geometry of data; low performance with attribute-related training data. |
| k-Means | Each data point may exist in several clusters; normalization of gene behavior depiction; a modifiable model that can accommodate varying dataset distributions; if the training data rise, the number of parameters does not alter. | Need to define cluster count c; membership cutoff value must be established; the initial assignment of centroids influences cluster formation; the convergence is slow in some cases. |
| Recurrent neural network (RNN) | Can record the information as timed activations; can manipulate consecutive data where lengths are arbitrary. | It is affected by the vanishing gradient type; it is incompatible with extra-deep modeling stacking. |
| Convolutional neural network (CNN) | Capable of detecting only the relevant features from a given dataset; similar parameters can be applied to distinct challenges; rapid training. | The tuning of parameters is challenging, and the network needs a substantial amount of data |
| Deep belief network (DBN) | A layer-by-layer learning technique enables it to learn the features; deals with unlabeled data and is immune to overfitting and underfitting problems; not affected by the fragmentation of training data, thus, it reduces the over-smoothing problem. | Some pre-training strategies degrade when the input data is constrained; runtime is extensive; the quality of output is low. |
| Author/Year | Algorithm Used | Findings | Parameters | Platform Used | Data Source |
|---|---|---|---|---|---|
| [38] Chen et al., 2021 | k-nearest neighbor algorithm (KNN), based on the Mahalanobis distance, using the ReliefF weight analysis algorithm | Cavitation, impeller damage, and machine seal damage | Root mean square, peak factor, skewness coefficient, and kurtosis | Python | Synthetic data |
| [40] Giro et al., 2021 | Gaussian mixture model (GMM) | Pressure | Real data | ||
| [49] Pier et al., 2020 | Support vector machine (SVM) and multilayer perceptron (MLP) | Early fault prediction of a centrifugal pump | Temperature, pressure, and vibration probes | KNIME | Real and synthetic data |
| [119] Hu et al., 2020 | Gaussian naive Bayes (GNB), support vector machines (SVM), random forest (RF), multilayer perceptron (MLP), and k-nearest neighbors (KNN) | Cavitation | Vibration | LINDA | Synthetic data |
| [129] Moleda 2020 | Polynomial regression | Fault detection and diagnostics | Temperature, Pressure, Mass Flow, Current | Real data | |
| [130] Zhou et al., 2020 | Monte Carlo modified NN | Monitoring and failure prediction of lube oil pumps | Time stamp, pressure transmitter, oil pressure, oil quality, oil temperature, alternating current, and direct current | Real data | |
| [131] Wang et al., 2019 | Gaussian mixture model (GMM) clustering | Operation modes | Vibration | Synthetic data | |
| [132] Yang et al., 2019 | Feature-based transfer neural network (FTNN), convolutional neural network (CNN) | Identify the health states of bearings used in real-case machines BRMs | Raw vibration data | Real data | |
| [131] Wang et al., 2019 | Adaptive order particle filter (AOPF) | Estimate RUL | Vibration | Synthetic data | |
| [45] Li et al., 2019 | Sparsity and neighbor- hood preserving deep extreme learning machine (SNP-DELM), extreme learning machine-autoencoder (ELM-AE) | Bearing fault diagnosis | Number of balls, Pitch diameter, Ball diameter, Outer-race fault order, Inner-race fault order | MATLAB | Real data |
| [133] Luis. P et al., 2019 | Temporal convolutional network (TCN), KNN, LSTM, | Internal pump leakage | Pressure, temp. volume flow, vibration, cooling efficiency, cooling power, the efficiency factor | ||
| [134] Janssens et al., 2018 | Deep neural networks, convolutional neural networks, deep learning. (DNN-CNN, DL) | Machine fault detection and oil level prediction | Accelerometer, thermocouple, and thermal camera measurements | Real data | |
| [135] Wu 2018 et al. | Self-organized mapping (SOM) neural network (NN); a long short-term memory (LSTM) network is utilized | Fault detection | Vibration | Synthetic data | |
| [28] He et al., 2018 | Ladder network, multi-layer perceptron, and denoising autoencoder (LN, MLP, DAE) | Estimate RUL | Flow, pressure, stress | ||
| [37] Dutta et al., 2018 | SVM | Cavitation detection | Speed, pressure | Lab view | Real data measurement |
| [132] Yang et al., 2018 | Feature-based transfer neural network (FTNN), convolutional neural network (CNN) | Health status of bearings | Normal (N), inner race fault (IF), roller fault (RF), and outer race fault (OF). | Real data | |
| [61] Zhang et al., 2018 | Convolutional neural networks (CNNs) | Fault diagnosis in rolling bearing | Healthy condition (H), outer race fault (OF), inner race fault (IF), and ball fault (BF). | Synthetic data | |
| [136] Samir et al., 2017 | Intrinsic time-scale decomposition (ITD) | Motor current signals from different pump fault cases. | RMS values of the first proper rotation component (PRC) with the raw signal RMS values | ||
| [137] Jason and David, 2017 | Deep belief network feed-forward neural network (DBN- FNN) | Remaining useful life (RUL) of the rotating components | Real data | ||
| [61] Zhao et al., 2016 | Stacked denoising autoencoder (SDA) and softmax regression | Identify possible failure modes | Real data | ||
| [138] Han et al., 2016 | Decision-tree C4.5 algorithm | Internal thermo-electric potential faults | Low-temperature superheat, high-temperature superheat, low energy discharge, high energy discharge, arc discharge with overheating | KNIME, MATLAB | Synthetic data |
| [139] Liu 2015 | Adaptive hidden semi-Markov model (AHMM) | Estimate RUL | Oil flow | Real data |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aliyu, R.; Mokhtar, A.A.; Hussin, H. Prognostic Health Management of Pumps Using Artificial Intelligence in the Oil and Gas Sector: A Review. Appl. Sci. 2022, 12, 11691. https://doi.org/10.3390/app122211691
Aliyu R, Mokhtar AA, Hussin H. Prognostic Health Management of Pumps Using Artificial Intelligence in the Oil and Gas Sector: A Review. Applied Sciences. 2022; 12(22):11691. https://doi.org/10.3390/app122211691
Chicago/Turabian StyleAliyu, Ruwaida, Ainul Akmar Mokhtar, and Hilmi Hussin. 2022. "Prognostic Health Management of Pumps Using Artificial Intelligence in the Oil and Gas Sector: A Review" Applied Sciences 12, no. 22: 11691. https://doi.org/10.3390/app122211691