
LBFT: An Asynchronous Committee-Based Blockchain Storage Strategy on Zero Trust Model

Abstract
:1. Introduction
1.1. Our Contributions
- Completely decentralized: LBFT is designed on the basis of the conception the zero-trust model, which assumes that all network traffic is untrusted [7,8]. In LBFT, all the messages transmitted on the network are inspected and verified before use by the receivers regardless of previous authority or authentication, which avoids authentication but not verification in the traditional trusted models. Moreover, LBFT deploys a CLAS scheme [9], in which the key generation center only delivers partial private keys in the initialization phase of each party and no longer participates in system operation.
- Committee-based decoding: In LBFT, only a random part of the nodes divided into several committees participate in the decoding process, to recover the requested data. It can be seen from Table 1 that, in BFT-Store, which requires all the parties to perform decoding, an level of communication complexity (where n is the number of nodes) is incurred, while the communication complexity of LBFT is merely (where k is the number of committees, c is the number of members in each committee, l is the decoded message length, and T is the size of a block).
- LBFT is a blockchain storage strategy that obtains higher robustness than BFT-Store and PartitionChain and that is still workable even in scenarios with large geographical ranges and unpredictable network situations. In addition, due to the elimination of a time-bound, the parties will make progress as soon as the messages are delivered, leading to a shorter latency in LBFT.
- LBFT is a combination of RS coding and the HB-BFT protocol, which enables each node to store merely a part of encoded blocks rather than a complete ledger in order to decrease storage consumption and improve system scalability. Moreover, as shown in Table 1, original blocks are partitioned before encoding, which will reduce the computational complexity of encoding and decoding from level to and , respectively, where E is the expected decoding rounds of recovering a block, which will be illustrated in Section 5.
1.2. Related Work
1.3. Organization
2. System and Problem Statement
2.1. System Model
- Ensure that all the resources are accessed securely, no matter where they originate from or who create them;
- Adopt a least privilege strategy to reduce the likelihood for people to behave maliciously, and enforce access control strictly to protect access to restricted resources;
- Inspect and log all the network traffic, flipping the mantra trust but verify into verify and never trust.
2.2. Design Goals
- 1
- Decentralization and Security. To carry forward the conception of decentralization, we should eliminate the reliance on a certain third trust party during the whole operation process of LBFT as far as possible. For system security, all the network traffic should be inspected and logged, and the transmitted values should be verified before they are accessed and operated. Access to certain resources and applications should also be strictly enforced [36].
- 2
- Frugal Communication. LBFT is constructed on a zero-trust model. Moreover, in the previous work BFT-Store, suffering from communication complexity in the decoding process, we aim to construct a protocol that can remove the term during each decoding round, on the premise that the system can recover the original block successfully for client requests.
- 3
- Robustness. Unlike the synchronous schemes that can only be applied to the relatively private and well-connected networks, we hope that LBFT can suit more large-scale, manifold, and unstable networks and can make progress even if the timing assumption of message delivery does not hold.
- 4
- Efficiency. To make LBFT an efficient strategy, we have twofold expectations: (1) minimize the loss of performance resulting from the extra encoding and decoding rounds (compared to the primordial blockchain storage scheme); (2) free the nodes from the constraint of the pre-set timing assumption, so that they can respond immediately after the messages are delivered.
- 5
- Scalability. We expect that LBFT, which is designed to be deployed in promising blockchain systems, can improve the system scalability as well as maintain the original functionalities of the blockchain. In LBFT, the storage costs of the blocks should maintain a constant level in regard to the number of nodes n in the system, on the premise that the data stored on the chain is consistent and accessible at any time.
3. Preliminaries
3.1. Methods and Technologies
- Agreement. If any two honest nodes output the values v and v’, respectively, then v = v’.
- Totality. If one honest node outputs the value v, then all the honest nodes will output v.
- Validity. If the sender is honest and it inputs the value v to the protocol, then all the honest nodes will output v.
- Agreement. If any honest node decides a bit b, then every honest node will decide the bit b.
- Validity. If any honest node decides a bit b, then at least one honest node has received the bit b as input.
- Termination. If all the honest nodes receive a bit as input, then every honest node will decide a bit.
3.2. Related Parameters
4. Design
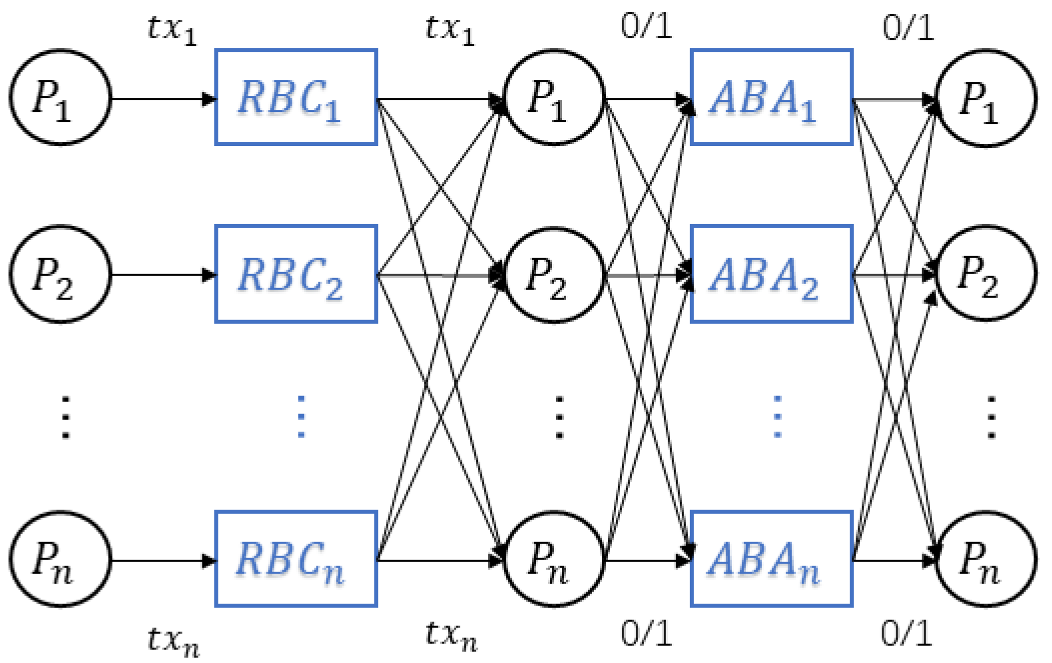
4.1. High-Level Overview
4.2. Detailed Construction
| Algorithm 1 Encoding and Consensus in LBFT. |
Input: node , original block
|
| Algorithm 2 Data Recovery of a Certain Block. |
|
4.3. Committee Election
4.4. Adapting to the Zero-Trust Model
- Provide real-time information on the network situation. The NAV system helps the core components to learn what is going on and to decide the permissions to resources or data for users.
- Give caution to the potential malicious nodes. The deployment of NAV can warn both the inside and outside individuals that their behavior is under supervision so that they will be less tempted to behave maliciously, which lessens the potential malicious behaviors and attacks to some extent.
5. Performance Analysis
5.1. Communication Complexity
- 1
- k round: leader followers, generating a total of l-bit decode messages (where l is the length of decode message);
- 2
- k round: followers leader, incurring communicated bits altogether (where T is the average size of an original block);
- 3
- a round: committees committees, transmitting recovered blocks of size T;
- 4
- a round: committees ABA instance, where the leader of each committee (i.e., k committees altogether) inputs one bit to the common ABA instance;
- 5
- a round: ABA instance committees, where the common ABA instance broadcasts a one-bit result to every committee.
5.2. Computation Efficiency
6. Experimental Evaluation
6.1. Experimental Parameter Setting
6.2. Storage Consumption
6.3. Throughput
6.4. Latency
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hileman, G.; Rauchs, M. Global cryptocurrency benchmarking study. Camb. Cent. Altern. Financ. 2017, 33, 33–113. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Business Review, 31 October 2008. [Google Scholar]
- Qi, X.; Zhang, Z.; Jin, C.; Zhou, A. BFT-Store: Storage partition for permissioned blockchain via erasure coding. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1926–1929. [Google Scholar]
- De Filippi, P. The interplay between decentralization and privacy: The case of blockchain technologies. J. Peer Prod. Issue 2016, 7, hal-01382006. [Google Scholar]
- Luu, L.; Narayanan, V.; Baweja, K.; Zheng, C.; Gilbert, S.; Saxena, P. Scp: A computationally-scalable Byzantine consensus protocol for blockchains. Cryptol. Eprint Arch. 2015, 2015, 1168. [Google Scholar]
- Du, Z.; Qian, H.f.; Pang, X. PartitionChain: A Scalable and Reliable Data Storage Strategy for Permissioned Blockchain. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Kindervag, J.; Balaouras, S.; Balaouras, S.; Mak, K.; Blackborow, J. No more chewy centers: Introducing the zero-trust model of information security. Forr. Res. 2010, 3, 2–16. [Google Scholar]
- Rose, S.; Borchert, O.; Mitchell, S.; Connelly, S. Zero Trust Architecture; Technical Report; National Institute of Standards and Technology: Gaithesburg, MA, USA, 2020. [Google Scholar]
- Zhang, L.; Zhang, F. A new certificateless aggregate signature scheme. Comput. Commun. 2009, 32, 1079–1085. [Google Scholar] [CrossRef]
- Xu, G.; Liu, Y.; Khan, P.W. Improvement of the dpos consensus mechanism in blockchain based on vague sets. IEEE Trans. Ind. Inform. 2019, 16, 4252–4259. [Google Scholar] [CrossRef]
- Zhang, X.; Grannis, J.; Baggili, I.; Beebe, N.L. Frameup: An incriminatory attack on storj: A peer to peer blockchain enabled distributed storage system. Digit. Investig. 2019, 29, 28–42. [Google Scholar] [CrossRef]
- Merkle, R.C. Protocols for public key cryptosystems. In Proceedings of the 1980 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 14–16 April 1980; p. 122. [Google Scholar]
- Poon, J.; Dryja, T. The Bitcoin Lightning Network: Scalable Off-Chain Instant Payments; NYDIG: Manhattan, NY, USA, 2016. [Google Scholar]
- Tremback, J.; Hess, Z.; Universal Payment Channels. November 2015. Available online: http://jtremback.github.io/universal-payment-channels/universal-payment-channels.pdf (accessed on 17 September 2022).
- Wang, B.; Li, Z.; Li, H. Hybrid consensus algorithm based on modified proof-of-probability and dpos. Future Internet 2020, 12, 122. [Google Scholar] [CrossRef]
- Wood, G.; Liang, T. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Kerman, A.; Borchert, O.; Rose, S.; Tan, A. Implementing a zero-trust architecture. Natl. Inst. Stand. Technol. 2020, 2020, 17. [Google Scholar]
- Mukhopadhyay, U.; Skjellum, A.; Hambolu, O.; Oakley, J.; Yu, L.; Brooks, R. A brief survey of cryptocurrency systems. In Proceedings of the IEEE 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 22–24 August 2016; pp. 745–752. [Google Scholar]
- Farell, R. An Analysis of the Cryptocurrency Industry. Ph.D. Thesis, University of Pennsylvania, Pennsylvania, PA, USA, 2015. [Google Scholar]
- Aublin, P.L.; Mokhtar, S.B.; Quéma, V. Rbft: Redundant Byzantine fault tolerance. In Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems, Philadelphia, PA, USA, 8–13 July 2013; pp. 297–306. [Google Scholar]
- Hanke, T.; Movahedi, M.; Williams, D. Dfinity technology overview series, consensus system. arXiv 2018, arXiv:1805.04548. [Google Scholar]
- Abraham, I.; Malkhi, D.; Nayak, K.; Ren, L.; Yin, M. Sync hotstuff: Simple and practical synchronous state machine replication. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–20 May 2020; pp. 106–118. [Google Scholar]
- Castro, M.; Liskov, B. Practical Byzantine fault tolerance. In Proceedings of the OsDI, New Orleans, La, USA, 22–25 February 1999; Volume 99, pp. 173–186. [Google Scholar]
- Yin, M.; Malkhi, D.; Reiter, M.K.; Gueta, G.G.; Abraham, I. Hotstuff: Bft consensus with linearity and responsiveness. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 347–356. [Google Scholar]
- Miller, A.; Xia, Y.; Croman, K.; Shi, E.; Song, D. The honey badger of BFT protocols. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 22 November 2016; pp. 31–42. [Google Scholar]
- Guo, B.; Lu, Z.; Tang, Q.; Xu, J.; Zhang, Z. Dumbo: Faster asynchronous bft protocols. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Online, 2 November 2020; pp. 803–818. [Google Scholar]
- Cachin, C.; Kursawe, K.; Petzold, F.; Shoup, V. Secure and efficient asynchronous broadcast protocols. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2001; pp. 524–541. [Google Scholar]
- Abraham, I.; Malkhi, D.; Spiegelman, A. Asymptotically optimal validated asynchronous Byzantine agreement. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 337–346. [Google Scholar]
- Ben-Or, M.; El-Yaniv, R. Resilient-optimal interactive consistency in constant time. Distrib. Comput. 2003, 16, 249–262. [Google Scholar] [CrossRef]
- Chen, S.; Mi, H.; Ping, J.; Yan, Z.; Shen, Z.; Liu, X.; Zhang, N.; Xia, Q.; Kang, C. A blockchain consensus mechanism that uses proof of solution to optimize energy dispatch and trading. Nat. Energy 2022, 7, 1–8. [Google Scholar] [CrossRef]
- Chen, S.; Shen, Z.; Zhang, L.; Yan, Z.; Li, C.; Zhang, N.; Wu, J. A trusted energy trading framework by marrying blockchain and optimization. Adv. Appl. Energy 2021, 2, 100029. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, L.; Yan, Z.; Shen, Z. A distributed and robust security-constrained economic dispatch algorithm based on blockchain. IEEE Trans. Power Syst. 2021, 37, 691–700. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Y.; Chen, Q.; Liang, Q. A new election algorithm for dpos consensus mechanism in blockchain. In Proceedings of the 2018 7th International Conference on Digital Home (ICDH), Guilin, China, 30 November–1 December 2018; IEEE: Hoboken, NJ, USA, 2018; pp. 116–120. [Google Scholar]
- Lu, Y.; Lu, Z.; Tang, Q.; Wang, G. Dumbo-mvba: Optimal multi-valued validated asynchronous Byzantine agreement, revisited. In Proceedings of the 39th Symposium on Principles of Distributed Computing, Online, 3–7 August 2020; pp. 129–138. [Google Scholar]
- Gilman, E.; Barth, D. Zero Trust Networks; O’Reilly Media Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Buck, C.; Olenberger, C.; Schweizer, A.; Völter, F.; Eymann, T. Never trust, always verify: A multivocal literature review on current knowledge and research gaps of zero-trust. Comput. Secur. 2021, 110, 102436. [Google Scholar] [CrossRef]
- Chang, J.M.; Maxemchuk, N.F. Reliable broadcast protocols. ACM Trans. Comput. Syst. 1984, 2, 251–273. [Google Scholar] [CrossRef] [Green Version]
- Cachin, C.; Kursawe, K.; Shoup, V. Random oracles in Constantinople: Practical asynchronous Byzantine agreement using cryptography. J. Cryptol. 2005, 18, 219–246. [Google Scholar] [CrossRef]
- Mostéfaoui, A.; Moumen, H.; Raynal, M. Signature-free asynchronous binary Byzantine consensus with t< n/3, O (n2) messages, and O (1) expected time. J. ACM 2015, 62, 1–21. [Google Scholar]
- Ben-Or, M. Another advantage of free choice (extended abstract) completely asynchronous agreement protocols. In Proceedings of the Second Annual ACM Symposium on Principles of Distributed Computing, Montreal, QC, Canada, 17–19 August 1983; pp. 27–30. [Google Scholar]
- Wicker, S.B.; Bhargava, V.K. Reed–Solomon Codes and Their Applications; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Schnorr, C.P. Efficient signature generation by smart cards. J. Cryptol. 1991, 4, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Shoup, V. Practical threshold signatures. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Trondheim, Norway, 30 May–3 June 2000; pp. 207–220. [Google Scholar]
- Rasmussen, R.V.; Trick, M.A. Round robin scheduling–A survey. Eur. J. Oper. Res. 2008, 188, 617–636. [Google Scholar] [CrossRef]
- Sandhu, R.S. Role-based access control. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 1998; Volume 46, pp. 237–286. [Google Scholar]
- Rashmi, K.V.; Shah, N.B.; Gu, D.; Kuang, H.; Borthakur, D.; Ramchandran, K. A solution to the network challenges of data recovery in erasure-coded distributed storage systems: A study on the Facebook warehouse cluster. In Proceedings of the 5th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 13), San Jose, CA, USA, 27–28 June 2013. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LBFT | BFT-Store | PartitionChain | |
|---|---|---|---|
| Security Model | Zero-Trust Model | Traditional Trust Model | Traditional Trust Model |
| Time Assumption | Asynchronous | Partially Synchronous | Partially Synchronous |
| Participants in Dec | Committees | Whole Network | Whole Network |
| Communication Complexity | |||
| Complexity in Enc | |||
| Complexity in Dec |
| Parameters | Descriptions |
|---|---|
| n | the number of nodes in the system |
| r | the fault factor of the system |
| f | the threshold of Byzantine nodes that can be controlled by the adversary |
| k | the number of committees |
| c | the number of members in each committee |
| l | the length of decode messages |
| T | the size of a block |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Z.; Gong, J.; Qian, H. LBFT: An Asynchronous Committee-Based Blockchain Storage Strategy on Zero Trust Model. Appl. Sci. 2022, 12, 11790. https://doi.org/10.3390/app122211790
Du Z, Gong J, Qian H. LBFT: An Asynchronous Committee-Based Blockchain Storage Strategy on Zero Trust Model. Applied Sciences. 2022; 12(22):11790. https://doi.org/10.3390/app122211790
Chicago/Turabian StyleDu, Zhengyi, Junqing Gong, and Haifeng Qian. 2022. "LBFT: An Asynchronous Committee-Based Blockchain Storage Strategy on Zero Trust Model" Applied Sciences 12, no. 22: 11790. https://doi.org/10.3390/app122211790