1. Introduction
With the emergence of the epidemic, face recognition technology has been rapidly implemented in various fields of people’s daily life, such as in recognition of automatic passage on campuses, temperature measurement (all-in-one machines), and the use of face recognition in attendance. Traditional face recognition technology includes two main parts: feature extraction and classification. Gabor [
1], the Histogram of Oriented Gradient (HOG) [
2], and the Local Binary Pattern (LBP) [
3] are often used to describe image features. Principal Component Analysis (PCA) [
4,
5] is based on the singular value decomposition (SVD) [
6] algorithm. It performs eigen decomposition on the covariance matrix to obtain the principal components of the data and to achieve data dimensional reduction and extraction. The purpose of important features of PCA is also known as eigenfaces. The feature extraction method, combined with the corresponding classification rules, has been used to solve initial face recognition problems. Common classifiers include the Nearest Neighbor Classifier (NNC) [
7], the Minimum Distance Classifier (MDC) [
8], the K-nearest Neighbor Classifier (KNNC) [
9], and so on. Since traditional face recognition technology may overlook some important facial information or cause the over-fitting of problems in the feature extraction process, the Representation-Based Classification Method (RBCM) [
10,
11,
12,
13] has attracted much attention in recent years. Due to the epidemic’s impact, people must wear masks while going out. The traditional face recognition method cannot effectively identify obscured faces, and the RBCM method is easily affected by abnormal features. In real life, face images often have problems such as illumination, facial expression changes, and facial occlusion. Among these problems, facial occlusion is considered the most challenging. From the literature [
10,
11,
12,
13,
14,
15,
16], it can be seen that the RBCM method can effectively identify face images with changes in light and changes in facial expressions. Still, it is not easy to identify face images with occlusion. Therefore, the RBCM method is improved for facial occlusion to solve the three problems: light changes, facial expression changes, and facial occlusion.
To solve the problem of abnormal features in the RBCM, many research groups have proposed related robust algorithms, among which the Sparse Representation-based Classification (SRC) algorithm was among the first proposed [
10,
11]. The biggest feature of this type of algorithm is its ability to linearly represent the test samples by building a dictionary containing all the training samples. The relatively large time complexity of the SRC algorithm in solving the L1 norm optimization problem has largely limited its applications. However, Zhang et al. [
14] proposed the Collaborative Representation-based Classification (CRC) algorithm. The SRC and CRC algorithms both use training samples from all categories to linearly represent test samples. However, the biggest difference between them is that the CRC algorithm uses the less computationally intensive L2 norm instead of the L1 norm, as used in the SRC algorithm, to solve the optimization problem. Some scholars have proposed a Two-Phase Test Sample Sparse Representation (TPTSSR) algorithm based on the CRC algorithm [
15]. In the first stage of the algorithm, CRC was used to select M training samples for the best representation of test samples. In the second stage, the CRC algorithm was used again to identify the test samples, and the training set was the M training samples determined in the previous stage. The training samples selected in the first stage of TPTSSR cannot improve the accuracy of CRC for face image recognition. Thus, Tang et al. [
16] further improved the algorithm and proposed the Random-filtering-based Sparse Representation (RFSR) algorithm. Liu et al. [
17] improved the distance metric of the SRC algorithm. According to the author’s experiments, using cosine or Euler distance as the measure can expand the inter-sample and intra-class distance simultaneously, and the multiple inter-class distance expansion was much higher than the multiple intra-class distance expansion, which was conducive to improving the robustness of the SRC algorithm. The various RBCM methods proposed in the literature [
10,
11,
12,
13,
14,
15,
16,
17] constrained the model coefficients to float in a small range, reducing the negative impact of face occlusion features on the model coefficients. Constraining the model coefficient through the L1 and L2 norm cannot improve model identification performance. Only when the model is constrained to learn as small a number of occlusion features as possible is model performance made stable.
In addition to using all classes of training samples to represent test samples linearly, representation-based classification methods can also use a single class of training samples to represent the test samples. Linear Regression Classification (LRC) [
18] uses a single category of training samples to reconstruct the samples to be tested. LRC can be viewed as a representation based on the L2 norm, which uses the classification rules of the nearest subspace to classify face images. LRC finally selects the subspace with the smallest distance by projecting the test image onto the subspace. For this, the decision method is based on the distance metric, which is unsuitable for dealing with continuous severe occlusion problems. The LRC method is similar to the SRC and CRC methods, but the LRC method does not restrict the representation coefficient. Therefore, if there are many abnormal variables in the training or test sample, the LRC method can learn a lot of abnormal information. As a result, the model classification fails. Therefore, some researchers, such as the authors of [
18], have adopted the method of modular [
19] image representation, which has made LRC more promising when trying to accurately identify face images with facial occlusions. The modular LRC algorithm [
18] first worked by segmenting a given occlusion image. The “good or bad” image patch was then judged by the distance metric of the intermediate decision, and the “best” image patch was selected. Finally, converting the block into individual decisions was considered the final classification result. The main advantage of this method is its equivalency when dynamically removing occluded partitions. However, the biggest drawback of modular LRC is that it uses only specific blocks (with minimal residuals), discarding blocks that contain other useful face information. At this point, how to extract effective face characteristics and remove occlusion has become a question that researchers [
20,
21] care about.
This paper proposes the Block Permutation Linear Repression Classification (BPLRC) algorithm. The proposed method first modulates the image and then groups the schemes that retain the same number of blocks. Next, their residuals are compared to determine the permutation of the group and the group with the best recognition effect is finally selected. Compared to the modular LRC algorithm, the proposed method retains more useful face information and also achieves the purpose of removing invalid occlusion blocks. Moreover, there is no need to judge the occlusion ratio to achieve the best recognition effect. The algorithm improves the robustness of LRC to recognize the occluded image to a certain extent.
The RBCM methods used in this article mainly include LRC, SRC, CRC, Euler Sparse Representation-based Classification (ESRC [
17]), Module LRC, and the BPLRC method proposed in this article. These methods are the same as linear models, and the type of linear representation is the difference. LRC uses a single class of travelers to reply to the test samples. SRC, ESRC, and CRC methods use all-class training samples to indicate test samples linearly. Among them, SRC and ESRC have differences in distance measurement. The difference between the SRC and CRC algorithm is that SRC uses the L1 model to restrain the sparse coefficient, and CRC uses the L2 model to restrain the sparse coefficient. Module LRC selects the “most useful” block as a feature input of the LRC algorithm through blocking. The difference from the LRC algorithm is that the Module LRC is used to screen the effective face characteristics as much as possible during identification, and the LRC algorithm simply uses all image features in identification. The BPLRC algorithm proposed in this article is similar to Module LRC. All images are modularized, and the identification of LRC algorithms characterizes effective face characteristics. The difference between the BPLRC algorithm and the Module LRC algorithm is that the Module LRC only retains one block, while the BPLRC method considers all the segmentation arrangement schemes to retain as much information as possible. From a principle point of view, all block arrangement schemes in BPLRC include the full-retained LRC and the Module LRC method that only retains one block.
The rest of this article is organized as follows:
Section 2 details the principles of the LRC, SRC, CRC, and BPLRC algorithms, with a slight reference to ESRC and Module LRC.
Section 3 describes the decision principles and experimental results of the proposed method.
Section 4 discusses the contrast between BPLRC and other related algorithms in relation to the other performance metrics of the model.
Section 5 is the conclusion of this paper.
2. Materials and Methods
The LRC [
18] method can effectively identify face images with illumination and expression changes, but this method finds it challenging to identify occluded face images. According to the literature [
14,
17,
20,
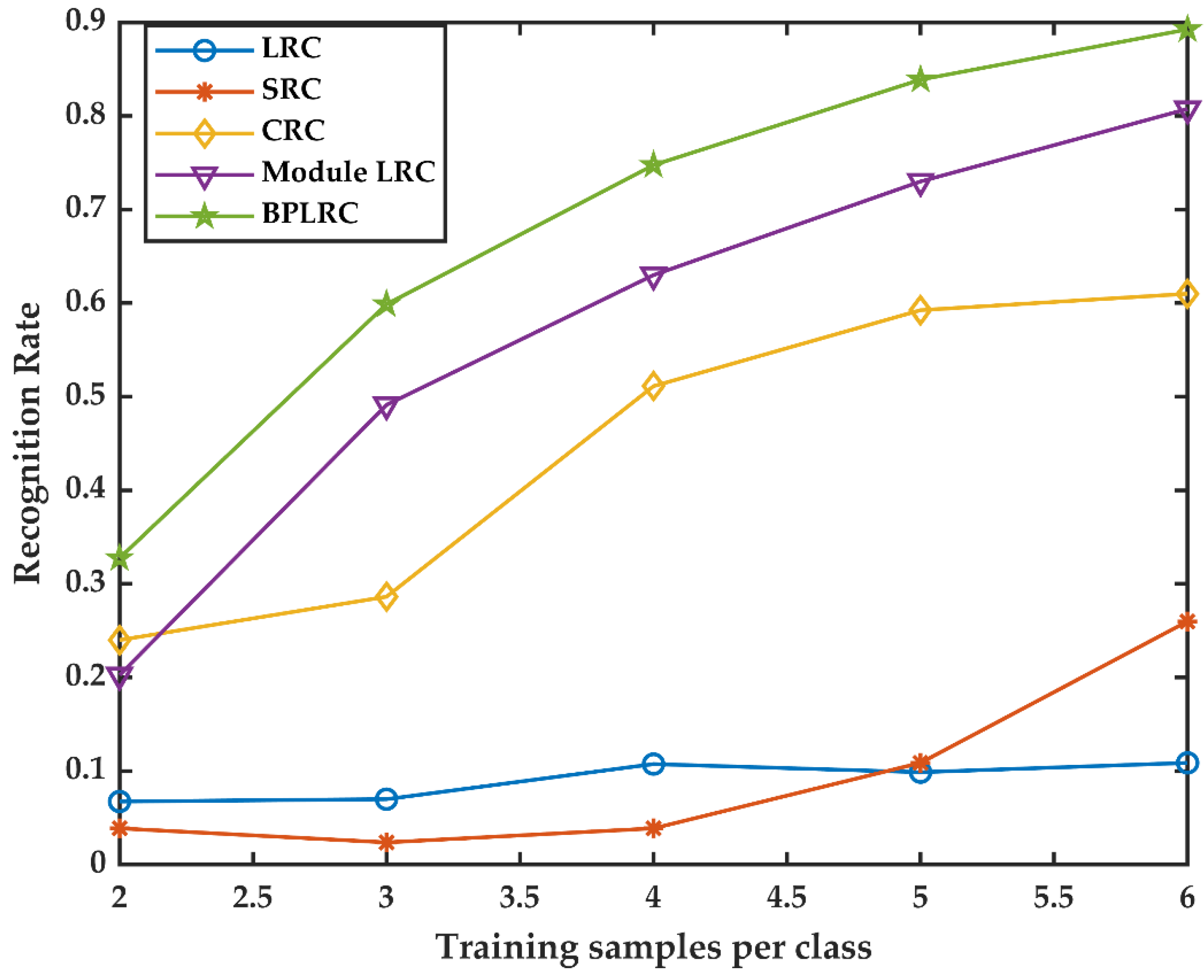
21], LRC finds it easier to identify face images with illumination and expression changes than SRC, CRC, and ESRC algorithms in both linear models. Nevertheless, its robustness is weaker than the SRC, CRC, and ESRC algorithms. The BPLRC algorithm proposed in this paper improves robustness based on the LRC algorithm to effectively identify face images with light changes, expression changes, and facial occlusion.
2.1. Related Works
Suppose that the training set samples are represented as , where n is the number of categories contained in the training set samples and d is the dimension of any sample. Suppose the training sample of the i-th subspace is , denoted as , with denoted as the j-th sample of the i-th class, denoted as the number of the i-th class of samples, and the test sample denoted as y.
The Linear Regression Classification algorithm is based on the assumption of subspace, and the data containing n categories are represented as n different subspace vectors, in which the samples belonging to the
i-th category are represented as
. The following is the specific principle of the LRC [
18] algorithm when classifying the test samples.
Assuming that the test sample y belongs to the
i-th class, it can be approximately represented as a linear combination of the training samples of the same category.
where
is the representation coefficient of the
i-th category of training samples.
Face recognition is expressed as a regression problem in the above formula, and the representation coefficient is obtained through the pseudo-inverse matrix.
where
is the test sample vector.
The projection and projection surface of the test sample y in each subspace can be expressed as:
where
is the predicted regression coefficient of the
i-th category training sample,
is the linear model reconstruction vector, and
P is the projection matrix.
The distance between the test sample vector and the projection of y on the
i-th subspace can be expressed as:
Selection of the category with the smallest Euclidean distance as the discrimination result obtains:
2.2. Other Related Algorithms
Sparse Representation-based Classification (SRC) is based on linear regression through the punishment of regression coefficients. The SRC [
10,
11] algorithm introduces the L1 norm to constrain the regression coefficients so that more zero values are included in the regression coefficient, equivalent to using the Lasso regression model. The SRC algorithm first encodes the test samples as a sparse linear combination of all the training samples. It then makes the final decision by comparing which category has the smallest error.
The sparse coefficient of the SRC model can be equivalent according to the Lasso regression model:
where
X is all the training samples,
y is the test sample,
is the regression coefficient of
X, and
is the L1 norm.
After determining the sparse coefficient of the SRC algorithm, the SRC algorithm is similar to the LRC algorithm, and the same equations as those of (3), (6), and (7) can use the Euclidean distance as a measure to determine the category of the test sample.
Since there is no analytical solution to the Lasso problem, its computational complexity is much greater than the classifier. Later, the L2 norm was introduced to restrict the regression coefficient, that is, the classification method (Collaborative Representation-based Classification, CRC).
The CRC [
14] problem is equivalent to the ridge regression problem. It is similar to the SRC algorithm in that it similarly encodes the test samples as a linear combination of all the training samples. The CRC algorithm performs the L2 norm constraint on the regression coefficient and its sparse coefficient:
where
X is all the training samples,
is the regression coefficient of
X,
is regularization coefficient, and
is the L2 norm.
The regression coefficients in Equation (9) have analytical solutions with the expression:
By combining Equations (3), (6), and (7), the residuals of the CRC algorithm and the predicted test sample category can be expressed as:
where
is the coefficient of the
i-th category of training samples.
The SRC and CRC algorithms improve the linear regression classifier by restricting the L1 and L2 norm on the regression coefficient, respectively, which can somewhat suppress the influence of noise on the linear model. Nevertheless, the CRC algorithm is more computational than the SRC algorithm.
The Euler Sparse Representation-based Classification (ESRC [
17]) algorithm is similar to the SRC algorithm, which takes Euler distance as a measure and expands intra-class and inter-class distance. The multiple of the inter-class distance will be greater than the multiple of the in-class distance in some data, thus improving the robustness of the SRC algorithm. The ESRC method involves an implementation process, and details of image mapping to the complex space process can found in [
17].
2.3. The Proposed Method
The workflow of the BPLRC method is shown in
Figure 1 under the assumption that the image is divided into 5 pieces. When the image only retains one block, the principle of the BPLRC algorithm is equivalent to Module LRC; when the image retains all blocks, the principle of the BPLRC algorithm is equivalent to LRC. The proposed method contains Module LRC that is reserved with a full block and blocks that only retain one block. Theoretically, its recognition effect will be better than LRC and Module LRC. BPLRC aims to find the best facial features for classification. The proposed method first divides all training images and a test image and divides the number of groups according to the number of reserved blocks. As shown in the figure, the number of arrangements from the first and fifth groups is 5, 10, 10, 5, and 1, respectively. The construction of a linear model according to each scheme then determines the scheme with the minimum residual and obtains the identification result of the scheme. Finally, samples can be continually drawn from the test concentration and the above work can be repeated.
Assuming that the training samples contain some noise when the test samples have the same noise, test samples can be linearly represented by the training samples. However, if the training samples contain no noise and the test samples contain a lot of noise, the linear model will be invalid. Therefore, selecting the sample variables and filtering out the variables with noise in the samples are necessary, which can then help train a more robust linear regression model. The proposed method divides the variables into blocks and performs permutation, combination, and reorganization. The best combination method is then judged by Euclidean distance (residual value) to achieve the purpose of removing continuous noise variables. BPLRC aims to find face characteristics that contain only a small amount of noise or no noise. The following is the basic process of the BPLRC method:
Suppose the training samples on the
i-th subspace are divided into
T blocks such that each sub-image can be represented as:
where
is the grayscale value on the
pixel of the
t-th block image from the
i-th class.
The number of groups of arrangement schemes is determined by the number of divided blocks, and the block arrangement and combination of the
i-th type of training samples in the first group can be expressed as:
where
is a zero matrix and
is the
-th block of class
i.
Different groups retain a certain number of sub-images. For example, the second group retains 2 sub-images, and the
T-th group retains
T sub-images. Therefore, the 2-
T groups
i-th training sample reorganization can be expressed as:
where
is the
-th arrangement and
is the number of arrangements.
Similar to Equations (14) and (15), the recombination test samples of different groups can be expressed as:
where
is the
-th arrangement and
is the number of arrangements. Equations (14)–(16) represent different segmentation arrangements in the image. In this article, which refers to the method of Module LRC, the residues of all solutions are compared and the minimum residual arrangement scheme is found to obtain the best face characteristics used in identification. BPLRC reduces the continuous occlusion characteristics of linear model learning and increases the learning of effective face characteristics, thereby building a strong, robust linear model.
The coefficient vector and prediction vector for each group were calculated in the same manner as the expressions in Equations (2) and (3):
where
is all the training samples of class
i in the
t-th group of scheme
.
In the same arrangement, the distance between the test vector and its projection on the
i-th subspace is:
where
is the test sample of the
arrangement scheme in
t-th group and
is the prediction vectors of class
i in the
t-th group of scheme
.
Selection of the distance to the nearest subspace of the test vector in the same arrangement:
where
is the distance between the test sample vector and the
i-th subspace in the
t-th group of scheme
.
Comparison of the size of the nearest subspace distance between different arrangements in the same group and selection of the arrangement with the smallest distance as the optimal arrangement in the group is expressed as:
where
is the distance (residual) of the
-th arrangement in
t-th group.
Under the optimal scheme, the subspace closest to the recombination test sample is selected as the prediction result:
where
is the distance between the reorganization test sample vector and the
i-th subspace under the optimal scheme in the
t-th group.
Assuming that the number of test samples is S, the true label is
and the predicted label is
, the model’s recognition accuracy can be expressed as:
where
is the indicator function.
According to Equation (23), the recognition accuracy of each group was obtained, and the final result was obtained by comparison:
where
is the accuracy of the identification of all test samples in the
t-th group.
In addition to recognition accuracy, precision and recall can be partially evaluated to evaluate the model. Precision and recall can be expressed as:
where
is actually a positive sample prediction as a positive sample,
is actually negative sample prediction as a positive sample, and
is actually positive sample prediction as a negative sample.
F1-Score can represent the harmonic average of accuracy and recall rate:
4. Discussion
As has been reported in the literature [
10,
11,
14,
18], LRC, SRC, and CRC use the residues between the Euclidean distance measurement model and the test image. There are advantages and disadvantages to each. From the above experimental results, ESRC identification is, in many cases, inferior to the SRC method. The proposed BPLRC algorithm aims to determine the characteristics of the best face recognition and then use the LRC method to classify them. Therefore, the measurement method of the BPLRC algorithm is Euclidean distance.
To fully verify that the BPLRC method’s recognition performance is better than other methods, in addition to identifying accuracy indicators this chapter introduces precision, recall, and F1score indicators to evaluate the model. Because AR, Extended Yale B, and ORL datasets include many categories, each category cannot be evaluated locally. All the methods involved in this paper were evaluated globally by calculating precision, recall, and F1score, which were >0.7 in all categories. When precision, recall, and F1score are equal to 0, the samples representing a certain category are incorrectly identified. The more of such categories there are, the worse the model’s performance.
4.1. Continuous Occlusion Analysis of the AR Database
The AR dataset contains 100 classes of target faces. Discussing the assessment metrics for all categories takes time and effort. We set the threshold for precision, recall, and F1score to 0.7 and then analyzed the number of categories that were greater than 0.7. If the threshold was too large or too small, the value was close and it was not easy to compare the performance of the following methods.
As shown in
Table 10, BPLRC identifies face images containing only scarf occlusion, sunglasses occlusion, or mixed occlusion whose number of precision, recall, and F1score > 0.7 categories is more than or equal to other methods. Precision, recall, and F1score equal to 0 was present in less categories than other methods. The model evaluation indicators involved in the table, combined with the identification accuracy of the experimental part, show that the proposed method can effectively solve the face occlusion problem in the AR face dataset. However, other relevant algorithms, such as the LRC, SRC, CRC, and ESRC methods, have poor identification performance, partly because they belong to linear models and are, in turn, susceptible to anomalous variables or abnormal points. The key to the SRC, CRC, and ESRC methods, compared to the LRC method, is that they regularize the model coefficient, which improves the robustness of the linear model to some extent. From the results relating to identification of scarf occlusion, the SRC, CRC, and ESRC methods are much better than the LRC method. The results relating to identification of sunglasses occlusion show that the LRC method is superior to the SRC, CRC, and ESRC methods. This indicates the effect of a face image linearly represented by the same category of face image, which is generally better than a face image linearly represented by all categories of face images. To circumvent this drawback, that LRC is extremely poor in robustness, block arrangement is combined with the LRC method. Block arrangement achieves excellent recognition performance in LRC and ensures that more useful face information is extracted. Module LRC only retains the most useful block, thus keeping too little effective information which further leads to its inferior recognition performance compared to BPLRC.
4.2. Extended Yale B Database Analysis and Discussion
Extended Yale B datasets include 38 target faces. As shown in
Table 11, when BPLRC recognizes 10%, 20%, and 30% of face images, its number of categories where precision, recall, and F1score are >0.7 is more than other methods. When BPLRC identifies 40% of the face image, its number of precision categories >0.7 is more than other methods, but the number of recall and F1score categories > 0.7 is less than the Module LRC method. In fact, in face recognition, precision indicators are more important than recall and F1Score. For example, when the precision value is too low in the family access control system, it is possible to identify strangers as family members. When the recall value is too low, even family members cannot be identified (though you can enter the house by inputting a password), and there will be no severe theft incidents. F1score is the harmonic mean of two metrics, and simply provides a summary evaluation of model performance. According to the results in
Table 11, the number of precision, recall, and F1score categories equal to 0 is only 1 or 0; thus, the model’s identification performance cannot be evaluated from the number of precision, recall, or F1Score categories equal to 0.
In summary, from the number of categories for each method with precision >0.7, the proposed method identifies 10%, 20%, 30%, and 40% of faces, vertical occlusion of 10% of faces, and diagonal occlusion of 20% of face images better than other related algorithms.
4.3. ORL Database Analysis and Discussion
The ORL dataset contains 40 classes of target faces. As shown in
Table 12, when BPLRC identifies random occlusion of 10%, 20%, and 30% of faces, 10% vertical occlusion of faces, and 20% diagonal occlusion of faces, its number of precision, recall, and F1score categories greater than 0.7 is greater than other related methods. The number of precision, recall, and F1score categories equal to 0 is less than or equal to different related algorithms. Therefore, the BPLRC method solves the face occlusion problem more effectively in the ORL datasets than the other related algorithms, showing stronger robustness than LRC, SRC, CRC, ESRC, and Module LRC. Combined with the identification accuracy obtained from the previous experiments, we fully confirm that BPLRC improves upon both LRC and Module LRC.
4.4. Comparison of Differences in Algorithms
The LRC method uses individual categories of training samples to represent the test samples linearly. In contrast, the SRC, CRC, and ESRC methods use all categories of training samples to represent the test samples linearly. Other differences are shown in
Table 13, with SRC being equivalent to the Lasso regression model and constraining the regression coefficients using the L1 norm. CRC is equivalent to the ridge regression model, and the regression coefficient is constrained using the L2 norm. At the same time, ESRC replaces the metric of the SRC method with the Euler distance. The Module LRC and BPLRC methods both determine the face features conducive to the LRC method and further determine the category to which the image belongs. The BPLRC approach is similar to Module LRC in that it considers the case of block combinations.
Table 13 shows the differences in the LRC, SRC, CRC, ESRC, Module LRC, and BPLRC methods. The linear model is susceptible to contaminated data [
26] and LRC is directly affected by contaminated data, while other RBCM algorithms are more robust than LRC algorithms. Notably, Module LRC and BPLRC can identify the target images by effectively using face features. If a small number of non-face images exist in the test sample, the influence function in the literature [
27] is used to obtain a clean sample set. From the recognition results of the three face datasets, Module LRC and BPLRC are more suitable for recognizing facial occlusion images and have strong robustness. The three datasets contain various face images with light changes and expression changes. Therefore, all RBCM methods (including LRC, SRC, CRC, ESRC, Module LRC, and BPLRC) can achieve better results when setting a low occlusion ratio. At the same time, it shows that RBCM methods can effectively solve the problem of illumination and facial expression changes.
5. Conclusions
The method proposed in this paper combines local image information into a whole, reflecting both the local information and the overall information of the image. In the AR datasets, face images with scarves were downsampled to 25 × 20 pixels as an example, and the recognition accuracy of the BPLRC algorithm in identifying the face images with scarf occlusion was 93.67%. The number of categories with precision, recall, and F1score greater than 0.7 was 86, 94, and 93, respectively, and the number of categories with precision, recall, and F1score equal to 0 was 1. These indicators can indicate the degree of excellence various algorithms have in identification. Furthermore, experiments on the Extended Yale B, ORL, and AR datasets showed that the BPLRC algorithm was significantly better than other related classification methods in identifying images with continuous occlusion. The LRC, SRC, ESRC, and CRC algorithms did not remove occlusions, which caused them to learn a lot of noise. As a result, model performance was worse than the Module LRC and BPLRC models. Although Module LRC removes the continuous occlusion part, it only considers retaining one block, and there may be less reserved effective face information than the BPLRC method. Therefore, the BPLRC algorithm’s ability to identify face images is better than other related algorithms.
BPLRC reorganizes different training samples and test samples through block arrangement and combination, but the number of combinations increases exponentially with the number of blocks. Compared to the LRC algorithm, the method proposed optimizes face characteristics in the image while at the same time reducing the negative impact of occlusion on the model. For example, the LRC method easily attributes face images with scarf occlusion to a large number of beards, or other categories that have characteristics similar to scarves. Compared to the Module LRC algorithm, this algorithm’s novelty lies in retaining as many image block schemes as possible in order to retain useful face characteristics. Additionally, the block arrangement can be combined with other algorithms that are less robust. For example, when the number of blocks is five, the average time taken with BPLRC in AR datasets for setting an image with a size of 25 × 20 pixels is 0.094 s, and the calculation amount is relatively small. However, when the number of image divisions is too large, many arrangement schemes will greatly reduce the recognition speed of the BPLRC algorithm. In response to the defects of the BPLRC algorithm, in the future, the rapid iteration method will be studied and the optimal or subsequent arrangement will be found in many solutions to reduce the calculation amount, which should provide the possibility of dividing more blocks.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}