1. Introduction
With the exploding magnitude of kernel code and the advent of the multi-core era, the operating systems we now use are full of invisible threads. In this way, it is inevitable that multiple threads access the same shared code, variables, and files concurrently or out of order. Due to the infinite threads and limited resources, some resources cannot be accessed at the same time. Multiple threads can cause race vulnerabilities due to chaotic access order. According to the Common Vulnerabilities and Exposures database [
1], Linux kernel race vulnerabilities discovered in 2017 nearly doubled from those discovered in 2016, and since then, nearly 100 system race vulnerabilities have been discovered every year. There are still many race vulnerabilities that are fixed without being assigned a CVE number or not fixed with a PoC available to the public [
2].
A race vulnerability is very harmful. Some race conditions can lead to deadlocks and breakdowns, which can be used to perform denial-of-service attacks. Severe race conditions can trigger different types of program errors or warnings from the sanitizer, and we call them triggering types, such as out-of-bounds write (
OOB) [
3], use-after-free (
UAF) [
4], double-free [
5], and direct control-flow hijacking (
CFH) errors. After investigating CVE over the past 20 years, we found that these four triggering types accounted for 85 percent of all race vulnerabilities. Some vulnerabilities can be used by attackers to escalate privileges, such as
CVE-2016-8655 [
6] and
CVE-2019-11815 [
7]. Due to the large number of vulnerabilities being discovered every year, it is difficult to fix all vulnerabilities in time. Large software vendors such as Microsoft [
8] and Ubuntu [
9] adopt certain strategies to prioritize the patching of security bugs. The most common strategy used to determine priority is based on the exploitability of the vulnerability.
It is more challenging to manually analyze the exploitability and generate exploits for race vulnerabilities than for other kinds of vulnerabilities. The first problem is related to debugging. We should care not only about the control flow and data flow within the thread but also about the concurrent execution between multiple threads. Due to the complex scheduling mechanism of the kernel and race conditions of a vulnerability, it is difficult for us to deterministically trigger race vulnerabilities, which makes debugging time-consuming. The second problem is related to exploitation. Race vulnerabilities have different kinds of triggering results. To determine the triggering type and choose the appropriate exploitation method, researchers have to thoroughly study the logic of the entire vulnerable code and the vulnerability context. This analysis process requires a high level of human security knowledge and experience. The third problem is related to how to detect whether a race condition is satisfied. Kernel race vulnerabilities are caused by competition between kernel threads or between kernel threads and user threads. Once the competition starts, it is difficult to perceive the execution states of the kernel space code from the user space. Due to the complexity of race vulnerability exploitations, no research has systematically analyzed the process of exploiting race vulnerabilities. Thus, race exploitation is still perplexing to the public.
In this paper, we propose an exploitation framework named
ERACE to evaluate the exploitability of kernel race vulnerabilities.
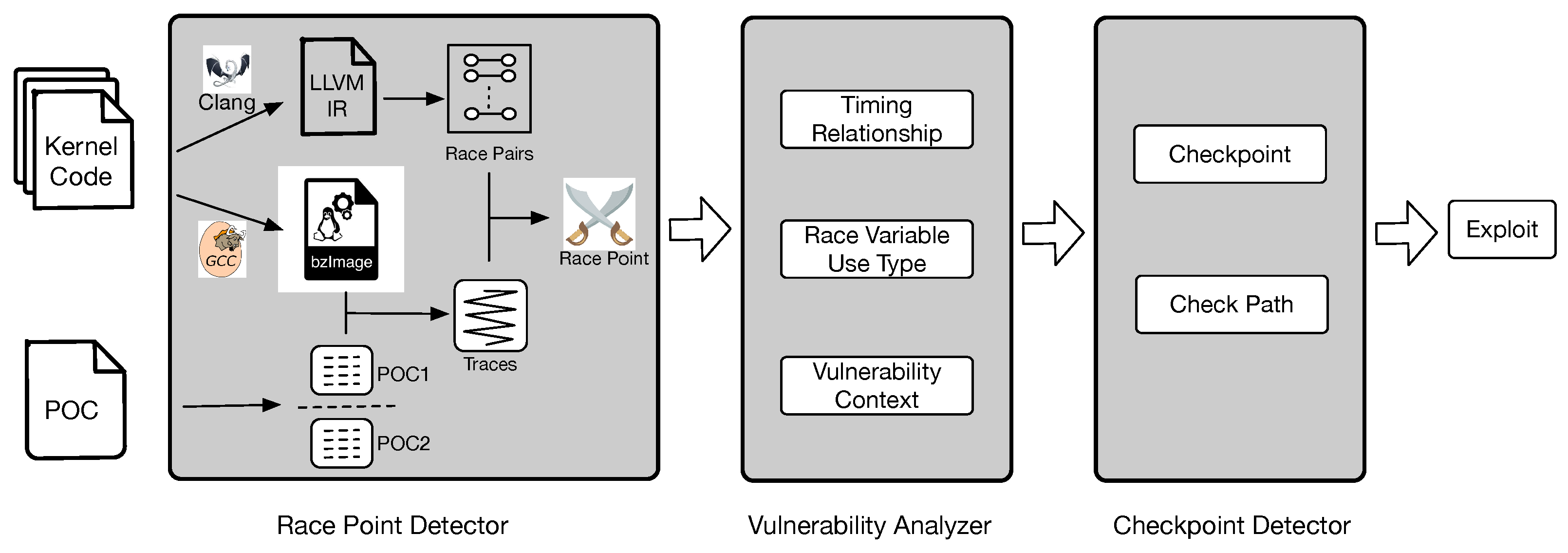
ERACE can simplify the process of exploiting race vulnerabilities in three aspects. First, the race point detector helps researchers automatically locate the position of race instructions triggered by a PoC. Second, the vulnerability analyzer determines the execution order of the race instructions that cause the vulnerability and analyzes the triggering type of the race vulnerability. Therefore, researchers can choose an appropriate exploitation method more quickly. Third, the checkpoint detector identifies the checkpoint near the race instruction, that is, the instruction that can reflect whether the race condition and heap spraying are satisfied, and records the system call to which the checkpoint belongs. Finally, we construct an exploit based on the information obtained above.
ERACE greatly standardizes and simplifies the process of exploiting race vulnerabilities. We introduce the detailed workflow of
ERACE in
Section 4.
To evaluate the accuracy and effectiveness of ERACE, we tested 23 real-world vulnerabilities. As a result, we successfully detected the race points of 19 vulnerabilities, the timing relationships among the race instructions, and the triggering types of 17 vulnerabilities, and assisted in generating exploits for 13 vulnerabilities.
In general, this paper makes the following contributions.
We design and implement ERACE, a new framework to facilitate the process of exploiting kernel race vulnerabilities, which applies a combination of dynamic and static analysis techniques. ERACE can effectively help security researchers simplify the analysis of kernel race vulnerabilities, select appropriate exploitation methods, and use checkpoints to increase the success rate of privilege escalation.
We analyze the kernel race vulnerabilities in depth and modeled their exploitation process. The main process includes locating the race point, identifying the triggering type of the vulnerability, and identifying the checkpoint of the race.
We demonstrate the utility of ERACE. By testing 23 real-world race vulnerabilities in the Linux kernel, ERACE facilitates the exploit generation for 13 race vulnerabilities.
The organizational structure of this article is as follows.
Section 2 describes the background and challenges of our research.
Section 3 provides an example to show the process of exploiting race vulnerabilities and presents an overview of
ERACE.
Section 4 describes the design details of
ERACE.
Section 5 describes the implementation of
ERACE.
Section 6 demonstrates the utility evaluation of
ERACE.
Section 7 summarizes the work related to this research. Finally, we conclude this work in
Section 8.
2. Background and Challenges
It is challenging to exploit kernel race vulnerabilities. First, it requires researchers to be equipped with comprehensive security knowledge and experience such as knowledge of the underlying operating system, binary reverse engineering, heap, stack, etc. Second, the indeterminacy of a race vulnerability decreases our analysis efficiency. For common vulnerabilities such as stack overflows, we can set accurate breakpoints to figure out whether the vulnerability has been triggered. However, for race vulnerabilities, it is unknown whether every execution can satisfy the race condition, further increasing the difficulty of debugging and analysis. Moreover, even senior security researchers have to spend a lot of time on reverse analysis to find useful exploit primitives or heap-spraying structures. This process is quite complicated and boring.
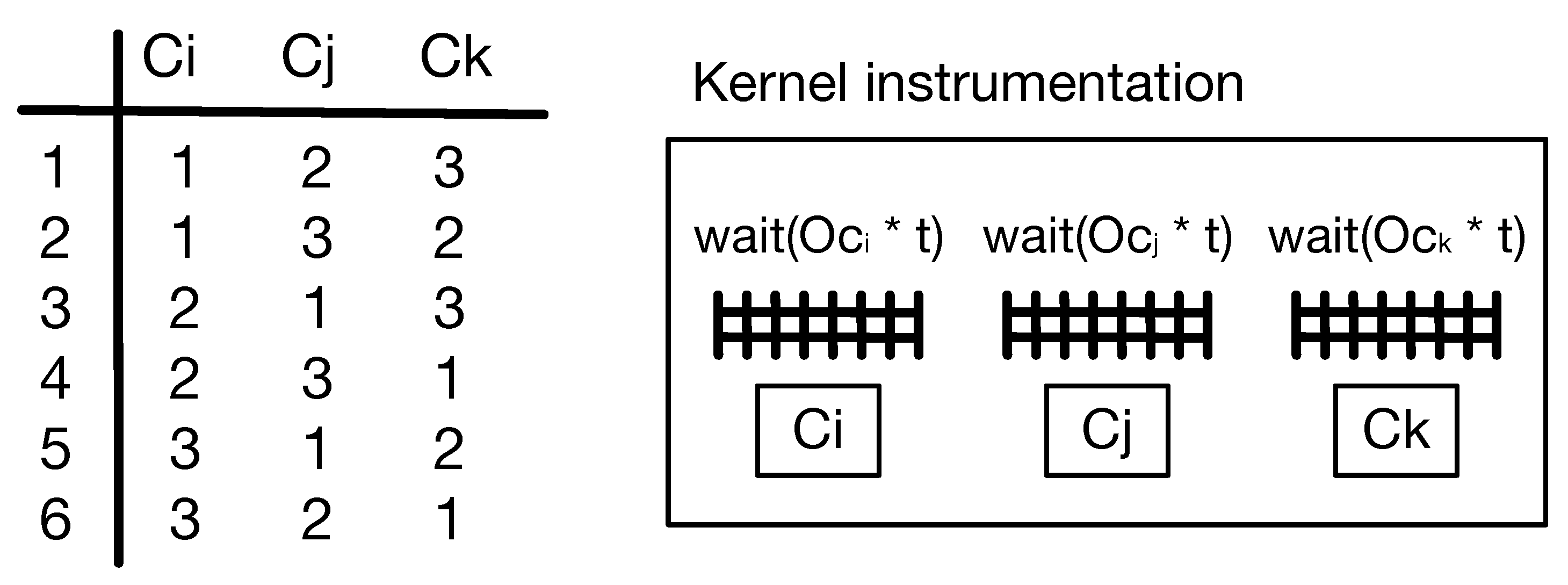
Many researchers have defined race vulnerabilities. Jeong D.R. et al. [
10] defined a data race, which is a behavior in which the output is dependent on the sequence or the timing of other non-deterministic events. If two memory-access instructions meet the following three conditions, a data race may occur: (i) they access the same memory location; (ii) at least one instruction is a write instruction; and (iii) they can be executed concurrently. A data race is one type of concurrent vulnerability. The concept of concurrency vulnerabilities is broader. However, most of the exploitable and user-controllable vulnerabilities belong to the data race type. Therefore, the definition of a data race by Jeong D.R. is more relevant to our research. As shown in
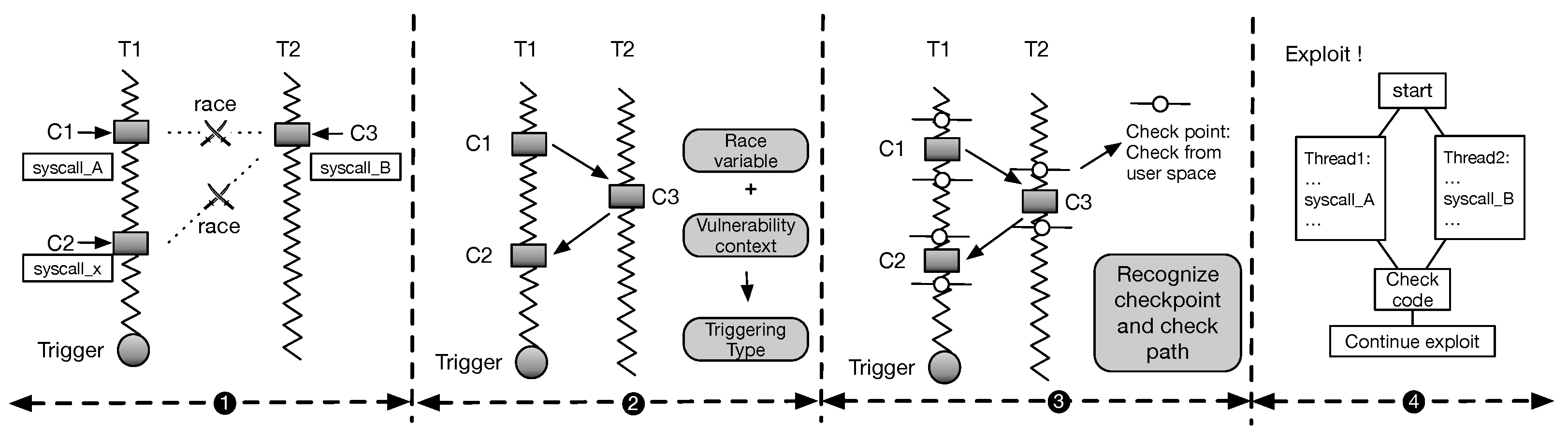
Figure 1, when a race occurs, C1, C2, and C3 are the instructions that access the same memory location. C3 is a write instruction. C1 and C3, and C2 and C3 can be executed concurrently and satisfy all three conditions.
2.1. The Process of Exploiting Race Vulnerability
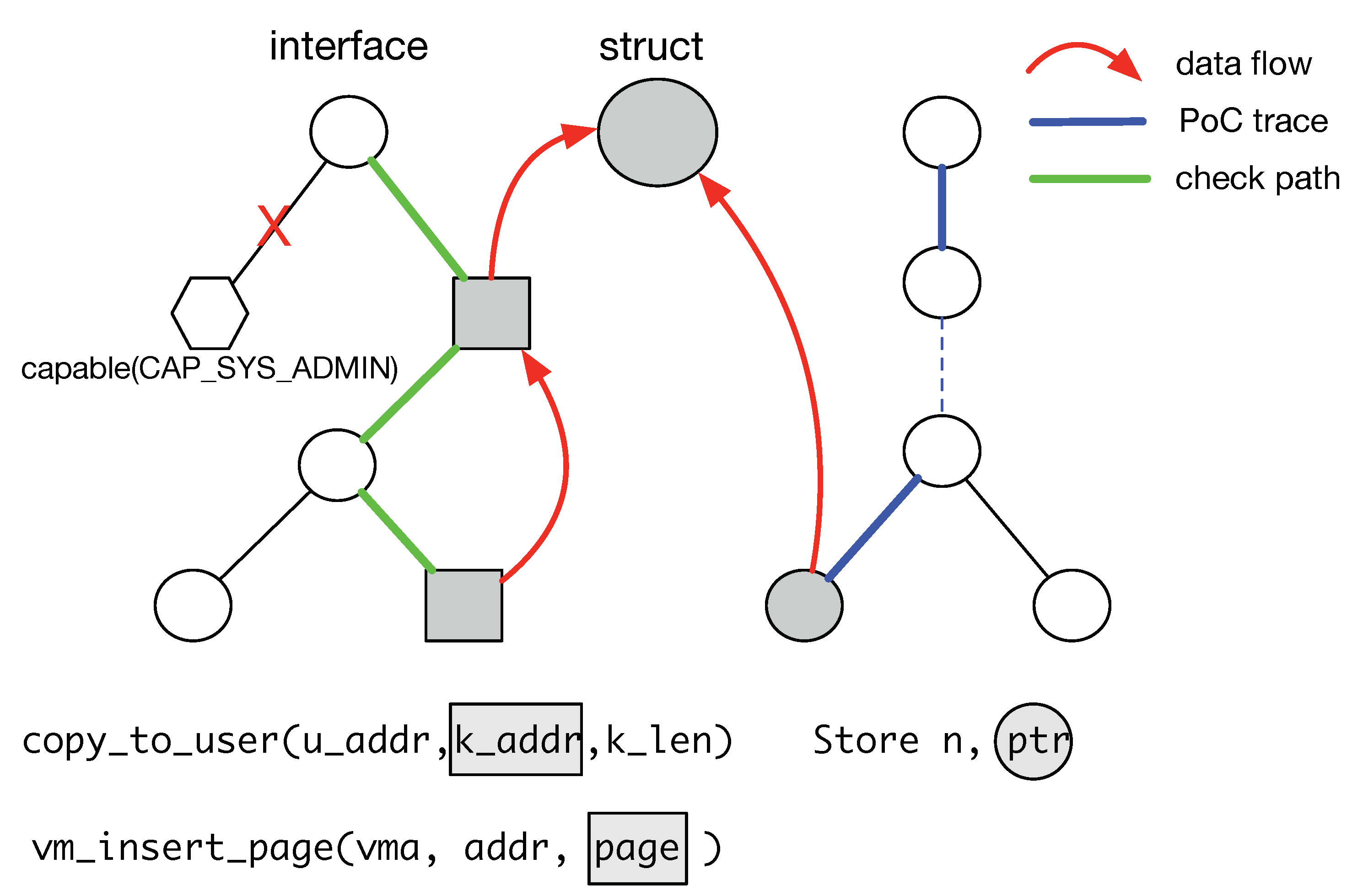
The process of exploiting a data race is shown in
Figure 1. Suppose that a researcher obtains a PoC that can trigger a data race but cannot successfully exploit the vulnerability yet. A successful exploitation means that we can escalate privileges from ordinary users to superusers. For a vulnerability caused by a data race, the race point is equal to the vulnerability point, whereas the vulnerability triggering point is equal to the crash point. The vulnerability point is different from the crash point for most data races. However, for most common kernel vulnerabilities, such as an
OOB write and
UAF not caused by data races, the vulnerability point is no different from the triggering point and the vulnerability point. Researchers need to perform the following steps to successfully escalate a privilege.
First, the researcher should find the root cause of a race vulnerability based on the PoC, that is, the race instructions that accessed the same variable or memory, and determine the system call to which the race instruction belongs (see ➊ in
Figure 1). This is conducive to the subsequent analysis and the construction of competing threads. Determining the root cause of the vulnerability requires analyzing the source code, understanding the logic of the source code, or completing a reverse analysis based on the output of the stack traceback information by the kernel address sanitizer (KASAN) [
11] at the crash point. For most data races, crash points are different from race points and they may even be far away from each other. Hence, it is not easy to locate race instructions.
Second, the timing relationship of race instructions and the triggering type of the vulnerability need to be determined (see ➋ in
Figure 1). Competition is the cause, whereas triggering is the result. A pure race is not necessarily exploitable. However, if a race can lead to
UAF or
OOB write vulnerabilities, then the race may be exploitable. Its exploitability also depends on the specific vulnerability context.
Third, the method of checking whether the race and heap spraying were successful needs to be determined (see ➌ in
Figure 1). Assuming that the race triggers a
UAF issue and only after the race succeeds, heap spraying can be used to complete control-flow hijacking and privilege escalation. We can directly perform heap spraying without confirming whether the race succeeded or not and just confirm whether the privilege was escalated at the end of the exploit. However, what happens when the race fails? We have to restore the heap-space layout and perform competing and heap spraying again, which are both time-consuming and greatly prolong the entire exploitation process. What is worse is that the heap-space layout might have been destroyed once the heap spraying occurred, making it difficult to recover the heap-space layout. Sometimes the system may directly crash and the exploitation cannot continue. Similarly, proceeding to the next exploitation stage without checking whether the heap spraying was successful may also reduce the success rate of the exploitation.
Fourth, the exploitation strategy is determined and the final exploitation is finished (see ➍ in
Figure 1). According to the recognized race instruction and the relative system call, we can construct competing threads. We can craft race and spraying checking codes with the check path identified and choose an appropriate exploitation method based on the triggering type.
2.2. Challenge of Crafting Working Exploits
In step ➊, it is hard to locate the race instructions. First, there is no existing tool that can directly locate the race points. The only tool that can be used is the KASAN [
11] instrumentation mechanism. The latest instrumentation tool called TCSAN [
12] can only be used in kernel 5.8 and above so it cannot cover all kernel versions. Generally, if we compile the kernel with the KASAN option set, the kernel will output warning information when the vulnerability is triggered. For most common types of kernel vulnerabilities, such as an
OOB write or
UAF not caused by data races, the triggering point is equal to the vulnerability point and it is more convenient to locate the vulnerability point by gathering useful information from the KASAN report. However, for a data race, the triggering point is not the vulnerability point. The triggering point usually occurs later than the race point in the instruction execution sequence. Second, the magnitude of kernel source code is too big and it is difficult to perform manual code auditing. Therefore, a more effective method should be adopted to locate race points.
In step ➋, there is no existing tool to determine the execution order of race instructions when a vulnerability is triggered and it is difficult to accurately identify the triggering type. KASAN’s warning information alone is not enough to determine the triggering type of the vulnerability. For example, KASAN often reports null-dereference warnings for race vulnerabilities, which is of little help to the exploitation because in the current system with the general configuration, a null dereference cannot be used to escalate a privilege. In fact, the triggering type of the race vulnerability may be an OOB write or another type.
In step ➌, our exploit runs in the user space. With limited privilege, how can we confirm whether competing and heap spraying succeeded? For vulnerabilities that can trigger direct CFH, we can judge whether the race condition was satisfied by checking whether the malicious code was executed successfully. However, it is hard to check the race status for vulnerabilities that can trigger a UAF, double-free, or heap OOB write. We can only check whether the malicious code was executed successfully after heap spraying succeeded, which costs too much time and may lead to exploitation failure. If we can check it before heap spraying, we can greatly reduce the running time of the exploit and increase the success rate of the exploitation. Similarly, it can also improve the success rate of the exploitation by checking whether the heap spraying succeeded.
To solve the problems mentioned above, we need to adopt automatic program analyzing techniques to avoid complicated and repetitive manual analysis, which may produce some omissions. The original objective of ERACE is to assist in the exploitation of race vulnerabilities to quickly evaluate its risk rating. Therefore, ERACE does not fully automate exploit generation but facilitates the process of exploitation.
To solve the problems mentioned above, we need to adopt automatic program analyzing techniques to avoid complicating and repetitive manual analysis, which may produce some omissions. The original objective of ERACE is to assist in the exploitation of race vulnerabilities to quickly evaluate its risk rating. Therefore, ERACE does not fully automate exploit generation but facilitates the process of exploitation. ERACE should meet the following three design requirements.
First,
ERACE should help researchers locate race instructions and relative system calls, which corresponds to step ➊ in
Figure 1. The race point is equal to the vulnerability point, from which researchers can quickly determine the root cause of the vulnerability. Second,
ERACE should help researchers determine the execution order of the race instructions and the triggering type and extract the vulnerability context, which corresponds to step ➋ in
Figure 1. In this way, a researcher can select a suitable exploitation method according to the triggering type and the vulnerability context. Determining the execution order of race instruction makes it easier to debug the vulnerabilities without wasting time waiting for the success of the race. Third,
ERACE should help researchers locate checkpoints to check whether the race condition and heap spraying are satisfied, which corresponds to step ➌ in
Figure 1. Some code in the kernel can modify variables or data structures. The user layer can indirectly determine where the kernel code is executed or whether kernel memory is sprayed with user-forged data by detecting changes in these variables or data structures. Checkpoints are instructions that modify variables or kernel data structures.
ERACE should also find the program path for the user layer to access these variables or data structures.
5. Implementation
We implemented a prototype of
ERACE, which contains three main components: the race-point detector, vulnerability analyzer, and checkpoint detector. The static analysis part of the race-point detector is based on SVF [
20] and the dynamic path collection is based on kcov [
17]. The race-point detector contains 2500 lines of
C code and is mainly responsible for identifying the race points. The static analysis and instrumentation of the vulnerability analyzer contain 1500 lines of
C code and are mainly responsible for identifying the timing relationships and triggering types. The static analysis of the checkpoint detector contains 2000 lines of
C code and is mainly responsible for identifying the checkpoints. The following paragraphs contain some implementation details about the above design.
Kernel division. During static analysis, the kernel is divided and the correlative modules are merged. As the Linux kernel source code is too large, i.e., reaching millions in magnitude, the lines of the compiled LLVM intermediate representation with symbolic information are three to four times those of the source code, which severely reduces the speed of static analysis and increases memory overhead. To solve this problem, Razzer [
10] and CRIX [
21] divided the different modules according to the directory structures, and k-miner [
22] analyzed them from different system calls. Although this effectively improved the speed of static analysis, some vulnerabilities were related to several modules. For example, the traces of the PoC we collected span multiple modules. If the kernel is divided into modules, it leads to false negatives. Therefore, when dividing the kernel, we integrate the modules involved in the PoC trace.
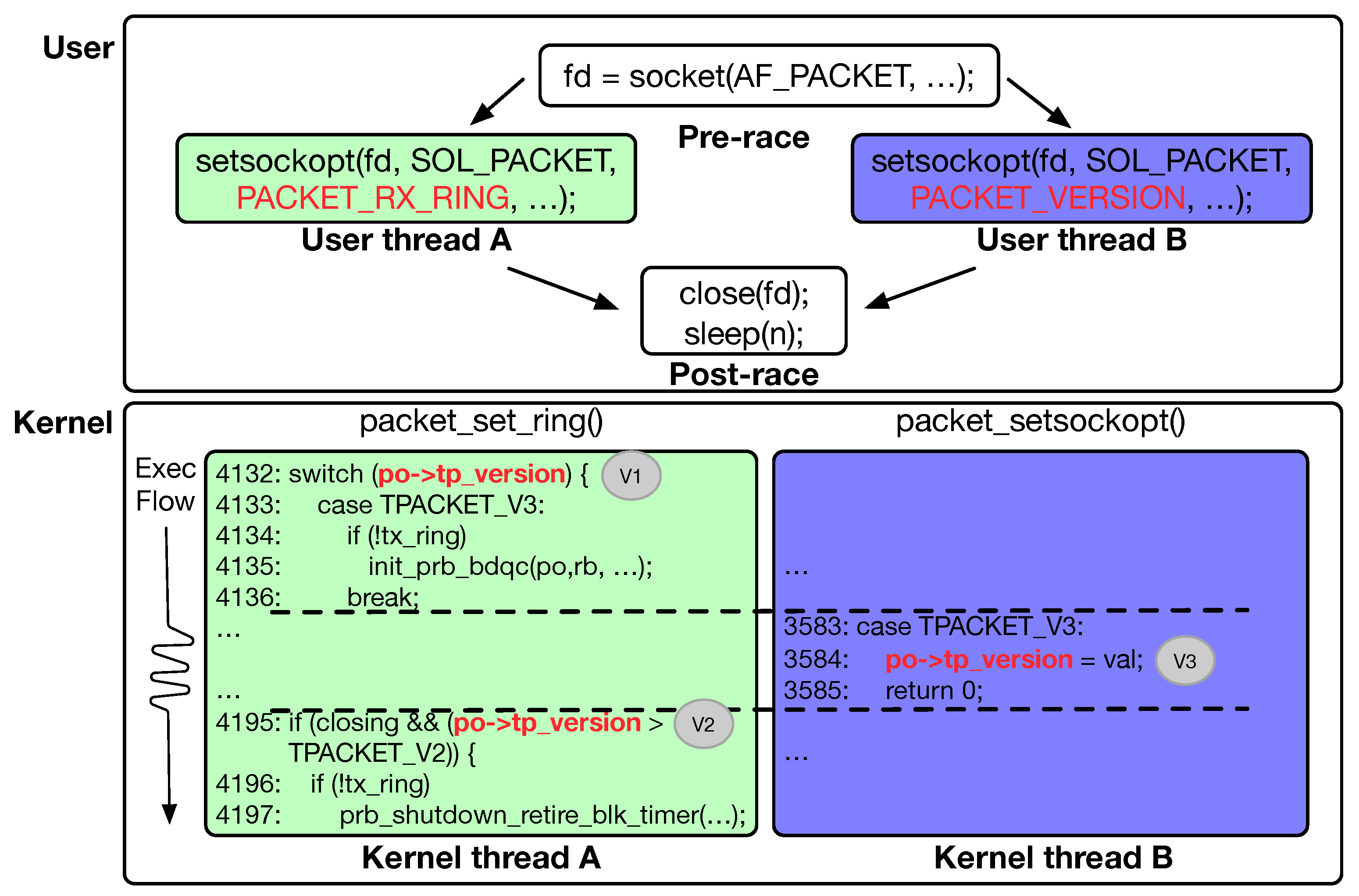
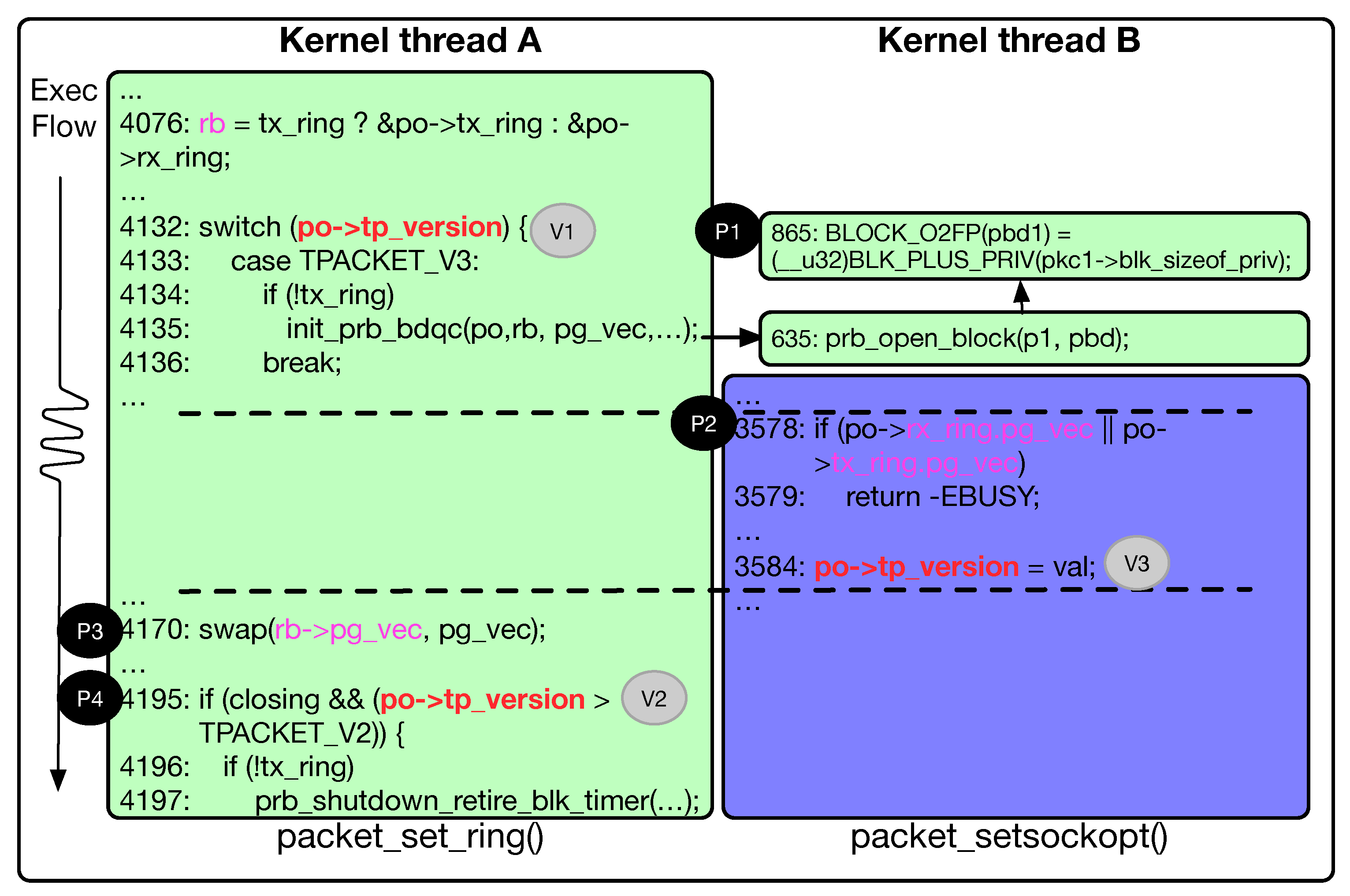
Relaxed alias analysis. When the race-point detector identifies suspicious race instruction pairs, it should first perform alias analysis on the variables and structure pointers. There is a characteristic in the Linux kernel. Two unrelated functions may reference the same structure member. Unrelated means that there is no direct or indirect calling relationship. For example, in
Figure 3, the
packet_set_ring() and
packet_setsockopt() functions can be called through different user call interfaces. However, as long as the same socket handle parameter is passed in, the same structure member
po->tp_version will be referenced. When using the existing
SVF tool [
20] or the
AliasAnalysis pass in LLVM itself to perform alias analysis, it is found that this situation will be under-reported. This is because traditional alias analysis can only identify alias relationships in the same function or the same path. Therefore, we improved the alias analysis method of the
SVF and adopted relaxed alias analysis. As long as the structure type pointed to by two pointers is the same, we treat the two pointers as aliases. The relaxed alias analysis has the problem of false positives, but our goal is to locate more race-point candidates, avoiding omissions. In our research, the problem of false negatives is more serious than that of false positives, and even if there are false positives, we can filter them based on the PoC traces.
Single-thread generator algorithm. As mentioned above, the indeterminacy of the data race makes it hard to trigger the vulnerability. However, even if the multi-thread PoC does not trigger the race condition, it may have passed the race point. To gather the execution traces of two threads, we have to transform the multi-thread PoC into two single-thread programs. We designed a single-thread algorithm to finish the task. As we know, Linux uses two functions, pthread_create() and fork(), to make programs run concurrently. First, we have to recognize these two functions. For the pthread_create() function, we find the two subfunctions on behalf of two threads. The third parameter of pthread_create() reveals the subfunctions. For the fork() function, we find the two branches on behalf of two processes, which we call two threads for convenience. Then, we delete pthread_create() or fork() and execute kcov-control statements before and after the two threads. Finally, we delete the other thread to obtain PoC1 and PoC2, respectively. We can collect execution traces in a real environment and compare them with suspicious race instruction pairs from the alias analysis to locate the final race points.
6. Evaluation
In this section, we use real-world kernel race vulnerabilities to demonstrate the utility of ERACE. Specifically, we demonstrate the accuracy of ERACE’s identification of race points, triggering types, and timing relationships of race instructions, and its effectiveness in facilitating the exploitation. In addition, we also discuss some kernel race vulnerabilities that ERACE failed to facilitate.
6.1. Setup
To demonstrate the utility of
ERACE, we conducted an investigation into Linux kernel race vulnerabilities in the past seven years from the Common Vulnerabilities and Exposures [
1] database and syzbot [
2]. Google’s syzbot [
2] platform has published many PoCs for Linux kernel vulnerabilities including a lot of race vulnerabilities that have not been confirmed. As discovered in our investigation of these two platforms, nearly 62 percent of race vulnerabilities had available PoCs, which can satisfy the input requirement of
ERACE. Then, we excluded the race vulnerabilities that were not related to data races or that involved specific hardware devices. Finally, we selected 17 CVE that had rich public vulnerability information to evaluate our results. In addition, we randomly chose six race vulnerabilities that had available PoCs from syzbot [
2]. We show these 23 vulnerabilities in
Table 1.
Since the race vulnerabilities selected involved different kernel versions, in order to better evaluate the utility of ERACE we transplanted all the vulnerabilities to the 4.12.1 version of the Linux kernel. Some vulnerabilities were located in the older version of the kernel, which does not support kcov or KASAN instrumentation. The research in this paper did not involve bypassing the mitigation mechanisms so we turned off the default protection mechanisms of the system such as the kernel address space layout randomization SMEP and SMAP mitigation mechanisms. Since ERACE needs to perform a static analysis of the Linux kernel to compare the warning information of KASAN and collect the dynamic execution path and instruction timing relationship, it was necessary to compile three versions of the kernel. One version used Clang to compile the kernel source code into the LLVM intermediate representation. The second used gcc to compile the kernel, with KASAN and kcov configured. The third performed delay instrumentation for the race points to recognize their timing relationship. The system selected for the experiments was an Ubuntu 18.04 system, running on a desktop with 128 G RAM and an Intel(R) Core(TM) i9-10900KF CPU @3.70 GHz.
To evaluate the accuracy in identifying the race points, timing relationships of the race instructions, and triggering types, we compared the output results of
ERACE with the publicly available vulnerability information. For vulnerabilities with less publicly available information, we manually analyzed the patch information and the related vulnerable code to confirm the validity. To show the effectiveness of
ERACE in facilitating the exploitation of race vulnerabilities, we chose a corresponding exploitation method according to the triggering type and vulnerability context recorded by
ERACE. The subsequent exploitation process mainly refers to the method introduced in previous articles [
13,
14,
15,
16]. There are two main methods for the final privilege escalation. One uses an ROP chain [
29] to call
commit_creds(prepare_kernel_cred(0)) and the other uses arbitrary write operations to modify the credential structure of the process. If
ERACE identifies the available checkpoints for the vulnerability, we can compare the impact of using checkpoints and not using checkpoints on the success rate of the vulnerability exploitation.
6.2. Accuracy
In this section, we evaluate the accuracy in identifying the race points, the timing relationships among the race instructions, and the triggering types (see
Table 1 for the experimental results). In general,
ERACE can effectively identify most race points, the timing relationships among the race instructions, and the triggering types.
ERACE identified a total of 19 vulnerabilities’ race points. The experiments show that ERACE can effectively help researchers locate vulnerable points, that is, race points. Moreover, to verify whether relaxed alias analysis brings improvements, we compared the number of race points that can be identified with and without relaxed alias analysis. To ensure the accuracy of the results, the other conditions were unchanged, except for the alias analysis component in ERACE. AA-SVF indicates the use of alias analysis in SVF, and Improved AA-ERACE indicates the use of relaxed alias analysis. The experimental results show that without improving alias analysis, only 4 vulnerabilities’ race points were identified, whereas 15 more vulnerabilities’ race points were identified with relaxed alias analysis.
We analyzed the specific program context of each vulnerability’s race point. The race points of
CVE-2016-6516,
CVE-2017-10661, and
e010 [
27] were located in the same function or on the same path, and the race variable of
4d33 [
24] was on a stack so traditional alias analysis could easily identify these race points. The race points of the 15 vulnerabilities were located on different paths. That is to say, users must use different system call interfaces to trigger the execution of different race instructions. As long as the user passes in certain identical parameters, the race variables accessed by the race instruction satisfy the alias relationships. Traditional alias analysis cannot identify such aliases. Relaxed alias analysis will treat the same objects in different functions as the same memory. Although this will cause false positives, filtering with the collected dynamic execution paths can effectively reduce false positives.
We analyzed four cases where
ERACE failed to identify the race points.
CVE-2015-8550 is quite special. This vulnerability does not exist in the source code. It was introduced after a
gcc compilation. The user-space data were accessed twice but the consistency of the data was not checked, resulting in control-flow hijacking. When compiled with Clang, there was no such vulnerability so the race point could not be identified. The PoC of
CVE-2017-15951 could not trigger kernel vulnerabilities so it was impossible to determine whether the vulnerability path was collected. Public information on
CVE-2017-15951 is very vague and it cannot provide researchers with enough information to confirm its triggering type and root cause.
CVE-2019-11599 is due to access competition between
VMA virtual mapping spaces and not between the general memory variables so
ERACE could not detect the race points.
def3 [
26] could only trigger a page fault so we could not find its race points.
ERACE identified a total of 17 vulnerabilities’ timing relationships among the race points, which can assist researchers in debugging. There were four vulnerabilities whose race points were not identified so the execution order of the race instructions could not be identified. CVE-2016-6516 belongs to the double-fetch vulnerability, whose user-space data were read twice, but the consistency of the data was not checked. The writing thread was located in the user layer but ERACE could only execute the kernel. Therefore, it could not identify the user-space competition and the instruction sequence when the vulnerability was triggered. The competition involved in CVE-2017-15265 was more complicated. After executing the suspicious three race points, we identified the relative instruction sequence but still could not stably trigger the vulnerability. After analyzing the source code, we found that only when the four program points in each thread were executed in a specific order could the vulnerability be stably triggered. Therefore, the execution method proposed in this paper could not identify the complete instruction order.
ERACE identified a total of 17 vulnerabilities’ triggering types, which can assist researchers in choosing an appropriate exploitation method. We compared the recognition accuracy of KASAN and
ERACE. KASAN falsely identified eight triggering types, whereas
ERACE was able to correct the KASAN identification errors. Of the six vulnerabilities that
ERACE failed to identify, four of them were not identified because the race-point detector did not identify the race point. The
CVE-2017-2671 vulnerability could trigger only a null deference, which did not belong to the currently exploitable triggering type so
ERACE failed to identify it.
CVE-2017-17712 is a vulnerability caused by using uninitialized stack variables. Neither KASAN nor
ERACE was able to identify it. After using STACKLEAK developed by Grsecurity/PaX [
18], it was easy to eliminate this vulnerability so it cannot be exploited.
6.3. Effectiveness
This section mainly tests the effectiveness of
ERACE in facilitating the process of exploiting the race vulnerability (see
Table 2 for the experimental results). In general,
ERACE can effectively help researchers generate exploits, and the identified checkpoints can increase the success rate of the privilege escalation.
Among these 23 vulnerabilities, exploits of only 3 vulnerabilities were publicly available and ERACE helped 13 vulnerabilities to achieve exploitation. We found a total of 294 checkpoints in the modules where the 23 vulnerabilities were located, which can be used by researchers to check whether race conditions or heap spraying has been satisfied. Among the 13 successfully exploited vulnerabilities, we compared whether the vulnerabilities could be successfully exploited by using and not using checkpoints. We found that eight of them could not be successfully exploited without using checkpoints. This shows that it is necessary to consider the use of checkpoints when exploiting race vulnerabilities. If heap spraying is performed without confirming whether the race condition has been satisfied, it consumes a limited amount of heap-spraying space and time and also makes the system unstable. Then, if it goes to the next exploitation stage without confirming whether the heap spraying has succeeded, it will further reduce the exploitation success rate.
There were five vulnerabilities that were successfully exploited without using checkpoints, namely
CVE-2017-15265,
CVE-2019-18683,
2021-26708,
7341 [
23], and
e010 [
27]. As fewer checkpoints were identified in the modules where the three vulnerabilities were located, no suitable checkpoints could help to exploit these three vulnerabilities. The main reason is that some kernel modules are implemented with less code and fewer functionalities and they contain fewer interfaces for users to access kernel data.
We analyzed 10 vulnerabilities that failed the exploitation. Four of them failed because the race point was not identified and the other six failed because their exploit primitives were restricted. For example, CVE-2016-6516 could only overwrite a continuous 12 bytes to 0, but modifying the credentials required 28 bytes to escalate privilege. Hence, we could not exploit the vulnerability at the time. We also made some interesting discoveries. The CVE-2016-8655 and CVE-2017-15649 vulnerabilities were both located in the /net/packet/af_packet.c file so the numbers of checkpoints were the same. CVE-2017-17712 was located in the /net/ipv4 module, which was very large with many functions, so the number of checkpoints was the largest. The CVE-2017-11176 and CVE-2017-2671 vulnerabilities involved multiple modules so the numbers of checkpoints found were relatively large.
7. Related Works
As mentioned above, the objective of this paper is to assist in the process of exploiting kernel race vulnerabilities. Therefore, the related works are mainly divided into three categories, namely race vulnerability detection, automatic exploit generation in the user space, and kernel vulnerability exploitation. Below, we discuss the existing works in these three categories in detail.
Race vulnerability detection. There are a lot of studies on detecting race vulnerabilities, and feature modeling and dynamic detection techniques for race vulnerabilities are very helpful for race exploitation. These techniques are mainly divided into two categories: static analysis and dynamic analysis.
Refs. [
30,
31,
32] adopted static analysis techniques. Among them, Relay [
31] proposed the concept of a relative lockset, which makes the function summary independent of the calling context so that it can perform easy-to-parallel modular and bottom-up analyses. Ref. [
30] was based on the Coccinelle engine and used static pattern matching to detect a special kind of data race, called a double-fetch vulnerability. It matched the kernel function that calls
copy_from_user() or
get_user() multiple times to read data from the user space at the same address and then manually analyzed these matched functions. Ref. [
32] formalized the double-fetch vulnerability, of which the two read operations have a spatial overlap and the overlapping variables have control dependence or data dependence. Then, static analysis and symbolic execution were performed on the LLVM intermediate representation. The advantage of static analysis is that it is scientific in race vulnerability feature modeling and has great scalability. The disadvantage is that it has a high false-positive rate and relies heavily on manual confirmations.
Refs. [
10,
33,
34,
35,
36,
37,
38,
39] applied dynamic analysis techniques. Bochspwn [
38] is a system-wide memory monitoring tool implemented on a Bochs ×86 emulator, which is capable of detecting kernel double-fetch and information leaks. ThreadSanitizer [
39] is an execution tool integrated into gcc [
40] and clang [
41] compilers that can detect multi-thread data race vulnerabilities at runtime. The goal of [
33,
34] was to detect concurrency vulnerabilities. The former proposed the coarse-grained interleaving hypothesis, which improves detection accuracy and reduces time costs. The latter defined relaxed exchangeable events, which can detect three types of concurrency vulnerabilities, the
UAF, null-pointer-dereference, and double-free vulnerabilities. The innovation in [
10,
35] was to explore thread interleaving, which applies modified
QEMU that can be used to set breakpoints to control thread interleaving. However, the former does not first determine the suspicious race instructions, resulting in a large search space. The latter proposed a deterministic thread interleaving technique, which modifies qemu and implements three hypercalls to schedule several virtual CPU cores to run and interrupt. However, it can only control thread interleaving on different CPU cores, whereas our exploit must run on one specific CPU to improve the success rate of heap spraying. Thus, the hypervisor-based solution does not promote our exploit debugging. The innovation in [
30,
37] was to improve the traditional fuzzing technique to adapt to detecting race vulnerabilities. Krace [
36] introduced a new coverage tracking metric, namely alias coverage. MUZZ [
37] introduced a new instrumentation mechanism and optimized the process of seed selection. The mechanism gives priority to the seed that can trigger new code coverage or a new thread context. The advantage of dynamic analysis is that it can directly generate input that triggers vulnerabilities, but the disadvantage is that it has poor scalability and slow speeds.
Automatic exploit generation. Kernel vulnerabilities are more difficult to exploit than vulnerabilities in the user space. This is because the kernel environment is more complicated and requires more system calls to complete the exploitation. However, the research on automatic exploit generation originates from vulnerabilities in the user space and the techniques used are similar.
APEG [
42] studied the automatic exploitation of real software vulnerabilities for the first time, but APEG needs software that contains vulnerabilities and a relatively patched version. Exploits generated by APEG can only trigger vulnerabilities. AEG [
43] and Mayhem [
44] are both end-to-end systems that can fully exploit vulnerabilities. The former relies on the source code and the latter only requires binary files. The latter applies concolic symbolic execution and index-based memory modeling. FLOWSTITCH [
45] first proposed a model based on data-flow stitching, which can generate valid inputs to bypass
DEP,
CFI, and even ASLR mitigations. The Q [
46] scheme is based on ROP and uses a small amount of unrandomized code to automatically generate an ROP chain, which can effectively bypass W⨁X and ASLR mitigations. For heap vulnerabilities, one of the most difficult vulnerabilities to exploit, [
47,
48,
49,
50] each proposed their own solutions. Revery [
47] is able to explore exploitable states that are different from the crash path based on the PoC. HeapHopper [
48] is based on model checking and symbolic execution and it can automatically analyze the exploitability of the heap implementation in the case of memory corruption. SHRIKE [
49] can automatically arrange a heap layout on the PHP interpreter and perform control-flow hijacking. ARCHEAP [
50] can systematically search undeveloped heap exploit primitives without considering their underlying implementations.
Kernel vulnerability exploitation. This paper refers to previous research on two aspects, which are not the focus of this paper. The first bypasses mainstream mitigation mechanisms such as
SMAP,
SMEP, and
KASLR [
19,
51,
52]. The second applies the follow-up exploitation stage after determining the triggering type of the race vulnerability [
13,
14,
15,
16,
53,
54,
55]. Next, we introduce the existing techniques for kernel vulnerabilities.
Refs. [
14,
53,
54] each proposed new exploitation techniques, among which KEPLER [
14] discovered a new ROP construction method for vulnerabilities that can only hijack the control flow once. Ref. [
53] used the shared space physmap between the kernel space and user space to bypass
SMAP and
SMEP mitigations. Ref. [
54] proposed a new kernel heap-spraying mechanism for when the physmap page is not executable. Refs. [
19,
51,
52] studied how to bypass the kernel address space layout randomization. ELOISE [
19] used an elastic object in the kernel. Refs. [
51,
52] used the side-channel technique to leak the kernel address. Ref. [
55] proposed a deterministic stack-spraying technique and memory-consuming stack-spraying technique to control the uninitialized variables on the kernel stack. FUZE [
13] is a framework for facilitating a kernel
UAF exploitation and adopts the kernel fuzzing and symbolic execution techniques to explore system calls that are useful for
UAF exploitation and mitigation bypassing. SLAKE [
15] modeled three kernel vulnerabilities:
UAF, double-free, and
OOB vulnerabilities. It can identify kernel objects and the corresponding system calls that are useful for heap spraying, and reorganize slabs to obtain the expected slab layout. KOOBE [
16] summarized the challenges in exploiting OOB access vulnerabilities. A new technique for capability-oriented fuzzing was proposed to search for certain capabilities. Symbolic tracing was used to automatically analyze
OOB vulnerabilities and identify the appropriate target objects.
The process of locating race points in this paper is similar to that of FUZE [
13], but FUZE aims at exploiting
UAF vulnerabilities. Memory allocation points and release points can be located according to the KASAN warning report. However, there is no existing tool for locating race points. EXPRACE [
56] uses an interrupt mechanism to slow down the execution of the specified core to improve the success rate of competition for multi-variable race vulnerabilities, whereas we use program analysis techniques to assist in the exploit generation of general race vulnerabilities. The problems we face are different.
8. Conclusions
In this paper, we show that it is challenging to exploit kernel race vulnerabilities. Aiming to address the problem of the exploiting process taking considerable time and requiring extremely high professional knowledge, we developed
ERACE, an effective framework for facilitating the process of exploiting kernel race vulnerabilities. To be more specific, we introduce the implementation of
ERACE. The race-point detector uses low-level virtual machine (LLVM) static analysis to search for all possible race instruction pairs and kcov [
17] to dynamically record the execution path of the PoC. The vulnerability analyzer uses the instrumentation mechanism to identify the timing relationships among the race instructions, uses static analysis to identify the triggering type of the vulnerability, and records the vulnerability context. The checkpoint detector uses LLVM static analysis to identify the checkpoints and records the system calls to which the checkpoints belong. Finally, based on the vulnerability information collected above, we finish generating the exploit.
We choose 23 real-world kernel race vulnerabilities to demonstrate the utility of ERACE. We successfully detect the race points of 19 vulnerabilities, the timing relationships among the race instructions, and the triggering types of 17 vulnerabilities, and assist in generating exploits for 13 vulnerabilities. Based on these findings, we can safely conclude that ERACE can effectively help security researchers simplify the analysis process of kernel race vulnerabilities, select appropriate exploitation methods, and use checkpoints to increase the success rates of exploitations. Furthermore, the relaxed alias analysis also helps to identify more race candidates, which may be beneficial for detecting race vulnerabilities.
In the future, we will extend the functionality of
ERACE to adapt to more scenarios. First, when identifying race points, we did not perform lockset-based analysis on the alias variables, which may have led to false positives.
ERACE uses dynamic execution paths to filter out unexecuted race instructions to reduce false positives. By performing lockset-based analysis, we can exclude race instructions with correct locking, further reduce false alarms, and reduce manual analysis. For example, refs. [
57,
58,
59] each applied lockset-based analysis to detect data race vulnerabilities. Second,
ERACE is only suitable for single-variable race vulnerabilities. For multi-variable race vulnerabilities, the execution order of the race instructions is so complicated that it was impossible for
ERACE to identify the exact timing relationships. Next, we will improve
ERACE to enable it to analyze multi-variable race vulnerabilities.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}