Abstract
Human skin detection is the main task for various human–computer interaction applications. For this, several computer vision-based approaches have been developed in recent years. However, different events and features can interfere in the segmentation process, such as luminosity conditions, skin tones, complex backgrounds, and image capture equipment. In digital imaging, skin segmentation methods can overcome these challenges or at least part of them. However, the images analyzed follow an application-specific pattern. In this paper, we present an approach that uses a set of methods to segment skin and non-skin pixels in images from uncontrolled or unknown environments. Our main result is the ability to segment skin and non-skin pixels in digital images from a non-restrained capture environment. Thus, it overcomes several challenges, such as lighting conditions, compression, and scene complexity. By applying a segmented image examination approach, we determine the proportion of skin pixels present in the image by considering only the objects of interest (i.e., the people). In addition, this segmented analysis can generate independent information regarding each part of the human body. The proposed solution produces a dataset composed of a combination of other datasets present in the literature, which enables the construction of a heterogeneous set of images.
1. Introduction
Due to the natural process of technological evolution, demands that require digital recognition from digital image processing and computer vision are increasingly appearing, such as people and movement identification and human skin recognition, among others. Of these, skin segmentation is an important step in enabling several computer vision-based applications, such as facial expression recognition [1], detection of nudity [2,3] or child pornography [4], body motion tracking, gesture recognition [1], and skin disease diagnostics, among other human–computer interaction (HCI) applications [5].
Methods commonly used in the skin segmentation problem are, in general, situation- or application-specific [6,7]. In the case of face recognition, the methods segment skin and non-skin pixels based on face detection [8], while in applications of medicinal interest (e.g. the abdominal region), they tend to solve the problem by actually considering the existence of elements corresponding to the abdomen in the examined image [9].
In these situations, the entire examination is applied in a controlled environment—the input image has previously known aspects, considering the lighting conditions, capture equipment, and objects present. There are approaches suggested by several authors which seek to segment the skin pixels according to each particular one in an optimal way [10,11]. For example, in an application related to biometrics, the response time for the user is fundamental, together with an acceptable accuracy for the expected result of this application [12]. Otherwise, in an application with medical purposes, the processing speed tends to not represent so much relevance; otherwise, the accuracy becomes fundamental due to the characteristics of the analysis, which primarily aims to increase the accuracy of the result and not the prediction time. Therefore, considering the application and its requirements, one approach may be more suitable than another in segmenting skin and non-skin pixels.
There are several problems—depending on the approach—when the input images have no given pattern, either because of difficulty in segmenting the elements belonging to the background of the objects of interest or the quality. The quality is affected by several factors, such as the image capture equipment, image illumination conditions during the capture process, and sampling process during digitization [6]. Therefore, this work aims to contribute to improving the image examination process in the forensic field, in which the input images may contain any of the above-mentioned aspects.
Furthermore—considering the possibility of sharing forensic examination target material through internet usage applications—these images suffer from data compression, which causes the loss of relevant image information, reducing its quality [13]. During compression processing, quantization and sampling methods eliminate similar information from image pixels, severely affecting skin regions. Skin regions have very discrete pixel variations, and these form the texture of the skin. However, this texture ends up being compromised by the compression processing, removing from it the texture information [13]. Therefore, applications with a controlled environment, considering images with previously known quality standards, allow approaches and techniques based on skin texture recognition to present the expected results [7,14]. However, these methods do not deliver the same results when examining images that have the skin texture information corrupted by the sampling and quantization process or the hard compression processing performed by sharing applications.
Figure 1 presents the change of an image after sharing the image through the message exchange application. In this example, we can note there was a loss of a piece of the pixel information. Therefore, the input image was modified after the compression process. This process induces a loss in the resulting qualities, mainly in applications based on images with discrete textures or small skin regions. However, image compression methods—such as the discrete cosine transform (DCT)—can eliminate the coefficients with relatively small amplitudes, which are a minimum deformation in the image. These processes still incur a loss of image information, mainly related to texture [15]. Therefore, texture analysis is a non-viable method for forensic applications [16].

Figure 1.
Example of the results of an image submitted to the compression process during transfer by a message transfer application: (a) original transferred image and (b) received image result with compression.
Therefore, this work brings a new approach to human skin segmentation in digital images. The contributions of this work are as follows:
- (1)
- A segmentation model with the ability to classify and quantize the pixels of human skin present in an image according to the regions of the human body;
- (2)
- The proposed model presents the possibility of segmenting and quantizing the pixels of human skin according to the instantiation of the object of interest in the image (i.e., of people);
- (3)
- The generation of a new dataset compiled through the collection of datasets present in the literature, thus generating a heterogeneous dataset;
- (4)
- The proposed model allows image analysis, especially in forensic applications, to focus on regions of interest to the human body, reducing the possibility of false positives in its examination.
The new dataset is due to existing challenges in the skin pixel segmentation technique of considering lighting conditions, ethnic differences, image quality, capture equipment, and relevant exposure of regions with the presence of skin.
In this work, we propose a solution for skin and non-skin pixel detection in digital images, even with compromised images by events related to capturing and storage. In the following sections, we review the background of the computational vision algorithm (Section 2). In Section 3, we describe the skin detection process. We present and discuss our results in Section 4. Lastly, we conclude this work (Section 5).
2. Background
2.1. Detection of the Regions of Interest
Considering that the objective of the use of this approach is to segment which pixels of the image are skin or are not skin as well as quantify the proportion of skin displayed, it was determined as an object of interest in analysis of the people present in the image, naming these objects regions of interest (RI). The material examined can contain images with complex backgrounds or even one or more RIs, and the first step is to segment these RIs.
In the first step, the model yields the essential characteristic of object detection. The proposed approach uses an implementation of the Mask R-CNN neural network architecture for this task. This convolutional neural network is considered the state of the art regarding image segmentation processing and object detection, including instance-based segmentation [17]. The Mask R-CNN was developed based on the Faster R-CNN, a convolutional neural network based on regions of interest which favors the goal of this task. During this task, by submitting the examined input image to find the prediction from the network, the coordinates of the RIs present in the image in the form of bounding boxes are obtained. The RI detection algorithm has been used by Liu [18] to recognize regions in video frames containing regions with human actions, such as swimming, driving, and others. From the knowledge of the RIs, Liu applied two more steps for his prospect of aiming to detect possible human needs.
In Figure 2, we present a conceptual diagram of the operation of this architecture. Note that in the first phase, the input image is submitted to a layer for extracting its features and characteristics. Then, the feature descriptors are evaluated by a layer for defining the proposed regions of interest (i.e., possible objects). These objects are then classified, delimited by coordinates, and also represented by employing masks.
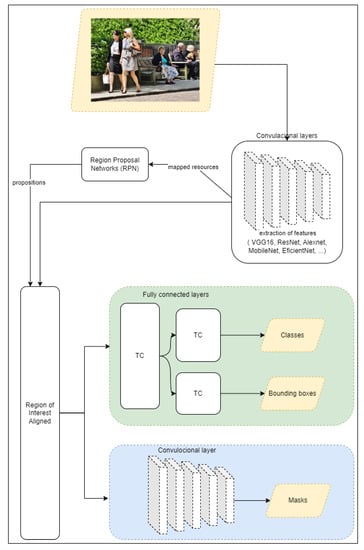
Figure 2.
Architecture diagram of Mask R-CNN.
For the development of the experiments, we used the implementation in [19] of the Mask R-CNN architecture as well as its pretrained model, considering for the purpose of this work only objects of the class person, which was the RI objective explored in this task. After the execution of the evaluation of the input image by implementation of the neural network, the resulting delimiting coordinates of the objects of interest were obtained. In Figure 3, this result is presented from an examined example image, which had a few people present within a complex scene.

Figure 3.
Example of a processed image after submission of the region of interest recognition process.
2.2. Segmentation of Body Parts
This work, in addition to presenting the segmentation of skin and non-skin pixels, evaluates each segmented RI from the previous step to determine the proportion of skin on display. In approaches proposed by other authors, especially when dealing with specific applications such as biometric applications, the determination of the proportion of skin present in the image [1,4,20,21] was not included in their studies.
Considering the forensic application, for example, the proposed approach needs to estimate the proportion of visible skin in the examined image. Digital images can contain large regions of visible skin due to the size of the image without generating forensic interest, or they can contain small regions of skin—due to the total size of the image—and present objects of forensic interest. Thus, this algorithm needs to present the complete region of the human body present in the image as well as having this region segmented by body part. For this task, a layer was implemented in the processing using the BodyPix neural network model [22].
BodyPix is a body segmentation model built under the TensorFlow framework. Taking as input an image containing a human body, it uses a pretrained neural network to separate the parts of a body into segments as specified in Table 1. Among the variety of uses of this model is the use intended to remove human objects from an evaluated image. Therefore, in this work—especially in the task of determining the proportion of visible skin—it was necessary to extract the visible parts of the human body from the RIs and thus calculate the proportion of skin as a ratio for the area of each visible part.

Table 1.
Index table with the identifier of each body part detected by the Bodypix model.
In this work, the BodyPix model is used to segment the major parts of the human body and thus determine the total pixels in the image corresponding to each human body part. However, because the original segmentation was very detailed (i.e., containing regions for each limb), the body parts were grouped into larger segments than were available from the original model. Parts such as legs (right and left) and feet were grouped under the class “legs” to consider as a single class all visible pixels in the image examined belonging to the legs. Similarly, the other body regions were grouped as described in Table 2.
Table 2.
Grouping rules for BodyPix model key parts.
After associating the images to each part of the body, it was possible to measure more precisely the number of pixels pertaining only to the human body. Thus, it was possible to calculate the proportion of visible skin concerning the total pixels that belonged to the person being evaluated and not under the total pixels of the image, which generates distorted values and is not useful for the application of forensic objectives. Figure 4 shows an example of the proposed segmentation. The human body in the input image (Figure 4a) was subdivided into four parts to be assessed individually.
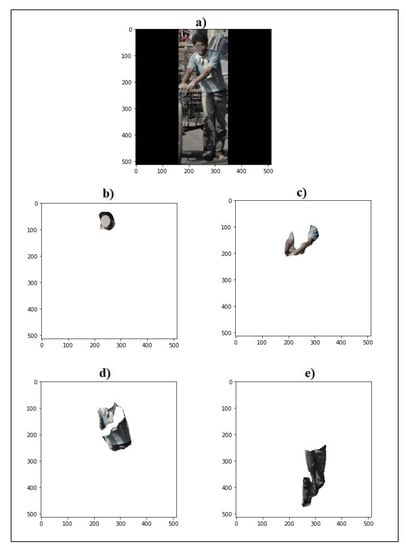
Figure 4.
Example of segmentation of human body parts: (a) input image, (b) face, (c) arm, (d) torso, and (e) leg.
For forensic applications, this individual analysis is important because by allowing one to know the content of each human body part in each person present in the examined image, it is possible to efficiently and accurately identify the objects of interest and discard the insignificant ones. For example, an image in which only one hand is displayed in proportion to the total size of the image will correspond to a large portion of the total size of the image. In this case, it makes the analysis unfeasible, because an image with only this fragment is irrelevant to the evaluation.
3. Skin Detection
3.1. Segmentation
Most approaches on the subject of skin segmentation are based on a particular color space [2,4,21,23] or on fusion components from different color spaces [3,7,24], but they are evidently limited to color images only. In general, skin color occupies a limited range of values in different color spaces [25], and detection consists of determining an optimal model for the thresholds belonging to the skin and non-skin groups [7]. In addition, some studies, such as [24,25,26], still tried to analyze other features, such as by segmenting regions by texture type. However, this approach needs images with previously known features, because it is necessary to locate the descriptors corresponding to the textures, which need to be preserved.
A skin detection process mainly needs two decisions, as presented in Figure 5. The first choice is to determine the appropriate color space in which it is easiest to discriminate skin pixels, which is a key factor in the design of a skin detector, considering the computational cost of transforming between color spaces [27]. The second decision is to determine the skin segmentation model that will be used to classify a given pixel, being either skin or non-skin. Thus, the system must be intelligent and flexible enough to handle various aspects, such as different skin tones or lighting conditions, reducing false negative rates by not identifying a skin pixel as a non-skin pixel [8]. In addition, it should be sensitive enough to differences between classes—background objects with skin color—to reduce false positive rates (i.e., identifying a non-skin pixel as a skin pixel) [25].
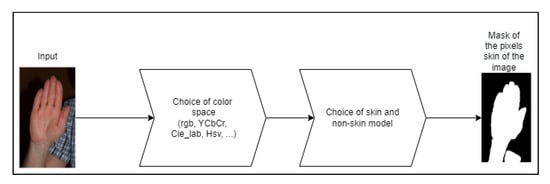
Figure 5.
Conceptual diagram of the skin segmentation process.
These choices aim to overcome the main challenges of skin recognition: the definition of an optimal model of skin and non-skin pixels for different skin types [26] and diverse lighting conditions [6,8,10]. Furthermore, the accuracy of skin recognition is affected by pixels of skin-like colors in the image background or clothing. These pixels generate false positives and hinder accurate skin recognition. This problem can be emphasized when we apply the recognition process in small regions containing skin, such as a person’s hands, since the treatment enforced to suppress false negatives can also suppress small true regions of skin [25].
An example is shown in Figure 6, where there are areas of clothing pixels that are confused with the values of regions belonging to skin tones in the color space. The main question in the recognition of skin and non-skin pixels is to determine an optimal model for this classification, neither being rigid in the threshold values for skin tones nor being flexible, which would increase the various false positives [10,20].

Figure 6.
Example image with skin-like pixels in clothing and background regions: (a) original image and (b) image without non-skin pixels.
In general, the proposed approaches seek to balance recognition accuracy and the required computational power, since human–computer interaction applications need low computational costs coupled with high accuracy [3,4]. The most common strategies for defining skin models can be separated into three approaches: (1) explicitly defined regions [2,3], where the boundaries are fixed by a set of rules, (2) parametric methods [8,28] and non-parametric methods [10,24], which are based on histograms applied (or not) to Gaussian models and elliptical boundaries, and (3) machine learning-based approaches which, through the training of a suitable neural network model, enable the identification of skin and non-skin pixels [29].
According to Gonzalez and Woods [30], the fundamental problem of segmentation is the division of an image into regions that satisfy certain conditions set to achieve the end goal. In skin segmentation, the problem becomes more complex because the goal is not exactly the detection of an object. It involves examination of image features, such as color regions of a given color space in color images and the intensity levels in non-color images. In general, the process of segmenting skin and non-skin pixels can be represented by
where the conclusion G is a comparison of the boundary and the result of the function f, and this represents the function applied by the approach taken in solving the problem.
3.2. Challenges
Considering the classification of pixels in an image as skin or non-skin as a typical image segmentation problem, the adopted approach must have the ability to overcome some difficulties (low illumination, camera characteristics, complex background, subject movement, etc.) [5]. Depending on the expected result for the final application of the skin identification process, some challenges may substantially affect this result. The following are the main ones:
- (1)
- Lighting conditions: The illumination applied at the moment of image capture directly impacts the result, especially in approaches that use color space analysis to determine if the pixel belongs (or not) to a certain region classified as skin. The lighting variation in the environment where the image was captured creates one of the most difficult issues for this operation. Computer vision must have the ability to adjust to this variation, recognizing the same object in different lighting conditions in the same way that human vision can.
- (2)
- Ethnicity: Ethnic skin tone features represent a difficulty during the classification process because the enlargement of the skin region causes an increase in the occurrence of false positives. Some approaches adopt as a measure to overcome this difficulty the elaboration of a skin pixel model based on the previous detection of the face of the image object, and from the resulting map, they classify the image pixels as skin or non-skin. Although this method can work around some cases of skin tone variation, it has no efficient application when there is no face in the image and when there are several people in the same image. Another factor that may make this technique unfeasible is the increased computational consumption as well as the increased processing time.
- (3)
- Background: The accuracy of skin detection, in the process of segmentation, is severely affected when the background is complex and contains textures and colors similar to the skin region in the color space. The increase in false positives makes skin detection in certain images impractical. Some authors consider this situation a probabilistic problem and propose the definition of a skin probability map for each pixel of an image. Although the result can significantly reduce the occurrence of false positives, there is an increase in the need for computational power, which can make the approach unfeasible for certain applications.
- (4)
- Characteristics of the scanned image: Applications in which the scanned images have variable characteristics impact the result obtained. Images that have multiple objects, small objects, and objects from different perspectives represent increased difficulty in the segmentation process. The process needs to have the ability to detect skin without being able to use features such as skin texture. In computer vision, the ability to detect an object is usually related to a set of preknown characteristics of the object, such as size, position, and quantity, thus generating a certain restriction for the result. It happens that in some final application demands, the condition of the objects in the image is not known, and the computer vision system needs to have the same capacity as human vision to obtain the result, waiting independently of the characteristics of the objects in the examined image.
3.3. Color Space
Skin detection can be considered a binary pixel classifier with two classes: skin and non-skin [31]. The classification achievement depends on an appropriate feature set for capturing the essential elements of these pixels [8]. Each application needs the appropriate color model (RGB, HSV, or YCbCr, among others) [10] for when we consider the accuracy, the computational cost required for transformation, and the separability of the pixels with skin colors as the principal decision point [8]. Colorimetry, computer graphics, and video signal transmission standards have given rise to many color spaces with different properties. We have observed that skin colors differ more in luminance intensity than in chrominance due to lighting variation. Therefore, it is common to apply a linear or nonlinear transform in the RGB color space. This process changes the input’s original space into another color space with independent components, eliminates in the classification process the luminance component analysis, and preserves the chrominance components [6]. A color space is made up of two components—chrominance and luminance [6]—and can be subdivided into four groups [31,32]:
- (1)
- Basic—RGB, CIE-XYZ: The RGB color model consists of three color channels, where R is red, G is green, and B is blue. Each channel has a value ranging from 0 to 255. This color space was originally developed for old cathode-ray tube (CRT) [32] monitors. Due to the model mixing the luminance and chromatic components, it is not always the most suitable color model for classifying pixels as skin and non-skin, as the variation in illumination greatly affects the accuracy of the result obtained from the classifier. The Commission Internationale de l’Eclairage (CIE) system describes color as a luminance component Y and two additional components X and Z. According to Kakumanu et al. [6] the CIE-XYZ values were constructed from psychophysical experiments and correspond to the color matching characteristics of the human visual system.
- (2)
- Orthogonal—YCbCr, YDbDr, YPbPr, YUV, YIQ: The common goal among these color models is to represent the components as independently as possible, reducing redundancy between their channels, unlike in basic models [4,32]. The luminance and chrominance components are explicitly separated, favoring their use in skin detection applications and, in this case, discarding the luminance component [6].
- (3)
- Perceptive—HSI, HSV, HSL, TSL: The RGB color space does not directly describe the perceptual features of color, such as hue (H), saturation (S), and intensity (I), and many nonlinear transformations are proposed to map RGB to perceptual features. The HSV space defines the property of a color that varies in the passage from red to green as the hue, the property of a color that varies in the passage from red to pink as the saturation, and the property that varies in the passage from black to white as intensity, brightness, luminance, or value [6]. HSV can be a very good choice for skin detection methods because the transformation from RGB to HSV is invariant to high intensities in white lights, ambient light, and surface orientations relative to the light source.
- (4)
- Uniforms—CIE-Lab, CIE-Luv: According to [6], perceptual uniformity describes how two colors differ in appearance to a human observer. However, perceptual uniformity in these color spaces is obtained at the expense of heavy computational transformations. In these color spaces, the calculations for the luminance (L) and chromaticity (ab or uv) are obtained by a nonlinear method of mapping the coordinates .
3.4. Methods
Our approach is based in four tasks:
- (1)
- Explicit boundaries: In this method, a small region in a given color space is selected, where the pixels that belong to that region are considered skin. This approach is one of the simplest and most widely used, although it has many limitations regarding the challenges already discussed in this article. Known in the literature as thresholding, it seeks to determine a threshold for considering pixels belonging to the skin group. Many approaches improve their results by applying conversion techniques from the RGB color space to other color spaces where one can work with the chrominance and luminance values in separate ways. As an example, Basilio [2] converted the RGB color space to YCbCr and considered a thresholding of . Benzaoui [15] used in his approach explicit boundaries directly over the RGB color model:
- (2)
- Histogram based: A skin and non-skin color model is obtained by training with a training dataset, where skin and non-skin pixels are identified. After obtaining the global histogram based on this dataset, the color space is divided into two classes of pixels (skin and non-skin). This approach is widely used [1,21] as it shows better results for varied condition images and needs low computational power for its execution. Buza et al. [24] used in their work a histogram-based approach as the basis for their hybrid implementation, which ultimately classified skin and non-skin pixels using a k-means clustering algorithm.
- (3)
- Neural networks: The Neural networks play an important role in research related to skin segmentation, especially the (multilayer perceptron) (MLP) model. Given a dataset of skin and non-skin samples and the determination of the learning parameters, the net adjusts the synaptic weights according to the expected training result. After obtaining the network training, it is possible to classify skin and non-skin pixels in an analyzed image. For example, to overcome the problems related to ethnic differences and capture conditions such as the lighting and object organization, the author of [29] used in his work a neural network architecture composed of convolutional layers followed by a deep learning layer for classification of skin and non-skin pixels [5].
The final task of the proposed solution is the segmentation of the skin and non-skin pixels present in the examined image for each part of the body previously segmented. In this step, the objective is to know the proportion of visible skin concerning the total number of pixels corresponding to the examined part, thus being able to present an accurate indicator of the skin content in the image.
Because it was necessary to determine a color space for this process, the shape that best represented the color hues, especially for a human observer, was chosen by us. Therefore, the H and S components, related to the hue from the HSV model, were mixed with the a and b components of the hue coordinates from the CIE-Lab model. In this way, we modified the skin tone components to reduce the impact of false positives in images with complex backgrounds containing skin-like elements. At the same time, we removed the components responsible for the pixel brightness intensity.
We applied the U-Net neural network model to determine the skin pixel map. In this case, we elaborated on a heterogeneous dataset—based on the mixture of several datasets collected during the literature review—for network training. It was necessary to assemble this dataset because each one available in the literature—related to skin segmentation—was directed to its respective application. For example, an image dataset for a face recognition application contains only face examples, other applications only contain abdomen examples, and so on. Then, by collecting these datasets, we compiled for the network training a new, totally heterogeneous dataset.
3.5. Dataset
The dataset of this project was collected, organized, and normalized, containing the union of seven datasets collected during the literature review. The images and their respective ground truths were set to the same image format (JPEG) and were randomly distributed so that the dataset had diversity of images and so similar images were not clustered together.
The collection was based on the following datasets:
- (1)
- SFA [33];
- (2)
- Abdomen [9];
- (3)
- FSD [34];
- (4)
- VDM [35];
- (5)
- Pratheepan [10];
- (6)
- TDSD [36];
- (7)
- HGR [37].
After the compilation, a new dataset was created, containing 8209 varied images with their respective ground truths. In this way, the dataset became diversified, as shown in Figure 7, containing images of close-ups, body parts with exposed skin areas, and other images with complex backgrounds considering several lighting conditions.

Figure 7.
Examples of the images included in the proposed new dataset.
3.6. Convolutional Neural Network
U-Net is a neural network model proposed for semantic segmentation and consists of a contraction process followed by an expansion process [38], as demonstrated in Figure 8. It is a widely used architecture for image segmentation problems, especially in biomedical applications. In this proposal, it was trained based on the aforementioned dataset, with the objective of segmenting skin and non-skin pixels. This convolutional neural network model is widely used and recommended in the literature, as many authors rely on this model to implement their approaches. For example Liu et al. [39], in the task of segmenting overlapping chromosomes from non-overlapping ones, used the UNet model in their paper, which gave excellent results.
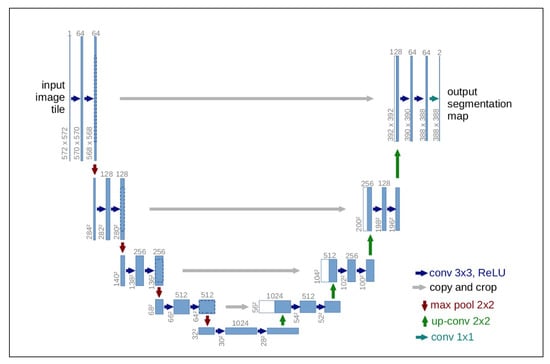
Figure 8.
Diagram demonstrating the construction of the U-Net neural network architecture.
It was presented in 2015 and won the cell tracking challenge of the International Symposium on Biomedical Imaging (ISBI) in the same year in several categories. It was considered, on that occasion, a revolution in deep learning. It uses the concept of fully convolutional networks for this approach. The intention of U-Net is to capture both the context and location characteristics, and this process is successfully completed by the type of architecture built. The main idea of the implementation is to use successive contracting layers, which are immediately followed by the sampling survey operators to achieve higher-resolution results for the input images. The goal of the U-Net architecture is to recognize the features and localization of the examined context, and for this, the main idea is to use successive contraction layers, followed by a decoder composed of expansion layers.
For training the network, we considered 30 epochs with steps for all samples in each epoch. We defined the parameters by evaluating the tests and noticed that after 30 epochs, the result remained stable. To evaluate the net training process, the k-fold cross-validation technique was applied, which estimates the net training considering k distinct segments of the dataset. As exemplified in Figure 9, this technique seeks to evaluate the neural net model on distinct datasets and finally assign the average of the evaluations as the final official performance of the net.

Figure 9.
Example demonstrating the distribution of dataset on .
Hence, using this technique, we divided the dataset into 10 folds (or segments), where each fold contained a random set of samples for training and another for testing without repetition of the sets. In addition, for the training process, we defined that the net parameters should be adjusted according to the validation step for each epoch, considering 15% of the samples in the training set. Thus, when the 30 epochs were completed, the samples reserved in the set for testing—totally unknown for net training—were submitted for evaluation of the trained model to obtain the final result for each fold. Figure 10 shows the training process, where the stability of the training appears in the 10 different dataset arrangements submitted to the training process.
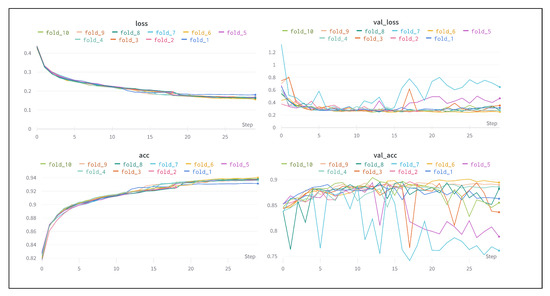
Figure 10.
Training the model for the k folds.
Table 3 presents the results of accuracy for the training phase, where the train column corresponds to the training result’s framed values and is the result of the validation step for adjusting the parameters of each completed epoch. The test column presents the results obtained from the set of images from the dataset reserved for applying the model evaluation after the training process. Considering the 10 arrangements produced by the k-fold technique, the model results were stable and obtained an average accuracy of a little over 85%, representing a good result for the forensic classification aspect of this research. This paper avoided comparing the results with other works in the literature because a fair comparison between deep learning-based works for skin detection is difficult due to the unavailability of a common benchmark [5].
Table 3.
Results of the neural network model training process.
4. Results
The set of tasks, explained in the previous sections of the proposed solution, form a system. The image submitted to the system is initially processed by the task of recognition and delimitation of the regions of interest (i.e., the people present in the image) and finally, if they exist, segments them from the image. Then, each segmented region of interest is submitted to the recognition and segmentation of the visible body parts. Each recognized body part is then processed by the next task, which produces the segmentation of the skin and non-skin pixels present in the analyzed body region. Finally, the image is then reconstructed, identifying the mask of the pixels recognized as skin in the image, the number of instances of objects classified as persons, and the ratio of skin pixels to non-skin pixels—the proportion of visible skin—for each person recognized in the image. In Figure 11, the macro diagram of the operation of the proposed solution is presented.
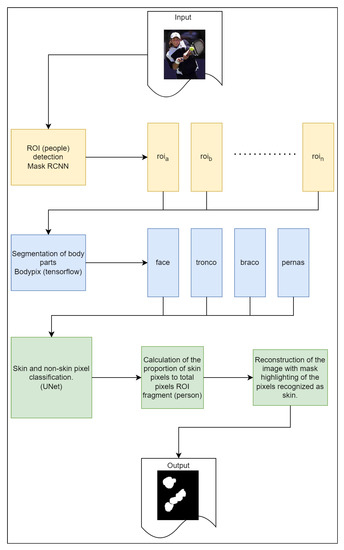
Figure 11.
Diagram showing the flow of processing tasks of the proposed solution.
To evaluate the results, some images and their respective ground truths were submitted to processing as described. In Figure 12, the result obtained after processing is presented. In the “Predicted Mask” column, the neural network prediction of each human body part is displayed, which is presented as being reassembled according to the input image. In Table 4, the data extracted from each processing step are presented to then allow calculating more precisely the estimate of skin presence in the examined image. Analytically, in Table 5, the individualized result per part of each image in the experiment is presented. It is possible to verify the results obtained for each examined part, knowing the ability of skin recognition in specific applications according to the part of the body as the objective.
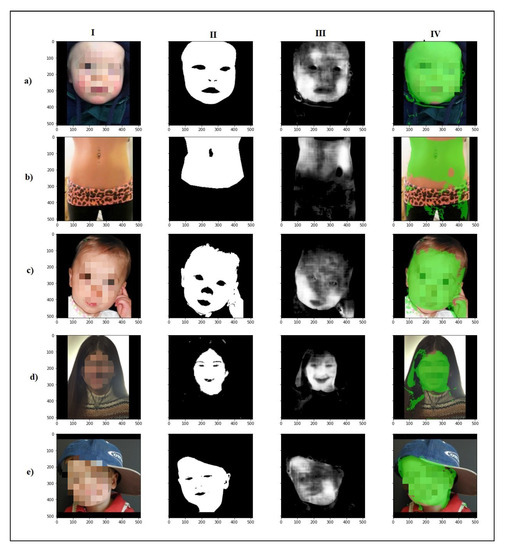
Figure 12.
Results obtained from processing: (I) input, (II) ground truth, (III) prediction, and (IV) prediction mask overlaid on input.
Table 4.
Results obtained from the experiment.
Table 5.
Results obtained from the experiment performed, segmented by part.
In Figure 13, another example is presented where more than one person was present in the input image. As can be seen, there were three people in the figure, and they were segmented to be examined individually by the process presented in the proposed solution. The results shown in Figure 14 present the segmented way of examining the process. The first and second lines show the data for the first segmented person, where the first line shows the segmentation of the body part (face, arm, torso, and leg) and the second line shows the prediction of the neural network corresponding to the segmentation of the skin and non-skin pixels for each part.

Figure 13.
Input image for the example considering the presence of more than one person in the scene: (a) input and (b) ground truth.
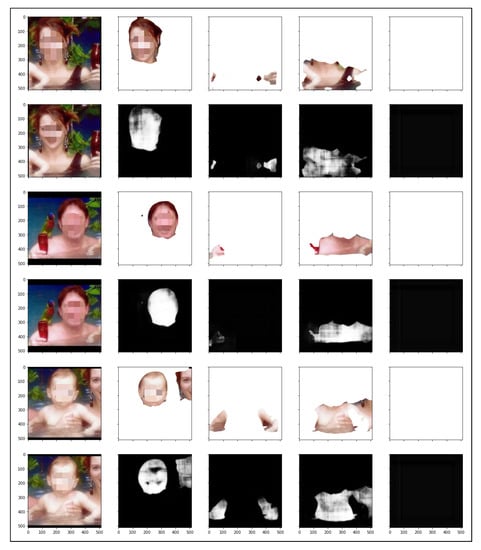
Figure 14.
Processing results containing more than one person and showing each body part segment.
Table 6 describes the information based on the composition of the pixels of the image, dividing this information by person and part of the person. For example, it is possible to verify that person c in Figure 15 had in all parts of the body exposed a high index of skin presence, except for the leg region. With the known information, applying the proposed solution may allow an image examination application to consider it potentially relevant for further analysis, considering the high index of skin pixels in specific regions of the human body. Although the focus of this work is not the privacy management of data or user information transmitted and received, we will use the definitions and criteria developed in accordance with [40,41,42,43,44].
Table 6.
Results obtained from the experiment performed on an image containing more than one person, as shown in the input image in Figure 13.

Figure 15.
Results of processing an image containing more than one person and showing the final result: (I) input, (II) ground truth, (III) prediction, and (IV) prediction mask overlaid on input.
5. Conclusions
Considering use in applications that need accurate information about the proportion of visible skin in an image, the proposed solution is efficient. We presented in the experiments in the previous sections the ability of a solution to recognize the proportion of skin according to the human body part. Our method makes it possible to restrict the recognition of images with visible skin by considering analyzing the relevant human body part, as occurs in cases of forensic image examination. In addition, we also presented a new dataset of images for segmentation, which was generated from the collection of research in the literature review. In future work, we will consider the performance analysis of experiments and evaluation of other specific neural network architectures for infrared segmentation and, in the same way, for the segmentation phase of skin and non-skin pixels. An approach may present difficulties in a certain image conditions, but this does not mean that this difficulty will result in harm to the final application. In general, we enable control of the capture process, allowing the simplest approach to present the best result, considering other factors such as time, complexity, and processing power. Another relevant factor to be considered is the level of precision needed, since not all applications need that. For each demand of the final application, there is a suitable approach.
In our approach, we can present a method capable of processing images that do not belong to a controlled or known environment but environments where the lighting conditions, capture quality, and orientation of objects in the image do not interfere with the result. The main application of our model is for forensic purposes, where images need to be classified according to the proportion of skin present. Thus, our model was able to determine the amount of skin present in an image, considering the real proportion of each identified person and not in relation to the total number of pixels in the image, thus being able to more efficiently apply a classification of images of forensic interest. Another aspect is that the proportion of skin can be evaluated for each part of the human body individually, which may contribute to future applications that target only certain parts of the human body. Although this work has a focus on overcoming the challenges of skin and non-skin segmentation in unfamiliar environments, some challenges or limitations persist. Grayscale images do not give the expected results, since the skin segmentation process is based on a color model, thus requiring color images as input. Another limitation is images with very small portions of objects containing skin, although this does not affect the result. As these objects are not of forensic interest, it is necessary to highlight this limit. These limitations can be considered as opportunities for future work, since they address important aspects of the entire process.
Author Contributions
Conceptualization, M.L, W.D.P. and A.M.d.R.F.; methodology, M.L. and W.D.P.; analysis, M.L., W.D.P. and A.M.d.R.F.; writing—original draft preparation, M.L., V.R.Q.L., A.M.d.R.F. and W.D.P.; writing—review and editing, M.L., V.R.Q.L., W.D.P. and A.M.d.R.F. All authors have read and agreed to the published version of the manuscript.
Funding
This study was funded by Fundação para a Ciência e a Tecnologia, I.P. (Portuguese Foundation for Science and Technology) under project UIDB/05064/2020, the Research Centre for Endogenous Resource 764 Valorization (VALORIZA) under project UIDB/04111/2020 and Instituto Lusófono de Investigação e Desenvolvimento (ILIND) under project COFAC/ILIND/COPELABS/3/2020.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACC | Accuracy |
| CNN | Convolutional neural networks |
| DCT | Discrete cosine transform |
| FP | False positive |
| FN | False negative |
| HCI | Human–computer interaction |
| MLP | Multilayer perceptron |
| R-CNN | Region-based convolutional neural networks |
| RI | Region of interest |
| RPN | Region proposal network |
| TC | Totally connected |
| TF | True negative |
| TP | True positive |
References
- Chakraborty, B.K.; Bhuyan, M.K.; Kumar, S. Fusion-Based Skin Detection Using Image Distribution Model. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing; Association for Computing Machinery, Guwahati, India, 18–22 December 2016; Association for Computing Machinery: New York, NY, USA, 2016. ICVGIP ’16. [Google Scholar] [CrossRef]
- Basilio, J.A.M.; Torres, G.A.; Pérez, G.S.; Medina, L.K.T.; Meana, H.M.P. Explicit Image Detection Using YCbCr Space Color Model as Skin Detection. In Proceedings of the 5th WSEAS International Conference on Computer Engineering and Applications, Puerto Morelos, Mexico, 29–31 January 2011; World Scientific and Engineering Academy and Society (WSEAS): Stevens Point, WI, USA, 2011. AMERICAN-MATH’11/CEA’11. pp. 123–128. [Google Scholar] [CrossRef]
- Platzer, C.; Stuetz, M.; Lindorfer, M. Skin Sheriff: A Machine Learning Solution for Detecting Explicit Images. In Proceedings of the 2nd International Workshop on Security and Forensics in Communication Systems, Kyoto, Japan, 3 June 2014; Association for Computing Machinery: New York, NY, USA, 2014. SFCS ’14. pp. 45–56. [Google Scholar] [CrossRef]
- de Castro Polastro, M.; da Silva Eleuterio, P.M. NuDetective: A Forensic Tool to Help Combat Child Pornography through Automatic Nudity Detection. In Proceedings of the Workshops on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 349–353. [Google Scholar] [CrossRef]
- Salah, K.B.; Othmani, M.; Kherallah, M. A novel approach for human skin detection using convolutional neural network. Vis. Comput. 2022, 38, 1833–1843. [Google Scholar] [CrossRef]
- Kakumanu, P.; Makrogiannis, S.; Bourbakis, N. A survey of skin-color modeling and detection methods. Pattern Recognit. 2007, 40, 1106–1122. [Google Scholar] [CrossRef]
- Nadian-Ghomsheh, A. Hybrid color-texture multivariate Gaussian model for skin detection. In Proceedings of the 10th Iranian Conference on Machine Vision and Image Processing (MVIP), Isfahan, Iran, 22–23 November 2017; pp. 123–127. [Google Scholar] [CrossRef]
- Hassan, E.; Hilal, A.R.; Basir, O. Using ga to optimize the explicitly defined skin regions for human skincolor detection. In Proceedings of the IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Topiwala, A.; Al-Zogbi, L.; Fleiter, T.; Krieger, A. Adaptation and Evaluation of Deep Leaning Techniques for Skin Segmentation on Novel Abdominal Dataset. In Proceedings of the IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019; pp. 752–759. [Google Scholar] [CrossRef]
- Tan, W.R.; Chan, C.S.; Yogarajah, P.; Condell, J. A Fusion Approach for Efficient Human Skin Detection. IEEE Trans. Ind. Inform. 2012, 8, 138–147. [Google Scholar] [CrossRef]
- Lumini, A.; Nanni, L. Fair comparison of skin detection approaches on publicly available datasets. Expert Syst. Appl. 2020, 160, 113677. [Google Scholar] [CrossRef]
- Chelali, F.Z.; Cherabit, N.; Djeradi, A. Face recognition system using skin detection in RGB and YCbCr color space. In Proceedings of the 2nd World Symposium on Web Applications and Networking (WSWAN), Sousse, Tunisia, 21–23 March 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Telegraph, T.I.; Committee, T.C. Digital Compression and Coding of Continuous-Tone Still Images. 1992. Available online: https://www.w3.org/Graphics/JPEG/itu-t81.pdf (accessed on 20 June 2022).
- Lei, Y.; Xiaoyu, W.; Hui, L.; Dewei, Z.; Jun, Z. An algorithm of skin detection based on texture. In Proceedings of the 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011; Volume 4, pp. 1822–1825. [Google Scholar] [CrossRef]
- Benzaoui, A.; Bourouba, H.; Boukrouche, A. System for automatic faces detection. In Proceedings of the 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 15–18 October 2012; pp. 354–358. [Google Scholar] [CrossRef]
- Nian, F.; Li, T.; Wang, Y.; Xu, M.; Wu, J. Pornographic image detection utilizing deep convolutional neural networks. Neurocomputing 2016, 210, 283–293. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Liu, S.; Li, Y.; Fu, W. Human-centered attention-aware networks for action recognition. Int. J. Intell. Syst. 2022. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 18 March 2022).
- Ma, B.; Zhang, C.; Chen, J.; Qu, R.; Xiao, J.; Cao, X. Human Skin Detection via Semantic Constraint. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xiamen, China, 10–12 July 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 181–184. [Google Scholar] [CrossRef]
- Dhantre, P.; Prasad, R.; Saurabh, P.; Verma, B. A hybrid approach for human skin detection. In Proceedings of the 7th International Conference on Communication Systems and Network Technologies (CSNT), Nagpur, India, 11–13 November 2017; pp. 142–146. [Google Scholar] [CrossRef]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards Accurate Multi-person Pose Estimation in the Wild. arXiv 2017, arXiv:1701.01779. [Google Scholar]
- Fang, X.; Gu, W.; Huang, C. A method of skin color identification based on color classification. In Proceedings of the 2011 International Conference on Computer Science and Network Technology, Harbin, China, 24–26 December 2011; Volume 4, pp. 2355–2358. [Google Scholar] [CrossRef]
- Buza, E.; Akagic, A.; Omanovic, S. Skin detection based on image color segmentation with histogram and K-means clustering. In Proceedings of the 10th International Conference on Electrical and Electronics Engineering (ELECO), Bursa, Turkey, 30 November–2 December 2017; pp. 1181–1186. [Google Scholar]
- Chakraborty, B.K.; Bhuyan, M.K. Skin segmentation using Possibilistic Fuzzy C-means clustering in presence of skin-colored background. In Proceedings of the 2015 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Trivandrum, India, 10–12 December 2015; pp. 246–250. [Google Scholar] [CrossRef]
- Shih, H.C.; Chen, J.Y. Multiskin Color Segmentation Through Morphological Model Refinement. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 225–235. [Google Scholar] [CrossRef]
- Vezhnevets, V.; Sazonov, V.; Andreeva, A. A Survey on Pixel-Based Skin Color Detection Techniques. Proc. Graph. 2004, 3, 85–92. [Google Scholar]
- Khosravi, S.; Chalechale, A. A hybrid neural network using ICA and CGA for skin detection in RGB images. In Proceedings of the Al-Sadeq International Conference on Multidisciplinary in IT and Communication Science and Applications (AIC-MITCSA), Baghdad, Iraq, 9–10 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Owais, M.; Park, K.R. OR-Skip-Net: Outer residual skip network for skin segmentation in non-ideal situations. Pattern Recognit. 2019, 141, 112922. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.C. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Xiong, W.; Li, Q. Chinese skin detection in different color spaces. In Proceedings of the 2012 International Conference on Wireless Communications and Signal Processing (WCSP), Huangshan, China, 25–27 October 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Moreira, D.C.; Fechine, J.M. A Machine Learning-based Forensic Discriminator of Pornographic and Bikini Images. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Casati, J.P.B.; Moraes, D.R.; Rodrigues, E.L.L. SFA: A human skin image database based on FERET and AR facial images. In Proceedings of the IX workshop de Visao Computational, Rio de Janeiro, Brazil, 3–5 June 2013. [Google Scholar]
- Phung, S.; Bouzerdoum, A.; Chai, D. Skin segmentation using color pixel classification: Analysis and comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 148–154. [Google Scholar] [CrossRef] [PubMed]
- SanMiguel, J.C.; Suja, S. Skin detection by dual maximization of detectors agreement for video monitoring. Pattern Recognit. Lett. 2013, 34, 2102–2109. [Google Scholar] [CrossRef]
- Zhu, Q.; Wu, C.T.; Cheng, K.T.; Wu, Y.L. An Adaptive Skin Model and Its Application to Objectionable Image Filtering. In Proceedings of the 12th Annual ACM International Conference on Multimedia, New York, NY, USA, 10–16 October 2004; Association for Computing Machinery: New York, NY, USA, 2004. MULTIMEDIA ’04. pp. 56–63. [Google Scholar] [CrossRef]
- Kawulok, M. Fast propagation-based skin regions segmentation in color images. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef]
- Liu, X.; Wang, S.; Lin, J.C.W.; Liu, S. An algorithm for overlapping chromosome segmentation based on region selection. Neural Comput. Appl. 2022, 10, 1–10. [Google Scholar] [CrossRef]
- Silva, L.A.; Leithardt, V.R.Q.; Rolim, C.O.; González, G.V.; Geyer, C.F.R.; Silva, J.S. PRISER: Managing Notification in Multiples Devices with Data Privacy Support. Sensors 2019, 19, 3098. [Google Scholar] [CrossRef] [PubMed]
- Martins, J.A.; Ochôa, I.S.; Silva, L.A.; Mendes, A.S.; González, G.V.; De Paz Santana, J.; Leithardt, V.R.Q. PRIPRO: A Comparison of Classification Algorithms for Managing Receiving Notifications in Smart Environments. Appl. Sci. 2020, 10, 502. [Google Scholar] [CrossRef]
- Rolim, C.O.; Rossetto, A.G.; Leithardt, V.R.Q.; Borges, G.A.; Geyer, C.F.R.; dos Santos, T.F.M.; Souza, A.M. Situation awareness and computational intelligence in opportunistic networks to support the data transmission of urban sensing applications. Comput. Netw. 2016, 111, 55–70. [Google Scholar] [CrossRef]
- Pereira, F.; Crocker, P.; Leithardt, V.R. PADRES: Tool for PrivAcy, Data REgulation and Security. SoftwareX 2022, 17, 100895. [Google Scholar] [CrossRef]
- de Moraes Rossetto, A.G.; Sega, C.; Leithardt, V.R.Q. An Architecture for Managing Data Privacy in Healthcare with Blockchain. Sensors 2022, 22, 8292. [Google Scholar] [CrossRef] [PubMed]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).