Abstract
The continuously growing population requires improving the efficiency of agricultural production. Wheat is one of the most wildly cultivated crops. Intelligent wheat ear monitoring is essential for crop management and crop yield prediction. Although a variety of methods are utilized to detect or count wheat ears, there are still some challenges both from the data acquisition process and the wheat itself. In this study, a computer vision methodology based on YOLOv4 to detect wheat ears is proposed. A large receptive field allows viewing objects globally and increases the connections between the image points and the final activation. Specifically, in order to enhance the receptive field, additional Spatial Pyramid Pooling (SPP) blocks are added to YOLOv4 at the feature fusion section to extract multi-scale features. Pictures of wheat ears taken at different growth stages from two different datasets are used to train the model. The performance of the proposed methodology was evaluated using various metrics. The Average Precision (AP) was 95.16% and 97.96% for the two datasets, respectively. By fitting the detected wheat ear numbers and true wheat ear numbers, the R2 value was 0.973. The results show that the proposed method outperforms YOLOv4 in wheat ear detection. It indicates that the proposed method provides a technical reference for agricultural intelligence.
1. Introduction
Wheat is one of the most important crops in the world. With the rapid population growth around the globe, the demand for increasing crop yields is becoming more urgent. Intelligent agricultural machinery is critical in improving agricultural efficiency [1,2]. Monitoring wheat ears is essential for predicting crop yield, making decisions on crop management, and developing intelligent agricultural machinery [3]. Traditionally, wheat ear counting is carried out almost manually, which is labor-intensive, time-consuming, and error-prone. Automatic detection of wheat ears would not only contribute to enhancing the working efficiency but also be significant for the development of intelligent agriculture machinery. Therefore, there is a pressing need to develop an efficient and automatic algorithm to detect wheat ears.
Computer vision provides an alternative for analyzing high-throughput image-based phenotypes. Conventionally, imaging processing methods are widely used to detect wheat ears. In conventional image processing, the image is preprocessed, then texture features are extracted, and finally, a classifier, which is trained based on the extracted features, is used for object detection. Zhou et al. extracted and fused three different kinds of features and then trained a twin-support-vector-machine segmentation model to segment the image to find the wheat ears [4]. Fernandez et al. preprocessed the image using Laplacian, median filter, and segmented local peaks to determine the wheat ears [5]. Alharbi et al. preprocessed the raw images, including resizing, normalization, and transformation and then detected wheat ears by utilizing Gabor filter banks and K-means clustering algorithms [6]. Conventional computer vision achieved the detection of wheat ears. However, it relies on handcrafted features. Manually designing features limits the utilization of conventional computer visions.
Deep learning is becoming a dominant tool in computer vision, including Transformers and Convolutional Neural Networks (CNN) [7,8]. Transformer, i.e., a mechanism of self-attention, is becoming an alternative of CNN for object detection. It achieves state-of-the-art results with a very large training dataset [9,10,11,12]. However, in the case of a limited dataset, object detection architectures with CNN perform better. CNN replaces handcrafted feature engineering by automatically learning features from big data. Algorithms based on CNN fall into two categories, i.e., semantic segmentation and object detection. Semantic segmentation marks the presence of an object through pixel-wise masks generated for each object in the image. It labels each pixel in the image with a category label to mark the presence of a wheat ear. The patches containing the wheat ears are positive samples, and the remaining regions in the image are treated as negative samples. Semantic segmentation deep learning neural networks are trained with the annotated dataset. Finally, the trained neural network can segment all the wheat ears pixel-wisely in the input image. Zeljana et al. used CNN architecture to segment wheat ears in images [13]. Ma et al. used a two-stage segmentation method to detect wheat ears in the image, with the coarse segmentation stage classifying super-pixels and the fine segmentation stage eliminating the non-ear pixels [14]. Semantic segmentation has achieved great success in assigning a category label to each pixel in the image, so it is beneficial in detecting diseased areas on the spikes [15]. However, fine segmentation is based on pixel-level annotation, which is trivial and time-consuming. Post-processing is needed because the mask output is not directly related to the number of wheat ears [16]. Moreover, due to the lack of global shape models, semantic segmentation does not perform well in detecting hypotheses of objects in cluttered backgrounds [17].
Object detection is often formulated as predicting object classes and bounding boxes enclosing the objects of interest in the image, which can be divided into two categories, one-stage detector and two-stage detector. Two-stage detector first utilizes a region proposal network to generate regions with a high probability of containing objects in the first stage and then feeds the region proposals down the pipeline for classification and bounding boxes regression in the second stage. Hasan et al. trained region-based CNN to detect and count spike regions in each plot, outputting spike density and classification probability [18]. Madec et al. utilized an object detector based on Faster-RCNN to estimate wheat ear density [19]. Two-stage detectors once took the lead in accuracy but are usually slower because of the complicated pipeline. One-stage detectors are more efficient and elegant with satisfactory accuracy. One-stage detectors often leverage the help of anchors and grid boxes to localize the region and constrain the shapes of the objects, to predict bounding boxes in a single step. There are various network architectures in this category; EfficientDet is a popular one [20]. Wang et al. used an improved EfficientDet-D0 object detection model to identify and count wheat ears [16]. YOLO (You Only Look Once) [21] is another prominent object detection algorithm, which transforms the detection problem into a regression problem. Over time, the network evolved to form a YOLO family, including YOLOv2 [22], YOLOv3 [23], YOLOv4 [24], and other variants. The YOLO family detectors and their improvements are also used for wheat ear detection studies. YOLOv3 was very popular once it was proposed. Gibbs et al. utilized YOLOv3 to detect wheat ears and used the characteristics of the bounding boxes to reconstruct the trajectories of wheat ears in videos [25]. Bhagat et al. used YOLOv3 as the baseline architecture for wheat ear detection, and designed a lightweight network [26]. The backbone was replaced with CSPDarknet53 [27] in YOLOv4, and some features were added [24]. YOLOv4 was declared faster and more accurate. Yang et al. added a convolutional block attention module to YOLOv4 to detect and count wheat ears in the field [28]. YOLOv5 is one of the state-of-the-art object detectors. Zhao et al. added a microscale detection layer and used adapting confidence loss function to make the network achieve better detection accuracy for wheat spike detection [29]. Najafian et al. used an implementation of YOLOv5 architecture to develop a semi-self-supervised learning approach for wheat head detection [30]. It can be concluded that object detectors are playing an increasingly important role in wheat ear detection. Although the methods mentioned above achieved the detection of wheat ears, there are still two types of challenges in wheat ear detection [26]. The first challenge comes from the environment in field conditions, including illuminating conditions leading to disturbing shadows and bright surfaces, wind conditions leading to blurring images, and observational conditions leading to object overlap and shape variation [31]. The second type is wheat inherent challenge, including different shapes and colors because of different genotypes, different tilting directions, and different growth stages. Therefore, even more research on wheat ear detection still needs to be carried out.
The main goal of this work is to improve wheat ear detection performance in images taken under natural field conditions. The main contribution is to introduce three SPP blocks to the Neck of YOLOv4 to extract multi-scale features, thus improving the object detection performance. The improved model performs well compared with state-of-the-art results. The remainder of this paper is organized as follows. Section 2 briefly introduced the materials and the proposed improved method for wheat ear detection. Section 3 provides results and a discussion. Finally, in Section 4, we summarize the research work.
2. Materials and Methods
2.1. YOLOv4 Object Detection Algorithm
YOLOv4 studied bags of tricks and integrated some of them to design an object detector with fast operating speed. YOLOv4 object detector is composed of three parts, i.e., backbone, neck, and head. From a functional point of view, they are called feature extracting network, feature fusion network, and the prediction network.
2.1.1. Feature Extracting Network
Feature extracting network, also referred to as the backbone, plays a key role in object classification and object detection, and highly determines the model’s performance. It encodes the input image into a certain feature representation. In order to mitigate the problem of heavy inference computations, Wang et al. proposed a Cross Stage Partial Network (CSPNet) [27]. CSPNet separates the input feature maps into two parts. One part goes through the following convolutional neural network block and transition layer, and the other part bypasses the mentioned block and transition layer and combines with the transmitted feature map to the next stage. Cross Stage partial connection technique was used on ResNeXt50 [32] and Darknet53 [23], referred to as CSPResNeXt50 and CSPDarknet53, individually. In pursuit of the fastest operation speed of the module, CSPResNeXt50 and CSPDarknet53 were compared on GPU in YOLOv4. Although CSPDarknet53 is not as good as CSPResNeXt50 in terms of object classification, it is better in terms of detecting objects [24]. In order to find the optimal balance among the input network resolution, the convolutional layer number, parameter number, and number of layer outputs, CSPDarknet53 was chosen as the backbone. Additionally, Mish activation function was used on CSPDarknet53.
YOLOv4 takes some measures to modify the backbone further, such as Mish activation function [33] and Dropblock regularization [34]. In the neural network, the weighted sum of the input from previous layers is transformed into output by the activation function, which is usually a nonlinear function. The activation function has a considerable impact on the performance of the model. In the YOLOv4 framework, several activation functions are used to compare the effects, and the Mish function is used for CSPDarknet53. The Mish function is [33]. Dropout is an effective tool to regularize convolutional networks. DropBlock was applied to regularize convolutional networks, where units in a contiguous region of a feature map are dropped together [34].
2.1.2. Feature Fusion Network
Feature Pyramid Network (FPN) is designed to probe feature maps at different spatial resolutions and detect objects at different scales, which is called the neck. In FPN, neighboring feature maps coming from the bottom-up stream and top-down stream are concatenated or added together element-wise in the feature fusion network [35]. The merged information, i.e., spatial information and semantic information are then fed into the head. By using the FPN-like feature pyramid, YOLOv3 makes object detection prediction at different scale levels [23]. Usually, a feature map with higher resolution is merged with an up-sampled feature map using element-wise addition. Then, the result is passed onto convolutional filters to make a set of predictions. In order to shorten the information path from bottom to top and enhance the feature pyramid with accurate localization signals in low levels, a bottom-up path augmentation is created in PANet [36]. YOLOv4 utilized a modified PANet, where feature maps are concatenated instead of adding neighbor layers together.
2.1.3. Prediction Network
The prediction network makes three predictions at each location on 3 feature maps with 3 different scales: encoding bounding box, confidence score, and class probabilities. For COCO [37], the output tensor is for the 4 bounding box offsets, 1 confidence score, and 80 class probabilities, where N is the dimension of the selected feature map. Similar to YOLOv3, YOLOv4 uses anchor boxes to predict bounding boxes. K-means clustering for various values of k is applied on the training set bounding boxes to automatically find anchor boxes. Instead of predicting arbitrary boxes, the prediction network only predicts offsets to the anchor boxes so that the bounding box prediction could focus on specific shapes. As for bounding box location, it predicts location relative to the location coordinate of the grid cell. A confidence score for each bounding box is predicted using logistic regression. The prediction network uses CIoU loss [38] because it considers the overlapping area, the central point’s distance, and the boxes’ aspect ratio. As a result, the convergence speed and accuracy in the regression are outstanding. Moreover, the prediction network takes the DIoU NMS to add the information of the distance between center points on the basis of soft-NMS [38].
2.2. Improved YOLOv4 to Enhance Receptive Field
A large receptive field allows viewing the entire object, viewing the context around the object, and increasing the number of connections between the image point and the final activation [24]. Spatial Pyramid Pooling (SPP) is an effective tool to enhance the receptive field and extract multi-scale features. SPP has long been a critical technique in computer vision before the prevalence of CNNs. Considering SPP has remarkable properties, He et al. used it in the context of CNNs by replacing the pooling layer after the CNN layer with an SPP layer to eliminate the requirement of fixed-size input image [39]. It partitions the image into divisions from finer levers to coarser levers, and combines local features within them. More concretely, it splits the feature maps from the backbone into several d×d blocks, where d can be 1, 2, 3, …. In each spatial bin for the SPP-net, they pool the responses of each filter to obtain a fixed-length representation. The representation would be fed into the fully-connected layers for final object detection. To increase the receptive field and separate context features, a modified SPP block was added over the CSPDarknet53 in YOLOv4 [24]. YOLOv4 inherits the prediction head mechanism of YOLOv3 to predict objects at 3 different scales. In the YOLOv4 framework, 3 convolutional layers are added after the CSPDarknet53 backbone. After that, the SPP module follows with kernel size k×k, where k = 1, 5, 9, 13, with stride 1. The outputs of max-poling in the SPP module are concatenated. Then, PANet structure is used to aggregate the parameters, and the results are fed into YOLO head to predict objects. YOLOv4 adds the SPP module to the lowest-resolution feature map, which has the largest receptive field. Nevertheless, wheat ear sizes are usually small in images and their size varies. In order to detect small-size objects and extract multiscale features with more different size receptive fields, two more SPP modules are added to YOLOv4’s neck part. The improved YOLOv4 network architecture is shown in Figure 1. The backbone adopts CSPDarknet53. The input image first runs through a convolutional layer with the Mish activation function. Then, the output feature maps run through 5 blocks from Resnet, which deepen the network.
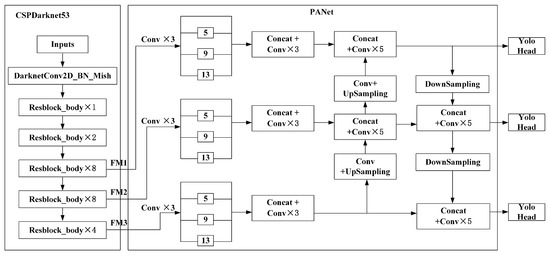
Figure 1.
Improved YOLOv4 neural network architecture.
Three feature maps (FPs) of different scales are extracted from the backbone, which are denoted as FM1, FM2, and FM3, with sizes of 13 × 13, 26 × 26, and 52 × 52. All three feature maps run through 3 convolutional operations before being fed into the SPP blocks. All three SPP blocks have the same kernel size k × k, where k = 1, 5, 9, 13 and the strides of all the SPP blocks equal 1. The max-pooling outputs of each SPP block are concatenated individually to increase the dimension of tensors. More meaningful semantic information is obtained from the up-sampled feature maps and finer-grained information is obtained from earlier feature maps [23] by this method. Three convolutional layers follow to process the concatenated feature maps. Then, the results are fed into the PANet path-aggregation neck, which aggregates parameters from different backbone levels for different detector levels. This improved neck could maintain spatial information and collect feature maps from different stages.
2.3. Evaluation of Model Performance
Some commonly used object detection metrics are calculated to evaluate the performance of the proposed model, including Precision, Recall, and Precision–Recall curve. Precision is the ratio of the number of true positives to the total number of positive predictions, which is defined in Equation (1).
where TP is True Positive number and FP is False Positive number. Recall is the ratio of the number of true positives to the total number of actual objects, and it indicates how many positive cases the model could identify out of all positive cases, which is defined as
where FN is the False Negative number. The predicted bounding box is associated with a confidence score, which assess the probability that the object class appears in the bounding box. By setting a threshold, we can obtain a pair of Precision and Recall values. Because of the trade-off between Precision and Recall, it is unlikely to yield both peak Precision and Recall values at the same confidence threshold value. Commonly, Precision and Recall are combined to make a Precision–Recall curve, where each point in the curve represents Precision and Recall for a certain confidence threshold value. Thus, the Precision–Recall curve provides a model-wide evaluation based on the Precision and Recall. With this curve, Average Precision (AP) is derived. AP is the precision average across all recall values between 0 and 1 at various IoU thresholds. By interpolating across all points, AP can be interpreted as the area under the curve. It serves as a better evaluation of the performance of the model, encapsulating both Precision and Recall. Mean Average Precision (mAP) is an extension of AP, which is defined as the mean of AP across all K classes, expressed in Equation (3). In this case, only one class is interested in the research, so mAP turns out to be AP.
Another important performance metric is the score. It is a weighted average of the Precision and Recall, whose value ranges from 0 to 1, where 1 means the highest accuracy, defined as
Finally, in order to evaluate the performance of detection speed, Frames Per Second (FPS) is calculated. All of these metrics are calculated and compared with the state-of-the-art method. It is believed that these metrics are enough to evaluate the performance of the proposed model.
3. Results and Discussion
3.1. Dataset and Platform
The dataset used to train, validate, and test the wheat ear detection model was derived from [19] and the Global Wheat Head Detection (GWHD) dataset [40]. The dataset in [19], named High-Resolution Ear Density (HRED) in this paper, is more ready to use on intelligent agricultural machinery in field conditions. The camera is fixed at the nadir view direction at a 2.9 m distance to the ground. There are 240 high-resolution RGB images and 30,729 ears in total. The spatial resolution or the Ground Sampling Distance (GSD) is 0.13 mm/pixel. However, when examining the original data, we found some invalid data. Some images needed to be rotated to some degree or flipped to make the labeled bounding boxes match the wheat ears in the images. Some data are not valid at all, no matter how we rotate or flip the images. After removing the invalid data and rotating or flipping the images, there were 25,185 wheat ears in the 222 valid images left. The GWHD dataset contains large and diverse high-resolution images, which were labeled to develop benchmark wheat head detection methods. Since it was created in 2020, it has attracted attention and is very popular.
In this work, all models were trained and tested on a workstation equipped with an Intel Core i9-9900K processor, and NVIDIA GeForce GTX 2080Ti GPU. The operating system was Ubuntu 18.04. The model was implemented with PyTorch machine learning framework in Python programming language. CUDA version is 10.0, and CUDNN version is 7.3.1.
3.2. Model Training
In the training phase, the models were trained for 100 epochs with batch size 4; 10% of the data was used as the validation set. Stochastic gradient descent (SGD) was used to optimize the model. The weight decay was . We set the initial learning rate as 0.001. The curves of loss function values during the training process are shown in Figure 2. The loss value drops dramatically in the initial 20 epochs. After that, the training loss continues to decrease in almost every epoch. The validation loss curve follows the training loss curve closely, which means no overfitting in the training process.
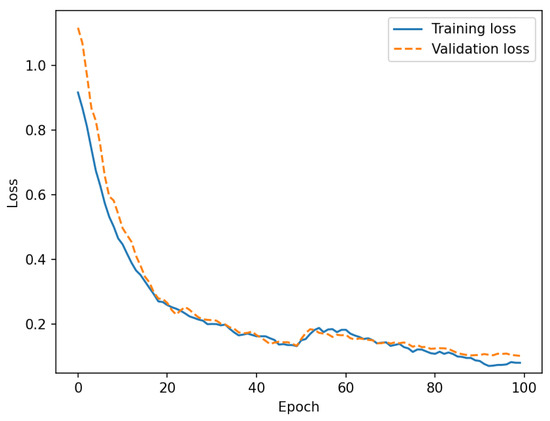
Figure 2.
Loss function value curves of Improved YOLOv4.
Here, 20% of the dataset was set as a test dataset. In order to verify the performance of the proposed model for wheat ear detection, comparative experiments were conducted using the improved YOLOv4, the original YOLOv4 [28] did a good job at wheat ear detection using, i.e., CBAM-YOLOv4. They also used the HRED [19] and GWHD dataset, so results were compared with [28]. The performance evaluation results with these datasets are listed in Table 1 and Table 2. AP is one of the most important metrics for object detection. AP provides a model-wide evaluation considering the trade-off between Precision and Recall. Precision–Recall curves of the two datasets are shown in Figure 3. For the HRED dataset, as can be seen from Figure 3a and Table 1, the AP of the proposed algorithm was 95.16%, which is a remarkable improvement compared with YOLOv4. remained the same as YOLOv4. With the 0.5 score threshold, Precision and Recall were 96.91% and 79.00% for the proposed algorithm, respectively. Precision had a 1.82% improvement compared with YOLOv4. The recall value was slightly smaller than YOLOv4, but the two values were very close. FPS is used to measure detection speed. The FPS of the proposed algorithm was 51.78, which is at the same level as YOLOv4. It is believed the reason for the FPS decline is that the added SPP modules consumed extra computing time. When comparing the results of the proposed algorithm with CBAM-YOLOv4, it can be seen that the AP of the proposed algorithm was 1.24% smaller, and was 0.06 smaller. This demonstrates the benefits of using the attention method. There was no FPS value in CBAM-YOLOv4 provided for this dataset. The detection metrics were also calculated based on the GWHD dataset. Table 2 lists all the evaluation results based on the GWHD dataset. The Precision–Recall curve is shown in Figure 3b. In this case, the proposed algorithm had the highest AP, , and Precision values compared with YOLOv4 and CBAM-YOLOv4, and its superiority is very salient. The FPS of the proposed algorithm had a 0.36 improvement compared with YOLOv4. There is no FPS value in CBAM-YOLOv4 provided. Despite the Recall value of the proposed algorithm being a little smaller than CBAM-YOLOv4, considering the overall performance, it can be concluded that the proposed algorithm works significantly better in the GWHD dataset. Considering the overall performance, it can be concluded that the proposed algorithm is effective for detecting wheat ears.

Table 1.
Performance evaluation result comparison on HRED dataset.
Table 2.
Performance evaluation result comparison with GWHD dataset.
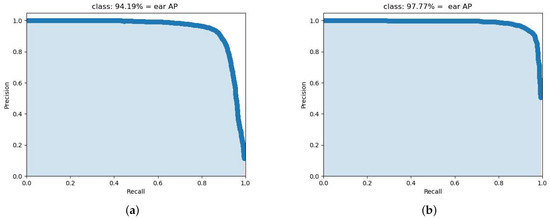
Figure 3.
Precision–Recall curves for 2 datasets. (a) Precision–Recall curve based on HRED dataset. (b) Precision–Recall curve based on GWHD dataset.
Based on the above analysis, it can be concluded that the proposed algorithm achieves state-of-the-art object performance and performs even better in most of the critical evaluation metrics. It demonstrates the effectiveness of the proposed method.
Some detection results are shown as examples in Figure 4. The top two images are from the HRED dataset, and the bottom two are from the GWHD dataset. It can be seen from the figures that most of the wheat ears are detected effectively. The real numbers, i.e., manually counted numbers and detected numbers of wheat ears in the four images, are listed in Table 3. The detected wheat ears are marked using red and yellow boxes. In Figure 4a, 170 objects were detected, 5 failed, and the accuracy was 97.14%. In Figure 4b, 132 objects were detected, 2 failed, and the accuracy was 98.5%. In Figure 4c, 47 objects were detected, 2 failed, and the accuracy was 95.92%. In Figure 4d, 56 objects were detected, 1 failed, and the accuracy was 98.25%. According to the results, few wheat ears were left out. The main reason is that the wheat ear size is very small, the wheat ear density is relatively large in some areas of the images, and there are mutual occlusions between the wheat ears, and between leaf and wheat ear. From the overall detection results of Figure 4, it can be seen that the algorithm shows high detection accuracy in different datasets. The size and position of the prediction boxes match well with the wheat ears. It demonstrates that the proposed algorithm has high robustness in wheat ear detection.

Figure 4.
Detection results of some example images. (a,b) are from HRED dataset. (c,d) are from GWHD dataset.
Table 3.
Detected and real numbers of wheat ears.
The numbers of detected wheat ears and true wheat ears by the proposed algorithm and YOLOv4 are fitted and shown in Figure 5. In Figure 5a, the value is 0.973 and Root Mean Squared error (RMSE) is 4.81. In Figure 5b, the value is 0.954 and RMSE is 6.7. The proposed algorithm works better than YOLOv4. Compared with [28], though RMSE is a little larger, the proposed method has a high . In conclusion, the fitted model by the proposed algorithm provides a strong linear relationship between the detected and real numbers. It implies that the model has a robust ability to detect wheat ears.
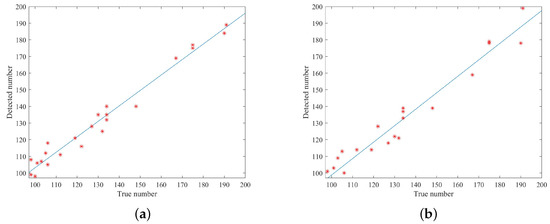
Figure 5.
Fitted results of detected ear numbers versus true ear numbers. (a) Fitted results by the proposed algorithm. (b) Fitted results by YOLOv4.
4. Conclusions
Wheat ear detection provides capital and useful information for crop management and intelligent agriculture machinery. This paper proposed a computer vision model based on deep learning to detect wheat ears. The model is based on YOLOv4. A large receptive field allows viewing of the entire object and the context. Extra SPPs are embedded into the feature fusion network to enhance the receptive field and extract multi-scale features. The improved model is capable of detecting small size objects and overlapped objects. For the first dataset, AP is 95.16% and is 0.87. Precision and Recall are 96.91% and 79.00%, respectively. For the second dataset, AP is 97.96% and is 0.93. Precision and Recall are 96.40% and 79.00%, respectively. We also evaluated the counting performance of the proposed algorithm. value achieves0.973. The results illustrate the effectiveness and superiority of the proposed method. Our feature work will shift to the detection of mature wheat ears. The self-attention mechanism makes Transformers able to embed information globally across the overall image; self-attention would improve the detection accuracy. We are going to incorporate Transformers to extract more features to improve the detection performance.
Author Contributions
Conceptualization, F.Z. and L.X.; methodology, F.Z. and Y.Z.; software, F.Z. and L.L.; validation, L.L. and Y.Z.; formal analysis, L.L.; investigation, L.X.; resources, F.Z.; data curation, F.Z.; writing—original draft preparation, F.Z.; writing—review and editing, F.Z. and L.L.; visualization, F.Z.; supervision, L.X. and L.L.; project administration, L.X. and L.L.; funding acquisition, L.X. and L.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Modern Agriculture-Key and General Program of Jiangsu Province (grant number BE2021339), Industrial Proactive and Key Technology Program of Jiangsu Province (grant number BE2022053-2), Philosophy and Social Science Program of the Higher Education Institutions of Jiangsu Province (grant number 2021SJA0151) and Science and Technology Innovation Foundation for Young Scientists of Nanjing Forestry University (grant number CX2019018).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data in this study are available on request by sending email to zfk@njfu.edu.cn. The data are not publicly available due to data management.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cheng, Z.; Lu, Z. System response modeling of HMCVT for tractors and the comparative research on system identification methods. Comput. Electron. Agric. 2022, 202, 107386. [Google Scholar] [CrossRef]
- Chen, Y.; Cheng, Z.; Qian, Y. Research on Wet Clutch Switching Quality in the Shifting Stage of an Agricultural Tractor Transmission System. Agriculture 2022, 12, 1174. [Google Scholar] [CrossRef]
- Cheng, Z.; Lu, Z. Research on load disturbance based variable speed PID control and a novel denoising method based effect evaluation of HST for agricultural machinery. Agriculture 2021, 11, 960. [Google Scholar] [CrossRef]
- Zhou, C.; Liang, D.; Yang, X.; Yang, H.; Yue, J.; Yang, G. Wheat ears counting in field conditions based on multi-feature optimization and TWSVM. Front. Plant Sci. 2018, 9, 1024. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Gallego, J.A.; Kefauver, S.C.; Gutiérrez, N.A.; Nieto-Taladriz, M.T.; Araus, J.L. Wheat ear counting in-field conditions: High throughput and low-cost approach using RGB images. Plant Methods 2018, 14, 1–12. [Google Scholar] [CrossRef]
- Alharbi, N.; Zhou, J.; Wang, W. Automatic Counting of Wheat Spikes from Wheat Growth Images. In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods, Funchal, Madeira, Portugal, 16–18 January 2018; pp. 346–355. [Google Scholar]
- Zhao, Y.; Ma, J.; Shen, L.; Qian, Y. Optimizing the junction-tree-based reinforcement learning algorithm for network-wide signal coordination. J. Adv. Transp. 2020, 2020, 6489027. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, A. Remaining useful life prediction of rolling bearings using electrostatic monitoring based on two-stage information fusion stochastic filtering. Math. Probl. Eng. 2020, 2020, 2153235. [Google Scholar] [CrossRef]
- Gupta, A.; Narayan, S.; Joseph, K.; Khan, S.; Khan, F.S.; Shah, M. OW-DETR: Open-world detection transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Louisiana, New Orleans, America, 19–23 June 2022; pp. 9235–9244. [Google Scholar]
- Tu, D.; Min, X.; Duan, H.; Guo, G.; Zhai, G.; Shen, W. End-to-End Human-Gaze-Target Detection with Transformers. arXiv 2022, arXiv:2203.10433. [Google Scholar]
- Zhao, Y.; Ukkusuri, S.V.; Lu, J. Multidimensional scaling-based data dimension reduction method for application in short-term traffic flow prediction for urban road network. J. Adv. Transp. 2018, 2018, 3876841. [Google Scholar] [CrossRef]
- Zhao, Y.; Guo, X.; Lu, Y. Semantic-aligned Fusion Transformer for One-shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Louisiana, New Orleans, America, 19–23 June 2022; pp. 7601–7611. [Google Scholar]
- Grbovic, Z.; Panic, M.; Marko, O.; Brdar, S.; Crnojevic, V. Wheat ear detection in RGB and thermal images using deep neural networks. Environments 2019, 11, 13. [Google Scholar]
- Ma, J.; Li, Y.; Du, K.; Zheng, F.; Zhang, L.; Gong, Z.; Jiao, W. Segmenting ears of winter wheat at flowering stage using digital images and deep learning. Comput. Electron. Agric. 2020, 168, 105159. [Google Scholar] [CrossRef]
- Su, W.H.; Zhang, J.; Yang, C.; Page, R.; Szinyei, T.; Hirsch, C.D.; Steffenson, B.J. Automatic evaluation of wheat resistance to fusarium head blight using dual mask-RCNN deep learning frameworks in computer vision. Remote. Sens. 2020, 13, 26. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, Y.; Cui, J. Occlusion robust wheat ear counting algorithm based on deep learning. Front. Plant Sci. 2021, 12, 645899. [Google Scholar] [CrossRef]
- Dong, J.; Chen, Q.; Yan, S.; Yuille, A. Towards unified object detection and semantic segmentation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 299–314. [Google Scholar]
- Hasan, M.M.; Chopin, J.P.; Laga, H.; Miklavcic, S.J. Detection and analysis of wheat spikes using convolutional neural networks. Plant Methods 2018, 14, 1–13. [Google Scholar] [CrossRef]
- Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution RGB imagery using deep learning technique. Agric. For. Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Gibbs, J.A.; Burgess, A.J.; Pound, M.P.; Pridmore, T.P.; Murchie, E.H. Recovering wind-induced plant motion in dense field environments via deep learning and multiple object tracking. Plant Physiol. 2019, 181, 28–42. [Google Scholar] [CrossRef] [PubMed]
- Bhagat, S.; Kokare, M.; Haswani, V.; Hambarde, P.; Kamble, R. WheatNet-lite: A novel light weight network for wheat head detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1332–1341. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid detection and counting of wheat ears in the field using YOLOv4 with attention module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A wheat spike detection method in UAV images based on improved YOLOv5. Remote. Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Najafian, K.; Ghanbari, A.; Stavness, I.; Jin, L.; Shirdel, G.H.; Maleki, F. A semi-self-supervised learning approach for wheat head detection using extremely small number of labeled samples. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1342–1351. [Google Scholar]
- Fernandez-Gallego, J.A.; Buchaillot, M.L.; Aparicio Gutiérrez, N.; Nieto-Taladriz, M.T.; Araus, J.L.; Kefauver, S.C. Automatic wheat ear counting using thermal imagery. Remote. Sens. 2019, 11, 751. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer -Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- David, E.; Serouart, M.; Smith, D.; Madec, S.; Velumani, K.; Liu, S.; Wang, X.; Pinto, F.; Shafiee, S.; Tahir, I.S.; et al. Global wheat head detection 2021: An improved dataset for benchmarking wheat head detection methods. Plant Phenomics 2021, 2021, 846158. [Google Scholar] [CrossRef] [PubMed]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).