1. Introduction
Recently, high-resolution (HR) satellite images have become important in many applications [
1], including building extraction, environmental disaster assessment, small object detection, and urban planning. However, because of high costs of hardware and limitations of current technology, the observed HR images usually have incomplete spatial and temporal coverage. Moreover, the resolution does not satisfy the required standard, making them unable to meet the gradually-growing applications and demand of the general public, which has caused a negative impact on the accuracy of subsequent computer vision tasks. As we know, super-resolution (SR) technology on images provides an effective and low-cost approach of reconstructing HR images from easily available and relatively low-resolution (LR) images. Thus, this paper mainly focuses on how to generate high-quality HR satellite images in a cost-effective direction.
In recent years, SR models based on Generative Adversarial Networks (GANs) [
2], such as Super Resolution GAN (SRGAN) [
3] and Enhanced Super Resolution GAN (ESRGAN) [
4] have been proposed and also have promising performance in enhancing noiseless or noisy LR images. The above models consist of generators and discriminators. Both sub-networks are composed of deep convolutional neural networks (CNNs). The dataset which contains LR and HR image pairs is required to train the model. Then the generator produces the HR image from an input (LR) image, and the discriminator decides if the generated image is just an enlarged LR image or a real HR image. After training with sufficient data and time, the generator is able to output synthetic (fake) HR images which are supposed to be similar to real HR images, while the discriminator is not capable of distinguishing between fake and true images.
The satellite imagery covers a wide area, including various ground scenes. In addition, the resolution of satellite images is much lower than general images, and it is also susceptible to several effects such as ultra-telephoto imaging, atmospheric disturbances, and equipment noise. This further increases the difficulty on the edge restoration with details and sharpness from LR input images. Therefore, the conspicuous outline of the ground target is more worth pursuing than the actual texture details inside the object. In the past few years, various shallow and deep learning-based reconstruction methods have been proposed to improve the resolution of satellite images. Especially, the residual learning strategy is applied to build a deeper CNN for computer vision tasks and makes the results amazing. For the image SR problem, these methods aim to predict the residual image (relative to the input image) rather than the target HR image, and the methods based on residual learning and their variants have been proven effective. Although the image generated looks very realistic, the image content is excessively eroded due to the global optimization strategy. As a result, the SR image may be inconsistent with the actual HR image and a large number of false or smooth edges may appear.
We are inspired by the EEGAN [
5] and EESRGAN [
6] and use EEGAN as the basic framework to propose a feasible infrastructure. For the two sub-networks in the generator, a combination of residual-in-residual dense block and two-dimensional topology (i.e., 2D-RRDB) is used. Compared with the conventional RRDB [
4], this 2D architecture with additional diagonal connections can lead to better gradient optimization on the links between different routes and provide more possibilities for information conversion. In other words, more connected paths can be obtained using the same number of layers through the diagonal links. That means by increasing the density of dense blocks connection over the traditional 1D infrastructure, we can effectively overcome the information propagation disappearance, gradient disappearance and training difficulty problems caused by increasing the layer depth.
Moreover, in the light of the use of the same approach to compute the perceptual loss for the entire image (e.g., we use the same features on the foreground, background, and edges), the proposed model needs to include new losses and learn the information for smaller features (e.g., the texture of the building). We use the feature map before the activation layer of VGG19 [
7] to compute both the perceptual loss and edge perceptual loss, which can assist in generating more visually consistent results and sharper edges. Moreover, since satellite images usually cause more noise than ordinary images, the Canny algorithm [
8] is required to be used for edge extraction to help the generator create distinguishable and clearer edge maps. In the end, we used several popular and publicly available datasets for training and testing, and compared the results with other state-of-the-art SR models. We not only consider PSNR but also look for several evaluation indices to evaluate the performance. As a result, we learned that our model can generate satellite images which look more natural and visually close to real images.
The paper is an extension of our previous work in [
9]. Compared to the original work, we add the following substantive new contents. First, we describe related works to this topic in
Section 2, including a review of existing methods on image super-resolution, an introduction of Generative Adversarial Network (GAN), edge detection algorithms, and perceptual loss. Furthermore, in
Section 3.1 and
Section 3.4, we perform a thorough ablation study on two sub-networks (UDSN, EESN) of the generator, edge detection algorithms, and loss functions to compare the performances. Moreover, in
Section 4, we conduct more experiments on two additional data sets, including WHU-RS19 and SpaceWill data sets to prove the robustness of the proposed approach.
The rest of paper is organized as follows. In
Section 2, we give an introduction of image super-resolution and review some existing state-of-the-art SR methods and several possible techniques that could be used to improve the SR performance. Then we describe the proposed approach in
Section 3, including the modifications in two sub-networks in the generator, edge extraction module, and perceptual loss on edges.
Section 4 shows the experimental results and discusses the performance comparison on several publicly available satellite image data sets. Finally, we draw the conclusions in
Section 5.
2. Related Works
Deep learning (e.g., CNN) [
10,
11,
12,
13,
14] has been widely used in image SR reconstruction, and the SR performance has been significantly improved due to the powerful function of deep neural networks. Therefore, we focus on exploring deep neural network methods to solve SR problems.
2.1. Image SR
CNN is widely used in image SR, and the early image SR model was proposed by Dong et al. [
15]. They use CNNs to achieve the end-to-end mapping between LR and HR images. Then Shi et al. improved the previous SRCNN and proposed FSRCNN [
16], which does not need to enlarge the image size outside the network. By adding a shrinkage layer and an expansion layer on the network, some small layers can be used to replace a large layer at the same time, and FSRCNN has a greater speed increase than SRCNN. Inspired by this work, other researchers proposed to adopt other deep learning architectures, such as RNN, Residual CNNs [
12] and GANs [
2] to solve single image super-resolution (SISR). Among them, Ledig et al. [
3] introduced an architecture “SRResNet” inspired by ResNet [
17], which preserves the batch normalization within the original residual block. This makes their model significantly reduce memory and allow adaptation to several ideas introduced for image deblurring. Similarly, Lim et al. [
12] proposed their EDSR (Enhanced Depth Super Resolution) model. This model effectively reduces the memory space by removing the batch normalization (BN) layer in the residual block in SRResNet, and uses this space to expand the size of the model, thereby achieving significant performance improvements.
Because of the specialty (e.g., the large size of spatial dimension) of satellite images, some SR methods are specifically developed for satellite images. In [
18], Kawulok et al. indicate the characteristics of training data have a large impact on the accuracy of a reconstructed image. In [
19], Shermeyer et al. investigate the application of SR techniques to satellite images and the effects on object detection performance. Wei et al. [
20] employ a deep segmented residual CNN approach to analyze the SR performance of a single satellite image. Rout et al. [
21] report considerable improvements in SR of remote sensing imagery are achieved by using supervised models in a reinforcement learning framework. In [
22], Zhu et al. claimed using a simple down-sampling approach with a fixed kernel to create training images works fine on synthetic data, but does not perform well on real satellite images. In addition, some examples for recent SR methods based on CNN and Generative Adversarial Network (GAN) are [
23,
24], respectively. Recently, Tewari et al. [
25] introduced a unique loss function and a new image reconstruction method to enable the SR model to be executed on a low-power device for satellite environments.
2.2. GAN Methods for Image SR
GAN [
2] is a deep learning model which is composed of two networks. One is the Discriminating Network and the other is the Generative Network. Inspired by GAN, researchers have conducted active research on it. Recently, some effective and practical techniques have been applied to low-level computer vision tasks, including image SR [
26]. For instance, Ledig et al. [
3] proposed a realistic single-image SR using GAN (SRGAN), which uses adversarial loss to push the reconstruction result to the natural image. Wang et al. [
4] improved the generator on the basis of SRGAN, and the RRDB network architecture is proposed. The BN layer is removed from the architecture, and the idea of relativity GAN is borrowed to let the discriminator predict the authenticity of the image instead of “whether it is a fake image”. Finally, the perceived loss is also improved. These improvements have brought better visual quality and more realistic and natural textures. Jiang et al. [
5] proposed an Edge Enhanced Network (i.e., EEGAN) architecture based on GAN. This method is used to provide robust satellite image SR reconstruction and an adversarial learning strategy that is insensitive to noise. This method retains enough edge information to bring better results to the final SR image.
2.3. Edge Detection and Extraction
Edge detection is a very important image feature extraction method in the area of computer vision, and it is also relatively easy to use. We use edge detection to find a set of pixels in the image that significantly change the brightness of the pixels. The edge extraction itself is a filtering process, using different operation elements to extract different features. Each type of operand has its own characteristics. There are generally three traditional methods: Sobel operator [
27,
28], Laplacian operator [
27,
28] and Canny operator [
8].
Sobel Operator
In target detection, Sobel operator has a better effect on image processing with more gray gradient and noise, but it is not very accurate in edge positioning (i.e., the edge of the image is more than one pixel). Therefore, the accuracy of Sobel operator is not very high.
Laplacian Operator
Since the Laplacian method is more sensitive to noise, it is rarely used to detect edges. However, it is used to determine whether edge pixels are regarded as bright or dark areas of the image. The Laplacian is the second derivative operand, which will produce steep zero crossings at the edges. Laplacian operands are isotropic and can sharpen borders and lines in any direction.
Canny Operator
The best things about Canny edge detection algorithms are: (1) Detecting edges with a low error rate, which means capturing as many edges as possible in the image and as accurately as possible. (2) The detected edge should be accurately positioned at the center of the true edge. (3) A given edge in the image should be marked only once, and the noise of the image should not produce false edges wherever possible.
2.4. Perceptual Loss
The perceptual loss function is usually used to convert images among various styles. The success of the style transfer algorithm lies in the field of image generation. A very important idea has emerged here, that is, the features extracted by the CNN can be used as part of the loss function, and the image generated by a certain layer of pretrained networks can be compared. The feature map obtained from the specific layer of the network makes the semantics in the generated image and the target image more similar. The network is divided into two types: transform network and loss network. The transform network is used to convert the image, and its parameters changed, while the loss network keeps the parameters unchanged. The transformed result map, style map and content map are passed through the loss network to obtain the feature map of each layer and we can use it to calculate the loss.
General style transfer uses both style loss and content loss. As the name suggests, style loss is used to change the style of the input image, while content loss is used to preserve the content of the image. The difference between the perceptual loss functions of super-resolution and style transfer is that the SR only needs content loss. Recently, SR methods aimed at improving visual quality and added this perceptual loss function. The generated image after adding perceptual loss function is much clearer than the image generated by using only the L1 (Manhattan norm) or L2 (Euclidean norm) loss function. We add the perceptual loss function to our SR method, and find a set of results that are more in line with human vision through different parameter adjustments.
To summarize, the main contributions and advantages of our proposed approach in this work are:
We incorporate the 2D topology into RRDB for both sub-networks in the generator to obtain extra diagonal connections to achieve better gradient optimizations among different paths to prevent the gradient vanishing and training difficulty problems.
We try different edge detection algorithms and choose Canny approach to replace original Laplacian method to get more detailed and clear edge information.
The new loss function (e.g., edge perceptual loss) is added into original loss function and different weighting combinations are conducted to obtain the best SR result.
Through extensive experiments on four well-known and publicly available satellite image databases, we evaluate all compared SR models with five objective image quality metrics to show the proposed approach is able to generate SR images with better visual quality and more close to the true image.
3. Materials and Methods
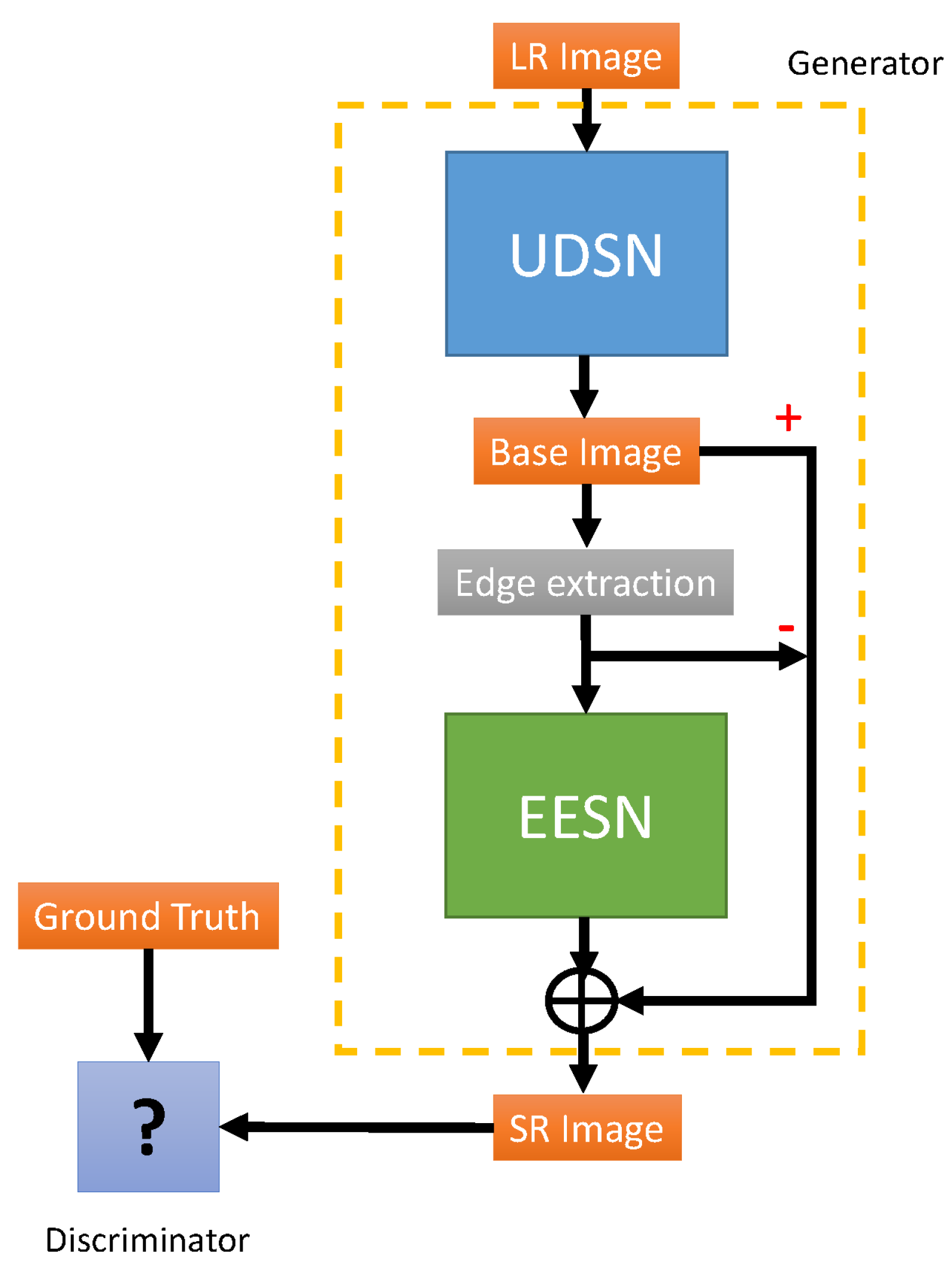
For our proposed approach, EEGAN [
5] is adopted as the basic framework and some modifications are made based on it. As shown in
Figure 1, we can divide the generator G into two sub-networks: ultra-dense subnet (UDSN) and edge-enhanced subnet (EESN). The UDSN is made up of several dense blocks and a reconstruction layer which can be used to generate intermediate HR image, while the EESN is used to enhance the edges extracted from the intermediate SR image by removing artifacts and noise. Then, the clean edges from EESN will replace the noisy edges in the intermediate SR image and output the final SR image. A perceptual loss function is tried to be added into the model to enhance visual quality [
29,
30,
31]. We find a set of parameters that can achieve better performance through the process of parameter adjustments in conducted experiments. The obtained HR images are also compared with the ones generated by other SR models. We will describe more details in the following subsections.
3.1. Generator Networks
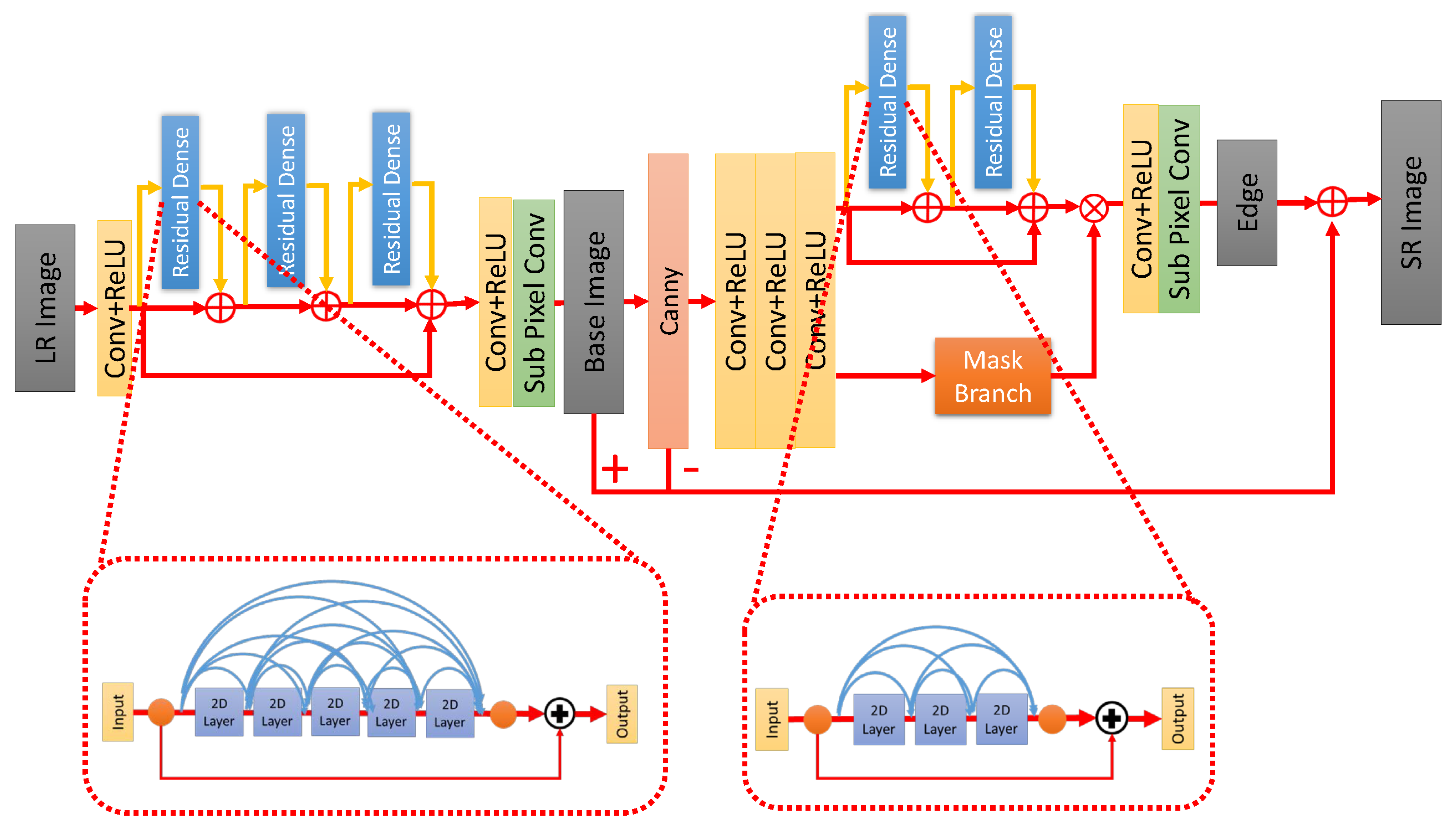
As shown in
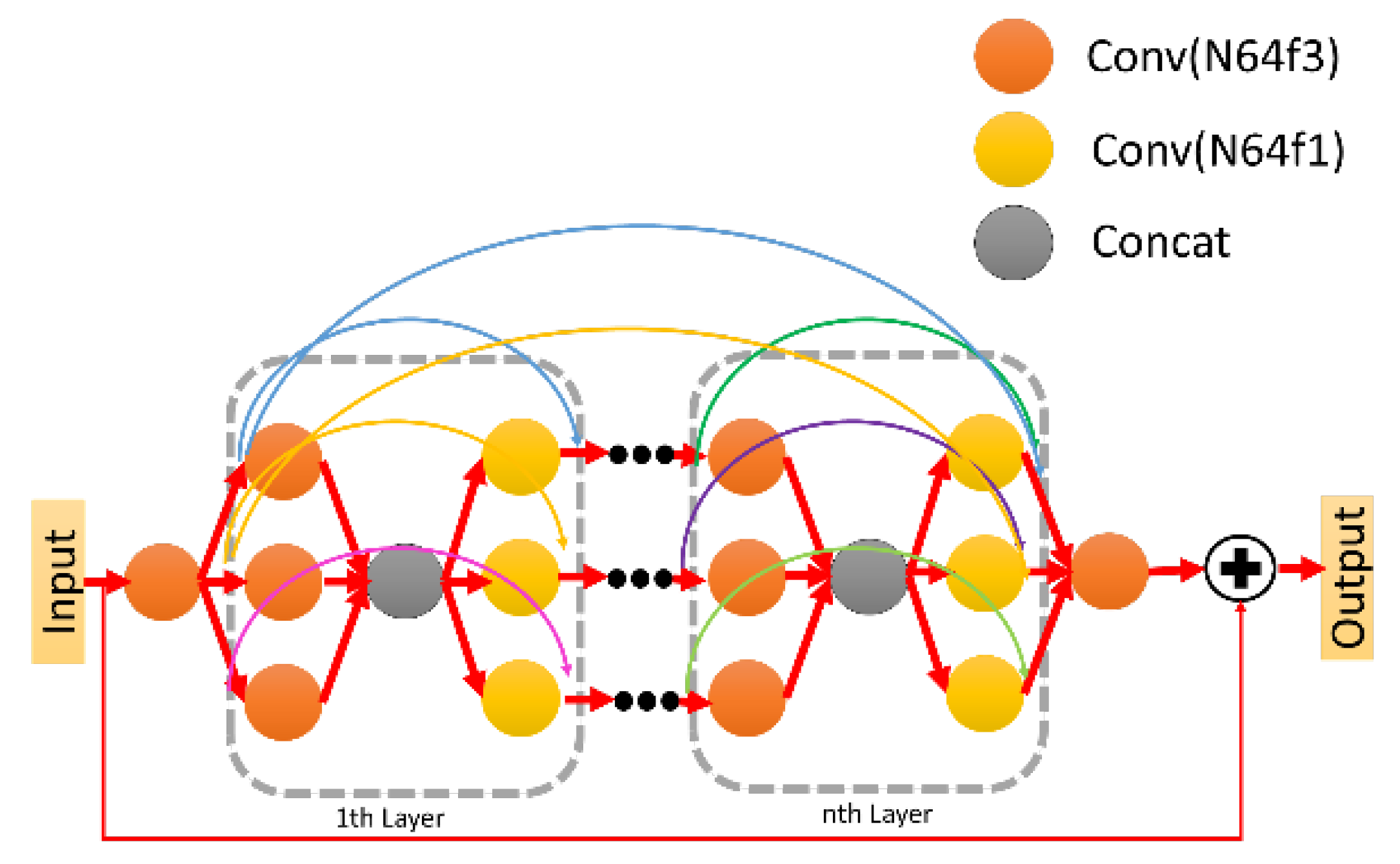
Figure 2, the UDSN is first modified to generate intermediate HR images, and then the dense subnet branch of the EESN is also modified. Regarding the UDSN, we replace the original dense block [
32] with two different blocks (i.e., residual dense block (RDB) and RRDB), and use two different convolution topologies (i.e., original one-dimensional and new two-dimensional (2D) topology [
5] in the convolutional layers, which is shown in
Figure 3) as the choice. Through the extensive experiments, we list the best results for each of the above four combinations, as shown in
Table 1. We can see it will have the best PSNR and FSIM results when the block type is RRDB with 2D-topology and the number of blocks is 3, while the number of convolutional layers in each block is 5. This means to modify the generator network architecture will output SR images that are more close to real HR images.
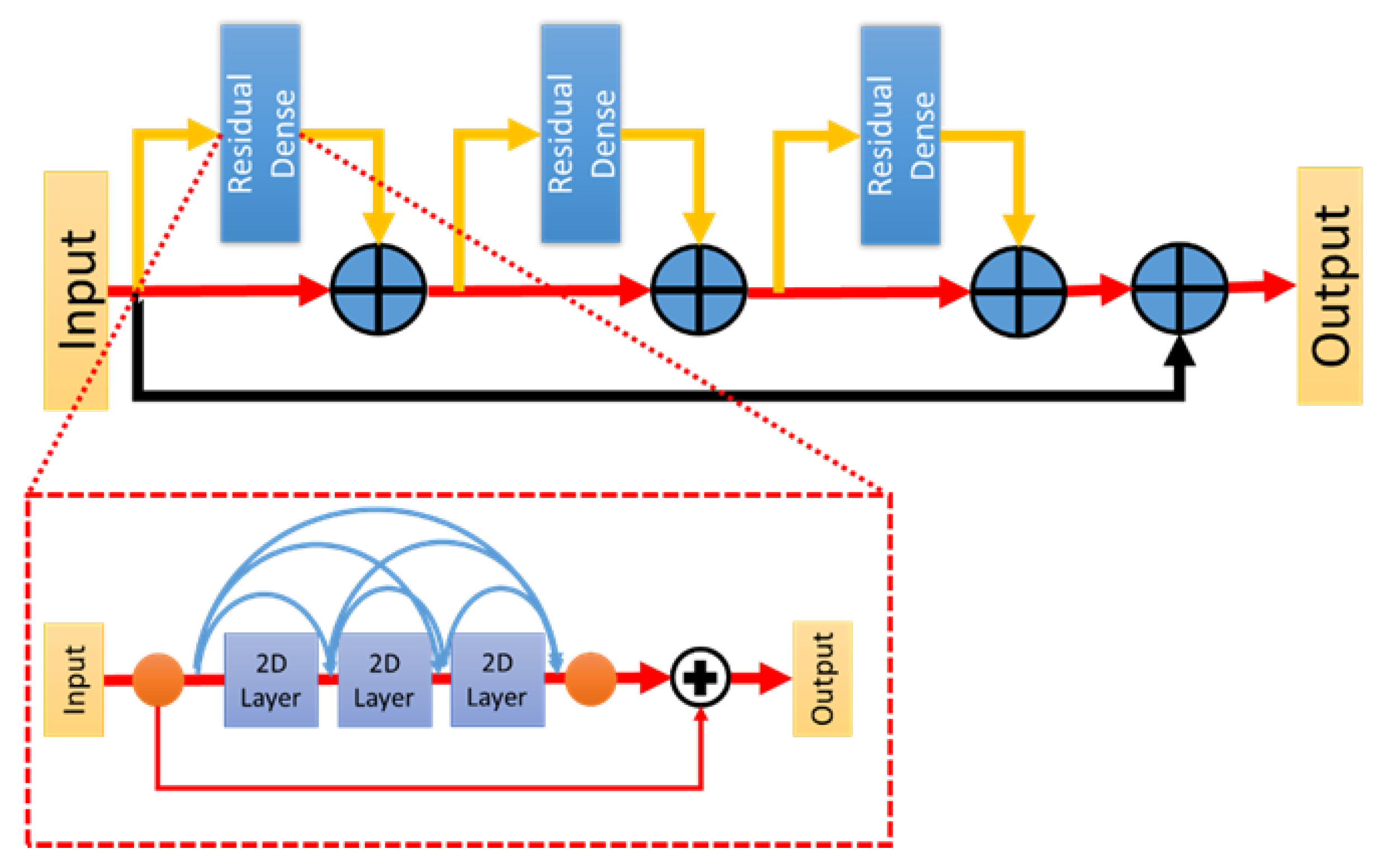
Then we use convolutional layers with 2D topology to replace the original convolution layers in the adopted RDB for the dense network branch of the EESN, as shown in
Figure 4. We hope that the EESN can generate useful edge features through this network architecture. In
Table 2, we test four different combinations for block types (RDB, RRDB) and convolution topologies (1D, 2D). We can find the model will have the best PSNR and SSIM values when the block type is RRDB with 2D-topology and the number of blocks is 2, while the number of convolutional layers in each block is 3.
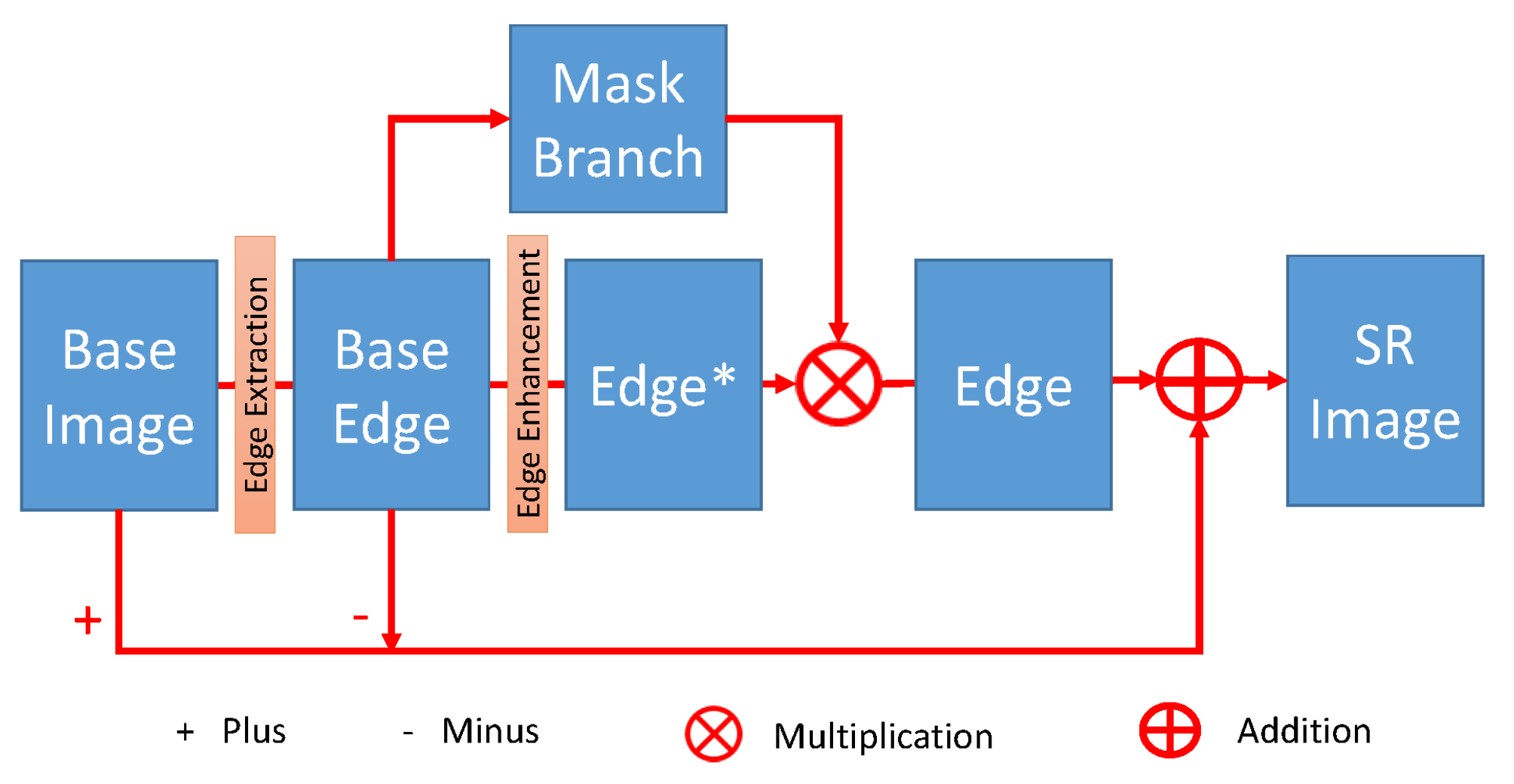
3.2. Edge Enhancement
In this part, we will investigate different edge extraction algorithms used in the EESN of the generator network. Through experiments, better edge extraction algorithms are found by comparing their effects. The results are shown in
Table 3. Furthermore, we adopt the Mask Branch in EEGAN [
5] to suppress false edges and noise.
Figure 5 shows the details of this operation. First, we use the intermediate SR image generated by the UDSN as an input (i.e., Base Image in
Figure 5), and a Base Edge image is obtained through the edge extraction method, and then it is fed to two sub-networks (i.e., edge enhancement and mask branch) separately. The outputs of these two sub-networks eventually combine (via multiplication) to produce the image with sharper edges. Then, the sharper edges (Edge in
Figure 5) will replace the noisy edges (Base Edge in
Figure 5) in the intermediate SR image and output the final SR image. In the conducted experiments, we try the Sobel and Canny methods [
33]. In consequence, we find that Canny method can generate the final SR image with better performance among the three compared algorithms.
3.3. Loss Functions
At first, we create a content loss function to force the generator G to output the intermediate HR image that is supposed to be similar to the real HR image by the equation below:
where
represents a set of model parameters in the generator,
represents the Charbonnier penalty function [
10]. As the same as [
10], the compensation parameter is set to
,
and
denote the real HR image and the intermediate HR image generated by the UDSN.
To reduce artifacts and enhance the quality of the reconstructed image, we included the pixel-based Charbonnier loss to improve the consistency of the image content between the real and generated HR images. The consistency loss function is denoted as:
where
is the model parameter set as the same as mentioned before,
and
refer to the real HR image and the final SR image.
Then,
and
are both input into the discriminator to determine the authenticity of
. Moreover, the discriminator is trained to minimize the adversarial loss, which can force the generator to output the reconstructed image
as similar as the real HR image. The adversarial loss can be written as:
where
refers to the model parameters in the discriminator,
represents the input LR image,
represents the generator function, and
is the discriminator function to compute the probability of being the generated HR image or real HR image. In the discriminator, the generated image is expected to be classified as 0, and the real image is expected to be classified as 1. If the discriminator can correctly decide whether this is a real or generated image, then the Equation (
3) will output 0, which is the smallest value. For the generator, it is expected to confuse the discriminator to make it unable to distinguish between the real image and generated image, and classify the generated image as 1.
Furthermore, we included the edge image consistency loss function, as shown in Equation (
4), where
is the edge image of the real HR image, and
is the edge image of the generated SR image. As we know, the image consistency loss
in Equation (
2) helps to obtain an output with good edge information, but the edges for some objects in the image are distorted and have produced noise. Therefore, we incorporate this loss to resolve this issue. The weighting coefficient of this loss is chosen to be the same as
.
Equation (
5) shows the perceptual loss [
34], and we incorporated the edge perceptual loss function described in Equation (
6). The feature map (
) before the activation layer of the fine-tuned VGG19 [
7] network are adopted to compute the perceptual loss and the edge perceptual loss as follows:
where
represents the intermediate SR image,
is the real HR image,
is the edge map of the intermediate SR image,
is the edge map of the real HR image, and
E denotes the calculation of mean value for the difference of feature maps.
3.4. Ablation Study
To prove the feasibility of the proposed model, we conducted ablation experiments using different UDSN and EESN networks, different edge extraction methods, and adding other different loss functions. In all the ablation experiments, we used the pre-processed Kaggle data set and randomly selected 4000 images (72% training, 8% validation, and 20% testing) to conduct experiments.
As shown in
Table 4, we can see that the network architecture using RRDB with two-dimensional topology convolution has significantly improved the output results. By extensive ablation experiments, we discover that for the UDSN, using the 2D-topology RRDB has the best results, where the number of residual dense blocks (RDBs) in the RRDB is 3, while the number of convolutional layers in each RDB is 5 and they are all connected in 2D-topology. For the EESN, it still shows using the 2D topology convolutional layers in the RRDB brings the best SR performance. However, the number of RDBs in the RRDB becomes 2, and the number of convolutional layers in each RDB is 3. The final decided architecture for the generator is shown in
Figure 2.
Next, through experiments by using different edge extraction approaches, it is found that using Canny edge extraction (PSNR: 33.011 dB, SSIM: 0.918) method can bring better performance to the SR results than the Sobel (PSNR: 32.950 dB, SSIM: 0.906) and Laplacian (PSNR: 32.947 dB, SSIM: 0.913) methods. Finally, we sequentially add different loss functions to the original loss function. It is found that adding these losses into the model will yield a better performance for the final output SR image. The best performance happens when we add , , and into the original loss function.
Therefore, the final loss function is decided from the ablation experiments in
Table 4 and shown in Equation (
8), where we combine
and
into
, as in Equation (
7). Based on the previous experiment experience, we set
,
.
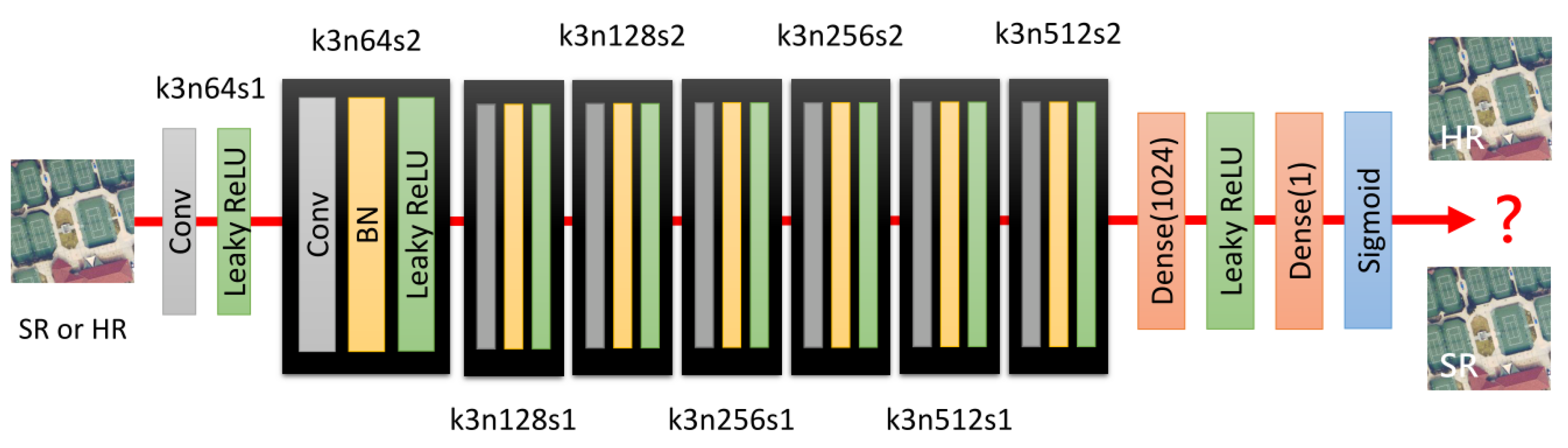
3.5. Discriminator Networks
The standard GAN is used to calculate the probability whether the image is true or fake. To be able to distinguish which images are real and which are generated, we trained a discriminator network. The architecture of the discriminator is depicted in
Figure 6, which contains eight convolutional layers. A batch normalization (BN) layer follows all convolutional layers, except for the first convolutional layer. Like the VGG network, the number of channels of the convolutional layer doubles from 64 to 128, and then 128 to 256, and finally 256 to 512. The stride size of the first, third, fifth, and seventh convolutional layers is set to 2, while the stride size of the remaining convolutional layers is set to 1. Moreover, the stride convolution and LeakyReLU activation (
) function are used rather than the maximum pooling layer. The main advantage of using stride convolution is to reduce the size of features. At the end of the network, two dense layers and a sigmoid activation function are followed to calculate the probability that the image is authentic.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}