Abstract
Accurate prediction of material defects from the given images will avoid the major cause in industrial applications. In this work, a Support Vector Regression (SVR) model has been developed from the given Gray Level Co-occurrence Matrix (GLCM) features extracted from Magnetic Flux Leakage (MFL) images wherein the length, depth, and width of the images are considered response values from the given features data set, and a percentage of data has been considered for testing the SVR model. Four parameters like Kernel function, solver type, and validation scheme, and its value and % of testing data that affect the SVR model’s performance are considered to select the best SVR model. Six different kernel functions, and three different kinds of solvers are considered as two validation schemes, and 10% to 30% of the testing data set of different levels of the above parameters. The prediction accuracy of the SVR model is considered by simultaneously minimizing prediction measures of both Root Mean Square Error (RMSE), and Mean Absolute Error (MAE) and maximizing values. The Moth Flame Optimization (MFO) algorithm has been implemented to select the best SVR model and its four parameters based on the above conflict three prediction measures by converting multi-objectives into a single object using the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) method. The performance of the MFO algorithm is compared statistically with the Dragon Fly Optimization Algorithm (DFO) and Particle Swarm Optimization Algorithm (PSO).
Keywords:
SVR; performance measures; kernel functions; MFO; DFO; PSO; diversity and spacing; magnetic flux leakage (MFL) 1. Introduction
Non-Destructive Testing (NDT) is a breakthrough in the industrial sector in the field of testing. Different components used in the industry need to be checked thoroughly for safety and better operability. Critical components such as SGTs and heater’s pressure values will be tested multiple times for their structural integrity to avoid damage while functioning; electromagnetic testing is also very useful in identifying the cracks in the SGTs and pipes. Daniel et al. [1] developed an ANN model to predict the SGT’s defect in terms of the length, width, and depth of crack from the given gray level co-occurrence matrix features from the Magnetic Flux Leakage (MFL) image. The structural integrity of the engineering components is increasingly very important in the modern scenario because of safety reasons. Usually, defects in steel pipes are cracks that might be in the surface or sub-surface; identifying any kind of such cracks and timely solving the issues will avoid a big disaster [2]. In NDT, different testing methods are available for each type of component or specimen needed to test. Normally, the NDT method will be determined based on the component/specimen size, shape, material, and conductivity of the material to be tested and the application capabilities of NDT techniques, including Visual Testing (VT), Ultrasonic Testing (UT), thermography, Radiographic Testing (RT), Electromagnetic Testing (ET), Acoustic Emission (AE), and shearography testing in terms of the benefits and drawbacks of these techniques. Based on their inherent qualities and applicability, further approaches are categorized. Most of the time, an NDT assessor simply employs one non-destructive test technique. Basic testing in NDT can be done with the expertise of individuals, but complex NDT testing requires experts with a wide knowledge of equipment operation and computer skills to obtain accurate results [3].
Material defects play a vital role in the industry, as they create major issues in the operation and safety of equipment and components. Material defects in the components and equipment can be inspected in two ways, like quality checking after manufacturing and on-site inspections during operations. Usually, most of the industry uses steel for the manufacturing of various equipment and components with different compositions, and steel will normally have defects like porosity, corrosion, pits, surface cracks, and sub-surface cracks, etc.; usually defects like corrosion, porosity, pits, and surface cracks can be manually identified with general NDT methods. The evaluation of the fracture area and the earlier identification of the cracks are particularly crucial, and those that are under stress or strain should be monitored regularly. Fatigue cracks or other pre-existing cracks may cause unexpected failure or disaster. Magnetic testing techniques produce good results in ferromagnetic materials and are extremely efficient for all components [4]. However, sub-surface cracks are difficult to find with the naked eye, and complex NDT methods should be used.
As a powerful and highly efficient non-destructive testing (NDT) method, magnetic flux leakage (MFL) testing is conducted based on the physical phenomenon that a ferromagnetic specimen in a certain magnetization state will produce magnetic flux leakage if any discontinuities are present in it. In the era of modern non-destructive testing, methods like magnetic flux leakage (MFL) testing have distinct benefits over conventional inspection techniques, including quicker inspection speeds, deeper examination depths, and simpler automated inspection. As a result, MFL testing is widely used in industries to evaluate ferromagnetic materials [5]. The specimen used during MFL experimental investigations of inner flaws or sub-surface fractures is often built with flaws that prevent the presentation of inner flaws of the same size but differing buried depths. A specimen with identical-sized interior flaws is conceived, built, and evaluated to study the MFL course of these defects. Identifying the sub-surface cracks also involves the simple magnetization of the material and obtaining the flux leakage output by using a hall sensor [6]. The periodic checking and verification of sub-surface cracks in critical areas may avoid drastic incidents. Magnetic flux testing (MFL) techniques are required in the inspection of steel tubes and pipes in the petrochemical industry, rope cars, nuclear reactor tubes, etc.
Ege and Coramik et al. [7] designed and produced two different PIGs to inspect pipelines using the flux leakage method. The authors also developed a new magnetic measurement system to investigate the effect of the speed variation of the produced PIGS. Shi et al. [8] introduced the principle, measuring methods, and quantitative analysis of the MFL method. The authors used statistical identification methods to establish the relationship between the defect shape parameter and magnetic flux leakage signals. Suresh et al. [9] developed a bobbin coil magnetizer arrangement to inspect the defects in small-diameter tubes and used an ANSYS Maxwell EM V-16-based Finite Element Method (FEM) and analytical model to support the experimental results.
For improving model accuracy, recently support vector regression (SVR), a machine learning tool, has gained focus among researchers in various fields to minimize prediction error. Jin et al. [10] proposed an internal crack-defect-detection method based on the relief algorithm and Adaboost-SVM, to overcome the problems of poor generalization and low accuracy in the existing defect detection process. Zhang et al. [11] developed an SVR regression model to forecast the stock price by optimizing the SVR parameters using dynamic adjustment and the opposition-based chaotic strategy in the Firefly Algorithm (FFA), termed the Modified Firefly Algorithm (MFFA). Kari et al. [12] implemented the SVR model with a Genetic Algorithm (GA) technique to forecast the dissolved gas content in power transformers to maintain the safety of the power system. Houssein et al. [13] used a twin support vector regression model to forecast the wind speed by tuning the SVR parameters by implementing the Particle Swarm Optimization (PSO) algorithm. Li et al. [14] presented a novel Sine Cosine Algorithm–SVR model to select the penalty and kernel function of SVR and validated the effectiveness by solving benchmark datasets. Yuvan et al. [15] introduced the GA–SVR model in forecasting sales volume to achieve better forecasting accuracy and performance than traditional SVR and Artificial Neural Network (ANN) prediction models. Pappadimitriou et al. [16] investigated the efficiency of the SVM forecasting model for the next-day directional change of electricity prices and reported 76.12% forecast accuracy over a 200-day period. Several other applications of SVR models exist in literature, ranging from process parameter prediction [17,18] to flow estimation [19] and from 3D-printing applications [20] to battery monitoring [21].
From the literature, it is understood that the SVR model, a machine learning tool, has been used by researchers in different areas like stock-market prediction, electricity prices, dissolved gas content, wind speed, etc. In this work, the SVR model is to be developed to predict the SGT’s defect in terms of length, width, and depth of cracks from the given gray level co-occurrence matrix feature from the Magnetic Flux Leakage (MFL) image. The selection of parameters, such as kernel function, solver type, and validation scheme, along with % of test data, will affect the performance of the SVR models. The root means square error, mean absolute error, and values are considered to measure the performance of the SVR model. Multiple contradictory performance measures require the conversion of multi-objectives into a single objective that initiated the implementation of the TOPSIS method. The Moth Flame Optimization Algorithm (MFO) is proposed to select the optimal parameters of SVR to minimize the prediction error. The effectiveness of the MFO algorithm is proven by comparing its performance with the Dragon Fly Optimization (DFO) and Particle Swarm Optimization (PSO) algorithms.
The paper is organized as follows. Section 2 describes the proposed methodology, SVR models, and MFO algorithm, along with its pseudocode and implementation. Section 3 deals with the results and discussion with a quantitative comparison of the performance of the MFO algorithm with the DFO and PSO algorithms. Finally, the conclusion part of the paper is given with future scope.
2. Machine Learning Methods
This paper proposes establishing a support vector regression model to predict the length, depth, and width of the given features of a crack image. The feature data set developed by Daniel et al. [1] is considered in this work to establish a more accurate SVR model compared to the neural network model. The data set had 22 features extracted from the 105 crack images with different lengths, depths, and widths. The model’s performance by different factors, such as kernel function, solver type, validation method and its parameters, and % of testing data set to validate the model are considered in this work. Built-in functions, such as ‘fitrsvm’ and ‘predict’, available in MATLAB 2022a version, have been used in this work to fit and predict the response value for the given training data set. The ‘resume’ function has been used to further train the SVR model until it reaches convergence status. Various performance measures are available; RMSE, MAE, and are considered in this work, MAE and are considered most often in literature and expressed in Equations (1)–(3). The above three performance measures will be calculated for the total data set, training data set, and testing data set separately and be considered for developing an optimized SVR model. Simultaneously minimizing both the values of RMSE and MAE and maximizing the values are taken as conflicting objectives, and a total of nine performance measures are involved; hence, the TOPSIS method is proposed in this work to convert these multi-objectives into a single objective using closeness values. Equations (4)–(9) are used to calculate the normalized value, performance matrix, the positive and negative ideal solution, ideal and negative ideal separation value, and closeness values, respectively. Figure 1 illustrates the proposed methodology of this work.
where, and
Minimization:
Maximization:

Figure 1.
Proposed methodology.
Figure 1.
Proposed methodology.

2.1. Support Vector Regression Model
The SVR model is adopted to compute the function relationship between independent (parameters—) and dependent (responses—) variables whose distributions are not known and concurrently minimize both model complexity and estimation errors. The model complexity and estimation errors are concurrently minimized by implementing SVR in the data set and its performance was outperformed compared to neural network models. A training SVR model used a training data set to learn about the data set and to construct a model about the generalization error by testing the model using an unseen data set. The response value is a function of multivariate parameters as represented in Equation (10), which can be written as Equation (11) to represent a linear regression support vector in terms of weight vector (W), a high dimensional space related to input parameter space, and a bias (b).
where,
—jth Parameter of ith training data
—kth Response of ith training data
i—Index for training data (i = 1, 2, 3,…nt)
j—Index for parameter (j = 1, 2, 3,…np)
k—Index for response (k = 1, 2,3,…nr)
The value of weight and bias is estimated by transferring the regression problem into the constraint minimization problem expressed in Equation (12).
where,
, —lower and upper positive slack variables
—Flatness value of the function
—Empirical error
C—Box constraint or penalty parameter value
Constraints:
where
—Error tolerance
The constraint problem is resolved using the following Lagrange multiplier function as given in Equation (16), which should be minimized concerning the conditions mentioned in Equation (17). The list of parameters considered to establish an SVR model is presented in Table 1. A list of kernel functions and their formulas are depicted in Table 2.
where
—Non-negative Lagrange multipliers
—Kernel function
Constraints:

Table 1.
List of parameters considered in SVR.
Table 1.
List of parameters considered in SVR.
| Parameters | Values |
|---|---|
| ) | Gaussian |
| Radial basis function | |
| Polynomial | |
| Linear | |
| Quadratic | |
| Cubic | |
| Solver (sr) | SMO (Sequential Minimal Optimization) |
| ISDA (Iterative Single Data Algorithm) | |
| Q1LP (Quadratic Programming) | |
| Validation scheme (vs) | Cross-validation Holdout validation |
| Validation scheme’s parameters | K-fold—Number of folds used for cross-validation (5 to 15) Holdout—% of data holdout for validation (10% to 40%) |
| % of training data | 10% to 30% |
Table 2.
Kernel functions and their formulas.
Table 2.
Kernel functions and their formulas.
| Kernel Function | Formula | Terms Used |
|---|---|---|
| Gaussian | —Euclidean distance —Variance | |
| Radial basis function | —Scaler value | |
| Polynomial | A—Free parameter n—Order of polynomial | |
| Linear | ||
| Quadratic | A—Free parameter | |
| Cubic | A—Free parameter |
One SVR model is developed using a kernel function, solver type, validation scheme and its parameter, and % of testing data using the ‘fitrsvm’ function. If the convergence does not occur with the model, then the model runs for another set of iterations using the ‘resume’ function. Once convergence is reached, then, using the ‘predict’ function, the response values are going to be computed by substituting the total data set, training data set, and testing data set. The performance measures of the model are calculated using the predicted () and actual () response values from the data set.
2.2. Moth Flame Optimization
Moth flame optimization also belongs to the family of butterflies inspired by its transverse orientation navigation method used for flying long distances and maintaining a fixed angle with the flying the moon and flying spirally [22]. The MFO algorithm provides very quick convergence at a very initial stage by switching from exploration to exploitation, which increases the efficiency of the algorithm. Apart from that, the MFO is selected in this work for its simplicity, speed in searching, simple hybridization with other algorithms, requiring no derivation information in the starting phase, few parameters, scalability and flexibility [23]. In this work, the number of dimensions that represent the position of the moth will be considered five, and the same is represented in Table 3, and its lower and upper bound values are listed in Table 4. One moth represents one solution that will produce one SVR-trained model with the performance measures of RMSE, MAE, and values by considering the moth dimensions as the parameters of the SVR model like kernel function, name of the solver, validation scheme, validation scheme’s parameter, and % of training data. Table 3 represents one such moth’s dimensions. It shows that an SVR model will be generated with the parameters of the 3rd kernel function, 1st solver type, 2nd validation scheme, 25% of data for validation as validation scheme’s parameter, and 20% of training data using the ‘fitrsvm’ and ‘resume’ functions in MATLAB 2022a and trained with the output of performance measures. The simultaneous maximizing of the value of and minimizing the value of RMSE and MAE are considered objective functions in this work. The non-dominated sorting method is adopted to generate 100 Pareto-optimal moths as the archive size and 100 moths as the population size by considering 100 iterations as the stopping criteria. After obtaining the trained SVR model, the three performance measures are calculated for both the testing and total data sets apart from the trained data set. This procedure has been followed for all three responses, L, D, and W; responses in SVR models will be available with their parameters and the output values of three performance measures each for the total trained and tested data sets. The evaluation of one such moth is represented in Figure 2. The parameters of the MFO algorithm considered in this work are presented in Table 5. The pseudo-code of the MFO algorithm is presented in Algorithm 1. Due to conflict objectives, the TOPSIS method has been implemented to convert the multi-objectives (three performance measures for each trained, tested, and total data sets) available in the archive into a single objective. The pseudo-code of this method is shown in Algorithm 2. The implementation of the MFO algorithm is represented as a flow diagram in Figure 3. The pseudo-code of the PSO algorithm is presented in Algorithm 3.




Figure 2.
Evaluation of one moth.
Figure 2.
Evaluation of one moth.
Figure 3.
Implementation of MFO Algorithm.
Figure 3.
Implementation of MFO Algorithm.
Table 3.
Moth’s representation.
Table 4.
Lower and upper bound value of SVR parameters.
Table 5.
Parameters of MFO, DFO and PSO algorithms [24].
| Algorithm 1: MFO Algorithm |
| Initialize the parameters for Moth-flame Initialize Moth position Mi randomly For each i = 1:n do Calculate the fitness function fi End For While (iteration ≤ max_iteration) do Update pareto optimal solution archive using non-dominated sorting method Update the position of Mi Calculate the no. of flames Evaluate the fitness function fi If (iteration==1) then F = sort (M) OF = sort (OM) Else F = sort (Mt-1, Mt) OF = sort (Mt-1, Mt) End if For each i = 1:n do For each j = 1:d do Update the values of r and t Calculate the value of D w.r.t. corresponding Moth Update M(i,j) w.r.t. corresponding Moth End For End For End While Using TOPSIS method (Algorithm 4) convert the archive multi objectives into single objective (closeness value) and display the optimum SVR model based on highest closeness value Print the best solution |
| Algorithm 2: DFO Algorithm |
| Define number of dragonflies (nd), number of iteration (nitr), and archive size As initial population, initialize position of dragonflies Pij Assign step vector (Vij) values as Pij Do While i<=nitr Calculate the value of inertia, separation, alignment and cohesion weights, food and enemy factor values. Compute the objective values of each dragonflies (Fi) Determine the non-dominated objective values Update the no. of non-dominated solutions in archive Assume best solution as food source and worst solution as enemy Update the values of Vij and Pij Check Pij values lies between the lower and upper limits of process parameters End Using TOPSIS method convert the archive multi objectives into single objective (closeness value) and display the optimum SVR model based one highest closeness value Print the best solution. |
| Algorithm 3: PSO Algorithm |
| P = Particle Initialization (); For i=1 to itrmax For each particle p in P do fp = f(p); If fp is better than f(pBest); pBest = p; end end gBest = best p in P Determine the non-dominated objective values Update the no. of non-dominated solutions in archive For each particle p in P do v = v + c1 *rand*(pBest − p) + C2 *rand*(gBest-P); p = p+v; end end Using TOPSIS method convert the archive multi objectives into single objective (closeness value) and display the optimum SVR model based on highest closeness value Print the best solution. |
| Algorithm 4: TOPSIS Method |
| Read objectives matrix—Ork with weights (Wk) and type of objectives (OT) For each Alternate r = na For each Response k = nr Compute Normalized value of Ork (Nrk) Calculate Performance Matrix (Ark) End End For each Response k = nr Determine positive ideal (Pk) and negative ideal solution (Mk) End For each Alternate r = na Determine Ideal (SPr) and negative ideal separation (SMr) Compute Relative Closeness (Rr) End Arrange alternatives in descending order based on Rr Display the alternate which has highest Rr value |
3. Results and Discussions
MATLAB codes were developed for the MFO algorithm, which has been executed repeatedly 30 times. Each time, there are 100 solutions in an archive, and one best solution is selected using the TOPSIS [25] method; hence, the 30 best solutions obtained by the MFO algorithm are shown in Table 6 for response L (crack length) and similarly for other responses; D (crack depth) and W (crack width) are presented in Table 7 and Table 8. Out of these 30 solutions, the best one is selected again using the TOPSIS method for all of the responses. It is confirmed from Figure 4 that the highest closeness values are obtained for the MFO algorithm as compared to the DFO [26] and PSO [27] algorithms. The convergence plot for three different performance measures is shown in Figure 5.
Table 6.
Performance of SVR model for crack length (L) using MFO algorithm.
Table 7.
Performance of SVR model for crack depth (D) using MFO algorithm.
Table 8.
Performance of SVR model for crack width (W) using MFO algorithm.
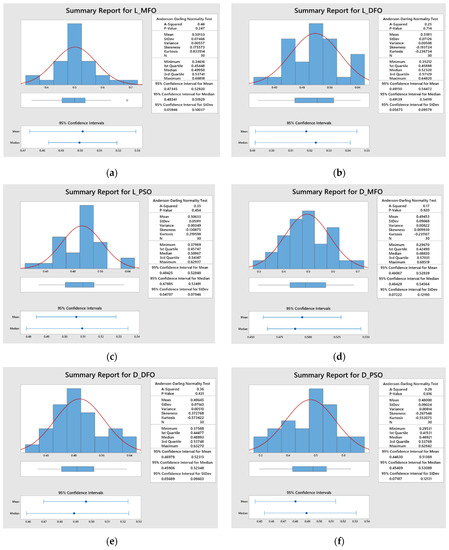
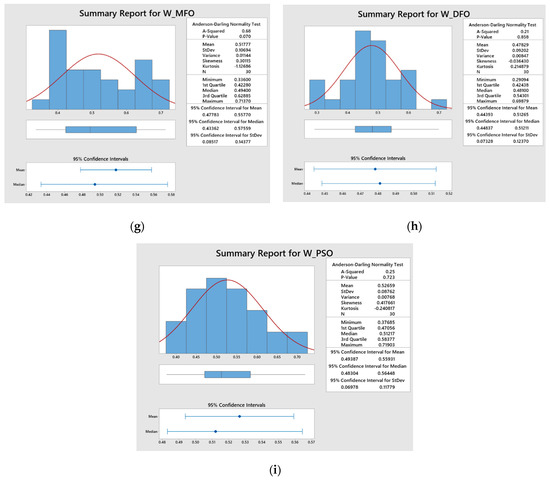
Figure 4.
Statistical analysis of closeness values for (a) Response L-MFO; (b) Response L-DFO; (c) Response L-PSO; (d) Response D-MFO; (e) Response D-DFO; (f) Response D-PSO; (g) Response W-MFO; (h) Response W-DFO; (i) Response W-PSO.
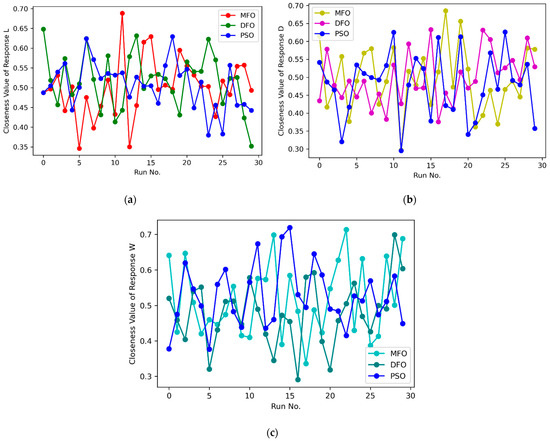
Figure 5.
Comparison of closeness values for (a) Response L; (b) Response D; (c) Response W.
Figure 4a–c. represent the statistical distribution of closeness values obtained for 30 runs from Minitab 19 software using MFO, DFO and PSO algorithms for response L. Similar representation for responses D and W are illustrated in Figure 4d–f. and Figure 4g–i. respectively. It is observed that all of the p-values are greater than 0.05, which shows that the closeness values are normally distributed. This confirmed that the results obtained by the MFO, DFO, and PSO algorithms are accepted. Figure 5a–c. illustrate the closeness values obtained for various responses using MFO, DFO, and PSO algorithms for responses L, D and W respectively. It is understood that, in most of the runs, the MFO has the highest closeness value as compared to the DFO and PSO algorithms. Based on the highest closeness value, the best SVR model has been selected for each response, L, D, and W, and presented in Table 9. Using these models, the predicted response values are calculated and represented in Figure 6. The actual training data set of responses, L, D, and W, with their predicted values are plotted in Figure 6a–c. A similar representation is shown for the testing data set in Figure 6d–f. The predicted values of L and W are closer to the actual value in the training data set compared with response D. In the testing data set, out of 29 samples of response W, almost all predicted values are closer to the actual values, whereas in L, out of 20 samples, 14 are closer, and in D, it is only 7 out of 25. It is inferred that the SVR models developed to predict the response values of L and W are more accurate compared to D. The probability plots shown in Figure 7a–c. reveal that the results obtained using MFO for 30 runs are normally distributed for trainnig data set of responses L, D and W. Figure 7d–f. represent probability plots for testing data set of responses L, D and W, it also show the results are normally distributed; hence, the developed SVR models are appropriate. The three performance measures of SVR models for responses, L, D, and W, are presented in Figure 8a–c. It is reported that RMSE values of 0.071, 0.0767, and 0.0678 were obtained in the testing data set of responses L, D, and W, respectively. Lesser MAE values of 0.0624, 0.0672, and 0.0583 and higher values of 0.9996, 0.9909, and 0.9999 were reported in the testing data set. Figure 9 illustrates the convergence plot of performance measures for three responses, L, D, and W, for the total, training, and testing data sets. It is observed from Figure 9a–c that the convergence occurred on the 34th, 41st, and 34th iterations in the MFO algorithm, whereas, in DFO, it occurred on the 52nd, 52nd, and 55th iterations in response L. It is confirmed from Figure 9d–f. that the convergence occurred on the 40th, 54th, and 48th iterations in the MFO algorithm, whereas, in DFO, it occurred on the 61st, 43rd, and 63rd iterations in response D. It is evident from Figure 9g–i. that the convergence occurred on the 40th, 41st and 45th iterations in the MFO algorithm, whereas, in DFO, it occurred on the 61st, 57th, and 67th iterations in response W. It is confirmed from Figure 9a–c. that the convergence occurred in PSO for response L will be at the 89th, 63rd and 87th iterations for RMSE, MAE, and R2 values that are higher than the convergence iteration numbers in the MFO algorithm. It is also observed from Figure 9d–i. that the convergence occurred in a higher iteration number in the case of response D and W in the PSO algorithm compared with the MFO. Hence, the MFO algorithm outperformed compared to the DFO algorithm in the convergence of objective values.
Table 9.
Best Parameters of the SVR model for responses L, D, and W.
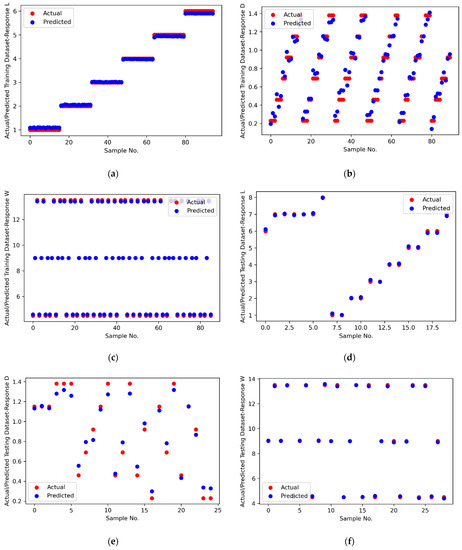
Figure 6.
Comparison of actual and predicted values for (a) Training Dataset-Response L; (b) Training Dataset-Response D; (c) Training Dataset-Response W; (d) Testing Dataset-Response L; (e) Testing Dataset-Response D; (f) Testing Dataset-Response W.
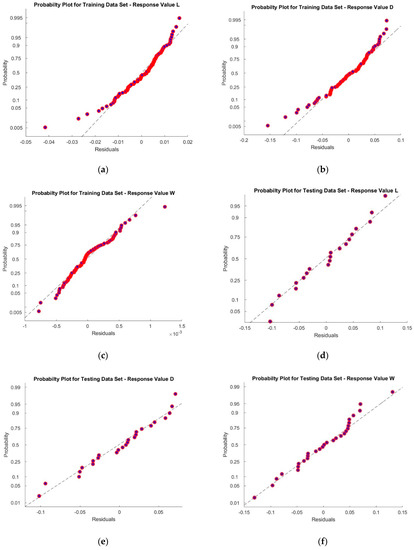
Figure 7.
Probability Plot for (a) Training Dataset-Response L; (b) Training Dataset-Response D; (c) Training Dataset-Response W; (d) Testing Dataset-Response L; (e) Testing Dataset-Response D; (f) Testing Dataset-Response W.
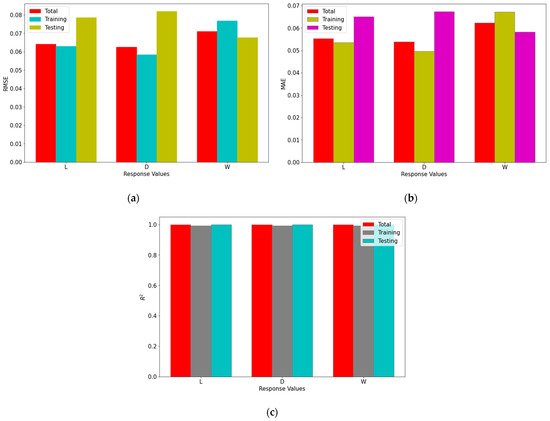
Figure 8.
Performance measures of SVR models (a) RMSE; (b) MAE; (c) R2.
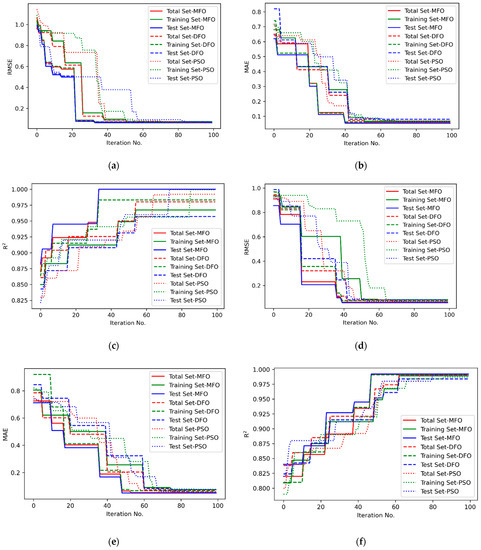
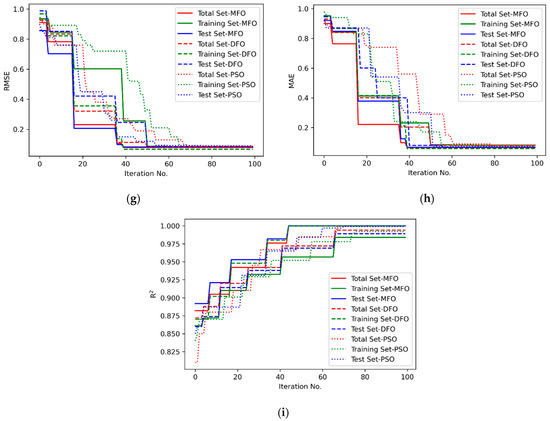
Figure 9.
Convergence plot of performance of SVR for (a) Response L—RMSE; (b) Response L—MAE; (c) Response L—R2; (d) Response D—RMSE; (e) Response D—MAE; (f) Response D—R2; (g) Response W—RMSE; (h) Response W—MAE; (i) Response W—R2.
Quantitative Comparison of MFO with DFO and PSO Algorithms
The performance of the MFO algorithm is compared with the DFO and PSO algorithms using two quantitative metrics, namely diversity and spacing [28]. Diversity indicates the spread of the Pareto solutions produced by an algorithm. The higher the value of diversity confirmed the better performance of the algorithm. The mathematical representation is given in Equation (18). Spacing is a straightforward method to compute the distance between the point and its closest neighbor. The minimum value of spacing indicates the better performance of the algorithm. The value of spacing is calculated using Equation (19). Table 10 represents the diversity and spacing values of the MFO, DFO, and PSO algorithms.
where
Pimax—Maximum value of ith performance measures
Pimin—Minimum value of ith performance measures
np—number of performance measures
where
where nr—Number of runs, I—index for a no. of performance measures, J—index for a no. of runs.
Table 10.
Comparison of performance of algorithms using performance indicators.
Table 10.
Comparison of performance of algorithms using performance indicators.
| Response | Algorithms | Diversity | Spacing |
|---|---|---|---|
| L | MFO | 0.0652 | 0.0053 |
| DFO | 0.0644 | 0.0054 | |
| PSO | 0.0648 | 0.0057 | |
| D | MFO | 0.0679 | 0.0026 |
| DFO | 0.0664 | 0.0058 | |
| PSO | 0.0653 | 0.0062 | |
| W | MFO | 0.0685 | 0.0063 |
| DFO | 0.0676 | 0.0066 | |
| PSO | 0.0680 | 0.0073 |
It is understood from Table 10 that the diversity value of the MFO algorithm is high compared to both the DFO and PSO algorithms in all of the three-response values, L, D, and W. Furthermore, the spacing value is less in the MFO algorithm for all three responses. Hence, it is confirmed that the MFO algorithm outperformed compared with both the DFO and PSO algorithms. The statistical analysis of three performance measures for training, testing, and total data sets for the MFO, DFO, and PSO algorithms are represented in Table 11, Table 12 and Table 13. The best values of three performance measures, RMSE, MAE, and are 0.0544, 0.0527, and 0.9999, respectively, for response L in the MFO algorithm, whereas in the DFO algorithm, the values are 0.0626, 0.0539, and 0.9993, and in the PSO algorithm, the values are 0.0626, 0.0538, and 0.9993. It is confirmed that the MFO algorithm is good compared to the DFO and PSO algorithms in predicting the response L. This is true for response W in the DFO algorithm, but in the PSO algorithm, both the RMSE and MAE values are lower compared with the MFO algorithm. In the case of response D in the DFO and PSO algorithms, the RMSE and MAE values are a little bit low compared to the MFO algorithm, but in the meantime, the value is higher than in the DFO and PSO algorithms. In overall performance, the SVR models developed by the MFO algorithm outperformed compared to the DFO and PSO algorithms.
Table 11.
Statistical analysis of output obtained by the MFO algorithm.
Table 12.
Statistical analysis of output obtained by the DFO algorithm.
Table 13.
Statistical analysis of output obtained by the PSO algorithm.
The comparison of the performance measures of the proposed method using MFO (PM-MFO) and the existing method using Feed Forward Back Propagation (EX-FFBP) by Daniel et al. [1] is illustrated in Figure 10. It is understood that, for the tested data set, the proposed method performed well for responses L in Figure 10a and for response W in Figure 10c as compared to response D in Figure 10b.
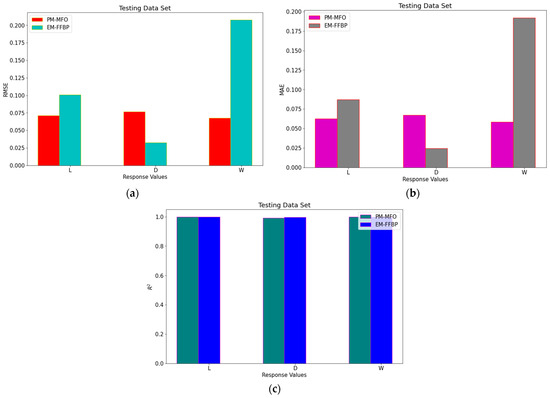
Figure 10.
Comparison of performance measures (a) RMSE; (b) MAE (c) R2.
4. Conclusions
In this work, SVR models have been developed to predict the length, depth, and width of the defect images using the given GLCM features extracted from MFL images. Five different parameters that decide the performance of SVR have been considered and three various performance measures, RMSE, MAE, and values, are taken into consideration to evaluate the performance of the SVR models. The MFO algorithm is implemented to find the best parameters of SVR models, and both DFO and PSO algorithms are used to compare the performance of the MFO algorithm. The normality test, probability, and residual plots have ensured that the results obtained using these algorithms are normally distributed and hence, accepted. The convergence, diversity, and spacing of performance measures are considered to evaluate the betterment of the functioning of the MFO with the DFO and PSO algorithms. Low convergence, a high value of diversity, and a low value of spacing reported at 34 iterations, 0.0685 and 0.0026, respectively, obtained with the MFO algorithm confirmed that it outperformed the DFO and PSO algorithms. The reported values of the three performance measures of SVR models, RMSE, MAE, and values of responses L, D, and W using the MFO algorithm, are 0.0527, 0.0613, and 0.9999. These lower values in both RMSE and MAE and high values in confirmed the performance of the MFO algorithm. Furthermore, in comparing the performance measures with the existing FFBP method, the proposed MFO–SVR method proved its effectiveness in responses L and W. The proposed SVR model is not suitable for a very large dataset, and all the features have been considered without finding the priority features. As a future work, this work can be extended further by adding the other additional features of GLSM extracted from the MFL image with data augmentation for different L, D, and W. Furthermore, features can be prioritized using the existing different algorithms, and based on that, the performance of the SVR models can be studied further.
Author Contributions
Conceptualization, M.V.A.W., S.R., R.C., M.S.K. and M.E.; data curation, M.V.A.W.; formal analysis, M.V.A.W.; investigation, M.V.A.W.; methodology, S.R. and M.E.; resources, R.C. and M.S.K.; software, S.R., R.C., M.S.K. and M.E.; visualization, M.V.A.W. and S.R.; writing—original draft, M.V.A.W. and S.R.; writing—review and editing, R.C., M.S.K. and M.E. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request through email to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Daniel, J.; Abudhahir, A.; Paulin, J.J. Magnetic Flux Leakage (MFL) Based Defect Characterization of Steam Generator Tubes Using Artificial Neural Networks. J. Magn. 2017, 22, 34–42. [Google Scholar] [CrossRef]
- Raj, B.; Jayakumar, T.; Rao, B.P.C. Non-Destructive Testing and Evaluation for Structural Integrity. Sadhana 1995, 20, 5–38. [Google Scholar] [CrossRef]
- Dwivedi, S.K.; Vishwakarma, M.; Soni, A. Advances and Researches on Non Destructive Testing: A Review. Mater. Today Proc. 2018, 5, 3690–3698. [Google Scholar] [CrossRef]
- Göktepe, M. Non-Destructive Crack Detection by Capturing Local Flux Leakage Field. Sens. Actuators A Phys. 2001, 91, 70–72. [Google Scholar] [CrossRef]
- Ling, Z.W.; Cai, W.Y.; Li, S.H.; Li, C. A Practical Signal Progressing Method for Magnetic Flux Leakage Testing. Appl. Mech. Mater. 2014, 599–601, 782–785. [Google Scholar] [CrossRef]
- Wu, J.; Wu, W.; Li, E.; Kang, Y. Magnetic Flux Leakage Course of Inner Defects and Its Detectable Depth. Chin. J. Mech. Eng. 2021, 34, 63. [Google Scholar] [CrossRef]
- Ege, Y.; Coramik, M. A New Measurement System Using Magnetic Flux Leakage Method in Pipeline Inspection. Measurement 2018, 123, 163–174. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, C.; Li, R.; Cai, M.; Jia, G. Theory and Application of Magnetic Flux Leakage Pipeline Detection. Sensors 2015, 15, 31036–31055. [Google Scholar] [CrossRef]
- Suresh, V.; Abudhahir, A.; Daniel, J. Development of Magnetic Flux Leakage Measuring System for Detection of Defect in Small Diameter Steam Generator Tube. Measurement 2017, 95, 273–279. [Google Scholar] [CrossRef]
- Jin, C.; Kong, X.; Chang, J.; Cheng, H.; Liu, X. Internal Crack Detection of Castings: A Study Based on Relief Algorithm and Adaboost-SVM. Int. J. Adv. Manuf. Technol. 2020, 108, 3313–3322. [Google Scholar] [CrossRef]
- Zhang, J.; Teng, Y.-F.; Chen, W. Support Vector Regression with Modified Firefly Algorithm for Stock Price Forecasting. Appl. Intell. 2018, 49, 1658–1674. [Google Scholar] [CrossRef]
- Kari, T.; Gao, W.; Tuluhong, A.; Yaermaimaiti, Y.; Zhang, Z. Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers. Energies 2018, 11, 2437. [Google Scholar] [CrossRef]
- Houssein, E.H. Particle Swarm Optimization-Enhanced Twin Support Vector Regression for Wind Speed Forecasting. J. Intell. Syst. 2017, 28, 905–914. [Google Scholar] [CrossRef]
- Li, S.; Fang, H.; Liu, X. Parameter Optimization of Support Vector Regression Based on Sine Cosine Algorithm. Expert Syst. Appl. 2018, 91, 63–77. [Google Scholar] [CrossRef]
- Yuan, F.-C. Parameters Optimization Using Genetic Algorithms in Support Vector Regression for Sales Volume Forecasting. Appl. Math. 2012, 03, 1480–1486. [Google Scholar] [CrossRef]
- Papadimitriou, T.; Gogas, P.; Stathakis, E. Forecasting Energy Markets Using Support Vector Machines. Energy Econ. 2014, 44, 135–142. [Google Scholar] [CrossRef]
- Gayathri, R.; Rani, S.U.; Cepova, L.; Rajesh, M.; Kalita, K. A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes 2022, 10, 1387. [Google Scholar] [CrossRef]
- Gupta, K.K.; Kalita, K.; Ghadai, R.K.; Ramachandran, M.; Gao, X.Z. Machine Learning-Based Predictive Modelling of Biodiesel Production—A Comparative Perspective. Energies 2021, 14, 1122. [Google Scholar] [CrossRef]
- Ganesh, N.; Joshi, M.; Dutta, P.; Kalita, K. PSO-tuned Support Vector Machine Metamodels for Assessment of Turbulent Flows in Pipe Bends. Eng. Comput. 2019, 37, 981–1001. [Google Scholar] [CrossRef]
- Jayasudha, M.; Elangovan, M.; Mahdal, M.; Priyadarshini, J. Accurate Estimation of Tensile Strength of 3D Printed Parts Using Machine Learning Algorithms. Processes 2022, 10, 1158. [Google Scholar] [CrossRef]
- Priyadarshini, J.; Elangovan, M.; Mahdal, M.; Jayasudha, M. Machine-Learning-Assisted Prediction of Maximum Metal Recovery from Spent Zinc–Manganese Batteries. Processes 2022, 10, 1034. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-Flame Optimization Algorithm: A Novel Nature-Inspired Heuristic Paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Abdelazim, G.H.; Mohamed, A.; El Aziz, M.A. A comprehensive review of moth-flame optimisation: Variants, hybrids, and applications. J. Exp. Theor. Artif. Intell. 2020, 32, 705–725. [Google Scholar] [CrossRef]
- Karthick, M.; Anand, P.; Siva Kumar, M.; Meikandan, M. Exploration of MFOA in PAC Parameters on Machining Inconel 718. Mater. Manuf. Process. 2021, 37, 1433–1445. [Google Scholar] [CrossRef]
- Ananthakumar, K.; Rajamani, D.; Balasubramanian, E.; Paulo Davim, J. Measurement and Optimization of Multi-Response Characteristics in Plasma Arc Cutting of Monel 400TM Using RSM and TOPSIS. Measurement 2019, 135, 725–737. [Google Scholar] [CrossRef]
- Mirjalili, S. Dragonfly Algorithm: A New Meta-Heuristic Optimization Technique for Solving Single-Objective, Discrete, and Multi-Objective Problems. Neural Comput. Appl. 2015, 27, 1053–1073. [Google Scholar] [CrossRef]
- Kumar, M.S.; Rajamani, D.; Nasr, E.A.; Balasubramanian, E.; Mohamed, H.; Astarita, A. A Hybrid Approach of ANFIS—Artificial Bee Colony Algorithm for Intelligent Modeling and Optimization of Plasma Arc Cutting on Monel™ 400 Alloy. Materials 2021, 14, 6373. [Google Scholar] [CrossRef]
- Khalilpourazari, S.; Khalilpourazary, S. Optimization of Time, Cost and Surface Roughness in Grinding Process Using a Robust Multi-Objective Dragonfly Algorithm. Neural Comput. Appl. 2018, 32, 3987–3998. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).