
An Adaptive Partitioning and Multi-Granularity Network for Video-Based Person Re-Identification

Abstract
:1. Introduction
- We propose a pure transformer-based APMG network for video Re-ID tasks;
- We propose a CAP module to adapt the partitioning of feature embeddings according to the correlation, which maintains the consistency of the overall structure and the semantic information of feature embeddings;
- We propose an MG module that can capture feature information at different levels of granularity, thereby improving the re-identification performance of the network.
- We perform experiments on three widely used video Re-ID datasets, which demonstrated that our APMG network achieves a better performance than other state-of-the-art models.
2. Related Work
3. Model and Methods
3.1. Model Frame Structure
3.2. Correlation-Adaptive Partitioning of Feature Embeddings Module
3.3. Multi-Granularity Module
4. Experiments
4.1. Datasets and Evaluation Protocols
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
5. Conclusions and Prospect
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MA, USA, 17–23 July 2021; pp. 10347–10357. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 2017, 1–11. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF international conference on computer vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15013–15022. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Chen, Z.; Zhu, Y.; Zhao, C.; Hu, G.; Zeng, W.; Wang, J.; Tang, M. Dpt: Deformable patch-based transformer for visual recognition. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–25 October 2021; pp. 2899–2907. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar]
- Chen, X.; Liu, X.; Liu, W.; Zhang, X.P.; Zhang, Y.; Mei, T. Explainable Person Re-Identification with Attribute-guided Metric Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11813–11822. [Google Scholar]
- Nguyen, B.X.; Nguyen, B.D.; Do, T.; Tjiputra, E.; Tran, Q.D.; Nguyen, A. Graph-based person signature for person re-identifications. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3492–3501. [Google Scholar]
- Shen, Y.; Li, H.; Yi, S.; Chen, D.; Wang, X. Person re-identification with deep similarity-guided graph neural network. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 486–504. [Google Scholar]
- Yan, Y.; Zhang, Q.; Ni, B.; Zhang, W.; Xu, M.; Yang, X. Learning context graph for person search. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2019; pp. 2158–2167. [Google Scholar]
- Yan, Y.; Qin, J.; Chen, J.; Liu, L.; Zhu, F.; Tai, Y.; Shao, L. Learning multi-granular hypergraphs for video-based person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2020; pp. 2899–2908. [Google Scholar]
- Liu, J.; Zha, Z.J.; Wu, W.; Zheng, K.; Sun, Q. Spatial-temporal correlation and topology learning for person re-identification in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4370–4379. [Google Scholar]
- Yang, J.; Zheng, W.S.; Yang, Q.; Chen, Y.C.; Tian, Q. Spatial-temporal graph convolutional network for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2020; pp. 3289–3299. [Google Scholar]
- Subramaniam, A.; Nambiar, A.; Mittal, A. Co-segmentation inspired attention networks for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 562–572. [Google Scholar]
- Wang, Y.; Zhang, P.; Gao, S.; Geng, X.; Lu, H.; Wang, D. Pyramid spatial-temporal aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 12026–12035. [Google Scholar]
- He, T.; Jin, X.; Shen, X.; Huang, J.; Chen, Z.; Hua, X.S. Dense interaction learning for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1490–1501. [Google Scholar]
- Eom, C.; Lee, G.; Lee, J.; Ham, B. Video-based person re-identification with spatial and temporal memory networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12036–12045. [Google Scholar]
- Bai, S.; Ma, B.; Chang, H.; Huang, R.; Chen, X. Salient-to-Broad Transition for Video Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2022; pp. 7339–7348. [Google Scholar]
- Li, J.; Zhang, S.; Huang, T. Multi-scale 3d convolution network for video based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8618–8625. [Google Scholar]
- Gu, X.; Chang, H.; Ma, B.; Zhang, H.; Chen, X. Appearance-preserving 3d convolution for video-based person re-identification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 228–243. [Google Scholar]
- Aich, A.; Zheng, M.; Karanam, S.; Chen, T.; Roy-Chowdhury, A.K.; Wu, Z. Spatio-temporal representation factorization for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 152–162. [Google Scholar]
- Jiang, X.; Qiao, Y.; Yan, J.; Li, Q.; Zheng, W.; Chen, D. SSN3D: Self-separated network to align parts for 3D convolution in video person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2021; Volume 35, pp. 1691–1699. [Google Scholar]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X.S. Attribute-driven feature disentangling and temporal aggregation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2019; pp. 4913–4922. [Google Scholar]
- Li, S.; Yu, H.; Hu, H. Appearance and motion enhancement for video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11394–11401. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Multi-granularity reference-aided attentive feature aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2020; pp. 10407–10416. [Google Scholar]
- Liu, X.; Zhang, P.; Yu, C.; Lu, H.; Yang, X. Watching you: Global-guided reciprocal learning for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13334–13343. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on visual transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Chu, X.; Zhang, B.; Tian, Z.; Wei, X.; Xia, H. Do we really need explicit position encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Zhang, T.; Wei, L.; Xie, L.; Zhuang, Z.; Zhang, Y.; Li, B.; Tian, Q. Spatiotemporal transformer for video-based person re-identification. arXiv 2021, arXiv:2103.16469. [Google Scholar]
- Zang, X.; Li, G.; Gao, W. Multi-direction and Multi-scale Pyramid in Transformer for Video-based Pedestrian Retrieval. IEEE Trans. Ind. Inform. 2022, 18, 8776–8785. [Google Scholar] [CrossRef]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 868–884. [Google Scholar]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person re-identification by video ranking. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 688–703. [Google Scholar]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 9 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 91–102. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
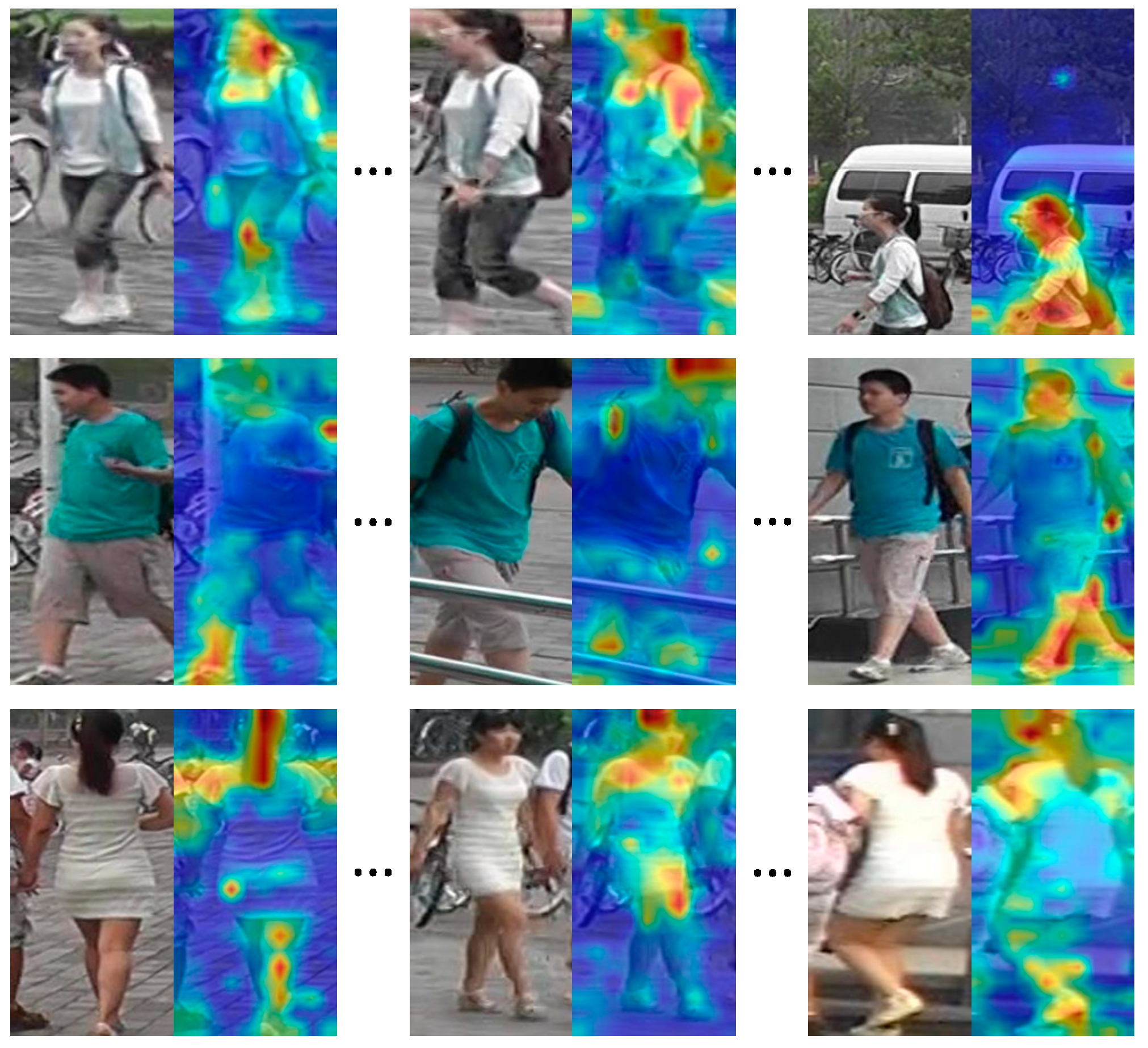{kind=link}
{kind=link}
| Methods | MARS | iLIDS-VID | PRID-2011 | |||||
|---|---|---|---|---|---|---|---|---|
| mAP | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | ||
| Attribute | ADFD | 78.2 | 87.0 | 95.4 | 86.3 | 97.4 | 93.9 | 99.5 |
| AMEM | 79.3 | 86.7 | 94.0 | 87.2 | 97.7 | 93.3 | 98.7 | |
| Graph | MGH | 85.8 | 90.0 | 96.7 | 85.6 | 97.1 | 94.8 | 99.3 |
| STGCN | 83.7 | 89.9 | 96.4 | - | - | - | - | |
| CTL | 86.7 | 91.4 | 96.8 | 89.2 | 97.0 | - | - | |
| 3D convolution | AP3D | 85.6 | 90.7 | - | 88.7 | - | - | - |
| STRF | 86.1 | 90.3 | - | 89.3 | - | - | - | |
| SSN3D | 86.2 | 90.1 | 96.6 | 88.9 | 97.3 | - | - | |
| Attention | DenseIL | 87.0 | 90.8 | 97.1 | 92.0 | 98.0 | - | - |
| STT | 86.3 | 88.7 | - | - | - | - | - | |
| SINet | 86.2 | 91.0 | - | 92.5 | - | 96.5 | - | |
| Grained | MG-RAFA | 85.9 | 88.8 | 97.0 | 88.6 | 98.0 | 95.9 | 99.7 |
| GRL | 84.8 | 91.0 | 96.7 | 90.4 | 98.3 | 96.2 | 99.7 | |
| PiT | 86.8 | 90.2 | 97.2 | 92.1 | 98.9 | - | - | |
| APMG networks | 88.4 | 92.1 | 97.8 | 93.6 | 98.7 | 97.1 | 99.8 | |
| Settings | Parameter Quantity | MARS | iLIDS-VID | PRID-2011 |
|---|---|---|---|---|
| mAP | Rank-1 | Rank-1 | ||
| 4 × 4 and 4 × 4 CAP | 126 M | 88.4 | 93.6 | 97.1 |
| 1. 16 × 16 | 125 M | 84.1 | 90.7 | 95.4 |
| 2. 2 × 2 and 8 × 8 | 148 M | 88.2 | 94.0 | 97.0 |
| 3. 8 × 8 and 2 × 2 | 131 M | 86.7 | 92.4 | 96.3 |
| 4. 4 × 4 and 4 × 2 no partition | 123 M | 86.2 | 89.1 | 93.2 |
| 5. use all patches to calculate the correlation | 154 M | 88.5 | 91.9 | 97.5 |
| Settings | Parameter Quantity | MARS | iLIDS-VID | PRID-2011 |
|---|---|---|---|---|
| mAP | Rank-1 | Rank-1 | ||
| 16 × 16, 8 × 16, 4 × 16 MG | 126 M | 88.4 | 93.6 | 97.1 |
| 1. 16 × 16 | 114 M | 86.6 | 90.0 | 94.9 |
| 2. 16 × 16, 8 × 16 | 119 M | 87.5 | 92.7 | 95.8 |
| 3. 16 × 16, 8 × 16, 4 × 16, 2 × 16 | 135 M | 88.2 | 92.9 | 97.2 |
| 4. MG without weighted sum | 121 M | 87.0 | 90.8 | 95.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, B.; Piao, Y.; Tang, Y. An Adaptive Partitioning and Multi-Granularity Network for Video-Based Person Re-Identification. Appl. Sci. 2022, 12, 12503. https://doi.org/10.3390/app122312503
Huang B, Piao Y, Tang Y. An Adaptive Partitioning and Multi-Granularity Network for Video-Based Person Re-Identification. Applied Sciences. 2022; 12(23):12503. https://doi.org/10.3390/app122312503
Chicago/Turabian StyleHuang, Bailiang, Yan Piao, and Yanfeng Tang. 2022. "An Adaptive Partitioning and Multi-Granularity Network for Video-Based Person Re-Identification" Applied Sciences 12, no. 23: 12503. https://doi.org/10.3390/app122312503
APA StyleHuang, B., Piao, Y., & Tang, Y. (2022). An Adaptive Partitioning and Multi-Granularity Network for Video-Based Person Re-Identification. Applied Sciences, 12(23), 12503. https://doi.org/10.3390/app122312503