
AB-LaBSE: Uyghur Sentiment Analysis via the Pre-Training Model with BiLSTM


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
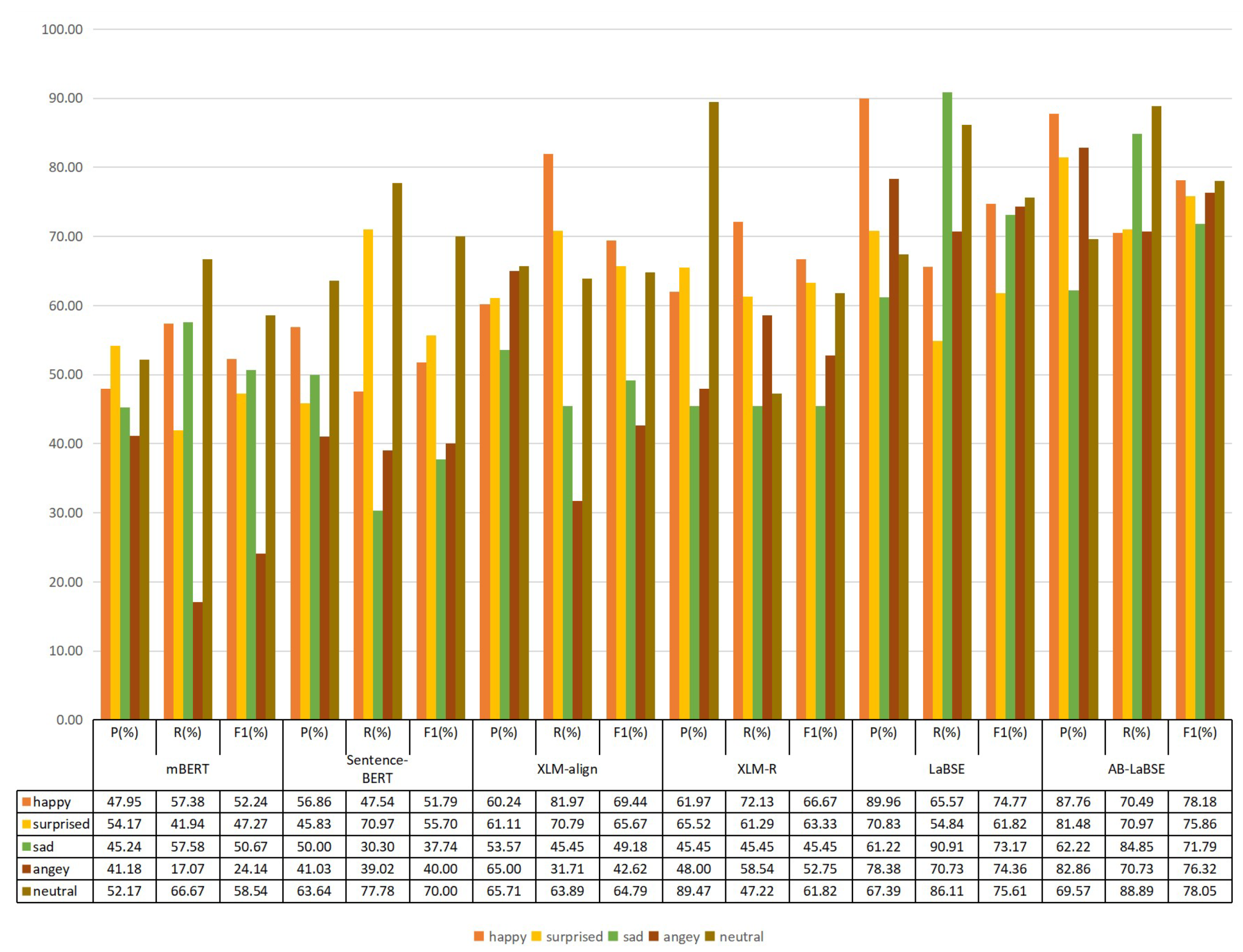{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Pei, Y.; Chen, S.; Ke, Z.; Silamu, W.; Guo, Q. AB-LaBSE: Uyghur Sentiment Analysis via the Pre-Training Model with BiLSTM. Appl. Sci. 2022, 12, 1182. https://doi.org/10.3390/app12031182
Pei Y, Chen S, Ke Z, Silamu W, Guo Q. AB-LaBSE: Uyghur Sentiment Analysis via the Pre-Training Model with BiLSTM. Applied Sciences. 2022; 12(3):1182. https://doi.org/10.3390/app12031182
Chicago/Turabian StylePei, Yijie, Siqi Chen, Zunwang Ke, Wushour Silamu, and Qinglang Guo. 2022. "AB-LaBSE: Uyghur Sentiment Analysis via the Pre-Training Model with BiLSTM" Applied Sciences 12, no. 3: 1182. https://doi.org/10.3390/app12031182
APA StylePei, Y., Chen, S., Ke, Z., Silamu, W., & Guo, Q. (2022). AB-LaBSE: Uyghur Sentiment Analysis via the Pre-Training Model with BiLSTM. Applied Sciences, 12(3), 1182. https://doi.org/10.3390/app12031182