
Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model



Abstract
:1. Introduction
2. Construction and Preprocessing of Insulator Image Dataset
2.1. Image Augmentation Based on GraphCut Segmentation
2.2. Laplacian Sharpening
2.3. Transmission Line Insulator Image Dataset
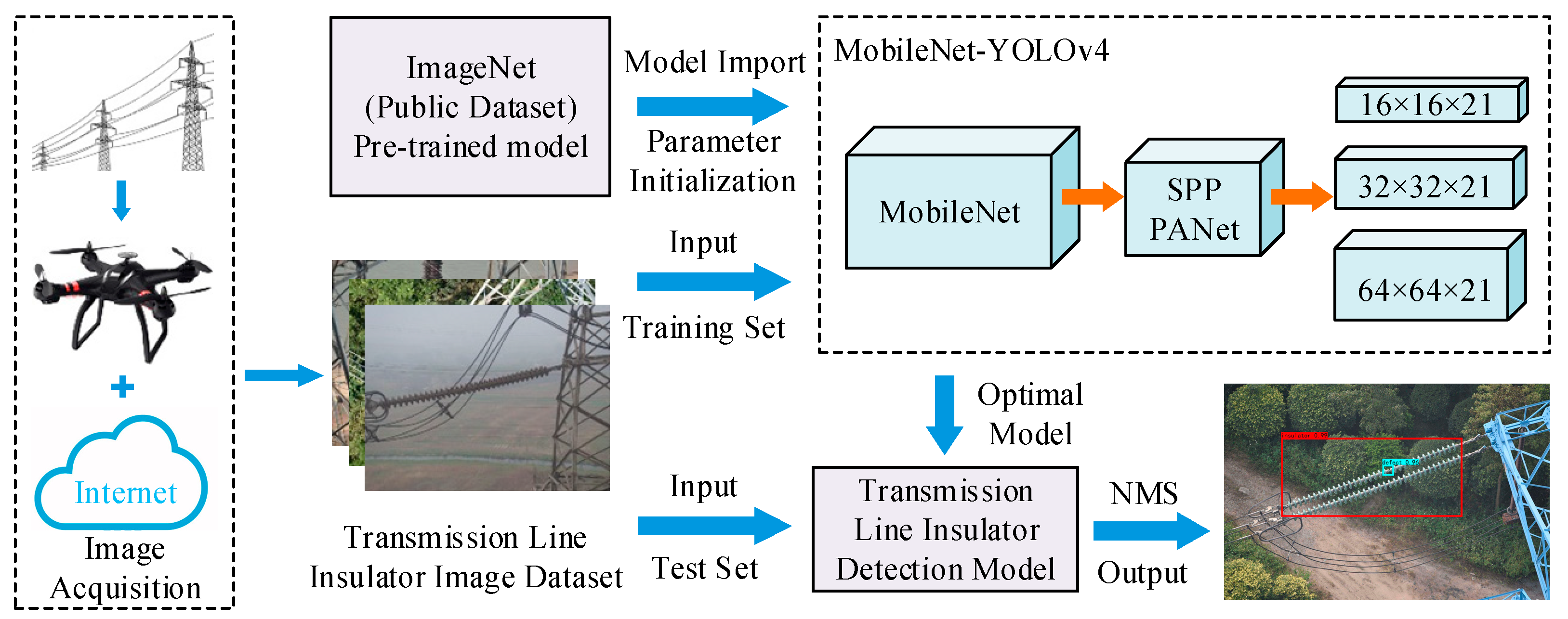
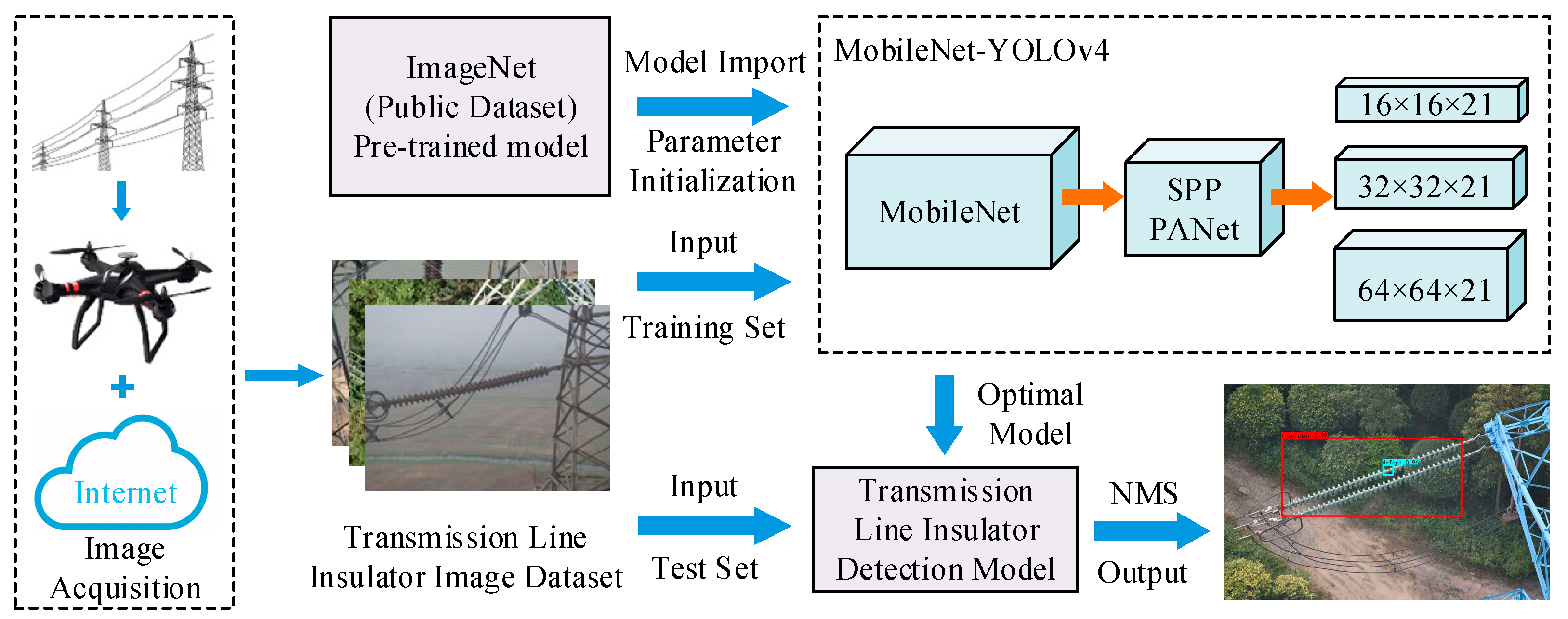
3. Detection Model of Transmission Line Insulator Defects
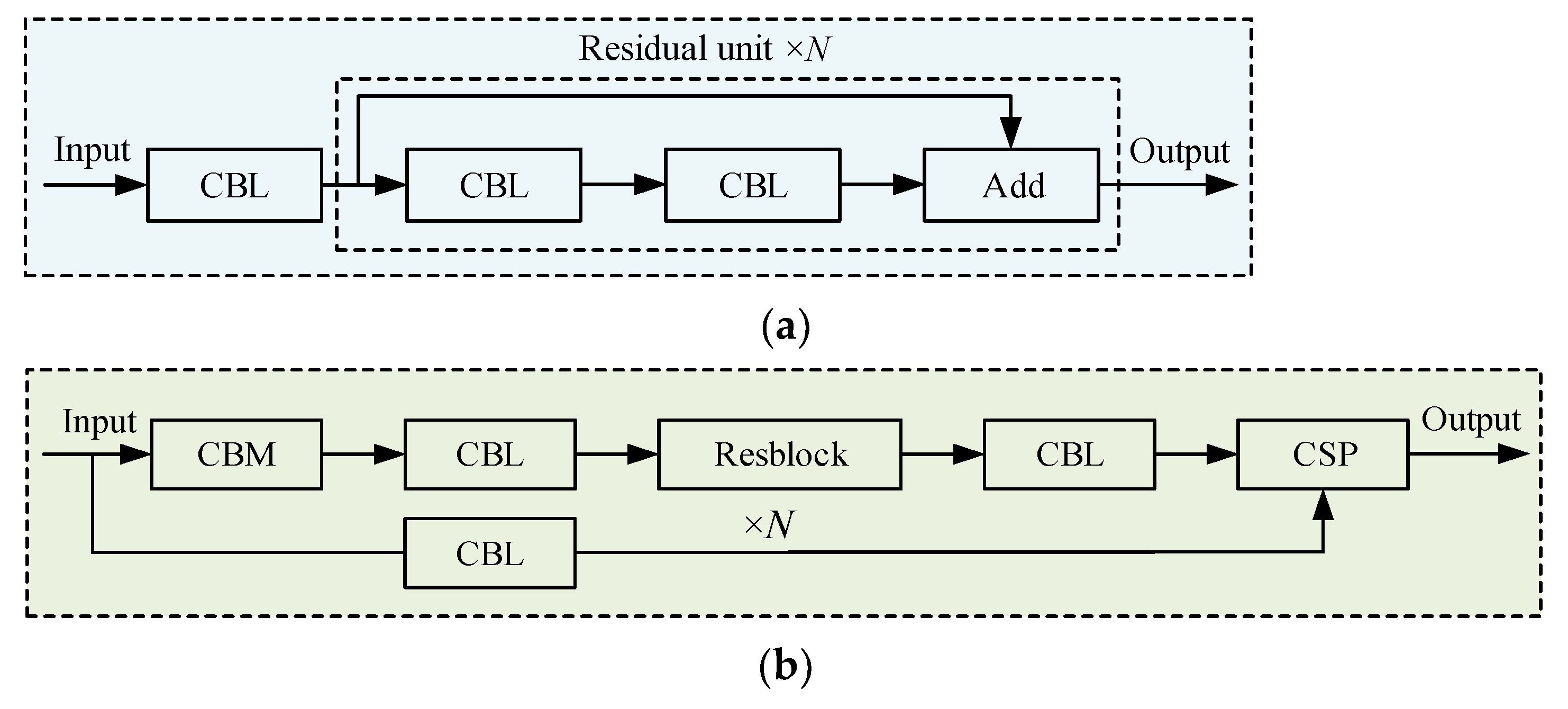
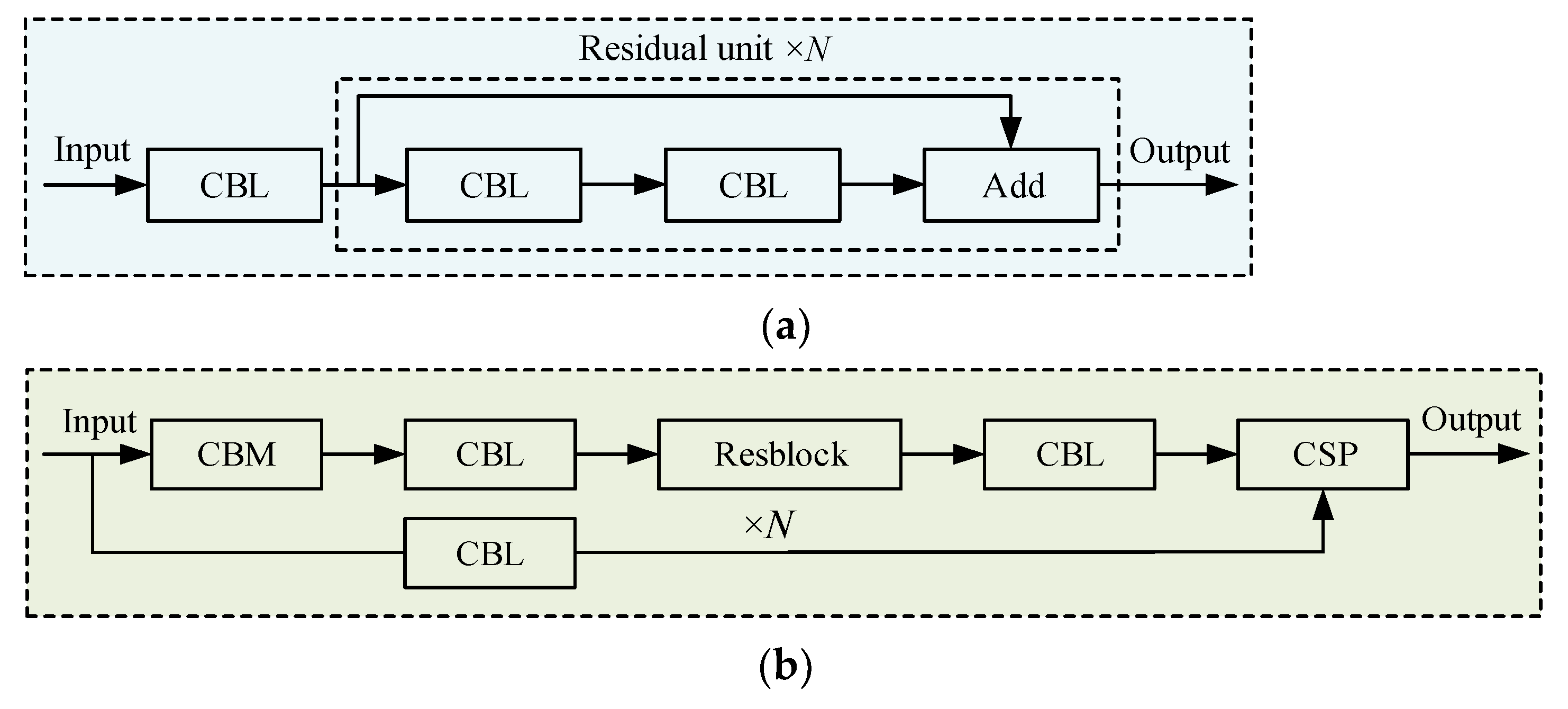
3.1. YOLOv4 Detection Algorithm
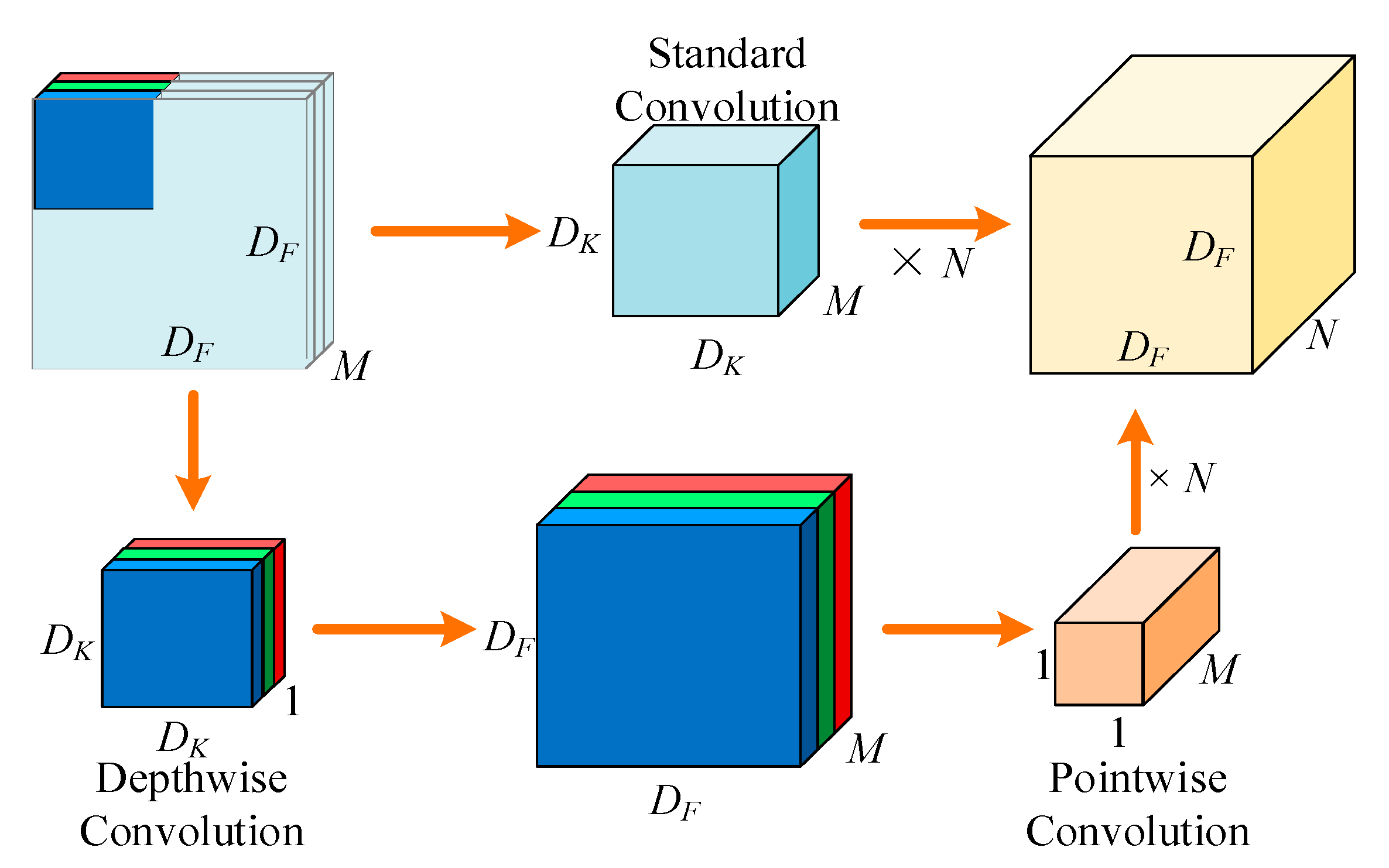
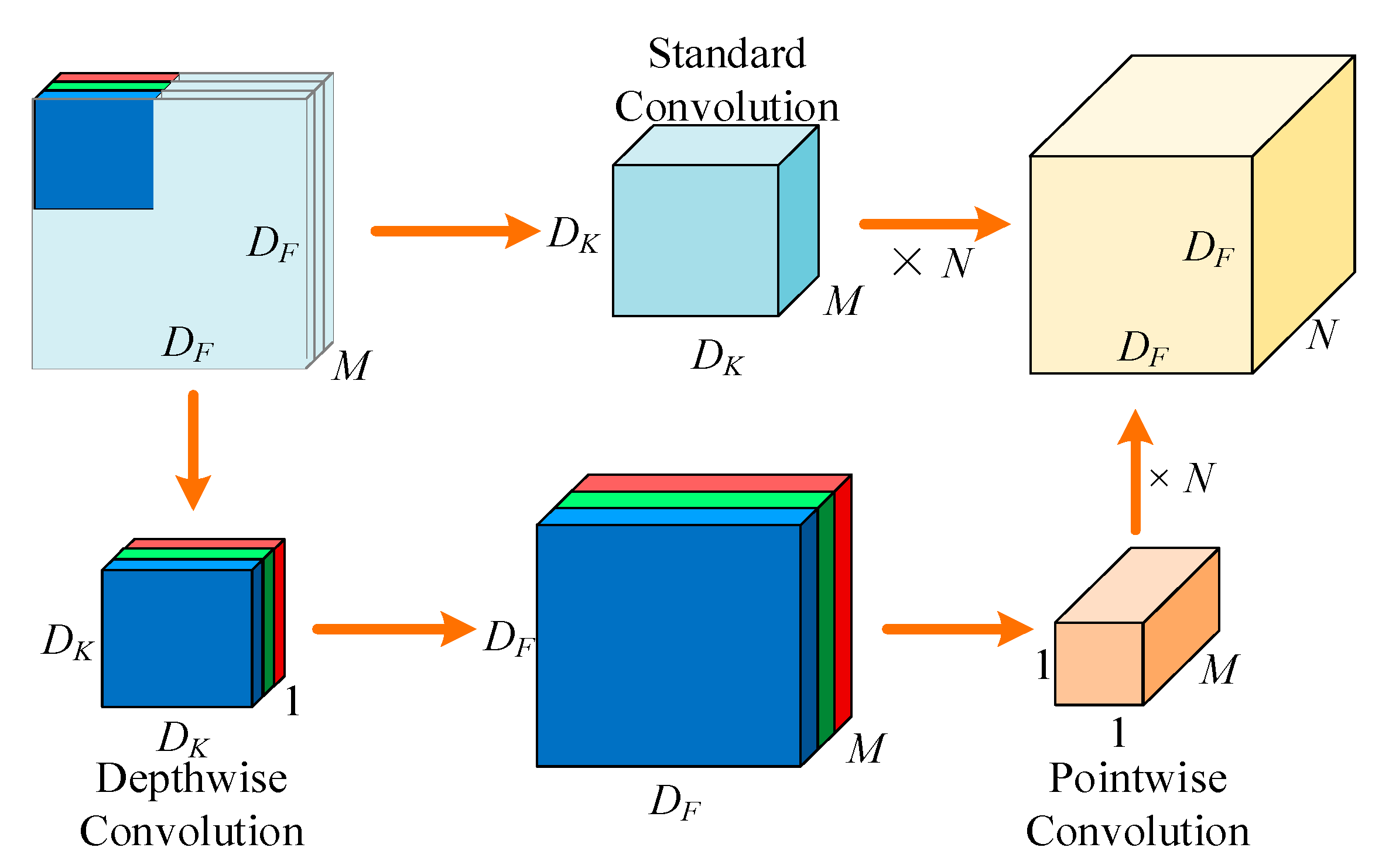
3.2. Depthwise Separable Convolution
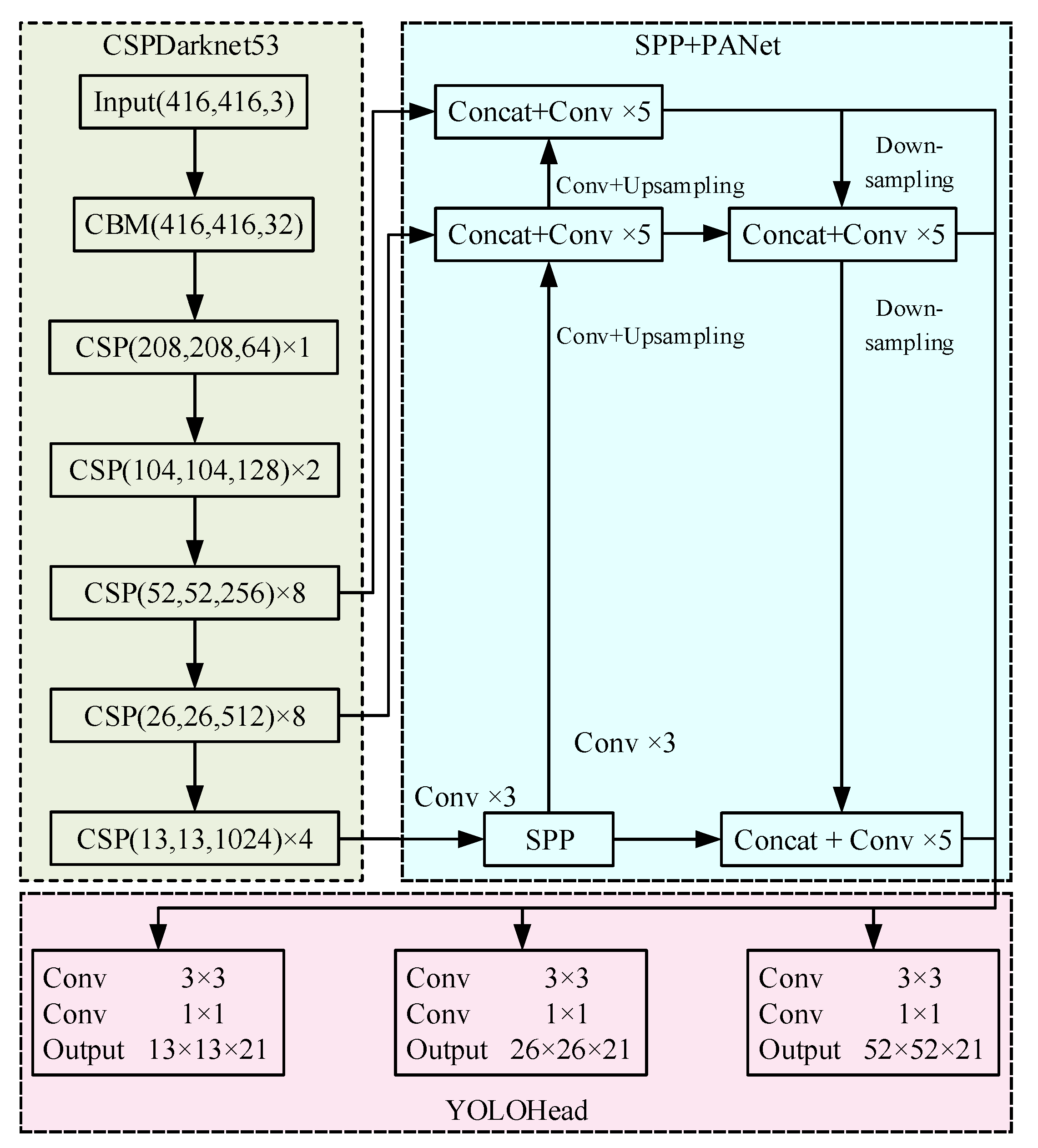
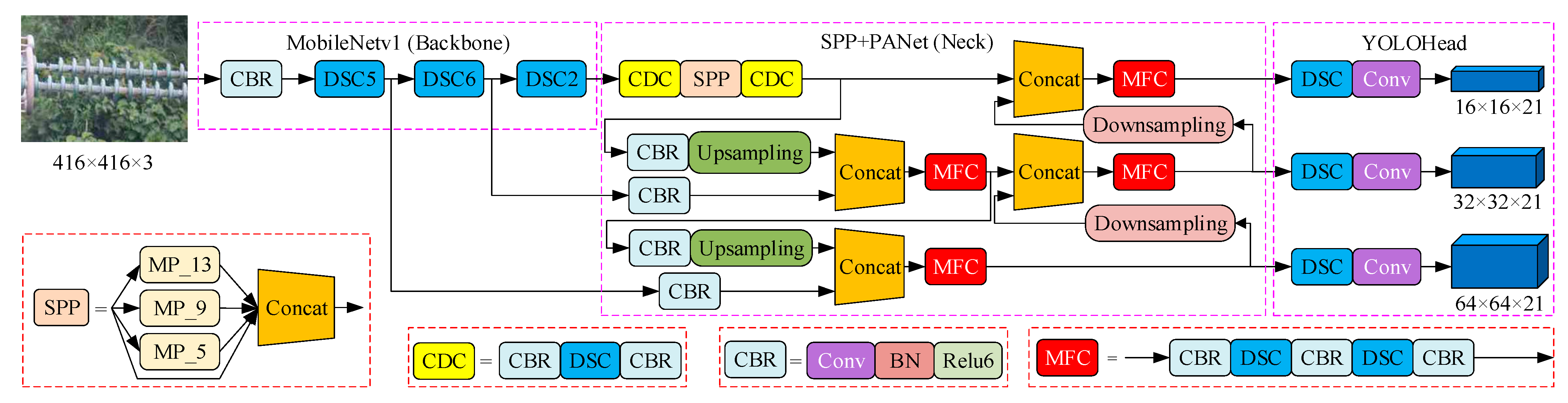
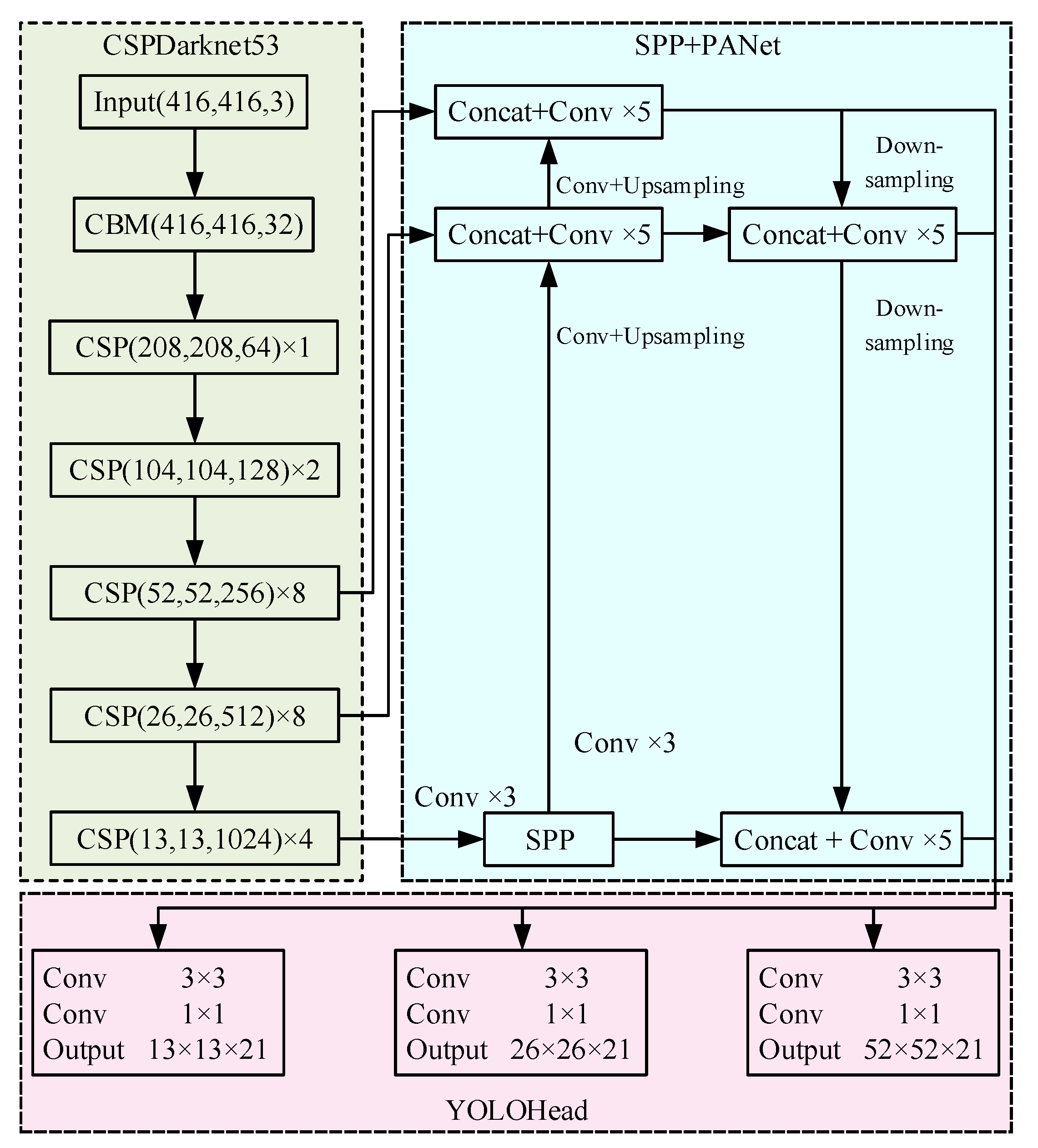
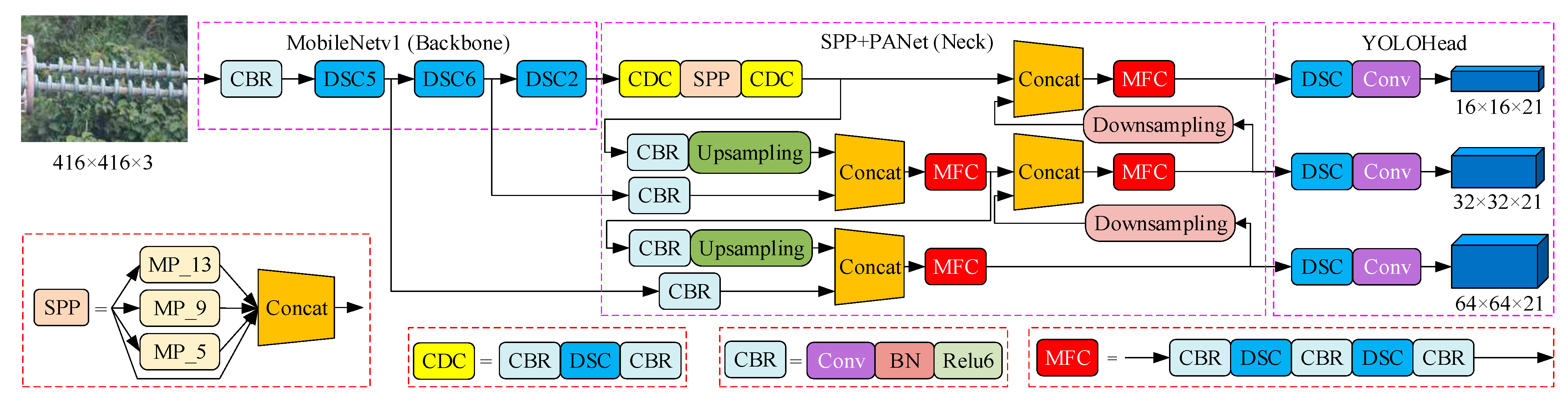
3.3. Improved YOLOv4 Insulator Defect Detection Model
- Feature Extraction Network
- 2.
- DSC-SPP and DSC-PANet
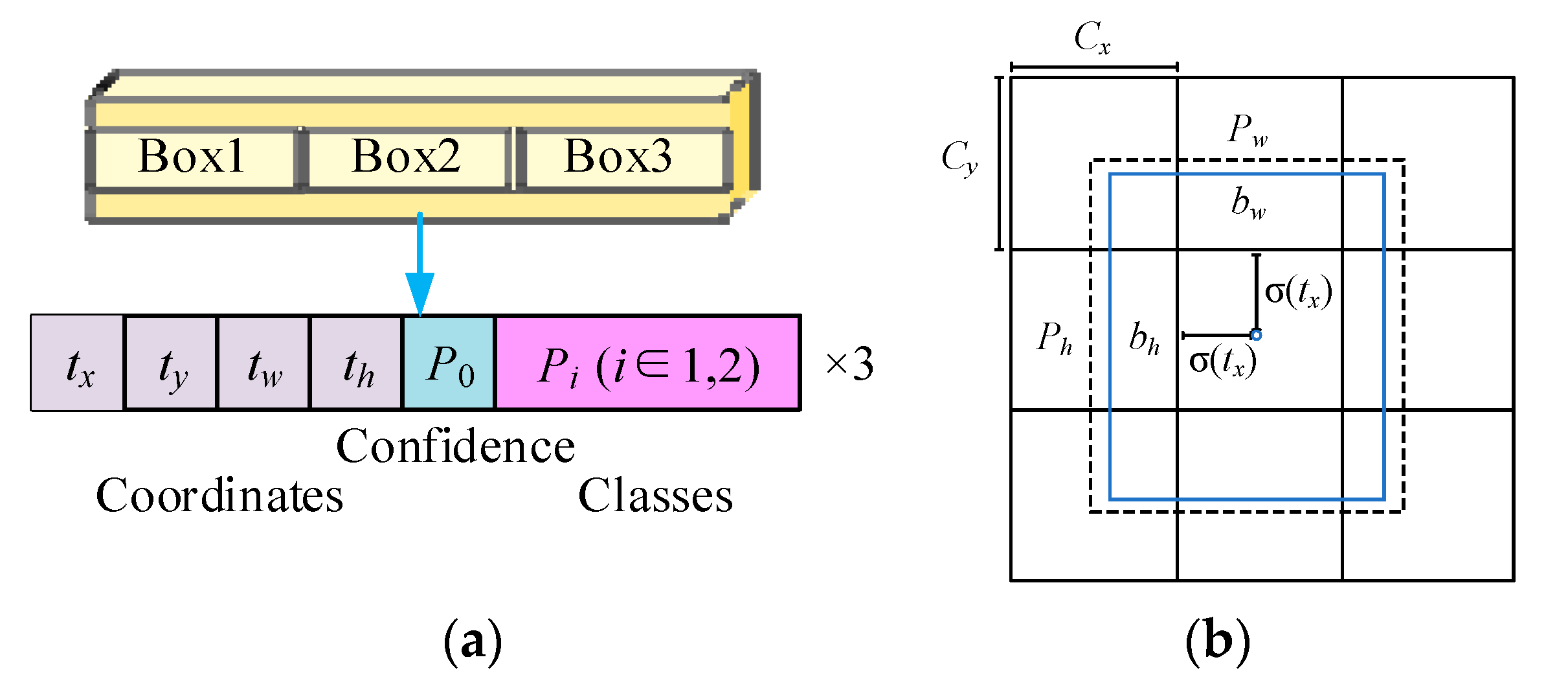
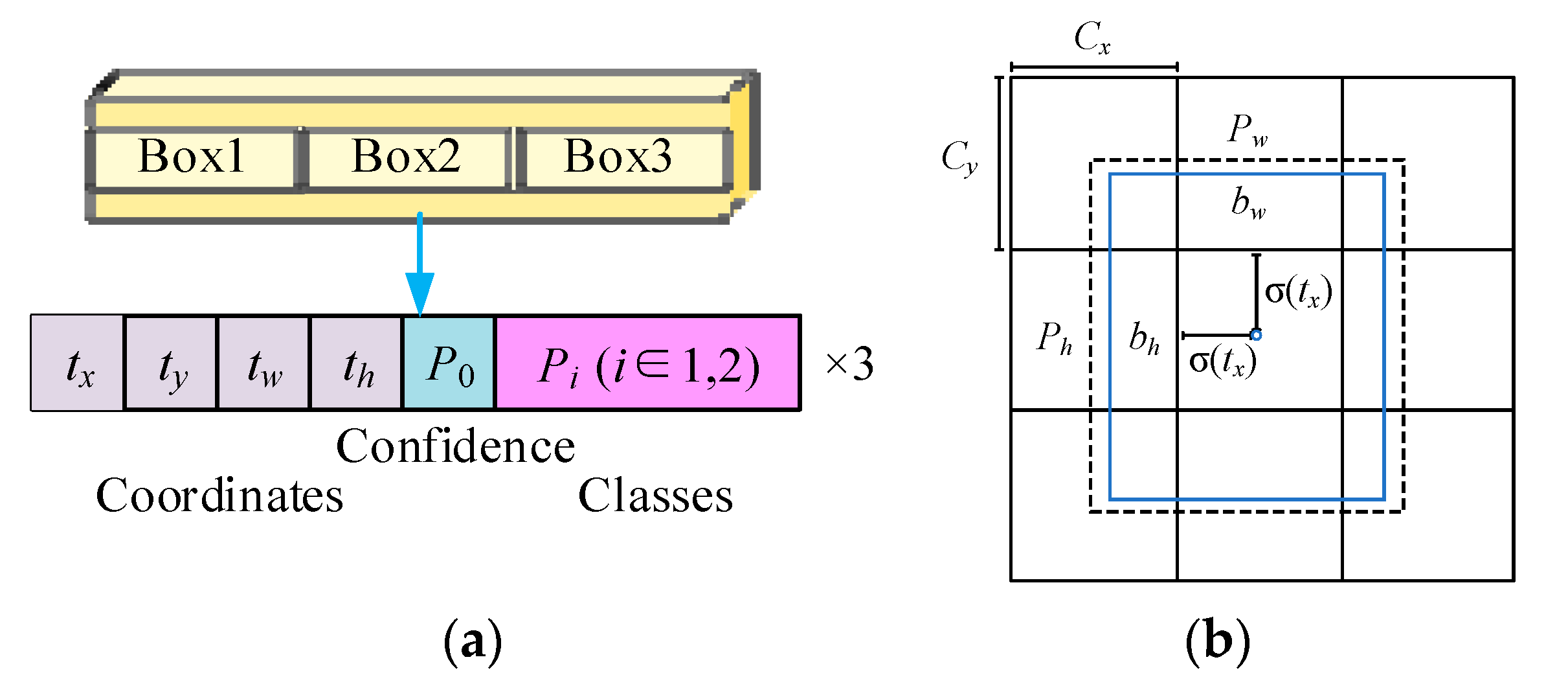
3.4. Prediction Network
4. Case Study of Transmission Line Insulator Defect Detection
4.1. Simulation Environment and Evaluation Indexes
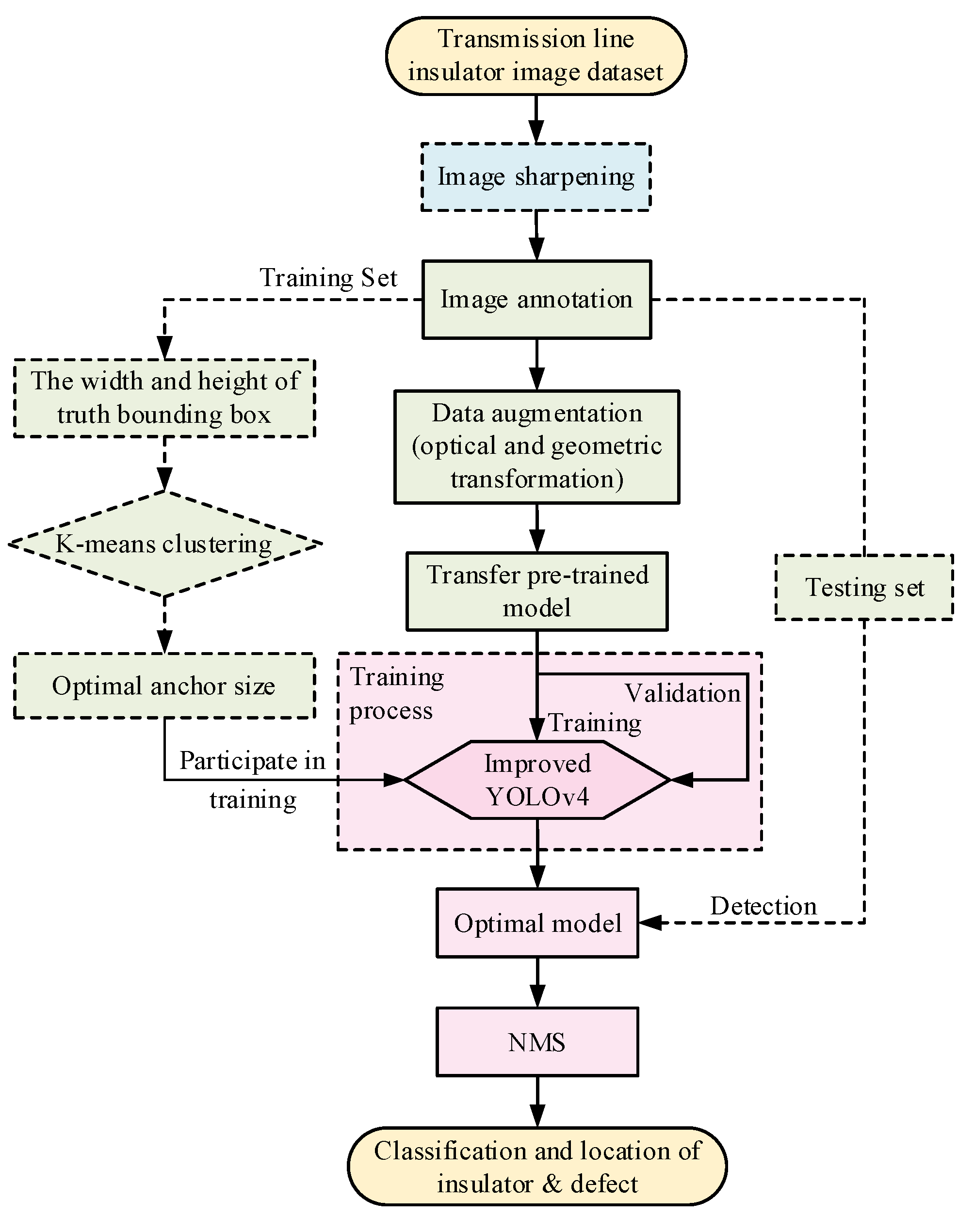
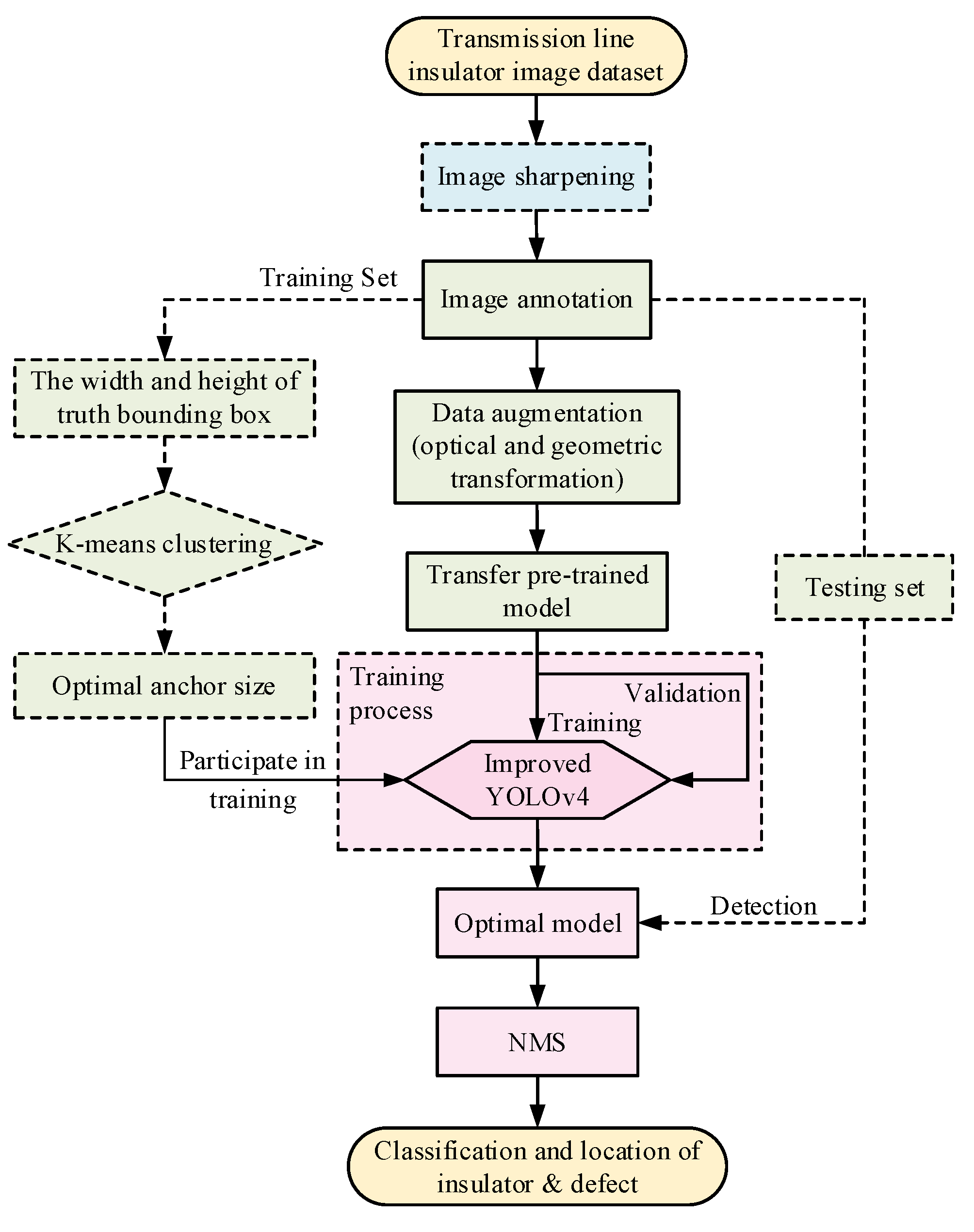
4.2. Implementation Process of Defect Detection
4.3. Result Analysis
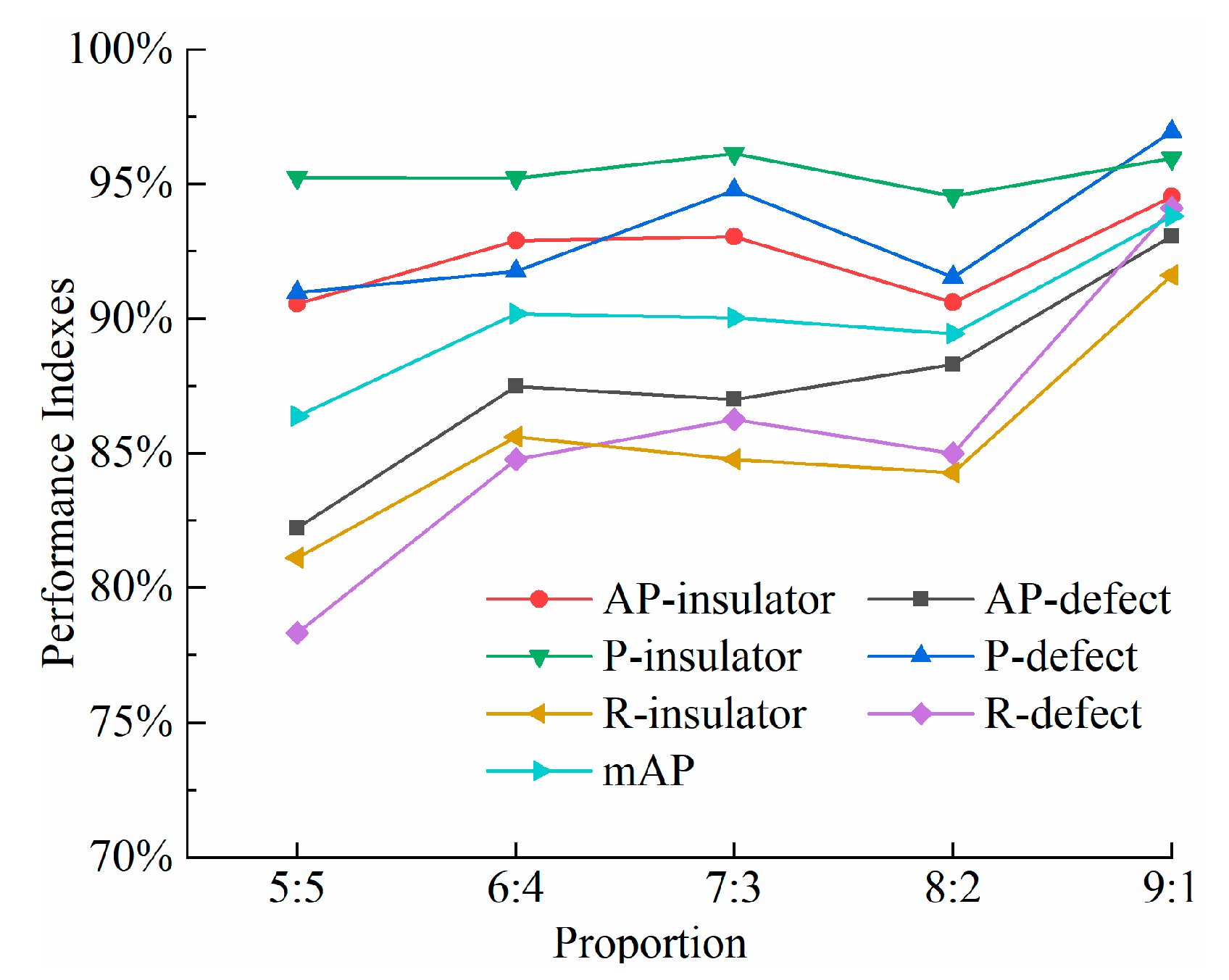
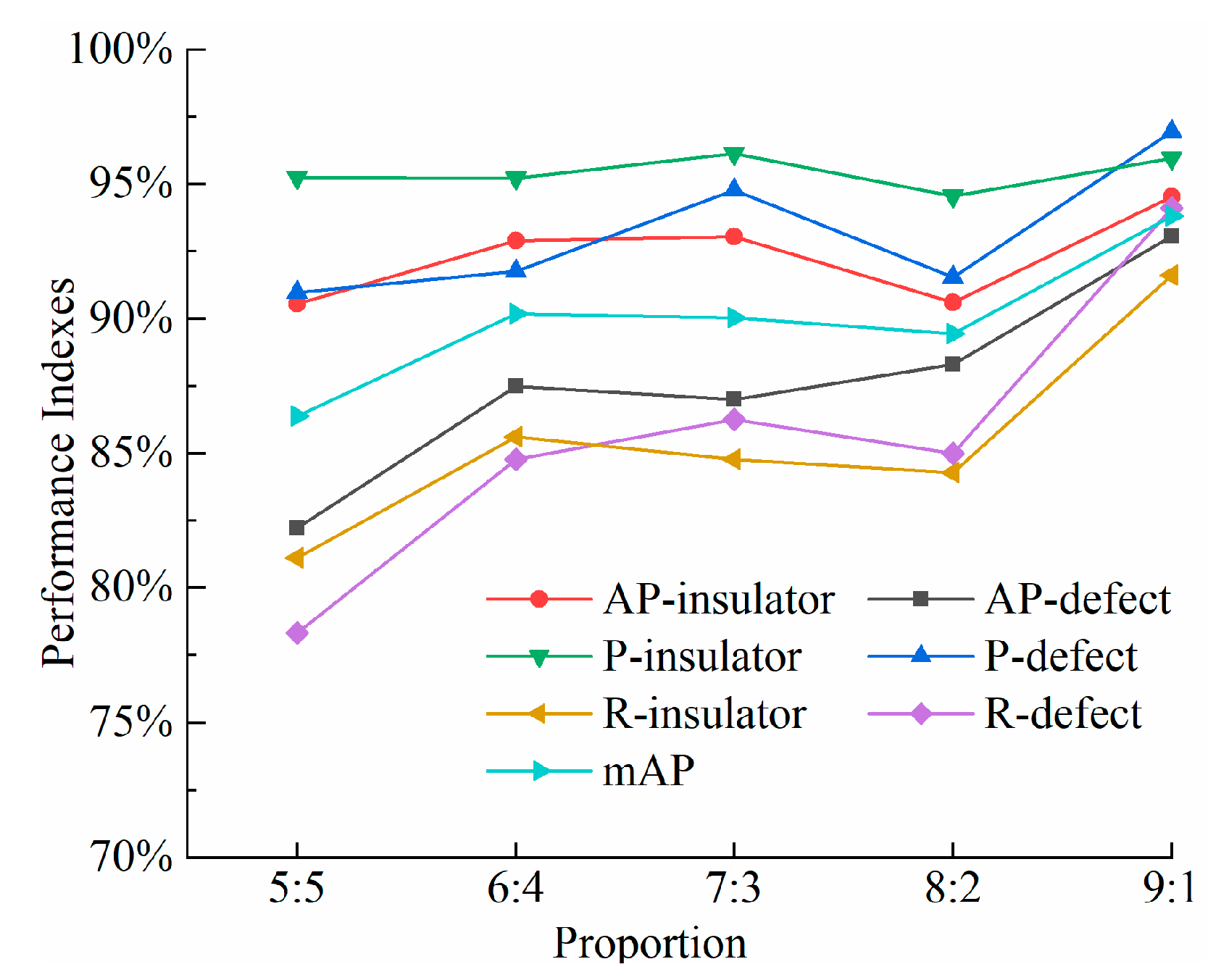
4.3.1. Detection Results with Different Proportion of Samples
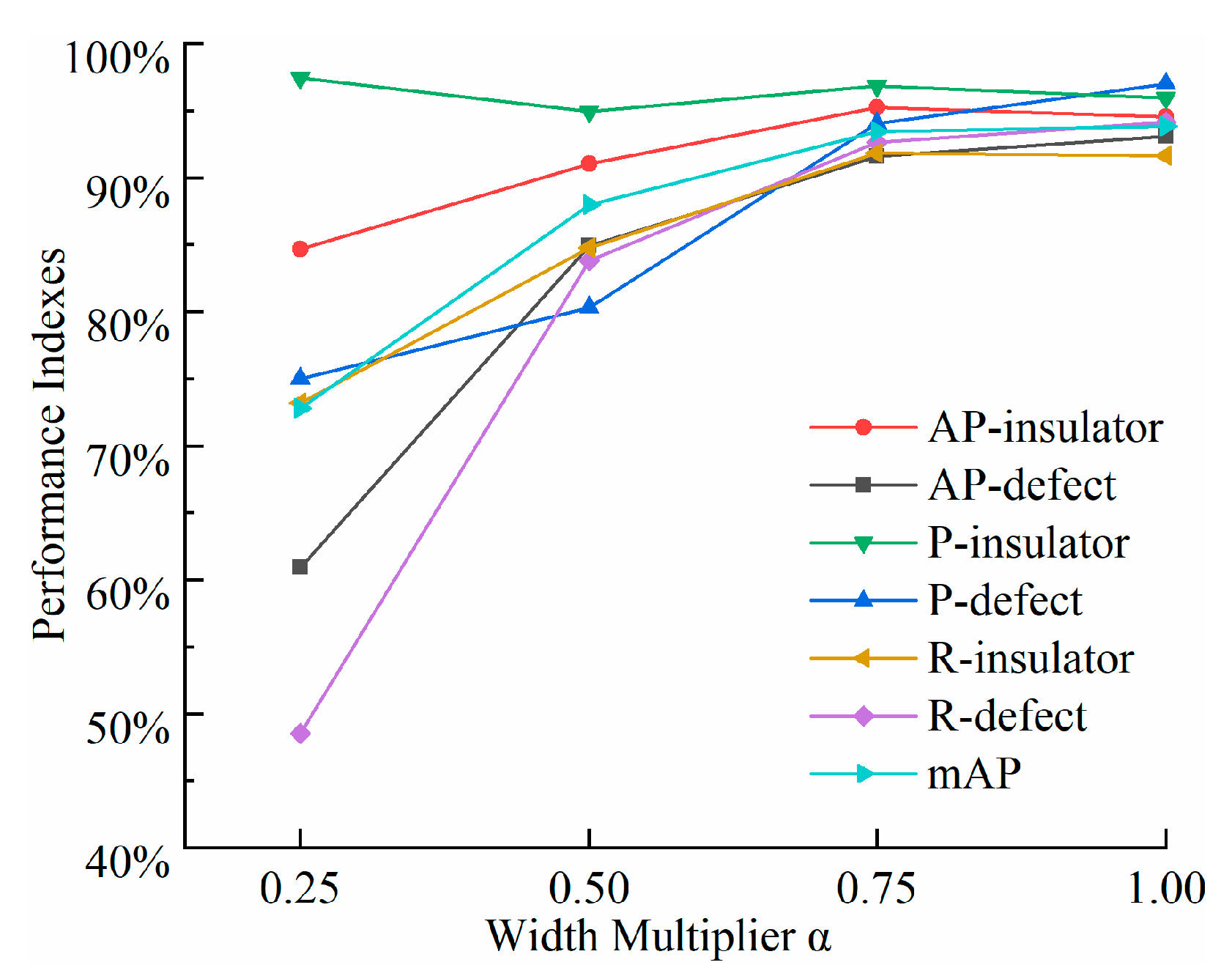
4.3.2. Detection Results with Different Width Multipliers
4.3.3. Comparison with Different Detection Algorithms
4.3.4. Influence of Image Sharpening Methods
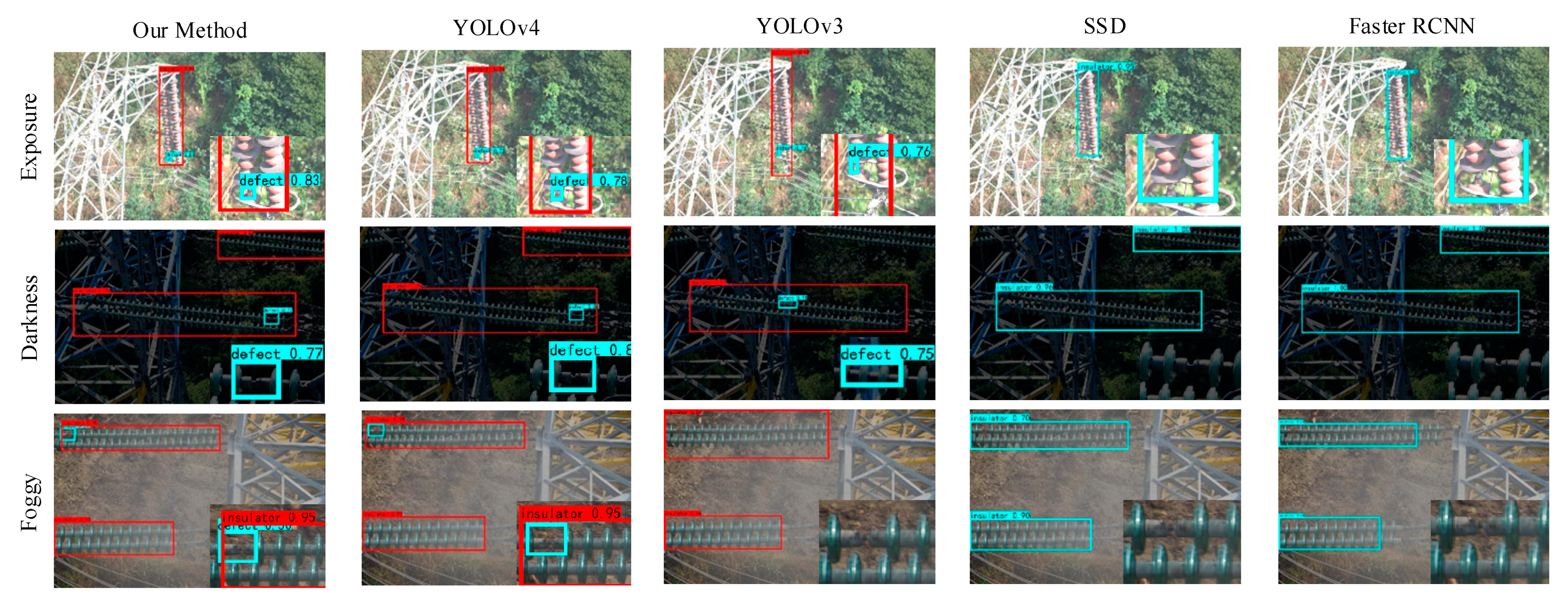
4.4. Generalization Ability and Robustness Verification
5. Conclusions
- The data augmentation method based on Graphcut segmentation is effective to expand the defective insulator images, which can avoid the problem of sample imbalance, improve the training effect and test accuracy, and therefore improve the generalization ability and robustness of the detection model.
- The lightweight YOLOv4 model improved by MobileNet, DSC-SPP, and DSC-PANet has good performance for detection of transmission line insulator defects, with a high detection accuracy and a fast detection speed. The mAP and FPS respectively reach 93.81% and 53 pictures/s, and the overall performance is better than that of Faster RCNN, SSD, YOLOv3, and YOLOv4 models.
- Laplace sharpening is able to compensate the detection accuracy of the lightweight YOLOv4 model, which increases the mAP to 97.26%, and its property is better than other sharpening methods including sobel, prewitt, and log. The proposed method is helpful for accurate detection of defective insulators on transmission lines, and applicable to meet the requirements of real-time detection in practical engineering.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, K.C.; Motai, Y.; Yoon, J.R. Acoustic fault detection technique for high-power insulators. IEEE Trans. Ind. Electron. 2017, 64, 9699–9708. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, L.; Wang, Y.; Mei, X. Insulator self-shattering detection: A deep convolutional neural network approach. Multimed. Tools Appl. 2019, 78, 10097–10112. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Katrasnik, J.; Pernus, F.; Likar, B. A survey of mobile robots for distribution power line inspection. IEEE Trans. Power Deliv. 2009, 25, 485–493. [Google Scholar] [CrossRef]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Matikainen, L.; Lehtomäki, M.; Ahokas, E.; Hyyppä, J.; Karjalainen, M.; Jaakkola, A.; Kukko, A.; Heinonen, T. Remote sensing methods for power line corridor surveys. ISPRS J. Photogramm. Remote Sens. 2016, 119, 10–31. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Ma, F.; Ge, L.; Ma, H.; Wang, H.; Mohamed, M.A. Icing-EdgeNet: A pruning lightweight edge intelligent method of discriminative driving channel for ice thickness of transmission lines. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Li, J.; Yan, D.; Luan, K.; Li, Z.; Liang, H. Deep learning-based bird’s nest detection on transmission lines using UAV imagery. Appl. Sci. 2020, 10, 6147. [Google Scholar] [CrossRef]
- Zhao, Z.; Qi, H.; Qi, Y.; Zhang, K.; Zhai, Y.; Zhao, W. Detection method based on automatic visual shape clustering for pin-missing defect in transmission lines. IEEE Trans. Instrum. Meas. 2020, 69, 6080–6091. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Liu, X.; Yuan, J.; Xu, L.; Sun, H.; Zhou, J.; Liu, X. RCNN-based foreign object detection for securing power transmission lines (RCNN4SPTL). Procedia Comput. Sci. 2019, 147, 331–337. [Google Scholar] [CrossRef]
- Hosseini, M.M.; Umunnakwe, A.; Parvania, M.; Tasdizen, T. Intelligent damage classification and estimation in power distribution poles using unmanned aerial vehicles and convolutional neural networks. IEEE Trans. Smart Grid 2020, 11, 3325–3333. [Google Scholar] [CrossRef]
- Davari, N.; Akbarizadeh, G.; Mashhour, E. Intelligent diagnosis of incipient fault in power distribution lines based on corona detection in UV-visible videos. IEEE Trans. Power Deliv. 2020, 36, 3640–3648. [Google Scholar] [CrossRef]
- Rong, S.; He, L.; Du, L.; Li, Z.; Yu, S. Intelligent detection of vegetation encroachment of power lines with advanced stereovision. IEEE Trans. Power Deliv. 2020, 36, 3477–3485. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 1486–1498. [Google Scholar] [CrossRef]
- Ling, Z.; Zhang, D.; Qiu, R.C.; Jin, Z.; Zhang, Y.; He, X.; Liu, H. An accurate and real-time method of self-blast glass insulator location based on faster R-CNN and U-net with aerial images. CSEE J. Power Energy Syst. 2019, 5, 474–482. [Google Scholar] [CrossRef]
- Liu, X.; Miao, X.; Jiang, H.; Chen, J. Box-Point Detector: A diagnosis method for insulator faults in power lines using aerial images and convolutional neural networks. IEEE Trans. Power Deliv. 2021, 36, 3765–3773. [Google Scholar] [CrossRef]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-time detection of outdoor high voltage insulators using UAV imaging. IEEE Trans. Power Deliv. 2019, 35, 1599–1601. [Google Scholar] [CrossRef]
- Wang, B.; Dong, M.; Ren, M.; Wu, Z.; Guo, C.; Zhuang, T.; Pischler, O.; Xie, J. Automatic fault diagnosis of infrared insulator images based on image instance segmentation and temperature analysis. IEEE Trans. Instrum. Meas. 2020, 69, 5345–5355. [Google Scholar] [CrossRef]
- Han, J.; Yang, Z.; Zhang, Q.; Chen, C.; Li, H.; Lai, S.; Hu, G.; Xu, C.; Xu, H.; Wang, D.; et al. A method of insulator faults detection in aerial images for high-voltage transmission lines inspection. Appli. Sci. 2019, 9, 2009. [Google Scholar] [CrossRef] [Green Version]
- Wen, Q.; Luo, Z.; Chen, R.; Yang, Y.; Li, G. Deep learning approaches on defect detection in high resolution aerial images of insulators. Sensors 2021, 21, 1033. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Shuang, F.; Gao, F.; Zhou, X.; Chen, X. ISSD: Improved SSD for insulator and spacer online detection based on UAV system. Sensors 2020, 20, 6961. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. arXiv 2021, arXiv:2111.00298. [Google Scholar] [CrossRef]
- Zha, M.; Qian, W.; Yi, W.; Hua, J. A lightweight YOLOv4-Based forestry pest detection method using coordinate attention and feature fusion. Entropy 2021, 23, 1587. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, Z.; Yan, L.; Wang, W.; Zhang, Y.; Zhang, C. Lightweight bird’s nest location recognition method based on YOLOv4-tiny. In Proceedings of the 2021 IEEE International Conference on Electrical Engineering and Mechatronics Technology (ICEEMT), Qingdao, China, 2–4 July 2021. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhu, X.; Liao, C.; Shi, D.; Kuang, Y.; Li, Y.; Zhang, Y. Detection of bird species related to transmission line faults based on lightweight convolutional neural network. IET Gener. Transm. Distrib. 2021. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. arXiv 2017, arXiv:1707.01083. [Google Scholar]
- Boykov, Y.Y.; Jolly, M. Interactive graph cuts for optimal boundary & region segmentation of objects in n-d images. In Proceedings of the 8th International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar] [CrossRef]
- Wang, Y. An enhanced scheme for interactive image segmentation. J. Univ. Sci. Technol. China 2010, 40, 129–132. [Google Scholar] [CrossRef]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.-Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | First Stage | Second Stage |
|---|---|---|
| Batchsize | 8 | 2 |
| Initial learning rate | 1 × 10−3 | 1 × 10−4 |
| Training epochs | 50 | 50 |
| IoU threshold | 0.5 | |
| NMS threshold | 0.3 | |
| Label smoothing value | 0.01 | |
| Minimum learning rate of cosine annealing | 1 × 10−6 | |
| Proportion | Training Set | Validation Set | Test Set |
|---|---|---|---|
| 5:5 | 1081 | 120 | 1202 |
| 6:4 | 1297 | 144 | 962 |
| 7:3 | 1514 | 168 | 721 |
| 8:2 | 1730 | 192 | 481 |
| 9:1 | 1946 | 216 | 241 |
| Method | AP (%) | mAP (%) | F1 Score | FPS (pictures/s) | ||
|---|---|---|---|---|---|---|
| Insulator | Defect | Insulator | Defect | |||
| Faster RCNN | 87.27 | 92.54 | 79.91 | 0.79 | 0.92 | 1 |
| SSD | 93.81 | 75.03 | 84.42 | 0.81 | 0.72 | 28 |
| YOLOv3 | 89.00 | 87.33 | 88.16 | 0.88 | 0.89 | 24 |
| YOLOv4 | 96.14 | 96.43 | 96.21 | 0.96 | 0.95 | 19 |
| Improved YOLOv4 | 94.53 | 93.09 | 93.81 | 0.96 | 0.94 | 53 |
| Sharpening Method | Insulator Location | Insulator Defect Location | mAP (%) | ||||
|---|---|---|---|---|---|---|---|
| AP (%) | P (%) | R (%) | AP (%) | P (%) | R (%) | ||
| Non-sharpening | 94.53 | 95.96 | 91.63 | 93.09 | 96.97 | 94.12 | 93.81 |
| prewitt | 94.04 | 93.91 | 89.27 | 93.56 | 93.94 | 91.18 | 93.80 |
| sobel | 94.76 | 93.42 | 91.42 | 95.57 | 98.44 | 92.65 | 95.17 |
| log | 94.32 | 95.22 | 89.70 | 93.62 | 96.97 | 94.12 | 93.97 |
| laplacian | 96.15 | 96.69 | 93.99 | 98.40 | 95.59 | 95.59 | 97.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Zhu, X.; Liao, C.; Shi, D.; Qu, W. Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model. Appl. Sci. 2022, 12, 1207. https://doi.org/10.3390/app12031207
Qiu Z, Zhu X, Liao C, Shi D, Qu W. Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model. Applied Sciences. 2022; 12(3):1207. https://doi.org/10.3390/app12031207
Chicago/Turabian StyleQiu, Zhibin, Xuan Zhu, Caibo Liao, Dazhai Shi, and Wenqian Qu. 2022. "Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model" Applied Sciences 12, no. 3: 1207. https://doi.org/10.3390/app12031207
APA StyleQiu, Z., Zhu, X., Liao, C., Shi, D., & Qu, W. (2022). Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model. Applied Sciences, 12(3), 1207. https://doi.org/10.3390/app12031207