
Transformer-Based Graph Convolutional Network for Sentiment Analysis




Abstract
:1. Introduction
- We propose a novel Sentiment Transformer Graph Convolutional Network (ST-GCN) that learns a new graph structure on a heterogeneous graph, including determining the useful connections between nodes that are not directly connected, and learning the soft selection of edge types and complex relations for learning node representation for sentiment classification. To the best of our knowledge, this is the first study to model the sentiment corpus as a heterogeneous graph and learn document and word embeddings using the proposed text graph transformer network;
- Inspired by the widespread use of positional encoding in NLP transformer models and current research on node positional features in GNNs, our model offers an easy mechanism to fuse node positional information for graph datasets using Laplacian eigenvectors;
- Results on several sentiment benchmark datasets demonstrate that our model outperforms the state-of-the-art sentiment classification methods.
2. Related Work
2.1. Sentiment Analysis
2.2. Transformer Convolutional Networks
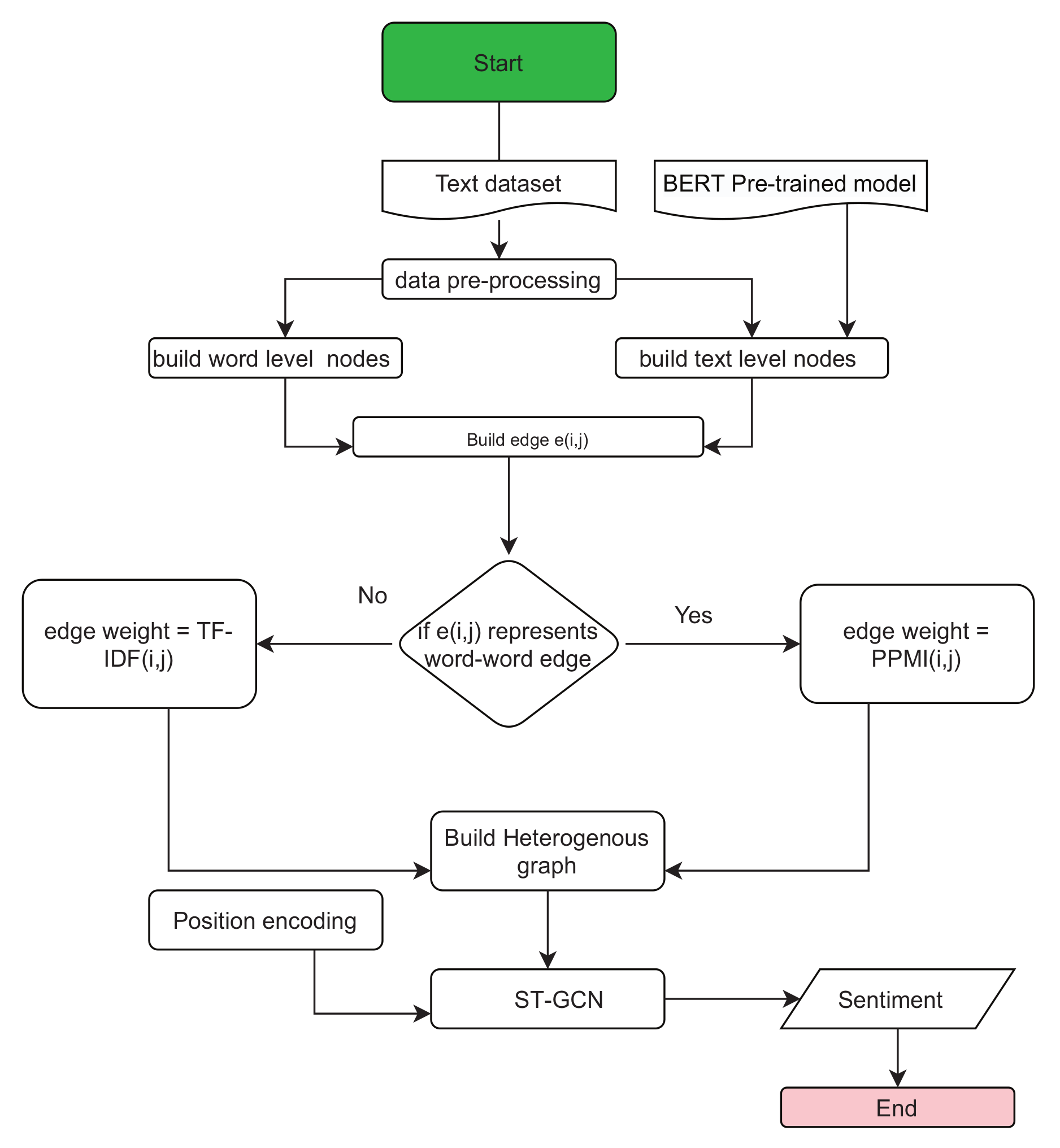
3. Method
3.1. Data Preprocessing
3.2. Textual Graph Building
3.2.1. Node Assignment
3.2.2. Edging
3.3. Embedding (Word Representation)
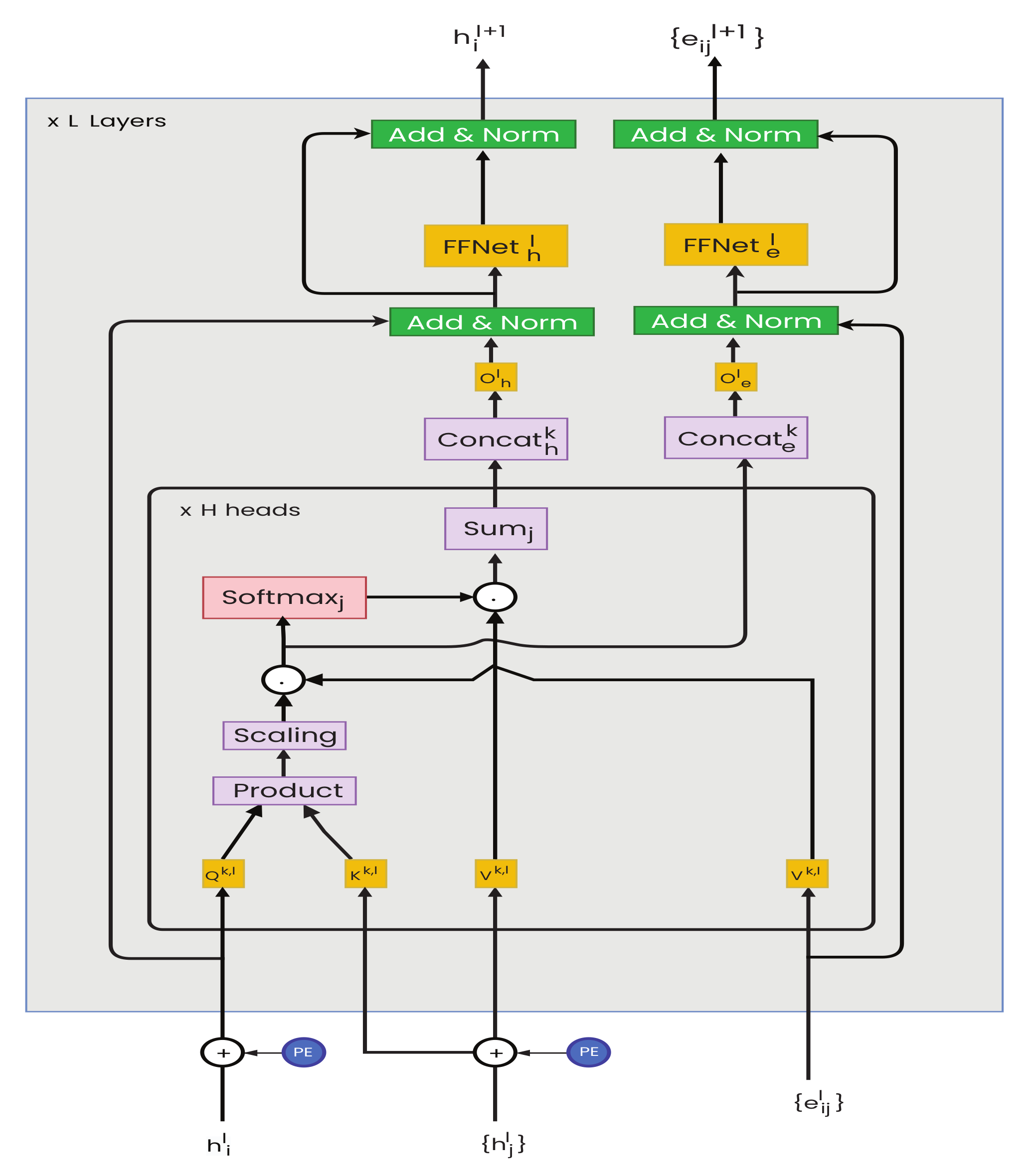
3.4. Graph Transformer Convolutional Networks
3.4.1. The Positional Encoding
3.4.2. Feature Transform Operator
3.4.3. Message Computation Operator
3.4.4. Multi-Head Operator
3.4.5. Aggregation Operator
4. Experiments
4.1. Baselines
- RGWE: Unsupervised methods, in particular neural network-based approaches, exploit unstructured data to generate and retrieve hidden sentiment information by identifying the constraints of conjunctions on the positive or negative semantic orientations [57];
- Seninfo + TF-IDF: an improved word representation method, which integrated the contribution of sentiment information into the traditional TF-IDF algorithm and generated weighted word vectors [58];
- Re(Glove): a word vector refinement model to refine pre-trained word vectors using sentiment intensity scores provided by sentiment lexicons, which improved each word vector and performed better in Sentiment Analysis [59];
- CHIM: a model in which the author represents attributes as chunk-wise important weight metrics. The authors consider four locations to inject attributes (i.e., encoding, embedding, classifier, and attention) with simple BiLSTM [60]. In our comparison, we compare with the embedding location inject since it achieved the highest accuracy score;
- HCSC: a model that combines BiLSTM and CNN as the base model and incorporates attributes by the bias-attention method, and considers the existence of cold start entities [61];
- CMA: a model that incorporates attributes using the bias-attention method with the baseline LSTM and hierarchical attention classifier [62];
- Single-layered BiLSTM: a single-layered BiLSTM model with a global pooling mechanism in which the number of parameters is reduced, leading to looser computation [63];
- LSTM/BiLSTM: Long short-term memory network and Bidirectional long short-term memory network;
- SAMF-BiLSTM: a bidirectional model with the self-attention technique and multi-channel features for sentiment classification [64];
- SMART: a robust computation framework that fine-tunes large-scale pre-trained natural language models in a principled manner. we report the usage of and the as the pre-trained models [65];
- RCNN: a model that combines RNN and CNN for text sentiment classification [66];
- BERT-pair-TextCNN: a representation framework called Bert-pair-Networks (p-BERTs) in which BERT is used to encode sentences for sentiment classification to classify a single sentence utilizing, on the top, the auxiliary sentence and feature extraction [67].
4.2. Datasets
4.3. Experiments Settings
4.4. Evaluation Criteria
4.5. Comparison Results
4.6. Ablation Study
4.6.1. Impact of Removing Less Frequent Words
4.6.2. Epoch
4.6.3. Learning Rate
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | natural language processing |
| DNN | deep neural network |
| GNN | graph neural network |
| ST-GCN | Sentiment Transformer Graph Convolutional Network |
| CNN | convolutional neural network |
| TF-IDF | Term frequency-inverse document frequency |
| PMI | point-wise mutual information |
| SVM | support vector machine |
| RNN | ecurrent neural network |
| LSTM | long short term memory |
References
- Habimana, O.; Li, Y.; Li, R.; Gu, X.; Yu, G. Sentiment analysis using deep learning approaches: An overview. Sci. China Inf. Sci. 2020, 63, 111102. [Google Scholar] [CrossRef] [Green Version]
- Anbazhagu, U.; Anandan, R. Emotional interpretation using chaotic cuckoo public sentiment variations on textual data from Twitter. Int. J. Speech Technol. 2021, 24, 281–290. [Google Scholar] [CrossRef]
- Cheng, Y.; Sun, H.; Chen, H.; Li, M.; Cai, Y.; Cai, Z.; Huang, J. Sentiment Analysis Using Multi-Head Attention Capsules With Multi-Channel CNN and Bidirectional GRU. IEEE Access 2021, 9, 60383–60395. [Google Scholar] [CrossRef]
- Lee, S.H.; Cui, J.; Kim, J.W. Sentiment analysis on movie review through building modified sentiment dictionary by movie genre. J. Intell. Inf. Syst. 2016, 22, 97–113. [Google Scholar]
- Li, Z.; Li, R.; Jin, G. Sentiment analysis of danmaku videos based on naïve bayes and sentiment dictionary. IEEE Access 2020, 8, 75073–75084. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine learning-based sentiment analysis for twitter accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef] [Green Version]
- Hew, K.F.; Hu, X.; Qiao, C.; Tang, Y. What predicts student satisfaction with MOOCs: A gradient boosting trees supervised machine learning and sentiment analysis approach. Comput. Educ. 2020, 145, 103724. [Google Scholar] [CrossRef]
- Jagdale, R.S.; Shirsat, V.S.; Deshmukh, S.N. Sentiment analysis on product reviews using machine learning techniques. In Cognitive Informatics and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 639–647. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment analysis based on deep learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- Kang, K.; Tian, S.; Yu, L. Drug Adverse Reaction Discovery Based on Attention Mechanism and Fusion of Emotional Information. Autom. Control Comput. Sci. 2020, 54, 391–402. [Google Scholar] [CrossRef]
- Peng, Z.; Song, H.; Kang, B.; Moctard, O.; He, M.; Zheng, X. Automatic textual Knowledge Extraction based on Paragraph Constitutive Relations. In Proceedings of the 6th International Conference On Systems And Informatics, ICSAI 2019, Shanghai, China, 2–4 November 2019; pp. 527–532. [Google Scholar]
- Luo, L.X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquitous Comput. 2019, 23, 405–412. [Google Scholar] [CrossRef]
- Chen, K.; Liang, B.; Ke, W.D. Sentiment analysis of Chinese Weibo based on multi-channel convolutional neural network. Comput. Res. Develop. 2018, 55, 945–957. [Google Scholar]
- Teng, Z.; Vo, D.T.; Zhang, Y. Context-sensitive lexicon features for neural sentiment analysis. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1629–1638. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Lee, C.M.; Narayanan, S.S.; Pieraccini, R. Classifying emotions in human-machine spoken dialogs. In Proceedings of the 2002 IEEE International Conference on Multimedia and Expo, ICME 2002, Lausanne, Switzerland, 26–29 August 2002; Volume I, pp. 737–740. [Google Scholar] [CrossRef] [Green Version]
- Lisetti, C.L.; Nasoz, F. Using Noninvasive Wearable Computers to Recognize Human Emotions from Physiological Signals. EURASIP J. Adv. Signal Process. 2004, 2004, 1672–1687. [Google Scholar] [CrossRef] [Green Version]
- Sharaf Al-deen, H.S.; Zeng, Z.; Al-sabri, R.; Hekmat, A. An Improved Model for Analyzing Textual Sentiment Based on a Deep Neural Network Using Multi-Head Attention Mechanism. Appl. Syst. Innov. 2021, 4, 85. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Hovy, E.H. Determining the Sentiment of Opinions. In Proceedings of the COLING 2004, 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004. [Google Scholar]
- Eguchi, K.; Lavrenko, V. Sentiment Retrieval using Generative Models. In Proceedings of the EMNLP 2006, 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; Jurafsky, D., Gaussier, É., Eds.; ACL: Stroudsburg, PA, USA, 2006; pp. 345–354. [Google Scholar]
- Duric, A.; Song, F. Feature selection for sentiment analysis based on content and syntax models. Decis. Support Syst. 2012, 53, 704–711. [Google Scholar] [CrossRef]
- Abbasi, A.; France, S.L.; Zhang, Z.; Chen, H. Selecting Attributes for Sentiment Classification Using Feature Relation Networks. IEEE Trans. Knowl. Data Eng. 2011, 23, 447–462. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khan, S.K.; Prasad, M. A comprehensive survey on word representation models: From classical to state-of-the-art word representation language models. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–35. [Google Scholar] [CrossRef]
- Singh, G. Decision Tree J48 at SemEval-2020 Task 9: Sentiment Analysis for Code-Mixed Social Media Text (Hinglish). arXiv 2020, arXiv:2008.11398. [Google Scholar]
- Liu, B. Sentiment Analysis-Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Ren, S.; Liu, S.; Zhou, M.; Ma, S. A Graph-based Coarse-to-fine Method for Unsupervised Bilingual Lexicon Induction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3476–3485. [Google Scholar] [CrossRef]
- Ghiassi, M.; Lee, S. A domain transferable lexicon set for Twitter sentiment analysis using a supervised machine learning approach. Expert Syst. Appl. 2018, 106, 197–216. [Google Scholar] [CrossRef]
- Chikersal, P.; Poria, S.; Cambria, E.; Gelbukh, A.F.; Siong, C.E. Modelling Public Sentiment in Twitter: Using Linguistic Patterns to Enhance Supervised Learning. In Computational Linguistics and Intelligent Text Processing, Proceedings of the 16th International Conference, CICLing 2015, Cairo, Egypt, 14–20 April 2015; Lecture Notes in Computer Science; Part II; Gelbukh, A.F., Ed.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9042, pp. 49–65. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallace, B.C. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Liu, J.; Chang, W.; Wu, Y.; Yang, Y. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; Kando, N., Sakai, T., Joho, H., Li, H., de Vries, A.P., White, R.W., Eds.; ACM: New York, NY, USA, 2017; pp. 115–124. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, Grand Hyatt, Seattle, Seattle, WA, USA, 18–21 October 2013; A Meeting of SIGDAT, a Special Interest Group of the ACL; ACL: Stroudsburg, PA, USA, 2013; pp. 1631–1642. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.J.; Hovy, E.H. Hierarchical Attention Networks for Document Classification. In Proceedings of the NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Ma, Q.; Yuan, C.; Zhou, W.; Hu, S. Label-Specific Dual Graph Neural Network for Multi-Label Text Classification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; ACL/IJCNLP 2021; (Volume 1: Long Papers); Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3855–3864. [Google Scholar] [CrossRef]
- Liao, W.; Zeng, B.; Liu, J.; Wei, P.; Cheng, X.; Zhang, W. Multi-level graph neural network for text sentiment analysis. Comput. Electr. Eng. 2021, 92, 107096. [Google Scholar] [CrossRef]
- Xu, S.; Xiang, Y. Frog-GNN: Multi-perspective aggregation based graph neural network for few-shot text classification. Expert Syst. Appl. 2021, 176, 114795. [Google Scholar] [CrossRef]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3442–3448. [Google Scholar] [CrossRef] [Green Version]
- Kuchaiev, O.; Ginsburg, B. Factorization tricks for LSTM networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.V.; Hinton, G.E.; Dean, J. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured Attention Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Ma, T.; Al-Sabri, R.; Zhang, L.; Marah, B.; Al-Nabhan, N. The Impact of Weighting Schemes and Stemming Process on Topic Modeling of Arabic Long and Short Texts. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 19, 1–23. [Google Scholar] [CrossRef]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. Proc. ACM Program. Lang. 2019, 3, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Multi-task learning model based on multi-scale CNN and LSTM for sentiment classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Picasso, A.; Merello, S.; Ma, Y.; Oneto, L.; Cambria, E. Technical analysis and sentiment embeddings for market trend prediction. Expert Syst. Appl. 2019, 135, 60–70. [Google Scholar] [CrossRef]
- Wu, Z.; Dai, X.Y.; Yin, C.; Huang, S.; Chen, J. Improving review representations with user attention and product attention for sentiment classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Murphy, R.L.; Srinivasan, B.; Rao, V.A.; Ribeiro, B. Relational Pooling for Graph Representations. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4663–4673. [Google Scholar]
- You, J.; Ying, R.; Leskovec, J. Position-aware Graph Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7134–7143. [Google Scholar]
- Dwivedi, V.P.; Joshi, C.K.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking Graph Neural Networks. arXiv 2020, arXiv:2003.00982. [Google Scholar]
- Srinivasan, B.; Ribeiro, B. On the Equivalence between Positional Node Embeddings and Structural Graph Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, Y.; Huang, G.; Li, J.; Li, H.; Zhou, Y.; Jiang, H. Refined Global Word Embeddings Based on Sentiment Concept for Sentiment Analysis. IEEE Access 2021, 9, 37075–37085. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Hou, Y.; Song, Y. A position-aware bidirectional attention network for aspect-level sentiment analysis. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 774–784. [Google Scholar]
- Amplayo, R.K. Rethinking attribute representation and injection for sentiment classification. arXiv 2019, arXiv:1908.09590. [Google Scholar]
- Amplayo, R.K.; Kim, J.; Sung, S.; Hwang, S.W. Cold-start aware user and product attention for sentiment classification. arXiv 2018, arXiv:1806.05507. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H.; Sun, X. Cascading multiway attentions for document-level sentiment classification. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, (Volume 1: Long Papers). Taipei, Taiwan, 27 November–1 December 2017; pp. 634–643. [Google Scholar]
- Hameed, Z.; Garcia-Zapirain, B. Sentiment classification using a single-layered BiLSTM model. IEEE Access 2020, 8, 73992–74001. [Google Scholar] [CrossRef]
- Li, W.; Qi, F.; Tang, M.; Yu, Z. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification. Neurocomputing 2020, 387, 63–77. [Google Scholar] [CrossRef]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. arXiv 2019, arXiv:1911.03437. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Wang, Z.; Wu, H.; Liu, H.; Cai, Q.H. Bert-Pair-Networks for Sentiment Classification. In Proceedings of the 2020 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 2 December 2020; pp. 273–278. [Google Scholar]
- Poursepanj, H.; Weissbock, J.; Inkpen, D. uOttawa: System description for semeval 2013 task 2 sentiment analysis in twitter. In Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, Georgia, 14–15 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 380–383. [Google Scholar]
- Jamadi Khiabani, P.; Basiri, M.E.; Rastegari, H. An improved evidence-based aggregation method for sentiment analysis. J. Inf. Sci. 2020, 46, 340–360. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Valid | Test | Total | #Labels | Labels | Balance |
|---|---|---|---|---|---|---|---|
| SemEval | 9684 | 1654 | 3813 | 15,151 | 3 | positive/negative/neutral | No |
| SST2 | 6920 | 872 | 1821 | 9613 | 2 | positive/negative | No |
| IMDB | 40,000 | 5000 | 5000 | 5000 | 2 | positive/negative | Yes |
| Yelp 2014 (Restuarant) | 3072 | 384 | 384 | 3840 | 5 | very positive/positive/neutral/negative/very negative | Yes |
| Hyperparameter | SST-B | IMDB | SemEval | Yelp |
|---|---|---|---|---|
| Epochs | 200 | 200 | 200 | 200 |
| learning rate | 0.2 | 0.05 | 0.001 | 0.05 |
| Optimization function | Mini-Batch Gradient Desent | |||
| loss function | Cross Entropy Loss function | |||
| Dropout | 0.6 | 0.5 | 0.6 | 0.5 |
| Batch Size | 512 | 512 | 512 | 512 |
| Weight Decay | 0.0005 | 0.00005 | 0.00001 | 0.00001 |
| Hidden layer unit | 32 | 32 | 64 | 16 |
| Method | SST-B | IMDB | Yelp 2014 |
|---|---|---|---|
| CHIM | – | 54.2 | – |
| HCSC | – | 56.4 | 69.2 |
| CMA | – | 54.0 | 67.6 |
| Single-layered BiLSTM | 85.78 | 90.585 | – |
| SAMF-BiLSTM-D | 89.7 | 48.9 | – |
| LSTM | 84.9 | 37.8 | 53.9 |
| BiLSTM | 91.24 | 83.02 | – |
| RCNN | 93.96 | 84.70 | – |
| BERT_pair_RCNN | 95.00 | – | – |
| Bert | 90.9 | – | – |
| SMART_BERT | 90.0 | – | – |
| SMART_RoBERTa | 92.8 | – | – |
| SGTN (ours) | 95.43 | 94.94 | 72.7 |
| Method | SemEval | SST-B | IMDB | Yelp 2014 |
|---|---|---|---|---|
| Re(Glove) | 68.2 | 89.5 | 89.6 | 46.1 |
| Seninfo + TF-IDF | 66.7 | 88.8 | 89.0 | 45.4 |
| RGWE | 69.1 | 89.68 | 90.1 | 46.9 |
| BiLSTM | – | 91.16 | 83.05 | – |
| RCNN | – | 93.88 | 84.72 | – |
| SGTN (ours) | 74.12 | 95.11 | 93.52 | 50.2 |
| Method | SST-B | IMDB | Yelp 2014 |
|---|---|---|---|
| SGTN with less Freq words | 95.24 | 94.53 | 72.3 |
| SGTN without less Freq words | 95.43 | 94.95 | 72.7 |
| SGTN with NLTK Stopwords | 93.43 | 93.01 | 71.10 |
| Method | SemEval | SST-B | IMDB | Yelp 2014 |
|---|---|---|---|---|
| SGTN with less Freq words | 74.01 | 94.91 | 93.72 | 49.50 |
| SGTN without less Freq words | 74.12 | 95.11 | 93.52 | 50.2 |
| SGTN with NLTK Stopwords | 72.46 | 93.09 | 92.84 | 48.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlBadani, B.; Shi, R.; Dong, J.; Al-Sabri, R.; Moctard, O.B. Transformer-Based Graph Convolutional Network for Sentiment Analysis. Appl. Sci. 2022, 12, 1316. https://doi.org/10.3390/app12031316
AlBadani B, Shi R, Dong J, Al-Sabri R, Moctard OB. Transformer-Based Graph Convolutional Network for Sentiment Analysis. Applied Sciences. 2022; 12(3):1316. https://doi.org/10.3390/app12031316
Chicago/Turabian StyleAlBadani, Barakat, Ronghua Shi, Jian Dong, Raeed Al-Sabri, and Oloulade Babatounde Moctard. 2022. "Transformer-Based Graph Convolutional Network for Sentiment Analysis" Applied Sciences 12, no. 3: 1316. https://doi.org/10.3390/app12031316
APA StyleAlBadani, B., Shi, R., Dong, J., Al-Sabri, R., & Moctard, O. B. (2022). Transformer-Based Graph Convolutional Network for Sentiment Analysis. Applied Sciences, 12(3), 1316. https://doi.org/10.3390/app12031316