
Evaluation of Tacotron Based Synthesizers for Spanish and Basque



Abstract
:1. Introduction
2. Materials and Methods
2.1. Training Dataset
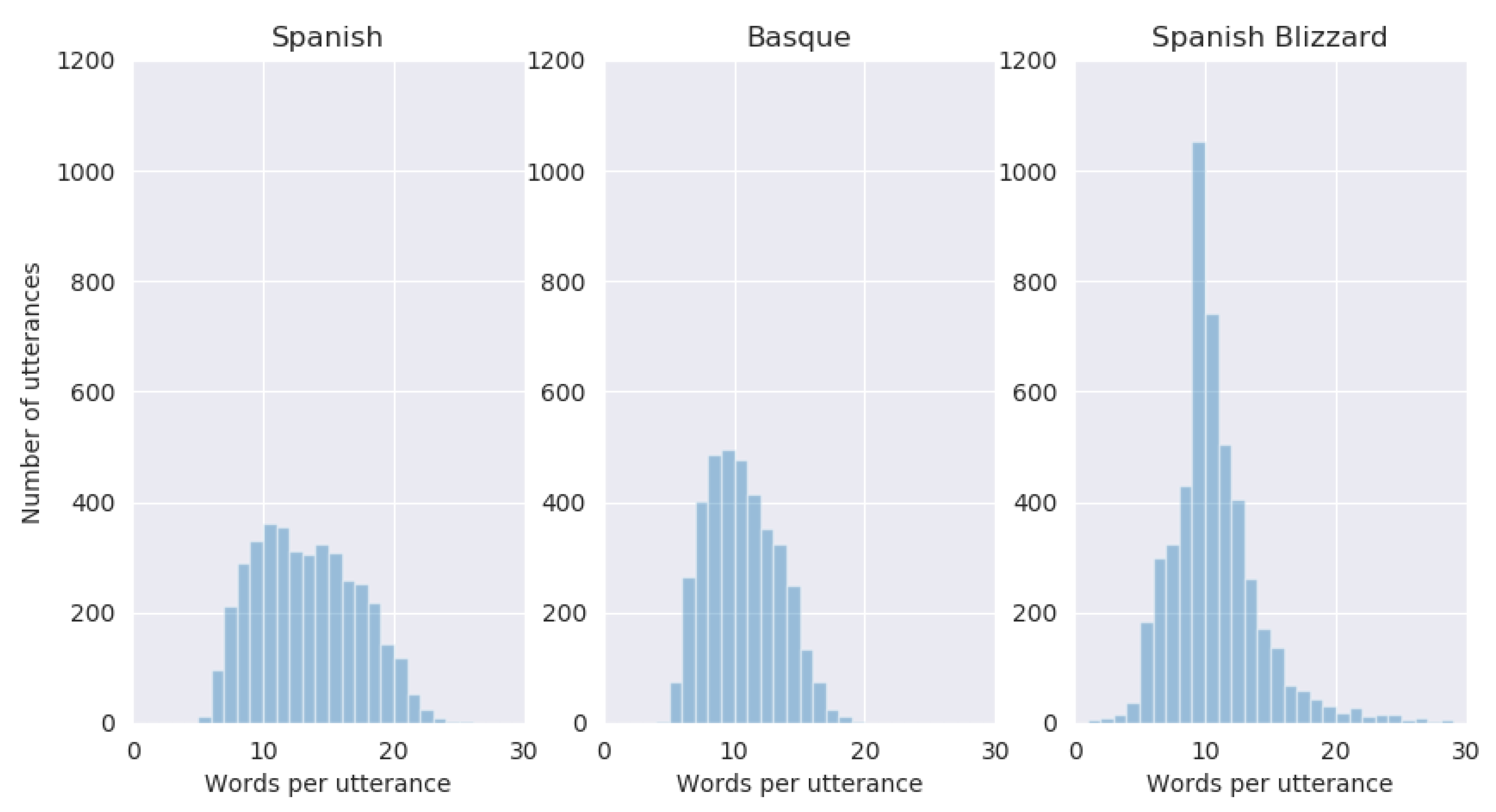
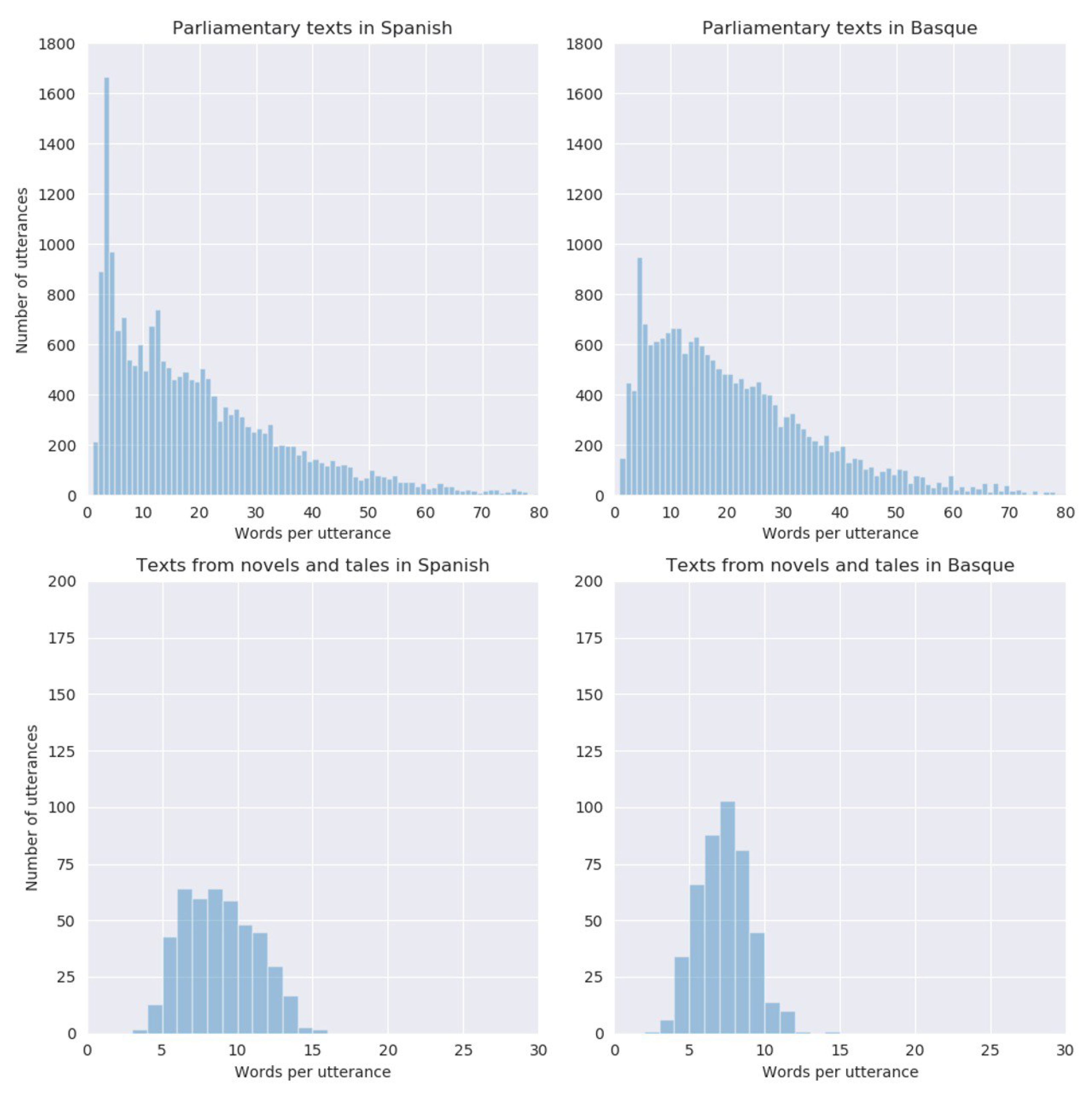
2.2. Testing Datasets
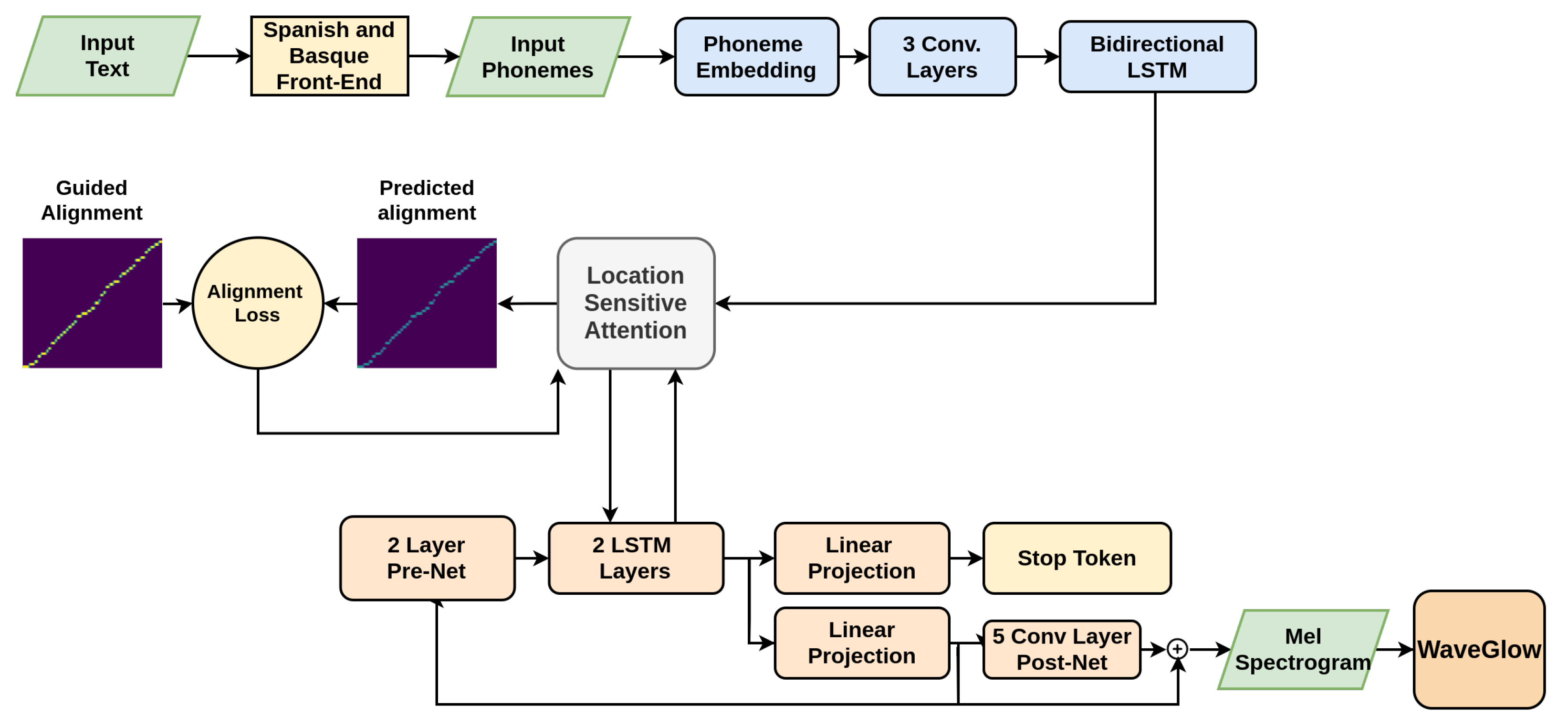
2.3. Tacotron 2
- The encoder handles and transforms the input of the acoustic model. In the encoder the input sentence is converted into a hidden feature representation (that is later consumed by the decoder). First, each character of the input sequence is represented by a 512-dimensional vector using character embedding. The sequence of vectors is then fed into a three-convolutional-layer stack that models the long-term relationships between the input characters. Finally, using the output obtained from the last convolutional layer, a bidirectional Long short-term memory (LSTM) network generates the encoder hidden output (a vector of 512 × T, being T the length of the input sequence).
- The attention mechanism consumes the output of the encoder to produce a context vector at each decoding step. This attention mechanism is one of the most important parts of the model. It is at this point where the alignment between the input text and the frame-level acoustic features is learnt. The context vector provides the decoder with the necessary information to refer to the corresponding part of the encoder sequence at each decoding step. Tacotron 2 uses a custom location-sensitive attention mechanism [25], with an additional feature that is computed from the cumulative attention weights of the previous decoding steps.
- The decoder of Tacotron 2 is a recurrent neural network that predicts one frame at each decoding step in an auto-regressive fashion. During training, the decoder makes use of the context vector and the previous ground truth frame to compute the current step frame. This way of training the network is referred to as “teacher-forcing”, and it is employed to ensure that each predicted frame is correctly aligned with the features of the target audio. During inference, as the ground truth frames are not available, the decoder uses the frame computed in the previous decoding step. The architecture of the decoder consists on a 2 layered pre-net, a 2 layer LSTM network and a convolutional post-net. The prediction from each decoding step is passed through the pre-net and then concatenated to the context vector. The resulting concatenation is fed into the two-layer LSTM. This output is again concatenated to the context vector and then passed through two different projection layers: one that predicts the stop token, and another one that predicts the target spectrogram frame. The final mel spectrogram is a combination of the whole spectrogram and a residual obtained in an ending convolutional post-net.
2.4. Waveglow
3. Methodology
3.1. Baseline
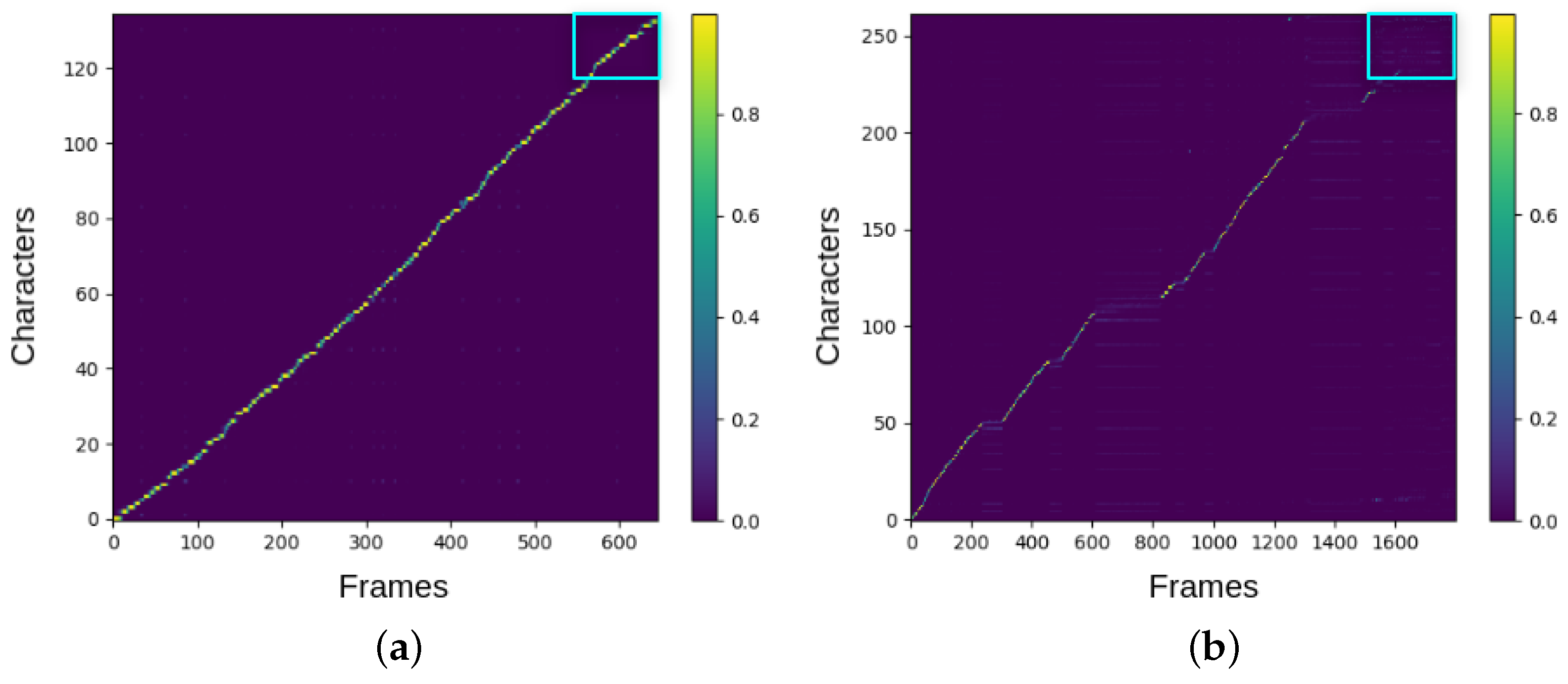
3.2. Error Detection Strategy
3.3. Robustness Improvement
3.4. Neural Vocoder
4. Evaluation
4.1. Robustness
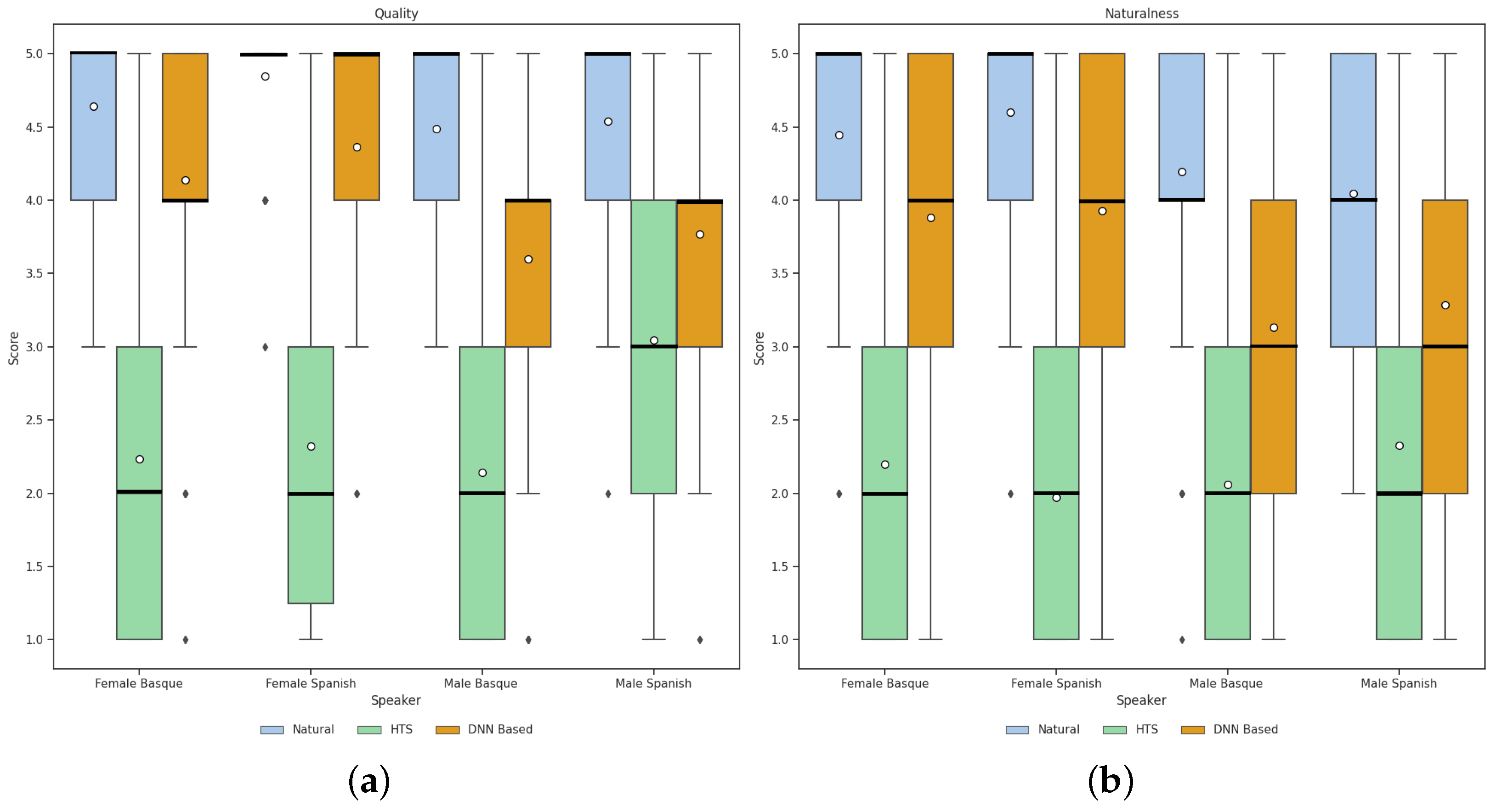
4.2. Naturalness and Quality
- Signals from the natural reference speech.
- Synthetic signals obtained using an HMM-based speech synthesis sytem (HTS) based TTS system for Spanish and Basque developed in our research group (https://sourceforge.net/projects/ahotts/ (accessed on 20 December 2021)) [21].
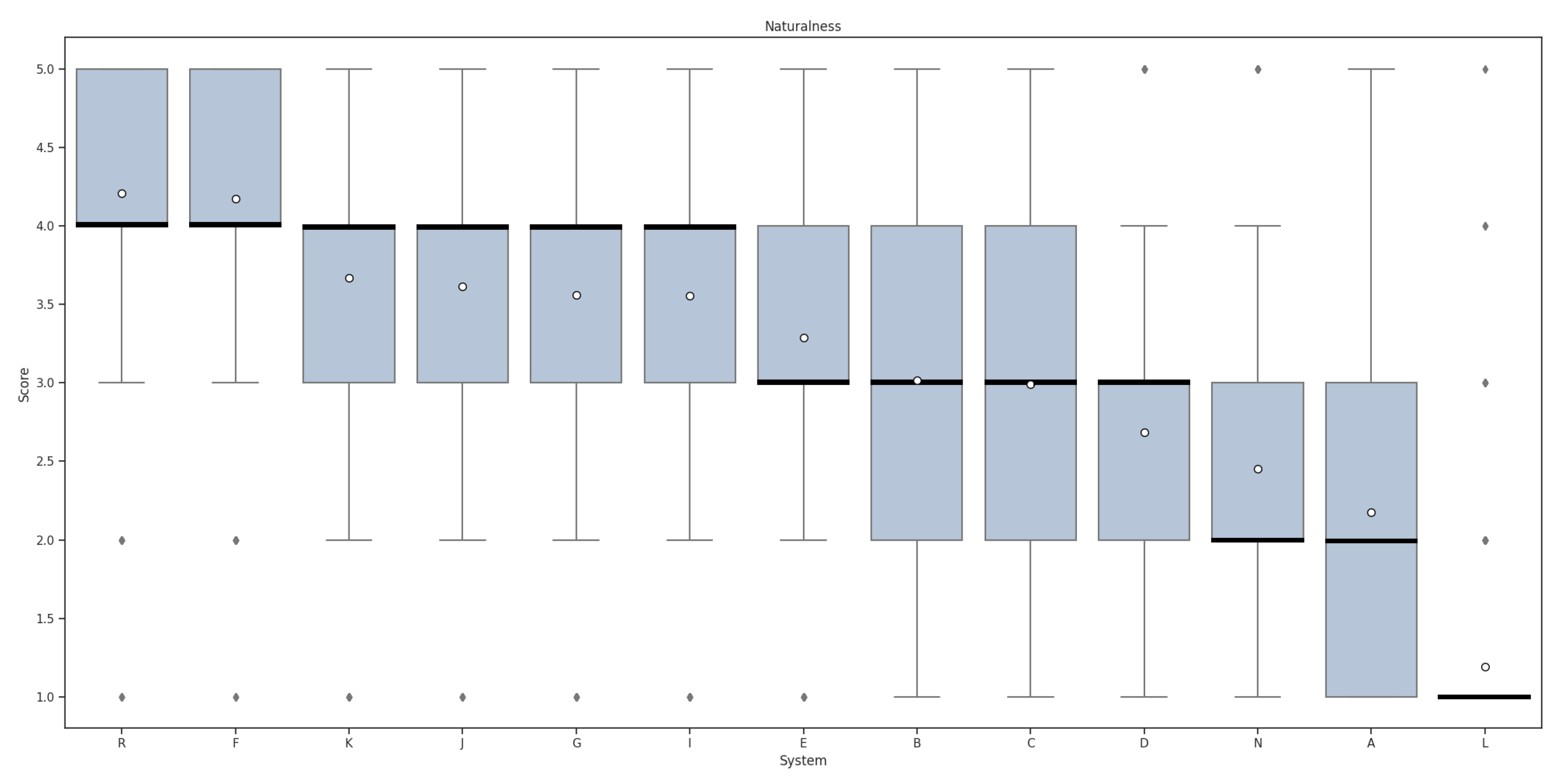
4.3. NISQA
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Black, A.W.; Taylor, P. Automatically Clustering Similar Units for Unit Selection Speech Synthesis. In Proceedings of the EUROSPEECH 1997, Rhodes, Greece, 22–25 September 1997; pp. 601–604. [Google Scholar]
- Campbell, N.; Black, A.W. Prosody and the Selection of Source Units for Concatenative Synthesis. In Progress in Speech Synthesis; Springer: New York, NY, USA, 1997; pp. 279–292. [Google Scholar]
- Wu, Y.J.; Wang, R.H. Minimum generation error training for HMM-based speech synthesis. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing Proceedings (ICASSP), Toulouse, France, 14–19 May 2006; Volume 1. [Google Scholar]
- Zen, H.; Tokuda, K.; Black, A.W. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Ze, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7962–7966. [Google Scholar]
- Fan, Y.; Qian, Y.; Xie, F.L.; Soong, F.K. TTS synthesis with bidirectional LSTM based recurrent neural networks. In Proceedings of the INTERSPEECH 2014, Singapore, 14–18 September 2014; pp. 1964–1968. [Google Scholar] [CrossRef]
- Qian, Y.; Fan, Y.; Hu, W.; Soong, F.K. On the training aspects of deep neural network (DNN) for parametric TTS synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3829–3833. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Arık, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep voice: Real-time neural text-to-speech. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 195–204. [Google Scholar]
- Gibiansky, A.; Arik, S.Ö.; Diamos, G.F.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep Voice 2: Multi-Speaker Neural Text-to-Speech. In Proceedings of the Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep voice 3: 2000-speaker neural text-to-speech. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 214–217. [Google Scholar]
- Sotelo, J.; Mehri, S.; Kumar, K.; Santos, J.F.; Kastner, K.; Courville, A.; Bengio, Y. Char2wav: End-to-end speech synthesis. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–6. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3617–3621. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1 × 1 convolutions. Adv. Neural Inf. Process. Syst. 2018, 31, 10215–10224. [Google Scholar]
- Chung, Y.A.; Wang, Y.; Hsu, W.N.; Zhang, Y.; Skerry-Ryan, R.J. Semi-supervised Training for Improving Data Efficiency in End-to-end Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6940–6944. [Google Scholar]
- Zhu, X.; Zhang, Y.; Yang, S.; Xue, L.; Xie, L. Pre-alignment guided attention for improving training efficiency and model stability in end-to-end speech synthesis. IEEE Access 2019, 7, 65955–65964. [Google Scholar] [CrossRef]
- Mittag, G.; Möller, S. Deep Learning Based Assessment of Synthetic Speech Naturalness. In Proceedings of the INTERSPEECH 2020, Shanghai, China, 25–29 October 2020; pp. 1748–1752. [Google Scholar]
- Garcia, V.; Hernaez, I.; Navas, E. Implementation of neural network based synthesizers for Spanish and Basque. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 225–229. [Google Scholar] [CrossRef]
- Erro, D.; Sainz, I.; Luengo, I.; Odriozola, I.; Sánchez, J.; Saratxaga, I.; Navas, E.; Hernáez, I. HMM-based speech synthesis in Basque language using HTS. In Proceedings of the FALA. RTTH, Vigo, Spain, 10–12 November 2010; pp. 67–70. [Google Scholar]
- Wells, J.; Barry, W.; Grice, M.; Fourcin, A.; Gibbon, D. Standard Computer-Compatible Transcription. Esprit Project 2589 (SAM), Doc. no. SAM-UCL-037, 1992; Volume 37. Available online: https://www.phon.ucl.ac.uk/home/sampa/ (accessed on 20 December 2020).
- Etchegoyhen, T.; Arzelus, H.; Gete, H.; Alvarez, A.; Hernaez, I.; Navas, E.; González-Docasal, A.; Osácar, J.; Benites, E.; Ellakuria, I.; et al. MINTZAI: Sistemas de Aprendizaje Profundo E2E para Traducción Automática del Habla MINTZAI: End-to-end Deep Learning for Speech Translation. Soc. Española Para Proces. Del Leng. Nat. 2020, 65, 97–100. [Google Scholar]
- Ren, Y.; Qin, T.; Ruan, Y.; Zhao, S.; Liu, T.Y.; Tan, X.; Zhao, Z. FastSpeech: Fast, robust and controllable text to speech. arXiv 2019, arXiv:cs.CL/1905.09263. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2015; pp. 577–585. [Google Scholar]
- Kobyzev, I.; Prince, S.; Brubaker, M. Normalizing flows: An introduction and review of current methods. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3964–3979. [Google Scholar] [CrossRef] [PubMed]
- Ito, K.; Johnson, L. The LJ Speech Dataset, v1.1. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 20 December 2020).
- He, M.; Deng, Y.; He, L. Robust Sequence-to-Sequence Acoustic Modeling with Stepwise Monotonic Attention for Neural TTS. In Proceedings of the INTERSPEECH 2019, ISCA, Graz, Austria, 15–19 September 2019; Volume 2019, pp. 1293–1297. [Google Scholar]
- Battenberg, E.; Skerry-Ryan, R.J.; Mariooryad, S.; Stanton, D.; Kao, D.; Shannon, M.; Bagby, T. Location-Relative Attention Mechanisms for Robust Long-Form Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6194–6198. [Google Scholar]
- Liu, R.; Sisman, B.; Li, J.; Bao, F.; Gao, G.; Li, H. Teacher-student training for robust tacotron-based tts. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6274–6278. [Google Scholar]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal forced aligner: Trainable text-speech alignment using kaldi. In Proceedings of the INTERSPEECH 2017, ISCA, Stockholm, Sweden, 20–24 August 2017; pp. 498–502. [Google Scholar]
- NVIDIA. 2020. Available online: https://ngc.nvidia.com/catalog/models/nvidia:waveglow_ljs_256channels (accessed on 10 March 2020).
- NVIDIA. 2020. Available online: https://drive.google.com/file/d/1rpK8CzAAirq9sWZhe9nlfvxMF1dRgFbF/view (accessed on 12 January 2021).
- Ling, Z.H.; Zhou, X.; King, S. The Blizzard Challenge 2021. In Proceedings of the Blizzard Challenge Workshop 2021, Online, 23 October 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spanish | Basque | Spanish Blizzard | |
|---|---|---|---|
| Number of utterances | 3993 | 3795 | 4920 |
| Number of words | 51,301 | 38,339 | 50,732 |
| Unique words | 10,687 | 12,352 | 8661 |
| Words in shortest utterance | 4 | 4 | 1 |
| Words in longest utterance | 26 | 19 | 50 |
| Avg. words per utterance |
| Parliamentary Texts | Texts from Novels and Tales | |||
|---|---|---|---|---|
| Spanish | Basque | Spanish | Basque | |
| Number of utterances | 20,000 | 20,000 | 450 | 450 |
| Number of words | 425,467 | 389,252 | 3748 | 3064 |
| Unique words | 10,704 | 18,563 | 1378 | 1703 |
| Words in shortest utterance | 1 | 1 | 3 | 2 |
| Words in longest utterance | 268 | 133 | 15 | 14 |
| Avg. words per utterance | ||||
| Baseline | Taco-PAG | Improvement | |
|---|---|---|---|
| Female Spanish | 1791 | 1103 | 38.41% |
| Female Basque | 2596 | 1941 | 25.23% |
| Male Spanish | 1077 | 95 | 91.18% |
| Male Basque | 1206 | 274 | 71.31% |
| Blizzard Spanish | 361 | 90 | 75.07% |
| HTS Based | Taco-PAG+WG-MA | Taco-PAG+WG-BA | |
|---|---|---|---|
| Female Spanish | 4.20 ± 0.04 | ||
| Female Basque | |||
| Male Spanish | |||
| Male Basque | |||
| Blizzard Spanish | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García, V.; Hernáez, I.; Navas, E. Evaluation of Tacotron Based Synthesizers for Spanish and Basque. Appl. Sci. 2022, 12, 1686. https://doi.org/10.3390/app12031686
García V, Hernáez I, Navas E. Evaluation of Tacotron Based Synthesizers for Spanish and Basque. Applied Sciences. 2022; 12(3):1686. https://doi.org/10.3390/app12031686
Chicago/Turabian StyleGarcía, Víctor, Inma Hernáez, and Eva Navas. 2022. "Evaluation of Tacotron Based Synthesizers for Spanish and Basque" Applied Sciences 12, no. 3: 1686. https://doi.org/10.3390/app12031686
APA StyleGarcía, V., Hernáez, I., & Navas, E. (2022). Evaluation of Tacotron Based Synthesizers for Spanish and Basque. Applied Sciences, 12(3), 1686. https://doi.org/10.3390/app12031686