
A Serial Attention Frame for Multi-Label Waste Bottle Classification


 ,
, 
Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- A CNN is used to recognize waste bottles.
- (2)
- A serial attention frame, mainly including channel attention, spatial attention, and self-attention mechanisms, is used to extract the salient features of diverse types to improve the multi-label classification of waste bottles.
- (3)
- Image datasets of waste bottles are collected.
2. Related Work
2.1. Bottle Classifications
2.2. Label Semantic Relationships
2.3. Object Proposals
2.4. Attention Mechanisms
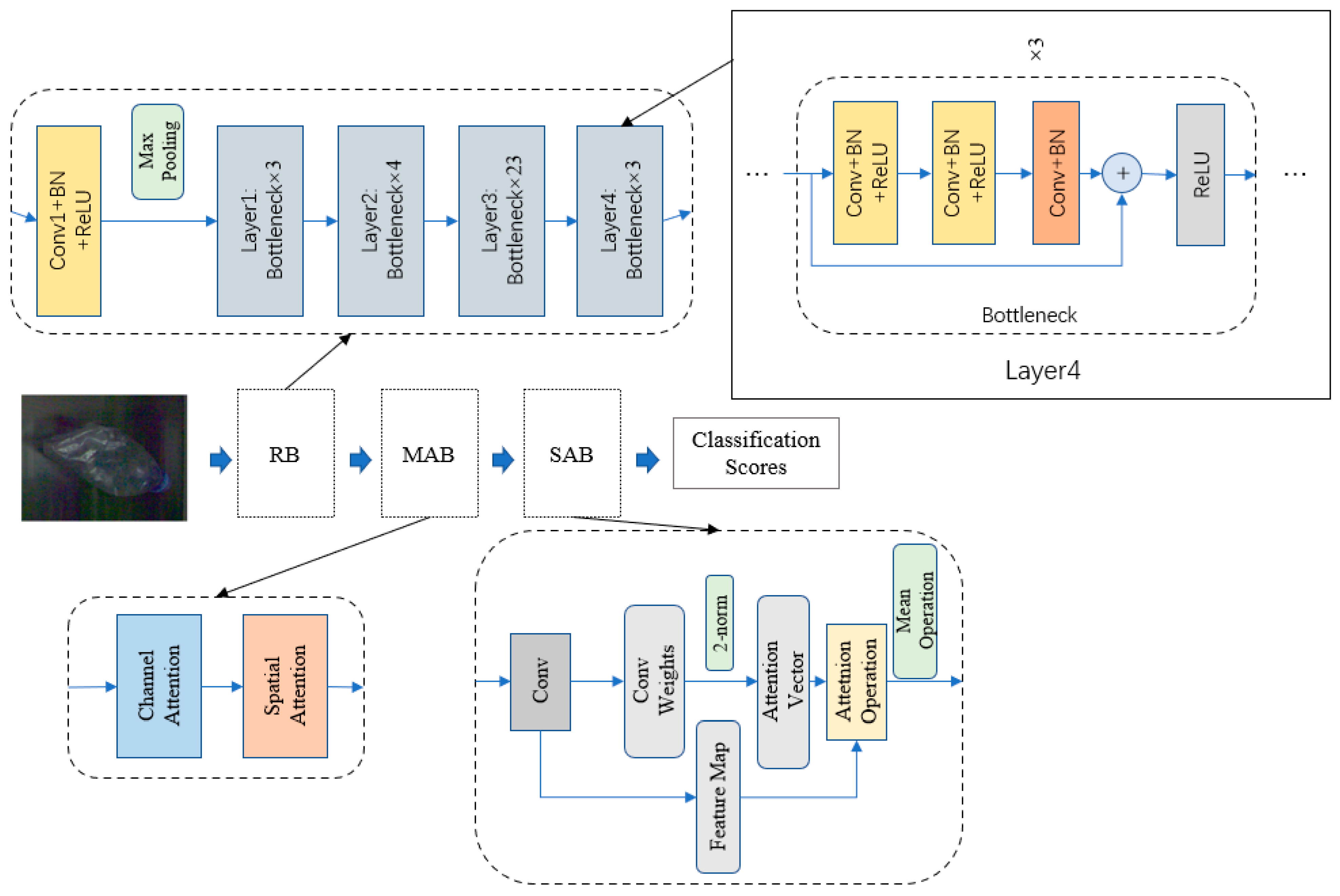
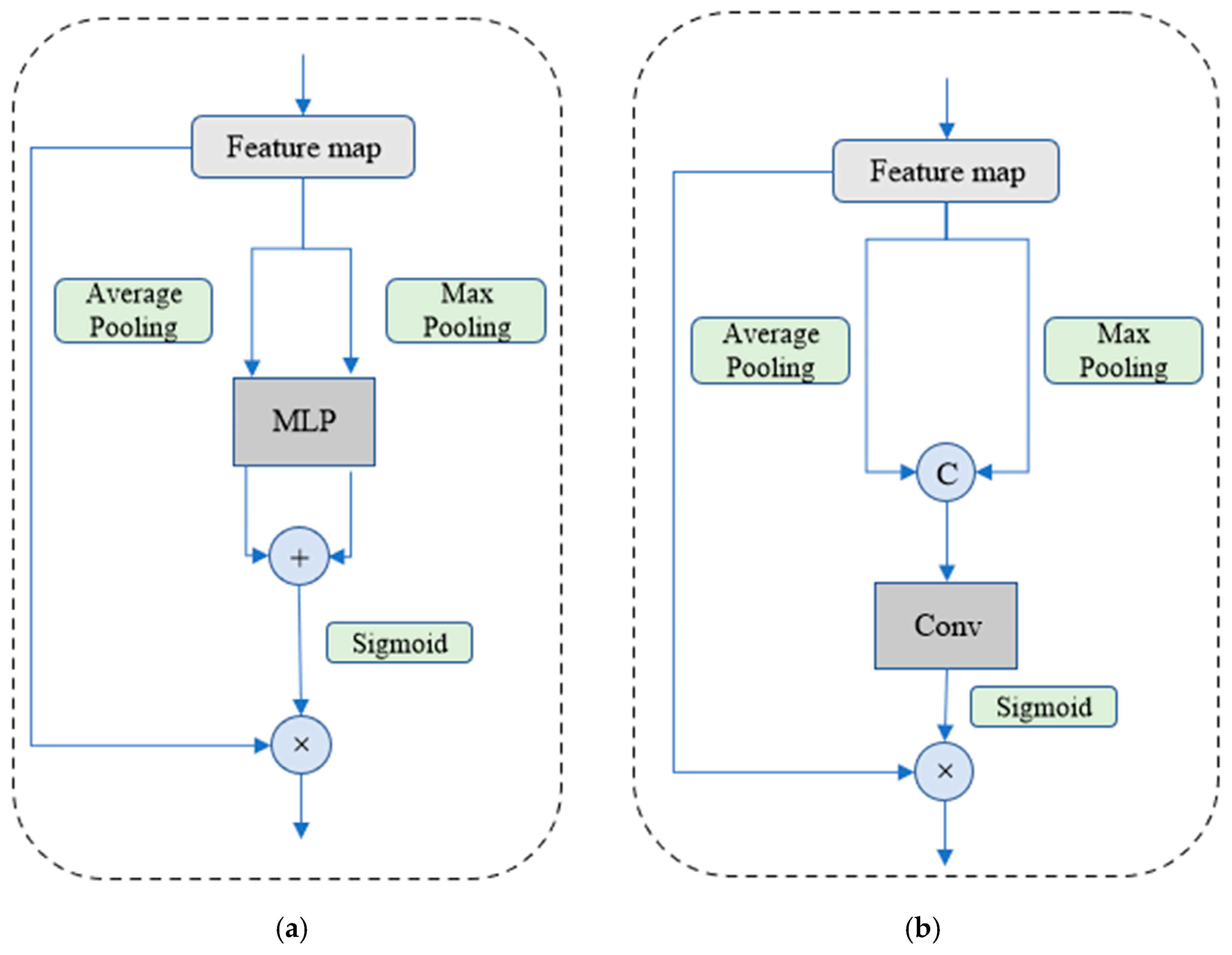
3. The Proposed SAF
4. Experiment
4.1. Dataset
4.2. Loss Function
4.3. Experimental Settings
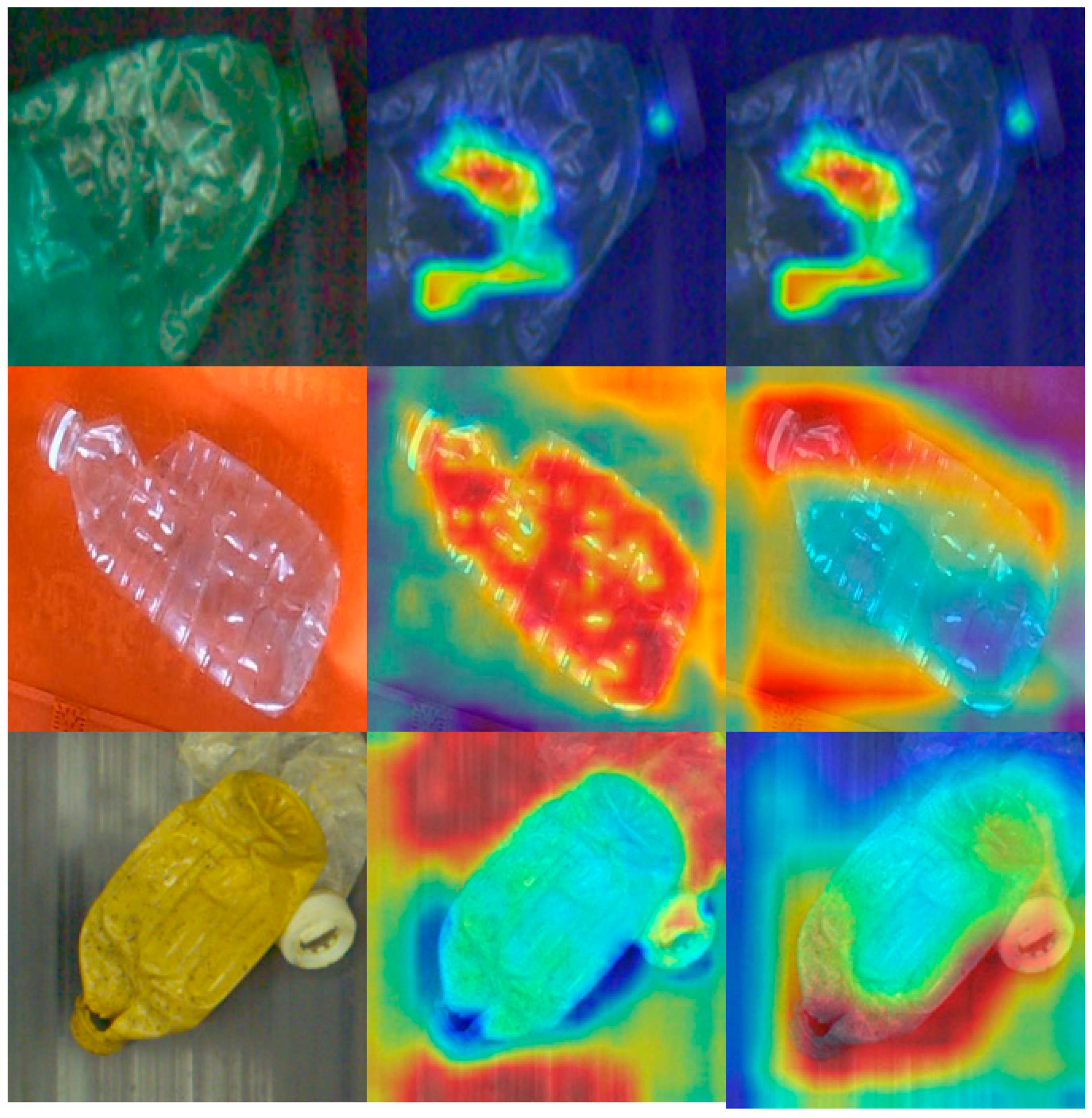
4.4. Ablation Experiments
4.5. Comparisons with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Chen, T.; Li, G.; Xu, R.; Lin, L. Multi-label image recognition by recurrently discovering attentional regions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 464–472. [Google Scholar]
- Guo, Y.; Gu, S. Multi-label classification using conditional dependency networks. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Chen, T.; Xu, M.; Hui, X.; Wu, H.; Lin, L. Learning semantic-specific graph representation for multi-label image recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 522–531. [Google Scholar]
- Wei, Y.; Xia, W.; Lin, M.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. HCP: A flexible CNN framework for multi-label image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1901–1907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, M.; Luo, C.; Hong, R.; Tang, J.; Feng, J. Beyond object proposals: Random crop pooling for multi-label image recognition. IEEE Trans. Image Process. 2016, 25, 5678–5688. [Google Scholar] [CrossRef] [PubMed]
- Gao, B.; Zhou, H. Learning to Discover Multi-Class Attentional Regions for Multi-Label Image Recognition. IEEE Trans. Image Process. 2021, 30, 5920–5932. [Google Scholar] [CrossRef]
- Zhu, F.; Li, H.; Ouyang, W.; Yu, N.; Wang, X. Learning spatial regularization with image level supervisions for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 5513–5522. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Muresan, M.P.; Szabo, P.A.; Nedevschi, S. Dot Matrix OCR for Bottle Validity Inspection. In Proceedings of the IEEE 15th International Conference on Intelligent Computer Communication and Processing (ICCP), Tokyo, Japan, 15–17 May 2019. [Google Scholar]
- Fang, J.; Wang, Y.; Wu, C. Binocular automatic particle inspection machine for bottled medical liquid examination. In Proceedings of the 2013 Chinese Automation Congress, Changsha, China, 7–8 November 2013; pp. 397–402. [Google Scholar]
- Thiyagarajan, K.; Meenakshi, R.; Suganya, P. Vision based bottle classification and automatic bottle filling system. In Proceedings of the International Conference on Advances in Human Machine Interaction, Bangalore, India, 3–5 March 2016. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Image Classification and Retrieval by Collective Network of Binary Classifiers; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Xiao, J.; Tang, S. Joint Learning of Binary Classifiers and Pairwise Label Correlations for Multi-label Image Classification. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzheng, China, 6–8 August 2020. [Google Scholar]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2285–2294. [Google Scholar]
- Chen, S.F.; Chen, Y.C.; Yeh, C.K.; Wang, Y.C.F. Order-free RNN with visual attention for multi-label classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 6714–6721. [Google Scholar]
- Jin, C.; Weihua, L.I.; Chen, J.I. Bi-directional Long Short-term Memory Neural Networks for Chinese Word Segmentation. J. Chin. Inf. 2018, 32, 29–37. [Google Scholar]
- Kip, F.T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulun, France, 24–26 April 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-termmemory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Wei, X.; Wang, P.; Guo, Y. Multi-Label Image Recognition with Graph Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5172–5181. [Google Scholar]
- You, R.; Guo, Z.; Cui, L.; Long, X.; Bao, Y.; Wen, S. Cross-modality attention with semantic graph embedding for multi-label classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12709–12716. [Google Scholar]
- Wu, J.; Yu, Y.; Huang, C. Deep multiple instance learning for image classification and auto-annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Liu, Y.; Li, S.J.; Cheng, M.M. RefinedBox: Refining for Fewer and High-quality Object Proposals. Neurocomputing 2020, 406, 106–116. [Google Scholar] [CrossRef]
- Yang, H.; Zhou, J.T.; Zhang, Y.; Gao, B.; Wu, J.; Cai, J. Exploit bounding box annotations for multi-label object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 280–288. [Google Scholar]
- Zitnick, C.L.; Dollar, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 3286–3293. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Liu, H. Attention-guided cnn for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef] [PubMed]
- Paoletti, M.E.; Moreno-Álvarez, S.; Haut, J.M. Multiple Attention-Guided Capsule Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2014. [Google Scholar] [CrossRef]
- Chen, T.; Wang, Z.; Li, G.; Lin, L. Recurrent attentional reinforcement learning for multi-label image recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Zurich, Switzerland, 6–12 September 2018; pp. 6730–6737. [Google Scholar]
- Guo, H.; Zheng, K.; Fan, X.; Yu, H.; Wang, S. Visual attention consistency under image transforms for multi-label image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 729–739. [Google Scholar]
- Luo, Y.; Jiang, M.; Zhao, Q. Visual Attention in Multi-Label Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; pp. 820–827. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 June 2015; Volume 37, pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Volume 27, pp. 807–814. [Google Scholar]
- Ke, Z.; Wu, J. Residual Attention: A Simple but Effective Method for Multi-Label Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual Event, 11–17 October 2021; pp. 184–193. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, C.; Loy, C.C.; Tang, X. Human attribute recognition by deep hierarchical contexts. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9910, pp. 684–700. [Google Scholar]
- Hsieh, C.Y.; Lin, Y.A.; Lin, H.T. A Deep Model with Local Surrogate Loss for General Cost-sensitive Multi-label Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3239–3246. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 198–213. [Google Scholar]
- Wang, Y.; He, D.; Li, F.; Long, X.; Zhou, Z.; Ma, J.; Wen, S. Multi-label classification with label graph superimposing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12265–12272. [Google Scholar]
- Guo, H.; Fan, X.; Wang, S. Human attribute recognition by refining attention heat map. Pattern Recognit. Lett. 2017, 94, 38–45. [Google Scholar] [CrossRef]
- Sarafianos, N.; Xu, X.; Kakadiaris, I.A. Deep imbalanced attribute classification using visual attention aggregation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11215, pp. 680–697. [Google Scholar]
- Ben-Baruch, E.; Ridnik, T.; Zamir, N.; Noy, A.; Zelnik-Manor, L. Asymmetric Loss for Multi-Label Classification. Asymmetric loss for multi-label classification. arXiv 2020, arXiv:2009.14119. [Google Scholar]
- Liu, S.; Zhang, L.; Yang, X.; Su, H.; Zhu, J. Query2label: A simple transformer way to multi-label classification. arXiv 2021, arXiv:2107.10834. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Wang, Y.; Stiefelhagen, R. Deep view-sensitive pedestrian attribute inference in an end-to-end model. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP | CF1 | OF1 |
|---|---|---|---|
| RB + Classifier | 97.39 | 93.41 | 96.40 |
| RB + SAB + Classifier | 97.46 | 93.63 | 96.33 |
| SAF | 97.79 | 94.50 | 97.05 |
| Methods | Metrics (%) | Parameters (M) | Running Time (ms per Image) | ||
|---|---|---|---|---|---|
| mAP | CF1 | OF1 | |||
| ASL [43] | 81.03 | 72.10 | 71.41 | 53.576 | 2.30 |
| Query2labels [44] | 87.09 | 82.57 | 89.23 | 193.507 | 7.07 |
| Resnet101 + CSRA [34] | 97.25 | 93.55 | 96.48 | 42.516 | 8.42 |
| SAF | 97.79 | 94.50 | 97.05 | 52.129 | 8.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Xu, J.; Tian, C.; Han, P.; You, L.; Zhang, S. A Serial Attention Frame for Multi-Label Waste Bottle Classification. Appl. Sci. 2022, 12, 1742. https://doi.org/10.3390/app12031742
Xiao J, Xu J, Tian C, Han P, You L, Zhang S. A Serial Attention Frame for Multi-Label Waste Bottle Classification. Applied Sciences. 2022; 12(3):1742. https://doi.org/10.3390/app12031742
Chicago/Turabian StyleXiao, Jingyu, Jiayu Xu, Chunwei Tian, Peiyi Han, Lei You, and Shichao Zhang. 2022. "A Serial Attention Frame for Multi-Label Waste Bottle Classification" Applied Sciences 12, no. 3: 1742. https://doi.org/10.3390/app12031742
APA StyleXiao, J., Xu, J., Tian, C., Han, P., You, L., & Zhang, S. (2022). A Serial Attention Frame for Multi-Label Waste Bottle Classification. Applied Sciences, 12(3), 1742. https://doi.org/10.3390/app12031742