
AT-BOD: An Adversarial Attack on Fool DNN-Based Blackbox Object Detection Models



Abstract
:1. Introduction
Contributions
- (1)
- We develop a new attack framework that targets the DL-based detectors, based on two types of adversarial attacks;
- (2)
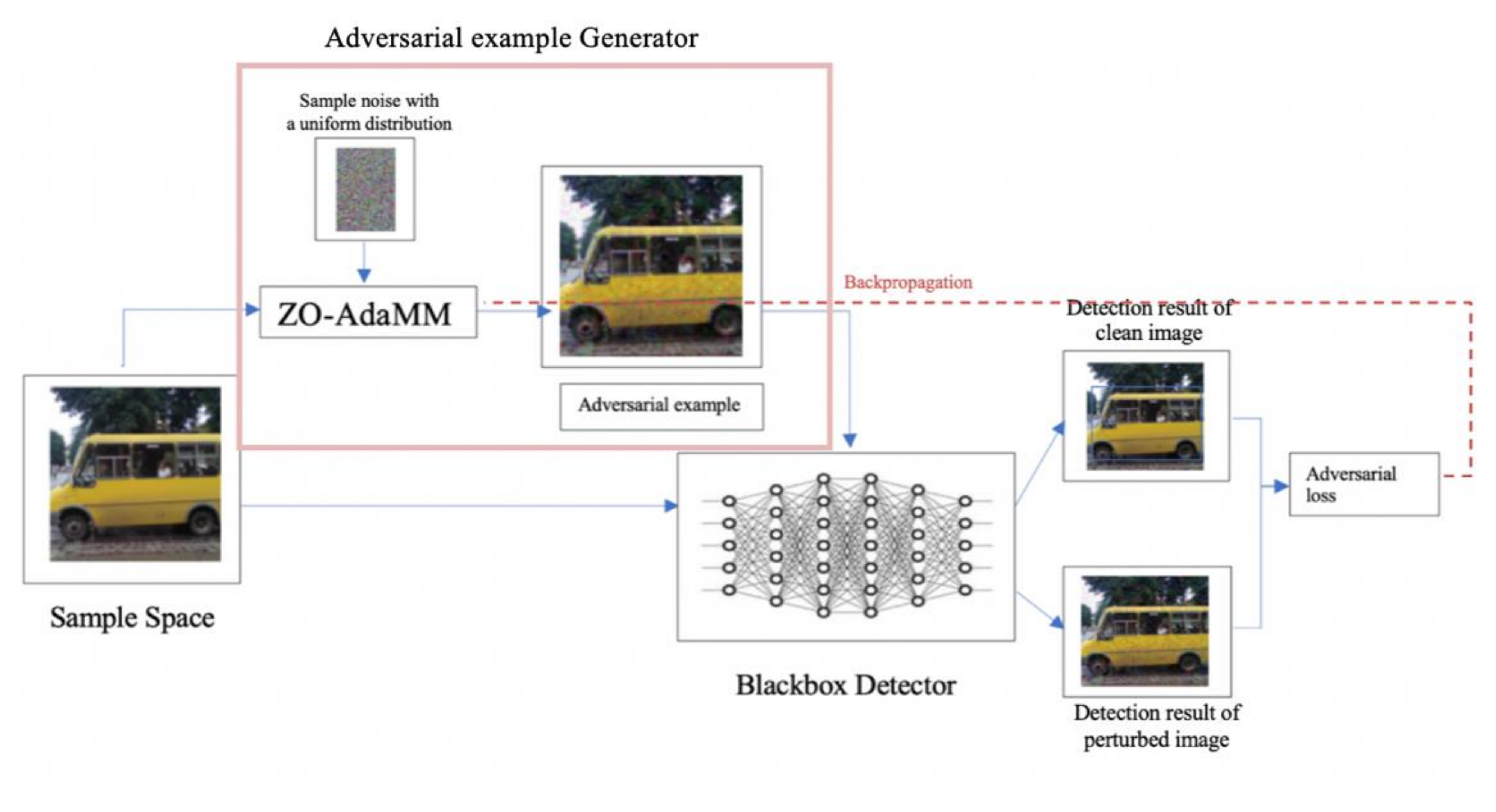
- The first attack is an adversarial perturbation based Blackbox attack using the zeroth-order adaptive momentum [24] algorithm that is known for solving the Blackbox optimization problem. We adjust the algorithm to target the classification component of the object detection model using an iterative method;
- (3)
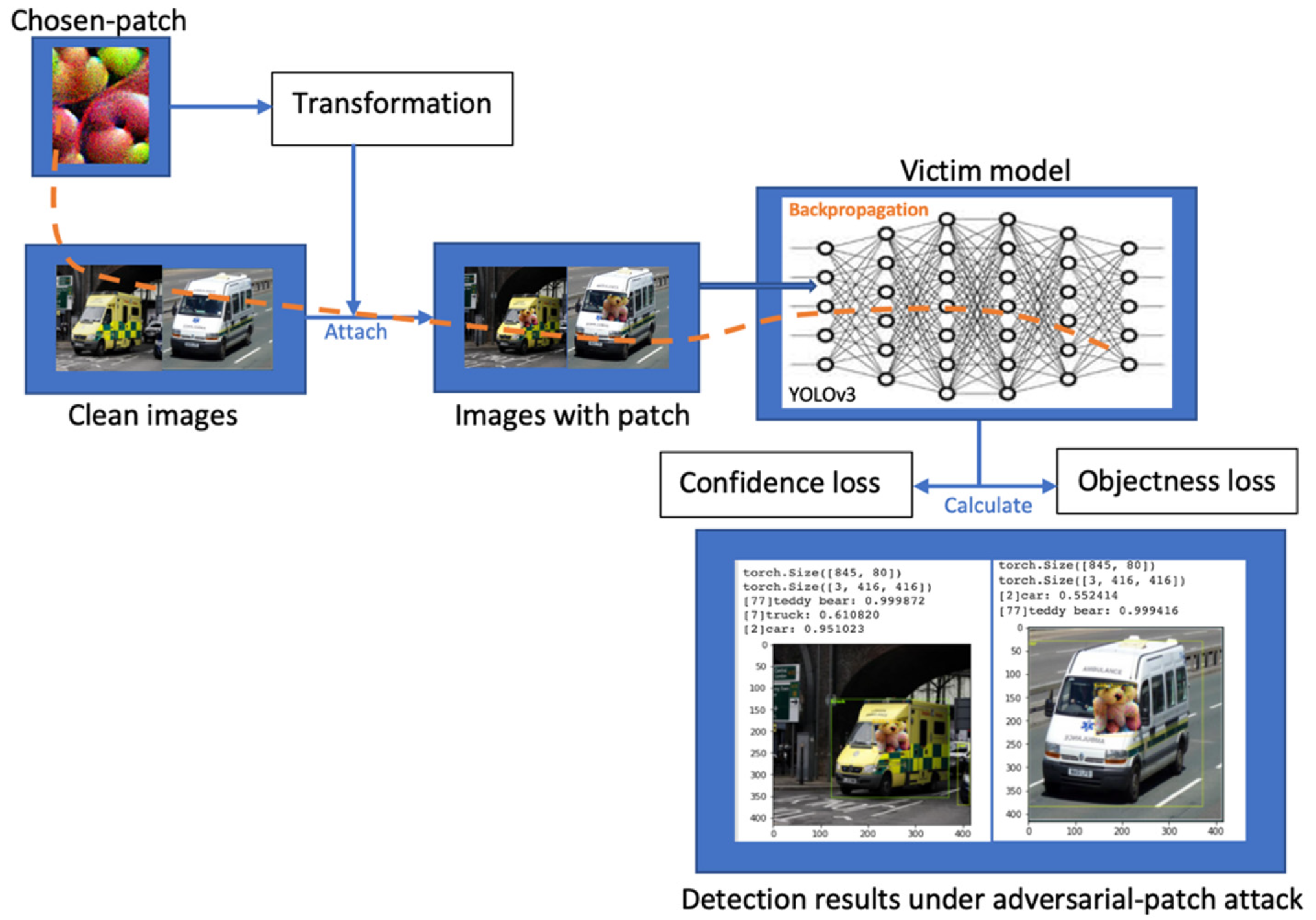
- In the second attack, we use the adversarial patch attack introduced by Thys et al. [25]. However, in our work, we used a different dataset, OpenImages-Vehicles, a custom dataset where we take a subset of the massive Google OpenImages dataset then label the images using LabelImg annotating tool to generate bounding boxes coordinates for each object in the input samples. The detector victims are YOLOv3 and Faster R-CNN, that are used to detect vehicles in the road;
- (4)
- The attacks are performed separately, targeting the YOLOv3 and Faster R-CNN detectors, where they work in three diverse ways, reducing the confidence score of vehicle classes, decreasing the objectness score, or both;
- (5)
- The detection rate is dramatically reduced under both attacks where the detection has two behaviors, whether making wrong decisions or making the detector blind.
2. Background
2.1. Definitions and Notations
2.2. Adversarial Attacks
Blackbox Attack
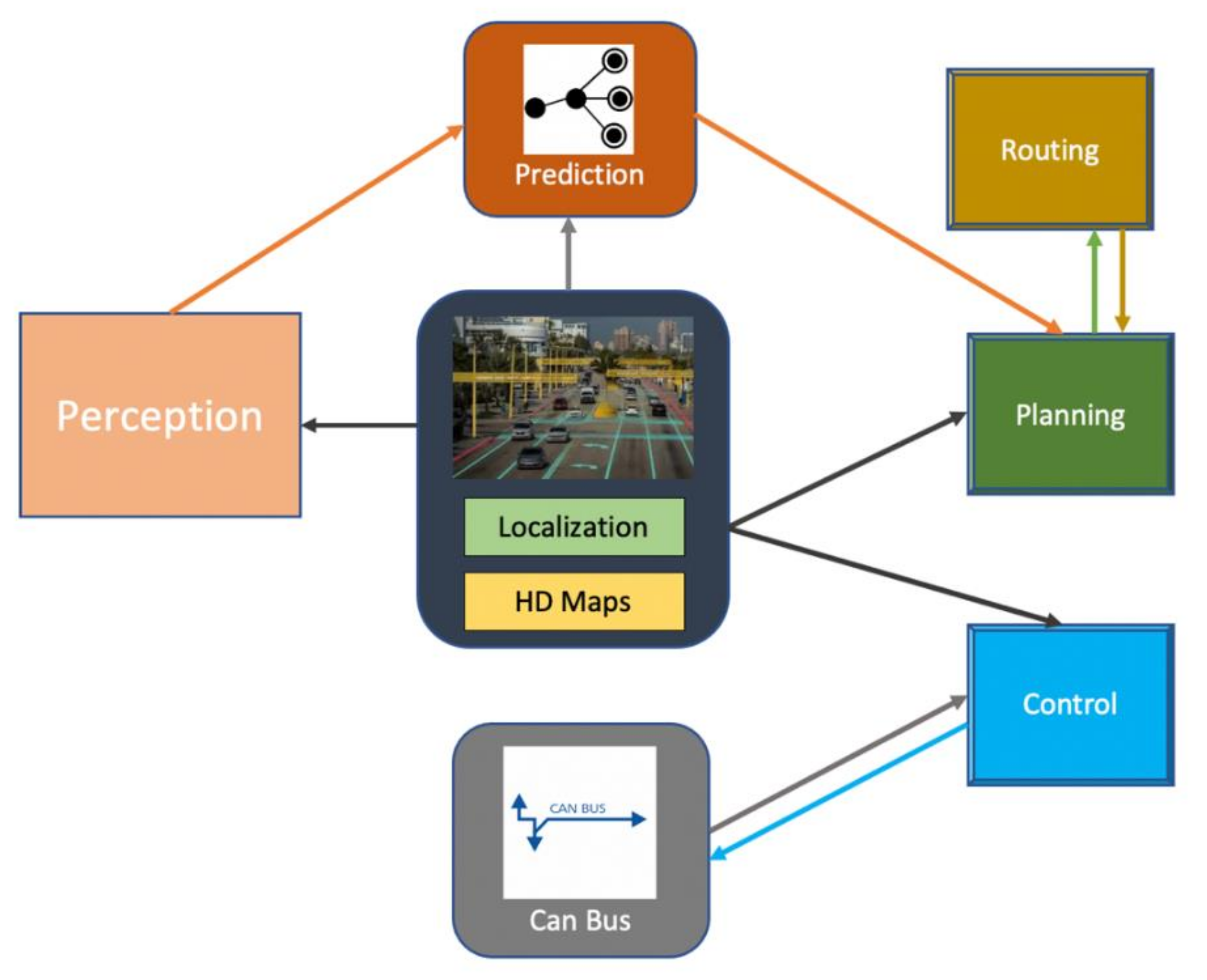
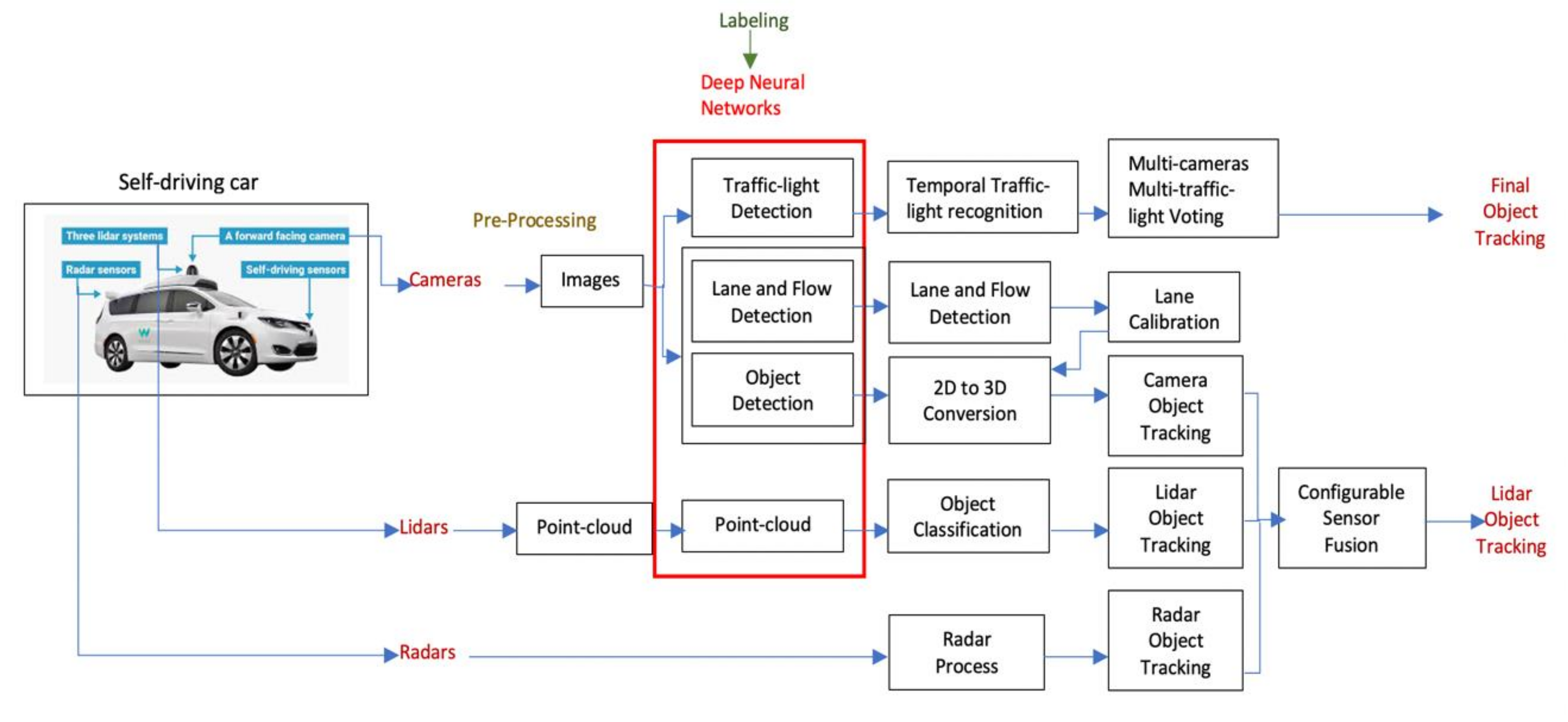
2.3. Adversarial Attacks on Self-Driving Cars
3. Related Work
4. The Proposed Model
4.1. Patch-Based AT_BOD
4.1.1. Problem Definition
4.1.2. Adversarial Patch Generation
4.2. Perturbation-Based AT-BOD
4.2.1. Problem Definition
4.2.2. Zeroth-Order Adaptive Momentum Method (ZO-AdaMM)
| Algorithm 1: ZO-AdaMM Algorithm |
| Input: xi ∈ X, step sizes {αt} T t = 1, β1,t, β2 ∈ (0, 1], 1: Initialize: , and 2: for t = 1, 2,…, T do 3 let gˆt = ∇ˆ ft(xt) by (1), 4: ft(xt): = f(xt; ξt) 5: mt = β1,tmt−1 + (1 − β1,t)gˆt 6: vt = β2vt−1 + (1 − β2)gˆ 2 t 7: vˆt = max(vˆt−1, vt), and Vˆ t = diag(vˆt) 8: xt+1 = Π X, √ Vˆ t (xt − αtVˆ −1/2 t mt) 9: end for |
4.2.3. Generating Perturbations
| Algorithm 2: Universal perturbation algorithm |
| Input: data sample , CNN model , -norm perturbation , adversarial example Output: universal perturbation vector 1: Initialize: 2: for each datapoint in data sample do 3: If then 4: Calculate the minimal perturbation that makes goes to decision boundaries 5: Update 6: end if 7: end for 8: return |
4.3. Evaluation Metrics
4.3.1. Metrics for Object Detection
Mean Average Precision (mAP)
Average Precision (AP)
Intersection over Union (IoU)
 .
. .
.4.3.2. Attacks Evaluation Methods
Fooling Rate
False-Negative Increase
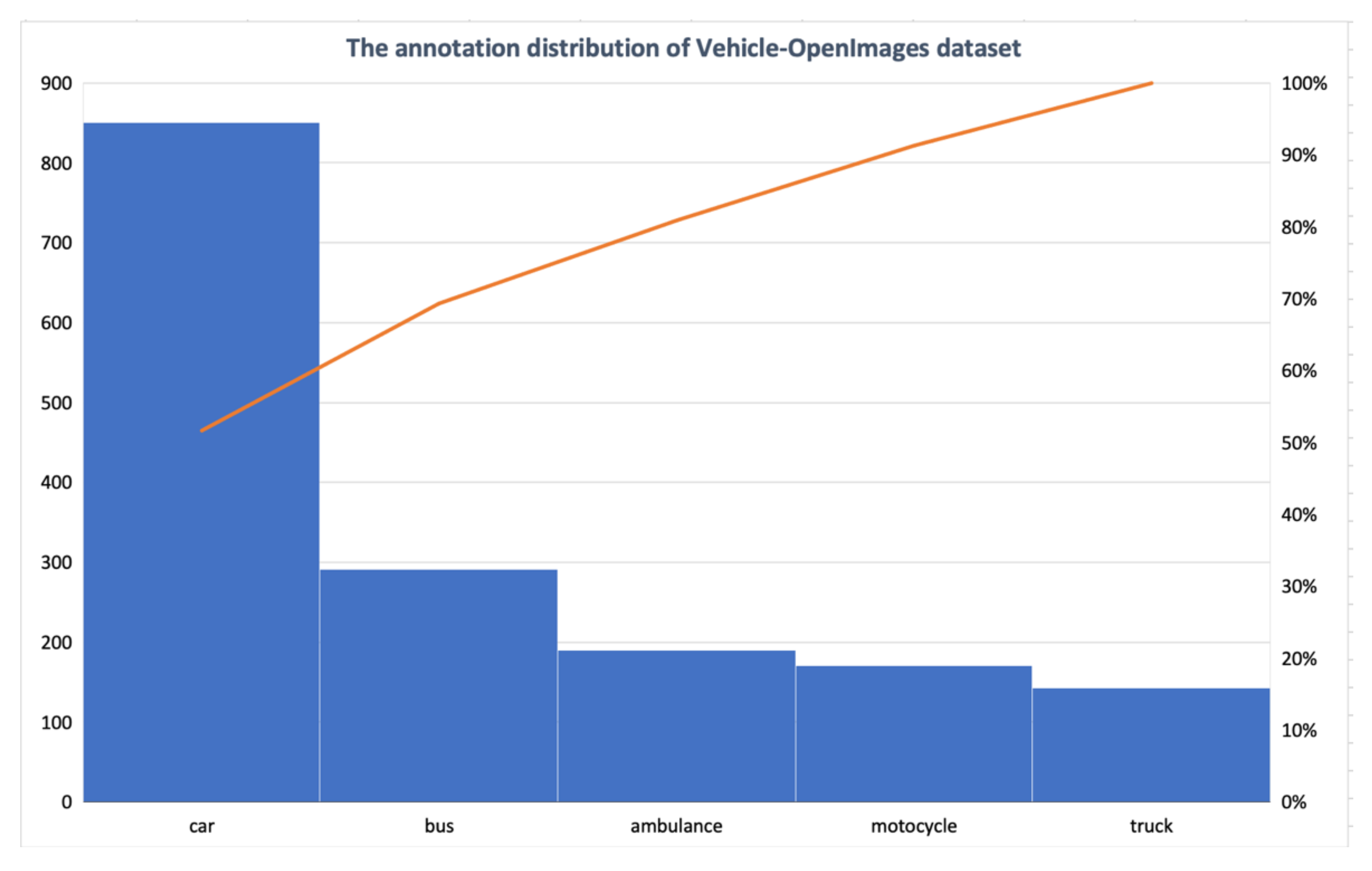
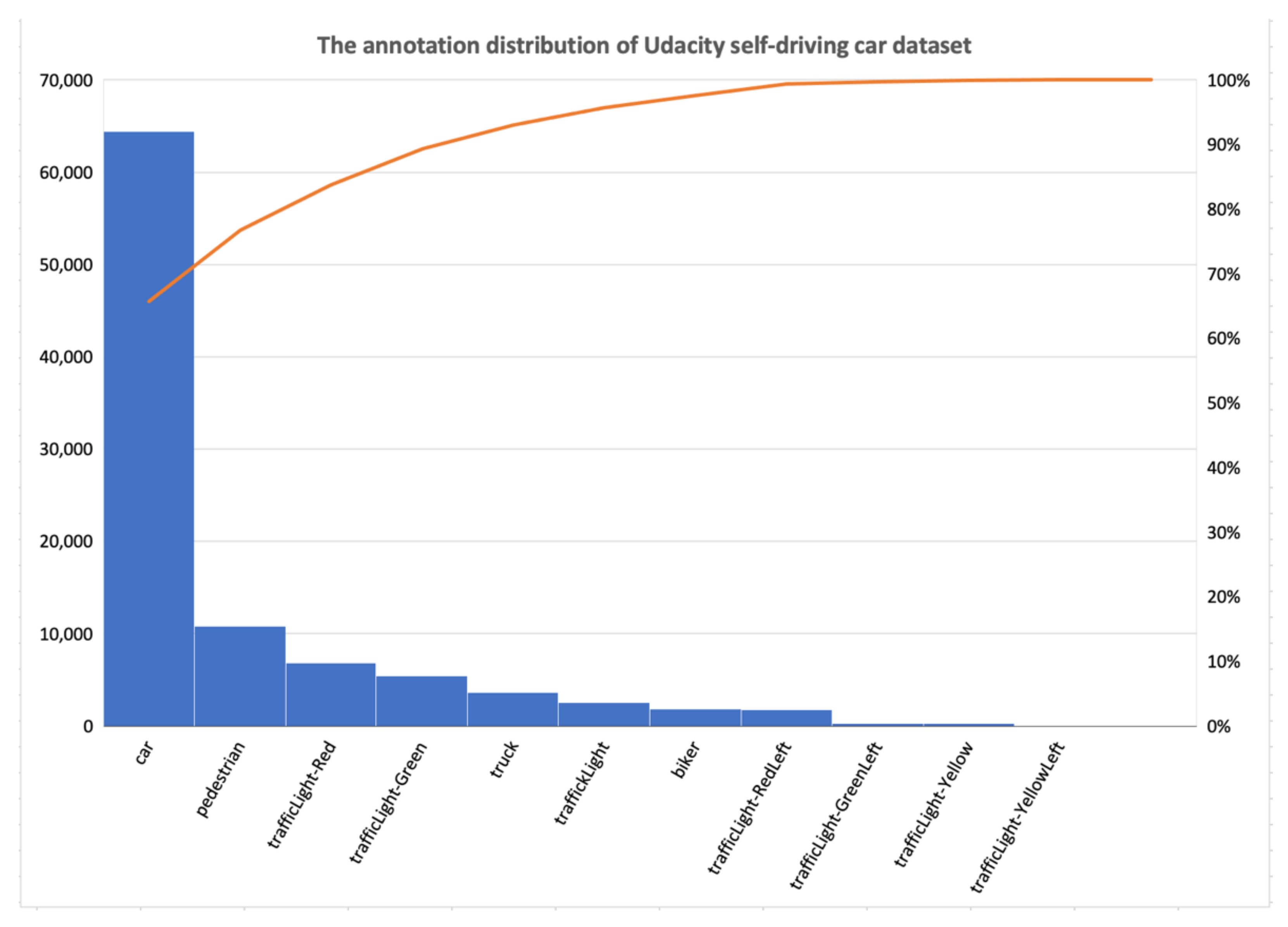
4.4. Dataset
4.5. The Victim Models
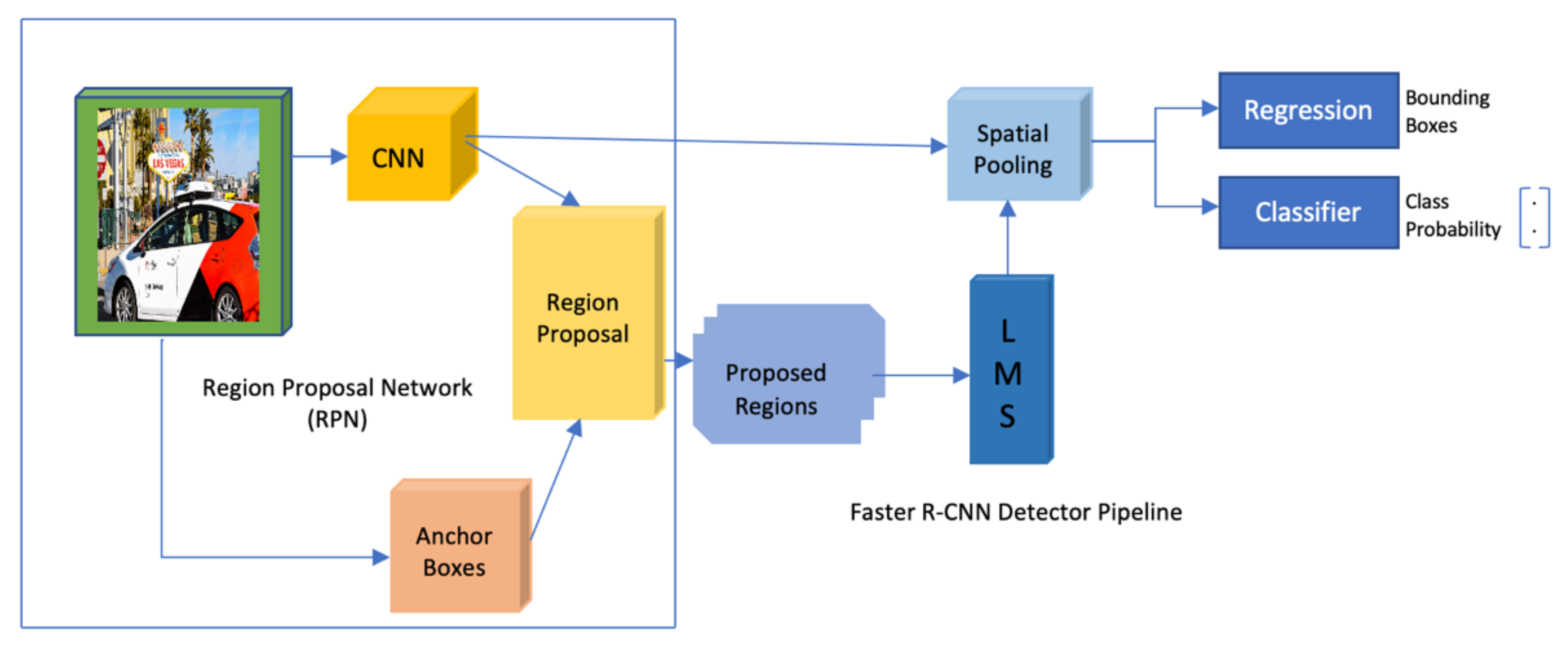
4.5.1. Faster R-CNN
- By using a pretrained CNN, that in our experiment was ResNet50_fpn [57] pre-trained on COCO, we retrained the last layer of the network depending on the number of classes we want to detect;
- After obtaining all regions of interest in each image, we reshape them to the same shape of the used CNN inputs;
- We used a classifier such as an SVM to classify both image’s objects and background where each class has a trained binary classifier;
- For each object in the input image, we generate bounding boxes using a linear regression model.
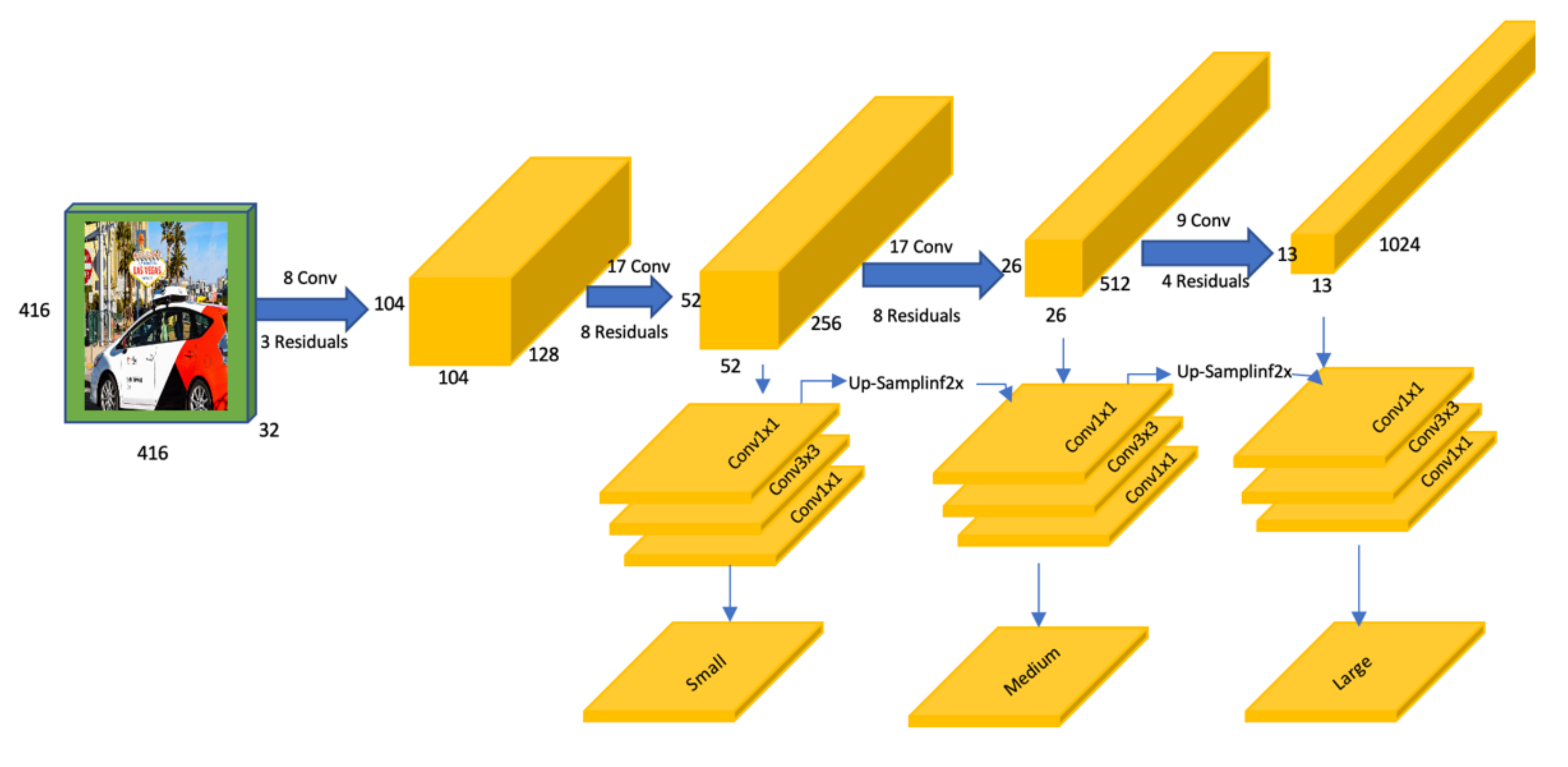
4.5.2. YOLOv3
4.6. Implementation Details
5. Results
5.1. Experiments Results
5.2. AT-BOD Ablation Study
5.3. Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; Garcia, N.; Scaramuzza, D. Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5419–5427. [Google Scholar] [CrossRef] [Green Version]
- Chernikova, A.; Oprea, A.; Nita-Rotaru, C.; Kim, B. Are self-driving cars secure? Evasion attacks against deep neural networks for steering angle prediction. In Proceedings of the IEEE Symposium on Security and Privacy Workshops, San Francisco, CA, USA, 19–23 May 2019; pp. 132–137. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Chen, Y.; Li, X.; Sanyal, A. Deep SCNN-Based real-time object detection for self-driving vehicles using LiDAR temporal data. IEEE Access 2020, 8, 76903–76912. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Shi, Y.; Erpek, T. IoT Network Security from the Perspective of Adversarial Deep Learning. In Proceedings of the 2019 16th Annual IEEE International Conference on Sensing Communication, and Networking, Boston, MA, USA, 1–9 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–11. [Google Scholar]
- Cao, Y.; Zhou, Y.; Chen, Q.A.; Xiao, C.; Park, W.; Fu, K.; Cyr, B.; Rampazzi, S.; Morley Mao, Z. Adversarial sensor attack on LiDAR-based perception in autonomous driving. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, Auckland, New Zealand, 9–12 July 2019; pp. 2267–2281. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Bruna, J.; Erhan, D.; Goodfellow, I. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Cisse, M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling Deep Structured Prediction Models. arXiv 2017, arXiv:1707.05373. [Google Scholar]
- Hashemi, A.S.; Mozaffari, S. Secure deep neural networks using adversarial image generation and training with Noise-GAN. Comput. Secur. 2019, 86, 372–387. [Google Scholar] [CrossRef]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the IEEE Symposium on Security and Privacy 2019, San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar] [CrossRef]
- Lopez, A.; Malawade, A.V.; Al Faruque, M.A.; Boddupalli, S.; Ray, S. Security of emergent automotive systems: A tutorial introduction and perspectives on practice. IEEE Des. Test 2019, 36, 10–38. [Google Scholar] [CrossRef]
- Morgulis, N.; Kreines, A.; Mendelowitz, S.; Weisglass, Y. Fooling a Real Car with Adversarial Traffic Signs. arXiv 2019, arXiv:1907.00374. [Google Scholar]
- Sitawarin, C.; Bhagoji, A.N.; Mosenia, A.; Chiang, M.; Mittal, P. DARTS: Deceiving Autonomous Cars with Toxic Signs. arXiv 2019, arXiv:1907.00374. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Roli, F. Evasion attacks against machine learning at test time. In Machine Learning and Knowledge Discovery in Databases, Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin, Germany, 2013; Volume 8190, pp. 387–402. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Melis, M.; Demontis, A.; Biggio, B.; Brown, G.; Fumera, G.; Roli, F. Is Deep Learning Safe for Robot Vision? Adversarial Examples against the iCub Humanoid. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E. Adversarial Examples that Fool Detectors. arXiv 2017, arXiv:1712.02494. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the IEEE International Conference on Computer Vision Workshops 2017, Venice, Italy, 22–29 October 2017; pp. 1378–1387. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Zhao, X.; Stamm, M.C. Generative Adversarial Attacks Against Deep-Learning-Based Camera Model Identification. IEEE Trans. Inf. Forensics Secur. 2019, X, 1–16. [Google Scholar] [CrossRef]
- Jeong, J.H.; Kwon, S.; Hong, M.P.; Kwak, J.; Shon, T. Adversarial attack-based security vulnerability verification using deep learning library for multimedia video surveillance. Multimed. Tools Appl. 2019, 79, 16077–16091. [Google Scholar] [CrossRef]
- Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:170606083. [Google Scholar]
- Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Liu, S.; Xu, K.; Li, X. ZO-AdaMM: Zeroth-Order Adaptive Momentum Method for Black-Box Optimization. arXiv 2019, arXiv:1910.06513v2. [Google Scholar]
- Thys, S.; Ranst, W.V.; Goedeme, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 49–55. [Google Scholar] [CrossRef] [Green Version]
- Rakin, A.S.; Fan, D. Defense-Net: Defend Against a Wide Range of Adversarial Attacks through Adversarial Detector. In Proceedings of the 2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Miami, FL, USA, 15–17 July 2019; pp. 332–337. [Google Scholar] [CrossRef]
- Balakrishnan, A.; Puranic, A.G.; Qin, X.; Dokhanchi, A.; Deshmukh, J.V.; Ben Amor, H.; Fainekos, G.; Yuan, X.; He, P.; Zhu, Q.; et al. Adversarial Examples: Attacks and Defenses for Deep Learning. In Proceedings of the 7th International Conference on Learning Representations. New Orleans, Louisiana, USA, 6–9 May 2019; Volume 36, pp. 2805–2824. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the ACM Asia Conference on Computer and Communications Security. Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-Box Attacks. arXiv 2017, arXiv:1611.02770. [Google Scholar]
- Narodytska, N. Simple Black-Box Adversarial Perturbations for Deep Networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Practical Black-box Attacks on Deep Neural Networks using Efficient Query Mechanisms. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 1–16. [Google Scholar]
- Chen, P. ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models. arXiv 2017, arXiv:1708.03999. [Google Scholar]
- Sharif, M.; Bauer, L.; Reiter, M.K. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna Austria, 24–28 October 2016; pp. 1–13. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Lee, W.; Zhai, J. Trojaning Attack on Neural Networks; Purdue E-Pubs: West Lafayette, IN, USA, 2017; pp. 1–17. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–5. [Google Scholar]
- Burton, S.; Gauerhof, L.; Heinzemann, C. Making the case for safety of machine learning in highly automated driving. In International Conference on Computer Safety, Reliability, and Security, Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Trento, Italy, 12–15 September 2017; Springer: Berlin, Germany, 2017; Volome 10489, pp. 5–16. [Google Scholar]
- Chatterjee, D. Adversarial Attacks and Defenses in a Self-driving Car Environment. Int. J. Adv. Sci. Technol. 2020, 29, 2233–2240. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the KITTI vision benchmark suite. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Tram, F.; Prakash, A.; Kohno, T.; Song, D. Physical Adversarial Examples for Object Detectors. arXiv 2018, arXiv:2108.11765. [Google Scholar]
- Stilgoe, J. Machine learning, social learning and the governance of self-driving cars. Soc. Stud. Sci. 2018, 48, 25–56. [Google Scholar] [CrossRef]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles. arXiv 2017, arXiv:1707.03501. [Google Scholar]
- Mimouna, A.; Alouani, I.; Ben Khalifa, A.; Hillali, Y.E.; Taleb-Ahmed, A.; Menhaj, A.; Ouahabi, A.; Essoukri, N.; Amara, B. electronics OLIMP: A Heterogeneous Multimodal Dataset for Advanced Environment Perception. Electronics 2020, 9, 560. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Shrivastava, A.; Gupta, A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the Proceedings-30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3039–3048. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. Standard detectors aren’t (currently) fooled by physical adversarial stop signs. arXiv 2017, arXiv:1710.03337. [Google Scholar]
- Models, P.; Li, Y. Robust Adversarial Perturbation on Deep Proposal-based Models. arXiv 2019, arXiv:1809.05962v2. [Google Scholar]
- Chen, S.-T.; Cornelius, C.; Martin, J.; Horng Chau, D. ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector; Springer: Cham, Germany, 2018; pp. 52–68. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Li, H.; Chen, Y. Dpatch: An adversarial patch attack on object detectors. arXiv 2017, arXiv:1806.02299. [Google Scholar]
- Liu, S.; Chen, P. Zeroth-Order Optimization and Its Application to Adversarial Machine Learning. Intell. Inform. 2018, 19, 25. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the 30th IEEE Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 86–94. [Google Scholar] [CrossRef] [Green Version]
- Lian, X.; Zhang, H.; Hsieh, C.-J.; Huang, Y.; Liu, J. A Comprehensive Linear Speedup Analysis for Asynchronous Stochastic Parallel Optimization from Zeroth-Order to First-Order. Adv. Neural Inf. Processing Syst. 2017, 29, 3054–3062. [Google Scholar]
- Liu, S.; Chen, P.Y.; Chen, X.; Hong, M. SignsGD via zeroth-order oracle. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–24. [Google Scholar]
- Kingma, D.P.; Lei Ba, J. Adam: A Method For Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Yun, J.W. Deep Residual Learning for Image Recognition. Enzyme Microb. Technol. 1996, 19, 107–117. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Inference with Clean Images/mAP@.5 | Inference with Adversarial Attack Examples/mAP@.5 |
|---|---|---|
| YOLOv3 | 84% | <1% |
| Faster R-CNN | 80.28% | 2% |
| Models | Inference with Clean Images/mAP@.5 | Inference with Adversarial Attack Examples/mAP@.5 |
|---|---|---|
| YOLOv3 | 70% | 1% |
| Faster R-CNN | 68% | 3% |
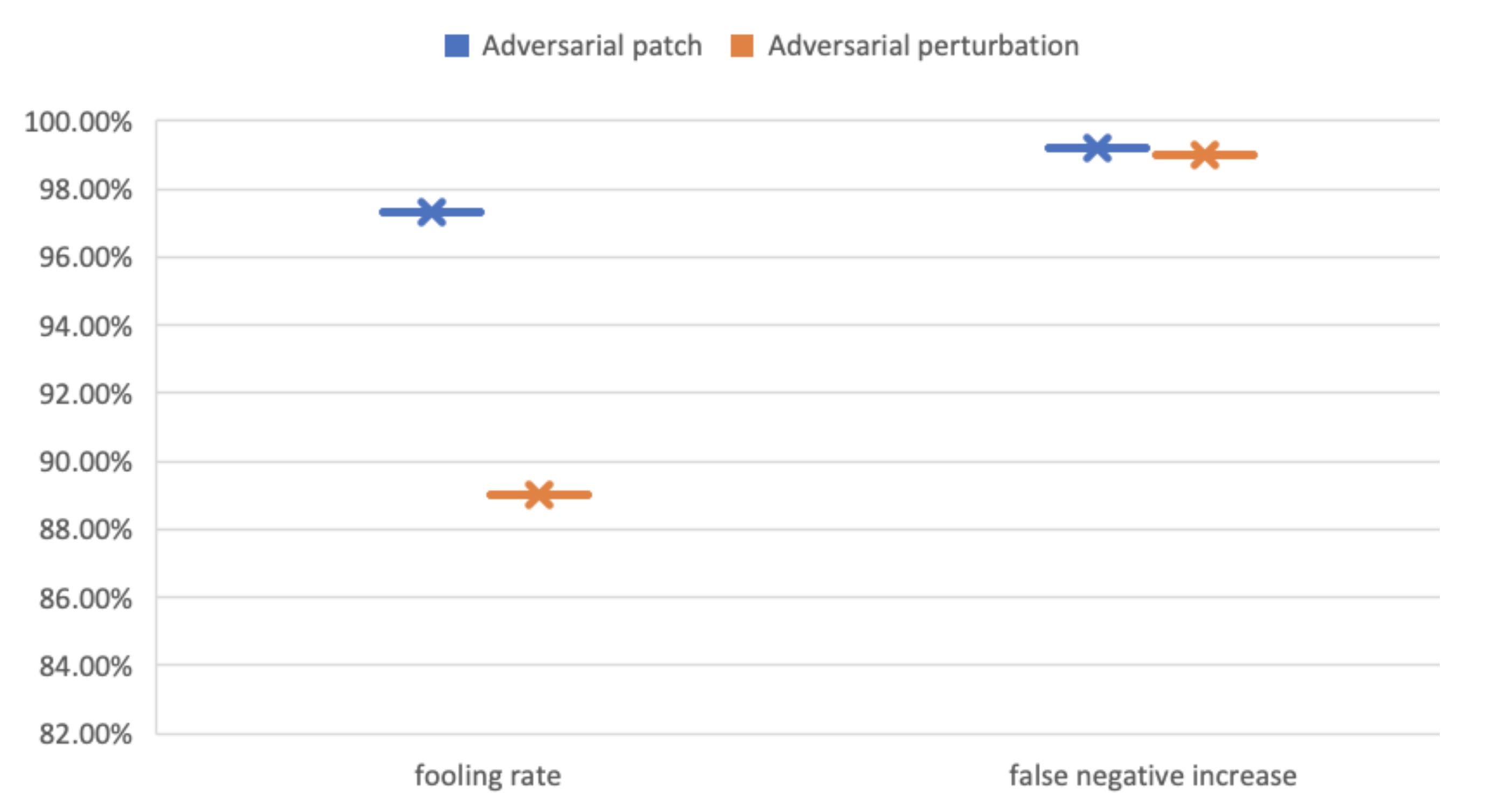
| AT-BOD Attack | Fooling Ratio | False-Negative Increase |
|---|---|---|
| Patch-based | 97.3% | 99.21% |
| Perturbations-based | 89% | 99.02% |
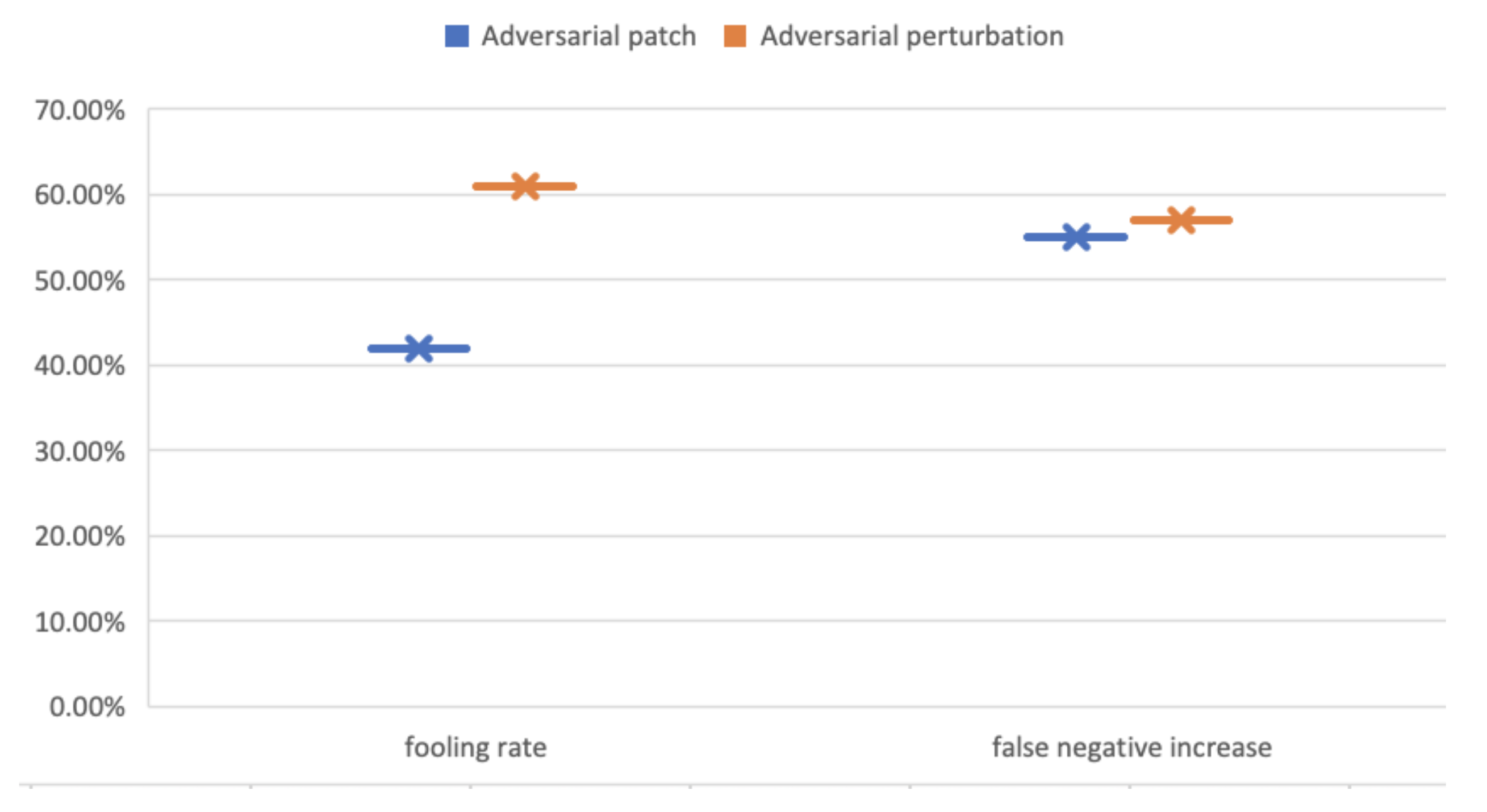
| AT-BOD Attack | Fooling Ratio | False-Negative Increase |
|---|---|---|
| Patch-based | 42% | 55% |
| Perturbations-based | 61% | 57% |
| AT-BOD Attack | Fooling Ratio | False-Negative Increase |
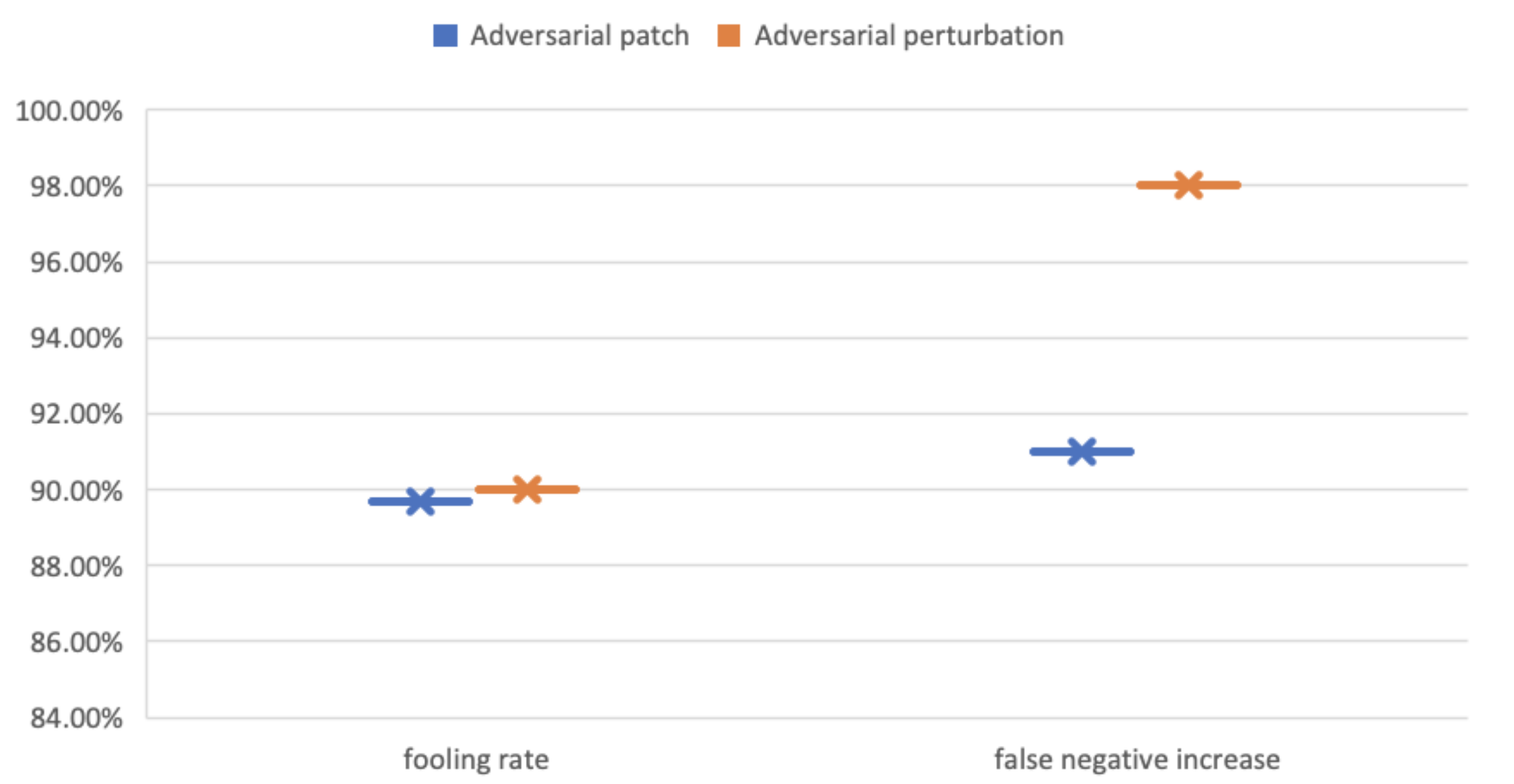
|---|---|---|
| Patch-based | 89.7% | 91% |
| Perturbations-based | 90% | 98% |
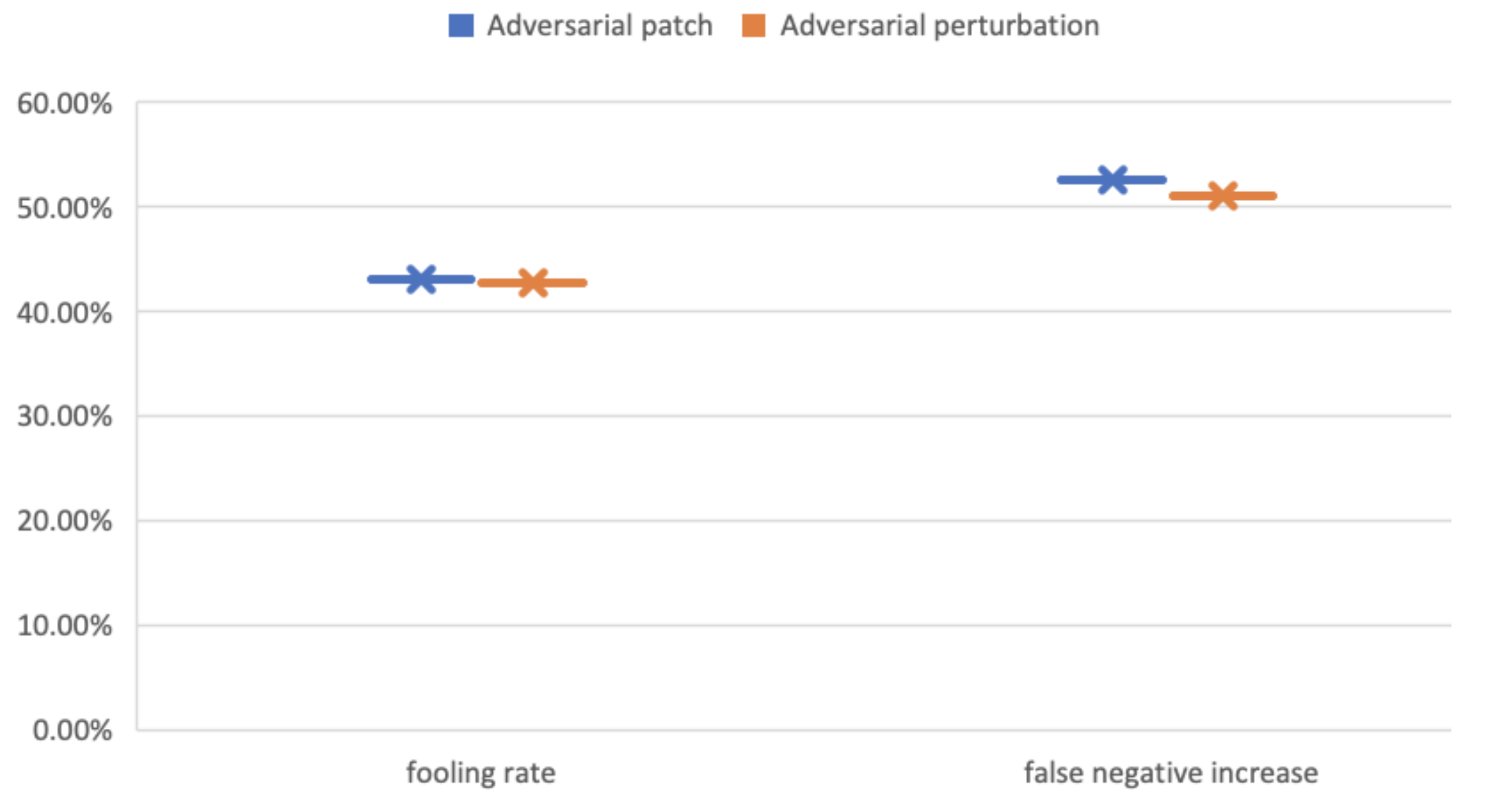
| AT-BOD Attack | Fooling Ratio | False-Negative Increase |
|---|---|---|
| Patch-based | 43% | 52.5% |
| Perturbations-based | 42.8% | 51% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elaalami, I.A.; Olatunji, S.O.; Zagrouba, R.M. AT-BOD: An Adversarial Attack on Fool DNN-Based Blackbox Object Detection Models. Appl. Sci. 2022, 12, 2003. https://doi.org/10.3390/app12042003
Elaalami IA, Olatunji SO, Zagrouba RM. AT-BOD: An Adversarial Attack on Fool DNN-Based Blackbox Object Detection Models. Applied Sciences. 2022; 12(4):2003. https://doi.org/10.3390/app12042003
Chicago/Turabian StyleElaalami, Ilham A., Sunday O. Olatunji, and Rachid M. Zagrouba. 2022. "AT-BOD: An Adversarial Attack on Fool DNN-Based Blackbox Object Detection Models" Applied Sciences 12, no. 4: 2003. https://doi.org/10.3390/app12042003
APA StyleElaalami, I. A., Olatunji, S. O., & Zagrouba, R. M. (2022). AT-BOD: An Adversarial Attack on Fool DNN-Based Blackbox Object Detection Models. Applied Sciences, 12(4), 2003. https://doi.org/10.3390/app12042003