
Interpolating the Directional Room Impulse Response for Dynamic Spatial Audio Reproduction


Abstract
:1. Introduction
2. DRIR Interpolation Framework
2.1. Overview of the Interpolation Approach
- Separate the FOA signals of DRIR into the direct sound, the specular reflection signals and the chaotic diffuse components;
- Analyze the W channel of the separated direct sound and specular reflection FOA signals to locate peaks corresponding to estimated image sources;
- Form a new FOA signal for this image source using a segment of the signal surrounding this peak for the W channel and corresponding X, Y, and Z channels;
- Repeat until a desired number of image sources (peaks) have been extracted;
- Interpolate such FOA signals and their extracted DOA information at two closest recording positions to the listening position using a weighted average approach;
- Synthesize the FOA signal of DRIR at the listening position utilizing the interpolated parameters and a known FOA signal recorded closely.
2.2. Separating FOA Signals into Specular and Diffuse Components
- is greater than a pre-defined threshold (in this work = 4 dB was chosen, under which ). Informal experiments found that should be in the range from 4 dB to 6 dB to avoid sensitivity of the approach to this threshold. For an smaller than 4 dB, this can lead to a few false peaks being extracted and if is greater than 6 dB it can lead to some clear peaks not being detected. This was initially verified by analyzing results from a sub-set of DRIR recordings, whilst the TOA results in Section 4 analyze this more thoroughly.
- is a local maximum.
- is greater than a pre-defined threshold , which distinguishes the peak from background noise, so the selection of depends on the noise floor level of specific DRIR recordings (in this work = −50 dB was chosen to match the noise floor of the chosen recordings [21], but in practice this could be adjusted to match the estimated noise floor level for recordings in another room).
2.3. Deriving the DOA for the FOA Encoded Image Sources
2.4. Deriving the Interpolated FOA Signals at the Virtual Listening Location
- Signal decomposition: the convolution operation in (4) and (5) is implemented using an overlap-add approach based on Fast Fourier Transform, which possesses a TCC of with being the window length [25]. The weighted average filters in (6) and (7) show a TCC of , followed by the peak salience calculation in (9) and value assignments in (10) and (11), with all having a TCC of where is the length of recording.
- Deriving DOA and TOA information: (12) and (13) include STFT calculations and thus have a TCC of with being the length of the window adopted.
- Interpolating and synthesizing FOA signals: the summation in signal synthesis shows a TCC of , which is not increased by the efficient interpolation operation.
3. Experimental Setup
3.1. Real-World DRIR Recordings
3.2. Simulated DRIR Recordings
4. Results and Analysis
4.1. Comparative Analysis in the Classroom
4.1.1. Example Interpolated DRIR Signals
4.1.2. DOA and TOA Error Results
4.2. Comparative Analysis in the Great Hall
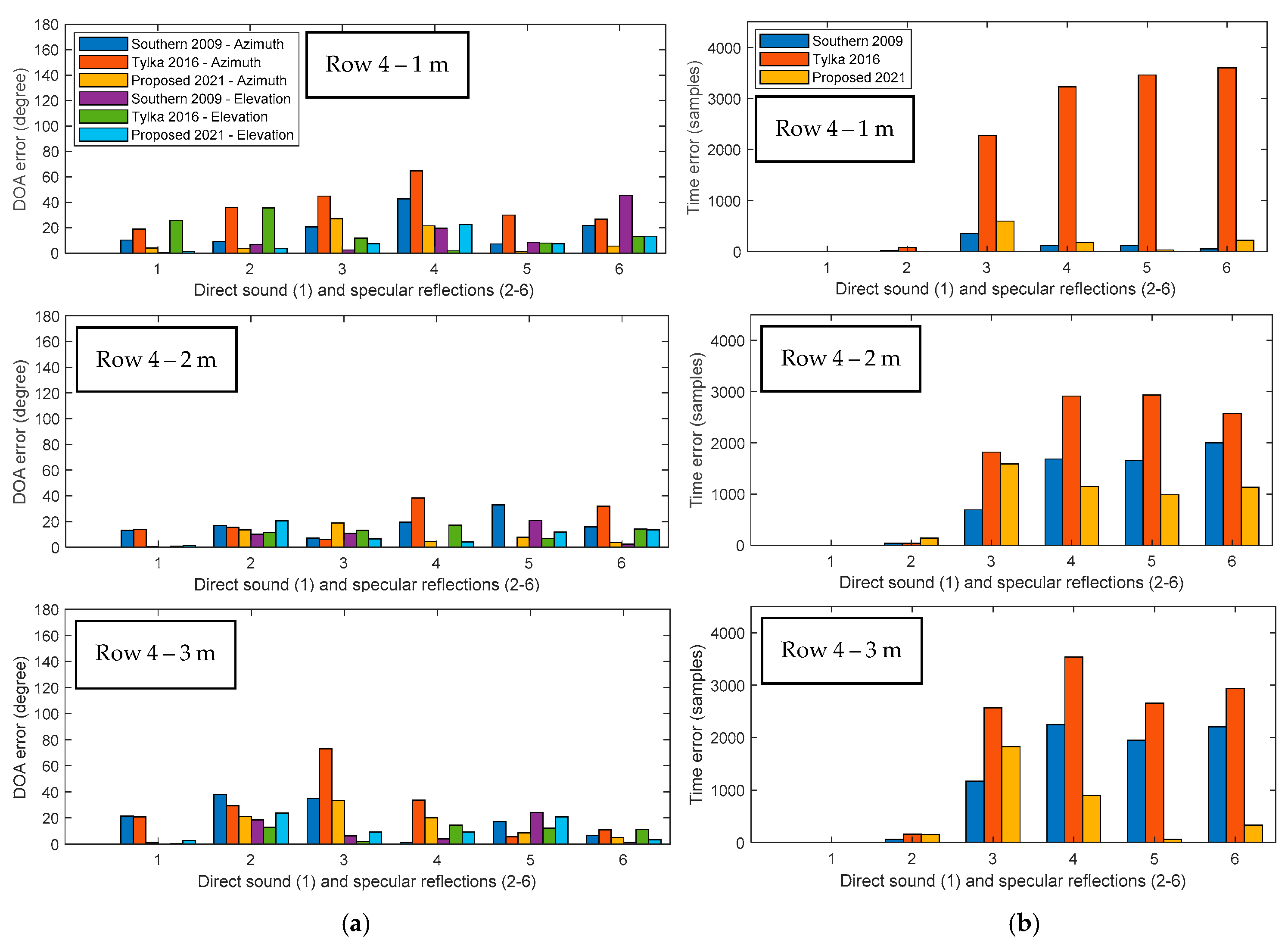
4.2.1. Regular Spacing, Row 4
4.2.2. Regular and Irregular Spacing, Row 9
4.2.3. Irregular Source-to-Microphone Distances Located Diagonally
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Antonello, N.; Sena, E.D.; Moonen, M.; Naylor, P.A.; Waterschoot, T.V. Room impulse response interpolation using a sparse spatio-temporal representation of the sound field. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1929–1941. [Google Scholar] [CrossRef] [Green Version]
- Allen, J.; Berkley, D. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Mariette, N.; Katz, B.F.G. SoundDelta–Large Scale, Multi-user Audio Augmented Reality. In Proceedings of the EAA Symposium on Auralization, Espoo, Finland, 15–17 June 2009. [Google Scholar]
- Southern, A.; Wells, J.; Murphy, D. Rendering Walk-through Auralisations Using Wave-based Acoustical Models. In Proceedings of the European Signal Processing Conference (EUSIPCO 2009), Glasgow, UK, 25–28 August 2009. [Google Scholar]
- Tylka, J.G.; Choueiri, E.Y. Fundamentals of a parametric method for virtual navigation within an array of Ambisonics microphones. J. Audio Eng. Soc. 2020, 68, 120–137. [Google Scholar] [CrossRef]
- Fernandez-Grande, E. Sound field reconstruction using a spherical microphone array. J. Acoust. Soc. Am. 2016, 139, 1168–1178. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Menzies, D.; Al-Akaidi, M. Nearfield binaural synthesis and Ambisonics. J. Acoust. Soc. Am. 2007, 121, 1559–1563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zotter, F. Analysis and Synthesis of Sound-Radiation with Spherical Arrays. Ph.D. Thesis, University of Music and Performing Arts, Vienna, Austria, 2009. [Google Scholar]
- Menzies, D.; Al-Akaidi, M. Ambisonic synthesis of complex sources. J. Audio Eng. Soc. 2007, 55, 864–876. [Google Scholar]
- Wang, Y.; Chen, K. Translations of spherical harmonics expansion coefficients for a sound field using plane wave expansions. J. Acoust. Soc. Am. 2018, 143, 3474–3478. [Google Scholar] [CrossRef] [PubMed]
- Tylka, J.G.; Choueiri, E.Y. Performance of linear extrapolation methods for virtual sound field navigation. J. Audio Eng. Soc. 2020, 68, 138–156. [Google Scholar] [CrossRef]
- Samarasinghe, P.; Abhayapala, T.; Poletti, M. Wavefield analysis over large areas using distributed higher order microphones. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 647–658. [Google Scholar] [CrossRef]
- Chen, H.; Abhayapala, T.D.; Zhang, W. 3D Sound Field Analysis Using Circular Higher-order Microphone Array. In Proceedings of the European Signal Processing Conference (EUSIPCO 2015), Nice, France, 31 August–4 September 2015. [Google Scholar] [CrossRef] [Green Version]
- Samarasinghe, P.; Abhayapala, T.; Poletti, M.; Betlehem, T. An efficient parameterization of the room transfer function. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2217–2227. [Google Scholar] [CrossRef]
- Ueno, N.; Koyama, S.; Saruwatari, H. Sound field recording using distributed microphones based on harmonic analysis of infinite order. IEEE Signal Process. Lett. 2018, 25, 135–139. [Google Scholar] [CrossRef]
- Tylka, J.G.; Choueiri, E.Y. Soundfield Navigation Using an Array of Higher-order Ambisonics Microphones. In Proceedings of the Audio Engineering Society International Conference on Audio for Virtual and Augmented Reality, Los Angeles, CA, USA, 30 September–1 October 2016. [Google Scholar]
- Tylka, J.G.; Choueiri, E.Y. Models for Evaluating Navigational Techniques for Higher-order Ambisonics. In Proceedings of the Meetings of Acoustical Society of America on Acoustics, Boston, MA, USA, 25–29 June 2017. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Ritz, C.; Xi, J. Encoding and communicating navigable speech soundfields. Multi. Tools A 2016, 75, 5183–5204. [Google Scholar] [CrossRef] [Green Version]
- Thiergart, O.; Galdo, G.D.; Taseska, M.; Habets, E.A.P. Geometry-based spatial sound acquisition using distributed microphone arrays. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 2583–2594. [Google Scholar] [CrossRef]
- Rumsey, F. Spatial audio psychoacoustics. In Spatial Audio, 1st ed.; Focal Press: Oxford, UK, 2001; pp. 21–51. [Google Scholar]
- Stewart, R.; Sandler, M. Database of Omnidirectional and B-format Impulse Responses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2010), Dallas, TX, USA, 14–19 March 2010. [Google Scholar] [CrossRef]
- Dabin, M.; Ritz, C.; Shujau, M. Design and Analysis of Miniature and Three Tiered B-format Microphones Manufactured Using 3D Printing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2015), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 2674–2678. [Google Scholar] [CrossRef]
- Ma, G.; Brown, C.P. Noise Level Estimation. International Patent WO 2015/191470 Al, 17 December 2015. Available online: https://patentimages.storage.googleapis.com/19/b4/8e/389e6024f46be7/WO2015191470A1.pdf (accessed on 24 October 2021).
- Remaggi, L.; Jackson, P.J.B.; Coleman, P.; Wang, W. Acoustic reflector localization: Novel image source reversion and direct localization methods. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 296–309. [Google Scholar] [CrossRef] [Green Version]
- Oppenheim, A.V.; Schafer, R.W.; Buck, J.R. Discrete-Time Signal Processing, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Farina, A. Simultaneous Measurement of Impulse Response and Distortion with a Swept Sine Technique. In Proceedings of the 108th Audio Engineering Society Convention, Paris, France, 19–22 February 2000. [Google Scholar]
- RIR-Generator. Available online: https://github.com/ehabets/RIR-Generator (accessed on 24 October 2021).
- Ambisonics Navigation Toolkit. Available online: https://github.com/PrincetonUniversity/3D3A-AmbiNav-Toolkit (accessed on 24 October 2021).
- IoSR Matlab Toolbox. Available online: https://github.com/IoSR-Surrey/MatlabToolbox/ (accessed on 24 October 2021).
- Zahorik, P. Direct-to-reverberant energy ratio sensitivity. J. Acoust. Soc. Am. 2002, 112, 2110–2117. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classrooms | Error—Tylka | Error—Southern | Error—Proposed | |
|---|---|---|---|---|
| real-world | row 3 | 6.53 | 4.04 | 4.16 |
| row 5 | 5.88 | 3.71 | 4.02 | |
| row 8 | 1.17 | 0.11 | 1.04 | |
| row 7 | 0.71 | 0.23 | 0.00 | |
| column 9 | 2.59 | 5.09 | 4.48 | |
| average | 3.38 | 2.64 | 2.74 | |
| simulated | row 3 | 19.96 | 2.12 | 2.17 |
| row 5 | 0.50 | 3.53 | 3.44 | |
| row 8 | 2.02 | 0.15 | 0.34 | |
| row 7 | 4.25 | 4.82 | 5.05 | |
| column 9 | 7.30 | 10.31 | 12.00 | |
| average | 6.81 | 4.19 | 4.6 | |
| Great Halls | Error—Tylka | Error—Southern | Error—Proposed | |
|---|---|---|---|---|
| real-world | row 4–1 m | 6.92 | 0.12 | 0.29 |
| row 4–2 m | 5.99 | 0.88 | 1.47 | |
| row 4–3 m | 5.84 | 1.59 | 0.62 | |
| row 9–1 m | 7.11 | 0.68 | 0.33 | |
| row 9–irregular | 7.36 | 0.68 | 0.61 | |
| diagonal | 12.65 | 0.49 | 1.75 | |
| average | 7.65 | 0.74 | 0.85 | |
| simulated | row 4–1 m | 20.20 | 0.69 | 0.08 |
| row 4–2 m | 23.75 | 0.03 | 1.02 | |
| row 4–3 m | 17.97 | 1.11 | 1.22 | |
| row 9–1 m | 2.27 | 1.10 | 0.70 | |
| row 9–irregular | 2.29 | 1.15 | 1.25 | |
| diagonal | 7.10 | 3.18 | 3.38 | |
| average | 12.26 | 1.21 | 1.28 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Zheng, X.; Ritz, C.; Jang, D. Interpolating the Directional Room Impulse Response for Dynamic Spatial Audio Reproduction. Appl. Sci. 2022, 12, 2061. https://doi.org/10.3390/app12042061
Zhao J, Zheng X, Ritz C, Jang D. Interpolating the Directional Room Impulse Response for Dynamic Spatial Audio Reproduction. Applied Sciences. 2022; 12(4):2061. https://doi.org/10.3390/app12042061
Chicago/Turabian StyleZhao, Jiahong, Xiguang Zheng, Christian Ritz, and Daeyoung Jang. 2022. "Interpolating the Directional Room Impulse Response for Dynamic Spatial Audio Reproduction" Applied Sciences 12, no. 4: 2061. https://doi.org/10.3390/app12042061
APA StyleZhao, J., Zheng, X., Ritz, C., & Jang, D. (2022). Interpolating the Directional Room Impulse Response for Dynamic Spatial Audio Reproduction. Applied Sciences, 12(4), 2061. https://doi.org/10.3390/app12042061