
Time Series Visualization and Forecasting from Australian Building and Construction Statistics




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We develop a Web application that collects, sorts, and visualizes building- and construction-related statistics from the website of Australian Bureau of Statistics. The application allows users to explore both the latest and historical data in an efficient and customized way.
- We provide future value forecasting, based on deep learning-based models, and visualize the forecast value.
- We adopt the building- and construction-related economic factors as features in our multi-variant time series prediction.
2. Related Works
2.1. Interactive Dashboard
2.2. Time Series Forecasting
3. Methodology
3.1. Data Processing
3.1.1. Data Collection
3.1.2. Data Preprocessing
3.2. Time Series Forecasting
3.2.1. Economic Features
- The data needs to be recorded quarterly, and the timestamp for each data point needs to be identical;
- The data sheet must include original data without any processing;
- The data must be state- or Australia-wide data after any processing.
- Residential property price indexes;
- Wage price indexes;
- State final demand;
- Selected living cost indexes;
- Producer price indexes.
3.2.2. Feature Selection
3.2.3. Prediction
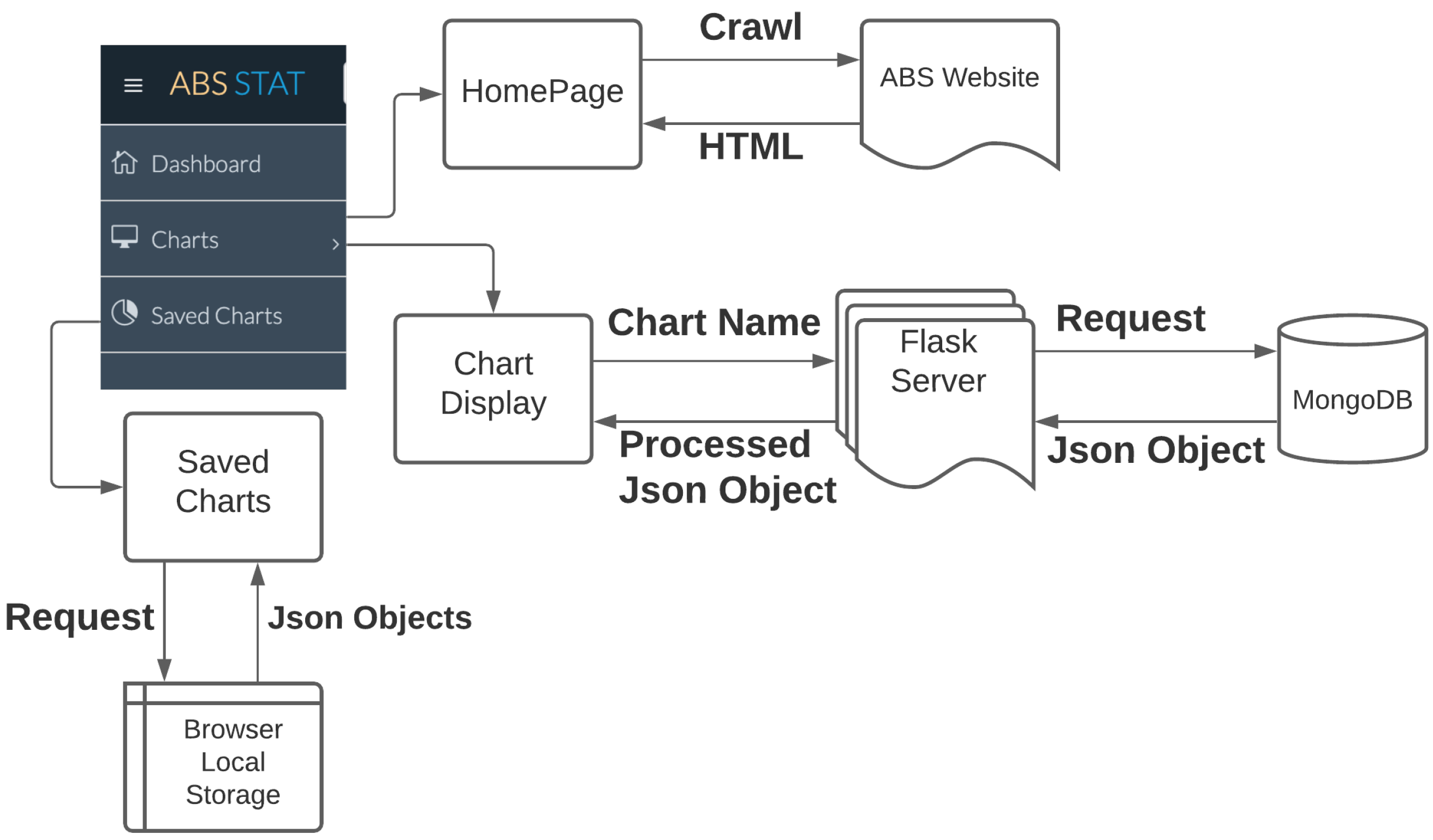
3.3. Web Application
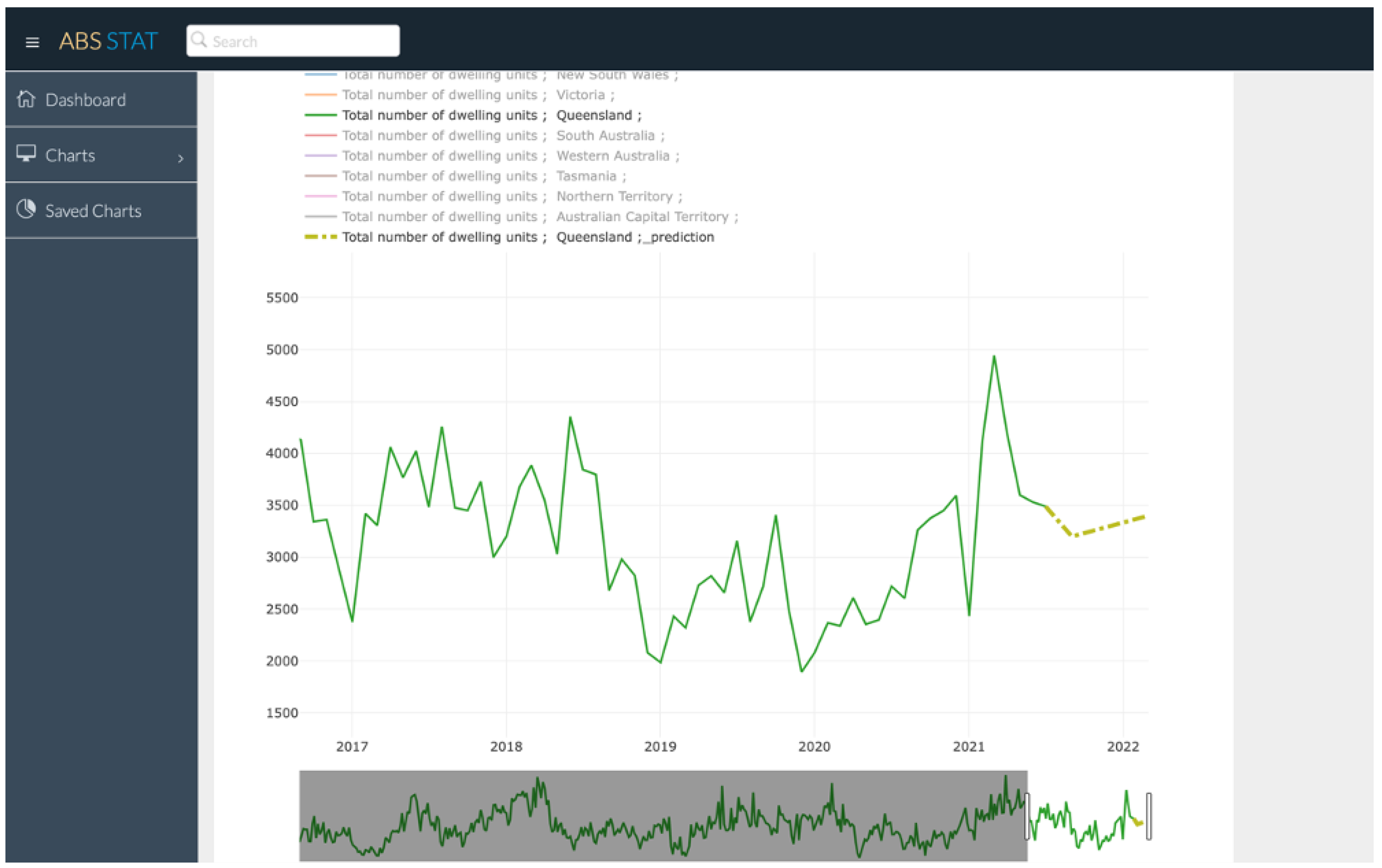
3.3.1. Functionalities
3.3.2. Implementation
4. Experiments
4.1. Model Settings
4.2. Lstm Model Performance
- The number of iterations, denoted as ;
- PCA output dimension, denoted as ;
- The length of input data points, denoted as ;
- The length of output data points, denoted as .
4.2.1. Varying
4.2.2. Varying and
4.2.3. Varying
4.3. Sarima and LSTM Model Results Comparison
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taylor, J. A Comparison of Univariate Time Series Methods for Forecasting Intraday Arrivals at a Call Center. Manag. Sci. 2007, 54, 253–265. [Google Scholar] [CrossRef] [Green Version]
- Mengjiao, Q.; Zhihang, L.; Zhenhong, D. Red tide time series forecasting by combining ARIMA and deep belief network. Knowl.-Based Syst. 2017, 125, 39–52. [Google Scholar]
- Mehrmolaei, S.; Keyvanpour, M. Time series forecasting using improved ARIMA. In Proceedings of the 6th conference on Artificial Intelligence and Robotics (IRANOPEN), Qazvin, Iran, 6–8 April 2016; pp. 92–97. [Google Scholar]
- Sezer, O.; Gudelek, U.; Ozbayoglu, M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106–181. [Google Scholar] [CrossRef] [Green Version]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Elsworth, S.; Güttel, S. Time Series Forecasting Using LSTM Networks: A Symbolic Approach. 2020. Available online: http://xxx.lanl.gov/abs/2003.05672 (accessed on 14 February 2022).
- Gers, F.; Eck, D.; Schmidhuber, J. Applying LSTM to Time Series Predictable through Time-Window Approaches. In Proceedings of the International Conference Vienna on Artificial Neural Networks (ICANN 2001), Vienna, Austria, 21–25 August 2001; pp. 669–676. [Google Scholar]
- Jian, W.; Wei, P.J.; Zhao, L.; Yang, L. A New Multi-Scale Sliding Window LSTM Framework (MSSW-LSTM): A Case Study for GNSS Time-Series Prediction. Remote Sens. 2021, 13, 3328. [Google Scholar]
- Gers, F.; Schmidhuber, J. Learning Precise Timing with LSTM Recurrent Networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Kumar, J.; Goomer, R.; Singh, A.K. Long Short Term Memory Recurrent Neural Network (LSTM-RNN) Based Workload Forecasting Model For Cloud Datacenters. Procedia Comput. Sci. 2018, 125, 676–682. [Google Scholar] [CrossRef]
- Chniti, G.; Bakir, H.; Zaher, H. E-Commerce Time Series Forecasting Using LSTM Neural Network and Support Vector Regression. In Proceedings of the 2017 International Conference on Big Data and Internet of Things (BDIOT 2017), London, UK, 20–22 December 2017; pp. 80–84. [Google Scholar]
- Box GEP, J.G. Time Series Analysis: Forecasting and Control, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Wang, J.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Chen, P.; Niu, A.; Liu, D.; Jiang, W.; Ma, B. Time Series Forecasting of Temperatures using SARIMA: An Example from Nanjing. IOP Conf. Ser. Mater. Sci. Eng. 2018, 394, 669–676. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Boslaugh, S. Statistics in a Nutshell, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Jolliffe, I.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- JAVASCRIPT.INFO LocalStorage, SessionStorage. 2015. Available online: https://javascript.info/localstorage (accessed on 14 February 2022).
- Grinberg, M. Flask Web Development: Developing Web Applications with Python, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Bierer, D. Learn MongoDB 4.x: A Guide to Understanding MongoDB Development and Administration for NoSQL Developers, 2nd ed.; Packt Publishing: Birmingham, UK, 2020. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Siami Namin, A. A Comparison of ARIMA and LSTM in Forecasting Time Series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Yunpeng, L.; Di, H.; Junpeng, B.; Yong, Q. Multi-step Ahead Time Series Forecasting for Different Data Patterns Based on LSTM Recurrent Neural Network. In Proceedings of the 2017 14th Web Information Systems and Applications Conference (WISA), Liuzhou, China, 11–12 November 2017; pp. 305–310. [Google Scholar]
- Yamak, P.T.; Yujian, L.; Gadosey, P.K. A Comparison between ARIMA, LSTM, and GRU for Time Series Forecasting. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 49–55. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.E.; Chang, R.; Zhu, M.; Zuo, J. Time Series Visualization and Forecasting from Australian Building and Construction Statistics. Appl. Sci. 2022, 12, 2420. https://doi.org/10.3390/app12052420
Zhang WE, Chang R, Zhu M, Zuo J. Time Series Visualization and Forecasting from Australian Building and Construction Statistics. Applied Sciences. 2022; 12(5):2420. https://doi.org/10.3390/app12052420
Chicago/Turabian StyleZhang, Wei Emma, Ruidong Chang, Minhao Zhu, and Jian Zuo. 2022. "Time Series Visualization and Forecasting from Australian Building and Construction Statistics" Applied Sciences 12, no. 5: 2420. https://doi.org/10.3390/app12052420
APA StyleZhang, W. E., Chang, R., Zhu, M., & Zuo, J. (2022). Time Series Visualization and Forecasting from Australian Building and Construction Statistics. Applied Sciences, 12(5), 2420. https://doi.org/10.3390/app12052420