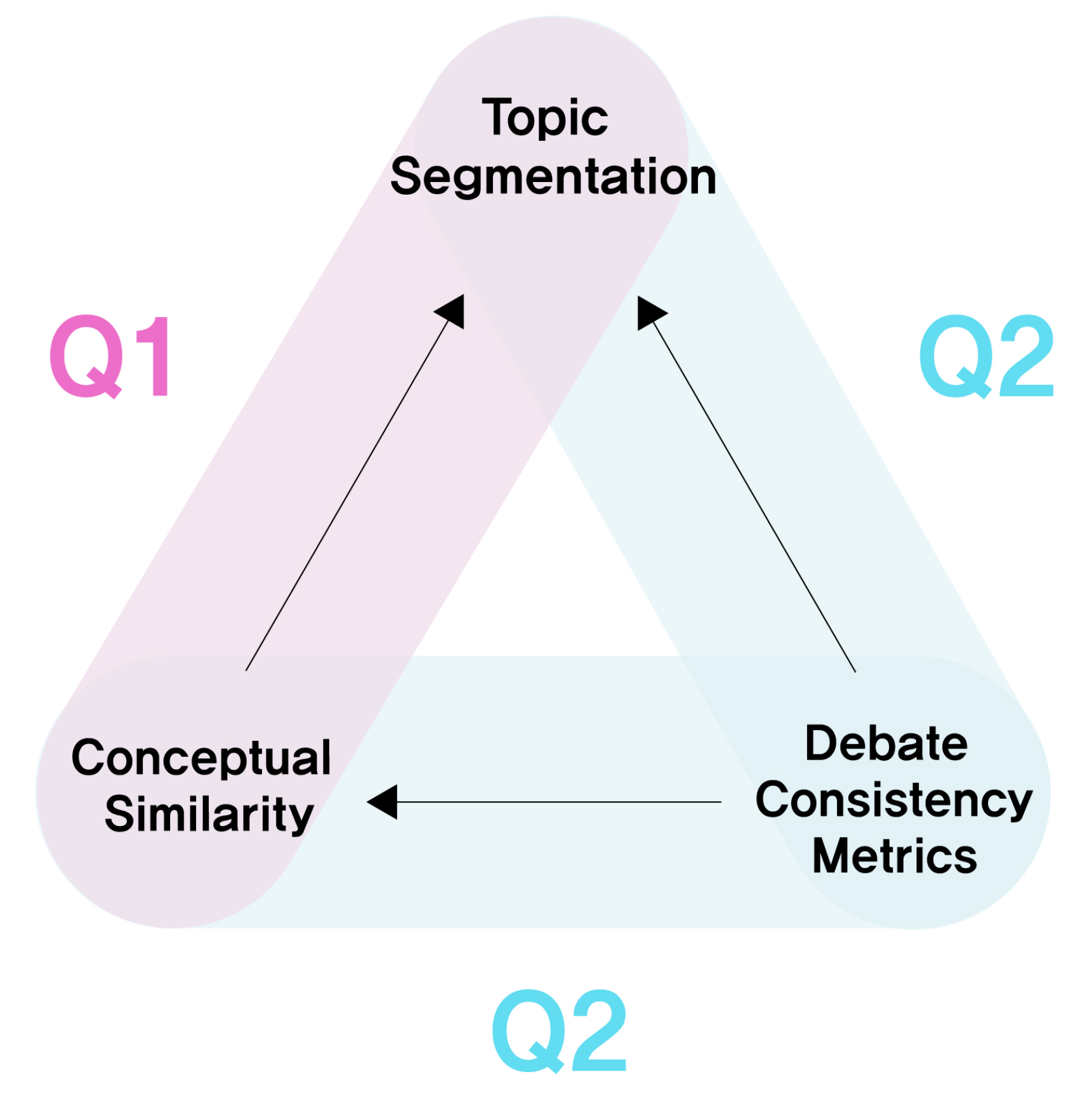
Figure 1.
Two research questions Q1 and Q2. Q1 is whether conceptual similarity affects topic segmentation. Q2 is whether debate consistency metrics affect conceptual similarity, and thus topic segmentation.
Figure 1.
Two research questions Q1 and Q2. Q1 is whether conceptual similarity affects topic segmentation. Q2 is whether debate consistency metrics affect conceptual similarity, and thus topic segmentation.
Figure 2.
The research framework of the proposed CSseg.
Figure 2.
The research framework of the proposed CSseg.
Figure 3.
Data structure organized by each speaker’s utterance unit.
Figure 3.
Data structure organized by each speaker’s utterance unit.
Figure 4.
An example of morphological analysis result. Along with an example of a Korean sentence, there is an example translated into English. Ellipses indicate morphemes predicted as NNP and NNG. The green ellipses represent the terms finally selected for the term list, and the red ellipses represent terms included in NNP and NNG but treated as stopwords.
Figure 4.
An example of morphological analysis result. Along with an example of a Korean sentence, there is an example translated into English. Ellipses indicate morphemes predicted as NNP and NNG. The green ellipses represent the terms finally selected for the term list, and the red ellipses represent terms included in NNP and NNG but treated as stopwords.
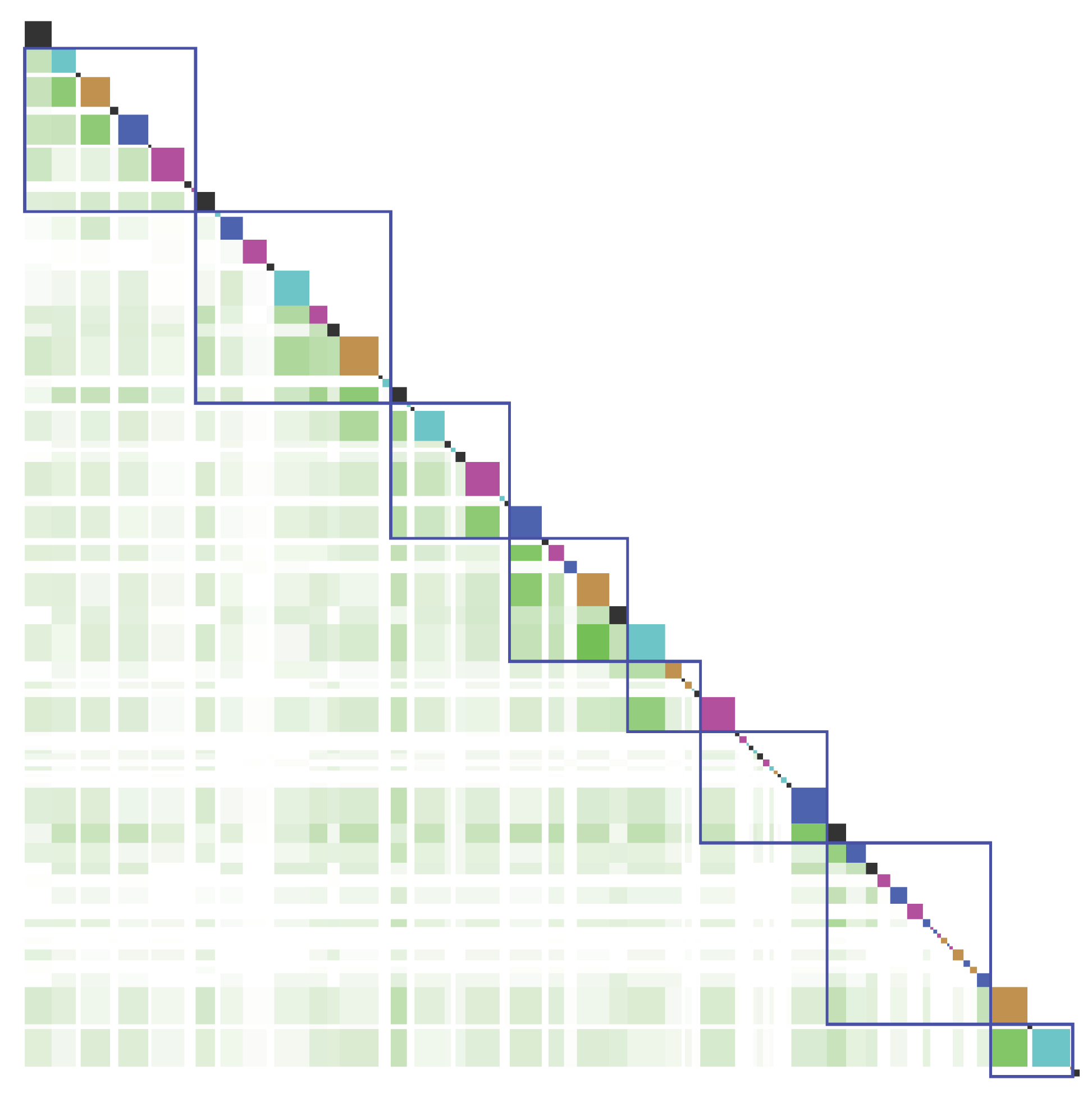
Figure 5.
Visualization of conceptual recurrence as a conceptual recurrence plot. The cyan, orange, purple, and blue squares at the top represent utterances. The larger the utterance, the larger the square. The utterances proceed diagonally from the upper left to the lower right. i denotes an index based on the horizontal axis, and j denotes an index based on the vertical axis. For example, these represent the i-th utterance based on the horizontal axis and the j-th utterance based on the vertical axis. A light green square represents conceptual similarity, which means a similarity between the upper utterance and the right utterance. The higher the light green saturation, the higher the conceptual similarity value.
Figure 5.
Visualization of conceptual recurrence as a conceptual recurrence plot. The cyan, orange, purple, and blue squares at the top represent utterances. The larger the utterance, the larger the square. The utterances proceed diagonally from the upper left to the lower right. i denotes an index based on the horizontal axis, and j denotes an index based on the vertical axis. For example, these represent the i-th utterance based on the horizontal axis and the j-th utterance based on the vertical axis. A light green square represents conceptual similarity, which means a similarity between the upper utterance and the right utterance. The higher the light green saturation, the higher the conceptual similarity value.
Figure 6.
Four small sets of topic segments. Red squares indicate topic segments. Since the way CSseg divides the transcript is by dividing one topic segment into two topic segments, we intend to designate these two adjacent topic segments as a unit, which is called a small set of topic segments.
Figure 6.
Four small sets of topic segments. Red squares indicate topic segments. Since the way CSseg divides the transcript is by dividing one topic segment into two topic segments, we intend to designate these two adjacent topic segments as a unit, which is called a small set of topic segments.
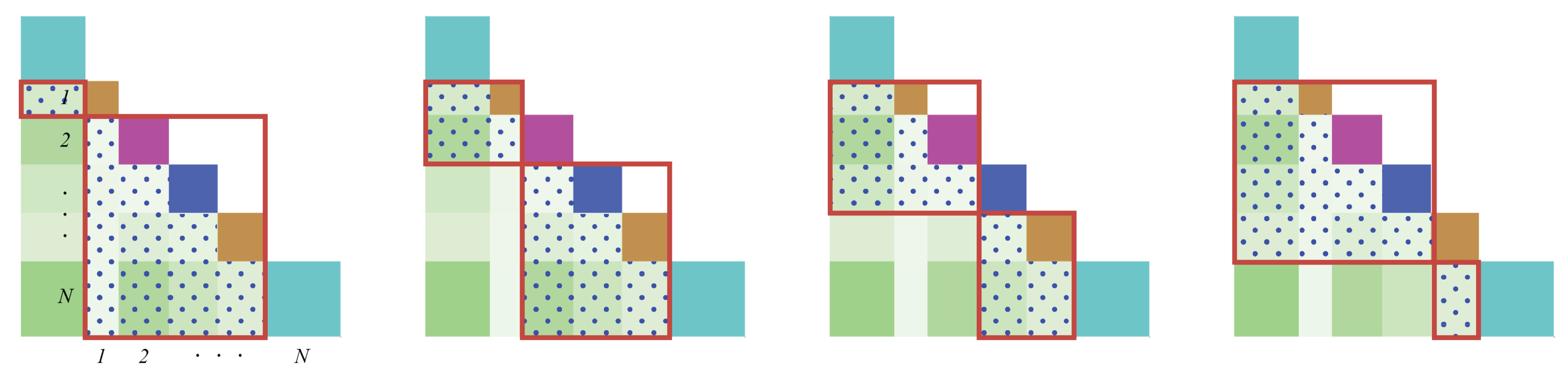
Figure 7.
Examples of conceptual similarities used in the Plane method. Each red square represents a topic segment. The light green squares with blue dots inside the red squares indicate the conceptual similarities used in the Plane method.
Figure 7.
Examples of conceptual similarities used in the Plane method. Each red square represents a topic segment. The light green squares with blue dots inside the red squares indicate the conceptual similarities used in the Plane method.
Figure 8.
Examples of conceptual similarities used in the Line method. Each red square represents a topic segment. The light green squares with red dots inside the red squares indicate the conceptual similarities used in the Line method.
Figure 8.
Examples of conceptual similarities used in the Line method. Each red square represents a topic segment. The light green squares with red dots inside the red squares indicate the conceptual similarities used in the Line method.
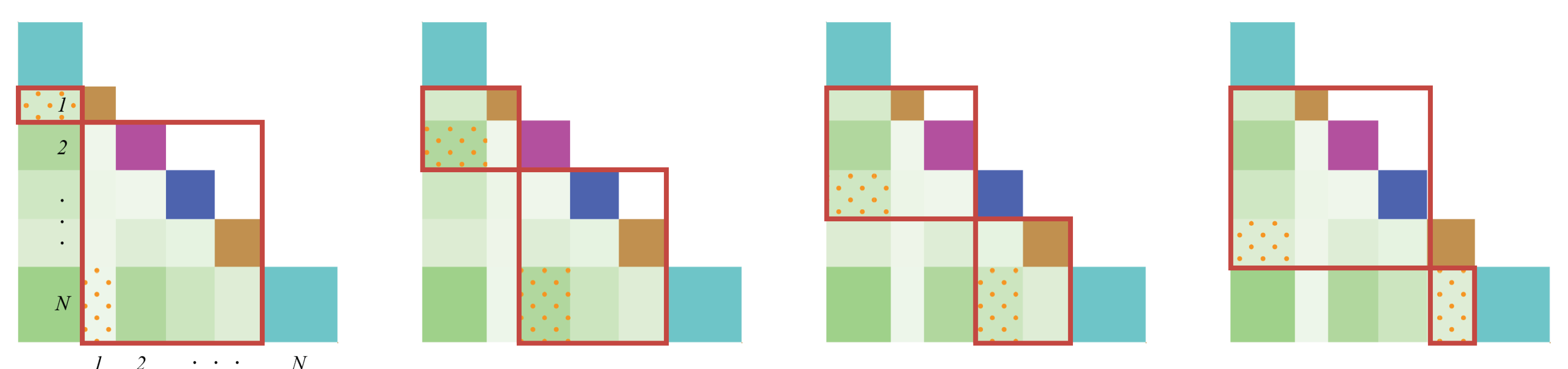
Figure 9.
Examples of conceptual similarities used in the Point method. Each red square represents a topic segment. The light green squares with orange dots inside the red squares indicate the conceptual similarities used in the Point method.
Figure 9.
Examples of conceptual similarities used in the Point method. Each red square represents a topic segment. The light green squares with orange dots inside the red squares indicate the conceptual similarities used in the Point method.
Figure 10.
Examples of conceptual similarities used in the combined method (Plane + Line + Point). Each red square represents a topic segment. The light green squares with blue dots indicate the conceptual similarities used in the Plane method. The light green squares with red dots indicate the conceptual similarities used in the Line method. The light green squares with orange dots indicate the conceptual similarities used in the Point method.
Figure 10.
Examples of conceptual similarities used in the combined method (Plane + Line + Point). Each red square represents a topic segment. The light green squares with blue dots indicate the conceptual similarities used in the Plane method. The light green squares with red dots indicate the conceptual similarities used in the Line method. The light green squares with orange dots indicate the conceptual similarities used in the Point method.
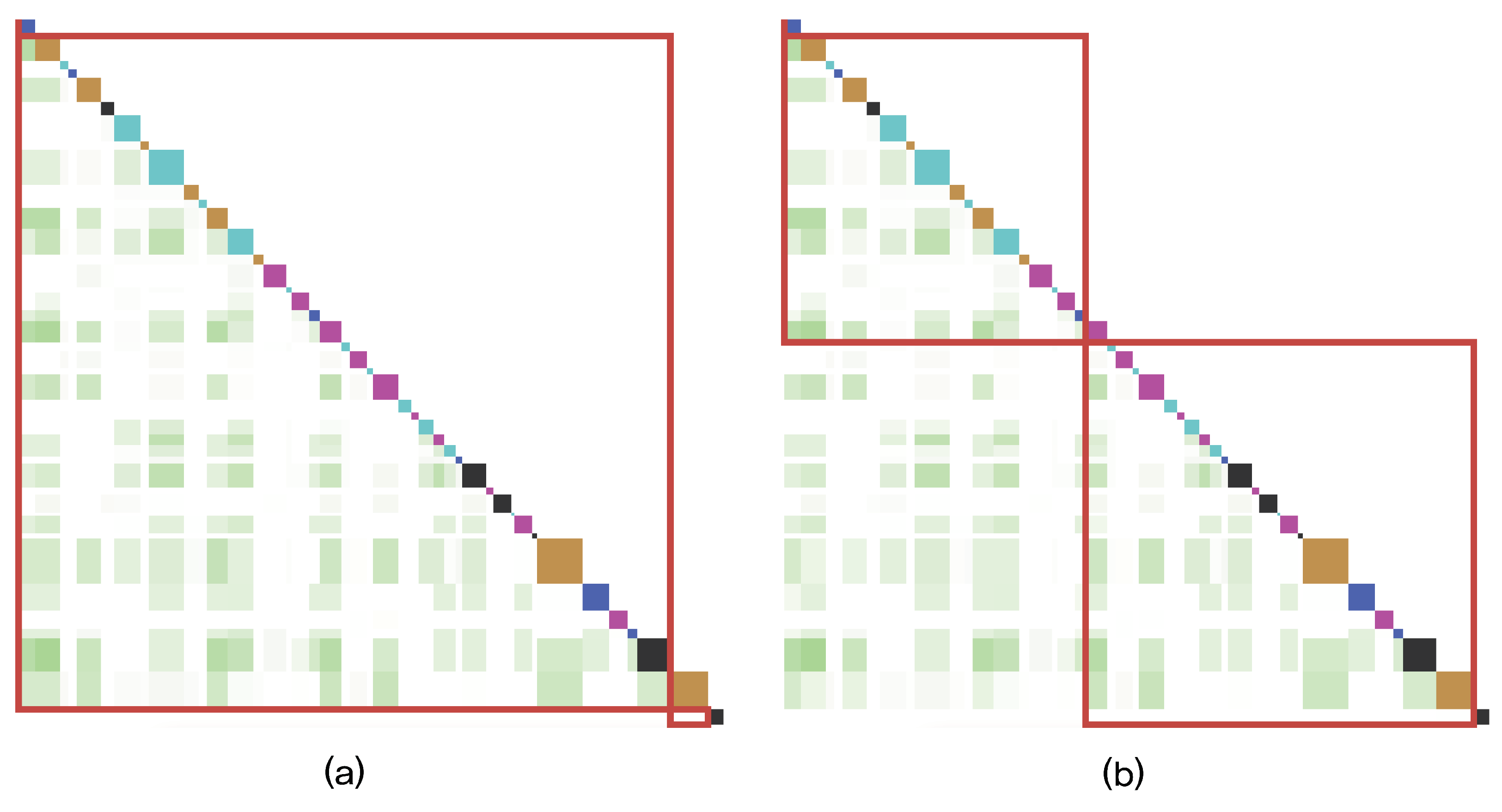
Figure 11.
Before (a) and after (b) other-continuity is applied to conceptual similarities. By applying the weight of the metric that quantifies the other-continuity, the transcript is segmented based on the corresponding conceptual similarities of other-continuity.
Figure 11.
Before (a) and after (b) other-continuity is applied to conceptual similarities. By applying the weight of the metric that quantifies the other-continuity, the transcript is segmented based on the corresponding conceptual similarities of other-continuity.
Figure 12.
Before (a) and after (b) self-continuity is applied to conceptual similarities. By applying the weight of the metric that quantifies the self-continuity, the transcript is segmented based on the corresponding conceptual similarities of self-continuity.
Figure 12.
Before (a) and after (b) self-continuity is applied to conceptual similarities. By applying the weight of the metric that quantifies the self-continuity, the transcript is segmented based on the corresponding conceptual similarities of self-continuity.
Figure 13.
Before (a) and after (b) chain of arguments and counterarguments is applied to conceptual similarities. By applying the weight of the metric that quantifies the chain of arguments and counterarguments, the transcript is segmented based on the corresponding conceptual similarities of arguments and counterarguments.
Figure 13.
Before (a) and after (b) chain of arguments and counterarguments is applied to conceptual similarities. By applying the weight of the metric that quantifies the chain of arguments and counterarguments, the transcript is segmented based on the corresponding conceptual similarities of arguments and counterarguments.
Figure 14.
Before (a) and after (b) topic guide of moderator is applied to conceptual similarities. By applying the weight of the metric that quantifies the topic guide of moderator, the transcript is segmented based on the corresponding conceptual similarities including moderator’s utterance.
Figure 14.
Before (a) and after (b) topic guide of moderator is applied to conceptual similarities. By applying the weight of the metric that quantifies the topic guide of moderator, the transcript is segmented based on the corresponding conceptual similarities including moderator’s utterance.
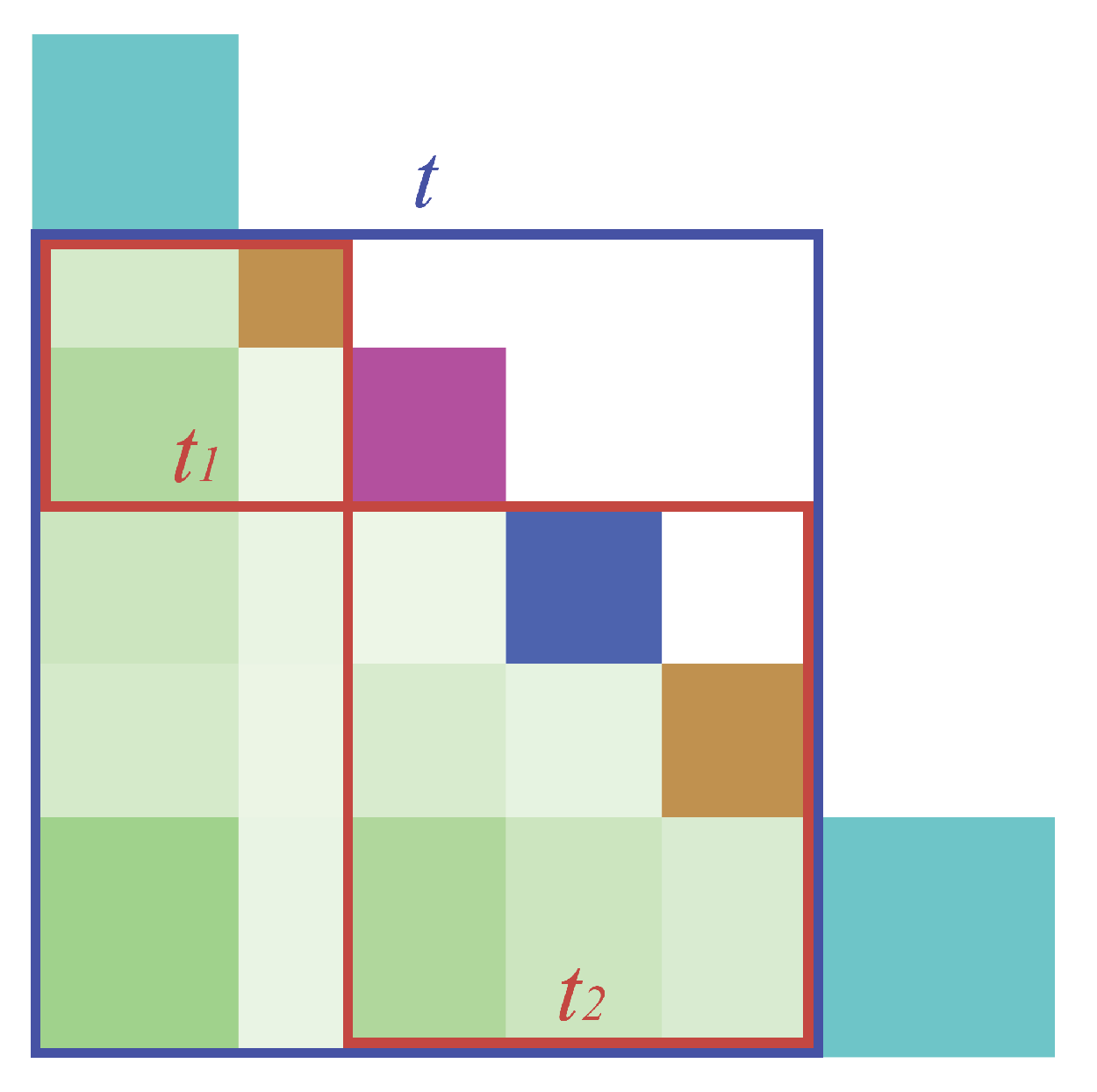
Figure 15.
Example showing two adjacent topic segments , , and a parent topic segment t in a small set of topic segments.
Figure 15.
Example showing two adjacent topic segments , , and a parent topic segment t in a small set of topic segments.
Figure 16.
Graphical model representation of CSseg.
Figure 16.
Graphical model representation of CSseg.
Figure 17.
User interface of CSseg: (a) is a controller with functions affecting topic segmentation; (b) is a visualization of conceptual recurrence showing all utterances, conceptual similarities, and topic segments; (c) is a transcript viewer that shows the content of the debate participants’ utterances.
Figure 17.
User interface of CSseg: (a) is a controller with functions affecting topic segmentation; (b) is a visualization of conceptual recurrence showing all utterances, conceptual similarities, and topic segments; (c) is a transcript viewer that shows the content of the debate participants’ utterances.
Figure 18.
Conceptual similarities between Jaemyung Lee and Sehun Oh in the 100-Munite Debate “Is the era of basic income really coming?”
Figure 18.
Conceptual similarities between Jaemyung Lee and Sehun Oh in the 100-Munite Debate “Is the era of basic income really coming?”
Figure 19.
Details of conceptual similarity when the user mouseovers the square.
Figure 19.
Details of conceptual similarity when the user mouseovers the square.
Figure 20.
User interface configured to collect topic segmentation points from a subject.
Figure 20.
User interface configured to collect topic segmentation points from a subject.
Figure 21.
Topic segmentation points in ‘basic income’.
Figure 21.
Topic segmentation points in ‘basic income’.
Figure 22.
Topic segmentation points in ‘volunteer military system’.
Figure 22.
Topic segmentation points in ‘volunteer military system’.
Figure 23.
Topic segmentation points in ‘SAT’.
Figure 23.
Topic segmentation points in ‘SAT’.
Figure 24.
Results of segmenting transcripts based on topic segmentation points marked at the same location by more than three out of seven subjects.
Figure 24.
Results of segmenting transcripts based on topic segmentation points marked at the same location by more than three out of seven subjects.
Figure 25.
Exploration process of the probe of , . Colored squares represent each sentence. The leftmost square represents the first sentence of text, and the color of the square represents the topic. The U-shaped joined arrows represent the probe, which moves one sentence at a time from left to right, as shown by the dotted lines.
Figure 25.
Exploration process of the probe of , . Colored squares represent each sentence. The leftmost square represents the first sentence of text, and the color of the square represents the topic. The U-shaped joined arrows represent the probe, which moves one sentence at a time from left to right, as shown by the dotted lines.
Figure 26.
Simplified Lexical Chains. The squares at the top indicate sentences. – represent the lexical chains for each word A to I.
Figure 26.
Simplified Lexical Chains. The squares at the top indicate sentences. – represent the lexical chains for each word A to I.
Figure 27.
Topic segments of CSseg where Plane, Line, and Point are combined and the debate consistency metrics are applied.
Figure 27.
Topic segments of CSseg where Plane, Line, and Point are combined and the debate consistency metrics are applied.
Figure 28.
Topic segments of LCseg.
Figure 28.
Topic segments of LCseg.
Figure 29.
A controller with all debate consistency metrics applied. (a) Control variables are shown. The number of topic segments was controlled to 8. Similarity cohesion calculation methods were controlled with the weights for Plane, Line, and Point in a 1:1:1 ratio. (b) Weights of all debate consistency metrics were doubled in the direction of improving internal consistency.
Figure 29.
A controller with all debate consistency metrics applied. (a) Control variables are shown. The number of topic segments was controlled to 8. Similarity cohesion calculation methods were controlled with the weights for Plane, Line, and Point in a 1:1:1 ratio. (b) Weights of all debate consistency metrics were doubled in the direction of improving internal consistency.
Figure 30.
Result of topic segmentation after doubling the weights of all debate consistency metrics in the direction of improved internal consistency.
Figure 30.
Result of topic segmentation after doubling the weights of all debate consistency metrics in the direction of improved internal consistency.
Figure 31.
Comparison of a case where weight of “topic guide of moderator” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments when weighted only by “topic guide of moderator”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Figure 31.
Comparison of a case where weight of “topic guide of moderator” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments when weighted only by “topic guide of moderator”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Figure 32.
Result of comparing a case where weight of “chain of arguments and counterarguments” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments of a result weighted only by “chain of arguments and counterarguments”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Figure 32.
Result of comparing a case where weight of “chain of arguments and counterarguments” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments of a result weighted only by “chain of arguments and counterarguments”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Figure 33.
Result of comparing a case where weight of “other-continuity”, “self-continuity” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments of a result weighted only by “other-continuity and self-continuity”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Figure 33.
Result of comparing a case where weight of “other-continuity”, “self-continuity” was applied and a case where all weights of debate consistency metrics were applied. Red squares are topic segments of a result weighted only by “other-continuity and self-continuity”, and blue squares are topic segments of a result weighted by all debate consistency metrics.
Table 1.
and values of CSseg combined with Plane, Line, and Point and applied with debate consistency metrics, and of the existing model LCseg for multi-party discourse.
Table 1.
and values of CSseg combined with Plane, Line, and Point and applied with debate consistency metrics, and of the existing model LCseg for multi-party discourse.
|
| | Basic Income | Military | SAT |
| CSseg | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| CSseg | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 2.
and values of each similarity cohesion calculation method without applying debate consistency metrics of CSseg.
Table 2.
and values of each similarity cohesion calculation method without applying debate consistency metrics of CSseg.
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1371 |
| Line | 0.0802 | 0.1852 | 0.1371 |
| Point | 0.0693 | 0.1852 | 0.1371 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1371 |
| Line | 0.0802 | 0.1852 | 0.1371 |
| Point | 0.0693 | 0.1852 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 3.
CSseg and values when applying the debate consistency metrics of other-continuity, self-continuity, chain of arguments and counterarguments, and topic guide of moderator.
Table 3.
CSseg and values when applying the debate consistency metrics of other-continuity, self-continuity, chain of arguments and counterarguments, and topic guide of moderator.
|
| | Basic Income | Military | SAT |
| Plane | 0.0656 | 0.1429 | 0.1554 |
| Line | 0.0474 | 0.1429 | 0.1554 |
| Point | 0.0729 | 0.1429 | 0.1577 |
| Plane + Line | 0.0474 | 0.1217 | 0.1371 |
| Plane + Point | 0.0656 | 0.1429 | 0.1371 |
| Line + Point | 0.0474 | 0.1217 | 0.1371 |
| Plane + Line + Point | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0656 | 0.1429 | 0.1554 |
| Line | 0.0474 | 0.1429 | 0.1554 |
| Point | 0.0729 | 0.1429 | 0.1646 |
| Plane + Line | 0.0474 | 0.1217 | 0.1371 |
| Plane + Point | 0.0656 | 0.1429 | 0.1371 |
| Line + Point | 0.0474 | 0.1217 | 0.1371 |
| Plane + Line + Point | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 4.
CSseg and values with the weight of other-continuity set to 2.
Table 4.
CSseg and values with the weight of other-continuity set to 2.
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1554 |
| Line | 0.0802 | 0.1640 | 0.1371 |
| Point | 0.0802 | 0.1640 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1640 | 0.1554 |
| Line + Point | 0.0693 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1554 |
| Line | 0.0802 | 0.1640 | 0.1371 |
| Point | 0.0802 | 0.1640 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1640 | 0.1554 |
| Line + Point | 0.0693 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 5.
CSseg and values with the weight of self-continuity set to 0.5.
Table 5.
CSseg and values with the weight of self-continuity set to 0.5.
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1371 |
| Line | 0.0693 | 0.1640 | 0.1371 |
| Point | 0.0693 | 0.1852 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1371 |
| Line | 0.0693 | 0.1640 | 0.1371 |
| Point | 0.0693 | 0.1852 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1371 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 6.
CSseg and values with the weight of chain of arguments and counterarguments set to 2.
Table 6.
CSseg and values with the weight of chain of arguments and counterarguments set to 2.
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1554 |
| Line | 0.0802 | 0.1852 | 0.1371 |
| Point | 0.0729 | 0.1640 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1463 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0693 | 0.1693 | 0.1554 |
| Line | 0.0802 | 0.1852 | 0.1371 |
| Point | 0.0729 | 0.1640 | 0.1463 |
| Plane + Line | 0.0693 | 0.1852 | 0.1646 |
| Plane + Point | 0.0693 | 0.1693 | 0.1554 |
| Line + Point | 0.0802 | 0.1852 | 0.1463 |
| Plane + Line + Point | 0.0693 | 0.1852 | 0.1646 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |
Table 7.
CSseg and values with the weight of topic guide of moderator set to 2.
Table 7.
CSseg and values with the weight of topic guide of moderator set to 2.
|
| | Basic Income | Military | SAT |
| Plane | 0.0583 | 0.1429 | 0.1371 |
| Line | 0.0474 | 0.1217 | 0.1371 |
| Point | 0.0547 | 0.1429 | 0.1371 |
| Plane + Line | 0.0474 | 0.1217 | 0.1463 |
| Plane + Point | 0.0583 | 0.1429 | 0.1554 |
| Line + Point | 0.0474 | 0.1217 | 0.1371 |
| Plane + Line + Point | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1057 | 0.1693 | 0.1714 |
|
| | Basic Income | Military | SAT |
| Plane | 0.0583 | 0.1429 | 0.1371 |
| Line | 0.0474 | 0.1217 | 0.1371 |
| Point | 0.0547 | 0.1429 | 0.1371 |
| Plane + Line | 0.0474 | 0.1217 | 0.1463 |
| Plane + Point | 0.0583 | 0.1429 | 0.1554 |
| Line + Point | 0.0474 | 0.1217 | 0.1371 |
| Plane + Line + Point | 0.0474 | 0.1217 | 0.1463 |
| LCseg | 0.1094 | 0.1746 | 0.1783 |






































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}