
Automatic Understanding and Mapping of Regions in Cities Using Google Street View Images



Abstract
:1. Introduction
2. Related Work
3. Proposal
- Dataset Gathering:
- -
- Determining the path between streets using the Google Map API (directions).
- -
- Computing the GPS coordinates within the paths. Note that the paths from the Google Map API provide a set of points in that path. If two of those points are too distant, we interpolate new points between them.
- -
- Gathering and storing the images belonging to the coordinates in the paths with the GSV API.
- City Information:
- -
- A graph of streets and intersections of a real city using the GeoApi.
- -
- A dataset of images of the coordinates in the streets.
- CNN Image Labeling:
- -
- Labeling the images obtained using a pretrained CNN model.
- Semantic Descriptors:
- -
- A set of semantic descriptors of all the images in the city dataset.
- Reduction of Semantic Descriptors:
- -
- Generating a mean semantic descriptor using the four semantic descriptors of each point in the graph.
- Mean Semantic Descriptors:
- -
- A set of mean semantic descriptors of all the points in the city graph.
- Semantic Map Generation:
- -
- Generating a semantic map using semantic descriptors and a similitude clustering procedure.
- -
- Smoothing the generated map with KNN.
- Semantic Map:
- -
- Final output consisting of a semantic map for the city graph, indicating the different zones within the city.
4. Methodology
4.1. Gathering GPS Points
4.1.1. Geoapi España
4.1.2. Google Maps Directions API
- Routes between points.
- Selection of transportation method.
- Several Paths.
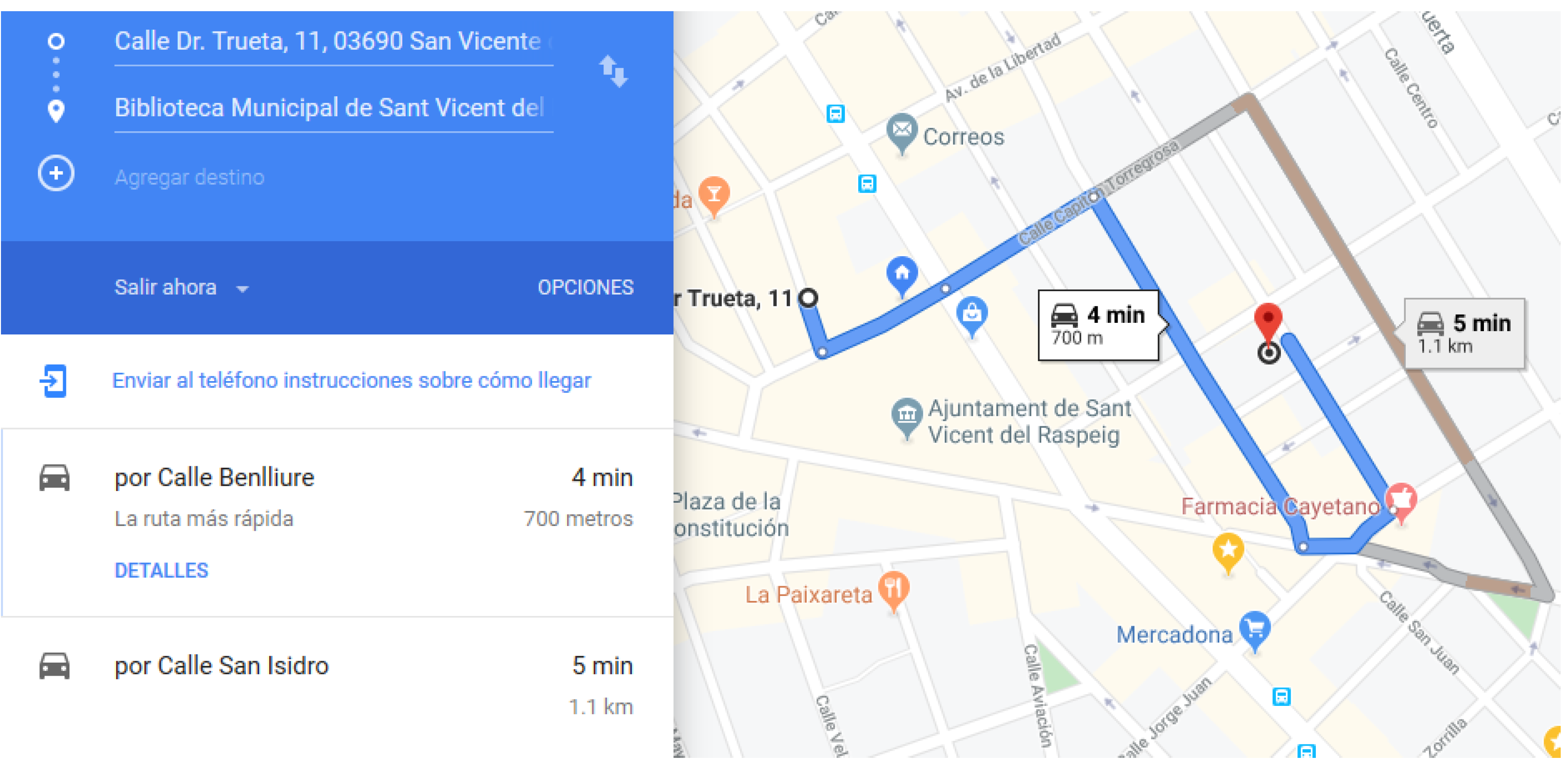
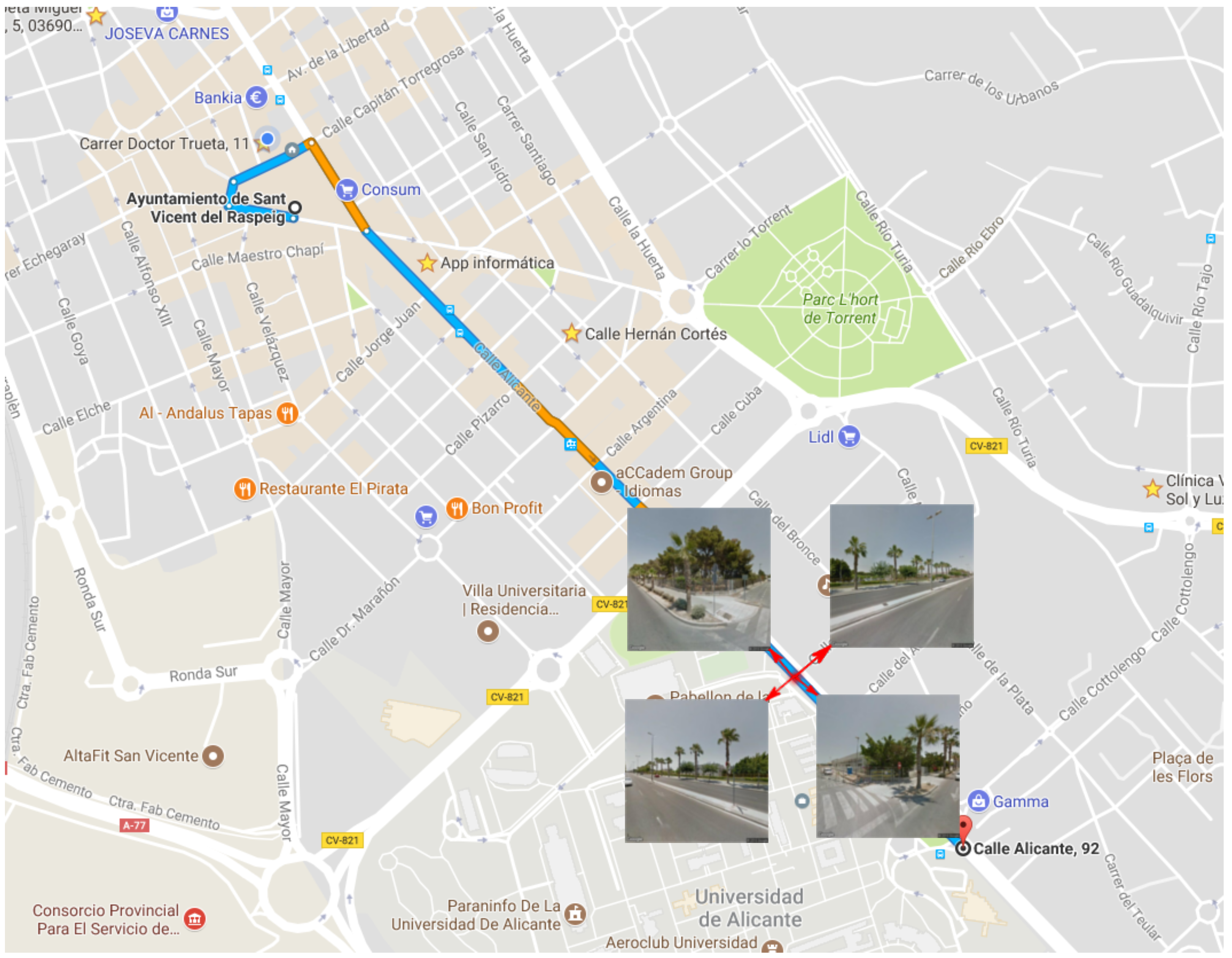
4.2. Obtaining Images
Google Street View Static API
- Images for a view (headings or yaw).
- Several image sizes.
- Several camera orientations of the view (pitch).
4.3. GPS Point and Image Acquisition Procedure
4.4. Lexical Labeling Using CNNs
4.4.1. Semantic CNN Descriptor
4.4.2. Mean CNN Descriptor
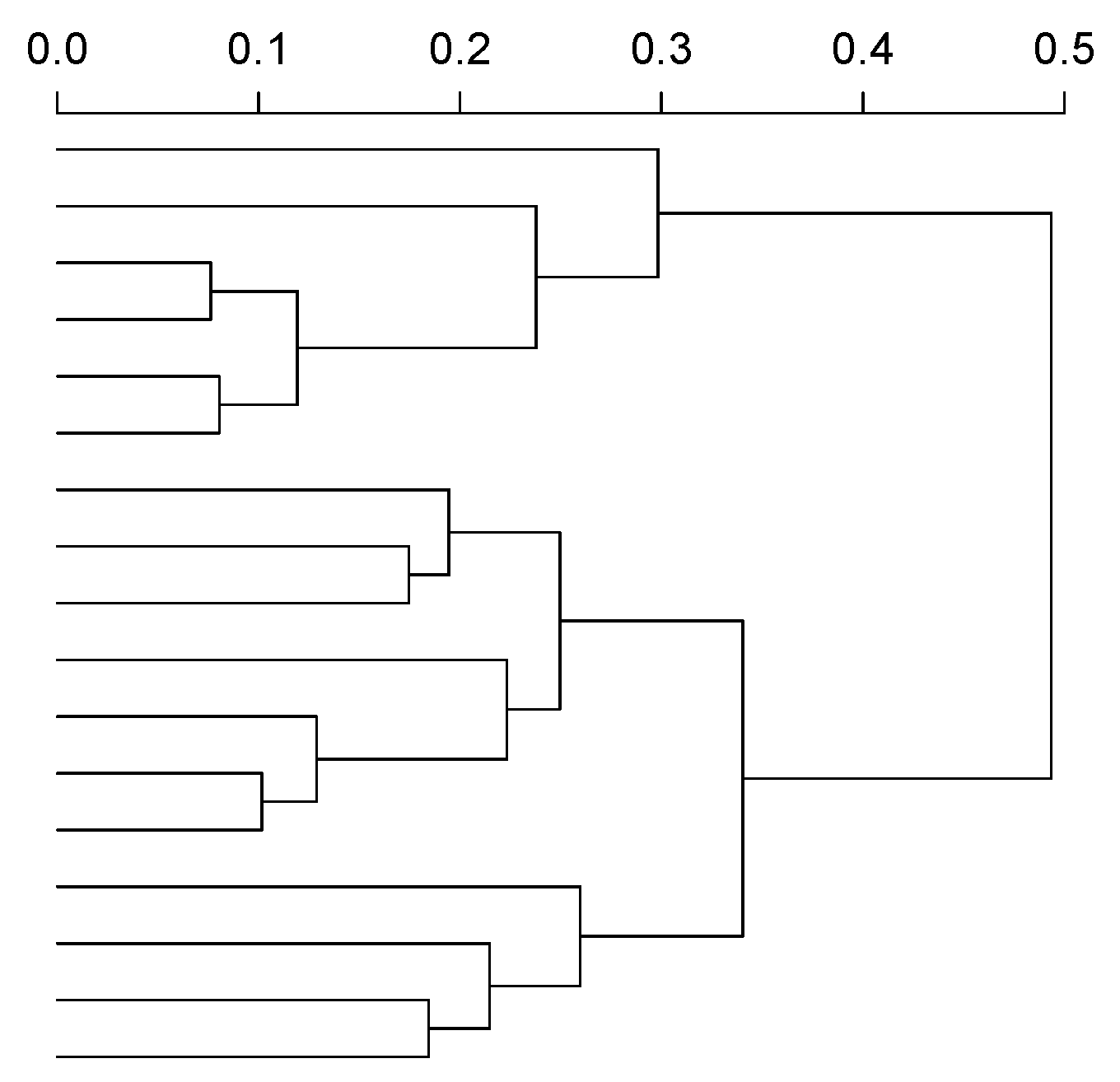
4.5. Bottom-Up Aggregation and Similarity Computation
4.6. KNN Map Smoothing Using GPS Coordinates
5. Experimentation
5.1. Experimental Setup
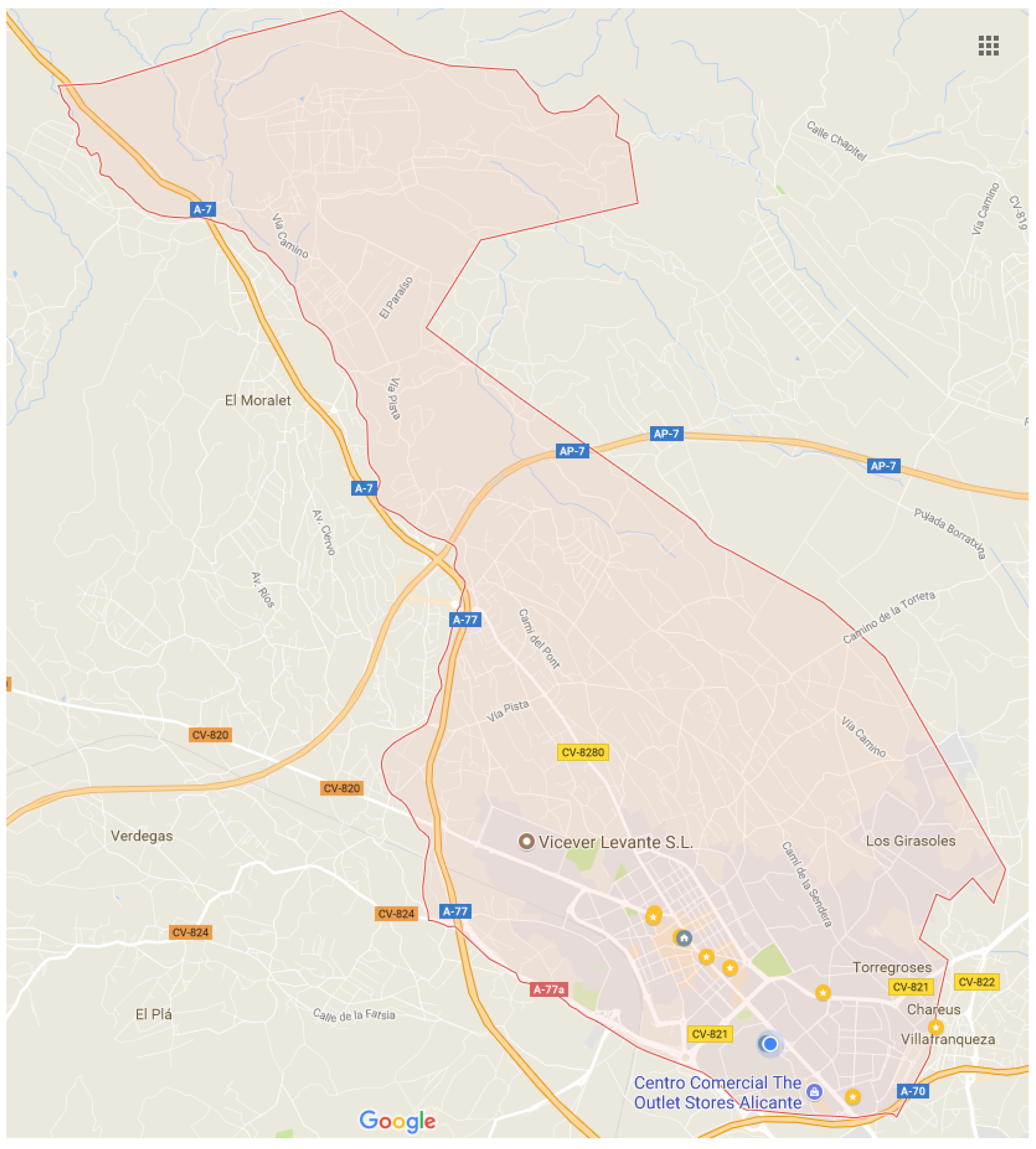
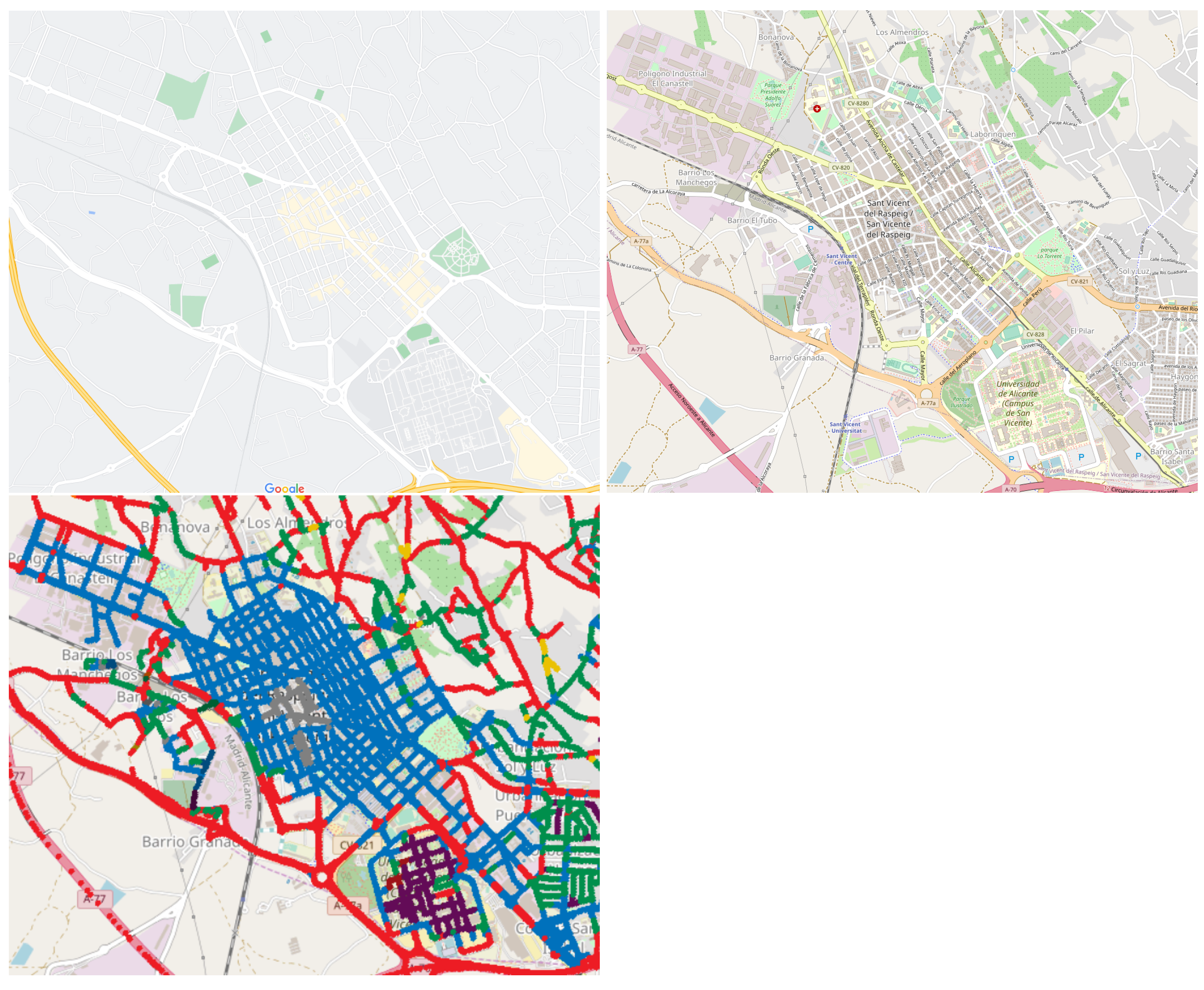
- City: San Vicente del Raspeig, Alicante, España (see Figure 6).
- CNN Model: Places-GoogLeNet [48].
- Class or categories number: 205.
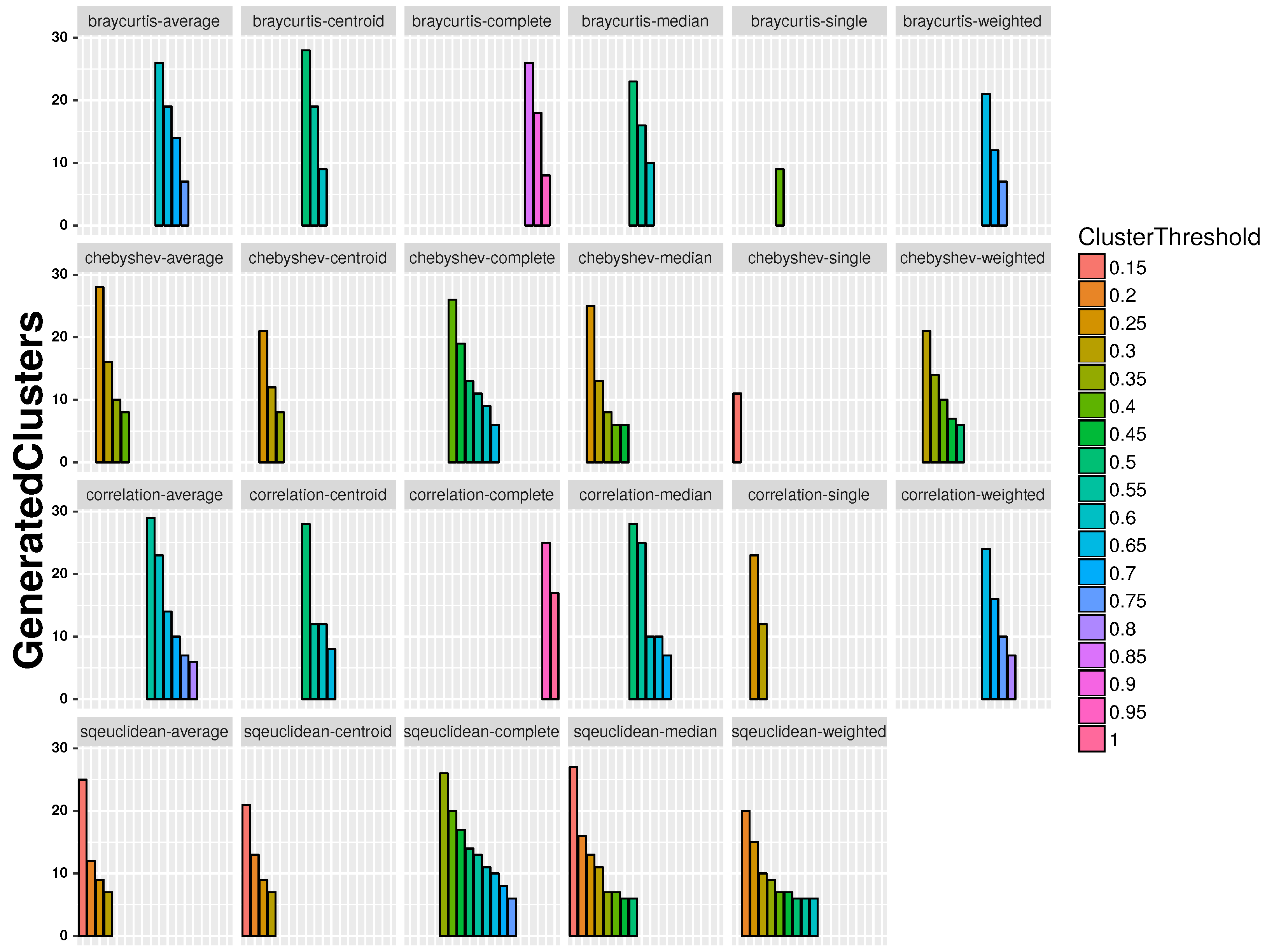
- Clustering threshold (): .
5.2. Pretrained CNN Model
5.3. Images from Street View API
6. Results
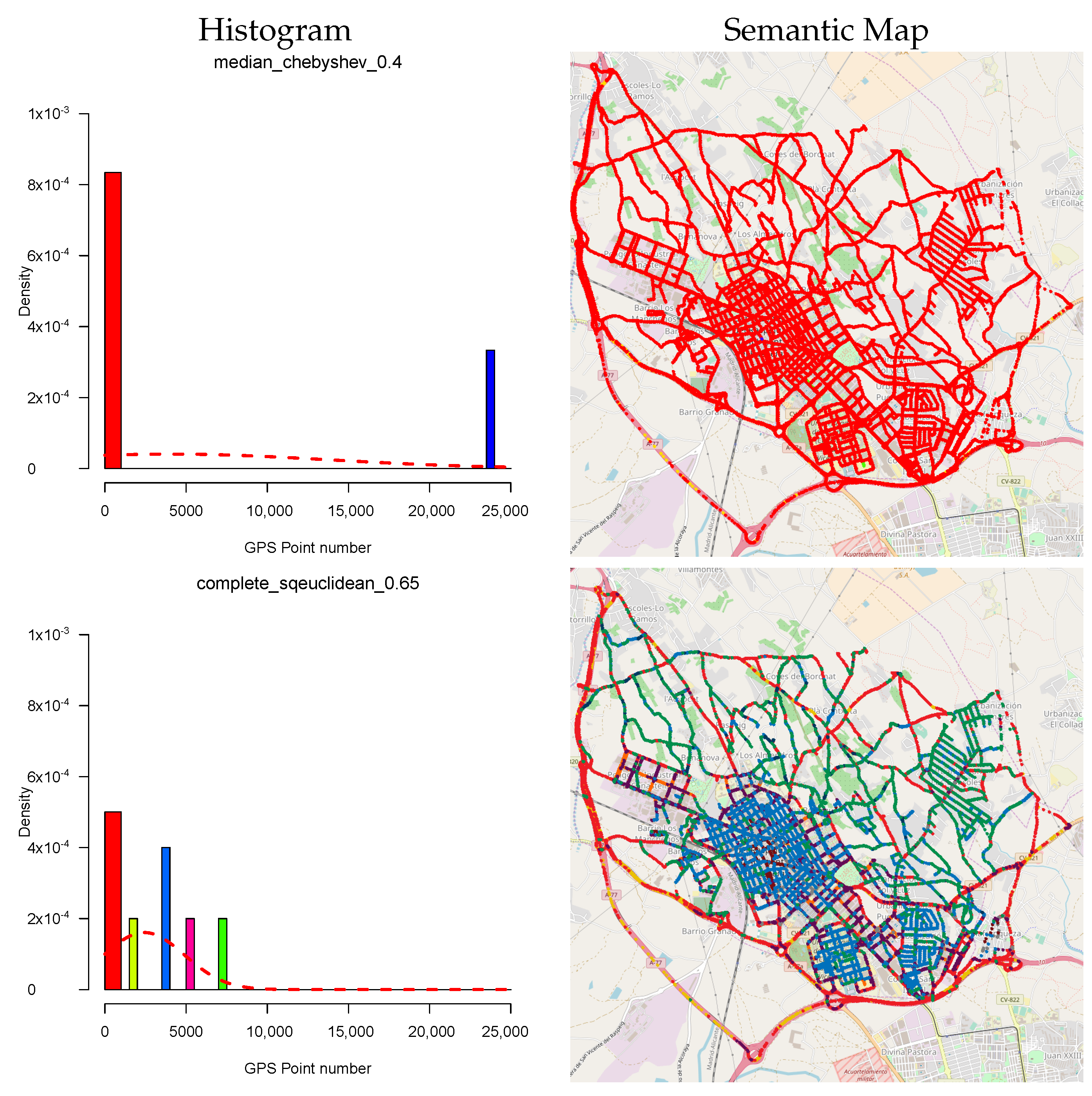
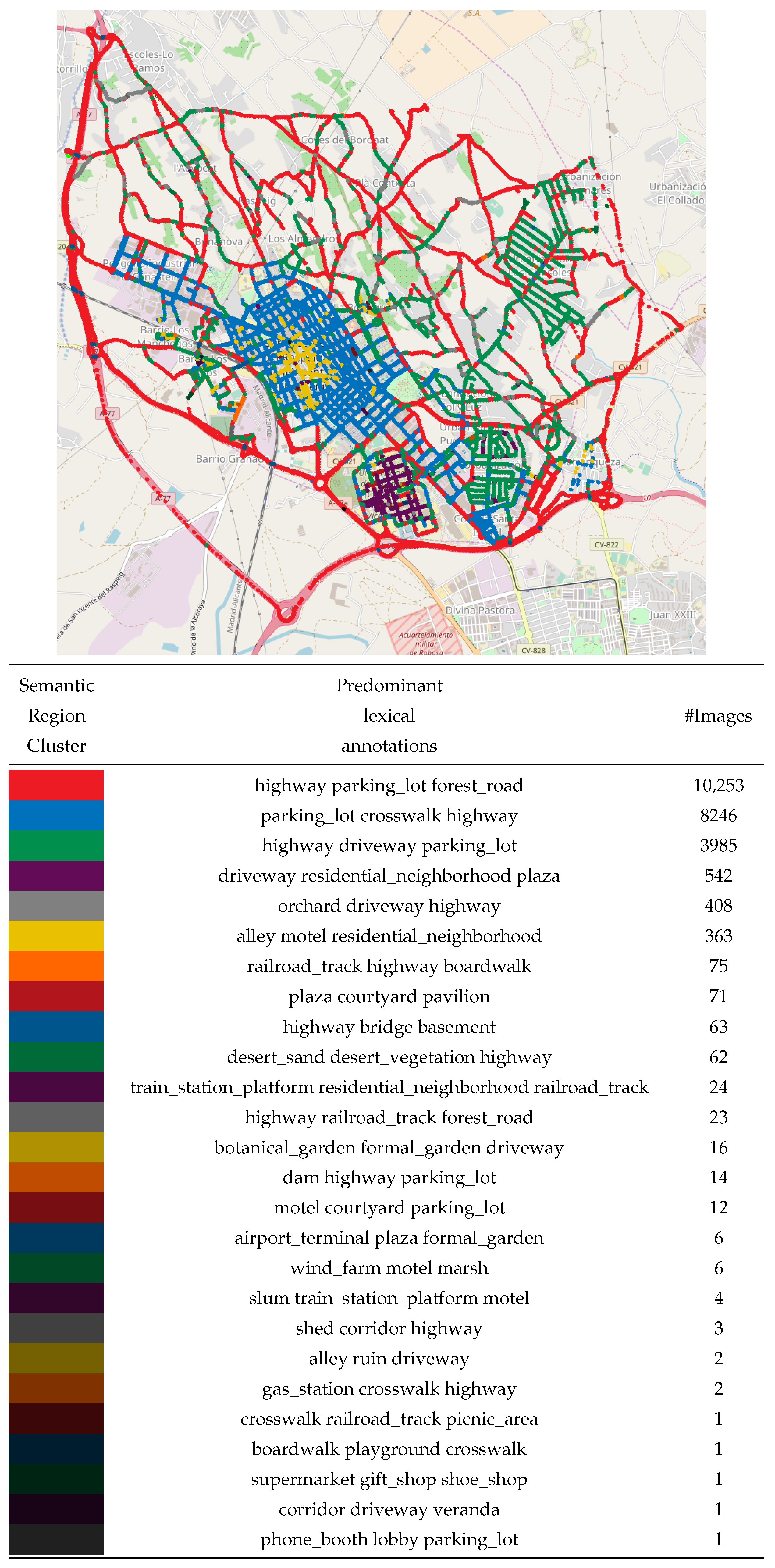
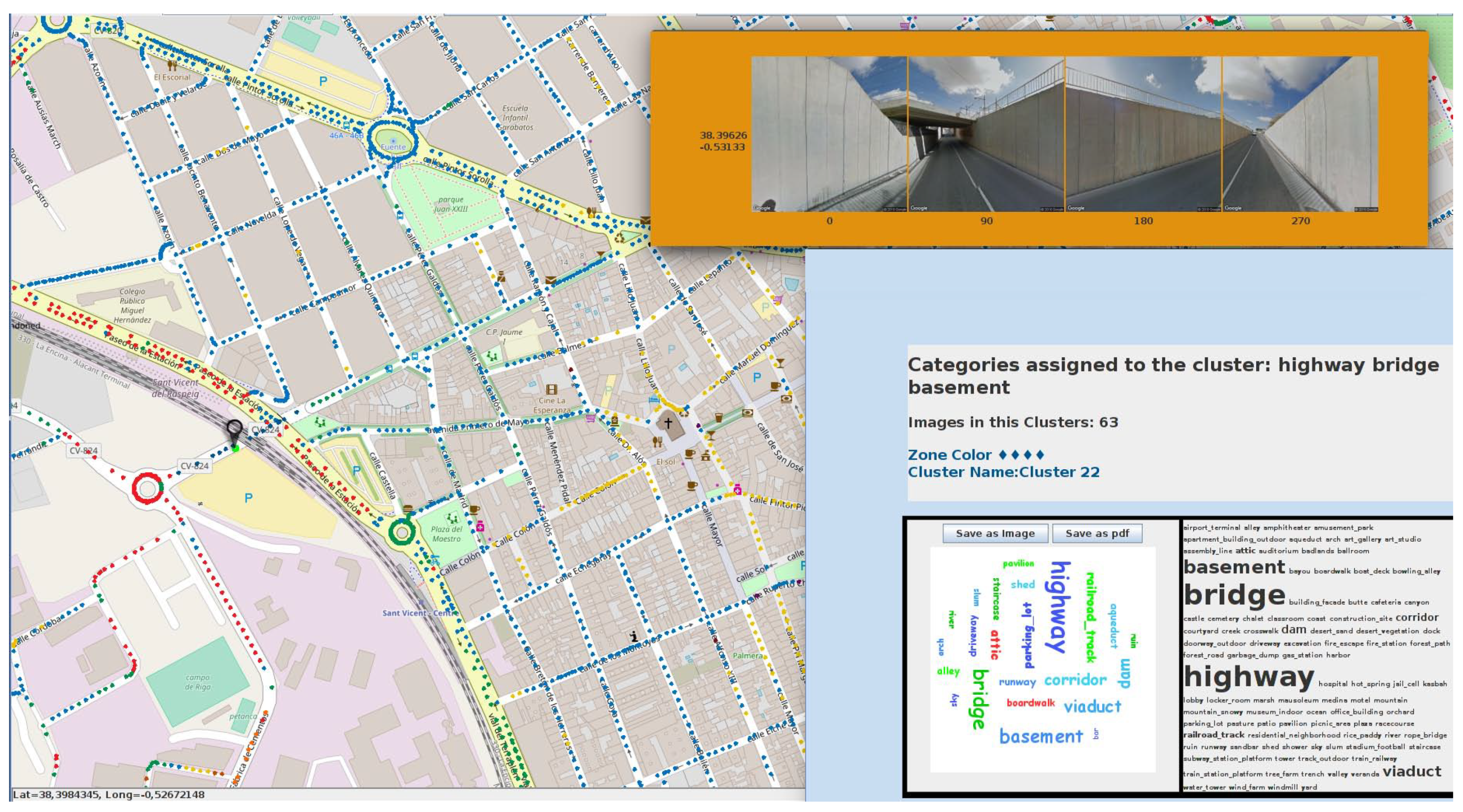
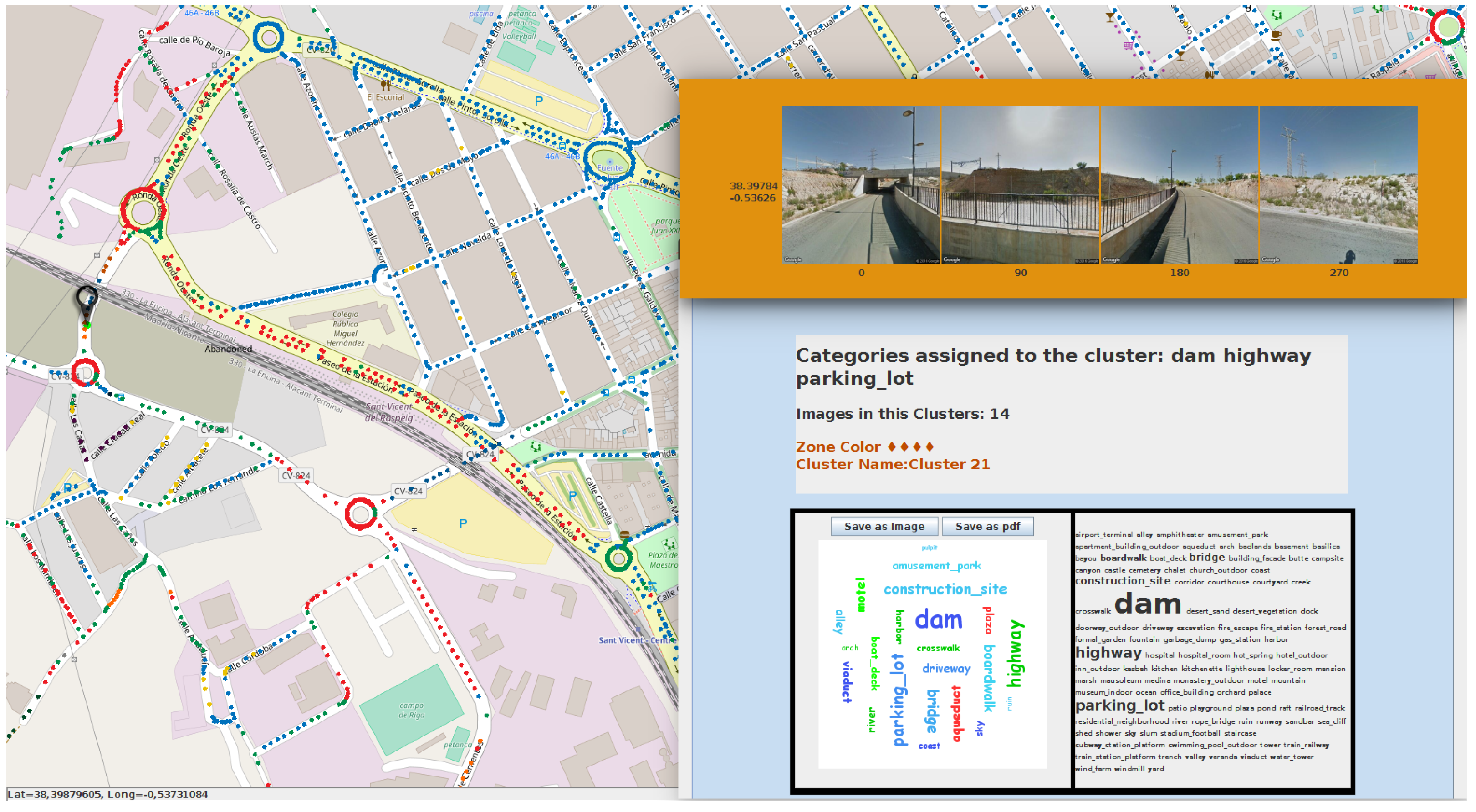
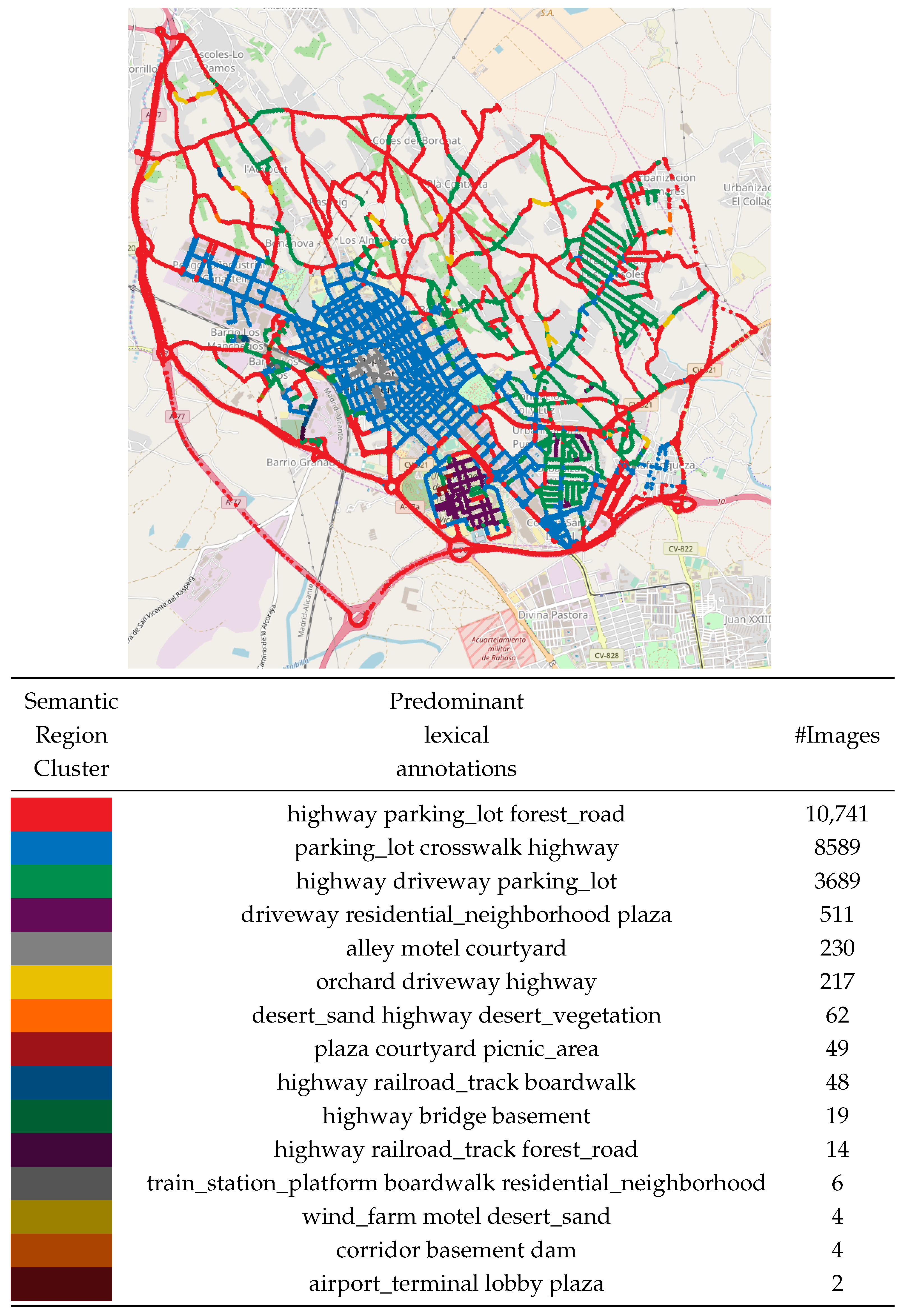
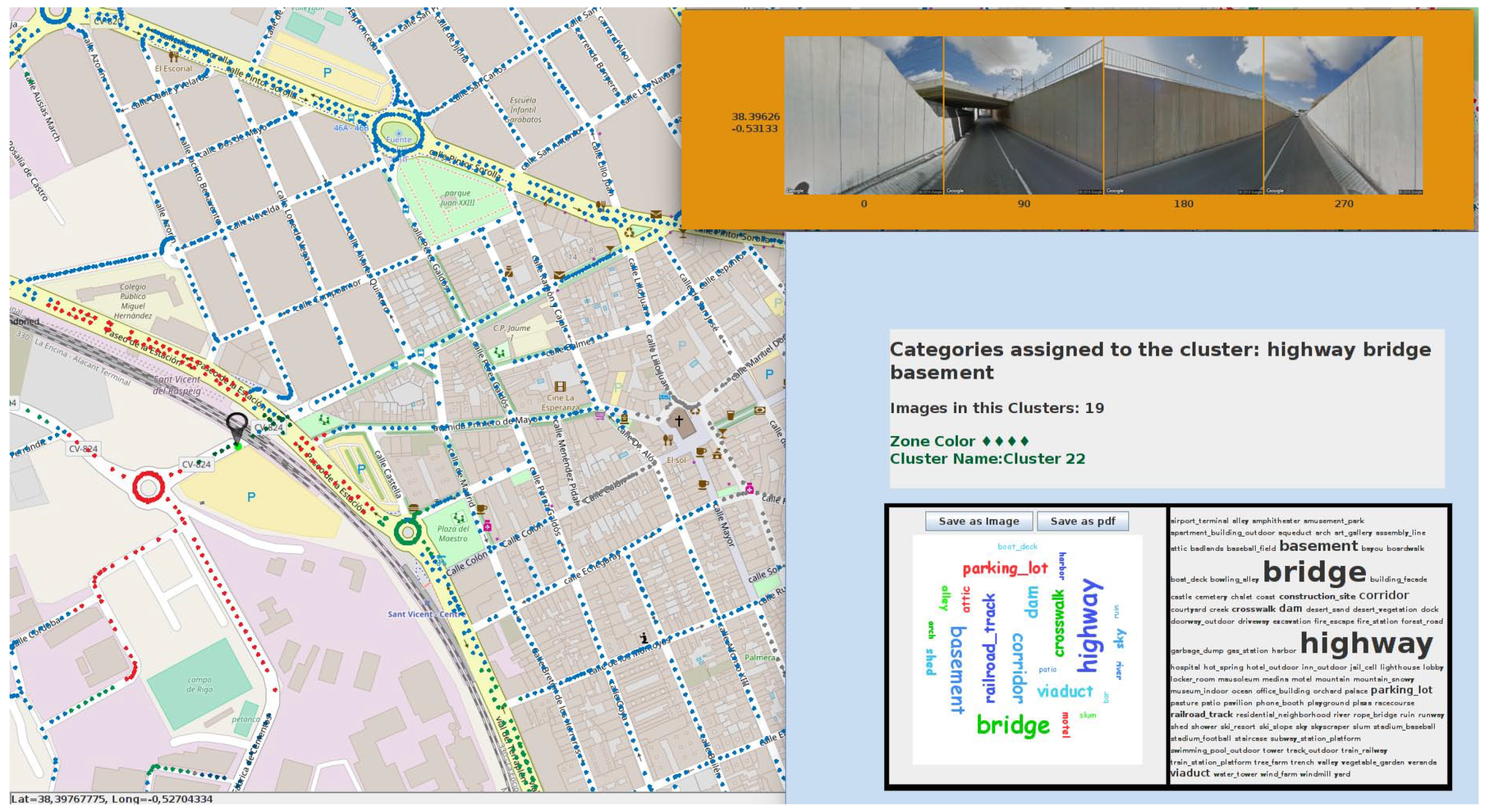
6.1. Semantic Map Results
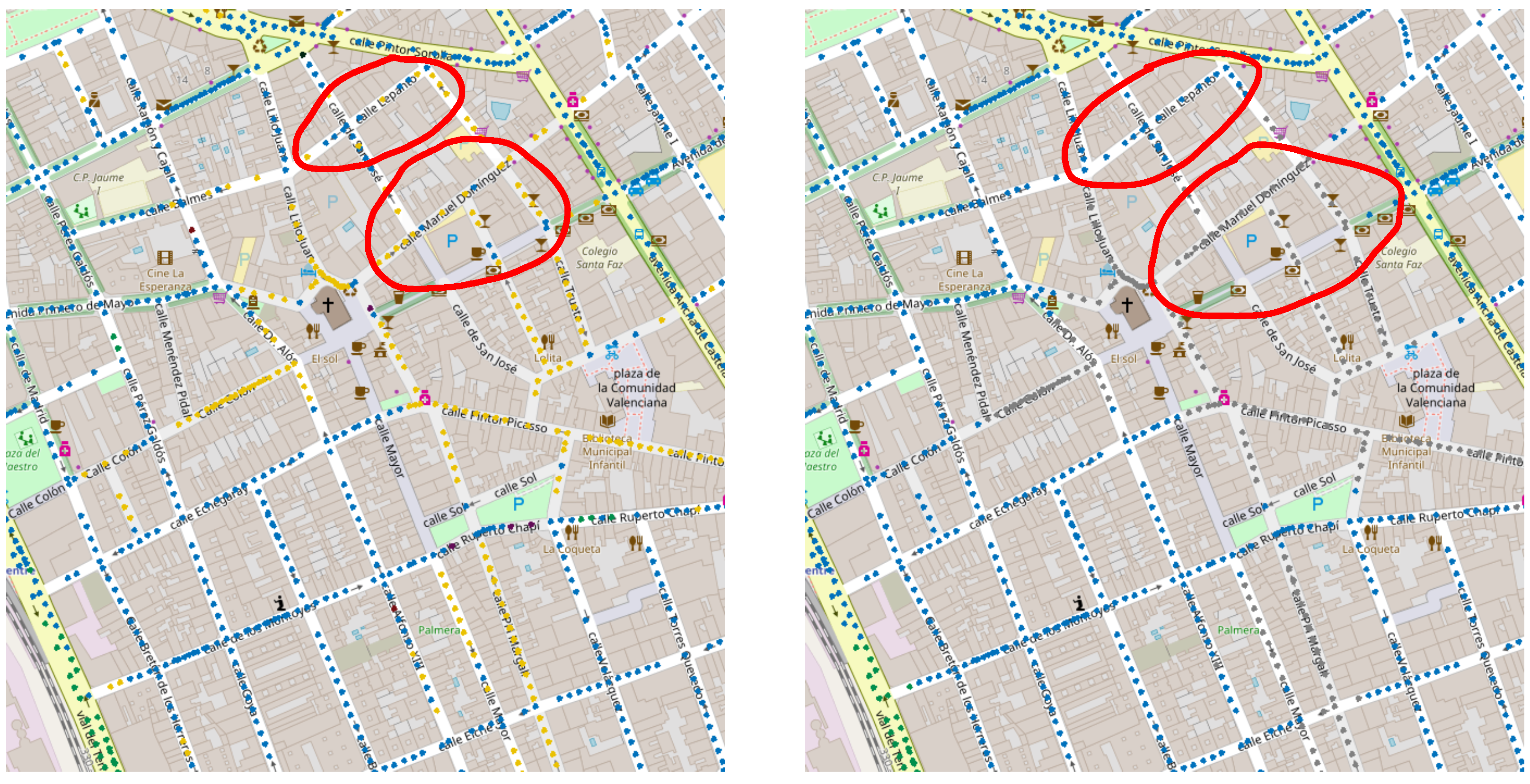
6.2. KNN Smoothing Procedure
6.3. KNN Smoothing Comparison
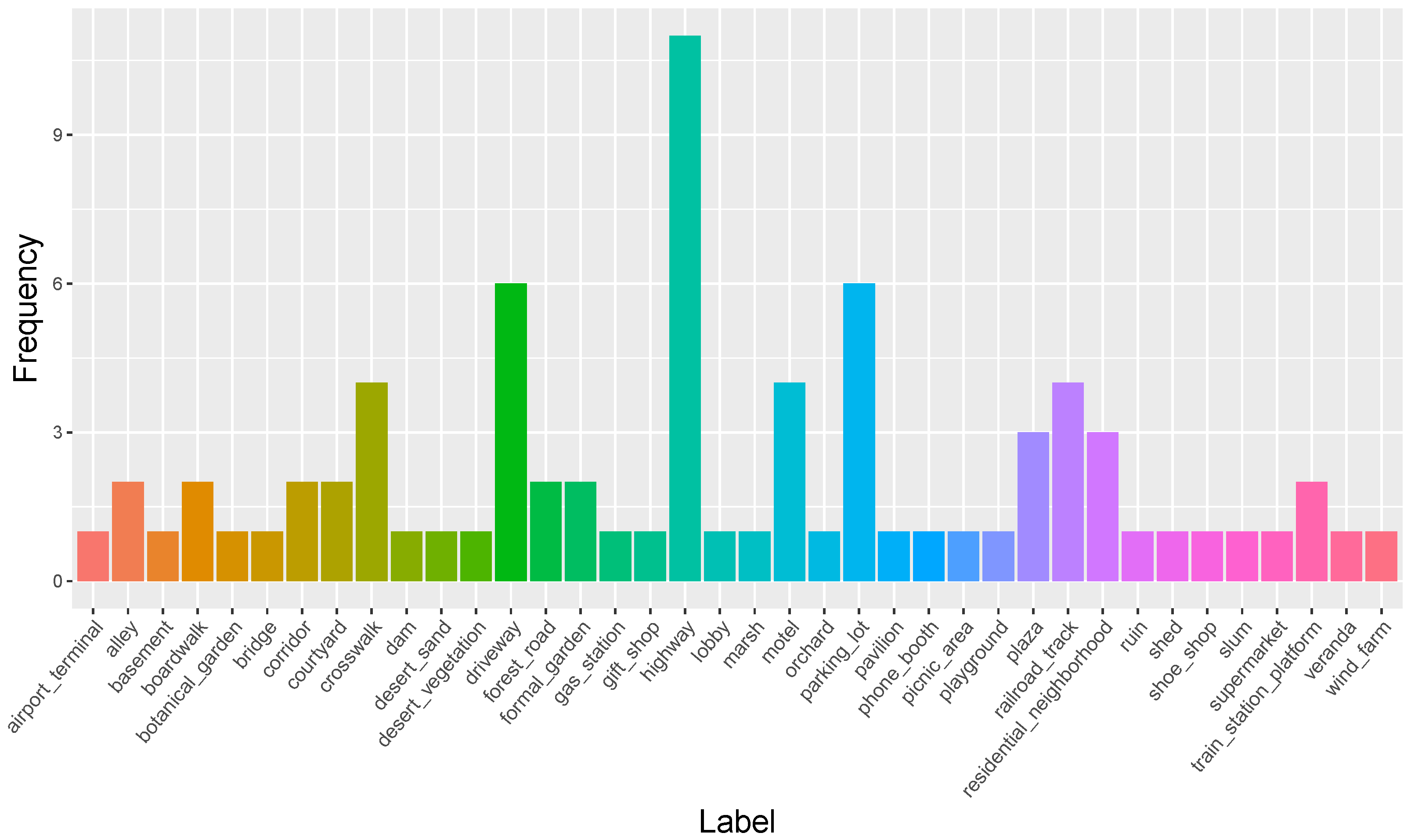
6.4. Ground Truth Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hara, K.; Sun, J.; Moore, R.; Jacobs, D.; Froehlich, J. Tohme: Detecting Curb Ramps in Google Street View Using Crowdsourcing, Computer Vision, and Machine Learning. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; ACM: New York, NY, USA, 2014; pp. 189–204. [Google Scholar] [CrossRef]
- Gebru, T.; Krause, J.; Wang, Y.; Chen, D.; Deng, J.; Aiden, E.L.; Fei-Fei, L. Using deep learning and Google Street View to estimate the demographic makeup of neighborhoods across the United States. Proc. Natl. Acad. Sci. USA 2017, 114, 13108–13113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruggieri, S.; Cardellicchio, A.; Leggieri, V.; Uva, G. Machine-learning based vulnerability analysis of existing buildings. Autom. Constr. 2021, 132, 103936. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Leggieri, V.; Uva, G. View VULMA: Data Set for Training a Machine-Learning Tool for a Fast Vulnerability Analysis of Existing Buildings. Data 2022, 7, 4. [Google Scholar] [CrossRef]
- Chen, C.; Lu, C.; Huang, Q.; Yang, Q.; Gunopulos, D.; Guibas, L. City-scale map creation and updating using GPS collections. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1465–1474. [Google Scholar]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic Segmentation of Aerial Images With Shuffling Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic Segmentation of Aerial Images with an Ensemble of CNSS. In ISPRS Congress; Halounova, L., Schindler, K., Limpouch, A., Šafář, V., Pajdla, T., Mayer, H., Elberink, S.O., Mallet, C., Rottensteiner, F., Skaloud, J., et al., Eds.; Copernicus Publications: Göttingen, Germany, 2016; Volume III-3, pp. 473–480. [Google Scholar]
- Luperto, M.; Amigoni, F. Predicting the global structure of indoor environments: A constructive machine learning approach. Auton. Robot. 2019, 43, 813–835. [Google Scholar] [CrossRef]
- Kaleci, B.; Parlaktuna, O.; Gürel, U. A comparative study for topological map construction methods from metric map. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. (In English). [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Nüchter, A.; Hertzberg, J. Towards semantic maps for mobile robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernandez-Madrigal, J.A.; Gonzalez, J. Multi-hierarchical semantic maps for mobile robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 2278–2283. [Google Scholar] [CrossRef]
- Maturana, D.; Chou, P.W.; Uenoyama, M.; Scherer, S. Real-Time Semantic Mapping for Autonomous Off-Road Navigation. In Field and Service Robotics; Hutter, M., Siegwart, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 335–350. [Google Scholar]
- Verma, R.; Ghosh, S.; Ganguly, N.; Mitra, B.; Chakraborty, S. Smart-Phone Based Spatio-Temporal Sensing for Annotated Transit Map Generation. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Aiello, L.M.; Schifanella, R.; Quercia, D.; Aletta, F. Chatty maps: Constructing sound maps of urban areas from social media data. R. Soc. Open Sci. 2016, 3, 150690. [Google Scholar] [CrossRef] [Green Version]
- Maturana, D.; Arora, S.; Scherer, S. Looking forward: A semantic mapping system for scouting with micro-aerial vehicles. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6691–6698. [Google Scholar] [CrossRef]
- Sousa, Y.C.N.; Bassani, H.F. Incremental Semantic Mapping with Unsupervised On-line Learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Luo, R.C.; Chiou, M. Hierarchical Semantic Mapping Using Convolutional Neural Networks for Intelligent Service Robotics. IEEE Access 2018, 6, 61287–61294. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar] [CrossRef] [Green Version]
- Bernuy, F.; Ruiz-del Solar, J. Topological Semantic Mapping and Localization in Urban Road Scenarios. J. Intell. Robot. Syst. 2018, 92, 19–32. [Google Scholar] [CrossRef]
- Xiang, Y.; Fox, D. DA-RNN: Semantic Mapping with Data Associated Recurrent Neural Networks. In Proceedings of the 2017 Robotics: Science and Systems XIII Conference, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar] [CrossRef]
- Grabler, F.; Agrawala, M.; Sumner, R.W.; Pauly, M. Automatic Generation of Tourist Maps. ACM Trans. Graph. 2008, 27, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Rangel, J.C.; Cazorla, M.; García-Varea, I.; Romero-González, C.; Martínez-Gómez, J. Automatic semantic maps generation from lexical annotations. Auton. Robot. 2019, 43, 697–712. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5079–5085. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, M.; Al-Fuqaha, A. Enabling Cognitive Smart Cities Using Big Data and Machine Learning: Approaches and Challenges. IEEE Commun. Mag. 2018, 56, 94–101. [Google Scholar] [CrossRef] [Green Version]
- Rangel, J.C.; Martínez-Gómez, J.; García-Varea, I.; Cazorla, M. LexToMap: Lexical-based topological mapping. Adv. Robot. 2017, 31, 268–281. [Google Scholar] [CrossRef] [Green Version]
- Cruz, E.; Bauer, Z.; Rangel, J.C.; Cazorla, M.; Gomez-Donoso, F. Semantic Localization of a Robot in a Real Home. In Workshop of Physical Agents; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–15. [Google Scholar]
- Cruz, E.; Rangel, J.C.; Gomez-Donoso, F.; Cazorla, M. How to add new knowledge to already trained deep learning models applied to semantic localization. Appl. Intell. 2020, 50, 14–28. [Google Scholar] [CrossRef]
- Rangel, J.; Cazorla, M.; García-Varea, I.; Martínez-Gómez, J.; Fromont, E.; Sebban, M. Scene classification based on semantic labeling. Adv. Robot. 2016, 30, 758–769. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, X.; Zhang, C.; Li, W. Building block level urban land-use information retrieval based on Google Street View images. GISci. Remote Sens. 2017, 54, 819–835. [Google Scholar] [CrossRef]
- Zhou, W.; Berrio, J.S.; Worrall, S.; Nebot, E. Automated Evaluation of Semantic Segmentation Robustness for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1951–1963. [Google Scholar] [CrossRef]
- Lee, Y.C.; Christiand; Park, S.H.; Yu, W.; Kim, S.H. Topological map building for mobile robots based on GIS in urban environments. In Proceedings of the 2011 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Incheon, Korea, 23–26 November 2011; pp. 790–791. [Google Scholar] [CrossRef]
- Kubota, N. Topological approaches for simultaneous localization and mapping. In Proceedings of the 2017 6th International Conference on Informatics, Electronics and Vision 2017 7th International Symposium in Computational Medical and Health Technology (ICIEV-ISCMHT), Himeji, Japan, 1–3 September 2017; p. 1. [Google Scholar] [CrossRef]
- Ravankar, A.A.; Ravankar, A.; Emaru, T.; Kobayashi, Y. A hybrid topological mapping and navigation method for large area robot mapping. In Proceedings of the 2017 56th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Kanazawa, Japan, 19–22 September 2017; pp. 1104–1107. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic maps from multiple visual cues. Expert Syst. Appl. 2017, 68, 45–57. [Google Scholar] [CrossRef]
- Walter, M.; Hemachandra, S.; Homberg, B.; Tellex, S.; Teller, S. Learning Semantic Maps from Natural Language Descriptions. In Proceedings of the 2013 Robotics: Science and Systems IX Conference, Berlin, Germany, 24–28 June 2013. [Google Scholar] [CrossRef]
- Crespo, J.; Castillo, J.C.; Mozos, O.M.; Barber, R. Semantic Information for Robot Navigation: A Survey. Appl. Sci. 2020, 10, 497. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Li, R.; Hu, H.; Gu, D. Extracting Semantic Information from Visual Data: A Survey. Robotics 2016, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5729–5736. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Gupta, J.; Li, Y.; Shekhar, S. Transforming Smart Cities with Spatial Computing. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MO, USA, 16–19 September 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Vasudavan, H.; Mostafa, S.A.; Gunasekaran, S.S.; Dhillon, J.S.; Chua, K.H. The Contextual Mapping of Smart City Characteristics with their Dimensions through Content Analysis Method. In Proceedings of the 2019 7th International Conference on Smart Computing Communications (ICSCC), Miri, Sarawak, 28–30 June 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Martínez-Gómez, J.; Morell, V.; Cazorla, M.; García-Varea, I. Semantic localization in the PCL library. Robot. Auton. Syst. 2016, 75, 641–648. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Liu, T.; Chen, H. Semantic manifold learning for image retrieval. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; ACM: New York, NY, USA, 2005; pp. 249–258. [Google Scholar]
- Premebida, C.; Ambrus, R.; Marton, Z.C. Intelligent Robotic Perception Systems. In Applications of Mobile Robots; Hurtado, E.G., Ed.; IntechOpen: Rijeka, Croatia, 2019; Chapter 6. [Google Scholar] [CrossRef] [Green Version]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Meshgi, K.; Ishii, S. Expanding histogram of colors with gridding to improve tracking accuracy. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 475–479. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 487–495. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linkage Strategies | Distance Metrics |
|---|---|
| Average | Bray-Curtis |
| Centroid | Chebyshev |
| Complete | Correlation |
| Median | SqEuclidean |
| Single | |
| Ward | |
| Weighted |
 |  |  |  |
|---|---|---|---|
 |  |  |  |
| Alley | Highway | Plaza | Residential |
| Latitude = Longitude = | |||
 |  |  |  |
| Latitude = Longitude = | |||
 |  |  |  |
| Latitude = Longitude = | |||
 |  |  |  |
| University | Industrial Region | ||
 |  |  |  |
| Urban Region | Highways | ||
 |  |  |  |
| Residential Areas | Old Town, Pedestrian Zone | ||
 |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rangel, J.C.; Cruz, E.; Cazorla, M. Automatic Understanding and Mapping of Regions in Cities Using Google Street View Images. Appl. Sci. 2022, 12, 2971. https://doi.org/10.3390/app12062971
Rangel JC, Cruz E, Cazorla M. Automatic Understanding and Mapping of Regions in Cities Using Google Street View Images. Applied Sciences. 2022; 12(6):2971. https://doi.org/10.3390/app12062971
Chicago/Turabian StyleRangel, José Carlos, Edmanuel Cruz, and Miguel Cazorla. 2022. "Automatic Understanding and Mapping of Regions in Cities Using Google Street View Images" Applied Sciences 12, no. 6: 2971. https://doi.org/10.3390/app12062971
APA StyleRangel, J. C., Cruz, E., & Cazorla, M. (2022). Automatic Understanding and Mapping of Regions in Cities Using Google Street View Images. Applied Sciences, 12(6), 2971. https://doi.org/10.3390/app12062971