1. Introduction
Autonomous underwater vehicles (AUVs) are deployed in the ocean to carry out specific missions, such as ocean observations, target identification, etc., due to their excellent advantages in maneuverability. In order to complete the mission, the AUV is often required to move to a target location under some constraints, such as the shortest time, shortest distance, and least energy consumption. Avoiding risks or obstacles in the ocean is also required. Aiming at different constraints, relevant path planning algorithms are developed. In this paper, the time-optimal is prioritized.
The path planning algorithms for mobile robots can be divided into two categories: discrete-grid-based and sampling-based planning algorithms [
1]. The former one is established on a gridded map. For example, the A* algorithm is transformed from the Dijkstra algorithm by adding a heuristic cost to enhance the computational efficiency. The A* algorithm can be modified, aiming at speeding the convergence of the A* algorithm, such as with iterative deepening A*, lifelong planning A*, and bidirectional A* algorithms [
2,
3]. Liu et al. [
4] introduced an improved A* algorithm for generating the procedure of the normal path and berthing path when considering obstacles with currents and marine traffic. The sampling-based planning algorithm does not directly calculate global optimization on a gridded map. It uses the random scattering of particles on the map to extract map-assisted planning. The probabilistic roadmap [
5] and rapidly-exploring random tree algorithms [
6] are two typical examples. Recently, some clustering algorithms are also applied to path planning, for instance, the ant colony algorithm, genetic algorithm, etc. [
7]. The level-set method is also an important branch of robotic path planning [
8].
With the rapid development of artificial intelligence, reinforcement learning is applied to robotic path planning. Julien et al. [
9] presented an MDP-based planning method for a robot with wheels. In order to resolve the impact of their surrounding environment, Lou et al. [
10] modeled the robotic motion as a Markov process and proposed a probabilistic-model-checking method to seek the optimal path. Singh [
11] applied the object-oriented Markov decision process for indoor robots, which greatly simplifies the problem of the so-called “curse of dimensionality”. It reduces the state spaces by making the MDP properties as objects. Pereira et al. [
12] used a minimum expected risk planner and a risk-aware Markov decision process to improve the reliability and safety of AUV operation in coastal regions.
Different from the land or air based robots, the AUVs have their special characters due to the underwater environment.
- (1)
Low positioning accuracy and high positioning cost
Land robots can directly acquire real-time positions through the global positioning system (GPS) with relatively high positioning accuracy (about 0.5 m [
13]). Because of the absorption of electromagnetic waves by seawater, satellite signals cannot be directly received underwater by AUVs. Alternatively, the inertial navigation system (INS) is commonly used for underwater positioning. However, it is expensive while providing low positioning accuracy, which produces about 100 m errors after traveling by 1 km [
14]. Its positioning error accumulates over time, which must be frequently calibrated for long-term underwater deployment.
- (2)
Low cruising speed and high fault tolerance
Compared with land or air based robots, the maximum speed of underwater robots is much slower, which ranges from about 3 to 10 knots [
15]. Except in the harbors, marine traffic is limited. The marine morphology, such as the coastline, islands, and seamounts, is relatively fixed. Therefore, more tolerance is allowed for AUVs to tip or roll over in the ocean.
- (3)
High impacts by the marine environment
In the ocean, the current velocity, and the speed of AUVs are usually in the same order of magnitude. If the ocean current is neglected, it will lead to an obvious deviation between the planned and practical paths. In contrast, if a real-time robust control is applied to eliminate these deviations, it will cost extra power and computational resources.
Several works have been done to solve the AUV path planning problem. Garau et al. [
16] used the A* searching procedure to determine the optimal path with consideration to the ocean currents and their spatial variabilities. Zeng et al. [
17] introduced a quantum-behaved particle swarm optimization algorithm for solving the optimal path planning problem of an AUV operating in environments with ocean static currents. Witt et al. [
18] described a novel optimum path planning strategy for long-duration operations in environments with time-varying ocean currents. Kularatne et al. [
19] presented a graph-search-based method to compute energy-optimal paths for AUVs in two-dimensional (2-D) time-varying flows. Subramani et al. [
20] integrated data-driven ocean modeling with the stochastic dynamically orthogonal level-set optimization methodology to compute and study energy-optimal paths. Lolla et al. [
21] predicted the time-optimal paths of autonomous vehicles navigating in any continuous, strong, and dynamic ocean currents through solving an accurate partial differential equation. Rhoads et al. [
22] presented a numerical method for minimum time heading control for the underwater vehicle moving at a fixed speed in known time-varying and two-dimensional flow fields.
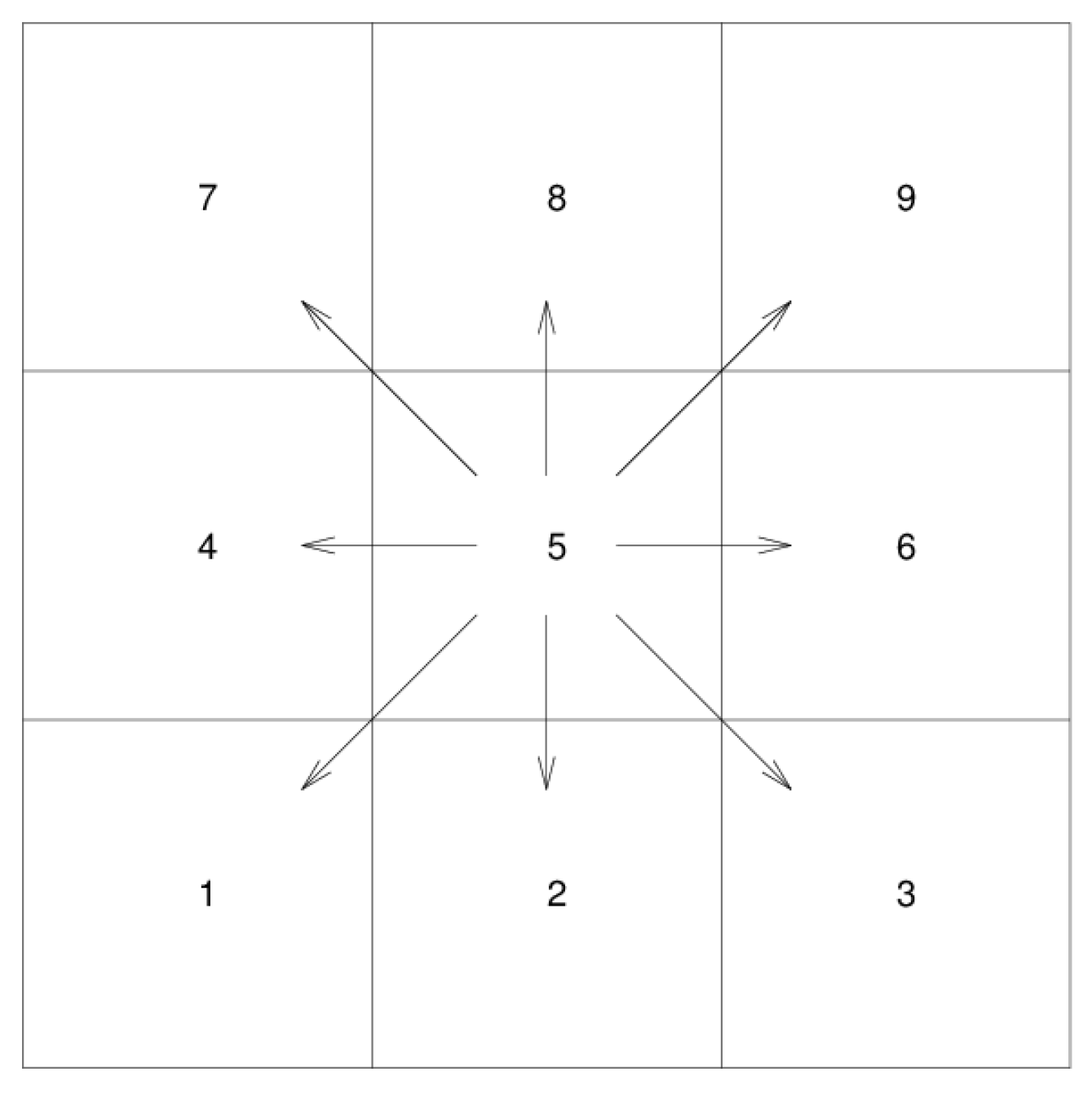
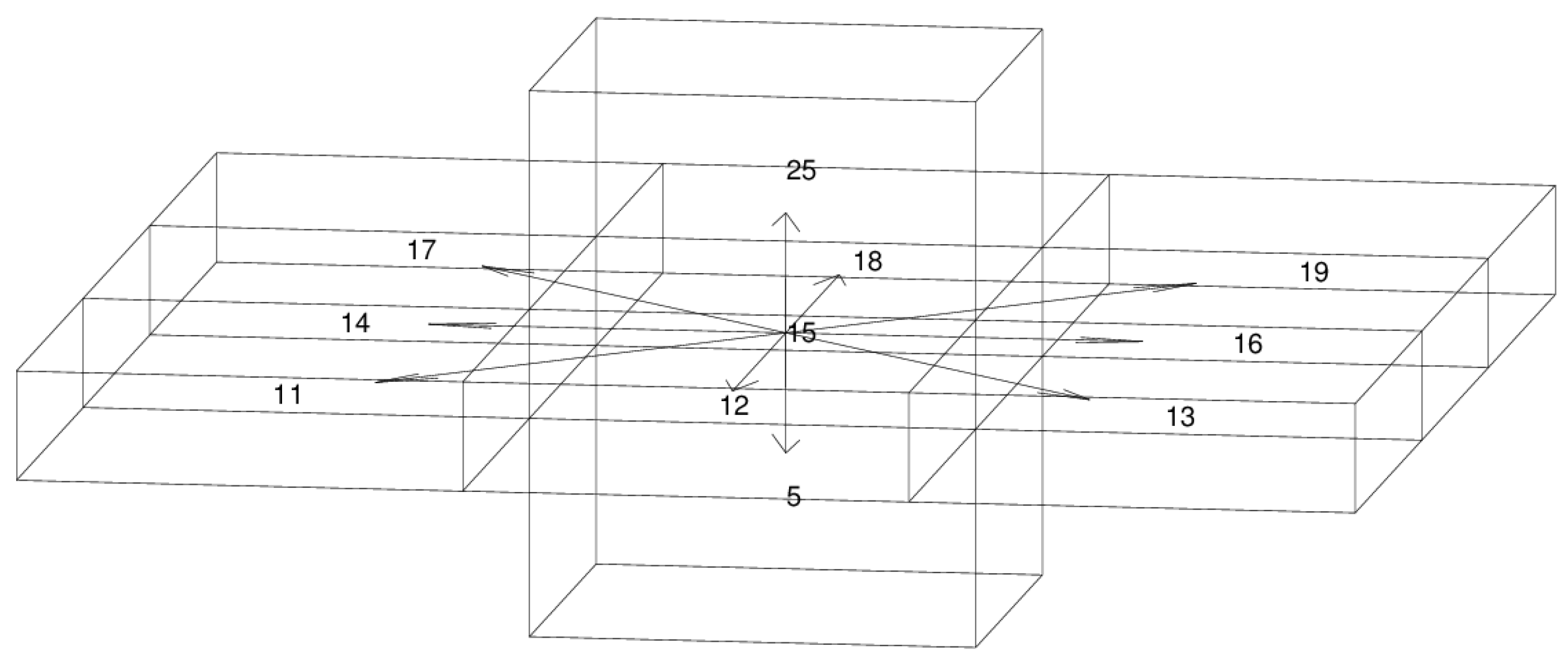
The MDP method is suitable for the AUV underwater path planning. The MDP seeks a globally optimal solution through a value iterative method. The optimal paths of all state points in the whole domain to the target are computed only once. This is more efficient than the traditional A* algorithm [
23,
24], which has to repeat similar computations for every step. Because AUVs move underwater with a low cruising speed and a high fault tolerance, the actions of AUVs are limited, and thus, suitable for establishing the MDP model. Otherwise, computational difficulties will increase exponentially with increasing robotic actions. In our application, the ocean current is predicted from an oceanic forecast model, therefore the ocean currents can be regarded as fully observable. This information is provided to the AUV as a priori or in real-time through acoustic communications so that the parameters used in the MDP model can be updated. The fully observable MDP model has a faster convergence rate than the partially observable MDP models.
The paper is organized as follows. The principle of the MDP path planning and its numerical algorithm for applications in the AUV navigation are introduced in
Section 2. In
Section 3, the efficiency of the MDP algorithm is examined and its performance is compared with the traditional A* algorithm. Then, the ocean currents predicted by a regional ocean model are incorporated into the MDP model to evaluate the performance of the MDP algorithm in a ‘real’ oceanic environment. The conclusions are presented in
Section 4.
4. Conclusions
In summary, we proposed a path planning method for AUV navigations based on the MDP algorithm. Using Daya Bay as a trial area, the algorithm’s performance is examined. The grid size of 2000 m turns out to be a computation-efficient and feature-resolved resolution suitable for Daya Bay. In this study, the ocean current is predicted using a regional ocean model (FVCOM) and is inputted into the MDP algorithm as a priori. Since ocean currents always vary with time and their magnitude is in the same order as the AUV’s cruising speed, including the ocean currents in the MDP algorithm, they can apparently change the predicted optimal path and arrival time, especially for the cases in that the AUV must make several detours to avoid obstacles, such as islands or coastline.
The MDP algorithm is validated through comparison with the A* algorithms, demonstrating its advantages in underwater navigation. The optimal paths obtained by the MDP algorithm are shorter than the A* algorithm with the same spatial resolution. It is especially suitable for the underwater navigation of AUVs, which have a slow speed and limited basic actions. The MDP method also avoids high complexity in the algorithm design. Information on ocean currents can be easily included in the algorithm so that it is more adaptive for the real operational environment in the ocean. The MDP algorithm with consideration of ocean currents can guarantee that the grids with extra-large counter-currents will not appear in the predicted optimal path. Using the value iteration method, the optimal paths to the target from all points in the navigation area can be updated in one step, which makes the algorithm robust and convenient to be used in the ocean, where varying oceanic currents and other uncertainties exist.
This method is especially suitable for underwater navigation in ocean observations. Collaboration and networking of autonomous vehicles, such as AUVs, gliders, etc., is becoming a trend in ocean explorations. To quickly move and arrive at the target locations requires robust and efficient path searching under the limit of the maximum speed for underwater or surface vehicles. Background circulation, eddies, and tides, which may have comparable velocities as the vehicles, can dramatically affect the optimal path. The MDP method proposed in this paper, with an input of predicted ocean currents, provides a feasible solution for finding the optimal path. The operation of the ocean forecast model can be deployed on computers on land or embedded inside the vehicles. In turn, measured ocean currents during the time of the underwater vehicle traveling can be transmitted back to the forecast model to update the ocean current prediction using some optimized methods, such as data assimilation, thus producing more accurate background ocean currents to feed back to the MDP method and guide the optimal path of underwater vehicles.
The performance of the MDP algorithm is numerically verified. Field experiments in Daya Bay will be conducted to verify the algorithm in the near future. The computing time increases dramatically when the grids increase. Even though some more efficient methods are available for a large grid number [
31], the computing efficiency and spatial resolution must be balanced for the AUV to acquire an optimal path in practical applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}