
Global Flood Disaster Research Graph Analysis Based on Literature Mining


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Research Methods and Data Processing
3. Results
3.1. Thematic Classification of Flood Disaster Literature
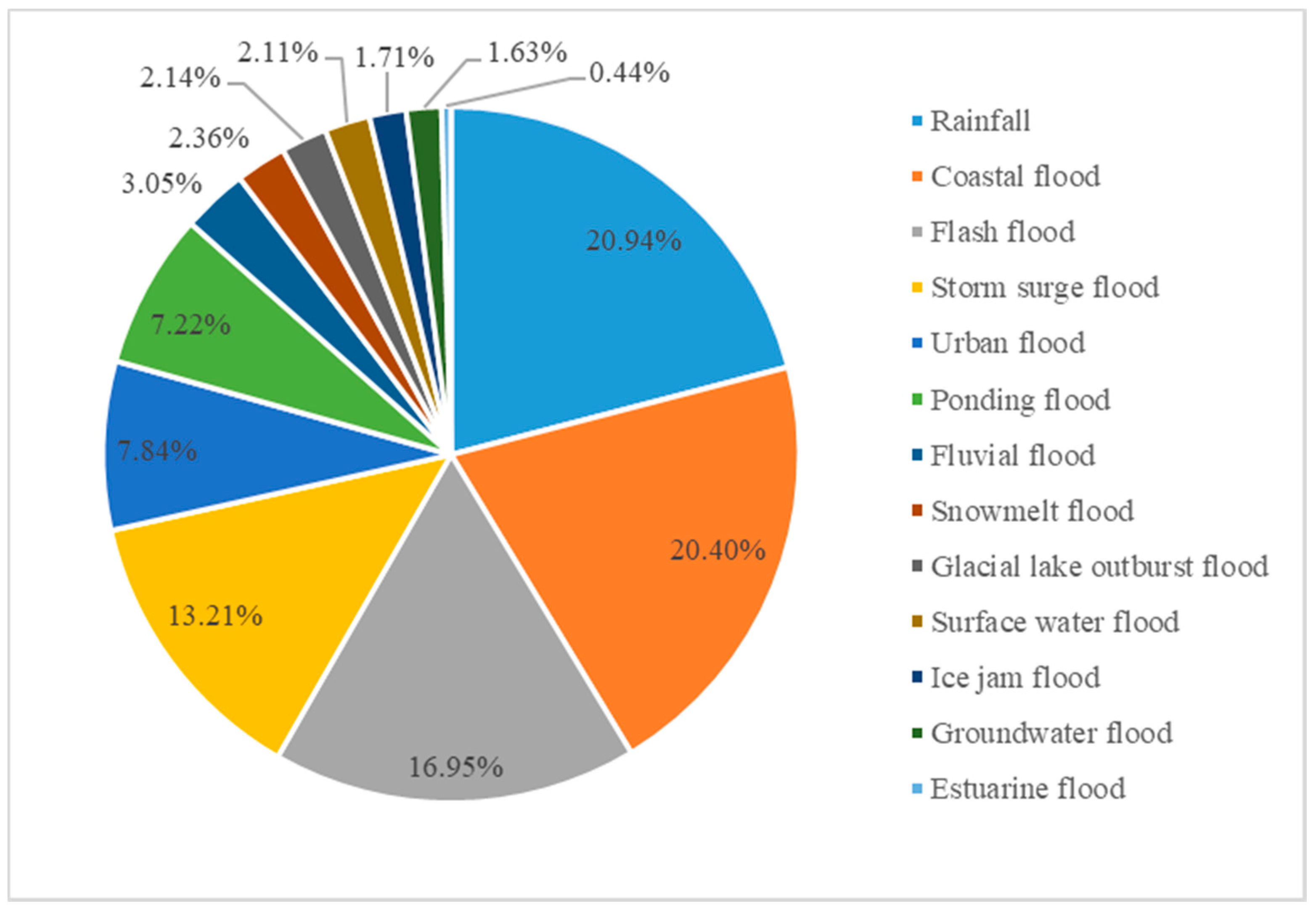
3.2. Analysis of Flood Disaster Subcategories
3.3. Identification of Hot Flood Disaster Research Areas
3.4. Analysis of Flood Disaster Research Institutions
3.5. Construction of Flood Disaster Knowledge Graph
4. Discussion
4.1. Research Hotspots of Flood Disasters
4.2. Hot Areas of Flood Disaster Research
4.3. Flood Disaster Knowledge Graph
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- United Nations Office for Disaster Risk Reduction International Science Council. UNDRR-ISC Hazard Definition and Classification Review—Technical Report. 2020. Available online: https://www.preventionweb.net/publication/hazard-definition-and-classification-review (accessed on 1 March 2022).
- Maziar, Y.; Mohammad, M.; Martin, L.; David, S. A modelling framework to design an evacuation support system for healthcare infrastructures in response to major flood events. Prog. Disaster Sci. 2022, 13, 100218. [Google Scholar] [CrossRef]
- UNDRR. Human Cost of Disaster 2000–2019. 12 October 2020. Available online: https://www.undrr.org/publication/human-cost-disasters-2000-2019 (accessed on 26 August 2021).
- Ministry of Emergency Management of the People’s Republic of China. “2019 Global Natural Disaster Assessment Report” Released Last Year’s Global Natural Disasters Were Generally Lighter, and Chinese Disaster Losses Were among the Highest in the World. 8 May 2020. Available online: https://www.mem.gov.cn/xw/bndt/202005/t20200508_352281.shtml (accessed on 26 August 2021).
- Academy of Disaster Reduction and Emergency Management Ministry of Emergency Management & Ministry of Education. “Global Disaster Data Platform (Chinese Version)” on May 12 Line, the “2020 Global Natural Disaster Assessment Report (Abstract in Chinese)” Was Released Simultaneously. 12 May 2021. Available online: http://adrem.bnu.edu.cn/xwkx/231044.html (accessed on 26 August 2021).
- Wang, L.; Gong, Z.; Shi, L.; Hu, Z.; Shah, A.A. Knowledge mapping analysis of research progress and frontiers in integrated disaster risk management in a changing climate. Nat. Hazards 2021, 107, 2033–2052. [Google Scholar] [CrossRef]
- Shen, S.; Cheng, C.; Yang, J.; Yang, S. Visualized analysis of developing trends and hot topics in natural disaster research. PLoS ONE 2018, 13, e0191250. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zheng, S.; Cao, Y. Research review on the analysis of mountain torrents disaster situation based on the statistics of keywords. J. China Inst. Water Resour. Hydropower Res. 2017, 15, 29–36. [Google Scholar]
- Cheng, X.; Dai, M. Bibliometric analysis of the team and development of the research on the flood disaster risk situation. J. Anhui Norm. Univ. (Nat. Sci.) 2017, 40, 275–281. [Google Scholar]
- Han, H.; Jiang, R.; Xie, J.; Xiang, Y.; Wang, Y. Research progress of urban water-logging in China based on bibliometrics. J. Water Resour. Water Eng. 2017, 28, 134–138. [Google Scholar]
- Tan, L.; Yao, W.; Li, L. Direct economic loss assessment of urban storm flood disasters based on bibliometric analysis. J. Catastrophol. 2020, 35, 179–185. [Google Scholar]
- Zeng, J.; Wang, Q.; Guo, H. Knowledge map analysis and progress review of international research on flood disaster risk. J. Catastrophol. 2020, 35, 127–135. [Google Scholar]
- Cheng, Q.; Zhu, Y.; Song, J.; Zeng, H.; Wang, S.; Sun, K.; Zhang, J. Bert-Based Latent Semantic Analysis (Bert-LSA): A Case Study on Geospatial Data Technology and Application Trend Analysis. Appl. Sci. 2021, 11, 11897. [Google Scholar] [CrossRef]
- Du, Z.; Li, Y.; Zhang, Y. Knowledge graph construction method on natural disaster emergency. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1344–1355. [Google Scholar]
- Song, K.; Kim, D.-H.; Shin, S.-J.; Moon, I.-C. Identifying the evolution of disasters and responses with network-text analysis. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, F.; Zheng, X. Complex network construction method to extract the nature disaster chain based on data mining. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017. [Google Scholar]
- Abburu, S.; Golla, S.B. Ontology and NLP support for building disaster knowledge base. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2018. [Google Scholar]
- Li, Z.; Xu, S.; Li, B.; Li, J.; Management, S.O. Information fusion technology of disaster scenario based on knowledge graph. J. North China Inst. Sci. Technol. 2019, 16, 1–5. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Purohit, H.; Kanagasabai, R.; Deshpande, N. Towards Next Generation Knowledge Graphs for Disaster Management. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019. [Google Scholar]
- Zhu, Q.; Zeng, H.; Ding, Y. A review of major potential landslide hazards analysis. Acta Geod. Cartogr. Sin. 2016, 51, 396–403. [Google Scholar]
- Tao, K.; Zhao, Y.; Zhu, P. Knowledge graph construction for integrated disaster reduction. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1296–1302. [Google Scholar]
- Li, W.; Zhu, J.; Zhang, Y.; Fu, L.; Cao, Y. An on-demand construction method of disaster scenes for multilevel users. Nat. Hazards J. Int. Soc. Prev. Mitig. Nat. Hazards 2020, 101, 409–428. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, J.; Zhu, Q.; Xie, Y.; Li, W.; Fu, L.; Zhang, J.; Tan, J. The construction of personalized virtual landslide disaster environments based on knowledge graphs and deep neural networks. Int. J. Digit. Earth 2020, 13, 1637–1655. [Google Scholar] [CrossRef]
- Google. The GDELT Project. 11 November 2020. Available online: https://www.gdeltproject.org (accessed on 3 September 2021).
- Rudnik, C.; Ehrhart, T.; Ferret, O. Searching News Articles Using an Event Knowledge Graph Leveraged by Wikidata. In Proceedings of the Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Wang, J.; Bu, K.; Yang, F.; Yuan, Y.; Wei, H. Disaster risk reduction knowledge service: A paradigm shift from disaster data towards knowledge services. Pure Appl. Geo-Phys. 2019, 177, 135–148. [Google Scholar] [CrossRef]
- Wang, J.; Han, X.; Bu, K.; Zhang, M.; Wang, X.; Yuan, Y. Knowledge service system on disaster risk reduction and its application in social media analysis. J. Glob. Chang. Data Discov. 2020, 4, 25–32. [Google Scholar] [CrossRef]
- Margesson, R.; Taftmorales, M. Haiti Earthquake: Crisis and Response. Library of Congress. Congressional Research Service. 2010. Available online: https://digital.library.unt.edu/ark:/67531/metadc501690/m1/1/high_res_d/R41023_2010May06.pdf (accessed on 1 March 2022).
- Hough, S.E.; Altidor, J.R.; Anglade, D. 7.0 Haiti earthquake. Nat. Geosci. 2010, 3, 778–782. [Google Scholar] [CrossRef]
- YNET. Haiti Earthquake Death Toll Rises to 2207, Nearly 600,000 People are Directly Affected. 23 August 2021. Available online: https://t.ynet.cn/baijia/31314429.html (accessed on 23 November 2021).
- Ecns. Extremely Strong Cyclone “Ampan” Is Approaching the Coastal Areas of the Bay of Bengal, India and Bangladesh Plan to Arrange the Evacuation of 3 Million People. 20 May 2020. Available online: https://baijiahao.baidu.com/s?id=1667145514410868535&wfr=spider&for=pc (accessed on 23 November 2021).
- Sina. Extremely Strong Cyclone “Ampan” Has Killed 102 People and Is Expected to Cost India US$13 Billion. 23 May 2020. Available online: https://tech.sina.com.cn/roll/2020-05-23/doc-iirczymk3188609.shtml (accessed on 23 November 2021).
- Xinhua News Agency. Kenya’s Drought Continues, 2.1 Million People Face Famine. 23 November 2021. Available online: http://www.news.cn/world/2021-10/27/c_1128000644.htm (accessed on 23 November 2021).
- Qiu, L. A Smart Aggregation Method of Spatial-Temopral Data for Natural Disaster Emergency Tasks. Ph.D. Thesis, Wuhan University, Wuhan, China, 2017. [Google Scholar]
- Sowa, J.F. Principles of Semantic Network: Exploration in the Representation of Knowledge; Morgan Kaufmann: San Mateo, CA, USA, 1991; pp. 135–137. [Google Scholar]
- Qi, G.; Gao, H.; Wu, T. The research advances of knowledge graph. Technol. Intell. Eng. 2017, 3, 4–25. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theme | Quantity | Proportion |
|---|---|---|
| Flood frequency | 542 | 3.85% |
| Influence analysis | 298 | 2.12% |
| Disaster management | 464 | 3.30% |
| Simulation and warning | 799 | 5.68% |
| Flood risk | 1080 | 7.67% |
| Disaster monitoring | 444 | 3.15% |
| Flood related research | 1554 | 11.04% |
| Other related research under the flood background | 6711 | 47.68% |
| Irrelevant research | 2184 | 15.52% |
| Total | 14,076 | 100.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Wang, J. Global Flood Disaster Research Graph Analysis Based on Literature Mining. Appl. Sci. 2022, 12, 3066. https://doi.org/10.3390/app12063066
Zhang M, Wang J. Global Flood Disaster Research Graph Analysis Based on Literature Mining. Applied Sciences. 2022; 12(6):3066. https://doi.org/10.3390/app12063066
Chicago/Turabian StyleZhang, Min, and Juanle Wang. 2022. "Global Flood Disaster Research Graph Analysis Based on Literature Mining" Applied Sciences 12, no. 6: 3066. https://doi.org/10.3390/app12063066
APA StyleZhang, M., & Wang, J. (2022). Global Flood Disaster Research Graph Analysis Based on Literature Mining. Applied Sciences, 12(6), 3066. https://doi.org/10.3390/app12063066