
Discrete HMM for Visualizing Domiciliary Human Activity Perception and Comprehension


Abstract
:1. Introduction
2. Human Activity Comprehension Framework
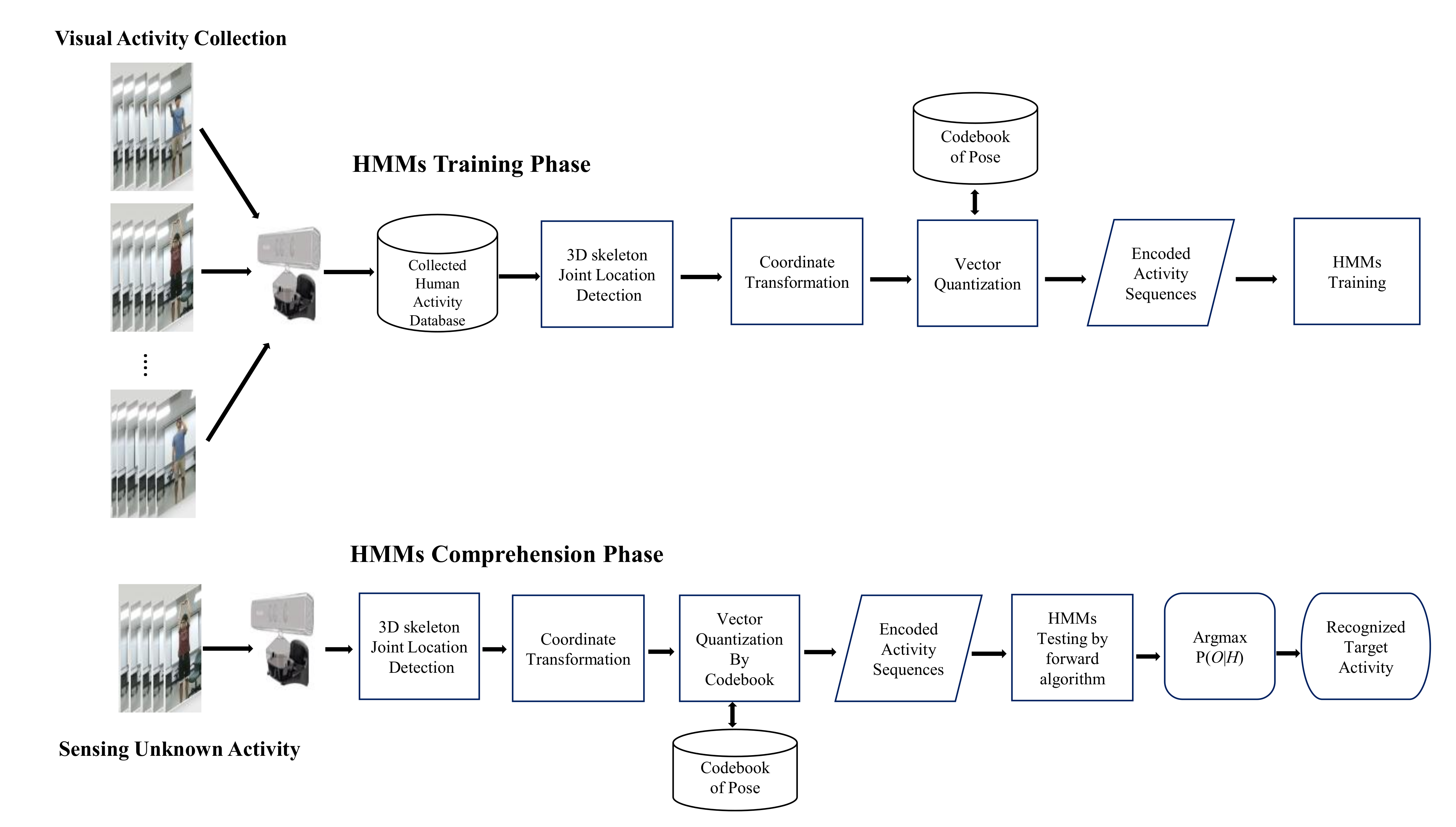
2.1. Overview
2.2. Human Activity Comprehension Module
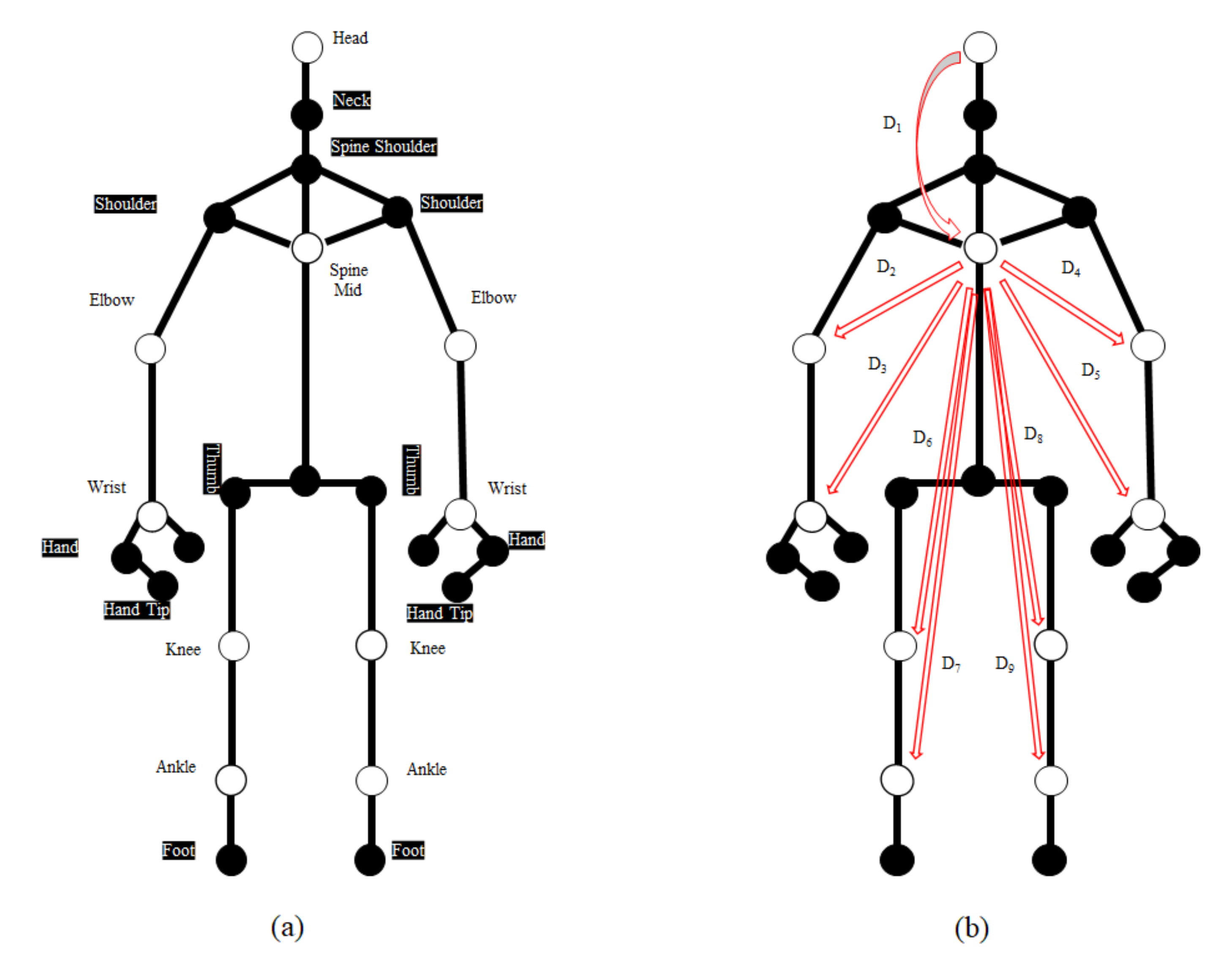
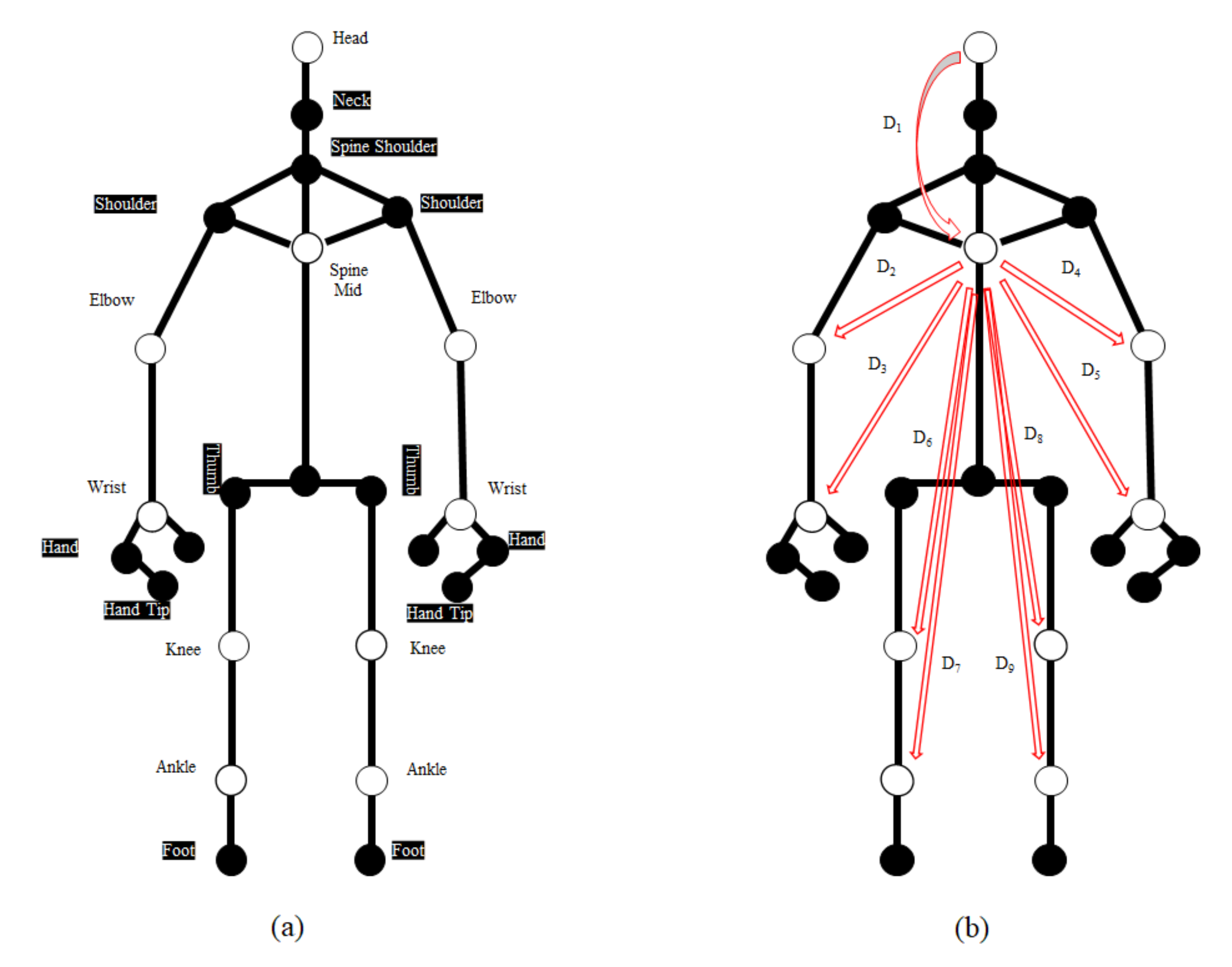
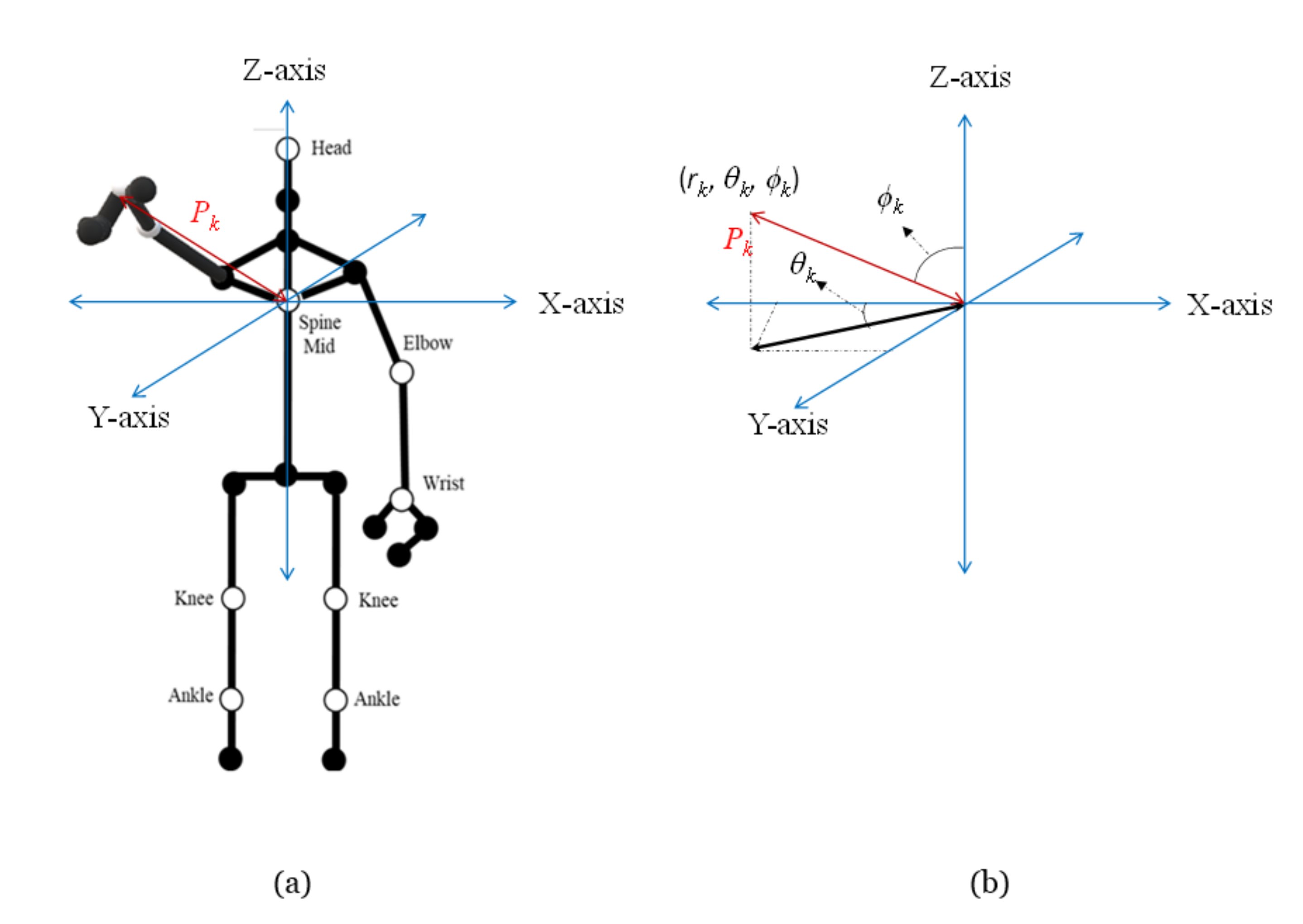
2.3. Feature Extraction
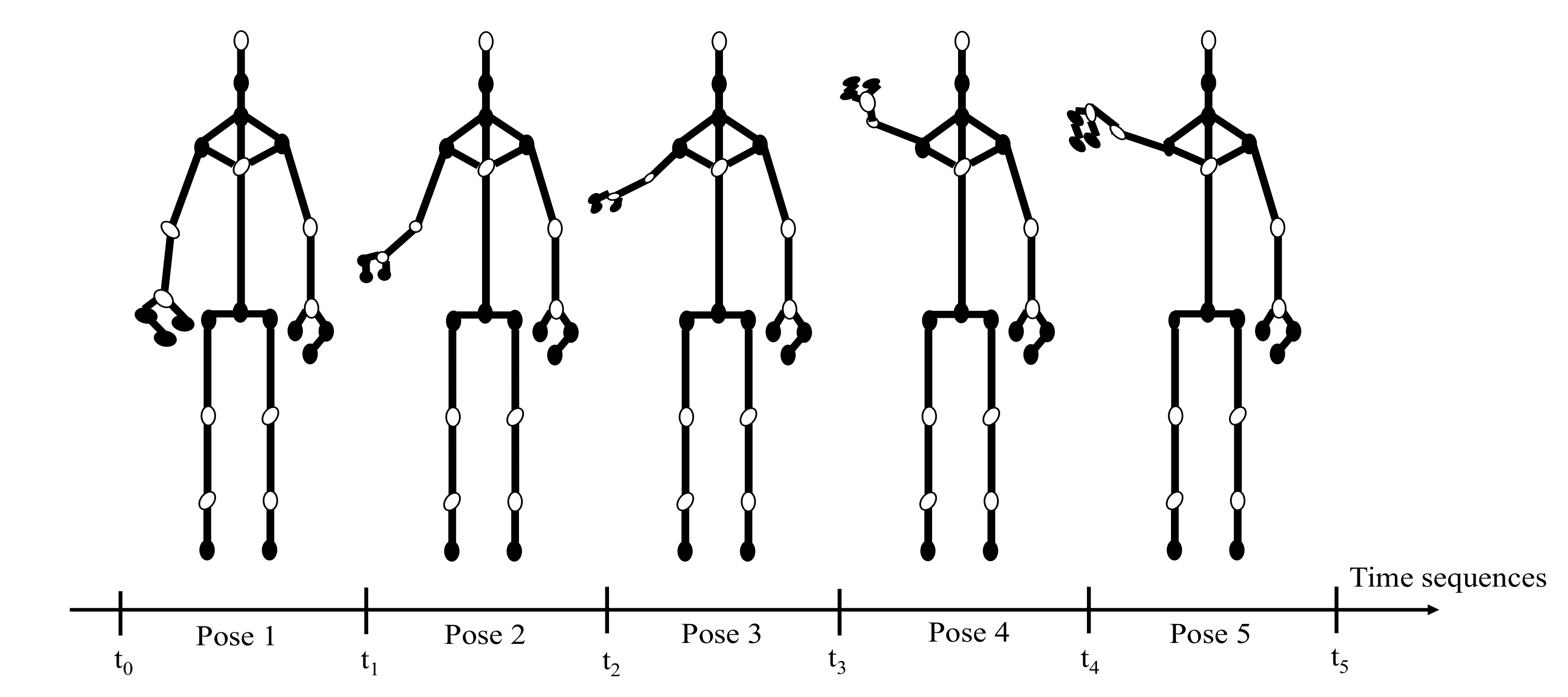
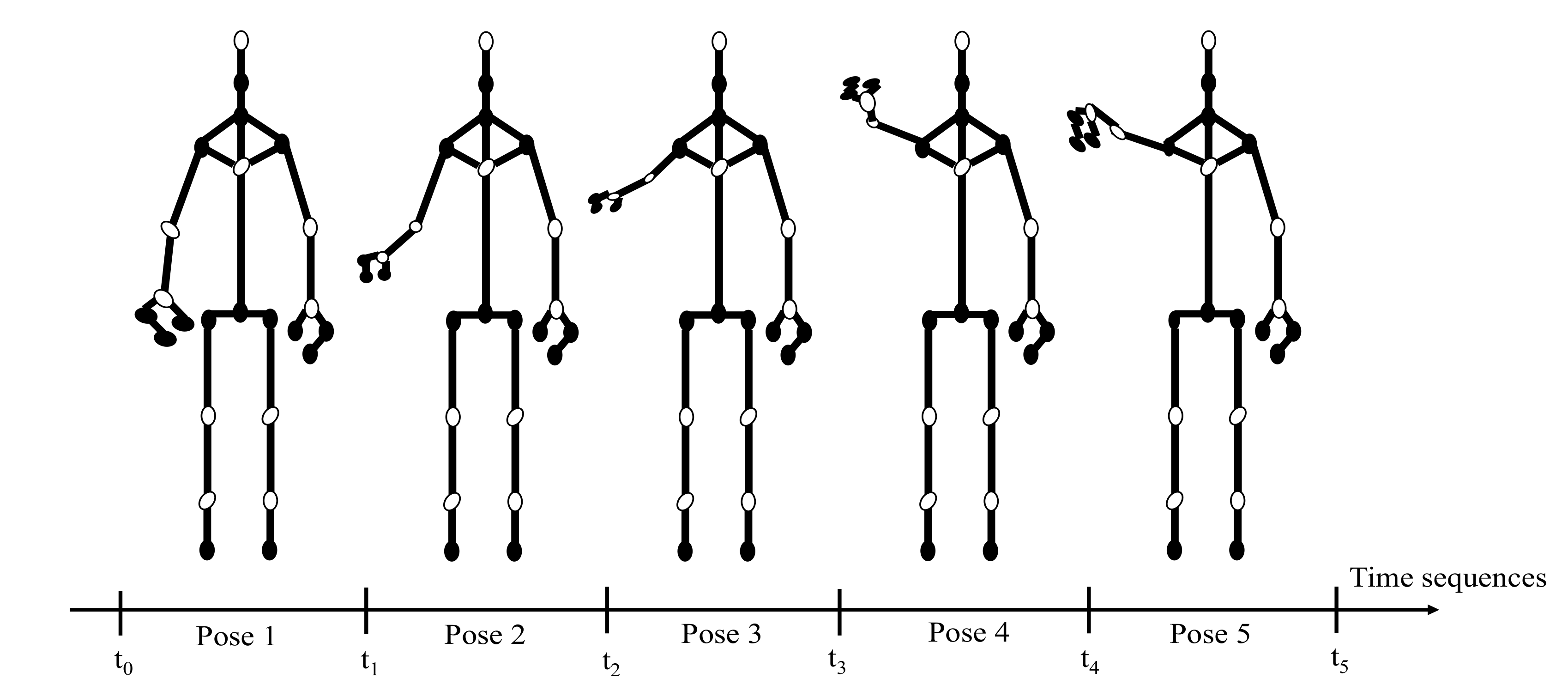
2.4. Pose Sequences for Human Activity
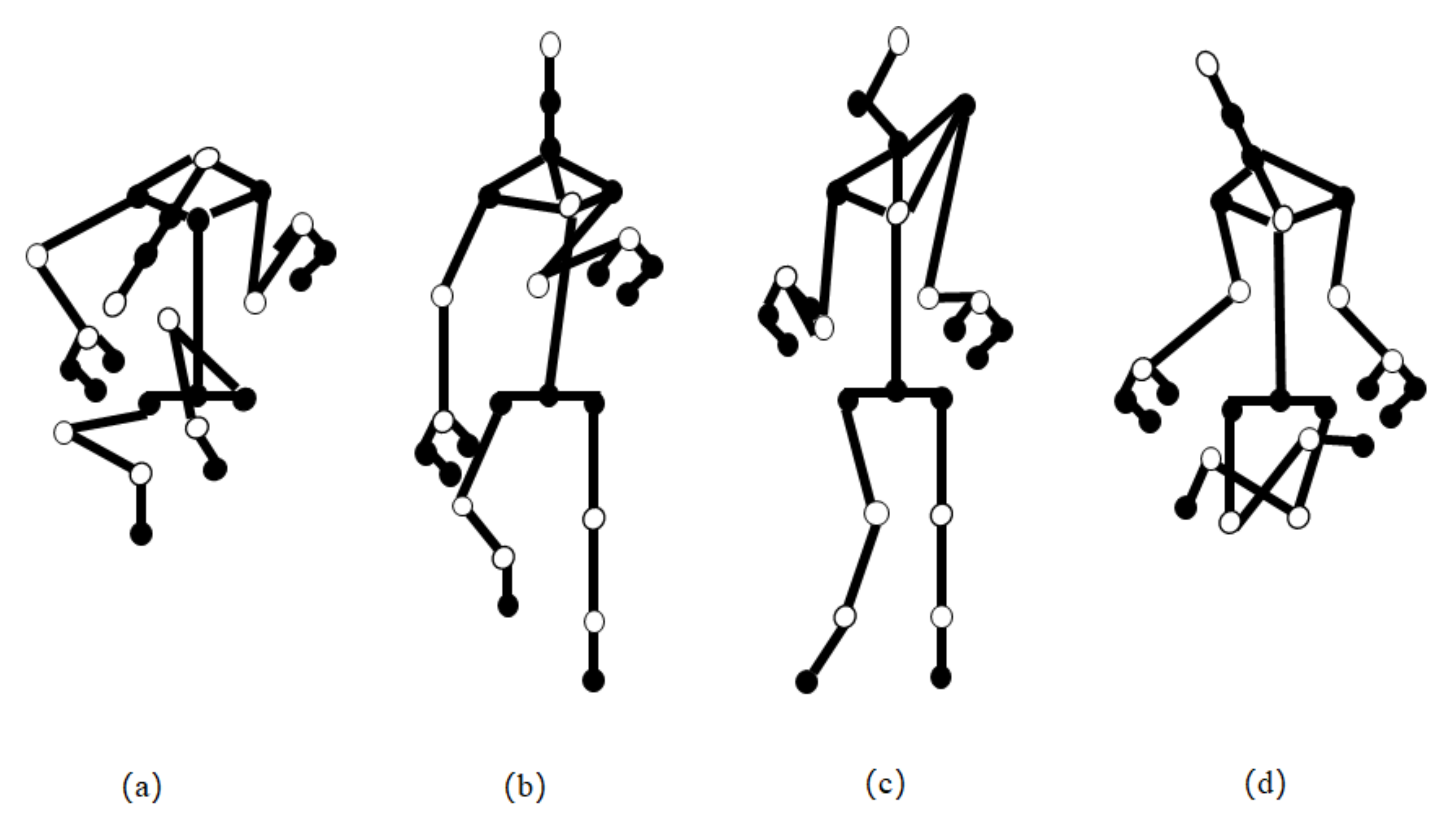
2.5. Noise Elimination
2.6. Discrete HMMs for Activity Recognition
3. Experimental Results
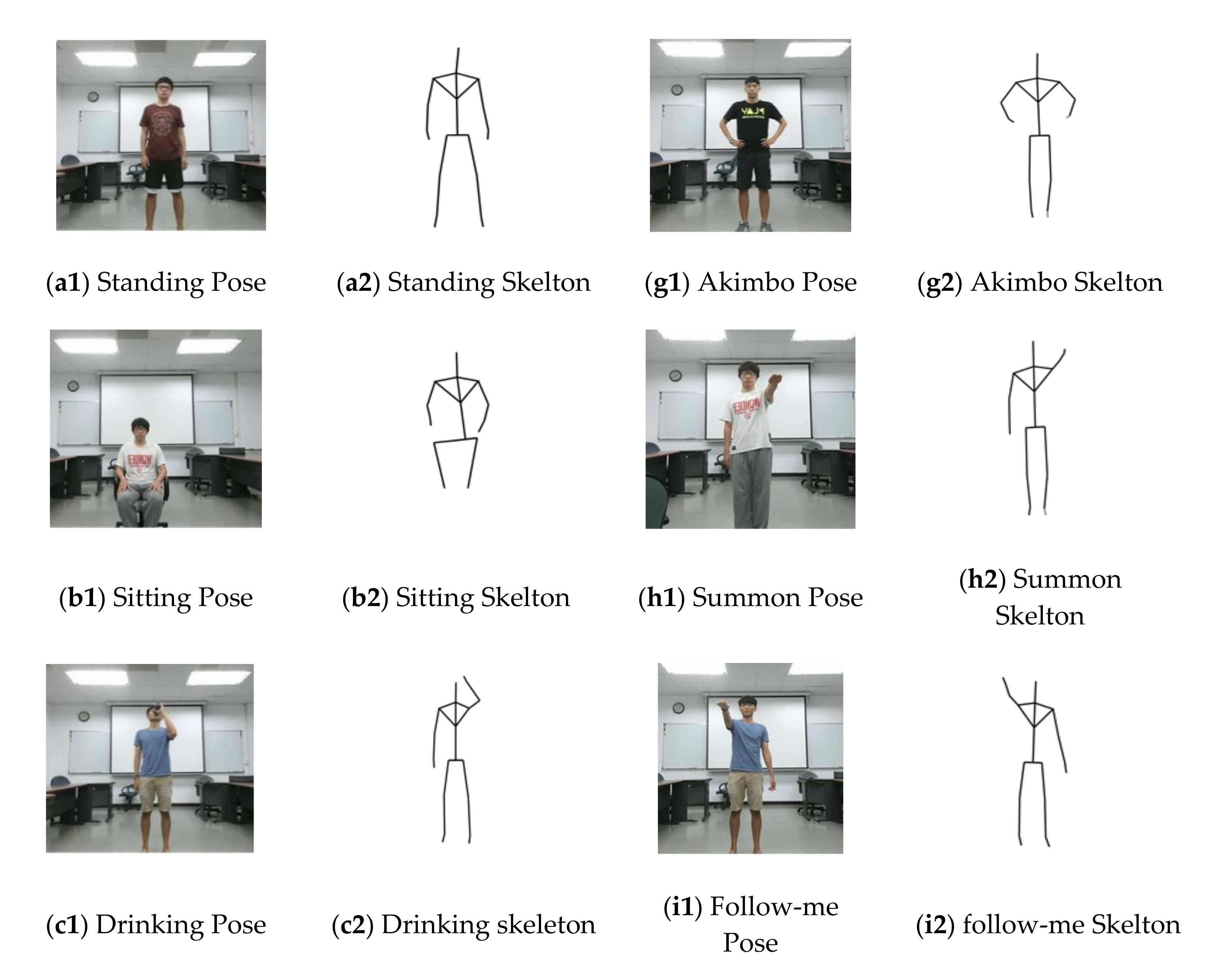
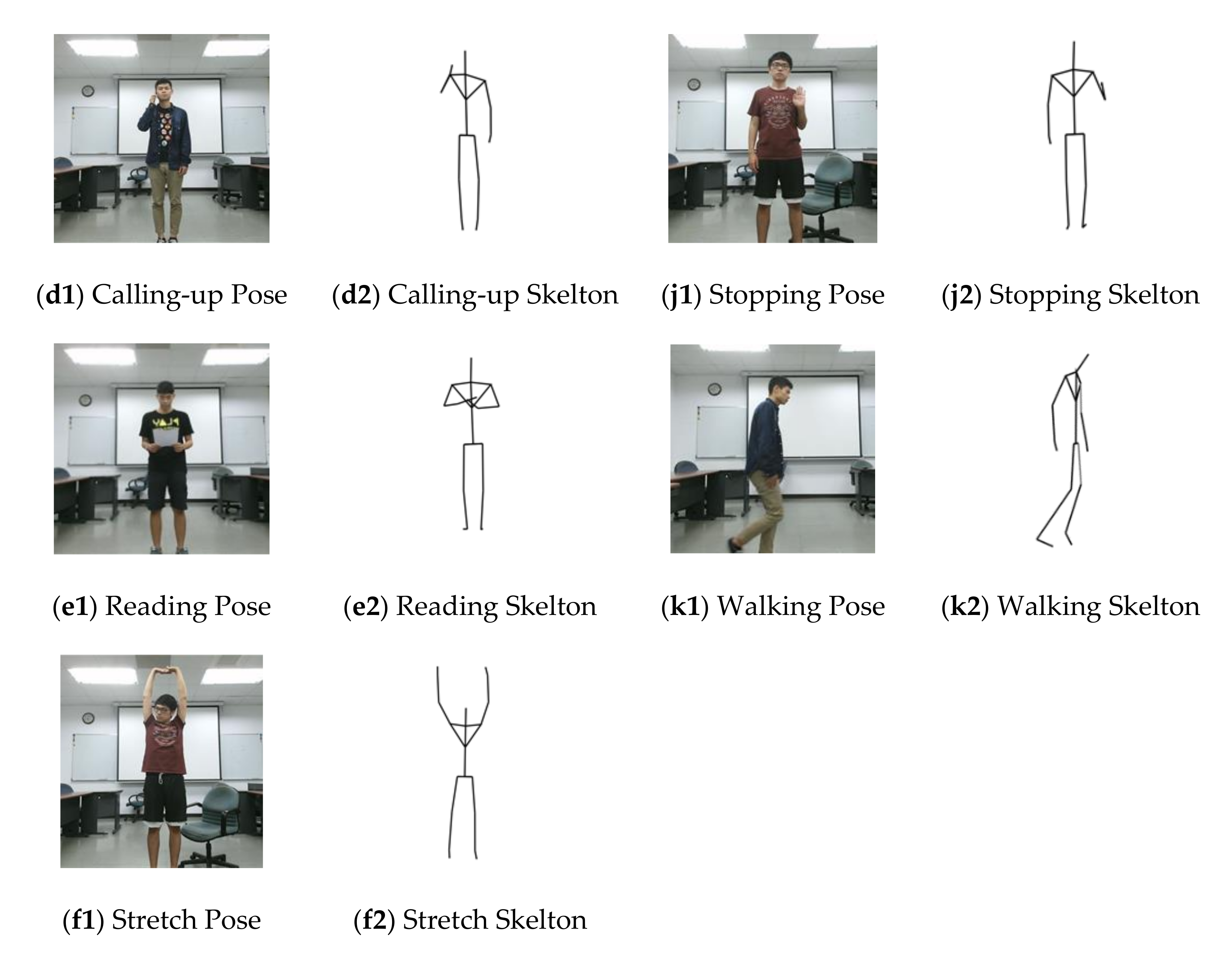
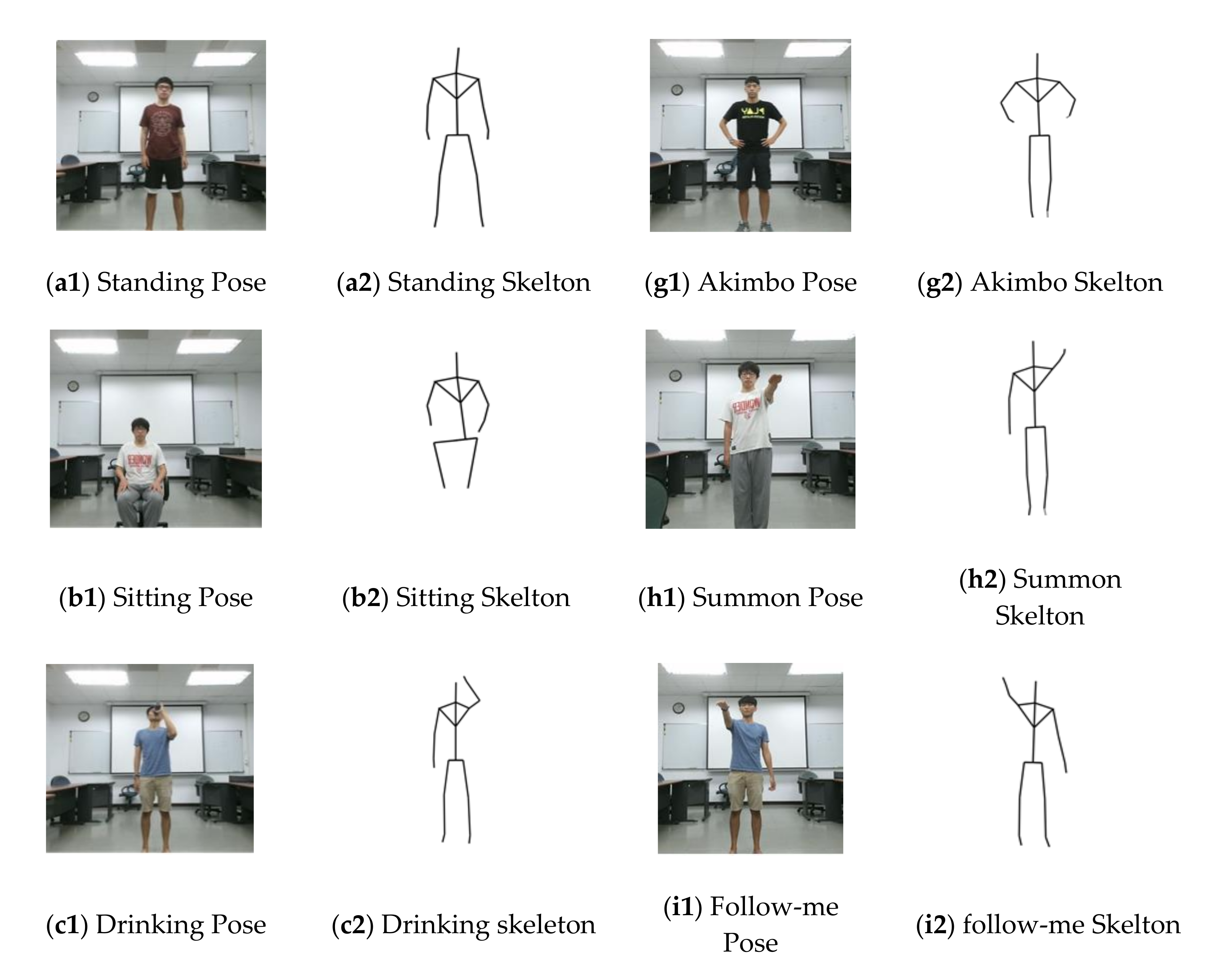
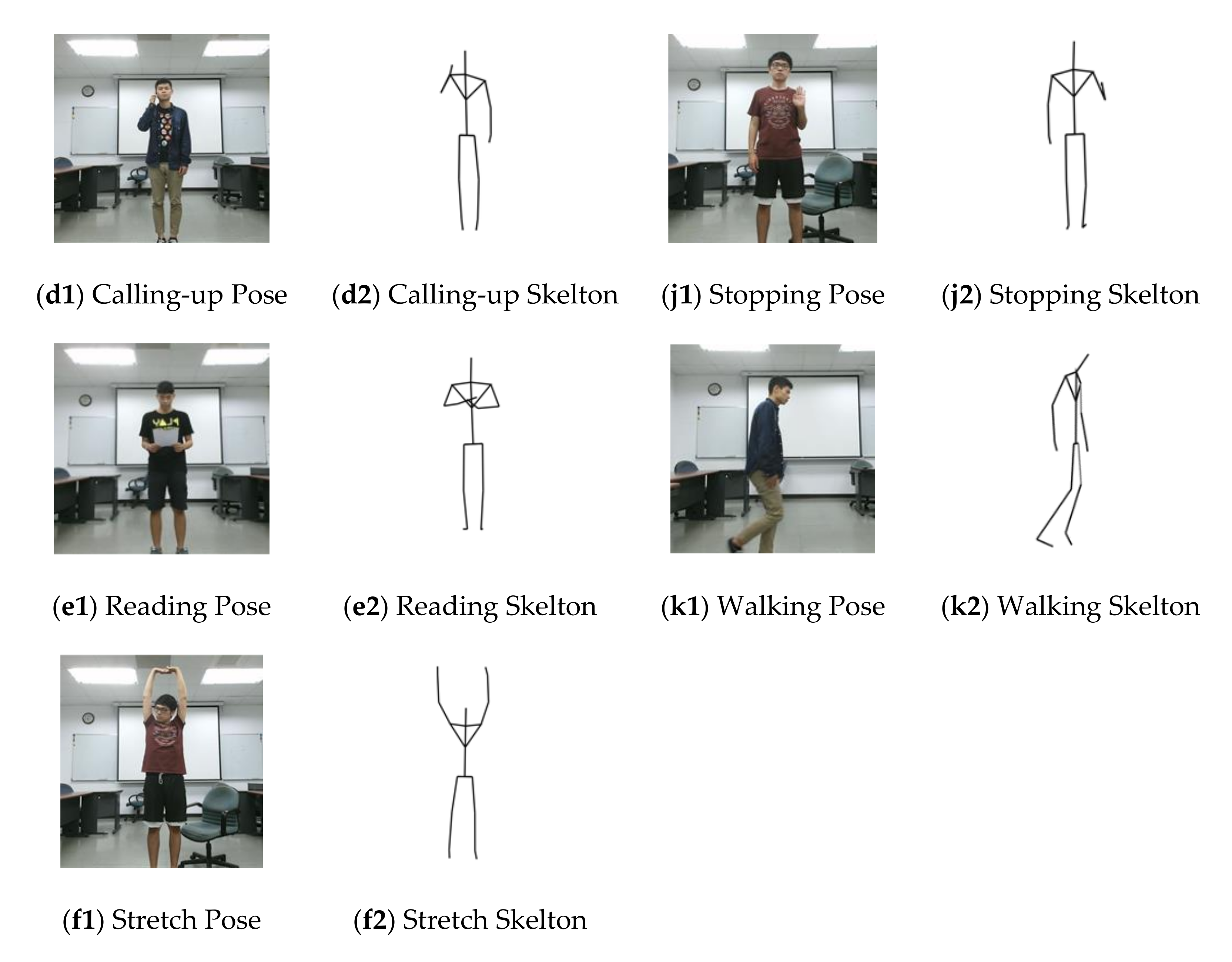
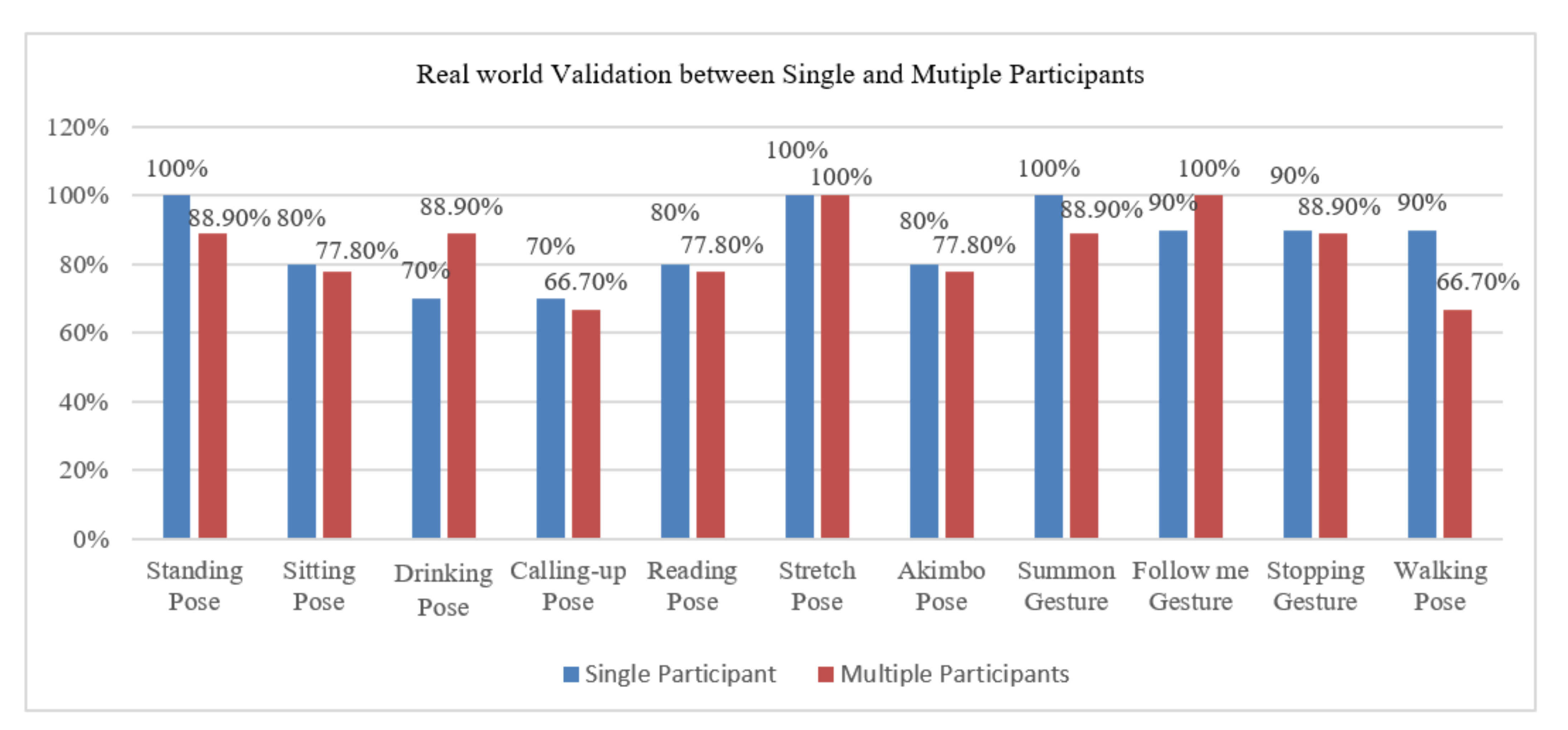
3.1. Dataset and Activity Implications
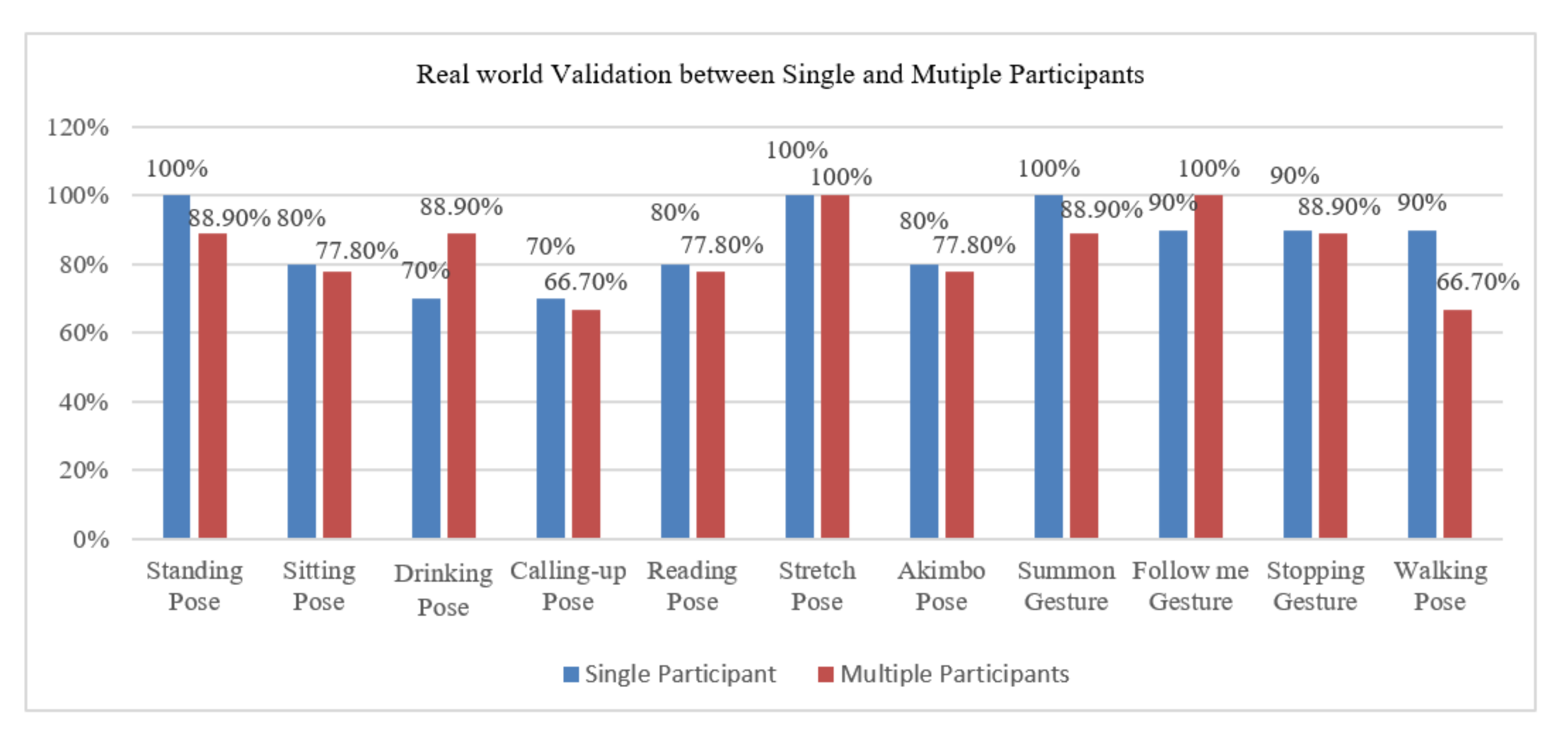
3.2. Experimental Evaluation
Confusion Matrix Assessment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensorbased and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 3. [Google Scholar]
- Bodor, R.; Jackson, B.; Papanikolopoulos, N. Vision-based human tracking and activity recognition. In Proceedings of the 11th Mediterranean Conference on Control and Automation, Rhodes, Greece, 18–20 June 2003; Volume 1. [Google Scholar]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef] [PubMed]
- Bux, A.; Angelov, P.; Habib, Z. Vision based human activity recognition: A review. In Advances in Computational Intelligence Systems; Springer: Cham, Switzerland, 2007; pp. 341–371. [Google Scholar]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Liu, Y.; Nie, L.; Liu, L.; Rosenblum, D.S. From action to activity: Sensor-based activity recognition. Neurocomputing 2016, 181, 108–115. [Google Scholar] [CrossRef]
- Kuan, T.W.; Tseng, S.P.; Wang, J.F.; Chen, P.J. A happiness cups system for holding-cup motion recognition and warming-care delivery. In Proceedings of the 2016 International Conference on Orange Technologies (ICOT), Melbourne, Australia, 17–20 December 2016. [Google Scholar]
- Yousefzadeh, A.; Orchard, G.; Serrano-Gotarredona, T.; Linares-Barranco, B. Active perception with dynamic vision sensors. minimum saccades with optimum recognition. IEEE Trans. Biomed. Circuits Syst. 2018, 12, 927–939. [Google Scholar] [CrossRef] [PubMed]
- Luan, P.G.; Tan, N.T.; Thinh, N.T. Estimation and Recognition of Motion Segmentation and Pose IMU-Based Human Motion Capture. In International Conference on Robot Intelligence Technology and Applications; Springer: Cham, Switzerland, 2017; pp. 383–391. [Google Scholar]
- Haescher, M.; Matthies, D.J.; Srinivasan, K.; Bieber, G. Mobile assisted living: Smartwatch-based fall risk assessment for elderly people. In Proceedings of the 5th international Workshop on Sensor-based Activity Recognition and Interaction, Berlin, Germany, 20–21 September 2018; pp. 1–10. [Google Scholar]
- Chanthaphan, N.; Uchimura, K.; Satonaka, T.; Makioka, T. Facial emotion recognition based on facial motion stream generated by kinect. In Proceedings of the 2015 11th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Bangkok, Thailand, 23–27 November 2015; pp. 117–124. [Google Scholar]
- Bouissou, M.B.; Laffont, J.J.; Vuong, Q.H. Tests of noncausality under Markov assumptions for qualitative panel data. Econom. J. Econom. Soc. 1986, 54, 395–414. [Google Scholar] [CrossRef]
- Li, S.Z. Markov Random Field Modeling in Computer Vision; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Ramage, D. Hidden Markov Models Fundamentals; CS229 Section Notes; Stanford University: Stanford, CA, USA, 2007. [Google Scholar]
- Yakowitz, S.J. Nonparametric density estimation, prediction, and regression for Markov sequences. J. Am. Stat. Assoc. 1985, 80, 215–221. [Google Scholar] [CrossRef]
- Benouareth, A.; Ennaji, A.; Sellami, M. HMMs with explicit state duration applied to handwritten Arabic word recognition. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 2, pp. 897–900. [Google Scholar]
- Russell, M.J.; Jackson, P.J.; Wong, M.L. Development of articulatory-based multilevel segmental HMMs for phonetic classification in ASR. In Proceedings of the EC-VIP-MC 2003 4th EURASIP Conference Focused on Video/Image Processing and Multimedia Communications (IEEE Cat. No. 03EX667), Zagreb, Croatia, 2–5 July 2003; Volume 2, pp. 655–660. [Google Scholar]
- Aarno, D.; Kragic, D. Layered HMM for motion intention recognition. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 5130–5135. [Google Scholar]
- Glodek, M.; Bigalke, L.; Schels, M.; Schwenker, F. Incorporating uncertainty in a layered HMM architecture for human activity recognition. In Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, Scottsdale, AZ, USA, 1 December 2011; pp. 33–34. [Google Scholar]
- Broumandnia, A.; Shanbehzadeh, J.; Nourani, M. Handwritten farsi/arabic word recognition. In Proceedings of the 2007 IEEE/ACS International Conference on Computer Systems and Applications, Amman, Jordan, 13–16 May 2007; pp. 767–771. [Google Scholar]
- Dehghan, M.; Faez, K.; Ahmadi, M. A hybrid handwritten word recognition using self-organizing feature map, discrete HMM, and evolutionary programming. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks, IJCNN 2000, Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; Volume 5, pp. 515–520. [Google Scholar]
- Yasuda, H.; Takahashi, K.; Matsumoto, T. A discrete HMM for online handwriting recognition. Int. J. Pattern Recognit. Artif. Intell. 2000, 14, 675–688. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Lo Presti, L.; La Cascia, M. 3D skeleton-based human action classification. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Guo, H.; Yang, Y.; Cai, H. Exploiting LSTM-RNNs and 3D skeleton features for hand gesture recognition. In Proceedings of the 2019 WRC Symposium on Advanced Robotics and Automation (WRC SARA 2019), Beijing, China, 21–22 August 2019; pp. 322–327. [Google Scholar]
- Elaoud, A.; Barhoumi, W.; Zagrouba, E.; Agrebi, B. Skeleton-based comparison of throwing motion for handball players. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 419–431. [Google Scholar] [CrossRef]
- Palanimeeraa, J.; Ponmozhib, K. Techniques used to Capture Skeletal Information and their Performance Accuracy: A Literature Review. In Proceedings of the Second International Conference on IoT Social, Mobile, Analytics and Cloud in Computational Vision Bio-Engineering (ISMAC-CVB 2020), Tamil Nadu, India, 29–30 October 2020; pp. 480–486. [Google Scholar]
- Raptis, M.; Kirovski, D.; Hoppe, H. Real-time classification of dance gestures from skeleton animation. In Proceedings of the 2011 ACM SIGGRAPH/Euro Graphics Symposium on Computer Animation, New York, NY, USA, 5–7 August 2011; pp. 147–156. [Google Scholar]
- Goldberg, M.; Sun, H. Image sequence coding using vector quantization. IEEE Trans. Commun. 1986, 34, 703–710. [Google Scholar] [CrossRef]
- Nasrabadi, N.M.; King, R.A. Image coding using vector quantization: A review. IEEE Trans. Commun. 1988, 36, 957–971. [Google Scholar] [CrossRef] [Green Version]
- Chahid, A.; Khushaba, R.; Al-Jumaily, A.; Laleg-Kirati, T.M. A Position Weight Matrix Feature Extraction Algorithm Improves Hand Gesture Recognition. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montréal, QC, Canada, 20–24 July 2020; pp. 5765–5768. [Google Scholar]
- Kästner, M.; Strickert, M.; Villmann, T.; Mittweida, S.G. A sparse kernelized matrix learning vector quantization model for human activity recognition. In Proceedings of the 21st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Classes | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standing Pose | Sitting Pose | Drinking Pose | Talking Pose | Reading Pose | Stretch Pose | Akimbo Pose | Summon Pose | Follow-me Pose | Stopping Pose | Walking Pose | ||
| True Classes | Standing Pose | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Sitting Pose | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Drinking Pose | 0 | 0 | 0.92 | 0.08 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Calling up Pose | 0 | 0 | 0.08 | 0.92 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Reading Pose | 0 | 0 | 0.04 | 0 | 0.96 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Stretch Pose | 0 | 0 | 0.08 | 0 | 0 | 0.92 | 0 | 0 | 0 | 0 | 0 | |
| Akimbo Pose | 0 | 0 | 0 | 0 | 0 | 0 | 0.96 | 0 | 0.04 | 0 | 0 | |
| Summon Pose | 0 | 0 | 0.04 | 0 | 0 | 0 | 0 | 0.96 | 0 | 0 | 0 | |
| Follow-me Pose | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
| Stopping Pose | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| Walking Pose | 0 | 0 | 0.08 | 0 | 0 | 0 | 0 | 0 | 0.04 | 0 | 0.88 | |
| P (Condition Positive) | N (Condition Negative) | TP (True Positive) | TN (True Negative) | FP (False Positive) | FN (False Negative) | TPR (True Positive Rate) | TNR (True Negative Rate) | FNR (False Negative Rate) | FPR (False Positive Rate) | ACC (Accu_Racy) | F1 Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standing Pose | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| Sitting Pose | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| Drinking Pose | 0.92 | 0.08 | 0.92 | 0.08 | 0.08 | 0.92 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.65 |
| Talking Pose | 0.92 | 0.08 | 0.92 | 0.08 | 0.08 | 0.92 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.65 |
| Reading Pose | 0.96 | 0.04 | 0.96 | 0.04 | 0.04 | 0.96 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.66 |
| Stretch Pose | 0.92 | 0.08 | 0.92 | 0.08 | 0.08 | 0.92 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.65 |
| Akimbo Pose | 0.96 | 0.04 | 0.96 | 0.04 | 0.04 | 0.96 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.66 |
| Summon Pose | 0.96 | 0.04 | 0.96 | 0.04 | 0.04 | 0.96 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.66 |
| Follow-me Pose | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| Stopping Pose | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| Walking Pose | 0.92 | 0.08 | 0.92 | 0.08 | 0.08 | 0.92 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuan, T.-W.; Tseng, S.-P.; Chen, C.-W.; Wang, J.-F.; Sun, C.-A. Discrete HMM for Visualizing Domiciliary Human Activity Perception and Comprehension. Appl. Sci. 2022, 12, 3070. https://doi.org/10.3390/app12063070
Kuan T-W, Tseng S-P, Chen C-W, Wang J-F, Sun C-A. Discrete HMM for Visualizing Domiciliary Human Activity Perception and Comprehension. Applied Sciences. 2022; 12(6):3070. https://doi.org/10.3390/app12063070
Chicago/Turabian StyleKuan, Ta-Wen, Shih-Pang Tseng, Che-Wen Chen, Jhing-Fa Wang, and Chieh-An Sun. 2022. "Discrete HMM for Visualizing Domiciliary Human Activity Perception and Comprehension" Applied Sciences 12, no. 6: 3070. https://doi.org/10.3390/app12063070
APA StyleKuan, T.-W., Tseng, S.-P., Chen, C.-W., Wang, J.-F., & Sun, C.-A. (2022). Discrete HMM for Visualizing Domiciliary Human Activity Perception and Comprehension. Applied Sciences, 12(6), 3070. https://doi.org/10.3390/app12063070