1. Introduction
Entity linking is the task of mapping mentions in a text to standard entities in a given knowledge base [
1]. Entity linking is one of the most important parts of information extraction [
2,
3], especially in biomedical research and clinical applications, and it is also the bridge between mentions and knowledge graphs in the knowledge base intelligent question answering process [
4]. The entity linking task remains challenging in that the same word or phrase can be used to refer to different entities, as well as the same entity can be referred to by different words or phrases. In the field of biomedical text processing, this task is more commonly referred to as biomedical entity normalization. Biomedical entity linking [
5] maps biomedical mentions such as disease, drug, and procedure terms that appear in a document to standard terminology words in the knowledge base.
Mentions extracted from biomedical texts suffer from a number of problems, such as colloquial, diverse, and erroneous representations, and if these conceptual entities are utilized or stored without processing, they may have adverse effects on subsequent tasks. The particular challenge of biomedical entity linking is not ambiguity, i.e., a word usually refers to only one entity, but the challenge actually lies in the fact that the surface forms differ significantly due to abbreviations, morphological variations, synonyms, and different word orders [
6]. For example, “alkaline phosphatase increased” is also written as “ALP increased”, “cerebral ischaemia” is also referred to as “ischemic cerebrovascular conditions”. The set of standard terms in the knowledge base is large, and the terms are still similar in form or semantics, making them difficult to distinguish. Moreover, unlike the traditional knowledge bases DBpedia [
7] and YAGO [
8], which contain information such as entity descriptions and entity attributes, entity information has only one entity name. Furthermore, not all biomedical mentions can be mapped to a specific term. Therefore, determining whether a mention can be mapped to a concept in a given ontology is part of the biomedical entity linking task, and these make medical entity linking very difficult.
In view of the current problems, researchers have deliberately proposed entity linking methods [
9,
10] for biomedical entity linking. Most of the biomedical entity linking research [
11,
12,
13] has focused on solving the problem of medical entity diversity. Currently, in the field of entity linking, deep learning shows its powerful advantages and is becoming the mainstream approach to studying biomedical entity linking. Recently, the BERT-based biomedical entity linking method [
14] has achieved the best results on different biomedical benchmark datasets. While this type of approach is effective, it poses challenges for fine-tuning in real industry and online services due to a large number of model parameters and long inference times. For deep learning models, the training efficiency of the model is very important, and the efficiency mainly includes training time and model parameters. Despite the fact that there are scientific facilities with a lot of computer capabilities, many people still have limited access to large-scale computational capacity. As a result, it is critical to create a more scalable approach for biological entity linking.
Essentially, biomedical entity linking is a type of semantic matching task. In general, they are mainly divided into representational matching models [
15,
16,
17] and interactive matching models [
18,
19,
20]. It is difficult for a representational model to measure the contextual importance between two sentences because the representational model needs to encode the representation of the two sentences separately, which will lose the semantic focus. The disadvantage of the interactive model is that it ignores global information such as syntax, inter-sentence contrast, etc., and thus cannot carve out global matching information from local information. In addition, biomedical entities are mentioned in too many different ways, and it is difficult to obtain good results with a single matching model. Inspired by recent progress, combining the advantages of each of them, we propose an efficient biomedical entity linking method by jointly modeling the intra-entity and inter-entity relationships of mention and candidate in a unified deep model to better capture the information between medical mentions and candidate entities themselves and each other. In summary, our main contributions can be summarized as follows:
We propose an efficient network for biomedical entity linking by jointly modeling inter- and intra-entity relationships of biomedical mentions and candidates in a unified model.
A novel fusion framework with cross-attention and self-attention is proposed to better exploit not only the relationship within each entity but also the relationship between mentions and candidates.
We also designed a biomedical entity linking method based on BERT and pairwise ranking to compare with the lightweight method in this paper.
The experimental results demonstrate that the proposed method in this paper achieves fairly competitive performance on two biomedical benchmark datasets. Furthermore, it also achieves comparable or even better results compared to the BERT-based entity linking method while having far fewer model parameters and very high inference speed.
The rest of the article is structured as follows: Biomedical entity linking research will be briefly discussed in
Section 2 of this paper. Our methodology for linking biomedical entities will be explained in
Section 3, and the general structure and processing flow of each portion will be shown. In order to show the efficacy of our approach, we provide an in-depth analysis of the experimental results in
Section 4.
Section 5 summarizes the research and discusses possible future directions.
2. Related Work
In the field of biomedical entity linking, earlier studies used rule-based systems to capture string similarity between mentions and entity names. Kang et al. [
9] proposed a natural language processing module with five rules to improve the normalization performance of disease terms in biomedical texts. D’Souza and Ng [
21] proposed a manual rule-based multichannel filtering system by defining 10 rules with different priorities to measure the morphological similarity between mentions and candidate entities in a given knowledge base for entity linking, and this is the best rule-based system that has worked so far on the NCBI [
22] dataset.
To avoid the inefficiency associated with manual rules, machine learning methods automatically learn the appropriate similarity metric between entity mentions and entity names from the training set. DNorm [
11] proposed by Leaman et al. uses a vector space model to represent medical entity mentions and a similarity matrix to measure the similarity between a given medical entity mention and a standard entity, with good results on the NCBI disease dataset. Ghiasvand and Kate [
23] automatically learned the edit distance pattern of 554 term variations between synonyms of all disease concepts in the Unified Medical Language System (UMLS) [
24] and the edit distance between mentions in the training data and the corresponding concepts in the UMLS to perform entity linkage processing. TaggerOne [
13] uses a semi-Markov model for biomedical entity identification and linkage and is by far the best machine learning-based system on the NCBI dataset. Xu et al. [
10] also defined three features and used linear RankSVM [
25] to group each positive ADR mentioned as an entry in MedDRA in the TAC2017 ADR Challenge [
26] that achieved the best performance. However, these machine learning methods cannot use semantically relevant information to link entity mentions more accurately.
Deep learning methods are currently showing their strong advantages in the field of entity linking. Since recently, deep learning approaches based on pre-trained embeddings have been effectively applied to many Natural Language Processing tasks, such as word2vec [
27] and Glove [
28]. In the field of biomedical entity linking, Li et al. [
6] proposed a Convolutional Neural Network (CNN)-based entity linking architecture that treats biomedical entity linking as a ranking problem, which exploits the semantic similarity modeling of CNNs between entity mentions and candidate entities, and this approach outperforms the traditional rule-based approach. However, this method only takes the final semantic vectors of mentions and candidate entities, which makes it hard to figure out how much information has been lost and how the information between mentions and candidate entities is not interacting.
In 2019, Wright et al. [
29] came up with a deep learning model called NormCo that takes into account the semantics of entity mentions and the consistency of entity mention topics in a single text. The biomedical entity normalization task is accomplished by combining the morphological similarity between entity mentions and candidate entities and the semantic similarity between mentions and entities computed using the GRU model. Phane et al. [
30] proposed a new framework for BNE that considers and encodes the similarity between contextual meaning, conceptual meaning, and synonyms during representation learning to learn biomedical names and robust representations of terms. In 2019, Ishan et al. [
31] proposed a framework for medical entity linking based on Triplet Networks, which uses three samples to form a training group, and useful features are learned by comparing distances. [
32] proposes a new paradigm for learning robust representations of biological names and phrases that takes contextual meaning, conceptual meaning, and synonym similarity into consideration throughout the representation learning process.
Traditional word embedding methods have a context-independent representation for each word. BERT (Bidirectional Encoder Representations from Transformers) pre-trained language model [
33] addresses this problem by training deep bidirectional representations from unlabeled texts. Based on the BERT pre-training model architecture, the domain-specific language representation model BioBERT (BERT for Biomedical Text Mining) [
34], which is pre-trained on large-scale biomedical texts and clinical notes, was introduced to improve the performance of many biomedical and clinical natural language processing tasks. Recently, Ji, Wei, and Xu [
14] considered biomedical entity linking as a sentence pair classification task and proposed an entity linking architecture by fine-tuning the BERT pre-training model and achieved the best results so far on different types of datasets in the field of biomedical entity linking. A problem with pre-trained models is that they are usually computationally expensive and inefficient in practice. To deal with the above issues, we propose an efficient method for biomedical entity linking based on Inter- and Intra-entity attention. Different from existing methods, the proposed biomedical entity linking model is able to exploit not only the intra-entity relationship within each entity, but also the inter-entity relationship between mention and candidate to enhance each other for mentions and candidates matching.
3. Method
Given the biomedical mentions recognized in the document and the knowledge base consisting of a set of concepts, the goal of the biomedical entity linking task is to link each mention to the correct medical entity in the knowledge base. If a mapping concept is not present in the knowledge base, then it is denoted by NIL as unlinkable. To solve this problem, given a training set that is already linked to the correct entity in the knowledge base, the biomedical entity linking approach in this paper consists of three steps:
- 1.
Preprocessing: All entity mentions in the corpus and entity names in the knowledge base are preprocessed to unify the format.
- 2.
Candidate entity generation: For each biomedical mention, a set of candidate entities is generated from the knowledge base.
- 3.
Candidate entity ranking: For each mention, a candidate ranking model is used to score each pair of mention and candidate entity, and the result with the highest score is output.
3.1. Preprocessing
Abbreviation Resolution: As in previous work on biomedical entity linking, in this paper, we use the Ab3p (Biomedical Text Abbreviation Recognition Tool) toolkit [
35] to extend biomedical abbreviations. The Ab3p tool identifies abbreviations in documents and returns a list of replacement terms with probability, and we use the replacement term with the highest probability. For example, Ab3p identifies that “pws” is an abbreviation for “Prader Willi syndrome,” and we replace each entity abbreviation with its corresponding expanded term.
Numeric Synonyms Replacement: Biomedical entity names may contain different forms of numbers. Therefore, in this paper, a numeric dictionary was manually created and different forms of numbers in biomedical mentions and concepts were replaced with their corresponding Arabic numerals.
Other Preprocessing: In addition, all punctuation was removed, and all words were converted to lowercase letters.
3.2. Candidate Generation
In the candidate generation phase, for each mention M, the goal of the biomedical entity linking system is to filter out irrelevant entities from the standard knowledge base and generate the candidate entity set , which contains the mention M with all possible standard entities e linked to it. The aim is to narrow down the scope of subsequent reordering links and thus improve overall efficiency.
The candidate entity generation method used in this paper calculates similarity scores for each pair of biomedical mentions in the corpus and entities in the knowledge base and returns the top entity with the highest score as the candidate set. In order to take advantage of the hidden features in biomedical mentions, two retrieval methods are designed. The first approach is to search directly for the closest standard terms to the biomedical entity mentions to be linked. The second way is to find the most similar entity mentions on the annotated data to be linked. The goal is to find the most similar data to the “original surgical term” to be normalized on the annotated data and take the corresponding standard term as the candidate entity. In this paper, the top 20 standard entities were selected as the candidates by combining the above two search methods.
In this paper, we use an unsupervised alignment method [
36], which calculates the cosine similarity between each word in an entity mention and the word embedding of each word in a given knowledge base entity to obtain a cosine similarity score matrix. For the words in each mention, the algorithm selects the most similar words in the text by maximum pooling. Each word is represented by a 200-dimensional word embedding trained from PubMed and the MIMIC-III corpus [
37]. A given word
is mapped to the most similar word
by alignment cosine similarity and returns the cosine similarity score for that word. We calculate the similarity from two directions.
Then, the similarity scores of mentions and candidate entities are calculated as the sum of the alignment cosine similarity.
Finally, a candidate entity set is constructed, which contains the previous candidate entities mentioned by each entity and the similarity score of each candidate entity. We find that there are entities with a score equal to 1 in the set of candidate entities, and if there are candidate entities with a score equal to 1 in this set, we can filter the other candidate entities with a score less than 1. Then we use the candidate entity ranking model for the set of entities to output the final result.
3.3. Candidate Ranking
Given a mention
M and its candidate entity set, the biomedical candidate ranking model calculates scores for each pair of mention and candidate
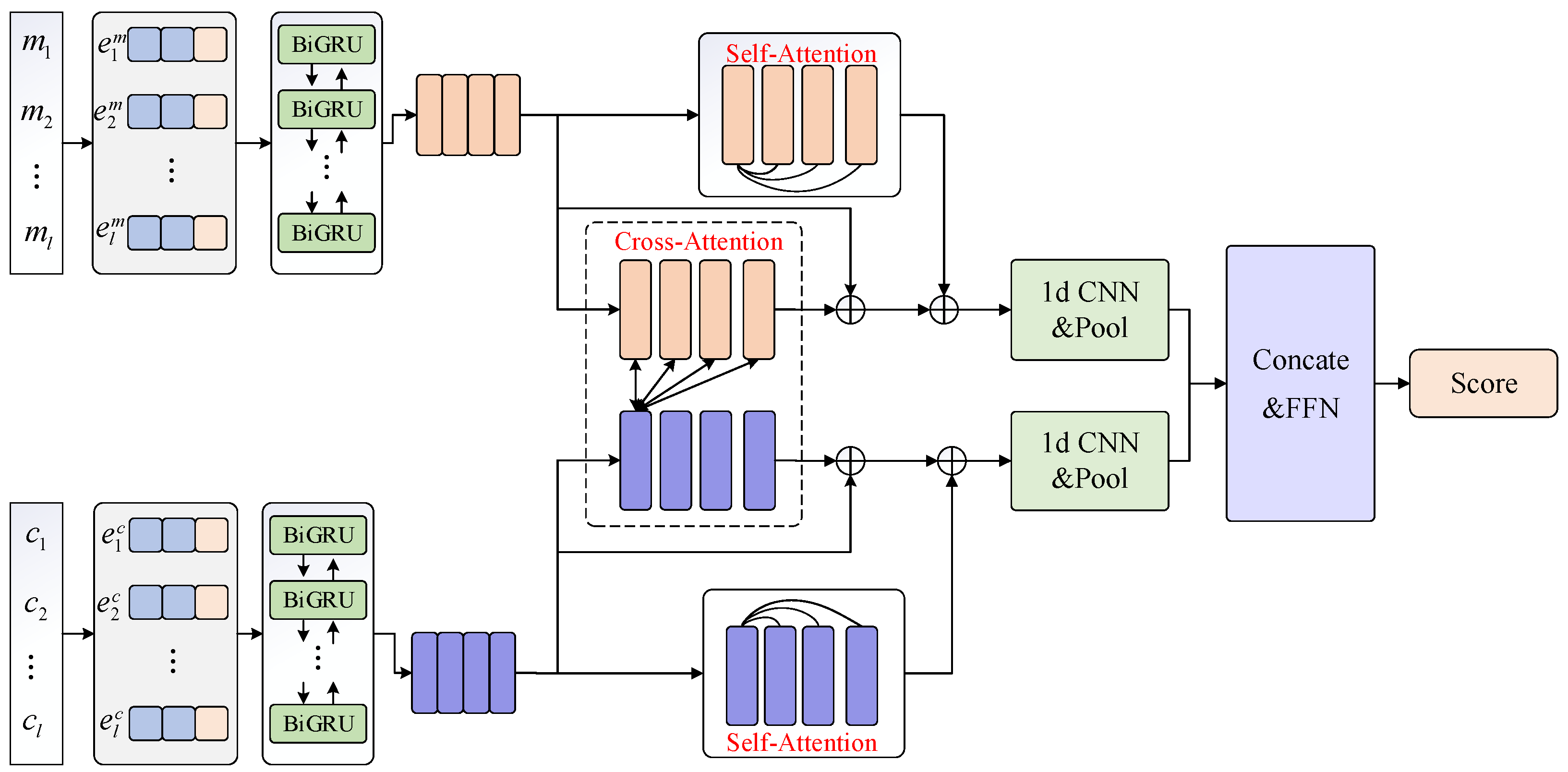
C. In this section, we describe the details of this ranking model, which mainly consists of a representation layer, a BiGRU encoding layer, an intra-entity attention module, an inter-entity attention module, and a CNN aggregation layer. The overall architecture of the biomedical candidate ranking model proposed in this paper is shown in
Figure 1. As shown in
Figure 1, given a biomedical mention-candidate pair, the mention and candidate entity are first converted into a corresponding word vector by querying the word vector table. Then it is concatenated with the character-level features of each word obtained using CNN. The vectors are sent into the BiGRU layer for encoding. Based on these extracted fine-grained representations for mentions and candidates, we model the intra-entity relationship with the Self-Attention Module, and adopt the Cross-Attention Module to model the inter-entity relationships for mentions and candidates. Then the 1d-CNN and pool operation are employed to aggregate the two sequences of matching vectors into fix-length vectors. Finally, we use a two-layer fully connected neural network to compute the final score.
3.3.1. Perfect Match
In the candidate generation stage, it is found that some candidate entities can completely match the standard entities; that is, the alignment cosine similarity is equal to 1. These entities are then linked directly into the knowledge base without being fed into the candidate ranking model. Then, the candidate ranking model is used to output the final result for entities with scores of less than 1 in the candidate set.
3.3.2. Representation Layer
The purpose of the representation layer is to vectorize the mentions and candidates expressed in natural language form. In this paper, the mentions and candidate entities are represented by the set of embeddings in the vocabulary
V. Each word is represented by a 200-dimensional word vector trained by PubMed and the MIMIC-III corpus [
37]. However, not all words in the dataset are present in the vocabulary
V. To deal with the problem of being out of vocabulary, a convolutional neural network (CNN) [
38] is used in this paper to capture the character-level features of each word to obtain a character vector. To make full use of both word-level and character-level information, the word vector is finally concatenated with the character vector to represent biomedical entity mentions with candidate entities.
3.3.3. Encoding Layer
We use Bi-directional Gated Recurrent Unit (BiGRU) [
39] to encode mentions and candidates separately because GRU is computationally more efficient than LSTM [
40], and its performance is comparable to LSTM. BiGRU learns to represent a word (or character) and its context. The output state of the BiGRU at time
i over the mention
m is denoted by the symbol
.
is the same way:
The gated recurrent unit (GRU) is a special type of recurrent neural network that captures the contextual order information of sequences. GRU can only encode historical information, while ignoring future contextual information. In this paper, a bidirectional GRU network consisting of both forward GRU and reverse GRU is used. BiGRU obtains the final hidden layer representation by splicing two different hidden layer representations obtained by sequential and inverse order calculations.
3.3.4. Self-Attention Module
The text sequence features extracted by the BiGRU encoder ignore the different contributions of different words to the semantic representation of the whole entity. Therefore, this paper further improves the ability to extract global features by using a self-attention mechanism [
41] in the intra-entity attention layer, which learns different semantic importance in the entity by the attention operations performed between each word. Each word is able to pay attention to the features of other segments in the same entity. The feature weights are dynamically adjusted by the self-attention mechanism to emphasize interdependent word features automatically. It can be used to find relationships within sequences, selectively focus on some important information, and give higher weights to the important ones. Thus, the problem of the equal contribution of each character is effectively solved.
Basically, it can be described as a mapping relationship between a query and a series of key-value pairs. The output is a weighted sum of these values, where the weight assigned to each value is calculated from the compatibility function of the query with the corresponding key-value. The self-attentive mechanism is defined as shown in the following Formula:
where
denotes the output of the BiGRU layer, l is the hidden layer dimension of the GRU unit.
is the trainable weight and d is the output dimension. In this paper, we take
as an example to further explore the execution process of the self-attentive mechanism, as shown in
Figure 2.
To be specific, given query vector and key vector . Firstly, the similarity of for each key is computed by the scaled dot product function. The similarity score is divided by to have stable gradients, and the weight coefficient is computed by the softmax function. After that, a weighted summation operation is performed on each value to obtain the final attention according to weighted coefficients .
3.3.5. Cross-Attention Module
Although the self-attention module described above may efficiently utilize the intra-entity relationship, the relationship between mention and candidate is not explored. In this section, we model the inter-entity relationship through the cross-attention module, where the attention weights of mentions and candidates can be mutually learned to learn the close association between text features. This allows us to achieve more accurate matching results by learning the close association between text features.
The inter-entity attention module first learns to capture the importance between the features of each pair of mention and candidate. Then an information flow is passed between the two models to update each mention feature and candidate feature based on the learned importance weights and aggregated features. Such an information flow is able to identify the relationship between mention and candidate entity. The implementation of Cross-Attention Module is illustrated at
Figure 3.
Given mention and candidate features, we first compute the association weights between each pair of word in mention and candidate. Each word feature is transformed into query, key, and value features by utilizing linear projection, where the transformed mention features are denoted as , and the candidate features denoted as .
By calculating the inner product between the mention features
and the candidate features
, we can obtain the initial attention weights, and then apply the softmax function to normalize them row-wisely.
These two bidirectional InterA matrices capture the importance between each mention and candidate word pair. Taking
as an example, each row represents the attention weight between a word in a mention and all word embeddings of the candidate. The final attention vector
is then aggregated as the weighted summation of the candidate word value features
.
Finally, we do a similarity calculation between the features and the attention vector for each moment. We denote the information flow of the updated mention features and candidate features as
and
respectively.
where the operator
refers to matrix multiplication.
3.3.6. Aggregation Layer
Rich mention and candidate representation are available by stitching together all interaction results, and this layer is used to aggregate two matched vector sequences into a fixed-length vector. CNN has been shown to excel in learning sentence vector expressions from both syntactic and semantic levels simultaneously in a variety of natural language processing tasks, and the unique convolutional operation allows them to learn the features of long sequences of text with stability. The unique convolution operation allows it to learn features of short sequences with stable expressions in long sequences of text, independent of their position of occurrence. The CNN is more suitable for this model since its sequential nature is not strong when the interaction model is used. Therefore, we use the CNN model to apply it to the sequence of entity mentions and candidate matching vectors, respectively, and then stitch the CNN output features together to construct fixed-length matching vectors. The core of CNN is the convolutional layer, which can encode important information in the input data with fewer parameters. The convolutional layer is equivalent to a sliding window, which allows contextual features to be obtained within a local window of the current word. In the biomedical entity linking task, we found that good performance can be achieved with only one convolutional layer. In general, multiple convolutional kernel sizes perform better than a single size. The convolution operation is as follows:
where,
, d is the word embedding dimension and
m is the convolution kernel size.
represents a window starting from the
i th contextual embedding to the
i +
m−1th contextual embedding,
is a bias vector.
denotes a nonlinear activation function. The output of the feature map is
, where
n is the number of convolution windows and
is the result of each convolution.
After that, by selecting the maximum value of each feature map, its most important features can be captured. Using maximum pooling for all convolution kernels and then cascading them together gives the final feature vector .
Finally, we use a two-layer fully connected neural network to compute the final result.
where
is the first layer of output features,
and
are trainable weight matrices, and
and
are biases.
3.3.7. Objective Function
In this paper, a triplet loss function [
42] is used to train the model. The neural network model based on the triplet loss function can distinguish the details well, especially in the entity linking task. When the mentions are very similar to the candidate entities, the triplet loss function can learn more subtle features for these two input vectors with fewer differences. The purpose of the triplet loss function is to separate positive and negative sample pairs at a certain distance (margin) by optimizing the embedding space to ensure that the positive sample pair is close enough to each other and the negative sample pair is far enough away from each other. The idea of Triplet loss can be formally expressed as follows.
To prevent uneven data selection from leading to unstable performance of the model training process, in this paper, positive examples are randomly obtained from the training set and synonym entities in the knowledge base, and negative examples are drawn from the candidate entities generated in the candidate entity generation phase (excluding the correct entities). This selection makes the negative examples very similar to the positive ones and forces the model to learn more subtle differences between the positive candidate entities and other candidate entities.
4. Experimental Results
4.1. Dataset
To demonstrate the effectiveness of our proposed method, we carried out extensive experiments on two publicly available biomedical entity linking benchmark datasets: the NCBI-NCBI disease corpus and the ADR-TAC 2017 Adverse Reaction Extraction (ADR) dataset. The statistics for both datasets are shown in
Table 1.
NCBI: This is one of the most popular datasets for biomedical entity linking tasks. It contains 792 PubMed abstracts, of which 692 abstracts were used for training and development, and 100 abstracts were used for testing. The 6 July 2012 version of MEDIC, which contains 7827 MeSH identifiers and 4004 OMIM identifiers, was used in this paper, and it contains 9664 disease concepts. All annotated disease mentions have their corresponding concept identifiers.
ADR: This dataset consists of 200 drug labels, divided into 101 labels for training and development and 99 labels for testing. The ADRs in each drug label were manually mapped to the MedDRA 18.1 knowledge base, which contains 23,668 concepts. In this dataset, only 0.7% of the training mentions and 0.3% of the test mentions were unlinkable.
4.2. Evaluation Metrics
The biomedical candidate entity generation task uses recall (Recall) as an evaluation metric, which is calculated as shown in Equation (17).
where P and Q denote the mentions to be linked and the set of candidate entities, respectively.
In the candidate ranking stage, following previous work, accuracy is used in this paper to evaluate the performance of the entity linking algorithm, i.e., the percentage of mentions that are correctly linked.
where, T is the predicted correct biomedical entities and N is the total number of entities to be linked.
4.3. Experiment Settings
The experiments in this chapter are based on Python 3.7, and the proposed network is implemented using the Tensorflow deep learning framework with an Intel(R) Xeon(R) E5-2678 v3 @ 2.50 GHz CPU, a GeForce RTX 3090 GPU graphics card, and 24 G of running memory.
The parameters of the deep learning model in this experiment are shown in
Table 2. In this paper, Adam was chosen as the optimizer for the experiments. We use dropouts the in BiGRU encoding layer, CNN aggregation layer, and the fully connected layer.
4.4. Benchmarks
In order to verify the validity of the method proposed in this paper, several recent state-of-the-art methods on the NCBI and ADR will be selected for comparison.
Sieve-based Model [
21]: A manual rule-based multi-channel sieving system, which is by far the best rule-based system on the NCBI dataset.
Dnorm [
11]: A pairwise ranking learning approach using similarity matrix to measure the degree of similarity between biomedical mentions and standard entities, and it is a machine learning based approach.
TaggerOne [
13]: It is the best machine learning based approach on the NCBI dataset using a semi-Markov model jointly for named entity recognition and entity linking.
Learning to Rank [
10]: A method for learning to rank, best performance in the TAC2017 ADR Challenge, a machine learning based system.
CNN-based Ranking [
6]: This approach treats biomedical entity linking as a ranking problem and uses CNN to model semantic similarity between mentions and candidate entities.
BNE [
30]: A novel encoding framework that considers all these aspects in representation learning.
NormCo [
29]: A deep learning model, in which the biomedical entity linking task is accomplished by combining morphological similarity and semantic similarity computed using the GRU model.
TripletNet [
31]: We make use of the Triplet Network for candidate ranking.
BERT-based Ranking [
14]: This approach treats biomedical entity linking as a sentence pair classification task and accomplishes entity linking by fine-tuning the BERT pre-training model.
4.5. Results and Analysis
In this section, we demonstrate the effectiveness of our proposed model on two benchmark datasets. Firstly, the model of this paper is compared with the current model of linking biomedical entities. Next, the properties of the proposed model are demonstrated by some ablation experiments. Finally, the lightweight model is compared with the state-of-the-art BERT-based model.
4.5.1. Candidate Generation Experiment
In this paper, in the process of candidate entity generation using the alignment method, the recall rate increases as the recall range increases, and the Top20 candidate entity recall effect reaches a high level. The recall rate of correct entities on the NCBI and ADR test sets is 94.52% and 96.73%, respectively, and the experimental results are shown in
Table 3. The candidate generation method based on aligned cosine similarity used in this paper does not miss too many correct candidate entities, indicating that the method is effective for the biomedical candidate generation task. Finally, we generated 20 candidate entities for each mention to ranking.
4.5.2. Comparison Experiment
We compare our model with several recent state-of-the-art non-BERT methods on NCBI and ADR datasets. The results in
Table 4 are taken from the original state-of-the-art papers. Since the two experimental datasets used in this paper are public and the training and testing parts have been divided, we think that the results of the original paper are comparable. The performance results show that the model in this paper outperforms the baseline approach with an accuracy of 91.28% and 93.13%, respectively. Compared with the rule-only or traditional machine learning baseline approaches, the deep learning model in this paper achieves a significant improvement in accuracy by 6.63% over the Sieve-based model, 9.08% over Dnorm, and 2.48% over TaggerOne on the NCBI dataset. On the ADR dataset, it improved by 1.08% compared to Learning to Rank. The CNN-based entity linking model with the NormCo model ignores the rich interaction information between candidate entities and mentions, which limits its performance. The framework of this paper outperforms the CNN-based approach by 5.18% and 2.89% on the NCBI and ADR datasets, respectively, which indicates that the attention mechanism is more effective than the single Siamese representations. From the performance results, we can also see that our model works better than TripletNet. The superiority of this model can be attributed to the fact that it utilizes the self-attention module and cross-attention module to form a unified network to better capture the interaction information between biomedical mentions and candidate entities themselves and each other and to better perform the matching task.
4.5.3. Ablation Study
To demonstrate the effectiveness of the various components of the model, some ablation studies are also conducted in this paper. We construct four ablation models (w/o BiGRU, w/o Cross-Attention, w/o Self-Attention, w/o CNN) by eliminating a component at each time.
Table 5 shows the accuracy rates on the test set. First, we study the impact of the BiGRU encoder and compare the ablation model with the “Full model”. We find that the impairment of performance by removing the BiGRU is about 1.13% and 1.12% on two datasets. After that, we evaluate the effectiveness of the attention mechanism. For this purpose, we construct the ablation model by removing the attention mechanism. From the experimental results, we can see that the attention mechanism has a significant impact on performance. Removing cross-attention has a larger impact on the model performance, with a decrease of 2.90% and 4.65% on the NCBI and ADR datasets, respectively, proving its effectiveness in considering the full alignment between entity mention-candidate entity pairs. In the case of removing self-attention, the accuracy decreases by 1.04% and 0.54%, respectively. Thus, better matching results can be achieved by weighted features computed by self-attention, which we can use to investigate potential alignments more carefully and precisely. Finally, removing the CNN decreases the accuracy by 2.43% and 1.73%. It is clear that adding CNN to the aggregation layer is complementary to extracting more fine-grained features.
4.5.4. Analysis of Margin Value λ
In addition, in order to study the effect of margin value on the model effect in the triplet loss function, different margin values were set for comparison experiments, and the experimental results are shown in
Figure 4. For the NCBI dataset and ADR dataset, the model achieved the best results when the margin value was 0.1. When the margin value was set too low, the loss tended to be close to zero, and it was difficult to distinguish similar entities. When the margin value was set to 0, the accuracy was only 88.38% and 89.65% on both datasets. When the margin value is set too large, the loss value keeps a large value, making it difficult to converge. Therefore, it is critical to set a reasonable margin value, which is an important indicator of similarity.
4.5.5. Comparisons with BERT-Based Methods
The original BERT-based biomedical entity linking method uses the pointwise ranking model to treat the ranking problem as a classification problem. However, this Pointwise ranking model does not abstract the relevant features mentioned by the candidates and mentions well, and it is difficult to distinguish the subtle features.
In response to the above problem, in this paper, we also try to introduce BERT and improve the original model utilizing Pairwise ranking. We propose a biomedical entity linking method (BPR) based on BioBERT and Pairwise ranking to learn better semantic representations. We introduce positive and negative entities and generate the form of triplets with mentions, then obtain semantic relevance representations by BioBERT pre-training model, respectively, and use the triplet loss function for training. Some effect improvement is achieved in the biomedical ranking task.
We also compare the proposed lightweight model with the BERT-Base model, which has 12 layers, 768 hidden dimensions, and 12 attention heads with a total of 107 million. Despite having less than 5 million parameters, our model based on inter-entity and intra-entity attention achieves very competitive or even better results than the BERT-based SOTA model on both datasets, and the experimental results are shown in
Table 6.
To show the efficiency of the model in this paper, we also compared the complexity (parameter size) and inference time of the model with the BERT-base model, and
Table 7 shows the comparison results. It is the time in the entire testing set. The comparison results show that the method in this paper has a very high CPU inference speed. The model in this paper is 9 times faster compared to the BERT-Base model and 11.8 times faster compared to the BERT(Pairwise) model, and the complexity of the model is much smaller, with about 23 times fewer model parameters. In summary, the experimental results show that the lightweight biomedical entity linking model proposed in this paper achieves performance comparable to state-of-the-art models on two benchmark datasets, with only a small number of parameters and fast inference. When speed and model size are taken into account, the method in this paper is easier and more practical to use for deployment and application.
4.5.6. Analysis of Different Dataset Size
By subsampling the dataset, we also investigate the performance of the model on training samples of different sizes, as shown in
Figure 5. The performance of the model in this paper grows when the number of training samples is gradually increased. When only 20% of the training samples were used, the accuracy on the NCBI and ADR datasets also reached 89.04% and 91.13%, respectively. More data will bring better performance, and the biomedical entity linking model in this paper can achieve better results despite using a small amount of labeled data.
4.5.7. Case Study of Removing Inter- and Intra-Entity Attention
In this part, we look more closely at the attention in a typical case. As a comparison, we used the model without self-attention or cross-attention. For the prediction results of the method in this paper, two samples are selected, as shown in
Table 8. Through the self-attention mechanism, each token in the mentions and candidates is given a weight to show how important each token is. By adding the cross-attention, the model can capture the keywords in entity mentions, and thus predict the standard words for irregular entity mentions. By integrating the self-attention and cross-attention modules, the model in this paper is highly capable of discovering and distinguishing the matching details and subtle features between candidate entities and entity mentions.
4.5.8. Error Analysis
For the prediction results of the method in this paper, three samples of prediction errors were selected, as shown in
Table 9. From the prediction error samples in
Table 9, the following conclusions can be obtained: for the case that one biomedical mention corresponds to multiple candidate entities, the model in this paper does not predict well. In addition, the more common causes of error cases are those of the same symptom part with different symptom modifiers, which is where this paper can continue to improve and enhance.
5. Conclusions and Future Work
Entity linking has received increasing attention as a fundamental task for various types of medical natural language processing tasks. In order to address the challenge of large numbers of parameters in large pre-trained models, the long inference time, and the difficulty of obtaining good results with a single matching model due to the excessive variety of biomedical mention representations, in this paper, we construct an efficient biomedical entity linking method that incorporates inter- and intra-entity attention in a unified model to better capture information between biomedical mentions and candidate entities themselves as well as between each other. The model in this paper is also more lightweight. We have systematically studied the influence of our idea and carried out experiments. Furthermore, we also designed a biomedical entity linking method based on BERT and pairwise ranking to compare with the lightweight method in this paper. Experimental results demonstrate that the proposed method in this paper achieves fairly competitive performance on two biomedical benchmark datasets. Furthermore, it also achieves comparable or even better results compared to the BERT-based entity linking method while having far fewer model parameters and very high inference speed. The results demonstrate the effectiveness of our model by achieving significant performance.
The biomedical entity linking method proposed in this paper can solve the problems in entity linking, but there are still some limitations, which will be addressed in future work. The specific shortcomings and improvement measures are as follows:
Firstly, the recall rate of the candidate phase directly determines the accuracy of the candidate ranking phase. It is worthwhile to further improve the upper bound of the ranking system. In addition, the task in this paper can also include features such as prior information, contextual information, and coherence information, and it is expected that the additional inclusion of this part of information can further improve the effect, which is to be further studied subsequently. Finally, the analysis of the incorrectly predicted entity mentions reveals that the ranking model is inaccurate in predicting the presence of a mention corresponding to more than one criterion word, for which a new model can be designed in future work to handle the prediction task of a mention corresponding to multiple criterion candidates.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}