
Pareto-Optimised Fog Storage Services with Novel Service-Level Agreement Specification




Abstract
:1. Introduction
- A new Fog Storage Services (an infrastructure layer) for database and file systems storage operations;
- A new SLA specification that is used in the orchestration of Fog storage containers;
- A new Pareto-based decision-making method for the placement of Fog storage containers (e.g., containerised databases and file systems) which is used to provide specific QoS guarantees.
2. Methodology
- Specification of infrastructure that is considered as deployment option in the Things-to-Cloud continuum. This also covered the consideration of deployment requirements for the proposed Fog Storage Services.
- Definition of SLA specification for the Fog Storage Services, which includes: mapping of the Fog Storage Services’ life cycle to the SLA life cycle stages, designing an SLA specification (language) for its use in Fog Storage and selection of relevant SLA parameters for the scenario.
- Definition of decision-making process for placement of service containers on nodes that guarantee optimal QoS.
- Implementation and integration of the research and developed decision-making method and SLA specification within the DECENTER Fog and Brokerage Platform.
- Proof of concept by means of simulation with a set of 100 nodes.
- Proof of concept in an experimental testbed with a set of 13 nodes and real-time metrics.
- Interpretation and discussion of results.
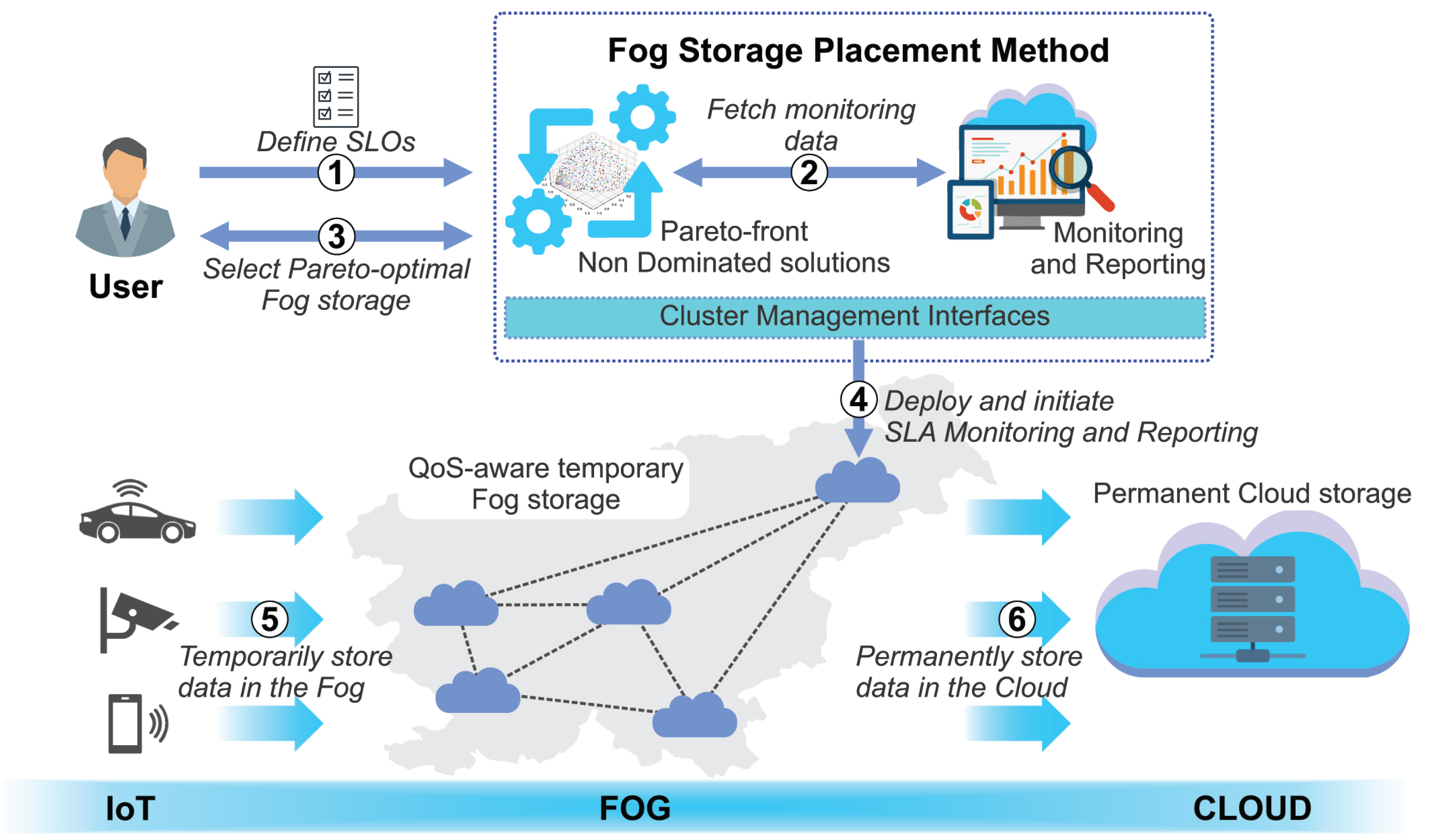
3. Dynamic Fog Storage Services
4. SLA Specification for the Fog Storage Services
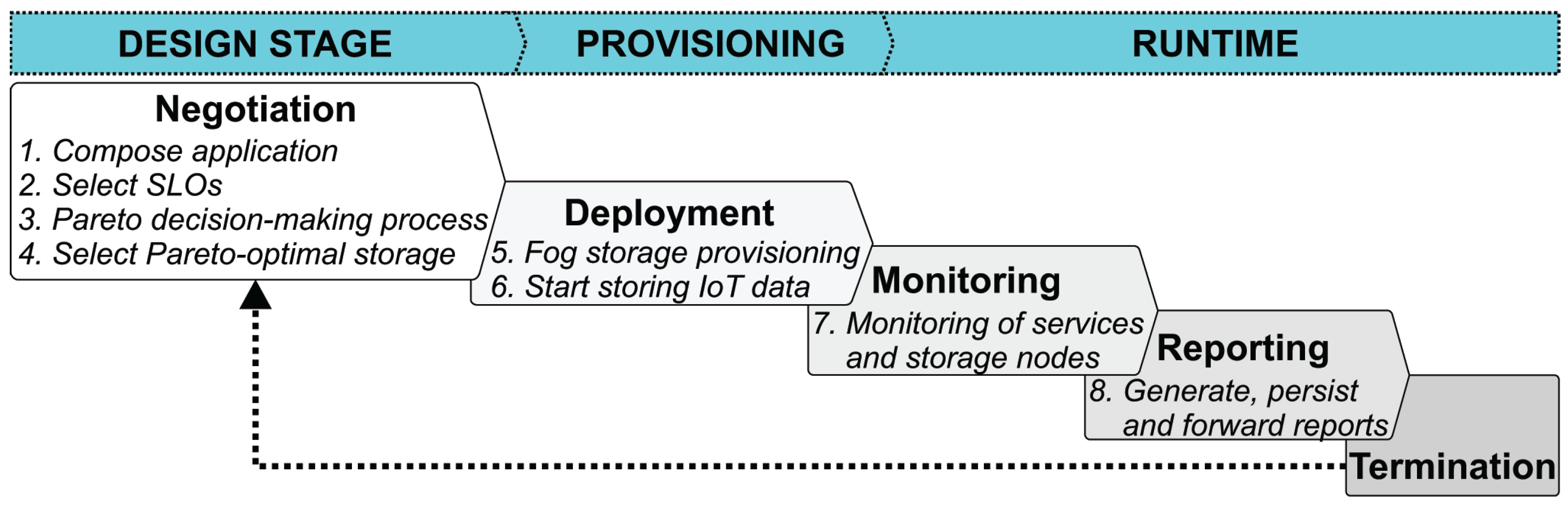
4.1. SLA Life Cycle
- Negotiation: Parties involved in the SLA specify service terms and levels of the provided service on which to agree and may contain also monetary elements. If negotiation adapts to changing QoS demands of the user, the negotiation is dynamic. For example, the user might request for more Fog storage instances. SLA terms might be formalised either by standardised application-agnostic templates, such as WSLA [38] and WS-Agreement [39], or in ad hoc manner that is understood by the enclosed parties. This paper contributes to formalisation of the SLA negotiation by defining custom SLA templates, as described in Section 4.3.
- Deployment (Establishment): Service requests from users are provisioned in respective Fog storage nodes. The SLA specification and evaluation define the allocation capacity of resource nodes. It is common to classify SLAs in various classes, such as gold, silver and bronze, to which users are assigned. In our work, SLA is established by applying user-specified QoS requirements and cost constraints in the SLA template, and then invoking the Multi-objective optimisation framework to enforce them.
- Monitoring: The deployed services, as well as the resource nodes where the services are run, are being monitored periodically for their health status. In case of substantial service disruptions, the terms of the SLA might get violated. Monitoring can span many dimensions, such as FRs and NFRs of the job, status of resource nodes and network conditions. We use monitoring to estimate performance-related metrics to detect SLA violations.
- Violation: The likelihood of a job failing or not meeting its defined service levels represents a violation alert and may be sometimes reported as part of monitored data. Our work focuses on SLA control mechanisms in order to maintain QoS as agreed by the SLA.
- Reporting: Provisioning of services and audits is reported in log files that can be securely stored on trusted storage infrastructures, immutable ledgers or similar.
- Termination: An SLA may end either when the service is finished or as a response to the violation of one of the parties.
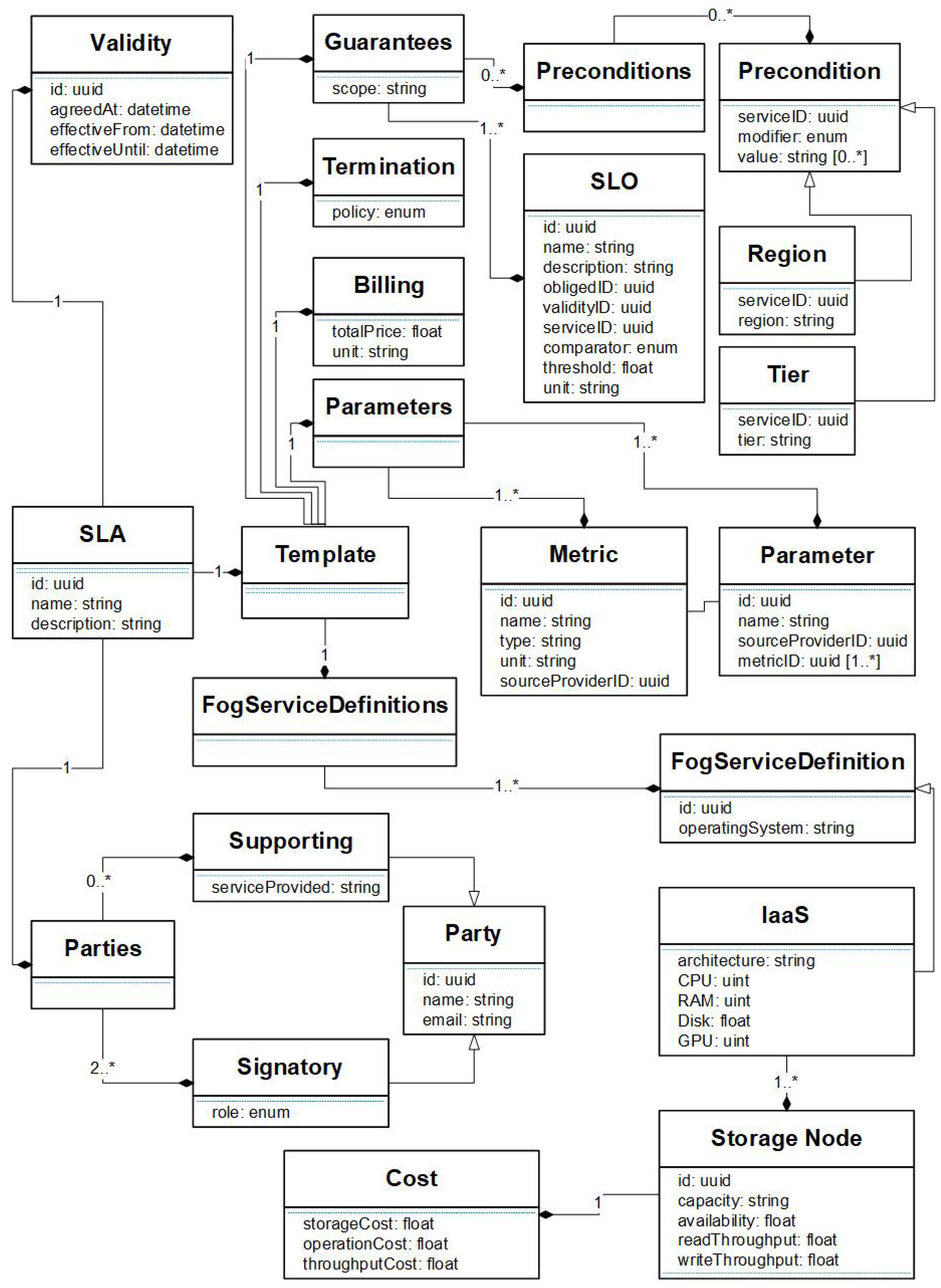
4.2. SLA Specification
4.3. SLA Specification Language for Fog Storage
- Parties are entities specified with unique IDs that sign the SLA agreement. Namely, the Signatory represents the service provider and service costumer, whilst Supporting represents trusted third party entities (e.g., trusted monitoring service provider).
- Validity refers to the agreement validity in the specified time period.
- Fog Service Definition is a detailed description of a storage node in the Edge-Fog-Cloud. It represents an IaaS, specified with attributes such as operating system, architecture type, amount of resources and cost.
- Guarantees are a set of precondition rules and SLOs, where the precondition rules refer to hard constraints (i.e., regional and/or tier restrictions) and SLO refers to a constraint on which parties are obliged to respect, how long an SLO is valid and which service an SLO applies to.
- Parameters are defined as a guarantee in an SLO definition. They are defined by a set of metrics, where a metric is the smallest unit that can be measured, and is defined by an arbitrary name, the type of its value, and the unit of measure. As future work, we will investigate on using simple metrics on monitoring directions in order to specify how often a metric should be monitored.
- Billing contains the total price of the reservation, which in our case is a single value. However, as future work, we will investigate on the definition of penalties in case an SLA is violated.
- Terminations contain a set of policies describing what events could terminate an SLA. In the future, we will also investigate on potential termination policies and the different associated penalties.
4.4. SLA Parameters
- Analysis of the various public Cloud providers and their currently offered SLA contracts (e.g., AWS S3 availability SLA (https://aws.amazon.com/s3/sla/, accessed on 5 January 2022));
- Analysis of the monitoring and control possibilities for SLA parameters, which can be implemented as a monitoring system.
4.4.1. Availability
4.4.2. Throughput
4.4.3. Cost
5. Pareto-Based Decision Making for Placement of Storage Containers
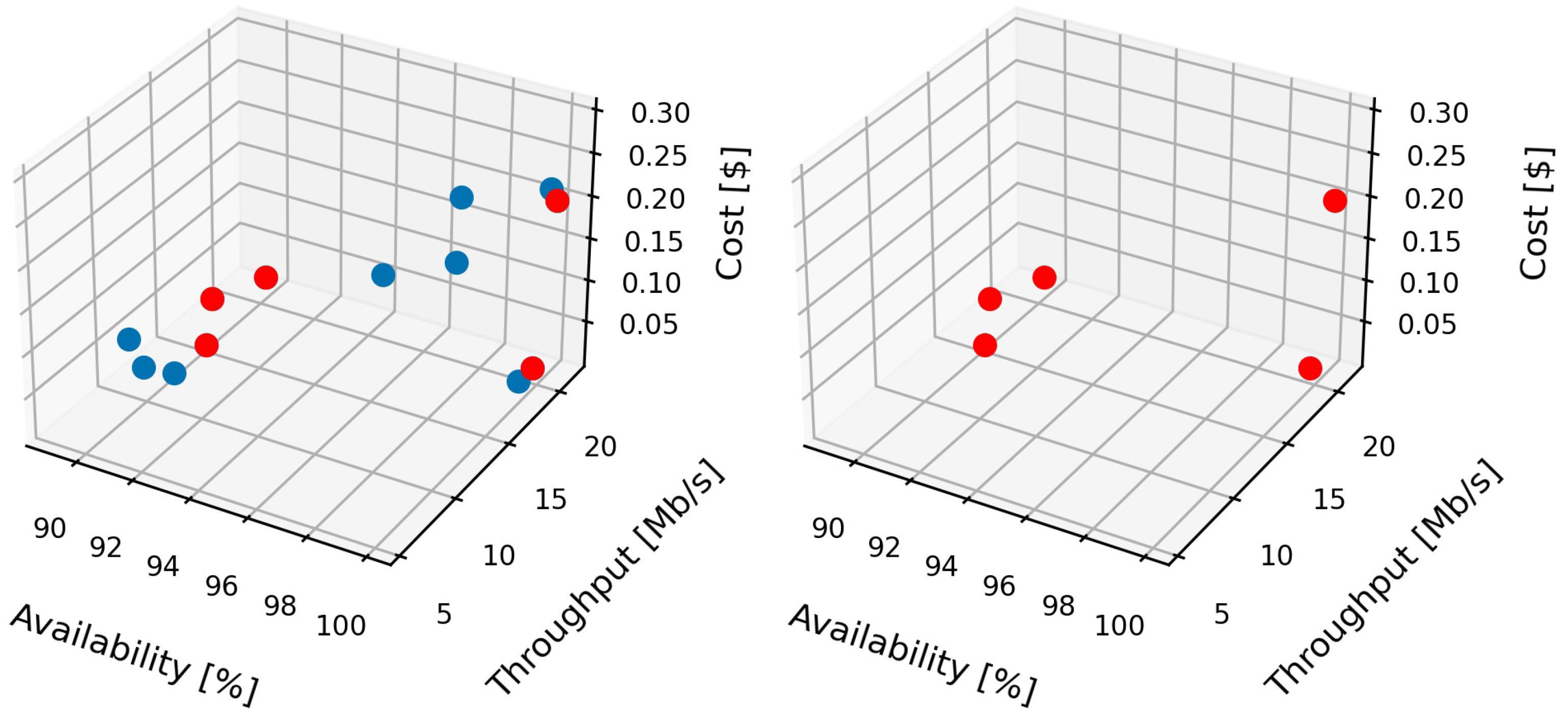
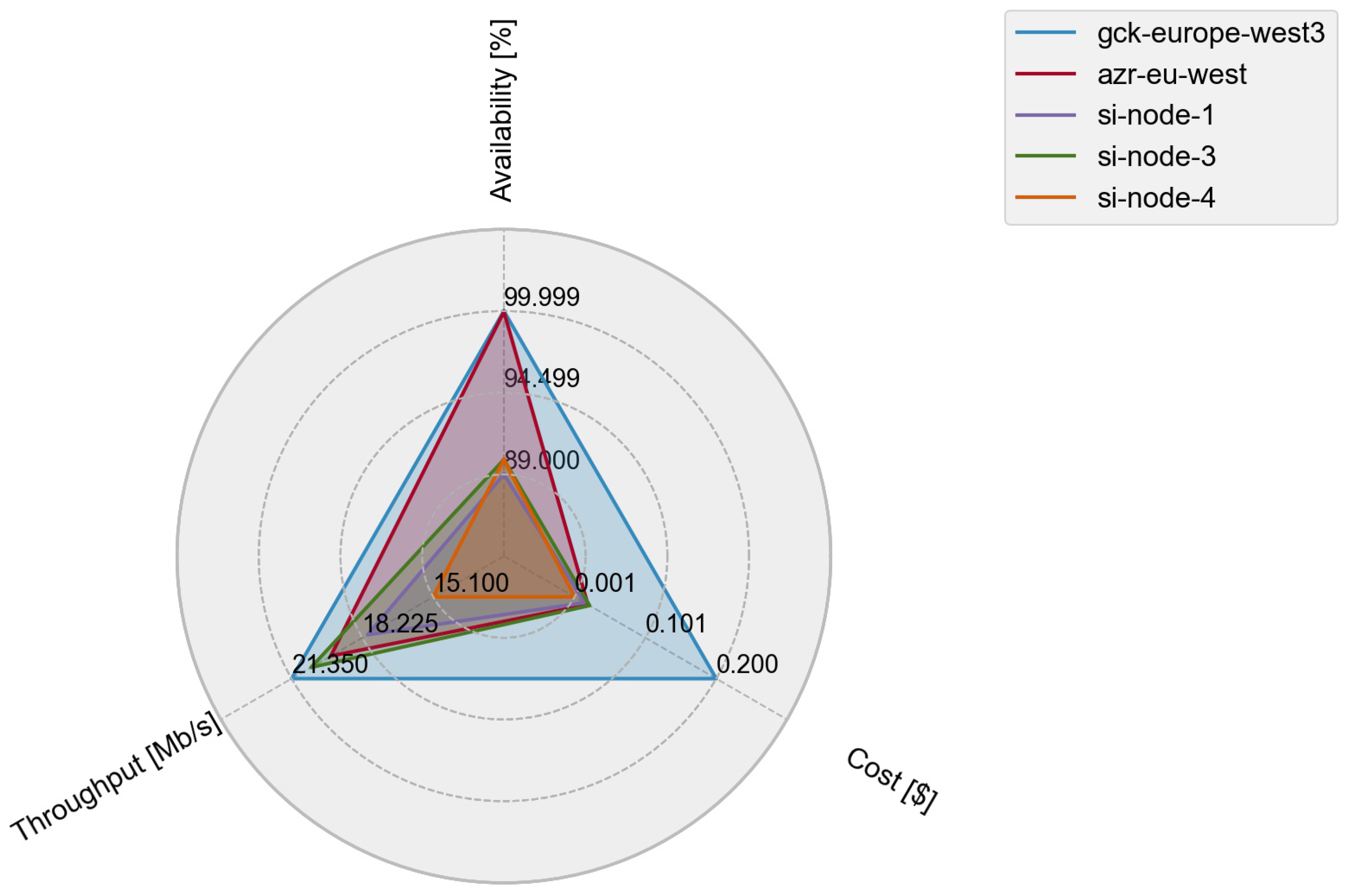
6. Experimental Evaluation
6.1. Implementation
- Application Services offer services for the composition of smart applications;
- Fog Platform facilitates resource allocation, monitoring and orchestration in the Edge-Fog-Cloud continuum. Hence, the proposed SLA specification (i.e., SLA management component and Pareto-based decision-making mechanism) is part of this layer. The SLA specification is represented by a JSON structure that is exchanged among the components in this layer. In particular, the SLA management component dynamically certifies SLAs stipulated with other cloud/fog providers when some resources are rented through the Brokerage Platform, by taking as input the needed monitoring data and notifying the Brokerage Platform if any SLA violations occur. Essentially, the Pareto-based decision-making mechanisms complement the set of (re)deployment algorithms that are available in the platform [58,59]. The Pareto-based decision-making mechanisms are implemented as a RESTful Java microservice that are run in a Docker container.
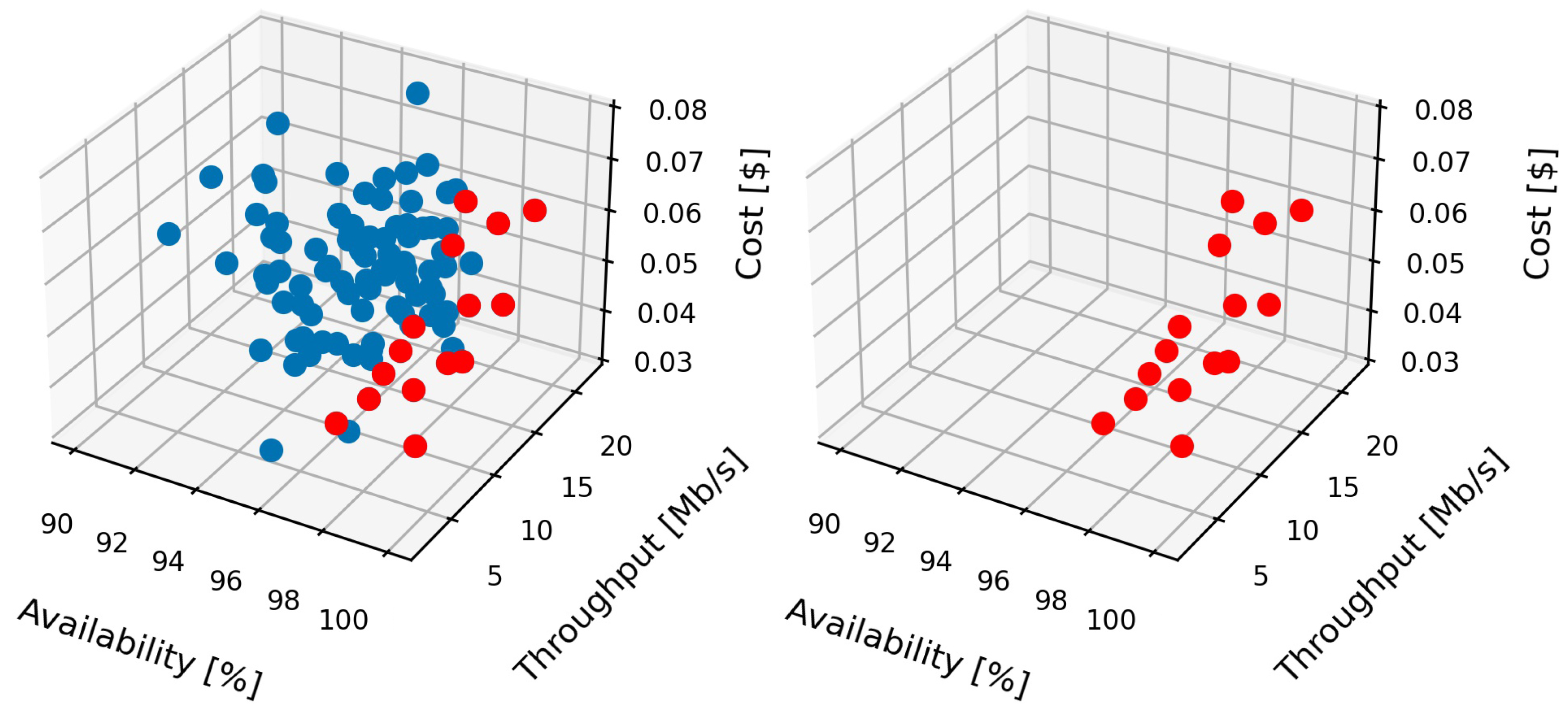
6.2. Experimental Evaluation and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kochovski, P.; Stankovski, V. Building applications for smart and safe construction with the DECENTER Fog Computing and Brokerage Platform. Autom. Constr. 2021, 124, 103562. [Google Scholar]
- Li, X.; Lu, R.; Liang, X.; Shen, X.; Chen, J.; Lin, X. Smart community: An internet of things application. IEEE Commun. Mag. 2011, 49, 68–75. [Google Scholar]
- Asghari, P.; Rahmani, A.M.; Javadi, H.H.S. Internet of Things applications: A systematic review. Comput. Netw. 2019, 148, 241–261. [Google Scholar]
- Kochovski, P.; Stankovski, V. Supporting smart construction with dependable edge computing infrastructures and applications. Autom. Constr. 2018, 85, 182–192. [Google Scholar]
- Kochovski, P.; Sakellariou, R.; Bajec, M.; Drobintsev, P.; Stankovski, V. An architecture and stochastic method for database container placement in the edge-fog-cloud continuum. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; IEEE: Rio de Janeiro, Brazil, 2019; pp. 396–405. [Google Scholar]
- The Linux Foundation. Kubernetes Documentation. 2021. Available online: https://kubernetes.io/docs/ (accessed on 5 January 2022).
- Gill, S.S.; Buyya, R. Resource provisioning based scheduling framework for execution of heterogeneous and clustered workloads in clouds: From fundamental to autonomic offering. J. Grid Comput. 2019, 17, 385–417. [Google Scholar]
- Wang, D.; Yang, Y.; Mi, Z. A genetic-based approach to web service composition in geo-distributed cloud environment. Comput. Electr. Eng. 2015, 43, 129–141. [Google Scholar]
- Serrano, D.; Bouchenak, S.; Kouki, Y.; de Oliveira, F.A., Jr.; Ledoux, T.; Lejeune, J.; Sopena, J.; Arantes, L.; Sens, P. SLA guarantees for cloud services. Future Gener. Comput. Syst. 2016, 54, 233–246. [Google Scholar] [CrossRef]
- Jrad, F.; Tao, J.; Brandic, I.; Streit, A. SLA enactment for large-scale healthcare workflows on multi-Cloud. Future Gener. Comput. Syst. 2015, 43–44, 135–148. [Google Scholar] [CrossRef]
- Yang, X.; Nasser, B.; Surridge, M.; Middleton, S. A business-oriented Cloud federation model for real-time applications. Future Gener. Comput. Syst. 2012, 28, 1158–1167. [Google Scholar] [CrossRef]
- García, A.G.; Espert, I.B.; García, V.H. SLA-driven dynamic cloud resource management. Future Gener. Comput. Syst. 2014, 31, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Yin, J.; Tang, Y.; Deng, S.; Zheng, B.; Zomaya, A.Y. MUSE: A multi-tierd and SLA-driven deduplication framework for cloud storage systems. IEEE Trans. Comput. 2020, 70, 759–774. [Google Scholar]
- Wang, Y.; Tao, X.; Zhao, F.; Tian, B.; Vera Venkata Sai, A.M. SLA-aware resource scheduling algorithm for cloud storage. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 1–10. [Google Scholar]
- Conejero, J.; Rana, O.; Burnap, P.; Morgan, J.; Caminero, B.; Carrión, C. Analyzing Hadoop power consumption and impact on application QoS. Future Gener. Comput. Syst. 2016, 55, 213–223. [Google Scholar] [CrossRef]
- Kessaci, Y.; Melab, N.; Talbi, E.G. A multi-start local search heuristic for an energy efficient VMs assignment on top of the OpenNebula cloud manager. Future Gener. Comput. Syst. 2014, 36, 237–256. [Google Scholar] [CrossRef] [Green Version]
- Mayer, R.; Gupta, H.; Saurez, E.; Ramachandran, U. Fogstore: Toward a distributed data store for fog computing. In Proceedings of the 2017 IEEE Fog World Congress (FWC), Santa Clara, CA, USA, 30 October–1 November 2017; IEEE: Santa Clara, CA, USA, 2017; pp. 1–6. [Google Scholar]
- Gedeon, J.; Himmelmann, N.; Felka, P.; Herrlich, F.; Stein, M.; Mühlhäuser, M. vStore: A context-aware framework for mobile micro-storage at the edge. In Proceedings of the International Conference on Mobile Computing, Applications, and Services, Shanghai, China, 12 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 165–182. [Google Scholar]
- Ficco, M.; Esposito, C.; Xiang, Y.; Palmieri, F. Pseudo-dynamic testing of realistic edge-fog cloud ecosystems. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar]
- Singh, J.; Singh, P.; Gill, S.S. Fog computing: A taxonomy, systematic review, current trends and research challenges. J. Parallel Distrib. Comput. 2021, 157, 56–85. [Google Scholar]
- Li, L.E.; Woo, T. Dynamic Load Balancing and Scaling of Allocated Cloud Resources in an Enterprise Network. U.S. Patent App. 12/571,271, 31 March 2011. [Google Scholar]
- Chaczko, Z.; Mahadevan, V.; Aslanzadeh, S.; Mcdermid, C. Availability and load balancing in cloud computing. In Proceedings of the International Conference on Computer and Software Modeling, Singapore, 19–23 March 2011; Volume 14. [Google Scholar]
- Puthal, D.; Obaidat, M.S.; Nanda, P.; Prasad, M.; Mohanty, S.P.; Zomaya, A.Y. Secure and sustainable load balancing of edge data centers in fog computing. IEEE Commun. Mag. 2018, 56, 60–65. [Google Scholar]
- Talaat, F.M.; Saraya, M.S.; Saleh, A.I.; Ali, H.A.; Ali, S.H. A load balancing and optimization strategy (LBOS) using reinforcement learning in fog computing environment. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4951–4966. [Google Scholar]
- Manvi, S.S.; Shyam, G.K. Resource management for Infrastructure as a Service (IaaS) in cloud computing: A survey. J. Netw. Comput. Appl. 2014, 41, 424–440. [Google Scholar]
- Ni, L.; Zhang, J.; Jiang, C.; Yan, C.; Yu, K. Resource allocation strategy in fog computing based on priced timed petri nets. IEEE Internet Things J. 2017, 4, 1216–1228. [Google Scholar]
- Hong, C.H.; Varghese, B. Resource management in fog/edge computing: A survey on architectures, infrastructure, and algorithms. ACM Comput. Surv. (CSUR) 2019, 52, 1–37. [Google Scholar]
- Chaisiri, S.; Lee, B.S.; Niyato, D. Optimization of resource provisioning cost in cloud computing. IEEE Trans. Serv. Comput. 2012, 5, 164–177. [Google Scholar]
- Singh, S.; Chana, I. Q-aware: Quality of service based cloud resource provisioning. Comput. Electr. Eng. 2015, 47, 138–160. [Google Scholar]
- Skarlat, O.; Schulte, S.; Borkowski, M.; Leitner, P. Resource provisioning for IoT services in the fog. In Proceedings of the 2016 IEEE 9th International Conference on Service-Oriented Computing and Applications (SOCA), Macau, China, 4–6 November 2016; IEEE: Macau, China, 2016; pp. 32–39. [Google Scholar]
- Naha, R.K.; Garg, S.; Chan, A.; Battula, S.K. Deadline-based dynamic resource allocation and provisioning algorithms in fog-cloud environment. Future Gener. Comput. Syst. 2020, 104, 131–141. [Google Scholar]
- Buyya, R.; Garg, S.K.; Calheiros, R.N. SLA-oriented resource provisioning for cloud computing: Challenges, architecture, and solutions. In Proceedings of the 2011 International Conference on Cloud and Service Computing, Hong Kong, China, 12–14 December 2014; IEEE: Hong Kong, China, 2014; pp. 1–10. [Google Scholar]
- Singh, S.; Chana, I. Resource provisioning and scheduling in clouds: QoS perspective. J. Supercomput. 2016, 72, 926–960. [Google Scholar]
- Gill, S.S.; Chana, I.; Singh, M.; Buyya, R. CHOPPER: An intelligent QoS-aware autonomic resource management approach for cloud computing. Clust. Comput. 2018, 21, 1203–1241. [Google Scholar]
- Singh, S.; Chana, I.; Buyya, R. STAR: SLA-aware autonomic management of cloud resources. IEEE Trans. Cloud Comput. 2017, 8, 1040–1053. [Google Scholar]
- DECENTER Consortium. DECENTER Use Cases: Smart City Crossing Safety. 2021. Available online: https://www.decenter-project.eu/use-cases-2/ (accessed on 5 January 2022).
- Faniyi, F.; Bahsoon, R. A Systematic Review of Service Level Management in the Cloud. ACM Comput. Surv. 2015, 48, 1–27. [Google Scholar] [CrossRef]
- Ludwig, H.; Keller, A.; King, R.P.; Franck, R. Web Service Level Agreement (WSLA) Language Specification; IBM: Armonk, NY, USA, 2003; pp. 815–824. [Google Scholar]
- Andrieux, A.; Czajkowski, K.; Keahey, K.; Dan, A.; Keahey, K.; Ludwig, H.; Pruyne, J.; Rofrano, J.; Tuecke, S.; Xu, M. Web Services Agreement Specification (WS-Agreement), 2004.
- Kochovski, P.; Stankovski, V.; Gec, S.; Faticanti, F.; Savi, M.; Siracusa, D.; Kum, S. Smart Contracts for Service-Level Agreements in Edge-to-Cloud Computing. J. Grid Comput. 2020, 18, 673–690. [Google Scholar]
- Venugopal, S.; Chu, X.; Buyya, R. A Negotiation Mechanism for Advance Resource Reservations Using the Alternate Offers Protocol. In Proceedings of the 2008 16th International Workshop on Quality of Service, Enschede, The Netherlands, 2–4 June 2008; pp. 40–49. [Google Scholar] [CrossRef]
- Ludwig, H.; Keller, A.; Dan, A.; King, R. A service level agreement language for dynamic electronic services. In Proceedings of the Fourth IEEE International Workshop on Advanced Issues of E-Commerce and Web-Based Information Systems (WECWIS 2002), Newport Beach, CA, USA, 26–28 June 2002; IEEE: Newport Beach, CA, USA, 2002; pp. 25–32. [Google Scholar] [CrossRef]
- Frolund, S.; Koistinen, J. QML: A Language for Quality of Service Specification; Hewlett-Packard Laboratories: Palo Alto, CA, USA, 1998. [Google Scholar]
- Sakellariou, R.; Yarmolenko, V. On the flexibility of WS-agreement for job submission. In Proceedings of the 3rd International Workshop on Middleware for Grid Computing, Grenoble, France, 28 November–2 December 2005; Volume 7, pp. 1–6. [Google Scholar]
- Skene, J.; Lamanna, D.; Emmerich, W. Precise service level agreements. In Proceedings of the 26th International Conference on Software Engineering, Edinburgh, UK, 23–28 May 2004; IEEE: Edinburgh, UK, 2004; Volume 11, pp. 179–188. [Google Scholar] [CrossRef] [Green Version]
- Loyall, J.; Schantz, R.; Zinky, J.; Bakken, D. Specifying and measuring quality of service in distributed object systems. In Proceedings of the First International Symposium on Object-Oriented Real-Time Distributed Computing (ISORC ’98), Kyoto, Japan, 20–22 April 1998; IEEE: Kyoto, Japan, 1998; pp. 43–52. [Google Scholar] [CrossRef]
- Copil, G.; Moldovan, D.; Truong, H.L.; Dustdar, S. SYBL: An Extensible Language for Controlling Elasticity in Cloud Applications. In Proceedings of the 2013 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, Delft, The Netherlands, 13–16 May 2013; pp. 112–119. [Google Scholar] [CrossRef]
- Cascella, R.G.; Blasi, L.; Jegou, Y.; Coppola, M.; Morin, C. Contrail: Distributed Application Deployment under SLA in Federated Heterogeneous Clouds. In The Future Internet; Galis, A., Gavras, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 91–103. [Google Scholar]
- Kearney, K.T.; Torelli, F. The SLA Model. In Service Level Agreements for Cloud Computing; Wieder, P., Butler, J.M., Theilmann, W., Yahyapour, R., Eds.; Springer: New York, NY, USA, 2011; pp. 43–67. [Google Scholar]
- Nabi, M.; Toeroe, M.; Khendek, F. Availability in the cloud: State of the art. J. Netw. Comput. Appl. 2016, 60, 54–67. [Google Scholar]
- Amini, M.R.; Baidas, M.W. GoodPut, Collision Probability and Network Stability of Energy-Harvesting Cognitive-Radio IoT Networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1283–1296. [Google Scholar]
- Naldi, M.; Mastroeni, L. Cloud storage pricing: A comparison of current practices. In Proceedings of the 2013 International Workshop on Hot Topics in Cloud Services, Prague, Czech Republic, 20–21 April 2013; pp. 27–34. [Google Scholar]
- Waibel, P.; Matt, J.; Hochreiner, C.; Skarlat, O.; Hans, R.; Schulte, S. Cost-optimized redundant data storage in the cloud. Serv. Oriented Comput. Appl. 2017, 11, 411–426. [Google Scholar] [CrossRef] [Green Version]
- Kimovski, D.; Saurabh, N.; Stankovski, V.; Prodan, R. Multi-objective middleware for distributed VMI repositories in federated cloud environment. Scalable Comput. Pract. Exp. 2016, 17, 299–312. [Google Scholar]
- Štefanič, P.; Kimovski, D.; Suciu, G.; Stankovski, V. Non-functional requirements optimisation for multi-tier cloud applications: An early warning system case study. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–8. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Kochovski, P.; Gec, S.; Stankovski, V.; Bajec, M.; Drobintsev, P.D. Trust management in a blockchain based fog computing platform with trustless smart oracles. Future Gener. Comput. Syst. 2019, 101, 747–759. [Google Scholar]
- Kochovski, P.; Drobintsev, P.D.; Stankovski, V. Formal quality of service assurances, ranking and verification of cloud deployment options with a probabilistic model checking method. Inf. Softw. Technol. 2019, 109, 14–25. [Google Scholar]
- Faticanti, F.; Savi, M.; De Pellegrini, F.; Kochovski, P.; Stankovski, V.; Siracusa, D. Deployment of Application Microservices in Multi-Domain Federated Fog Environments. In Proceedings of the 2020 International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; IEEE: Barcelona, Spain, 2020; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | QoS Attributes | SLA Impl. | SLA Spec. | Type of Nodes | Utility |
|---|---|---|---|---|---|
| Gill and Buyya, 2019 [7] | Reliability Availability User satisfaction | Yes | No | Cloud | Data storage and processing |
| Wang et al., 2015 [8] | Cost Reputation Availability Response time | Yes | No | Cloud | Data storage and processing |
| Serrano et al., 2016 [9] | Cost Reliability Availability Response time | Yes | Yes | Cloud | Data storage and processing |
| Jrad et al., 2015 [10] | QoS Cost Time complexity Network throughput | Yes | No | Cloud | Data Processing |
| Yang et al., 2012 [11] | RTFThroughput RTFTickDuration AveragePacketLatency ClientConnectionCount | Yes | No | Cloud | Data storage and processing |
| García et al., 2014 [12] | Cost Number of failed requests | Yes | Yes | Cloud | Data storage and processing |
| Yin al., 2020 [13] | Cost I/O performance | Yes | Yes | Cloud | Data storage |
| Wang et al., 2020 [14] | Storage Throughput | Yes | No | Cloud | Data storage |
| Conejero et al., 2016 [15] | Cost Energy-efficiency | Yes | No | Cloud | Data processing |
| Kessaci et al., 2014 [16] | Cost Energy-efficiency | Yes | No | Cloud | N/A |
| Mayer et al., 2017 [17] | Latency Usage-context | No | No | Fog | Data storage |
| Gedeon et al., 2018 [18] | Data type Usage-context | No | No | Edge | Data storage |
| Proposed solution | Cost Availability Throughput | Yes | Yes | Things-to-Cloud computing continuum | Data storage and processing |
| Infrastructure | Location | Availability [%] | Throughput [Mb/s] | Cost [$] |
|---|---|---|---|---|
| aws-eu-west-3 | France | 99.999 | 12.1 | 0.306 |
| aws-eu-south-1 | Italy | 99.999 | 5.41 | 0.297 |
| aws-eu-central-1 | Germany | 99.999 | 11.81 | 0.237 |
| gck-eu-west-3 | Germany | 99.999 | 21.35 | 0.200 |
| gck-eu-west-6 | Switzerland | 99.999 | 20.73 | 0.221 |
| azr-de-central | Germany | 99.95 | 18.22 | 0.021 |
| azr-eu-west | The Netherlands | 99.95 | 19.62 | 0.020 |
| si-node-0 | Slovenia | 89.0 | 12.01 | 0.001 |
| si-node-1 | 89.0 | 17.99 | 0.015 | |
| si-node-2 | 90.0 | 10.88 | 0.050 | |
| si-node-3 | 90.0 | 20.49 | 0.022 | |
| si-node-4 | 90.0 | 15.1 | 0.001 | |
| si-node-5 | 90.0 | 12.3 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kochovski, P.; Paščinski, U.; Stankovski, V.; Ciglarič, M. Pareto-Optimised Fog Storage Services with Novel Service-Level Agreement Specification. Appl. Sci. 2022, 12, 3308. https://doi.org/10.3390/app12073308
Kochovski P, Paščinski U, Stankovski V, Ciglarič M. Pareto-Optimised Fog Storage Services with Novel Service-Level Agreement Specification. Applied Sciences. 2022; 12(7):3308. https://doi.org/10.3390/app12073308
Chicago/Turabian StyleKochovski, Petar, Uroš Paščinski, Vlado Stankovski, and Mojca Ciglarič. 2022. "Pareto-Optimised Fog Storage Services with Novel Service-Level Agreement Specification" Applied Sciences 12, no. 7: 3308. https://doi.org/10.3390/app12073308
APA StyleKochovski, P., Paščinski, U., Stankovski, V., & Ciglarič, M. (2022). Pareto-Optimised Fog Storage Services with Novel Service-Level Agreement Specification. Applied Sciences, 12(7), 3308. https://doi.org/10.3390/app12073308